Why Open-Source Embodied AI Models? Self-Variable Robotics CTO Wang Hao Explains | Yunqi Capital Doers

The GPT-3 Moment for Robotics Models
Will the "acceleration effect" that open source had on large language models repeat itself in embodied intelligence?
On September 8, Yunqi Capital portfolio company and embodied intelligence innovator X-Bionic Robotics open-sourced its embodied model WALL-OSS. One day later, American embodied intelligence company Physical Intelligence also open-sourced an embodied model. Some analysts believe 2025 marks the entry of embodied open source into a "hundred flowers blooming" phase.
Recently, X-Bionic Robotics CTO Hao Wang appeared on the well-known tech podcast Silicon Valley 101, where he not only explained in depth the thinking behind X-Bionic's open-source embodied model, but also engaged in deep discussion with Physical Intelligence researcher Kay Ke on topics including data costs, evaluation challenges, end-to-end architecture, application scenarios, and the critical signals of a "GPT-3 moment."
In this edition of "Yunqi Doers," we share highlights from Wang's contributions to the program.
This article is excerpted from the WeChat account "Silicon Valley 101"
Original title: Approaching Robotics' GPT-3 Moment: The Accelerating Evolution of Open-Source Embodied Intelligence Models
Interview: Jun Hong | Text and images: Ziqin Wang, Zeping Sun | Editor: Jie Zhu
Industry Breakthroughs and Generalization Capabilities
Jun Hong: What do you think was the most important breakthrough in the robotics model field in 2025?
Hao Wang: This year there's been a very noticeable phenomenon: exponential effects in application. The driving force behind this actually comes from the development and progress of general-purpose robot foundation models.
Before 2023, many of us would focus on a single task and push it to the limit; but now that we have unified foundation models, we can simultaneously learn and execute hundreds or thousands of different tasks. What this means is: our optimization objective has changed, and the emphasis is on improving the model's average success rate across all tasks. This is the foundation for exponential development. We can now start to work on complex long-horizon tasks — tasks comprising a series of sequential steps that require robots to perform multi-step reasoning, planning, and execution before they can be completed. This is a very exciting phenomenon.
Jun Hong: What do you think is the hardest part of the generalization problem in robotics model R&D? Is it because there's too little data, or is it an algorithm problem?
Hao Wang: One difficulty is robustness against long-tail effects in the physical world — for instance, visual errors caused by environmental conditions or lighting. While these long-tail effects can be mitigated through better sensors, stronger compute, and better generative models for data synthesis and augmentation, the real challenge is that the real world contains too many possibilities, and we can't predict all possible corner cases.
So these are situations that machines can't learn in advance. For example, when a robot is executing a task, there might be a small wrinkle in the tablecloth, a cup might be placed unstably, or a transparent object might reflect light that happens to interfere with the camera. Humans can instantly adapt to these minor physical changes through intuition and rich experience, but because algorithms are so data-dependent, AI large models may not handle these new challenges well when they encounter them.
Another difficulty is that in long-horizon tasks, many minor physical disturbances create various small errors that snowball and get amplified. By the tail end, these errors may directly lead to task failure. So what we need to solve is how to get models to handle these various corner cases that can't be contained in the data. The core of this is building a model foundation that can understand physical commonsense and have physical intuition, giving the model spatial understanding and reasoning capabilities.
So the core of this problem is that we need to combine real robot data, human video data, and so on, making the data larger in scale, richer in sources, higher in quality, and more diverse, so that robots can understand physical laws through this learning process. But this high-fidelity data from real-world interaction is currently quite scarce, and obtaining it doesn't simply mean frantically collecting in the real world. This is far more complex than imagined — it's not just a matter of data volume, but also of data engineering and data pipelines, such as how to reduce our data collection costs.
Jun Hong: Earlier I saw that China had robot sports competitions and the first robot exhibition, where robots demonstrated many capabilities like playing soccer, racing, and performing specific tasks. How do you judge whether a robot's technology is good or bad? Can you tell from these demos?
