Wang Yu of Tsinghua University: Lowering Costs Is Key to Commercializing Large Models

Solving the Last Mile for Large Model Deployment


Recently, Wang Yu, professor and department head of Tsinghua University's Department of Electronic Engineering and founder of Infinigence AI, participated in a Zhihu event on the theme How the Large Model Industry Can Develop Sustainably. He shared his academic perspective on computing power, costs, and the software-hardware ecosystem. Wang noted that the deployment of large models today faces numerous challenges, and balancing compute supply with demand while lowering application costs requires an AI ecosystem built on integrated software-hardware co-optimization.
Infinigence AI was founded in May 2023 as a company developing an algorithm-chip joint optimization platform for large models, dedicated to addressing pain points such as difficult deployment and high inference costs. Previously, Professor Wang Yu co-founded DeePhi Tech in 2016 with students Song Yao and Shan Yi. The company was acquired in 2018 by Xilinx, the world's largest FPGA manufacturer, for $300 million — becoming the first prominent Chinese AI chip startup to be acquired during the AI chip entrepreneurship boom.
Large models are driving the next generation of AI technology development, a key investment theme for Monolith since its founding. Monolith led Infinigence AI's Series A round and is also a co-founder of See Fund, Tsinghua University Department of Electronic Engineering's early-stage technology investment fund.
Below is the transcript of Professor Wang Yu's speech, edited by Monolith. Enjoy:

It's a great honor to share my current understanding of the large model industry. I'm currently a professor at Tsinghua University's Department of Electronic Engineering, focusing on hardware, chips, and system software. I've had some entrepreneurial experience. Many of you here probably work more on algorithms and applications, so today I hope to offer a different perspective on how I view artificial intelligence, particularly this wave of large model development.

The emergence of large models has significantly advanced fields including artificial intelligence, autonomous driving, scientific computing, and robotics. As head of Tsinghua University's Department of Electronic Engineering, the freshman orientation each September is an important moment for exchanging ideas with new students. When analyzing future career directions with these 200-plus students, one area I discuss is robotics.
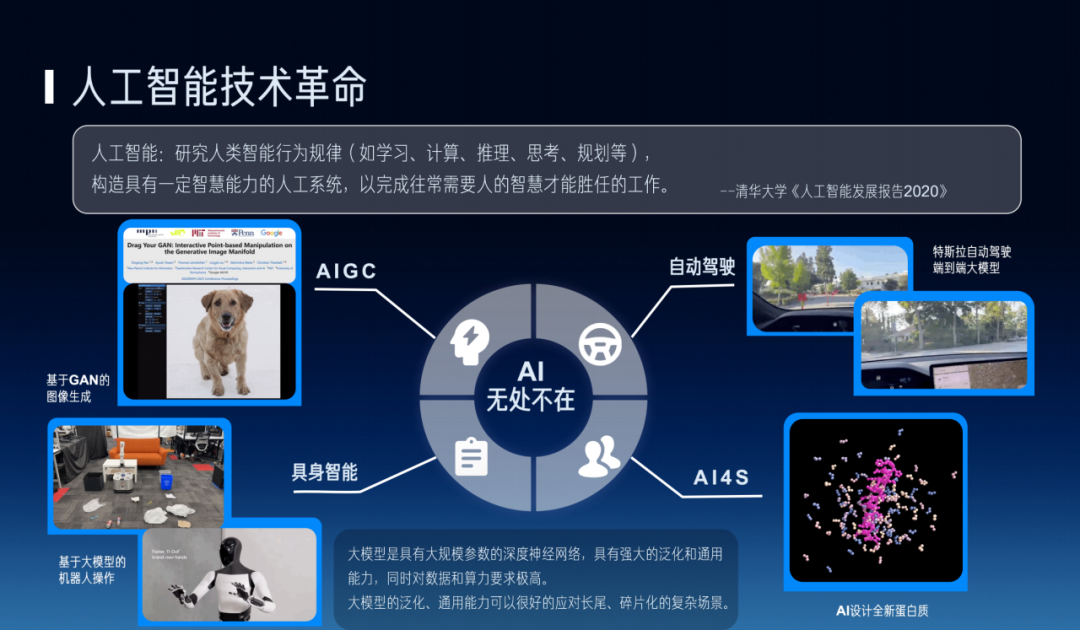
One challenge facing future society is population aging, and robotics can play a key role in addressing elderly care. In recent years, the number of gaokao takers has remained relatively high, and competition is fierce — because back then there were 18 million births annually, while in the last year or two it's been around 8 million. I always ask them: "Look, I'm in my forties now. I can work healthily for my country until my fifties or beyond. But when I'm seventy or eighty — about 30 years from now — who will take care of me?" There won't be enough people then. The pressure of supporting the elderly in 2050 will be enormous, because our GDP needs to grow. GDP equals what? GDP = population × GDP per capita. China's economic development is now shifting from high-speed growth to high-quality development, so we need to raise GDP per capita. But if population declines, merely raising per-capita GDP may not be enough. So we must vigorously promote the robotics industry and cultivate more specialized talent to prepare for future societal needs.

China's service robot production is continuing to grow. Though they currently mainly handle relatively simple tasks, they're already penetrating widely into household life. Taking service robots as an example — in general-purpose robotics and humanoid robots, on one hand, large amounts of decision-making algorithms are needed to adapt to ever-expanding state spaces, solving increasingly complex problems through more powerful computing and superior algorithms. On the other hand, perception capabilities are also continuously upgrading. In recent years, companies like Google and Tesla have integrated perception, decision-making, and control in practice, building massive systems. This integrated approach plays an important role in robotics technology development.

In such massive systems, end-to-end large models are needed for real-time operation. This places extremely high demands on computation, response speed, and throughput. Therefore, these application scenarios raise higher requirements for "how hardware can keep up with software development" or even "support software development."
From a personal perspective, large models currently face three main challenges:
First, compute constraints.
Second, costs are quite high for both inference and training — a challenge faced universally by entrepreneurs and large companies alike.
Third, driving ecosystem development in the face of unique algorithms and diverse hardware is also an important challenge.
Compute Constraints
Basic Research is the Fertile Soil for Technological Breakthroughs
Chips need to go through design, manufacturing, testing, packaging, and other processes before they can be used. The chip industry chain is globalized, with many key production steps distributed across different regions — EDA software, critical materials and equipment in the manufacturing process, and so on. Currently, China's chip industry remains in an active development process.
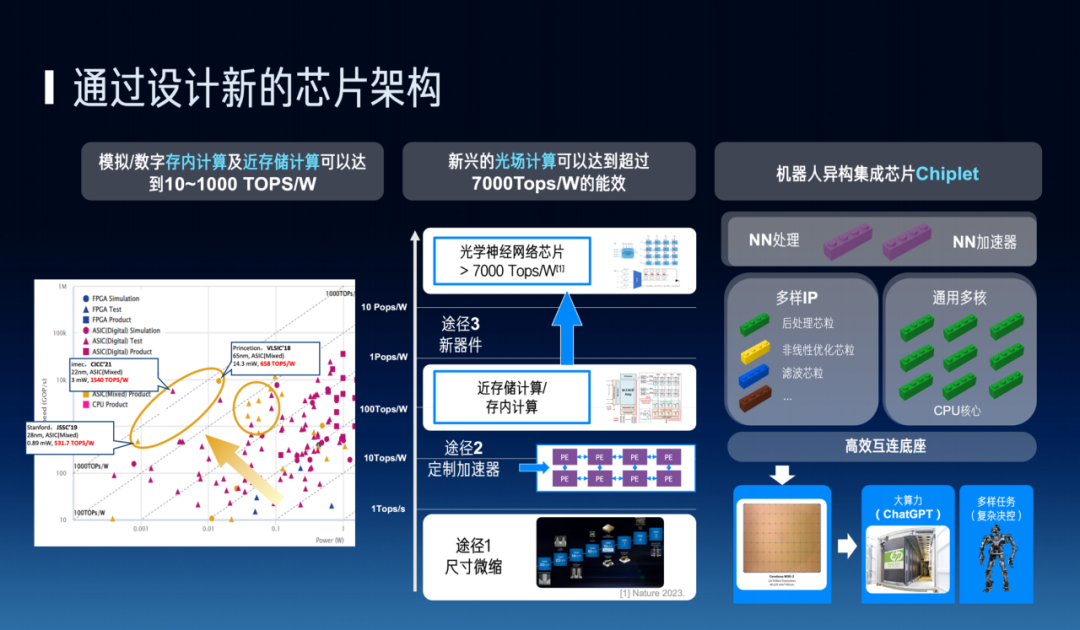
In chip manufacturing, we face limits on compute density. What people are currently discussing is 1 TOPS/Watt design — that is, 1 trillion operations per watt (the human brain consumes about 20 watts). For certain tasks in the future, we'll need hardware to reach 1,000 TOPS/Watt. So how do we achieve 1 TOPS/Watt, or even hundreds or thousands of TOPS/Watt, through chips?
In recent years, compute chips have ridden the dividend of dimensional scaling, improving from roughly 1 giga-ops/Watt to 10 TOPS, even 100 TOPS, enabling various specialized processors. Now, we're beginning to focus on near-memory computing and in-memory computing, because moving data consumes more power than computing it, and data movement (bandwidth) has become more complex. Going further, we're also exploring whether we can use optoelectronics rather than silicon-based microelectronics to manufacture chips — a series of research directions the industry is watching.
The robotics field is similar, though robots are heterogeneous, so I won't elaborate in detail here. In summary, we have multiple different paths (such as designing new chip architectures, etc.) to improve compute per watt.
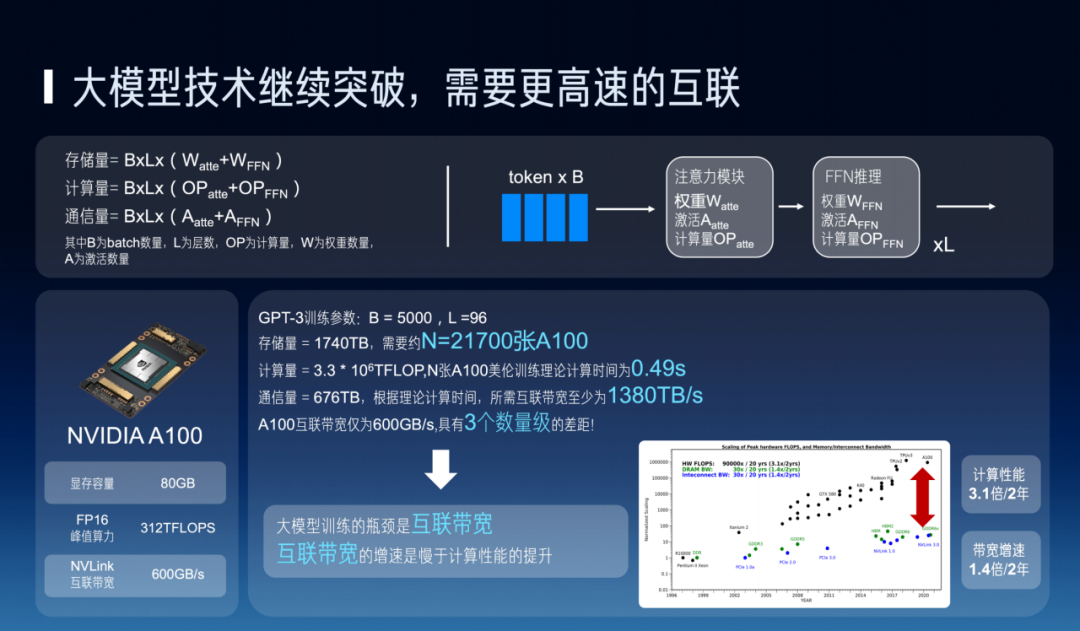
On the other hand, large model development requires extremely high interconnect bandwidth. From derived data, we can observe substantial information, such as communication volume. According to theoretical calculations in our lab, GPT-3 requires interconnect bandwidth of 1,380 TB/s, while a single NVIDIA card's native 600 GB/s interconnect bandwidth shows a significant gap from this requirement. This is why many such cards need to be connected together to complete training for this model. Currently, compute performance is improving faster than bandwidth growth, and in multi-interconnect application scenarios, how to effectively connect machines together is a rather complex task.
When compute is constrained — for example, training GPT-4 requires using 24,000 A100 GPUs. When our single-card capability is limited, and our own chip performance falls short of A100, we might need 100,000 compute cards to complete the same computational work. But how do we efficiently interconnect these 100,000 cards for training? Even if each individual card or machine has only a one-in-ten-thousand failure rate, connecting 100,000 of them will certainly have a much higher failure probability than connecting 10,000. This poses a higher, more challenging requirement for our AI system capabilities, requiring innovation and breakthroughs at the system level.
Cost Reduction is the Key to
Large-Scale Commercial Application of Large Models
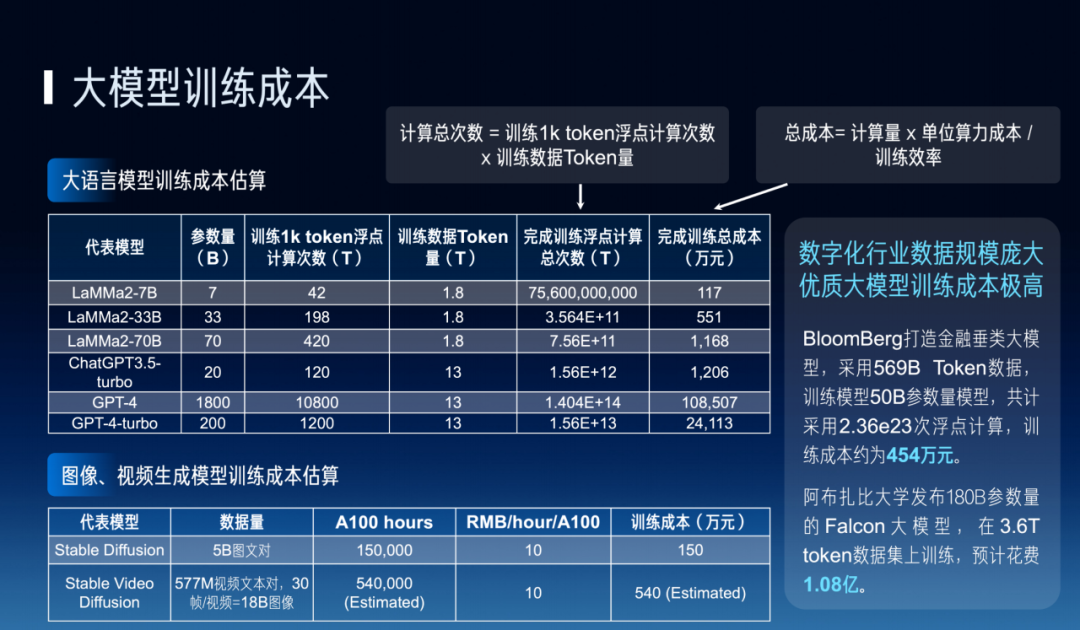
Currently we notice many manufacturers and universities are training their own models, but whether foundation models or domain-specific vertical models, all are facing very unfriendly cost challenges. Academia needs to cooperate more closely with industry, because training costs are indeed a quite severe problem requiring joint efforts to find solutions.
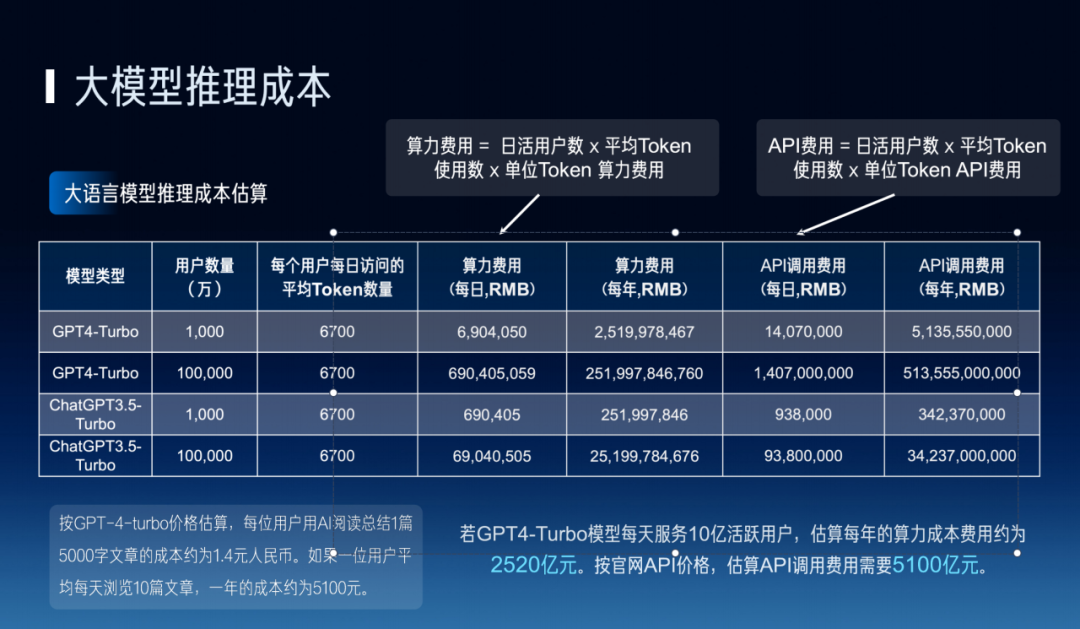
Is the inference stage any better? We found it's not. Calculating across different model types and user counts, compute costs can be expressed as daily active users × average token usage × compute cost per token. With self-built compute clusters, daily costs may reach 6.9 million yuan. Using existing APIs for operations, costs may be even higher.
We used publicly available data to do a rough order-of-magnitude estimate of compute costs. Assuming GPT-4 Turbo needs to serve 1 billion daily active users, annual compute costs could exceed 200 billion yuan. Considering that the vast majority of companies have revenues in the hundreds of millions, not hundreds of billions, how to resolve this cost pressure is an extremely challenging problem.
Similarly, for individual users, if each person browses 10 articles per day on average, annual costs could reach 5,000 yuan. Imagine — who would be willing to spend 5,000 yuan to use a single feature? Certainly no one.

We tried thinking from some practical cases. For example, The Three-Body Problem Book 3 is about 400,000 Chinese characters. Using GPT-4 Turbo for inference once might cost several dozen yuan. This cost means it can't be a rigid demand — perhaps 1 yuan, 0.1 yuan, or even below 0.01 yuan would be acceptable to the masses. Another example: in e-commerce shopping scenarios, to get a user to buy a product under 100 yuan, is it necessary to spend several dozen yuan to persuade them or directly help them purchase? The answer is also no.
Therefore, cost is a key factor that large model inference must consider going forward. Only by reducing costs is there hope for achieving large-scale commercial application.
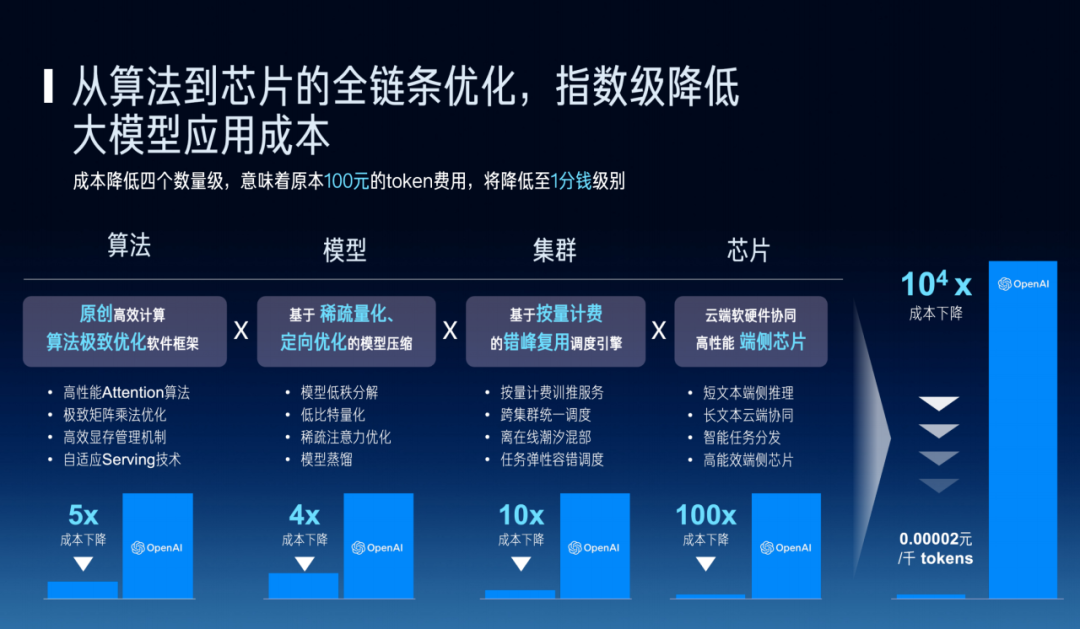
At the algorithm stage, customized vertical models can indeed achieve smaller scales through optimization — not needing hundreds of billions of parameters, models with tens of billions of parameters can also complete tasks. At the model stage, methods like sparse quantization and targeted optimization can reduce per-call computation or memory access, as well as processor power consumption. Additionally, methods like utilizing idle cloud compute during off-peak hours are also key means of cost reduction.
Finally, at the hardware level, we can consider designing specialized edge hardware for large model computation to achieve efficient operation. Through collaborative optimization from algorithms to chips, costs could potentially be reduced by four orders of magnitude. Once reduced from 100 yuan to the 0.01 yuan level, I believe many things can then use large models. This full-chain optimization work holds significant importance for driving large-scale commercial adoption of large models.
Software-Hardware Co-Optimization Ecosystem
Driving Sustainable Development of Large Models
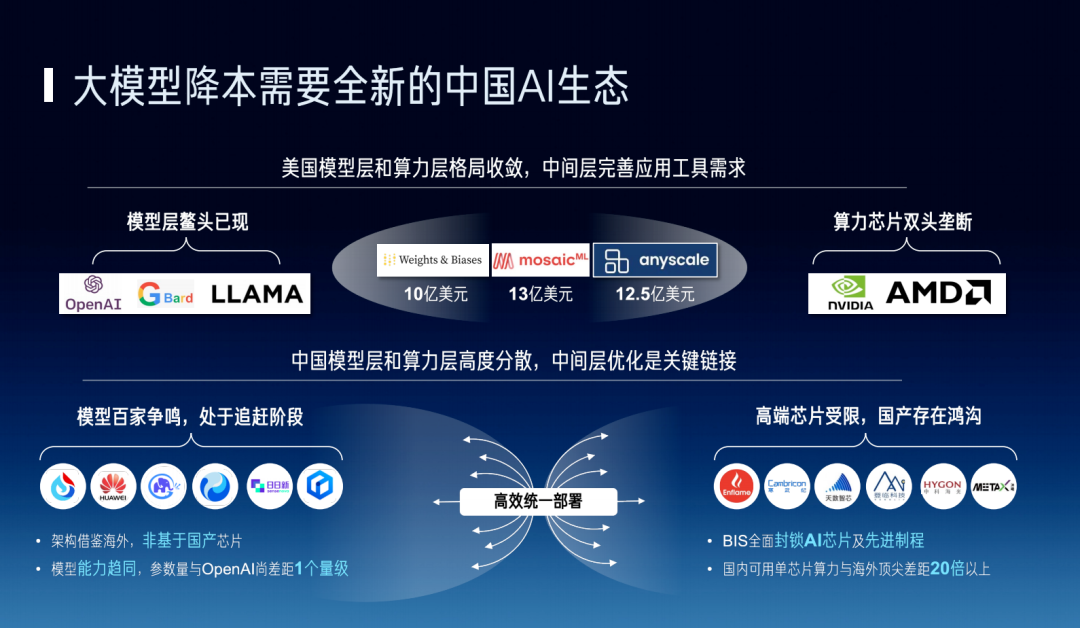
At the chip level, due to NVIDIA's powerful ecosystem influence, many people build environments on NVIDIA. Now many companies worldwide are trying to break free from this ecosystem constraint. For example, Google launched TPU to serve more users at lower prices. Recently, AMD released the MI300, causing its stock price to rise rapidly and being seen as having great potential to compete head-to-head with NVIDIA.
At the model level, there are numerous model choices — this is common both domestically and internationally.
Finally, in the middleware layer, foreign companies typically provide software services in tiers: SaaS and some software-based revenue models remain fairly standard, so we can see a batch of companies already working hard to support model companies and help maximize compute utilization.
In China, at the model layer we have the "hundred-model war," and at the chip layer there are also a dozen or two dozen very good companies working hard to break through giant constraints. How the middleware layer can achieve efficient unified deployment between the model layer and chip layer is a very important topic.
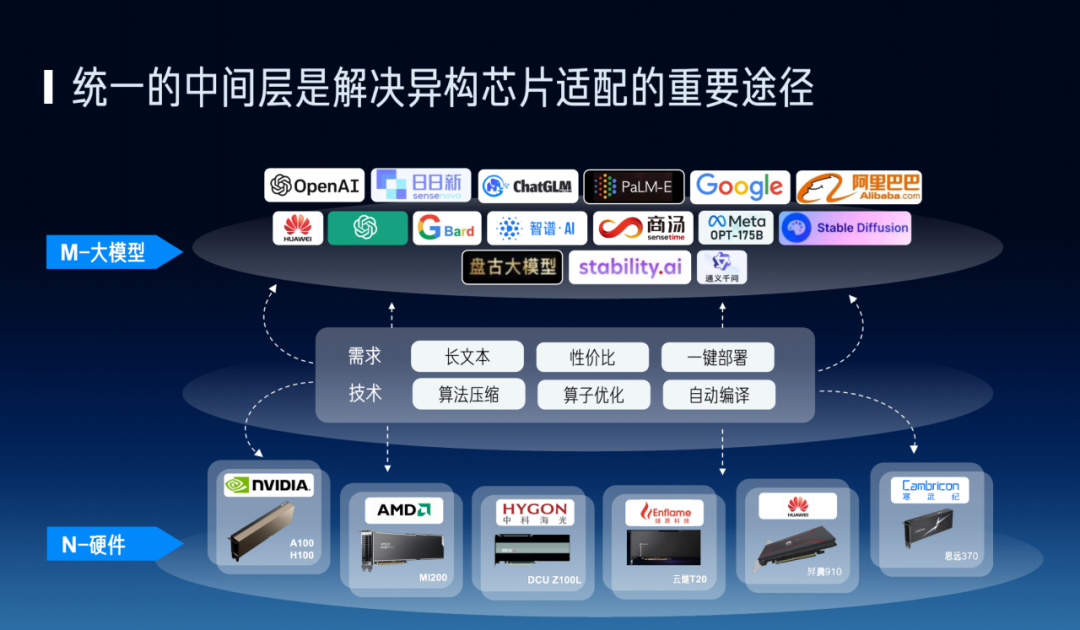
We're also thinking about creating a relatively unified middleware layer to support long context, achieve higher cost-performance, and enable one-click deployment. And within this middleware layer, incorporating tools to assist algorithm and application development — such as integrating algorithm compression, operator optimization, and automatic compilation. Through such a middleware layer, we can hope to better match M large models with N hardware, enabling more flexible deployment.

Building our large model ecosystem requires tightly integrating applications, models, algorithm frameworks, development platforms, and infrastructure. This requires our collective effort to bring everyone together and jointly contemplate the future of sustainable large model development. Thank you all!

