StarMem Tech, a Tsinghua University spinoff, secures seed funding to challenge Nvidia's EgoScale data path
The match point has shifted.

"The inflection point has shifted." By Qian Ren

The global race for embodied data infrastructure is heating up fast. NVIDIA Research released the EgoScale dataset and training framework in 2026, training VLA models on egocentric human operation videos — using 20,854 hours of first-person human video with action annotations — and observed an approximately log-linear scaling law between data scale and validation loss. 1X collects first-person human perspective and household behavior data, amassing millions of hours of home-scene video through its Project Sunday. Lightwheel Intelligence takes a hybrid approach combining simulated synthetic data with human video data (EgoSuite), claiming cumulative deliveries exceeding 1 million hours with its valuation climbing toward $1 billion.
Within months, industry attention has shifted from "who can collect more" to "who can turn Human-centric / Ego-centric data into genuinely high-DoF, high-precision, low-cost, trainable assets."
Behind this lies a clear paradigm shift in data. Over the past year, leading global players have almost simultaneously turned their gaze toward Human-centric data: not larger-scale third-person footage, not merely expensive and scarce real-device teleoperation, but data closer to the true distribution of human operation. And among these, Ego-centric — centered on first-person human perspective, real physical interaction, and multimodal perception — is rapidly becoming the most critical collection route.
The reason is straightforward: what robots ultimately need to learn isn't to understand the world, but to get actions right in real physical environments. Third-person video lacks contact and control details; simulation struggles to fully cover real-world physical long tails; pure teleoperation data remains expensive and scarce. What's truly scarce is data that is sufficiently real, sufficiently fine-grained, and simultaneously scalable and directly digestible by models. At precisely this inflection point, a company choosing to tackle this hard problem through multimodal fusion and wearable high-precision collection is beginning to emerge.
"Dark Current Waves" (An Yong Waves) has learned exclusively that Stellar Memory Technology (星忆科技), a startup focused on Ego-centric data collection, has completed a seed round in the tens of millions of RMB, led by Tsinghua-affiliated Shuimu Venture Capital, with Quanshi Capital — the company's incubator — providing long-term industrial and capital support and also participating in this round; Shenzhou Tongyu-affiliated Yaozhuo Capital and seasoned industrial angel teams also joined. Maple Pledge Capital has long served as the company's private equity financing advisor.**
Stellar Memory Technology was incubated from Tsinghua University's Department of Computer Science. Founder Zhiheng Song previously served as product lead for full-size bipedal humanoid robots at Zhiyuan Robotics, where he also built out the company's data collection and teleoperation systems. Before that, he was among the first 20 employees at MegaRobo, where he established the Innovative Applications Division and served as product lead, leading the R&D team through five 0-to-1 new product developments, heading development from dual-arm collaborative robots to desktop intelligent devices, and achieving the company's first 10,000-unit mass production milestone and over 100 million RMB in revenue.
If human-centric/ego-centric data is becoming the new foundation of embodied intelligence, then Stellar Memory's most distinctive feature isn't merely having bet on the right direction — it's that it happens to have assembled the hardest-to-connect segments of this chain within a single organization. Its core members cover embodied data, models, wearable devices, complex systems, and data engineering, forming a capability structure where "data — model — product — commercialization" all connect.
The team's technical backbone comes from Tsinghua, Beihang University, and other institutions, alongside seasoned industry experts from Efort and Hikvision, with long-term research in embodied intelligence, multimodal perception, 3D hand understanding, virtual reality, human-computer interaction, and computer vision. Collectively, they have published over 70 papers in top international conferences and journals including CVPR, ICCV, ECCV, NeurIPS, and IJCAI, and have led multiple national-level research projects.
Benchmarking against NVIDIA's EgoScale technical path, Stellar Memory is building a data collection hardware and software system oriented toward embodied intelligence and world models. Its differentiation lies in: not pursuing the two-finger gripper UMI route, but high precision on a high-DoF foundation; not collecting vision alone, but simultaneously fusing vision, touch, and pose; not merely providing tools, but attempting to close the full loop from collection to training.
Zhiheng Song believes that truly valuable real-device data isn't about who collects more, but who can simultaneously satisfy five conditions: real, precise, high-DoF, low-cost, and trainable. In his view, Stellar Memory's current advantages concentrate on the precision and DoF dimensions, while low cost and trainability will determine whether this path can truly scale.