Hao Wang: I think it's quite difficult. This is also a pain point and difficulty that everyone in the embodied intelligence field feels. It's hard to have a unified evaluation standard that allows people to evaluate models at relatively low cost and fairly. The best evaluation is to test in the real world, but it's hard to build a fair arena for that, so this is a difficult area. But I think there are still some ways to evaluate.
For example, we have a batch of open-source models, and people can test them on their own robot platforms to see how much data different models need when learning the same tasks, and the generalization and reasoning capabilities they demonstrate — these can be evaluated. As for different robotics companies, a reasonable and fair approach might be: we apply their robots to specific scenarios and see how different models perform. Because in real-world application, the diversity, generalization, and environment it demonstrates are very random, so it best reflects your model's capabilities.
Data Challenges and Hardware Bottlenecks
Jun Hong: We used to say that becoming a top scholar or expert in a field requires the 10,000-hour rule. I've also observed my baby learning to eat — when she was very small, she couldn't even get the spoon to her mouth accurately, but she practiced every day and gradually learned. But why do robots need vastly more data than humans to train this kind of dexterity?
Hao Wang: Actually, compared to humans, I think it's quite unfair to robots. The core reason is that humans essentially have "pre-training." Throughout the large-scale evolutionary process of the biological world, there are two very core points: first, through evolution, humans have accumulated many previously validated things, such as cognition about interacting with the world and strategies for dealing with the physical world — these are essentially written into our genes. On the other hand, humans are constantly evolving their own hardware. The entire biological world is like this: if something can be solved without "intelligence," then "hardware" is used instead. So many organisms evolve certain structures — for example, E. coli doesn't need eyes; it can adapt to its surroundings with just sensitivity to chemicals and temperature.
What we're doing now is essentially helping robots build their pre-training models. Although it seems like we need to cover the hundreds of millions of years of human evolution, it's actually somewhat different. First, because robots can be mass-replicated, different robots can share their experiences, so we can quickly build robot pre-training models that give them perception and understanding capabilities for the physical world. Of course, this process also involves robots becoming increasingly familiar with their own bodies. As Kay just mentioned, "cross-embodiment generalization" — we're making different robots (models) adapt to different bodies and enabling them to perceive differences between bodies. This is very important.
Second, in human learning, the so-called 10,000-hour theory has many nuances. Humans don't necessarily spend a set amount of time learning one task, finish it, and then move to the next new task. When you start teaching a baby to do something, like picking up an object, he may not have enough precision and can't grasp it accurately, so he'll throw it aside and ignore it, go play with other toys, build blocks, and so on. And after a month, you'll find that for this picking-up task, even though he didn't spend much time learning it, he can already do it. This also shows that in the process of postnatal interaction with the environment, human learning is actually multi-task parallel learning. It can learn from different tasks this underlying, shared physical structure, and this shared physical structure will help reduce the amount of data needed when learning new tasks.
So now when we train robots, we do the same thing. We use as diverse data as possible, covering tasks with various capabilities, to build this large data system and build robot capabilities. Perhaps when learning new tasks, the amount of data needed will be greatly reduced. So when we say robots need millions of hours of data, the core is to solve two problems. First, to cover the pre-training process of human evolution over long periods, we need diverse data to help robots build this foundational capability. Second, when learning new tasks, we also need to leverage the general capabilities formed in previous task learning, enabling it to generalize to new capabilities. So in terms of data and time length, we can't completely analogize with humans, but I think the learning process and the underlying principles may be consistent.
Jun Hong: Do you use much synthetic data now? I know many in the industry use synthetic data. A few weeks ago, Google released the Genie 3 world model, and I heard two different viewpoints: one side thinks Genie 3 is very helpful for robots because this kind of world model data is useful, but the other side thinks the data quality still isn't good enough.
Hao Wang: Currently, the data volumes of leading robotics companies, because of real physical world constraints, are probably concentrated in the range of tens of thousands to hundreds of thousands. But compared to training a language model at the GPT-4 level, this is still much less data. Besides using the most important real-world data and robot data, we also use some other types of data, but every type of data certainly has its own problems. Real robot data is relatively expensive, limited by robot hardware, facilities, operator collection speed, and other factors. So people have developed many improved methods — not only relying on real robot platforms, but also making some low-cost platforms, or even not making complete platforms at all, just having some wearable sensor devices, all of which can be used for collection.
