Attention Shifts Direction, Transformers Get a Bone-Deep Overhaul

Moonshot AI's New Architecture: AttnRes


Since its debut in 2017, the Transformer has become the near-universal foundation of modern AI. It has two core mechanisms: Attention, which selects information along the sequence dimension — deciding "which word to look at" when processing a passage; and residual connections, which propagate information along the depth dimension — passing the results of earlier layers all the way down.
The former has been studied and refined extensively. The latter has remained in its most basic form: each layer's output is added directly to the next layer's input with a fixed weight of 1, with all layers treated equally.
This design comes from ResNet, introduced in 2015. It solved the vanishing gradient problem in deep networks, making networks with hundreds or even thousands of layers feasible, and indirectly enabled the Transformer. But its operation is radically "egalitarian" — every layer's contribution is treated the same, with no prioritization.
Here's an analogy: a student takes 40 classes, and when finals come, they stack all their notes together in equal measure — regardless of which subjects are actually on the exam, each gets the same review time.
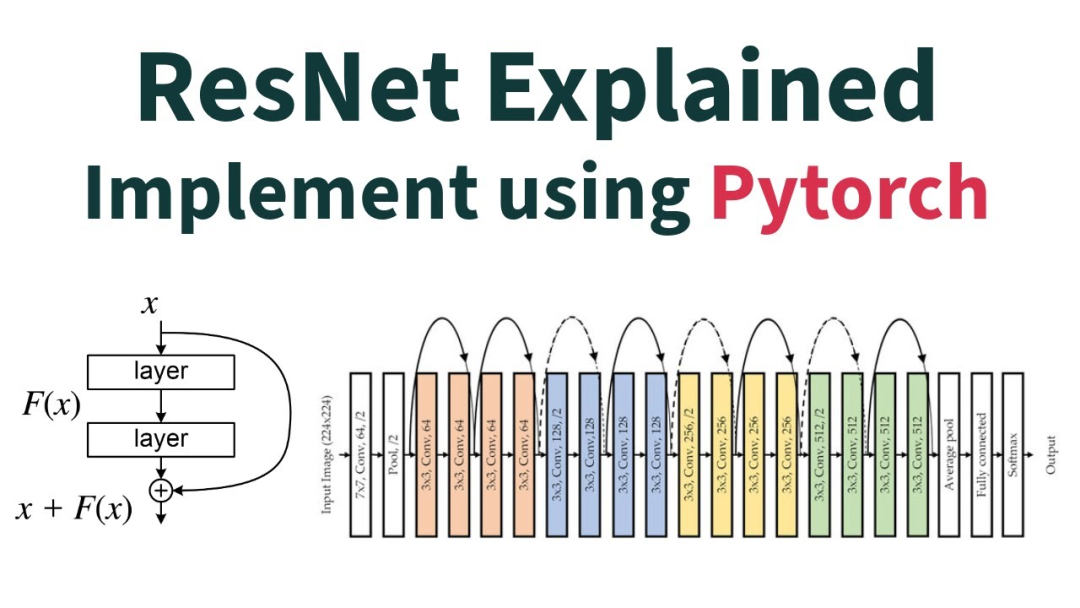
As models grow deeper, the cost of this "egalitarian" approach keeps rising: important early information gets diluted by later noise, differences in importance between layers get masked, and overall efficiency steadily declines.
Empirical research has even found that in many large models, a substantial portion of layers can be removed with barely any impact on performance — in other words, the model isn't effectively using its full depth.
The paper Attention Residuals (AttnRes), released by the Moonshot AI team, targets this exact problem.
Their core insight is intuitive: since Attention has already proven in the sequence dimension that "letting the model choose where to look" beats fixed rules, could the same logic apply to the depth dimension — letting each layer choose "who to listen to"?
The specific approach: each layer has a learnable query vector, which it uses to perform attention over all previous layers' outputs, producing a weighted combination as its own input. Prior layers more important to the current computation get higher weights; less important ones get automatically downweighted.
Returning to our analogy: now the student has an intelligent review system — before solving each problem, the system automatically picks out the most relevant notes from those 40 classes based on the problem content, instead of making you flip through everything.
On the engineering side, to prevent computational costs from spiraling out of control in deep models, the paper proposes a practical variant called Block AttnRes: consecutive layers are grouped into blocks, with ordinary residual connections inside each block, and attention applied only between blocks. Testing shows roughly 8 blocks can recover most of the gains, with inference latency increasing by less than 2% — essentially free.
The results are solid.
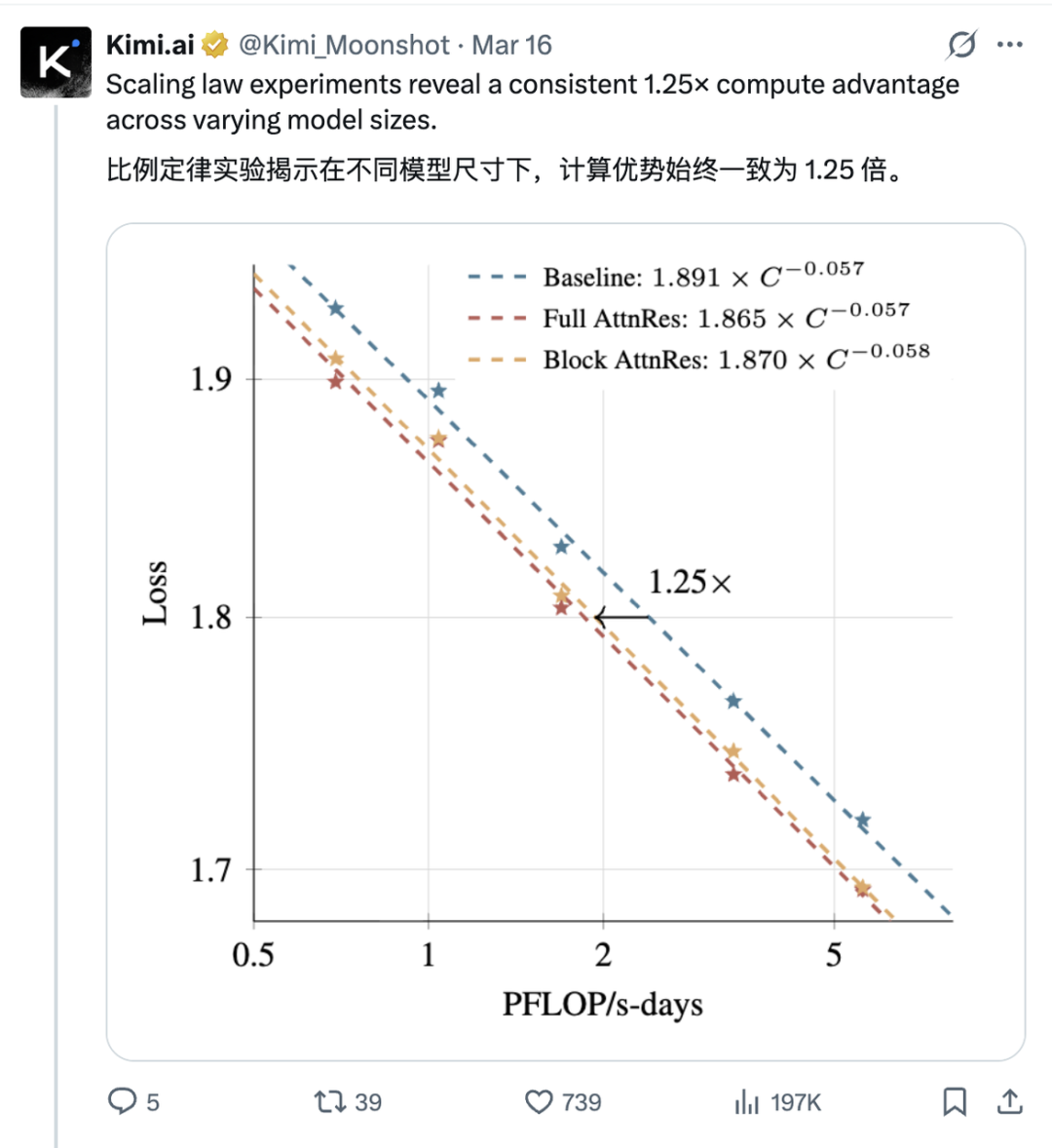
In scaling law experiments, Block AttnRes performs equivalently to giving the baseline model 25% more training compute. Conversely, the training budget needed to reach equivalent performance drops by about 20%. For model companies locked in an intense arms race, this is a tangible cost advantage.
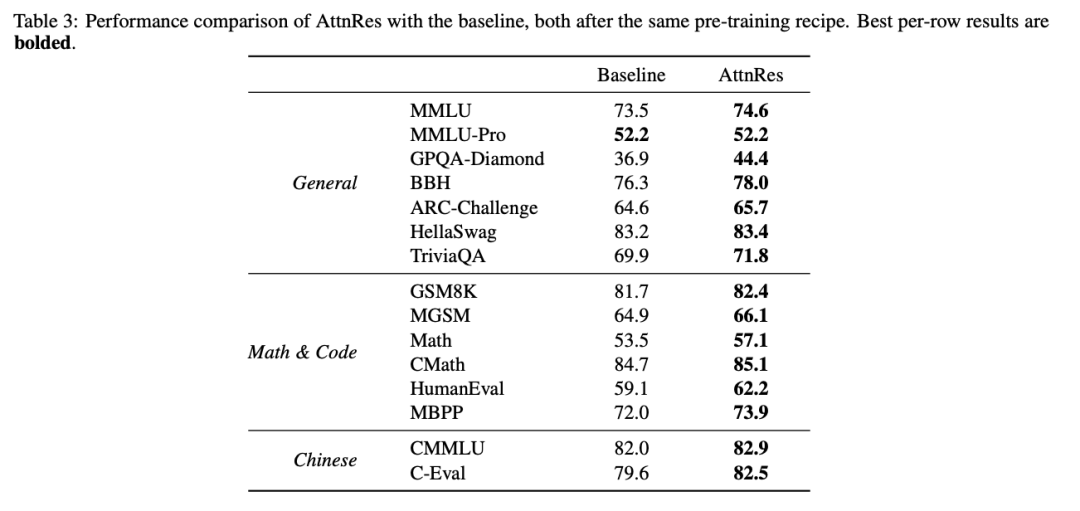
On a 48B-parameter MoE model, AttnRes achieves consistent improvements across nearly all downstream tasks — GPQA-Diamond (scientific reasoning) up 7.5 points, Math up 3.6 points, HumanEval (code) up 3.1 points. Meanwhile, the model's gradient distribution and hidden state magnitudes become more uniform, with significantly improved training dynamics — not just better results, but a healthier process.
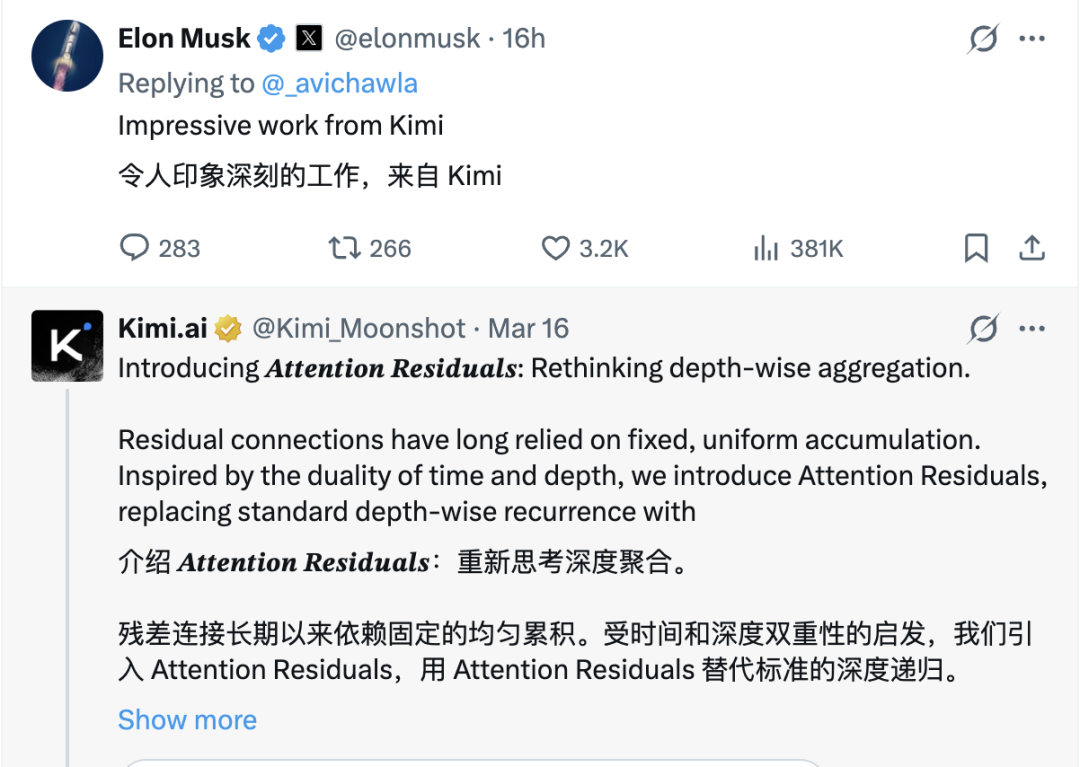
The paper quickly drew attention after release. Elon Musk commented directly on X: "Impressive work from Kimi." Andrej Karpathy's response was more intriguing — he half-jokingly asked whether we hadn't fully understood the phrase "Attention is All You Need." Jerry Tworek, former VP of Research at OpenAI and widely credited as "the father of the o1/o3 reasoning model series," went further, calling it "deep learning 2.0 is approaching."

Ilya Sutskever once said that LSTM is just ResNet rotated 90 degrees. AttnRes proves that Attention can also be rotated 90 degrees — from the sequence dimension to the depth dimension.
What does AttnRes tell us? In the short term, it's a training efficiency optimization: better models for the same compute, or the same performance for less money — a visible, practical cost advantage.
In the long term, it points to a larger possibility: if the depth dimension becomes learnable and dynamic, future large models may no longer be fixed-depth feedforward networks, but instead dynamically dispatch computational resources across different layers at runtime — simple problems solved with shallow layers, complex problems only then engaging the full depth.
Looking back over the past decade, the biggest paradigm shifts in AI — from fixed features to learned features (deep learning), from fixed sequence processing to dynamic sequence processing (Attention), from fixed reasoning to dynamic reasoning (Chain-of-Thought) — have all fundamentally been about taking something "fixed" and making it "learnable." AttnRes continues this same thread.
Of course, the paper was only recently released and hasn't yet undergone large-scale replication and validation. There's a long road from architectural innovation on paper to industrial deployment.
Still, it's worth noting that AttnRes's emergence confirms a principle Moonshot AI has long emphasized: technical breakthroughs come from talent density and retention. It also demonstrates a structural technical sensibility — the willingness to question foundational assumptions that have stood untouched for a decade, and to provide a clean answer. Only the combination of talent density, team cohesion, and technical taste can explain why this team produced this work.
We look forward to the next "rotation."