Recently, "Dark Current Waves" met with Zhiheng Song and Stellar Memory's self-developed multimodal data collection wearable device in Beijing's Zhongguancun. He spoke with us about the fundamental divergences in dataset collection technical routes, the challenges of millimeter-level pose annotation, and the long road from data supplier to physical-world interface.
The conversation follows —
Part 01
From Collecting More to Collecting Right
Dark Current: There are many data companies, some with much larger funding than yours. How do you position Stellar Memory Technology?
Zhiheng Song: We're the physical data infrastructure for embodied intelligence. Through self-developed high-precision wearable devices and a data engine, we transform human "productive experience" into "digital nutrients" that robots can learn from. There's only one core thing: enabling robots to perform fine manipulation in real, complex environments. Not making robots dance, but making them hold a scalpel steady like a surgeon.
Dark Current: Why choose to start a company at this moment, from the data link? What did you see at Zhiyuan?
Zhiheng Song: At Zhiyuan, as product lead for full-size bipedal humanoids, I also handled data collection and teleoperation. We could clearly see that the industry's best-selling scenarios remained showrooms, commercial performances, research, and data collection — struggling to form replicable productive closed loops. The core bottleneck was insufficient high-quality real data: models lacked both effective representations of the physical world and transferable operation priors. What we're doing is filling this layer. From the outside, we're benchmarking EgoScale; from our internal perspective, this was a judgment formed early on — embodied intelligence ultimately lacks not just models and bodies, but the most efficient data pathway. NVIDIA making this route public and hot also shows it's becoming industry consensus.
Dark Current: Why has EgoScale become so prominent? Why are embodied robotics companies actively following this technical route? What's special about the EgoScale framework, and where's the breakthrough?
Zhiheng Song: EgoScale's rapid rise stems from validating a highly attractive path: achieving efficient transfer from human behavior to robotic operation capability through ultra-large-scale human first-person data. This matters enormously for embodied intelligence because robot training has long been constrained by expensive, slow real-device data collection with limited scene coverage, making true scale difficult. EgoScale's breakthrough isn't simply piling up data, but building a more systematic training framework. Through staged training, it first learns general behavior priors from massive human first-person operation data, then further transfers to robot action space, significantly improving success rates in dexterous manipulation tasks. This design gives it potential to break through traditional limitations of "small samples, heavy teleoperation, strong dependence on body-specific data."
More critically, this path naturally fits embodied industry's core current demand: on one hand, human data is easier to scale than robot data; on the other, this framework has strong generalization potential across different robot body forms and degrees of freedom. For robotics companies, whoever can more efficiently obtain transferable, scalable, reusable data and training paradigms gains advantage in the next phase of capability competition. This is why the entire industry is closely watching EgoScale.
Dark Current: How do you differ from EgoScale? Where?
Zhiheng Song: We differ in having more modalities — touch is essential for fine manipulation — and higher scene compatibility, not limited to laboratories. We're EgoScale in the wild, with virtually no scene constraints, able to directly deploy our devices in real production environments. This poses higher challenges for both algorithms and wearability comfort.
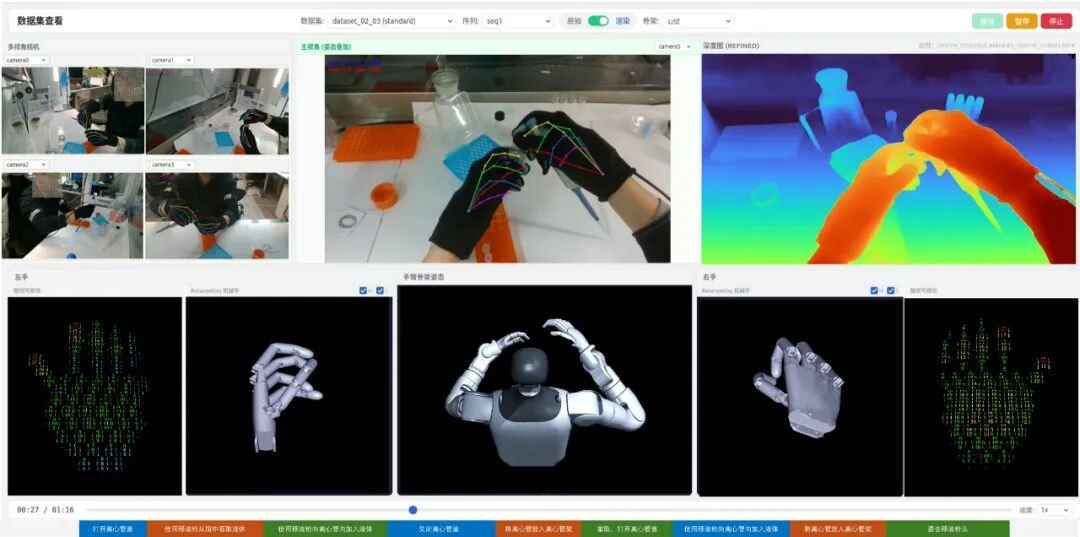
Stellar Memory EgoKit multimodal data collection suite and Stellar Memory HBR Engine data engine | Image source: Company
Dark Current: How do you understand "world-class"?
Zhiheng Song: What determines the ceiling isn't just model parameters, but the quality of teacher signals: multimodal collection, fine-grained hand understanding, and high-precision annotation — these are the first principles of high-quality embodied data. Imagine if demonstration actions themselves contain jitter, offset, and temporal errors — what the model learns won't be capability, but error. Human pose estimation is often a centimeter-level problem; hands typically enter millimeter-level territory: denser joints, more occlusion, more complex hand-object contact — technical difficulty doesn't increase linearly but multiplies. Precisely for this reason, hand understanding is among the hardest layers in embodied data, an L4-L5 level technology. We happen to have globally leading capability here, while human body pose is L2. Having gone deep on this layer, extending upward to upper body and full body becomes a smoother path.
Dark Current: Why must you do multimodal fusion (vision + touch + pose)? Isn't vision alone enough? Can't large models already understand the world?
Zhiheng Song: It's not that models aren't smart enough — they've simply never truly "touched" the real world. Fine manipulation requires at least three information types: 3D vision, body pose, and touch. 3D vision tells you where objects are; pose tells you how hand and arm reach there. But once contact actually occurs, what determines success or failure is often touch: whether there's contact, whether there's slip, how much force to apply, when to release. Touch provides contact state, friction change, and micro-slip information — it's the endpoint of vision and the starting point of force control.
Dark Current: We heard you can do hand gesture recognition while wearing gloves. Is that hard? Aren't Meta and Apple also doing this?
Zhiheng Song: Extremely hard. Meta uses flesh-colored gloves — essentially asking the model to treat them as "thicker human hands." We can use black gloves; the model recognizes this as a hand in feature space and precisely parses pose. Apple's hand technology is strong, but publicly still focuses on bare-hand interaction. Why does this matter? Because the most natural carrier for touch is gloves — if you can't stably complete hand understanding in worn state, you can't truly fuse vision, touch, and pose. The difficulty isn't just recognition itself, but making a multimodal system simultaneously work on precision, latency, and cost.
Dark Current: You mentioned "millimeter-level annotation" — what precision specifically? How does cost compare to traditional methods?
Zhiheng Song: For high-density, heavily occluded tasks like hands, traditional manual annotation and general open-source algorithms both struggle to simultaneously achieve precision and consistency. We can stably push our data engine's annotation capability to millimeter-level under long sequences and strong contact conditions, with stronger consistency than human expert annotators. On cost: manual annotation of one second of video (30 frames) from three perspectives, even at 0.1 RMB per image, costs 3 RMB per second — 180 RMB per minute. Our powerful annotation engine costs a few hundredths of traditional manual methods, with higher precision. This is the "low cost + high quality" dual flywheel.
Dark Current: Why not do simulated data? Isn't NVIDIA also pushing sim-to-real transfer?
Zhiheng Song: Simulation has value in pre-training, policy search, and parallel trial-and-error. But once entering real-world complex contact, the sim-to-real gap remains significant.
For example, accurately inserting a flexible ribbon cable — something that bends, springs back, and slips — into a millimeter-level interface and completing the snap in one try: such tasks involve contact, deformation, friction, occlusion, and continuous feedback correction, difficult to fully replicate in simulation. NVIDIA promoting sim-to-real is directionally correct, but the essence isn't "using simulation to replace reality" — it's making simulation closer to reality, which still requires substantial real data for continuous alignment and calibration.
Our judgment: truly valuable real-device data must simultaneously satisfy five conditions — real (physical interaction), precise (fine manipulation), high-DoF (generalization), low-cost (scalability), and trainable (standardized processing). All five are indispensable; simulation data fails at "real."
Dark Current: What specifically is your data collection process? How do you ensure low cost?
Zhiheng Song: Traditional real-device teleoperation requires renting space, buying equipment, hiring people — extremely high costs. Ours is a streaming process: collectors or workers wear our suite in real production lines or scenes, and the data engine captures vision, touch, position, and trajectory in real time with millisecond-level alignment, forming multimodal training data that can be further tensorized. Subsequently, our offline toolchain automatically performs "millimeter-level annotation," filtering invalid noise to form high-quality data directly usable for embodied model training.
Dark Current: Real environments are uncontrollable — how do you ensure data quality and safety? Will data be open-sourced?
Zhiheng Song: We have an embedded "quality audit engine" that automatically剔除 jitter, dropped frames, and logically unreasonable actions. On open-sourcing: Stellar Memory has a clear节奏 — we will gradually open-source 1,000 to 10,000 hours of high-precision datasets this year. We believe embodied intelligence prosperity can't rely on "closed-door" approaches; we want to push industry-wide co-building of foundations.
Dark Current: You mentioned two "pyramids" — one for robot capability, one for data. What do they each mean? Which layer does Stellar Memory target?
Zhiheng Song: We internally use two "pyramids" to understand embodied intelligence.
The first is the capability pyramid: from bottom up, the body is the base, above which is motor intelligence, then cognitive intelligence; and cognitive intelligence can be further divided into interaction intelligence and operational intelligence. The former addresses "can it understand, can it express"; the latter addresses "can it complete goal-directed, constraint-bound operation tasks in real physical environments." What truly determines an embodied system's ceiling is this operational intelligence layer.
The second is the data pyramid: the base is internet data, largest in scale, providing semantic and commonsense priors; above that is simulation/synthetic data, suitable for pre-training, policy search, and parallel trial-and-error; above that is multimodal real data represented by first-person human data; at the very top is real-device teleoperation data. Going higher, data volume decreases, but proximity to real tasks, real contact, and real control loops increases.
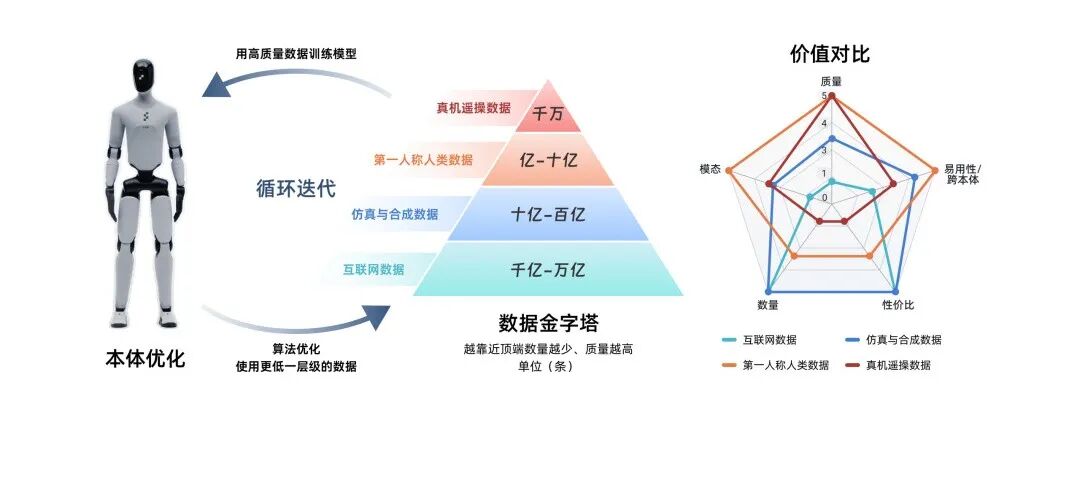
The higher you go, the less data, but the higher the value density. What the industry truly lacks today isn't another layer of broad, generic data, but high-quality real data that can enter complex contact and be effectively digested by models.
Part 02
From Data Supplier to Physical World Interface
Dark Current: What's your essential difference from other data collection companies, like those doing UMI (Universal Manipulation Interface) or real-device teleoperation?
Zhiheng Song: The significance of the UMI route lies in proving human demonstration can be an important entry point for robot learning; work like DexUMI pushes this route toward higher degrees of freedom. But Stellar Memory's difference from such routes isn't about whether we agree with this direction — it's about different objective functions: they prioritize solving low barrier, transferability, and scalability; while Stellar Memory prioritizes, under high-DoF premises, truly collecting complete, accurate, trainable data assets from the signals that determine fine manipulation ceilings — vision, touch, and pose.
We believe the two-finger gripper is an industrial legacy product, efficient only in specific scenes for specific tasks. But AGI requires generalization — using one body to perform various operations in complex physical worlds. This requires end effectors with high degrees of freedom. We don't do two-finger grippers; we do "high precision on a high-DoF foundation." The human hand has 21 degrees of freedom; UMI's two-finger gripper can't steadily hold a scalpel or press a lighter, but high-DoF dexterous hands can.
Stellar Memory's difference from such routes isn't about whether we can collect data at low cost, but whether we can simultaneously achieve precision, trainability, and scalability under higher degrees of freedom.
Dark Current: So your products and services are also B2B.
Zhiheng Song: Yes. The path is very clear: step one, serve universities and top labs (research needs), including data collection factories; step two, cut into robot body and model manufacturers (training needs); step three, reach end-scene parties (deployment needs). We want to build a complete commercial closed loop from collection tools to online engine to scene deployment. Selling wearable hardware and datasets — these are two standard product categories. For customers who simply want to quickly improve model training effects, they can directly buy finished datasets. We have corresponding technical support to rapidly help customers complete corresponding model training.
Dark Current: Both Tsinghua-affiliated and Huawei-affiliated players are working on embodied intelligence. How do you define your uniqueness? Do you worry that focusing only on data means lacking end-to-end capability?
Zhiheng Song: The Huawei-affiliated approach excels more at understanding systems from communications, engineering systems, and underlying architecture. We don't simply reduce this to factional differences — the key is how you define the hardest, most scarce problem in embodied intelligence.
Bodies can be bought; algorithms can run open-source. But high-precision, high-quality action data with real-device feedback is unavailable for purchase. It's non-standardized, strongly dependent on physical feedback. We're digitizing and standardizing this hardest-to-scale "craftsmanship," making it flow like tap water to all brain manufacturers.
Dark Current: How high is the ceiling for data scale? Some say hundreds of billions of data points are needed, others say 10 billion is enough. What do you think?
Zhiheng Song: This is an efficiency problem. Model builders want to reduce data needs; data builders want to improve quality and scale — they'll eventually meet in the middle. Early academia believed hundreds of billions to trillions of samples were needed, meaning 100 million to 1 billion hours. We believe it will ultimately land around 100 million hours. But this 100 million hours isn't a "weighted average" — it's the highest quality data. Like human genes evolving over 400-500 million years, pre-trained large models need this high-quality data to form "embodied genes," then improve specific task capabilities through real-device reinforcement learning.
Dark Current: Some say the endgame of robotics is national-level data infrastructure. Do you agree? Will you take sides?
Zhiheng Song: Rather than taking sides, it's about banding together. This industry is hard to tackle alone; it needs national teams and industrial ecosystems to build together.
Dark Current: When do you judge embodied intelligence can truly deploy? What role does Stellar Memory play in this process?
Zhiheng Song: Three years to factories, five years to homes.
Factories mean specific scenes with single tasks, improving accuracy to above 99% through real-device reinforcement learning. Homes mean different environments, requiring model generalization capability, plus safety and privacy requirements. The industry overall remains in POC phase; pure end-to-end solutions typically achieve only 70-80% accuracy, insufficient for stable deployment, still requiring human oversight or rule-based mechanisms as backup.
In the global embodied intelligence landscape, Physical Intelligence and Generalist focus more on upper-layer breakthroughs in models and general policies, while Stellar Memory cuts into a harder-to-replace layer: defining the general action interface for the AGI era through accumulation of high-quality, scalable real physical data.
Dark Current: Your team configuration is quite cross-disciplinary — Tsinghua academic background, Zhiyuan and MegaRobo mass production experience. How does this combination translate to competitiveness?
Zhiheng Song: Many understand embodied intelligence as point competition in models, hardware, or scenes. But the more fundamental competition is system efficiency in converting real-world experience into robot capability. Our team's true competitiveness lies in fully connecting within the team the hardest-to-link chains across academia, engineering, and industry: we understand both how real-world experience is collected, aligned, represented, and沉淀 as trainable assets, and how models learn from these assets and continuously verify, calibrate, and回流 in real scenes.
Point capabilities can be supplemented; closed-loop capability is hard to grow. What will truly differentiate embodied intelligence in the next stage isn't who can make a flashier model, better hardware, or more viral demo, but who can first establish scalable production capability for high-standard data assets, and make it into a system that continuously learns from the real world, continuously回流, and continuously grows capability. Whoever builds this system first has more opportunity to define the next stage of embodied intelligence's industrial path.
Layout | Meng Du Image sources | Visual China
Recommended Reading
Where Money Flows, People Rise and Fall