We actually also use many generative models for synthetic data, but synthetic data mainly alleviates some visual and real-world distribution gap issues. It's very difficult to generate data with physical interaction processes — this kind of data still needs to come from real-world collection. There's another type of data: human video data. This is extremely large in scale, very diverse, and relatively low in cost. We've also helped many companies explore in this area. But relying on this data to help robots with action-level generation is still very difficult. What current embodied models learn from video data is still at the level of action intention — from human video, we let models learn some high-level semantic understanding and task planning.
But this kind of planning is learned by machines through video, not language. Including something like Genie 3 — I think it's excellent work — it obtains massive amounts of high-quality data from the internet and gaming environments, so through video generation, it can do some motion control, which is a very promising direction for the future. Although this environment is somewhat simplified compared to reality, it can still serve as a training environment to help you with this kind of interaction. So we still have work to do on the data front. I imagine every company's investment ratio in data is probably different, and this also depends on the company's overall capabilities — operational capacity, hardware level, different plans for data usage — all of which affect your data costs.
Compared to the US, China may have significant differences in hardware costs and labor costs. Even within the same region, operational capabilities, data filtering, cleaning, task generation and distribution, data collection capabilities in different scenarios, and the ability to rapidly set up and restore scenarios — all of these affect data costs.
Hong Jun: So compared to other robotics companies, roughly where does your company's data cost sit?
Wang Hao: This is very difficult to compare across companies, because everyone's requirements for data quality and diversity may differ. But for our company, data definitely accounts for a substantial proportion of overall R&D costs.
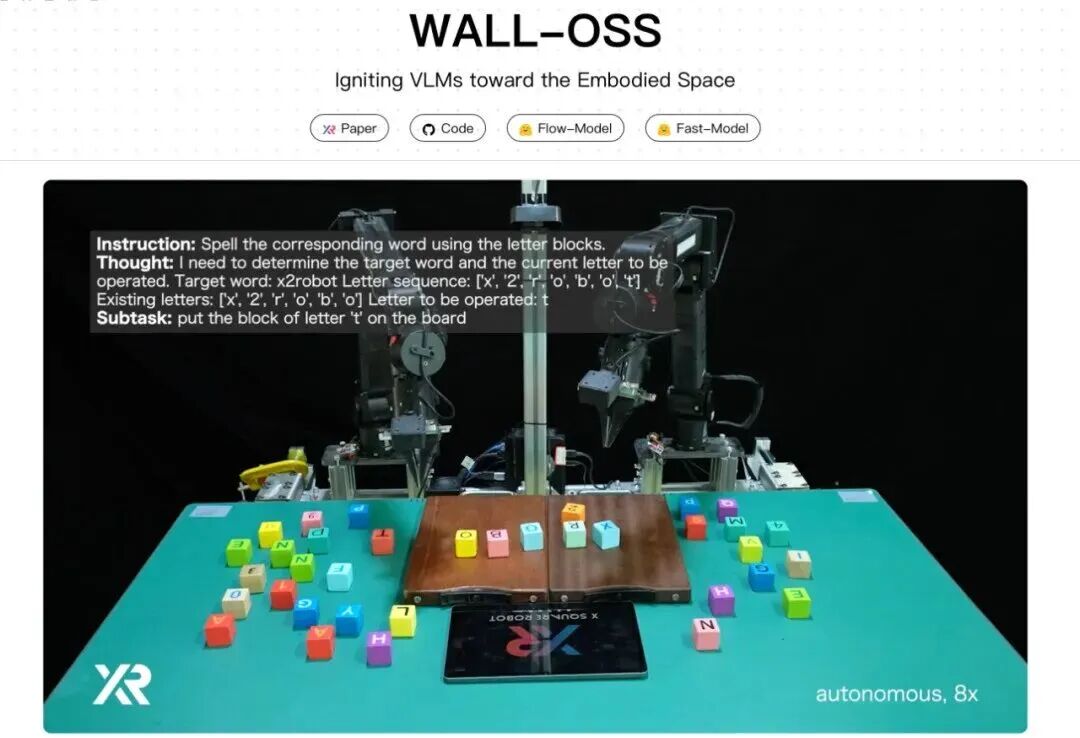
Image source: X-Variable Robotics
Hong Jun: On September 8th of this year, your WALL-OSS open-source model went live. Could you briefly introduce what this open-source model is, and what its industry characteristics are?
