AIGC Pioneer "Jina AI": Decoding the Paradigm Shift in Multimodal AI | Yunqi Capital

The Frontier of a New AI Era

"Yunqi Tech π" shares updates from Yunqi Capital's portfolio companies, exploring how cutting-edge technology pushes the boundaries of real-world applications and tracking the present and future of tech commercialization. Dr. Han Xiao, founder of Jina AI, recently wrote an article recalling his first meeting with Yunqi during the seed round and sharing his insights on multimodal AI. This edition of "Yunqi Tech π" brings you the latest from Yunqi seed portfolio company Jina AI.
**➤➤➤ **In 2022, AIGC became one of the most closely watched frontiers in artificial intelligence. AIGC stands for AI-Generated Content — using AI technology to produce content. It offers significant technical advantages in creativity, expressiveness, production speed, iteration, and distribution, and has emerged as a new mode of content creation following PGC (Professionally Generated Content) and UGC (User Generated Content). At its core, AIGC is powered by artificial intelligence and built on the integration of multiple key technologies, including multimodal interaction.
Against this backdrop, Yunqi seed portfolio company Jina AI stands as a pioneer in AIGC. Its products already span cross-modal, multimodal, neural search, and generative AI — covering a substantial portion of future AI applications. Its MLOps platform helps enterprises and developers accelerate the entire application development process, enabling them to seize the initiative in this paradigm shift and build applications designed for the future.
This article features Dr. Han Xiao, founder of Jina AI, sharing his industry insights on multimodal AI technology.
| Author: Dr. Han Xiao, Founder and CEO of Jina AI
Just a few days before Christmas 2019, I sat in a cramped conference room surrounded by the investment committee of our seed VC firm. We'd been in the office for hours, going back and forth. This was the final, nerve-wracking pitch to secure the $2 million in incubation funding my neural search initiative needed: the birth of Jina AI hung in the balance — a make-or-break moment.
One partner, who had been at Google in New York since 2005, asked me a question I'll never forget:
"Who will be your biggest competitor?"
"Google, Elastic, Algolia, …" I answered confidently — I'd prepared for this one. Then I braced myself, waiting for the tired cliché: "How do you compete with Google?" Before they could ask, I added: "But the more serious competition may come from a technology that doesn't need embeddings as an intermediate representation — an end-to-end technology that returns exactly what you want."
That technology is generative AI, while neural search is discriminative AI.
At that time — fifteen months after Google released BERT — generative AI was not yet a scalable, high-quality answer for search. Neural search was a flexible framework that could easily use dense embedding representations and combine multiple sub-tasks, the only realistic approach for searching multimodal data at the time.
"AI has shifted from unimodal AI to multimodal AI" has become an industry consensus, as shown in the figure below:
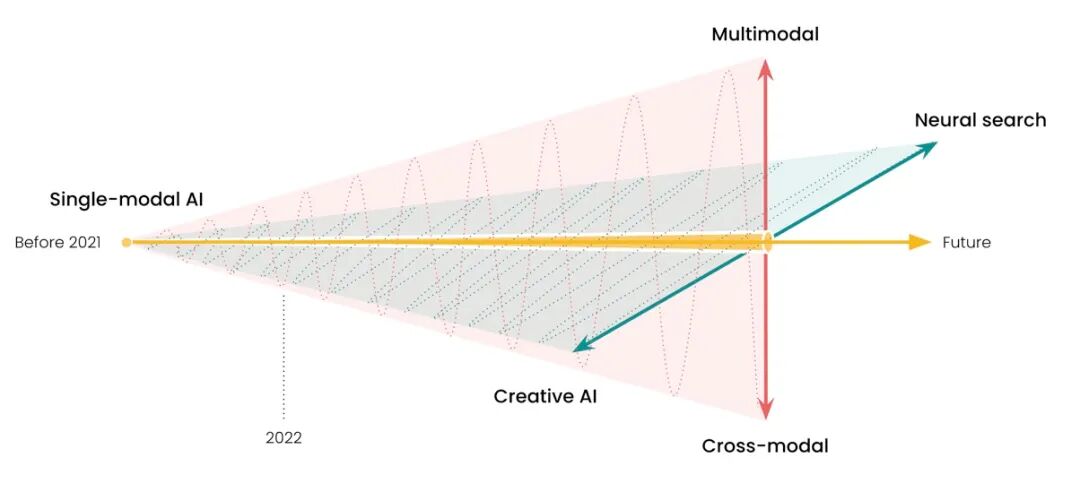
In the rest of this article, we'll review the evolution of unimodal AI and see how this paradigm shift has been happening right before our eyes.
Unimodal AI
In computer science, "modality" roughly means "data type." So-called unimodal AI applies AI to one specific type of data. This was very common in early machine learning. Even today, when you read machine learning papers, unimodal AI still accounts for half the field.
Natural Language Processing
Let's start with natural language processing (NLP). Back in 2010, I published a paper on an improved Gibbs sampling algorithm for Latent Dirichlet Allocation (LDA) models.

Efficient Collapsed Gibbs Sampling For Latent Dirichlet Allocation, 2010
Some veteran machine learning researchers may still remember LDA, a parametric Bayesian model for modeling text corpora. It "clusters" words into topics and represents each document as a mixture of topics. Hence it's sometimes called a "topic model."
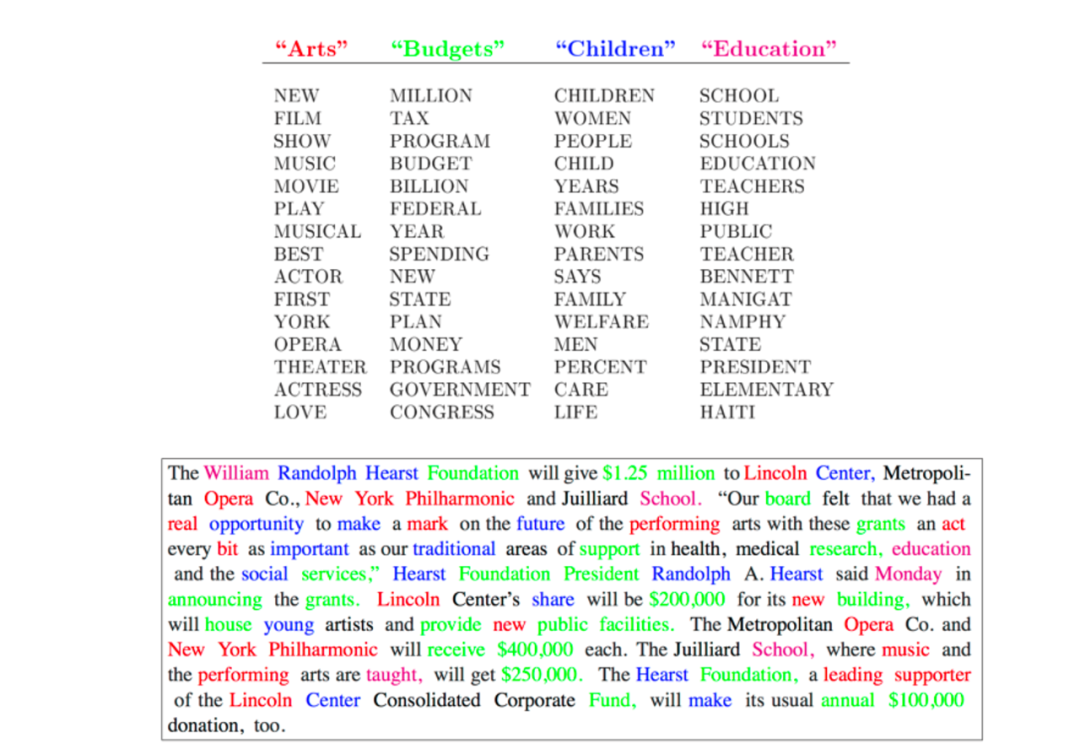
From 2008 to 2012, topic models were among the most effective and popular models in the NLP community — their prominence was comparable to BERT/Transformer in their day. Every year at top ML/NLP conferences, many papers extended or improved upon the original model. But looking back today, it was a fairly "shallow learning" model using a one-off language modeling approach. It assumed words were generated from a mixture of multinomial distributions. This made sense for certain specific tasks, but wasn't generalizable enough for other tasks, domains, or modalities.
Throughout 2010-2020, such one-off methods were the norm in NLP research. Researchers and engineers developed specialized algorithms, each excellent at solving one task, yet limited to exactly that one task:
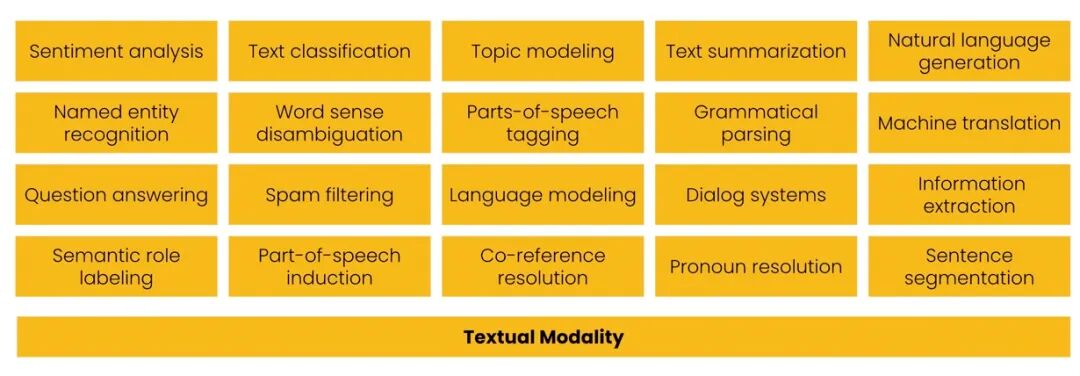
20 Most Common NLP Tasks
Computer Vision
I entered computer vision (CV) somewhat later than NLP. In 2017, while at Zalando, I published a paper on the Fashion-MNIST dataset. This dataset was a direct replacement for Yann LeCun's original 1990 MNIST dataset — a set of simple handwritten digits used to benchmark computer vision algorithms. The original MNIST was too easy for many algorithms — shallow learning algorithms like logistic regression, decision trees, and support vector machines could easily hit 90% accuracy, leaving little room for deep learning to demonstrate its advantages.

Fashion-mnist: a Novel Image Dataset for Benchmarking Machine Learning Algorithms, 2017

Fashion-mnist: a Novel Image Dataset for Benchmarking Machine Learning Algorithms, 2017
Fashion-MNIST provided a more challenging dataset, allowing researchers to explore, test, and measure their algorithms. To this day, over 5,000 academic papers still cite Fashion-MNIST in research on classification, regression, denoising, generation, and more — a testament to its value.
But just as topic models were only for NLP, Fashion-MNIST was only for computer vision. Its limitation was that the dataset contained virtually no information useful for studying other modalities. If you look at the 20 most common CV tasks from 2010-2020, you'll find that almost all of them are unimodal. Likewise, each covers a specific task, but only that one task:
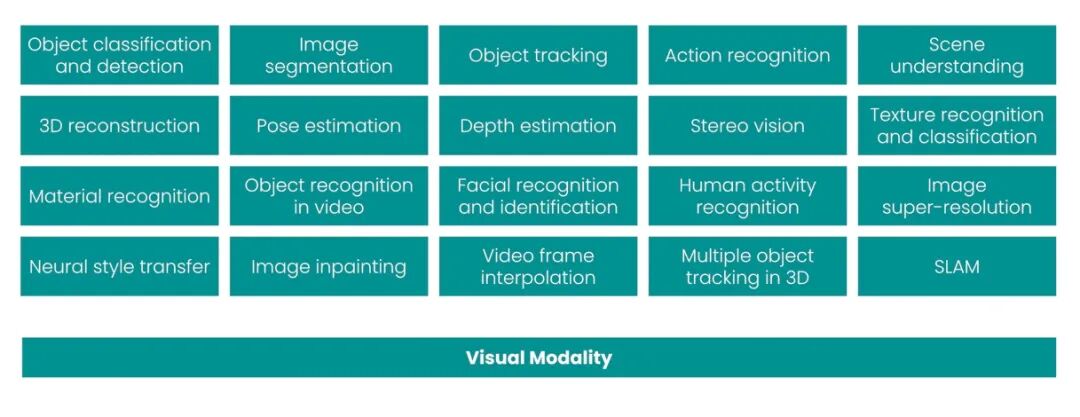
Speech and Audio
Machine learning for speech and audio follows the same pattern: algorithms are designed for ad-hoc tasks around the audio modality. Each performs one task, and only one task, but now all together:
20 Most Common Audio Processing Tasks
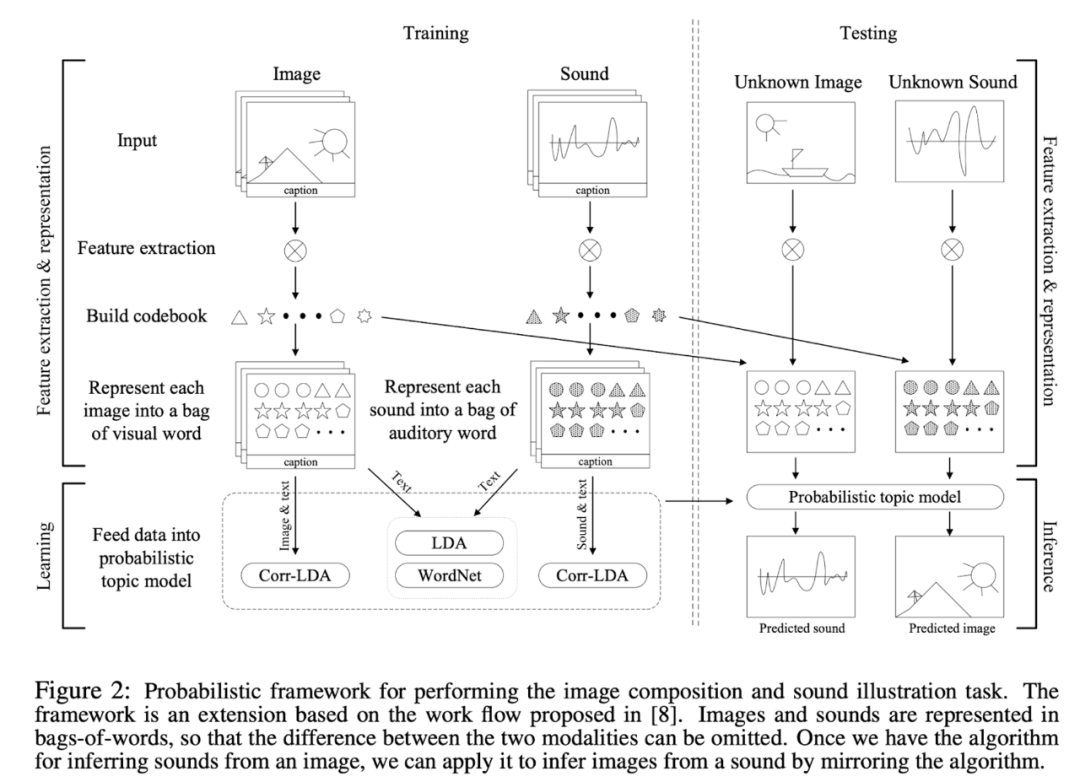
One of my earliest attempts at multimodal AI was a paper I published in 2010, where I built a Bayesian model that jointly modeled three modalities: vision, text, and sound. After training, it could perform two cross-modal retrieval tasks: finding the best matching image from a sound clip, and vice versa. I gave these two tasks a cyberpunk-sounding name: "Artificial Synesthesia."

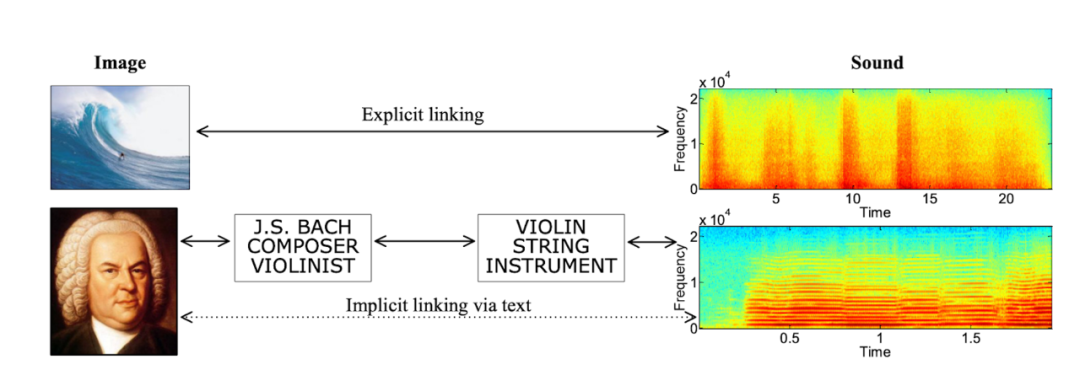
Toward Artificial Synesthesia: Linking Images and Sounds via Words, 2010
Toward Multimodal AI
From the examples above, we can see that all unimodal AI algorithms share two common drawbacks:
- Tasks are designed for only one modality (e.g., text, image, audio, etc.).
- Knowledge can only be learned from one modality and applied within that same modality (i.e., vision algorithms can only learn from images and apply to images).
Above, I've discussed text, images, and audio. There are other modalities, such as 3D, video, and time series, that should also be considered. If we visualize all tasks from different modalities, we get the cube below, with modalities arranged orthogonally:
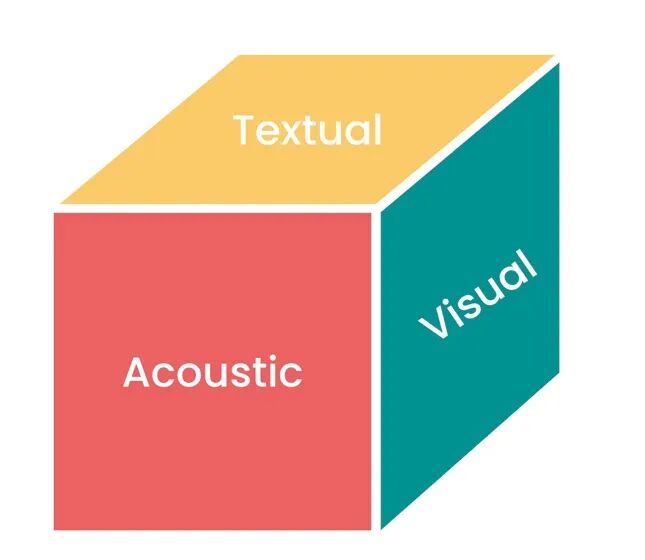
Representing unimodal relationships as a cube, we can assume each face represents tasks for an individual modality.
However, multimodal AI is like reassembling this cube into a sphere. The crucial difference is that it erases the boundaries between different modalities, where:
- Tasks are shared and transferred across multiple modalities (so one algorithm can process images, text, and audio)
- Knowledge is learned from multiple modalities and applied to multiple modalities (so one algorithm can learn from text data and apply it to vision data)
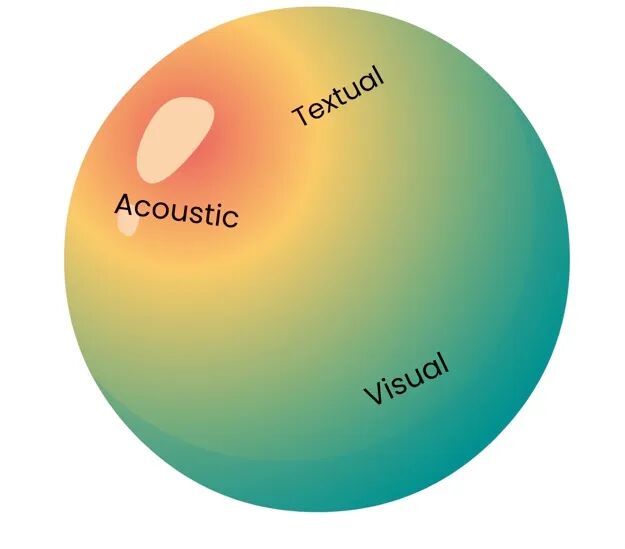
Multimodal AI
The rise of multimodal AI can be attributed to advances in two machine learning techniques: representation learning and transfer learning.
- Representation learning: enabling models to create universal representations for all modalities.
- Transfer learning: enabling models to first learn fundamentals, then fine-tune for specific domains.
Without the advances in representation learning and transfer learning, implementing multimodal AI on general data types would be extremely difficult to realize — like my 2010 paper on sound-image cross-modal retrieval, it would have remained purely theoretical.
In 2021, we saw CLIP, a model connecting correspondences between images and text; in 2022, we saw DALL·E 2 and Stable Diffusion, generating high-quality images from text prompts.
Thus, the paradigm shift has already begun: going forward, we will inevitably see more and more AI applications evolve beyond single modalities toward multimodal systems that cleverly exploit relationships between different modalities. As the boundaries between modalities blur, one-off approaches will no longer suffice.
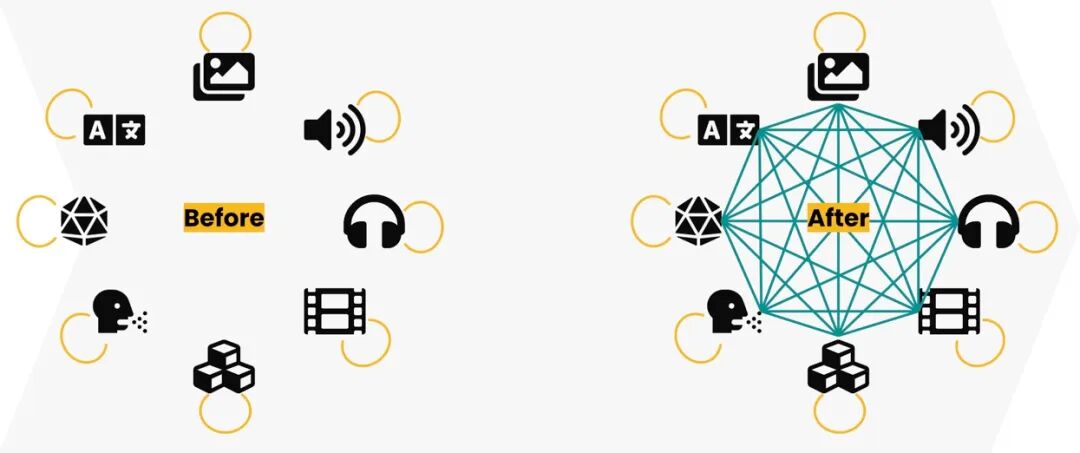 The Paradigm Shift from Unimodal AI to Multimodal AI
The Paradigm Shift from Unimodal AI to Multimodal AI
The Duality of Search and Generation
Search is overfitted generation; generation is underfitted search
Search and generation are two fundamental tasks in multimodal AI. What exactly is their relationship?
Search and generation are two sides of the same coin — a duality.
To understand this, let's take text-to-image and image-to-image as examples and look at the following two functions:
def foo(query: str) -> List[Image]: ...
def bar(query: Image) -> List[Image]: ...
So, what are foo and bar?
- When they are search,
foorepresents text-to-image retrieval (CBIR), andbarrepresents image-to-image retrieval. - When they are generation,
foorepresents text prompt to AI-generated image, andbarrepresents initial image to AI-generated image.
So, can you tell the difference below? Which results are from search, and which are AI-generated? And does it really matter? Search is finding what you need; AI generation is making what you need. If a system returns what you need, does it really matter whether it came from search or AI generation?
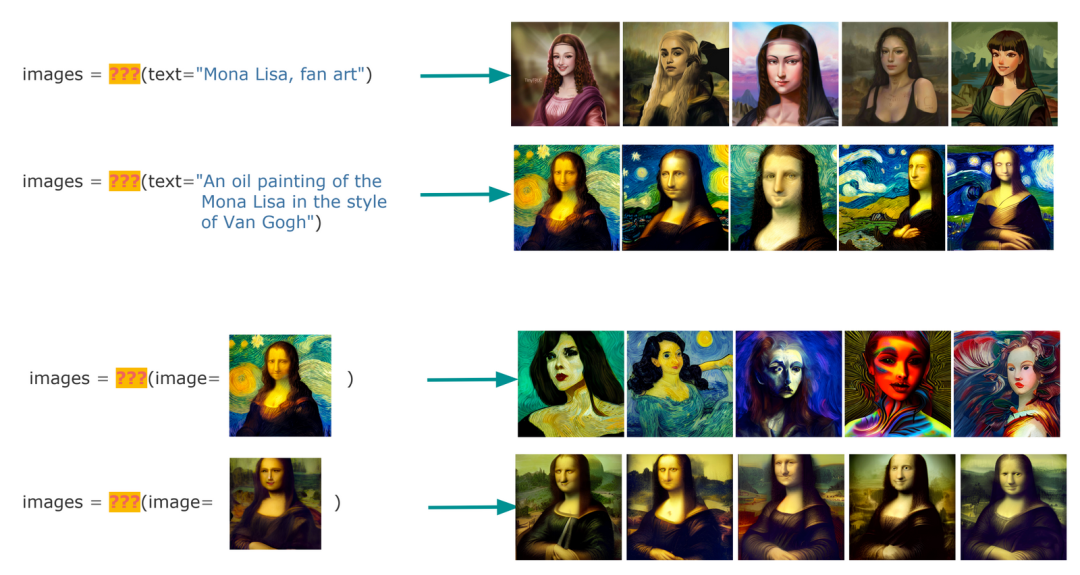
"Well, but database integrity does matter," you might retort. "Because I don't want to see fabricated product images in my product search results." Sometimes people do care about database accuracy, but solving that is easy — we just need to overfit a generative AI model. We can make the model memorize everything it saw in its training data, losing all generality and generalization ability. It will only return content from the training data. See, now you have a reliable search system.
Generative AI alleviates this repressive restriction. Let the model improvise, let us embrace randomness, let perception trump fidelity. Generative AI is simply an underfitted search system.
The coin keeps spinning. Which side will it land on? Does it still matter?
Conclusion
We stand at the frontier of a new era in artificial intelligence, where multimodal learning will soon dominate. This type of learning, which combines learning from multiple data types and modalities, has the potential to revolutionize how we interact with machines. So far, multimodal AI has already achieved tremendous success in fields like computer vision and natural language processing. In the future, there is no doubt that multimodal AI will have an even greater impact — for example, developing systems that can understand the nuances of human communication, or creating more realistic virtual assistants. In short, the future holds infinite possibilities, and we have only scratched the surface!









