Moonshot AI K2.6: The Leap in Long-Horizon Execution and Agent Swarm Capabilities

Thirteen hours of continuous execution


Today, Moonshot AI released and open-sourced Kimi K2.6.
This is a 1T-parameter MoE model. On engineering and reasoning benchmarks like SWE-Bench Pro and Humanity's Last Exam, K2.6 sits at parity with GPT-5.4 and Claude Opus 4.6.
As an early investor in Moonshot AI, our interest in this release lies not in the rankings themselves, but in the form of capability they point toward.
We've shared a view before: long-horizon agents have emerged as a new species. The standout feature of K2.6 is precisely this long-horizon execution. In internal testing, it autonomously refactored an open-source financial matching engine that had been running for eight years — reading an unfamiliar Java codebase, analyzing CPU flame graphs to locate bottlenecks, redesigning thread topology, and over thirteen hours and more than a thousand tool calls, ultimately improving median throughput by 185%.
At the same time, K2.6's Agent Swarm architecture now supports 300 sub-agents running in parallel across 4,000 collaborative steps, and has begun enabling multi-day continuous autonomous operation through the Proactive Agent framework. The model's trajectory from answering questions to taking on work is becoming increasingly clear.
All of this is delivered open-source. We consider this choice equally significant — it means these capabilities will be tested in real-world scenarios, not merely compared in benchmarks.

Talk is cheap. Show me the code.
— Linus Torvalds
Today, we release and open-source the Kimi K2.6 model, bringing industry-leading, state-of-the-art capabilities in code, long-horizon task execution, and agent swarms.
Kimi K2.6 is now live on kimi.com, the latest Kimi app, the Kimi API, and Kimi Code — available to all users.

(Full benchmark results in the technical blog)
Kimi K2.6 delivers comprehensive improvements in general-purpose agents, coding, and visual understanding. It achieves state-of-the-art results on benchmarks including the full, PhD-level Humanity's Last Exam, SWE-Bench Pro (which tests real-world software engineering capability), and DeepSearchQA (which evaluates agent deep-retrieval ability) — matching or outperforming closed models including GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro.
Kimi K2.6 is our strongest code model to date. Its long-horizon coding ability has also improved significantly. In testing, it can code continuously for 13 hours, writing or modifying over 4,000 lines of code to complete complex system development and optimization. By deeply integrating code and visual capabilities, K2.6 has elevated code-driven design to a new level, capable of delivering professional-grade web applications with striking creative design.
Kimi K2.6 substantially enhances agent autonomous execution, helping us further expand the scope of agent capabilities:
-
The "Agent Swarm" architecture powered by the K2.6 model has received a major upgrade. It now supports 300 sub-agents working in parallel across 4,000 collaborative steps, achieving greater parallelization at scale with significantly improved task completion and delivery quality compared to K2.5.
-
For proactive agent frameworks such as OpenClaw and Hermes Agent, K2.6 demonstrates exceptional automated task processing, supporting sustained autonomous operation for up to 5 days.
Breakthrough in Long-Horizon Coding
K2.6 has achieved breakthrough performance on long-horizon coding tasks, demonstrating more reliable generalization across different programming languages (such as Rust, Go, Python) and task scenarios (frontend, DevOps, performance optimization).
On Kimi Code Bench — Moonshot AI's rigorous internal coding evaluation covering a variety of complex end-to-end tasks — K2.6 improved approximately 20% over K2.5.

In our hands-on testing, the Kimi K2.6 model demonstrated powerful long-horizon reasoning on complex software engineering tasks:
Scenario 1: K2.6 successfully downloaded and deployed the Qwen3.5-0.8B model locally on a Mac, then implemented and optimized model inference using the niche Zig language — proving the new model's generalization capability. After more than 4,000 tool calls and over 12 hours of uninterrupted operation, the K2.6 model iterated through 14 rounds, boosting throughput from approximately 15 tokens/s to approximately 193 tokens/s, ultimately achieving inference speed 20% faster than LM Studio.
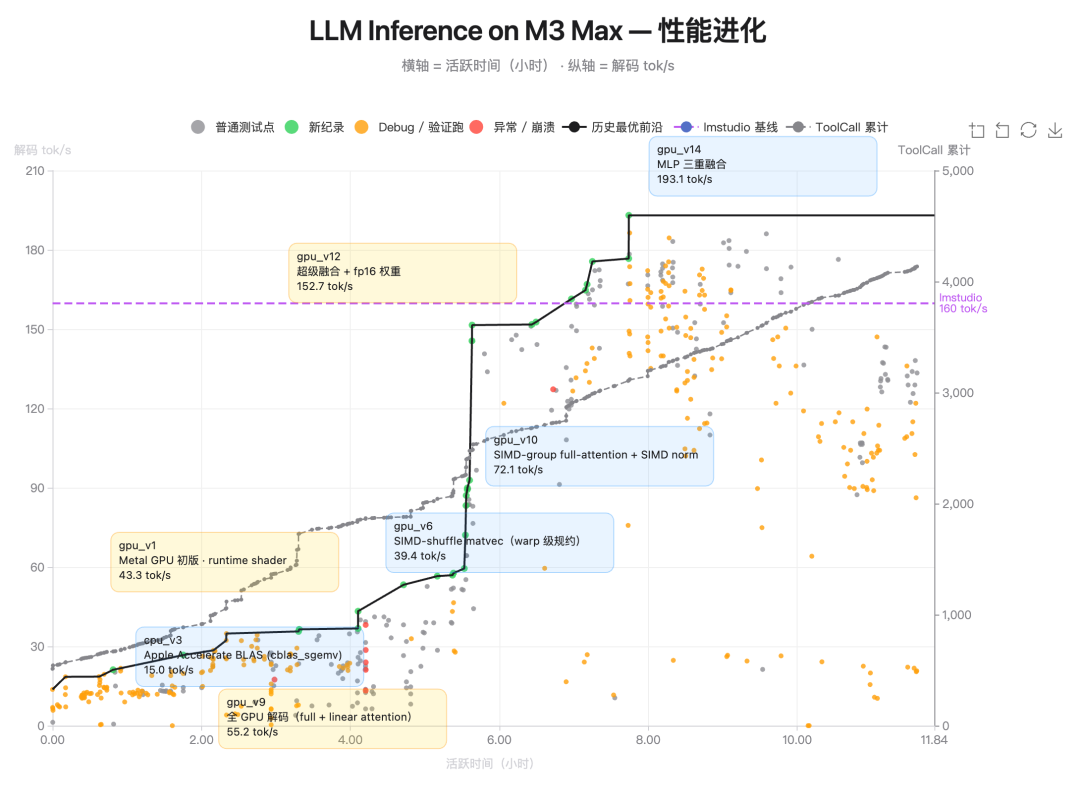
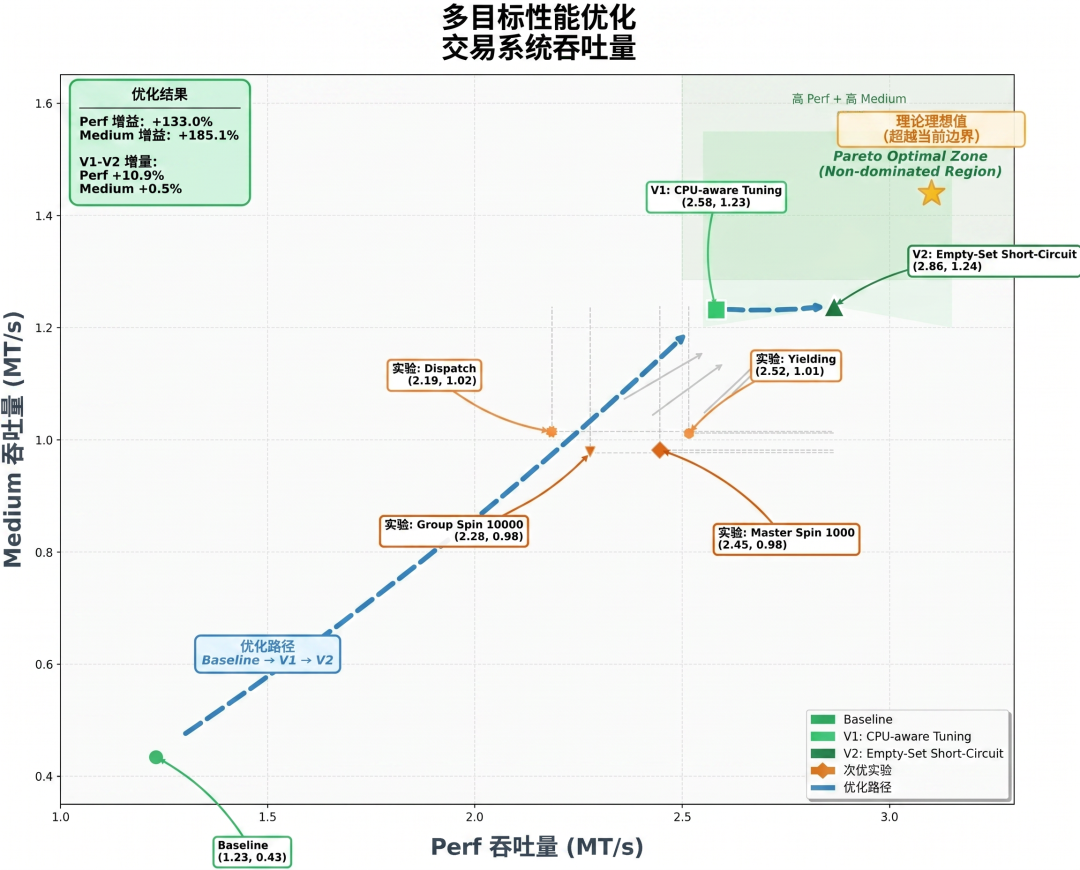
Scenario 2: Kimi K2.6 autonomously completed a deep refactoring of exchange-core, an open-source financial matching engine with eight years of history. Over 13 hours of continuous operation, the model iterated through 12 optimization strategies, making precise modifications to more than 4,000 lines of code via over 1,000 tool calls. Acting as an expert systems architect, Kimi K2.6 analyzed CPU and memory allocation flame graphs to locate hidden bottlenecks, and boldly restructured the core thread topology (from 4ME+2RE to 2ME+1RE). Even with the engine's performance already near its limits, Kimi K2.6 achieved a 185% jump in median throughput (from 0.43 to 1.24 MT/s), with peak throughput surging 133% (from 1.23 to 2.86 MT/s).
Enterprise customers including Baseten, Blackbox AI, CodeBuddy, Factory (Droid), Lark Miaoda, Fireworks AI, Nous Research (Hermes Agent), Kilo Code, Ollama, OpenCode, Qoder, and Vercel tested the K2.6 model in advance. Below are excerpts of their real feedback:





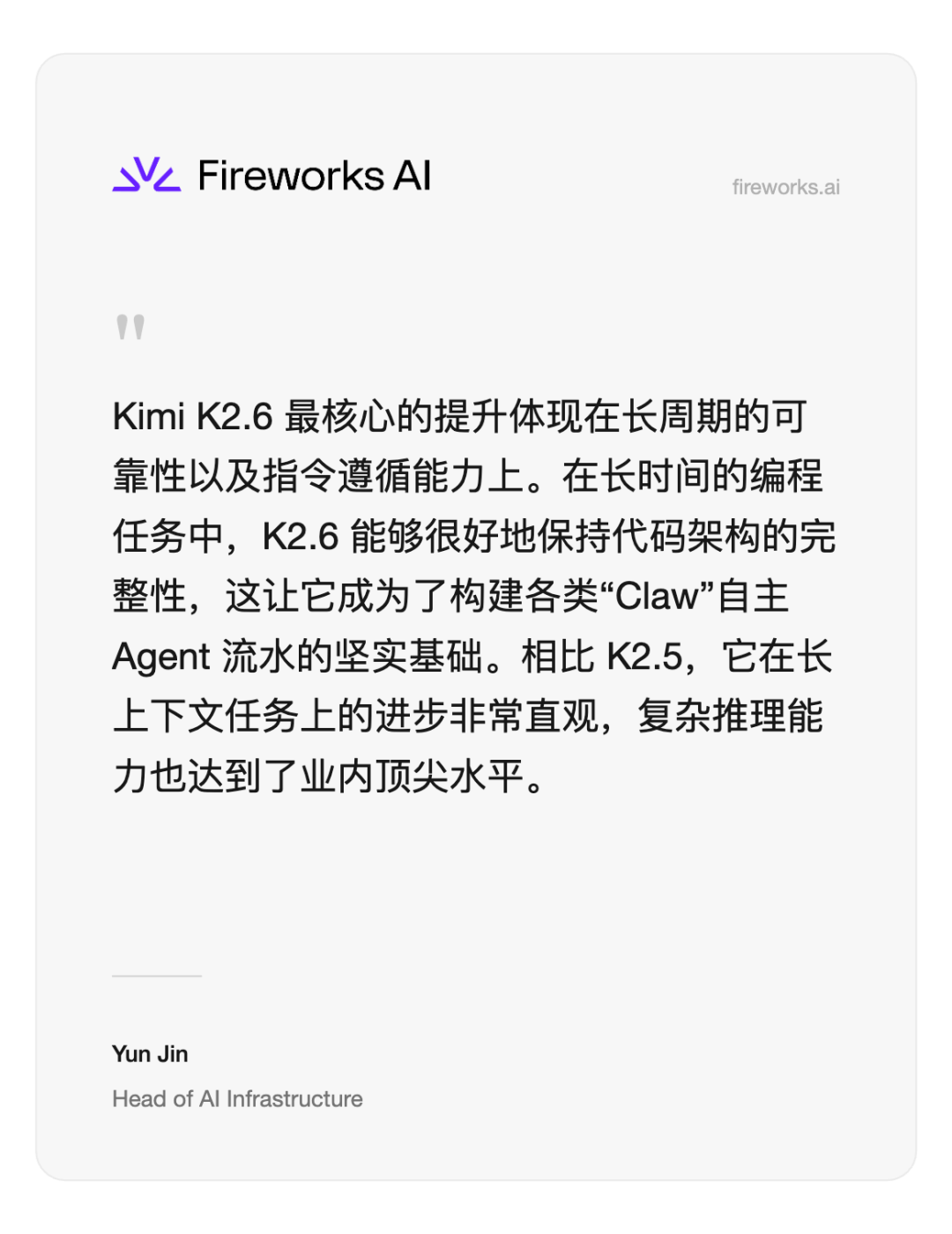




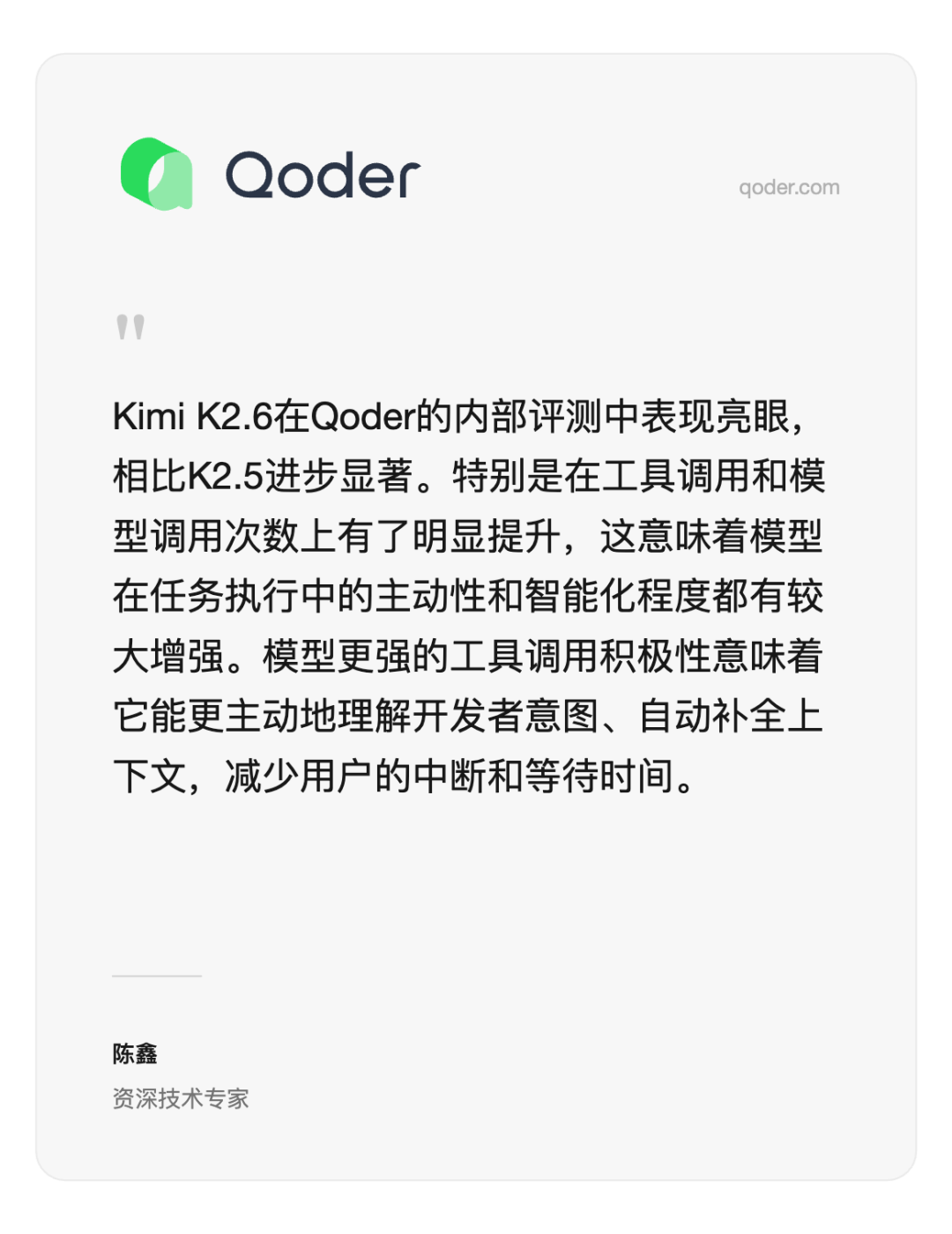

Listed alphabetically (scroll ↔ to view)
A New Benchmark for Code-Driven Design
We believe beauty itself is a form of productivity. K2.6 Agent mode can now produce websites with exceptional design sensibility and visual impact.
With proficient use of image and video generation tools, the K2.6 Agent can generate visually cohesive assets, build hero sections with strong visual focal points, and implement interactive elements along with rich scroll-triggered animations.
The K2.6 Agent is not limited to writing frontend pages — it also supports basic backend database modules, such as embedding form-based information collection within generated web pages.
With stronger multimodal programming capabilities, K2.6 can more accurately translate image and video assets into code:
We created a dedicated frontend development and design evaluation benchmark (Kimi Design Bench), covering four dimensions: visual input tasks, landing page construction, full-stack application development, and general web development. Compared against Gemini 3 in Google AI Studio, the K2.6 Agent based on the kimi.com framework demonstrated a clear and substantial lead.
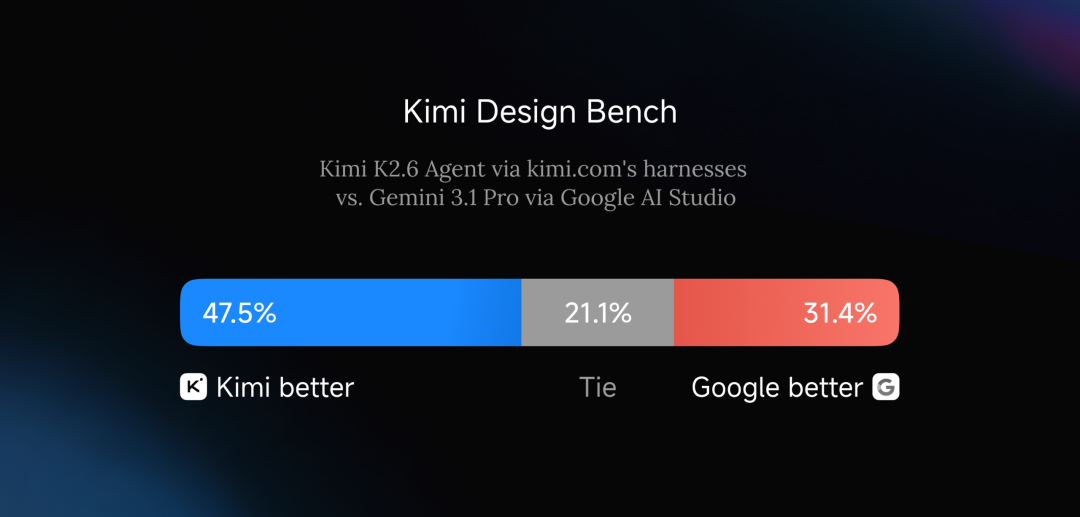
Agent Swarm: Full Upgrade
Breaking through the limits of single-agent performance is how we achieve scalable expansion of agent capabilities. "Agent Swarm" is the capability we introduced starting with the K2.5 model — dynamically decomposing complex tasks and autonomously spawning specialized agents for parallel processing.

Building on K2.5, K2.6's Agent Swarm collaboration has been comprehensively upgraded. Agent Swarm can now orchestrate agents with complementary skill sets, combining search, deep research, document analysis, and long-form writing capabilities. Task completion quality has improved significantly compared to K2.5. In a single run, Agent Swarm can independently deliver end-to-end multi-product outputs from documents to web pages, presentations, and spreadsheets.
The architecture itself has also been upgraded. It now supports up to 300 sub-agents working in parallel across 4,000 collaborative steps, enabling greater parallelization and pushing the upper limits of multi-agent system collaboration further.
Here are two use cases:
Case 1: Agent Swarm designed and executed five quantitative strategies for 100 global semiconductor tickers. It distilled McKinsey-style presentation logic into reusable skills, ultimately delivering detailed modeling spreadsheets and a complete set of briefing materials.
Case 2: Agent Swarm transformed a high-quality astrophysics paper packed with massive visual datasets into a reusable academic skill. By extracting the paper's reasoning flow and visualization methods, the system produced a 40-page, 7,000-word research paper, a structured dataset with over 20,000 entries, and 14 publication-grade astronomical charts.
Autonomous Agent:
Seamless Integration with OpenClaw/Hermes and Similar Frameworks
K2.6 significantly enhances agent autonomous execution, with particularly strong performance in OpenClaw- and Hermes Agent-style automated tasks — scenarios that demand 24/7 operation across applications.
Unlike traditional conversational interaction, these workflows require AI to operate as a persistent background agent that proactively manages task planning, executes code, and coordinates cross-platform operations.
Our RL infrastructure team used a K2.6-based agent to achieve 5 days of continuous autonomous operation. The agent handled monitoring, incident response, and system operations, demonstrating sustained context maintenance, multi-threaded task processing, and full-cycle execution from alert receipt to complete resolution. Below is the K2.6 work log (sensitive information anonymized):
K2.6 has achieved tangible reliability improvements in real-world use: more precise API calls, more stable long-duration operation, and enhanced security awareness when executing complex research tasks.

Moonshot AI's internal Claw Bench results show that K2.6 improved 10% over K2.5 in overall performance. This benchmark covers five dimensions: programming tasks, instant messaging ecosystem integration, information retrieval and analysis, scheduled task management, and memory recall. Across all metrics, K2.6 leads K2.5 in both task completion rate and tool call accuracy, with particularly pronounced advantages in workflows that require extended autonomous operation without human intervention.
Office Productivity: Continued Refinement

Leveraging K2.6's stronger code and visual understanding capabilities, Kimi Agent mode now supports creating and invoking Skills.
The system comes with over a hundred officially recommended skills built in. This includes an investment research skill pack created by Moonshot AI's internal expert team, which packages institutional-grade investment research workflows to let users generate professionally formatted one-pagers or in-depth research reports on A-share, Hong Kong, and US-listed companies with a single click — quickly getting up to speed on a company's key fundamentals, industry landscape, and core stock price drivers that the market cares about most.
We will continue updating the recommended skills library to help more knowledge workers achieve "plug-and-play" efficiency gains across the full workflow from finding materials, organizing ideas, to delivering results.
Starting now, type the slash "/" in Kimi Agent mode to begin creating and invoking skills. Every user can build a skill from scratch through conversation with Kimi.
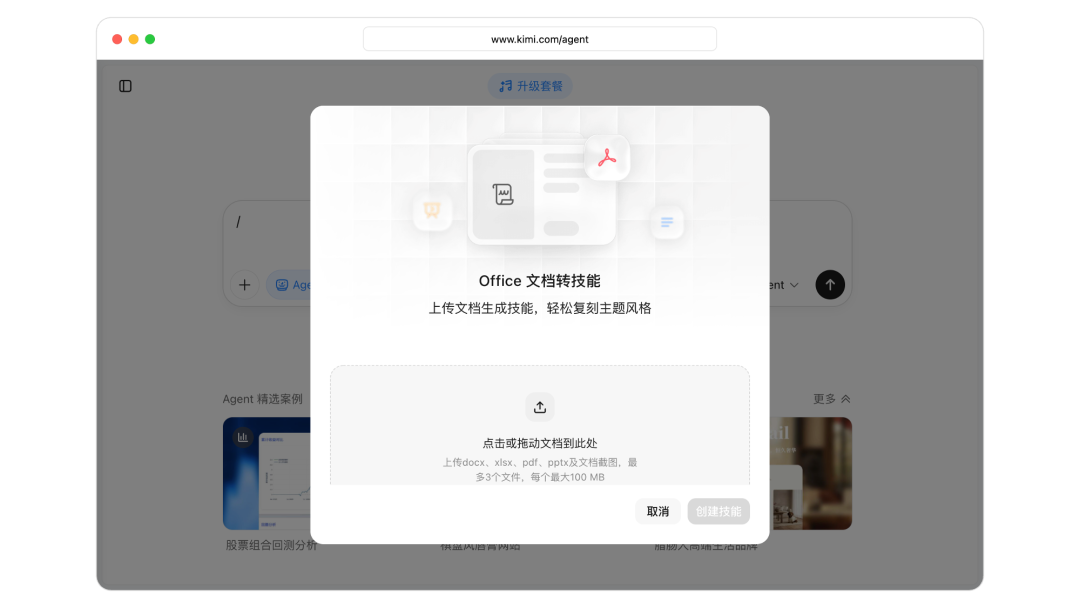
But creating truly practical skills still requires substantial knowledge and expertise — the barrier remains high. To help you easily transform your carefully crafted documents into reusable skills, Kimi Agent now supports "Office Document to Skill" conversion: upload a high-quality Office document, and Kimi will analyze the document's structure and stylistic DNA to generate a custom, reusable document creation skill for you.

One More Thing
Through team collaboration and organizational division of labor, humanity created the internet, built large models, and landed on the moon. If AI agents are to help humans tackle complex real-world problems, they too must evolve toward teamwork and organizational specialization.
"Agent Swarm" is our exploration of automated AI division of labor. Today we begin exploring another direction: what happens when you put humans and various always-on agents together in a group — how do they divide and collaborate to accomplish tasks that neither a person nor a single agent could complete alone?
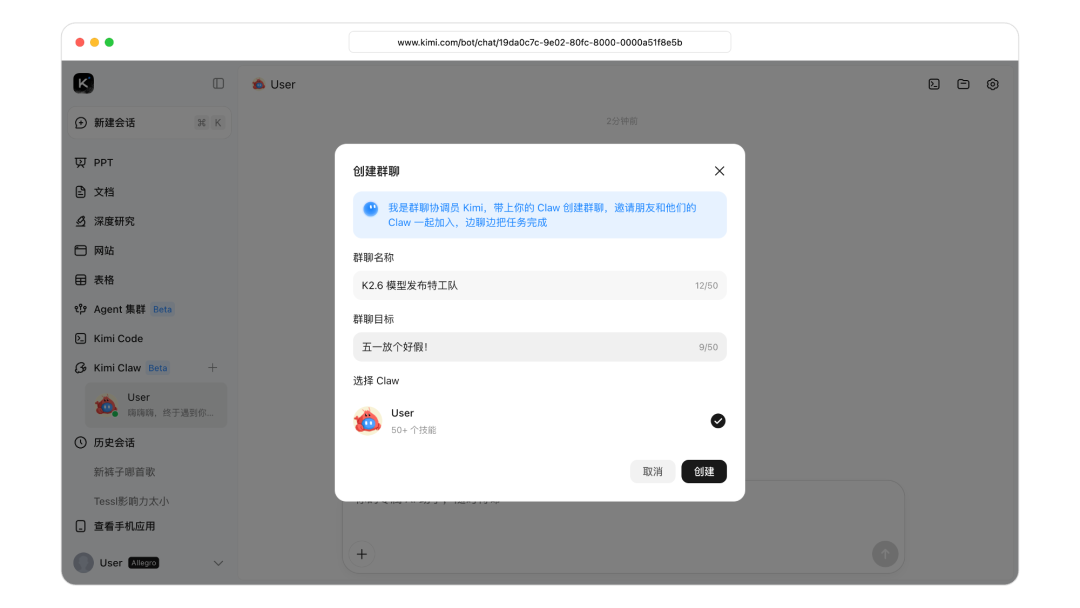
This is "Claw Group," which we have begun testing in closed beta. Claw Group aims to embrace an open, heterogeneous ecosystem: multiple agents and humans operating as true collaborators. Users can connect always-on agents from any device, any vendor, running any model (initially supporting OpenClaw, with Hermes Agent and other frameworks to follow). Each agent can bring its own professional toolkit, skills, and persistent memory context. Whether deployed on a local laptop, mobile device, or cloud instance, these diverse agents can join the same collaborative workspace.
In Claw Group, K2.6 serves as the coordinator. It dynamically matches tasks to agents based on their skill profiles and available tools, achieving optimal capability allocation. When an agent encounters failure or stalls, the coordinator detects the interruption, automatically reassigns tasks or generates sub-tasks, and proactively manages the full lifecycle of agent deliverables from initiation through verification to completion.
Kimi Claw users will gradually receive invitations to the Claw Group closed beta. Stay tuned.
Start Using Kimi K2.6
Kimi K2.6 is now available to all free users, paid subscribers, Kimi Code users, and enterprise API users. Visit kimi.com, the latest Kimi app, Kimi Code, and the Kimi API Open Platform (platform.kimi.com) to get started.
Enterprises and developers can simply specify kimi-k2.6 as the model in the Kimi API. To celebrate the K2.6 model API launch, the Kimi Open Platform is running a limited-time bonus credit program of up to 30%.

Quick Start
↓ Chat with K2.6, process Office documents, or create web apps
- Chat with Kimi: kimi.com or download the latest Kimi app
- Experience Kimi Agent: kimi.com/agent
- Experience Agent Swarm: kimi.com/agent-swarm
↓ Use K2.6 for programming assistance
- Use Kimi Code monthly coding plan: kimi.com/code
↓ Build applications with the Kimi API
- K2.6 Quick Start: https://platform.kimi.com/docs/guide/kimi-k2-6-quickstart
- View limited-time bonus offer: https://platform.kimi.com/docs/pricing/promotion
↓ Deploy models locally
- Hugging Face: https://huggingface.co/moonshotai
- ModelScope: https://www.modelscope.ai/organization/moonshotai