Wang Hao: We've been continuously carrying forward the open-source spirit, and have also absorbed a lot of experience. So we used roughly tens of thousands of hours of real-world data to train an embodied foundation model.
Under a unified framework, we made it capable of both chain-of-thought reasoning and action generation. We built upon an already-trained foundation vision-language model and extended it, giving it relatively strong visual understanding, spatial reasoning, multilingual instruction-following capabilities, while also maintaining relatively high action generation precision. These are capabilities we've observed to be relatively lacking in current open-source embodied models. We also hope this open-source release can provide a good supplement to the embodied intelligence industry, allowing everyone to better use our foundation model to tackle some long-horizon tasks and solve complex tasks.
To solve these long-horizon tasks requires better language following, better spatial and causal reasoning. We also hope our end-to-end reasoning, planning plus action execution model can play a role and be put to use by the community.
Hong Jun: So what is the main selling point of your model? I feel like the model players in the industry have quite different directions — some focus on fine manipulation, like Google is very good at origami-type actions, while PI hopes for stronger generalization capabilities. If you had to summarize your advantage in one sentence, what do you think is the point you care most about in robotics?
Wang Hao: What we care most about is robot generalization and its ability to solve long-horizon tasks. Solving long-horizon tasks means it must have relatively strong generalization capabilities, because solving any long-sequence task involves constantly changing scenes behind it. The task may encounter various failure situations, various unseen manipulation objects — all of which require strong generalization.
Hong Jun: For example, what kinds of long and complex problems? Please give an example.

Image source: X-Variable Robotics — WALL-OSS, the open-sourced embodied intelligence foundation model
Wang Hao: Actually, applying robots to any real-world scenario involves long and complex tasks. For example, completely cleaning up a dining table is a long and complex task, because the types of objects you need to manipulate are very diverse: you may have hard objects to manipulate, like utensils; there may be liquids to handle, like pouring food residue and fluids into designated places; you may have many irregular objects to deal with, like trash and leftovers; there are many flexible things to handle, like wiping the table, folding towels, and so on; you may need to put different things in different places, and also be careful about potential spills or other situations.
So in the task of cleaning a dining table, there isn't a fixed execution sequence of what to do first and what to do next. Everything is interleaved within a long-horizon task, with various subtasks woven together. It's actually very difficult for humans to delineate where the boundary of each task lies. This kind of task has to rely on the model to autonomously decide end-to-end, plan in real-time, and completely finish the entire task.
Hong Jun: So in your lab, when evaluating how well robots perform tasks, what does actual training look like?
Wang Hao: While our actual training also includes some other scenarios, it's still mainly focused on home environments, because home environments basically already contain all the tasks that embodied intelligence needs to solve. Things like cleaning the entire dining table, setting tableware, cleaning the entire bathroom, tidying rooms — these are all our training tasks. We've also genuinely seen robots demonstrate improvements in manipulation capabilities and generalization when handling these long-sequence closed-loop tasks, which has really boosted our confidence. We also hope to leverage X-Variable's open-source model to let everyone see the capabilities that current foundation models demonstrate when solving long-horizon tasks in generalized scenarios.
Model Architecture and Technical Approach
Hong Jun: I've noticed that both PI and X-Variable are doing open-source models. Why does everyone want to go open-source? What are the benefits of open-source for the entire ecosystem?
Wang Hao: I've always felt that open-source is extremely important. Open-source means we can stand on the shoulders of giants and continue moving forward. We can make further improvements based on existing achievements. