Yunqi Capital | Astribot and Top Research Institutes Propose New CLAP Framework to Teach Robots Skills by Watching Videos

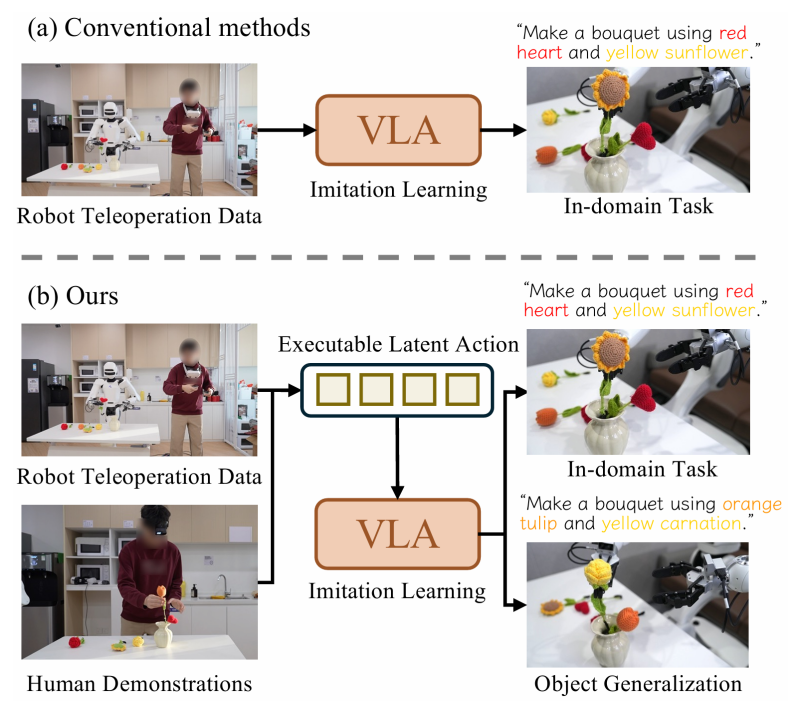
Actions move from the screen into reality

Can robots learn new skills by "watching videos," the way humans do?
Recently, Astribot (星尘智能) teamed up with Tsinghua University, the University of Hong Kong, and MIT to propose the CLAP (Contrastive Latent Action Pretraining) framework — the first approach to directly align motion information from human videos into robot-executable action space, turning massive publicly available videos into usable robot training data. This offers a new solution to the long-standing "data famine" that has plagued the field of robot learning. Read on with Yunqi Capital for the details.
The following content is from Astribot
Recently, Astribot, together with Tsinghua, HKU, and MIT, jointly proposed the Contrastive Latent Action Pretraining (CLAP) framework based on contrastive learning.
This framework aligns the purified motion space from videos with the robot's action space — meaning robots can learn skills directly from videos! Paper: https://arxiv.org/abs/2601.04061
For a long time, robot learning has faced a vexing "data famine" problem: the internet contains hundreds of millions of human behavior videos, yet data specifically for training robots remains scarce. The root of this asymmetry lies in the fact that collecting robot manipulation data requires expensive hardware, specialized operating environments, and extensive human annotation — costly and inefficient. By contrast, human behavior video data is abundant, but due to the vast semantic gap between visual representations and robot action space, traditional methods struggle to effectively leverage these resources.
Existing Latent Action Models attempt to utilize video data, but often fall prey to "visual entanglement" — the models learn more visual noise unrelated to actual manipulation rather than genuine manipulation skills.
The core innovation of the CLAP framework is precisely solving this long-standing technical bottleneck. The framework aligns the purified motion space from videos with the robot's action space, effectively avoiding the "visual entanglement" problem that has been widespread in previous latent action models. Through contrastive learning, CLAP maps state transitions in videos to a quantized, physically executable action codebook.
The research team trained based on two VLA modeling paradigms: first, CLAP-NTP, an autoregressive model that excels at instruction following and object generalization; and second, CLAP-RF, a policy based on Rectified Flow for high-frequency, fine-grained manipulation.
The practical significance of this breakthrough manifests on multiple levels. First, from a data utilization efficiency perspective, the CLAP framework enables robots to learn skills from massive videos on platforms like YouTube and Douyin, vastly expanding the scale of usable training data. Second, from a cost-benefit angle, this "learn from watching" approach significantly lowers the barrier to acquiring robot skills.
Furthermore, the framework addresses a key technical challenge in robot learning — knowledge transfer. Through the Knowledge Matching (KM) regularization strategy, CLAP effectively mitigates catastrophic forgetting during model fine-tuning, ensuring robots don't lose previously mastered capabilities while learning new skills. Extensive experiments show that CLAP significantly outperforms strong baseline methods, enabling skills learned from human videos to effectively transfer to robot execution.
From an industry application perspective, the long-term value of the CLAP framework lies not only in its technical innovation, but in its potential to accelerate robot industrialization. When robots can rapidly master new skills by watching videos, the cost and deployment cycle for enterprises will drop dramatically — potentially speeding up large-scale adoption of robots in service, manufacturing, and other sectors.
CLAP Framework in Detail
The research team constructed a unified Vision-Language-Action (VLA) framework capable of simultaneously leveraging the action precision of robot data and the semantic diversity of large-scale unlabeled human video demonstrations. The framework consists of two interconnected stages:
- **Cross-modal alignment via CLAP: Establishing a shared latent action space that bridges the supervision gap between unlabeled human videos and labeled robot trajectories. This process, Contrastive Latent Action Pretraining (CLAP), "anchors" visual state transitions from human videos into a quantized, physically executable action space.
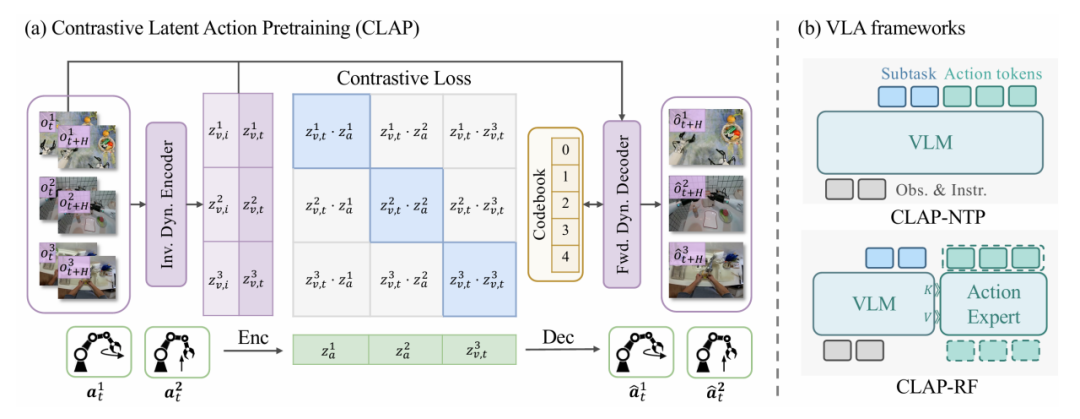
-
**Hierarchical policy training: The research team sequentially trains two VLA models to effectively decouple semantic understanding from control dynamics:
(1) CLAP-NTP: A VLA trained with Next-Token Prediction, adept at instruction following and task planning;
(2) CLAP-RF: Comprising a VLM model and an action expert trained with Rectified Flow, for high-frequency, precise control.
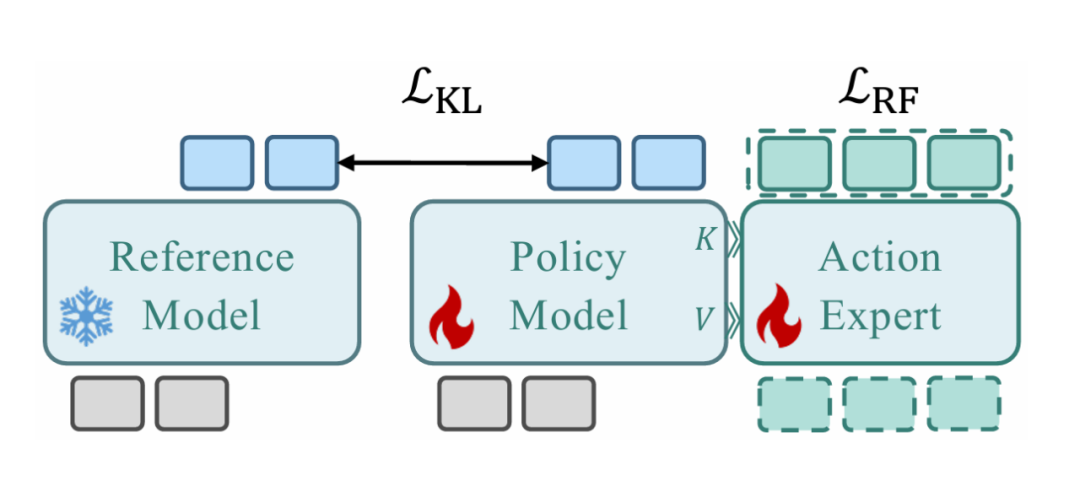
To efficiently adapt to new robot morphologies and prevent catastrophic forgetting of pretrained priors during fine-tuning, the team further proposes Knowledge Matching (KM) fine-tuning: a regularization method that anchors policy updates within a trustworthy region during fine-tuning.
Experimental Results
Extensive experiments demonstrate that CLAP significantly outperforms strong baseline methods, enabling skills learned from human videos to effectively transfer to robot execution.
Table 1 below compares CLAP with baseline methods on real-world tasks under initial settings.
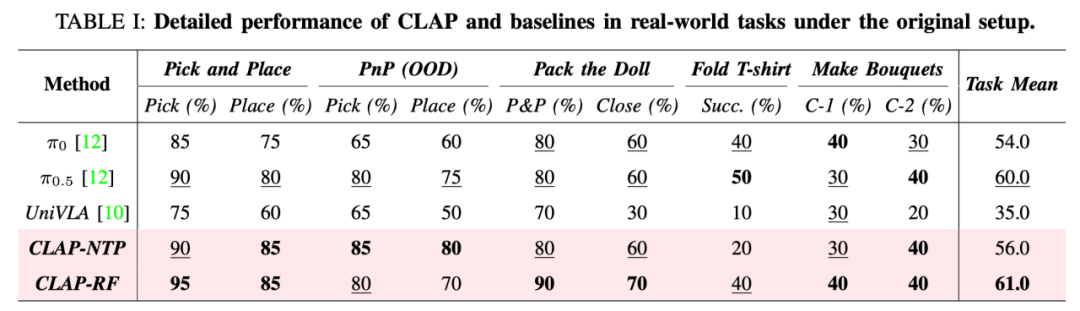
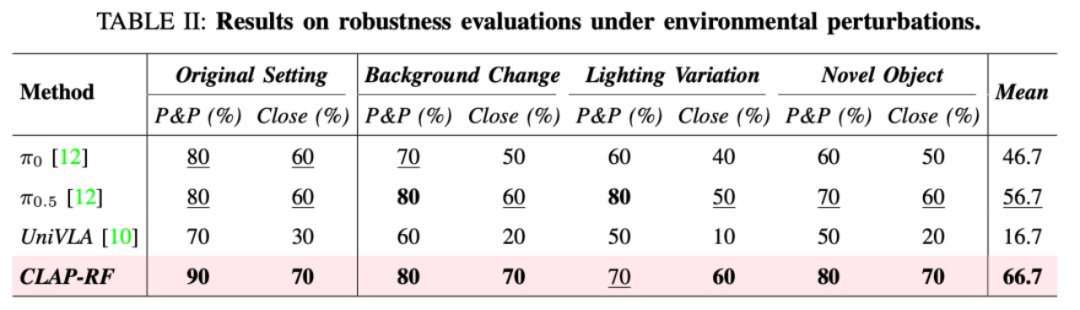
Table 2 below evaluates the robustness of CLAP versus baseline methods under environmental perturbations.
- Paper title: CLAP: Contrastive Latent Action Pretraining for Learning Vision-Language-Action Models from Human Videos
- Paper: https://arxiv.org/abs/2601.04061
- Project page: https://arxiv.org/abs/2601.04061



