Moonshot AI Kicks Off the "Long-Context Era" for 100-Billion-Parameter Models

A 100-billion-parameter LLM product that supports 200,000-word context windows

On October 9, 2023, Moonshot AI — a large language model startup barely six months old — announced a breakthrough in "long-context" capabilities, launching Kimi Chat, the first AI assistant product supporting inputs of up to 200,000 Chinese characters. This marked the longest context window available in any production-ready large model service globally, establishing Moonshot AI's world-leading position in this critical technology.

Monolith was among the three investment firms participating in Moonshot AI's first funding round, and has consistently backed the team's growth through concrete action. The company name Moonshot AI derives from Pink Floyd's album The Dark Side of the Moon — "月之暗面" (the dark side of the moon) evokes mystery, curiosity, and aspiration, reflecting the founding team's drive to explore unknown frontiers. This resonates with Monolith's own symbolism: the enigmatic black monolith representing cosmic truth and wisdom, and the fearless pursuit of fundamental truths about business and the world. Monolith will continue to double down and steadfastly support Moonshot AI's bold innovation and technical breakthroughs.

From a technical standpoint, parameter count determines how complex a model's "computation" can be, while the amount of text it can receive as input (long-context technology) determines its "memory" capacity. Together, these define a model's practical effectiveness. Supporting longer contexts means larger "memory," enabling deeper and broader applications: market analysis across multiple earnings reports, processing lengthy legal contracts, rapidly distilling key information from multiple articles or webpages, role-playing based on full-length novel settings — all become part of our work and daily lives with the support of ultra-long-context technology.
Compared to existing large model services trained primarily on English, Kimi Chat demonstrates strong multilingual capabilities. It shows particular strength in Chinese, supporting approximately 200,000 characters in practice — 2.5 times Anthropic's Claude-100k (roughly 80,000 characters in testing) and 8 times OpenAI's GPT-4-32k (roughly 25,000 characters in testing). Meanwhile, through innovative network architecture and engineering optimizations, Kimi Chat achieves lossless long-range attention mechanisms at the 100-billion-parameter scale, without relying on performance-degrading shortcuts like sliding windows, downsampling, or smaller auxiliary models.
Moonshot AI's intelligent assistant product Kimi Chat is now open for beta testing. Visit moonshot.cn to join the beta program.

The Application Bottleneck of Limited Context Windows
The generally short input lengths of current large models severely constrain their real-world deployment:
-
In the popular virtual character use case, inadequate long-context capabilities cause characters to easily forget important information. For instance, users in Character AI's community frequently complain that "because the character forgets its identity after multiple rounds of dialogue, I have to start a new conversation."
-
For developers building on large models, prompt length limits restrict application scenarios and capability expression. When developing murder-mystery-style games, for example, developers often need to feed tens of thousands or even over 100,000 characters of plot setup and game rules as prompts. If the model's input length is insufficient, rules and settings must be cut back, making it impossible to achieve the intended game experience.
-
In another major application direction — AI agents — autonomous multi-step planning and decision-making requires referencing historical memory information at each action step. This rapidly increases model input, meaning models unable to process longer contexts will fail to plan and decide comprehensively and accurately based on history, reducing agent success rates.
-
Nearly every power user has encountered input length limits when using large models as work assistants. This happens especially frequently for professionals like lawyers, analysts, and consultants who regularly need to analyze and process lengthy documents.
All these problems dissolve once large models gain sufficiently long context inputs.
Long Context Opens a New World of Large Model Applications
What can large models with ultra-long context inputs actually do? Here are some real-world examples of Kimi Chat in action —
Feed a long WeChat article directly into Kimi Chat for rapid summarization and analysis:

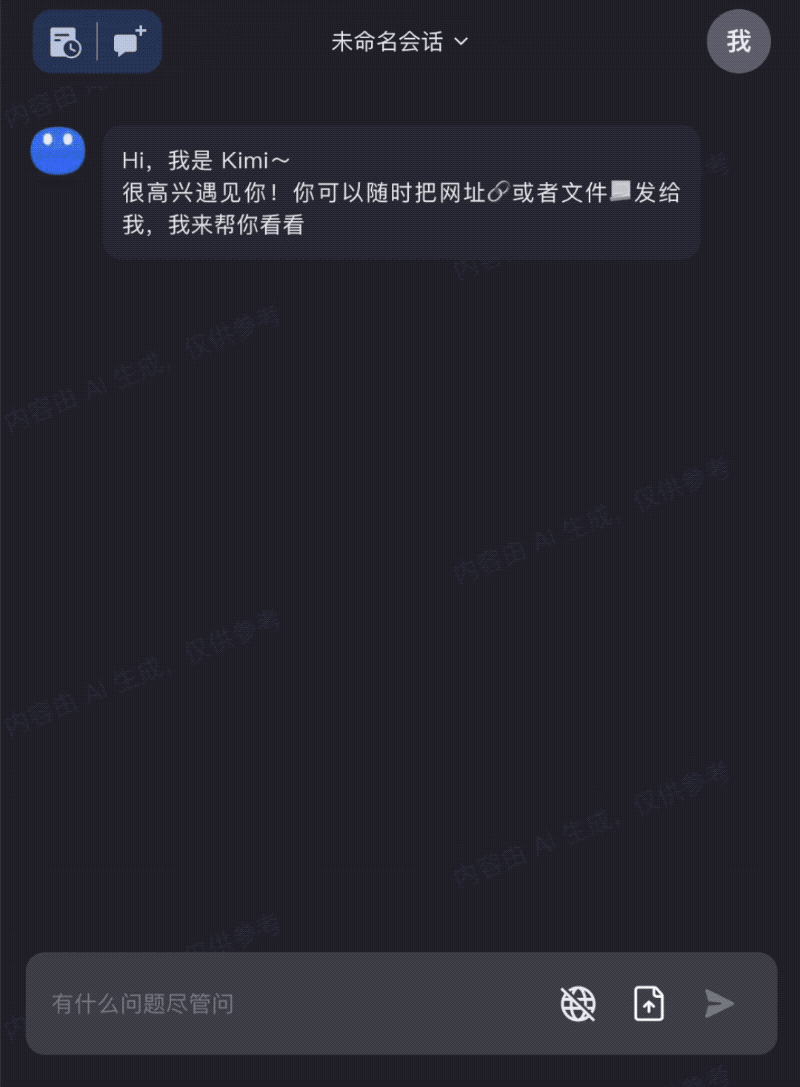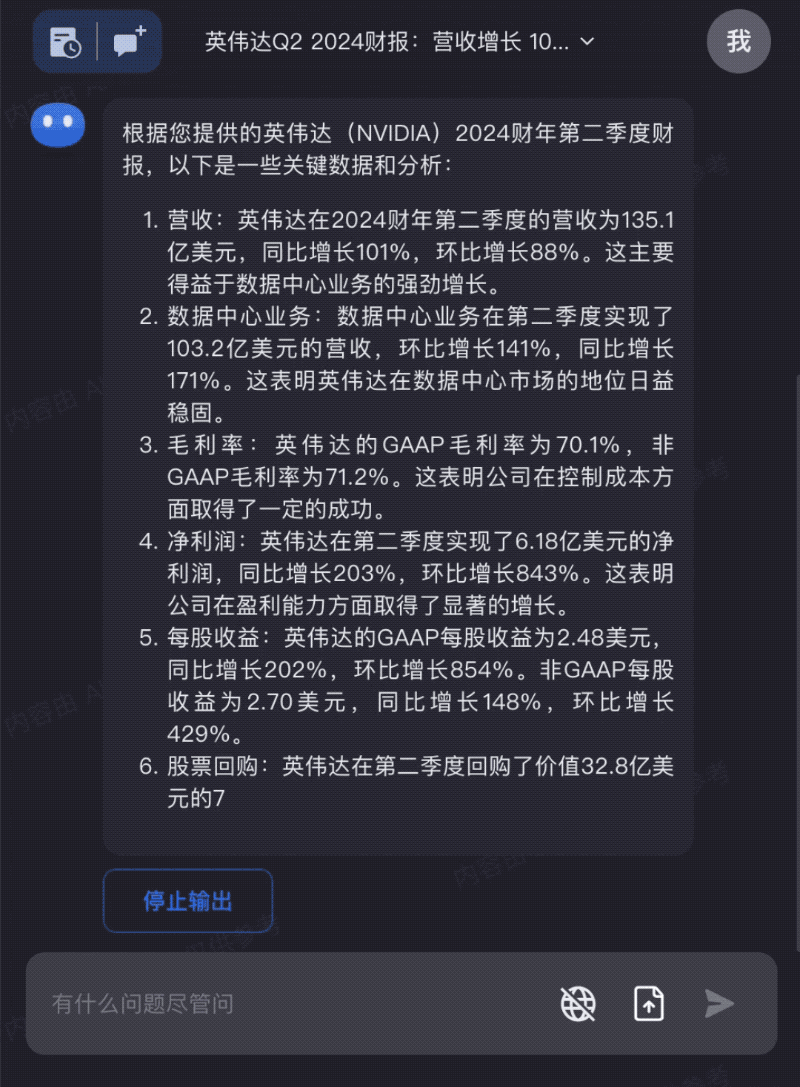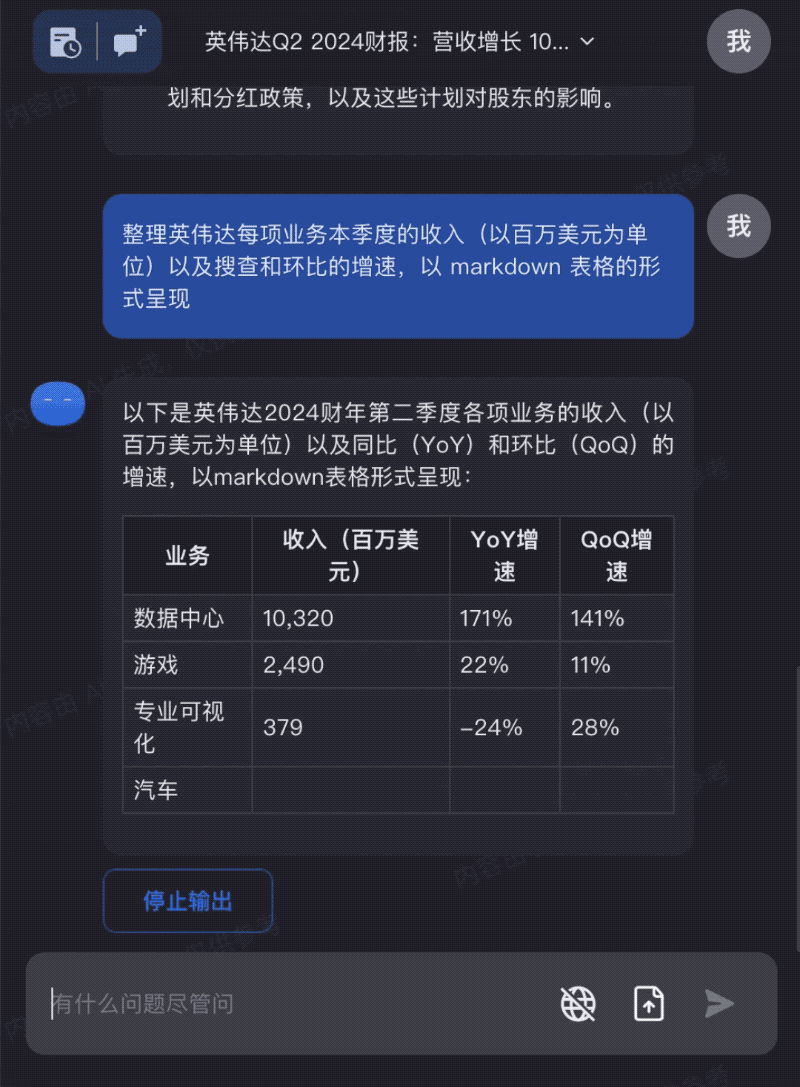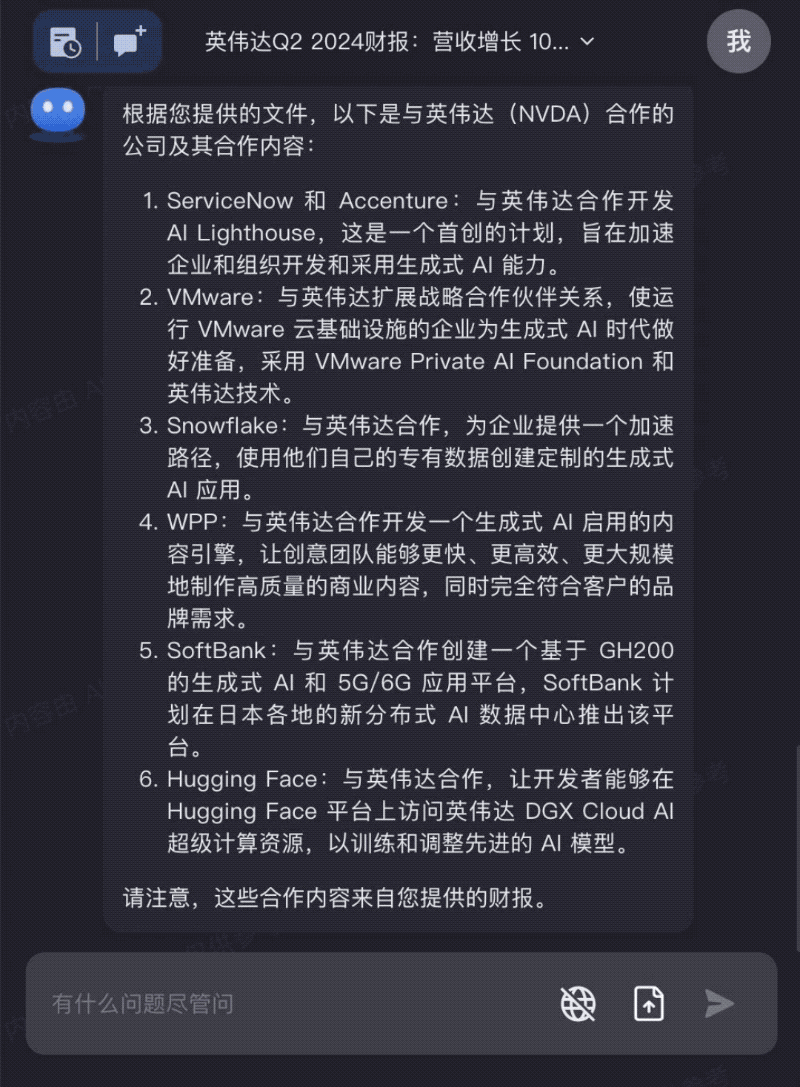
Hand fresh NVIDIA earnings reports to Kimi Chat for quick extraction of key insights:
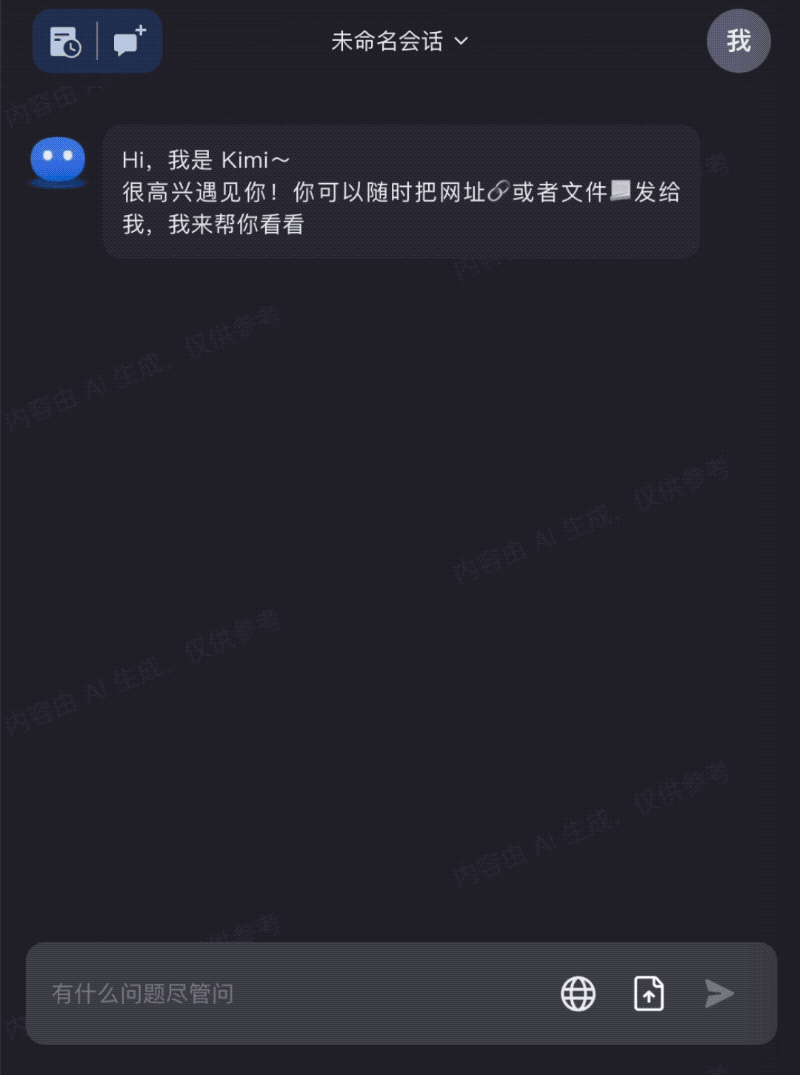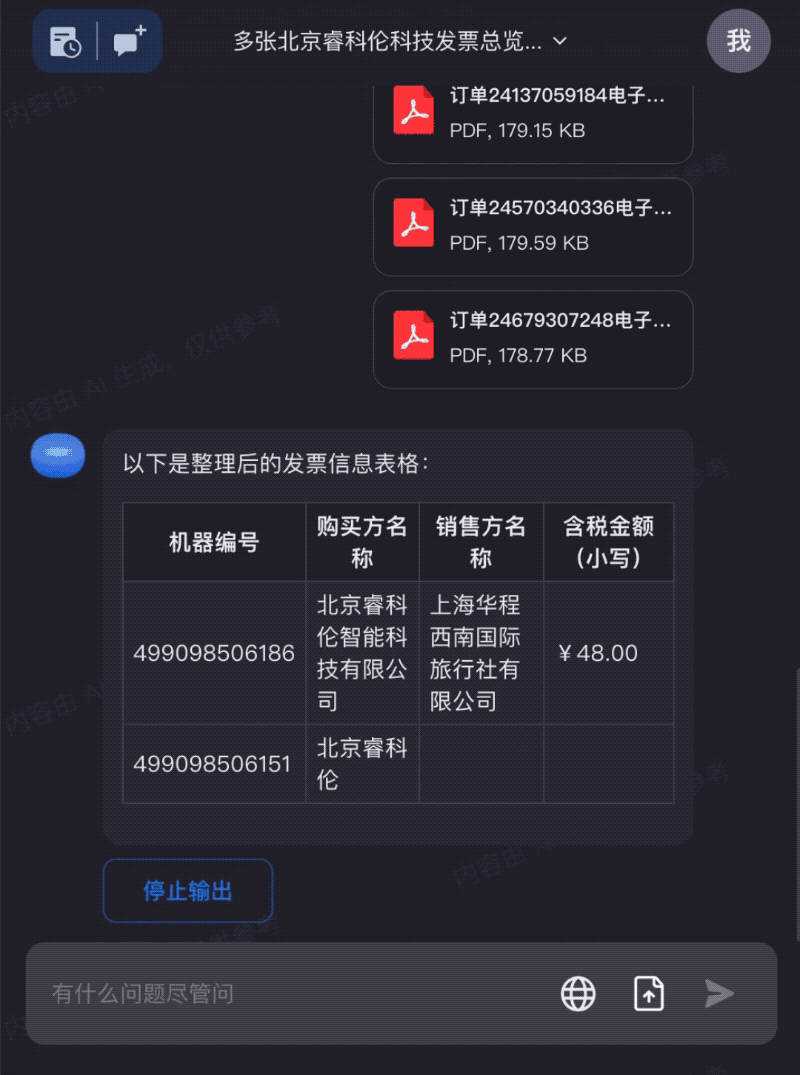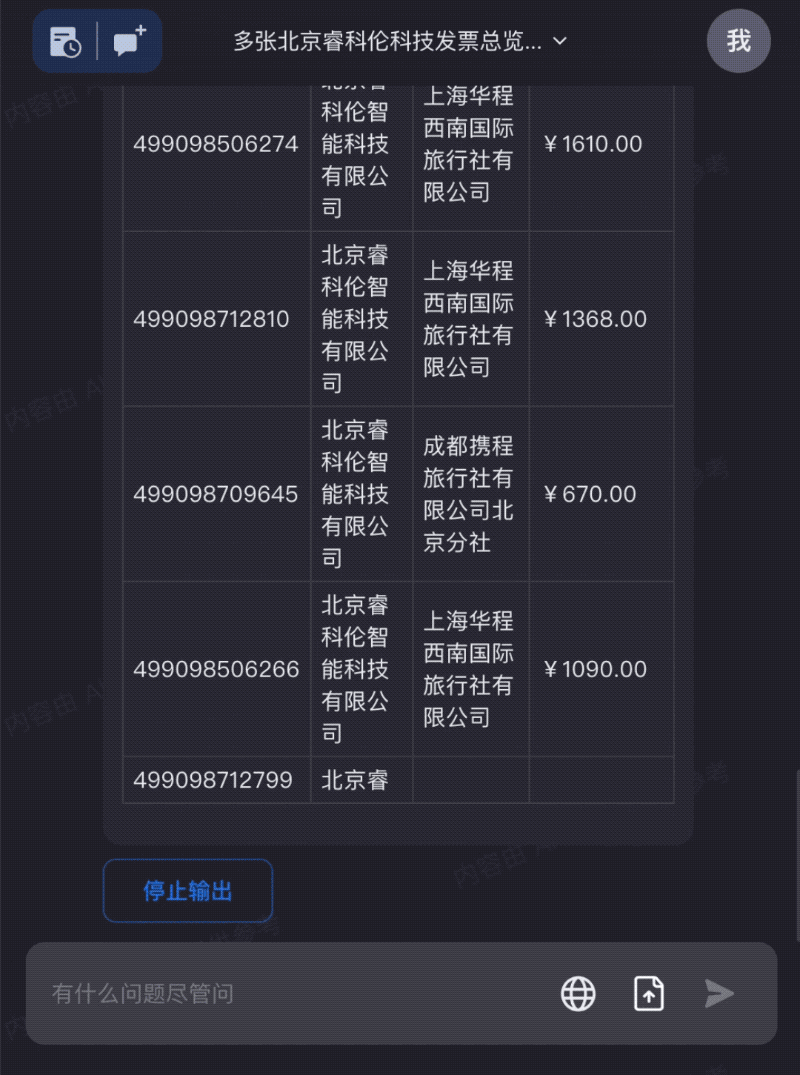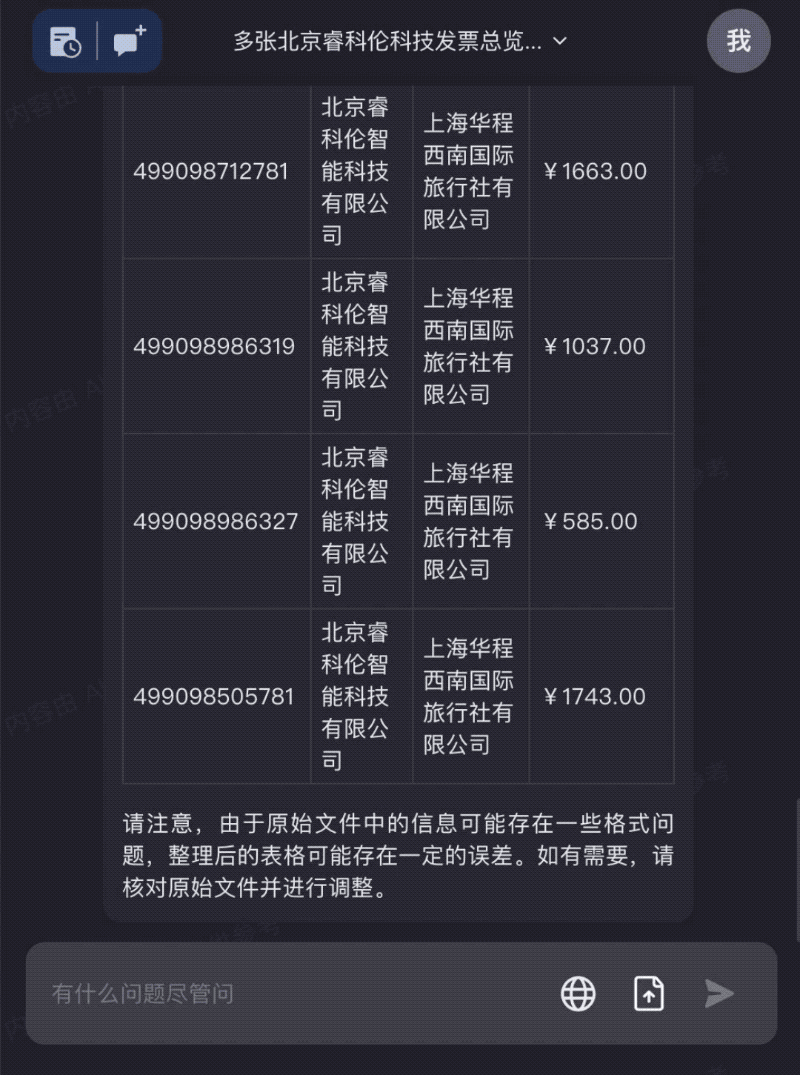
Too many travel expense receipts? Drag them all into Kimi Chat to quickly organize the information you need:
When you discover a new algorithm paper, Kimi Chat can directly help you reproduce the code based on the paper:

With just a URL, chat with your favorite Genshin Impact character in Kimi Chat:
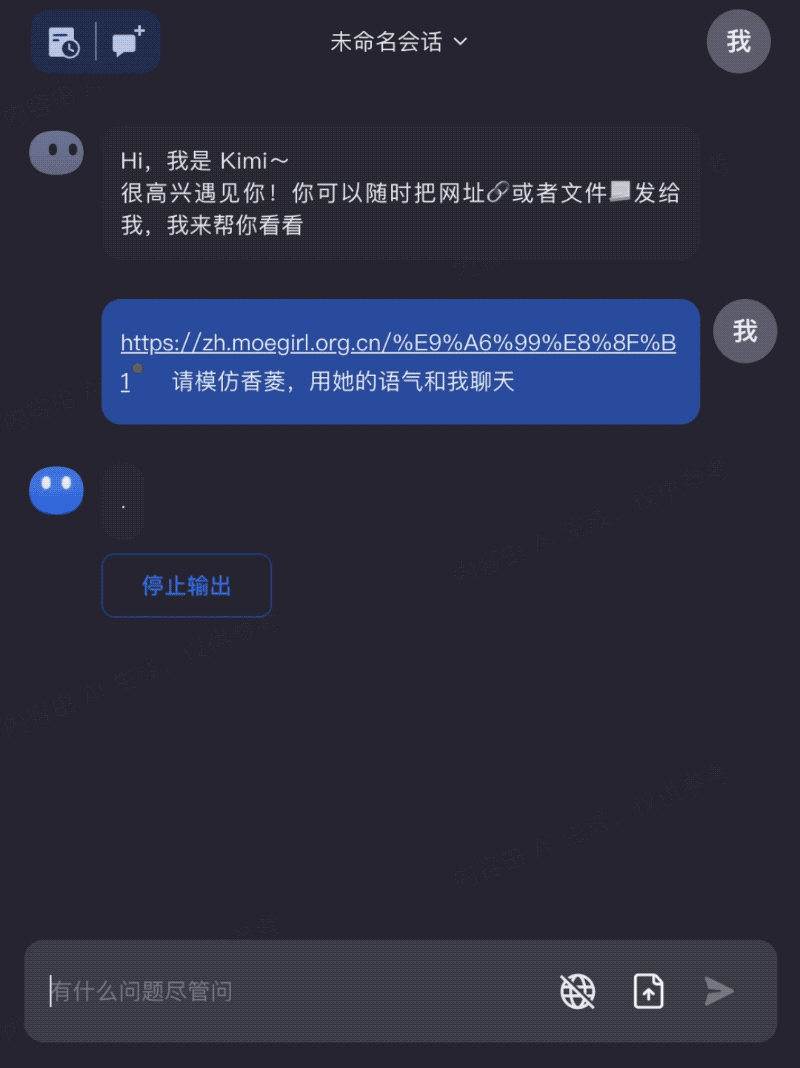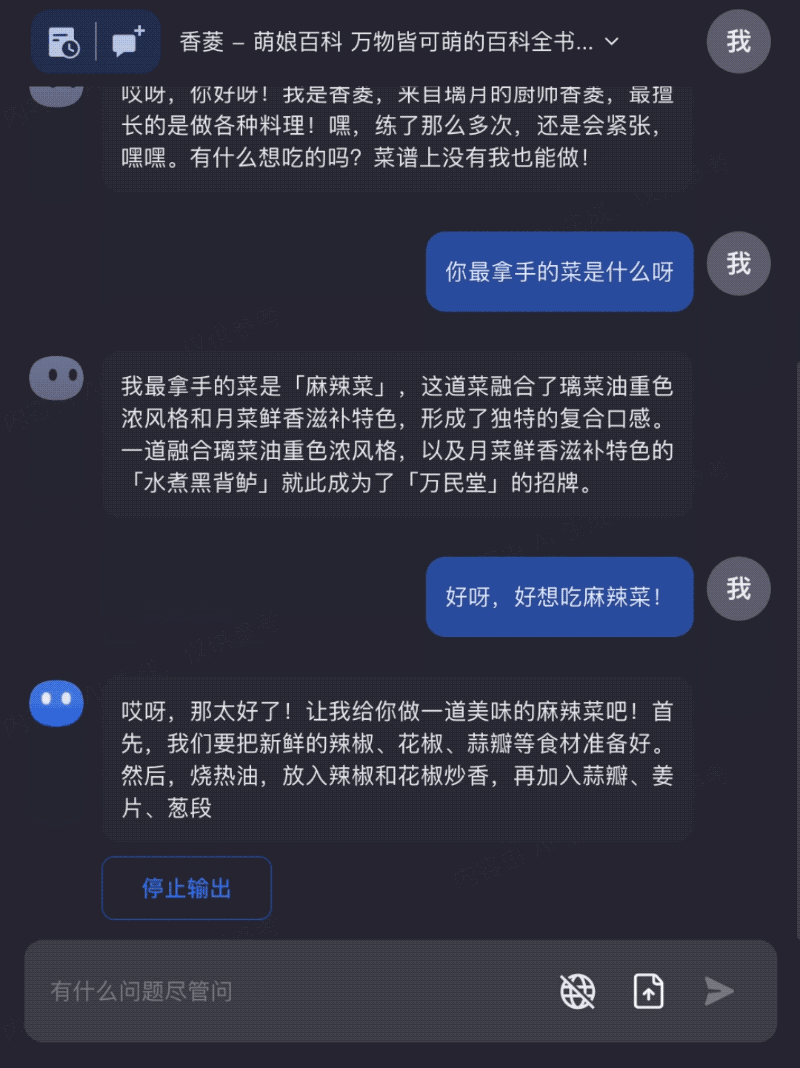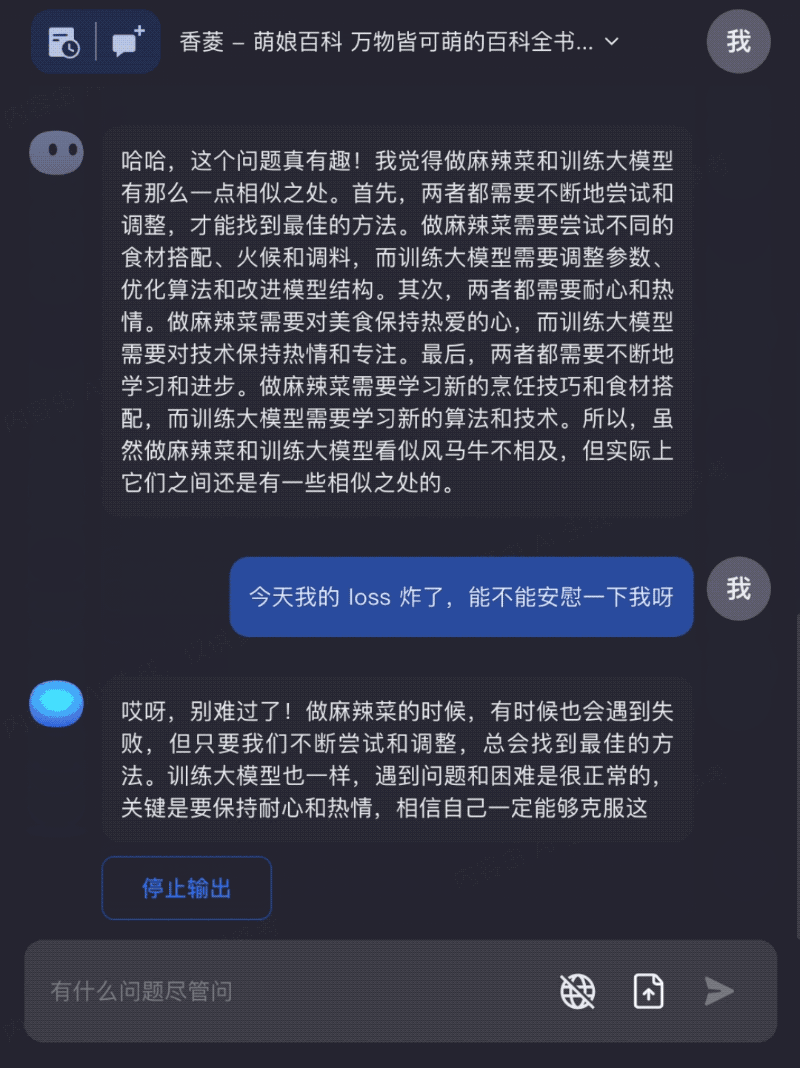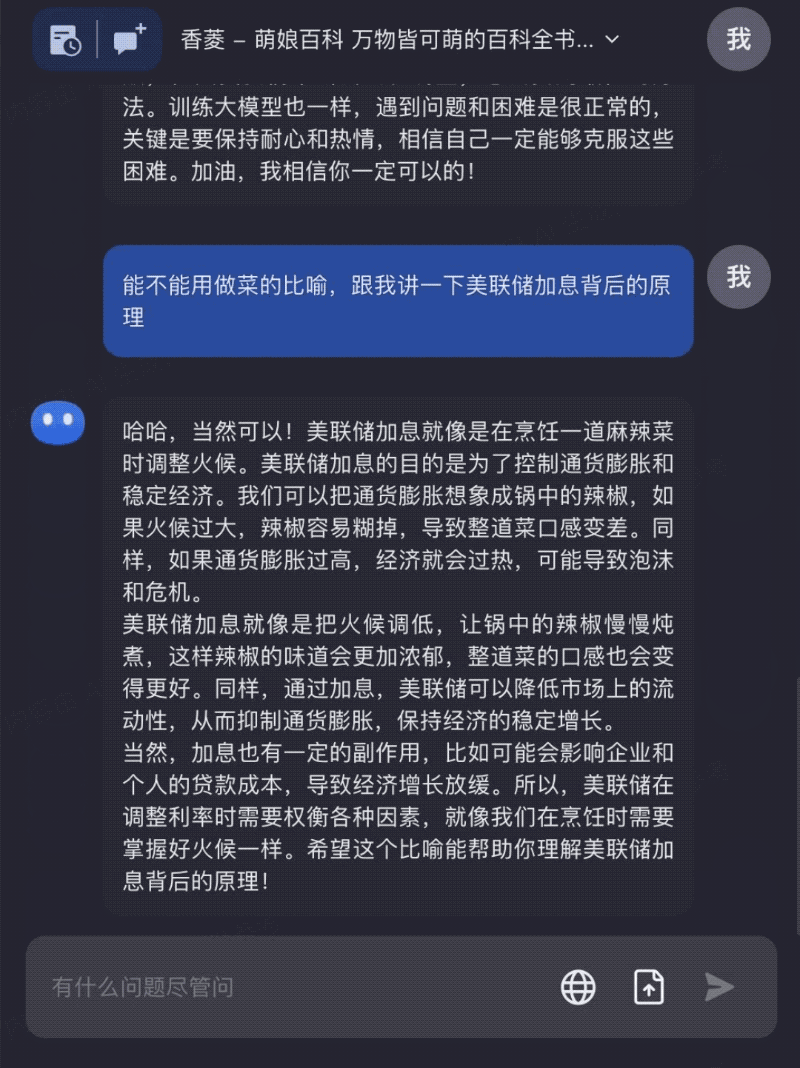
Input the entire The Moon and Sixpence to read together with Kimi Chat, helping you better understand and apply the book's knowledge:
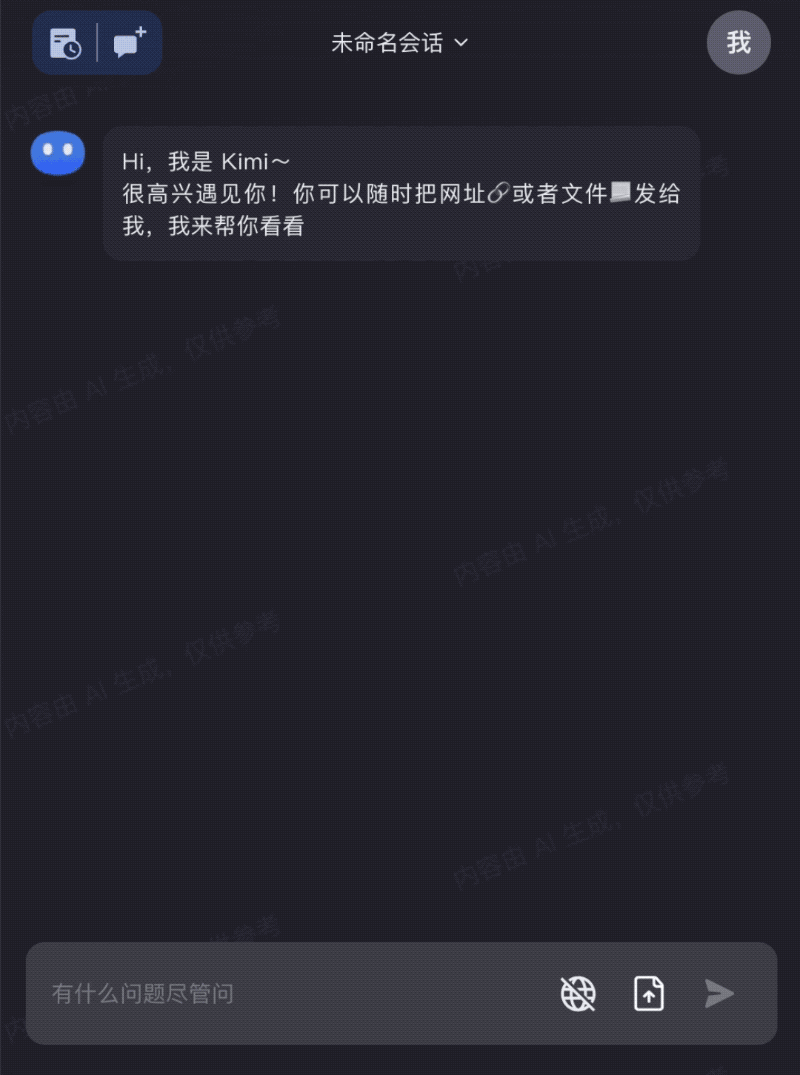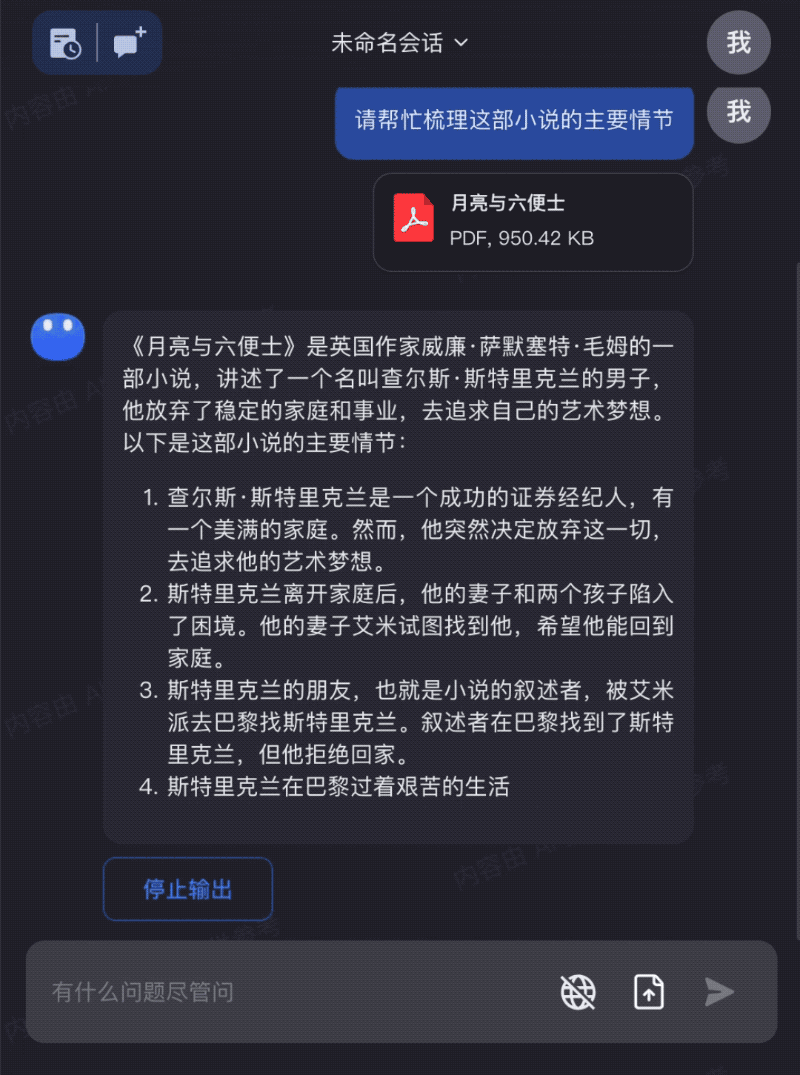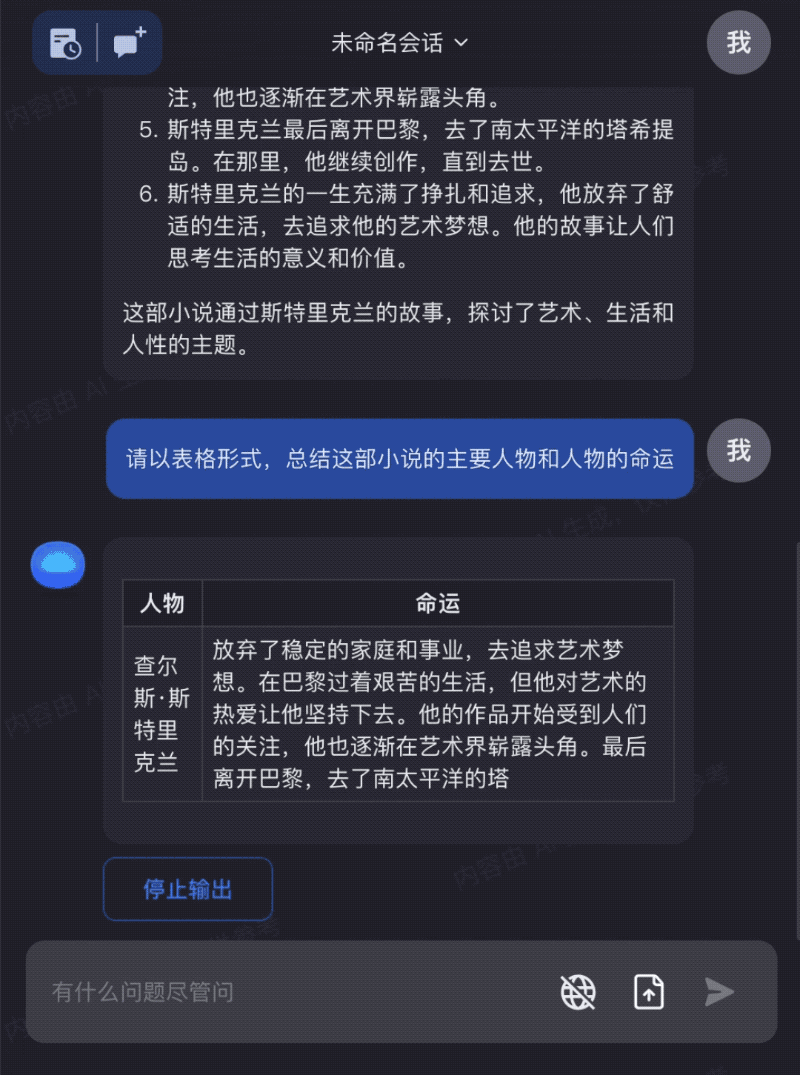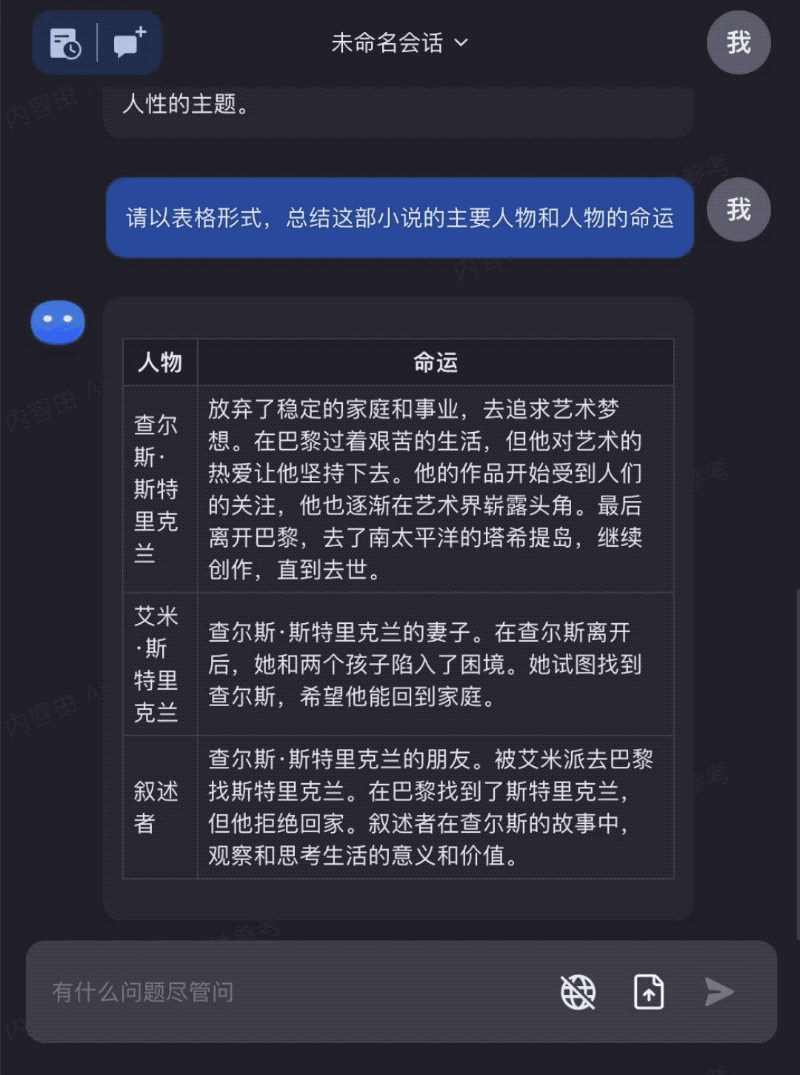
These examples demonstrate that as models can process longer contexts, their capabilities expand to cover more use cases, truly making a difference in people's work, life, and learning. Moreover, because responses can be generated based on comprehensive understanding of full texts rather than fragments, the "hallucination" problem in large model outputs can be substantially mitigated.
No Shortcuts: Solving the Dual Challenges of Algorithm and Engineering
Developing long-context technology involves several "shortcuts" that significantly degrade performance:
-
"Goldfish" models, prone to forgetfulness. They actively discard previous context through sliding windows and similar techniques, retaining attention only to the most recent input. The model cannot achieve holistic understanding of full texts, failing at cross-document comparison and comprehensive long-text comprehension (for example, extracting the ten most valuable insights from a 100,000-character user interview transcript).
-
"Bee" models, focused only on local details while missing the big picture. Through context downsampling or RAG (Retrieval-Augmented Generation), they retain attention to only portions of the input. These models likewise fail at full-text comprehension (for example, they cannot synthesize candidate profiles from 50 resumes).
-
"Tadpole" models, with underdeveloped capabilities. They increase context length by reducing parameter count (for example, to 10 billion parameters), which degrades the model's inherent capabilities. While supporting longer contexts, they cannot handle numerous tasks.
Simple shortcuts cannot achieve desirable production outcomes. To build genuinely usable, useful products, one must reject false shortcuts and confront challenges head-on.
On the training side, developing models with sufficiently long context capabilities inevitably faces these difficulties:
-
How can a model accurately attend to required content within hundreds of thousands of context tokens, without degrading its underlying capabilities? Existing techniques like sliding windows and length extrapolation significantly harm model performance, failing to achieve true context understanding in many scenarios.
-
Training long-context models at the 100-billion-parameter scale demands far greater compute and creates severe memory pressure. Traditional 3D parallelism schemes can no longer meet training requirements.
-
With insufficient high-quality long-sequence data available, how can more effective training data be provided to the model?
On the inference side, after obtaining models supporting ultra-long contexts, serving numerous users presents equally formidable challenges:
-
In transformer models, self-attention mechanism computation scales quadratically with context length. For example, when context increases 32-fold, actual computation grows roughly 1,000-fold. This means that with naive implementation, users would face excruciatingly long wait times for responses.
-
Ultra-long contexts further increase memory demands: Taking GPT-3's 175 billion parameters as an example, the highest current single-machine configuration (80 GiB × 8) can support at most 64k context length inference — illustrating the substantial memory requirements of ultra-long text.
-
Extreme memory bandwidth pressure: NVIDIA A800 or H800 GPUs offer memory bandwidth of 2–3 TiB/s, yet faced with such long contexts, naive approaches achieve generation speeds of only 2–5 tokens/s, creating a severely laggy user experience.
Moonshot AI's technical team executed extreme algorithm and engineering optimizations, overcoming these challenges to productize large-memory models and release a 100-billion-parameter LLM product supporting 200,000-character inputs.
Step One of the "Moonshot": Welcome to the Long LLM Era
Zhilin Yang, founder of Moonshot AI, has stated that whether for text, voice, or video, lossless compression of massive data can achieve high degrees of intelligence.
Progress in lossless compression was once heavily dependent on the "parameter supremacy" model, where compression ratio correlated directly with parameter count — dramatically increasing training costs and application barriers. Moonshot AI believes that a large model's capability ceiling (i.e., lossless compression ratio) is jointly determined by single-step capability and number of execution steps. Single-step capability correlates with parameter count, while execution steps correspond to context length.
Moonshot AI believes longer context lengths can open an entirely new chapter for large model applications, propelling large models from the LLM era into the Long LLM (LLLM) era:
-
Everyone can have a virtual companion with lifelong memory, recalling every detail of interactions across the span of life, establishing long-term emotional bonds.
-
Everyone can have an assistant co-inhabiting their work environment, knowing all knowledge in both public domains (the internet) and private domains (enterprise internal documents), helping you achieve your OKRs based on this comprehensive understanding.
-
Everyone can have an omniscient learning guide, not only providing accurate knowledge but guiding you to break down disciplinary barriers and explore and innovate more freely.
Of course, longer context lengths are merely Moonshot AI's first step toward next-generation large model technology. Moonshot AI plans to leverage its leading position in this domain to accelerate innovation and real-world application of large model technology.
Voices from the Moonshot Partners:
Xi Cao, founding partner of Monolith, stated that Zhilin Yang is among the most recognized Chinese technical experts in the global large model field, with his team possessing deep technical accumulation in artificial intelligence technology, particularly large language models, and having gained broad international recognition. While OpenAI and Anthropic in Silicon Valley have attracted considerable attention, Moonshot AI — with sufficient technical reserves — is also growing into a globally leading AGI startup. Multimodal large models represent a key competitive domain for AI vendors, with long-context input technology being one of its core technologies. Moonshot AI's newly released large model and Kimi Chat have achieved important breakthroughs in this area, with successful application across multiple real-world scenarios. Monolith will continue to increase its investment and support Moonshot AI team's bold innovation and technical breakthroughs in the AGI field, leading the future development of China's artificial intelligence technology.

