After OpenClaw, What Are We Still Missing for Agents That Can Scale?

How Can Agents Actually Be Put into Practice


As model scaling laws begin to plateau, entrepreneurs, investors, and consumers are shifting more attention toward Agent.
The viral success of OpenClaw seems to further confirm this trend, with some optimists even declaring that Agent's "iPhone moment" has arrived on the demand side.
But returning to reason: for individual geeks, OpenClaw is fun; for enterprises and commercial environments, it has serious drawbacks. It's expensive (burns tokens), uncontrollable (blurry safety boundaries), raises privacy concerns, and is difficult to collaborate with.
To put it dramatically, OpenClaw represents the most dazzling demo in the Agent space right now, but between that demo and a truly scalable production system lies a massive engineering chasm.
Recently, Monolith hosted an "After the Model" tech salon in Wudaokou, inviting developers and researchers from various universities and industry to discuss this very proposition.
We found that today, as model capabilities are no longer the sole bottleneck, how Agents can truly land in production has become the focal point for practitioners. One recurring theme throughout the salon: An Agent needs to be a sustainably operating system, not just a one-off task completion.
This means it requires not just model intelligence, but also stringent engineering metrics — stability, high throughput, cost control, and precise state management.
Centered on this question, the salon focused on four barriers constraining Agent scalability and sustainable system operation: Cost, Environment, Infrastructure, and Memory.
We've compiled some core insights from the salon for practitioners' reference. (Note: Views expressed in this article do not represent Monolith's institutional positions.)
Contents:
-
You Can't Build a Bungalow with Gold
-
When a Supercomputer Brain Gets Paired with a Broken PC
-
Infra That's "Too Heavy, Too Expensive, Out of Reach"
-
Long Context Is No Panacea

1. You Can't Build a Bungalow with Gold
The sustainability of any system ultimately comes down to unit economics. If the value an Agent creates can't cover its consumption costs, then no matter how advanced the model, the system is commercially unsustainable.
Current Agent barriers lie primarily in data and infrastructure.
In SFT (Supervised Fine-Tuning) mode, we rely on human experts to teach models how to act. But in high-barrier tasks like GUI Agents (AI operating computer interfaces), this dependency becomes an unbearable burden.
To obtain high-quality GUI task data, some practitioners found they needed to hire "senior PhD students from top-tier universities" for annotation — and even this caliber of human talent required 20 minutes to annotate a single data point.
This exorbitant time and labor cost directly limited data scale; teams ultimately annotated only 200+ tasks, unable to expand further.
Put simply, we're literally building bungalows with gold — relying on stacking expert manpower for intelligence gains is unsustainable in complex Agent scenarios.
This reverse-forces the industry toward RL (Reinforcement Learning) — letting Agents trial-and-error and self-play in virtual environments, breaking free from expensive human-labeled data. Only then can data costs shift from "per-head" to "per-compute," achieving marginal cost reduction.
But RL's barrier isn't low either.
Traditional industrial-grade RL training typically relies on massive compute clusters. Even optimized training pipelines still require 16 GPUs (8 for sampling, 8 for training) plus substantial CPU resources to support simulation environments.
For most SMEs or academic teams, this is a hefty expense. Without RL-enabled self-generated data, Agent business models get locked down by prohibitive labor costs.
The breakthrough lies in building high-fidelity environments where Agents produce massive interaction data through autonomous exploration, then training stronger policies via well-designed reward signals in RL.
2. When a Supercomputer Brain Gets Paired with a Broken PC
Another paradox in current Agent training: lightning-fast GPU compute paired with turtle-speed operating systems.
In traditional RL tasks (chess, gaming), environment feedback is millisecond-level, with short step lengths and fast speeds.
But in GUI Agent scenarios, a single action — clicking an Excel button in a virtual machine — requires traversing a lengthy chain: "VM rendering → screenshot → image transmission → vision model processing."
In actual training, completing one step of interaction takes over 30 seconds — unbearably slow.
This extreme latency further causes extreme compute waste — in traditional RL workflows, architectures are typically tightly coupled. This means when GPUs are updating models, environments wait idle; when environments are sampling data, GPUs sit empty.
This temporal-spatial mismatch and mutual blocking leads to abysmal compute utilization.
Beyond speed, environmental complexity rises exponentially.
Unlike text generation, GUI Agents face a pixel-level action space — theoretically they can click or drag at any coordinate on screen, making the action space near-infinite.
This makes rewards extremely sparse. For a task like "print Excel content to PDF," the Agent must execute dozens of consecutive steps. Throughout this process, the environment typically remains silent, telling the Agent nothing about whether an intermediate click was right or wrong — only the final step yields a result.
This combination of "long-horizon + sparse feedback + infinite space" constitutes the true face of Agent environments — one filled with friction. We can no longer train Agents using the same logic as chatbots.
For startups, this means mustering resources to build simulation training environments, which tests a team's technical depth more than simply buying H100 GPUs.
3. Infrastructure That's "Too Heavy, Too Expensive, Out of Reach"
How to solve the environment problem?
At the event, different presenters offered infrastructure reconstruction answers from two dimensions — horizontal scaling and vertical lightweighting: Decoupling.
Horizontal Decoupling: Breaking the Sampling-Training Synchronization Lock
Facing the painfully slow interaction speed of GUI Agents, one researcher proposed a framework called Dart (Decoupled Agent RL).
Its core logic: physically separating sampling and training ends entirely.
In this architecture, the sampling side no longer waits for model updates. Instead, it uses Kubernetes (K8s) to parallel-launch hundreds of Docker containers as Environments, continuously producing trajectory data. Data flows through a MySQL-based trajectory manager for asynchronous scheduling, then feeds to the training side.
This design introduces off-policy challenges (data and model out of sync) requiring data filtering mechanisms to balance, but the gains are massive — at least threefold:
- Eliminates GPU idle time waiting for environment feedback
- Achieves 5.5x environment utilization improvement
- Nearly doubles overall training throughput
This means Agent infrastructure must handle asynchronous data streams, not traditional synchronous batch processing — transforming training into a continuously flowing, high-throughput pipeline.
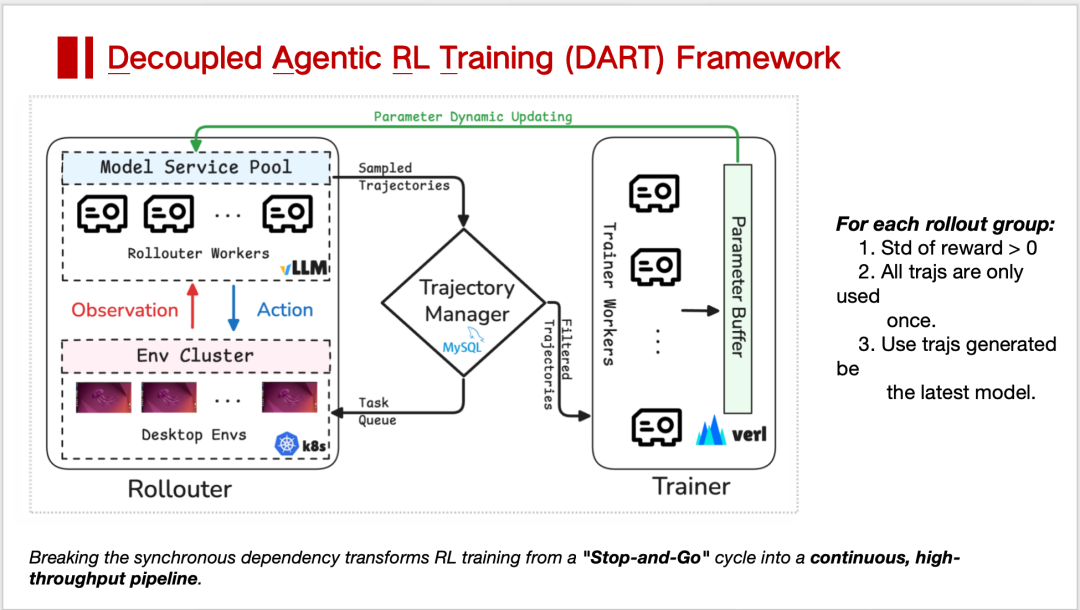
Dart Framework
Vertical Decoupling: Lowering the Compute Barrier
Another infrastructure pain point is "heaviness."
Existing industrial-grade frameworks (like Verl, OpenRLHF) target large-scale clusters, with massive codebases and tightly coupled modules. For academia or resource-constrained startup teams, modifying algorithm logic or adapting to small-scale clusters carries extremely high barriers.
Another researcher demonstrated a lightweight decoupling approach — developing modular frameworks that separate algorithm logic, model architecture, and distributed engines.
This RL-centric design philosophy encapsulates engineering complexity within module boundaries, achieving "logic as implementation" — researchers can freely combine algorithm components like GAE, GRPO, PPO through plug-and-play configurations like building blocks, drastically reducing the burden of handling underlying distributed systems.
They also achieved memory reuse through CPU Offload — unloading training parameters to CPU during inference sampling, then loading back to GPU during optimization updates, significantly lowering hardware barriers.
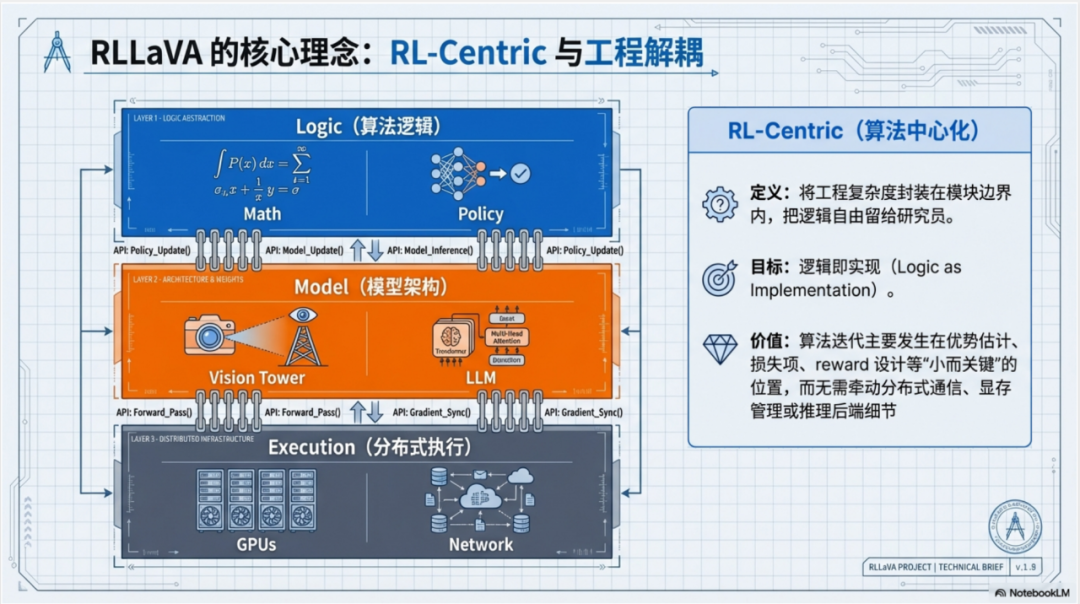
RLLaVA Framework
The logic behind all these technical details converges on one point: to make AI Agents viable, you first need to properly equip their workstation (infrastructure). Existing tools are too heavy, too expensive, too slow. So we need lighter, more modular middleware that lets small and medium teams afford Agent training too.
This is precisely where infrastructure entrepreneurship opportunities lie.
4. Long Context Is No Panacea
Beyond compute and environment, another problem is state management.
The Transformer architecture, while powerful, lacks read-write memory — it cannot explicitly store or update intermediate reasoning states, nor does it have looping or recursive mechanisms.
For simple Q&A, this stateless characteristic isn't a major issue; but when facing complex software development or long-horizon logical reasoning, this deficiency is fatal.
Without effective management of reasoning states, models often experience broken inference chains or logical drift when solving complex recursive tasks.
These are problems heavy AI users can surely relate to.
Academia and industry are also attempting repairs at the architectural foundation. Approaches like Mamba and other State Space Models (SSM), Linear Attention mechanisms, and Stack mechanisms are becoming popular directions for addressing this issue.
These new architectures attempt to give models native state evolution capabilities through more efficient state compression and transfer mechanisms, thereby compensating for Transformer's congenital deficiency in long-horizon state management.
Another approach is changing the reasoning vehicle. Most current Agents rely on natural language for chain-of-thought reasoning, but natural language has limitations in precise computation and state tracking.
One direction is teaching models to think in code — code inherently possesses variables, functions, and logical flows, making it more suitable than natural language for precise state management.

Code Thinking
At the engineering implementation level, a common misconception equates Long Context with "memory." But simply stretching context windows is neither economical nor practical.
In real scenarios, memory divides into two categories: user-side memory and execution-side memory. The former resembles traditional user profiling, recording preferences and basic information — most AI customer service already has rudimentary forms of this. The latter is key to Agent self-evolution — not just remembering "who the user is," but remembering "how I completed this task last time," including execution trajectories and lessons learned.
When encountering similar tasks again, Agents should be able to reuse successful paths or avoid previously stumbled pitfalls, rather than starting from scratch.
On memory architecture, one approach designs it as a file system-style layered storage. When an Agent needs to review, it performs file-reading operations rather than needle-in-haystack searching through context windows.
For a system, the essence of "memory" shouldn't be remembering all conversation history, but rather being able to precisely manage every variable's lifecycle and state, like a computer.
In short, for enterprise applications, customers don't care how long your context window is — only whether the AI can remember "what I said last time" and "what my company's business rules are."
Solving the forgetfulness problem is the ticket for Agents to graduate from toys to enterprise-grade workers.
5. The Moat Has Changed, and So Will the Winners
Though this salon was a technically and engineering-oriented exchange, we can still extract many signals from it.
We used to believe the moat lay in the model itself, but as open-source capabilities rapidly close the gap, the moat is expanding from "single-point model capability" to "system integration capability."
Future winners won't necessarily be the teams with the strongest models, but those who can maximize model capabilities through excellent infrastructure architecture, low-cost data flywheels, and efficient memory management. Engineering capability is becoming the new source of differentiation.
Second, we should note: the picks-and-shovels logic has changed, and Agent infrastructure is an undervalued pocket.
As discussed in the salon, to truly land Agents we need entirely new infrastructure — not traditional cloud computing, but Agent-native infrastructure purpose-built for Agents: asynchronous training frameworks, decoupled sampling environments, vectorized memory file systems, and the like.
The current Agent development stack remains extremely primitive. This means whoever can provide developers with usable "IDEs," "debuggers," and "virtual training grounds" has the opportunity to become the Databricks or Snowflake of the AI 2.0 era.
Finally, with complex scenarios like GUI emerging, manual annotation costs are clearly unsustainable.
Future data moats will no longer be about who scraped more internet text, but who can build more realistic simulation environments where Agents self-play and self-evolve. This high-quality synthetic data produced through RL will be the scarcest resource in the next phase.
We forever inhabit a commercial environment of constant noise emergence and noise filtration. The deep waters of Agents have only just begun.


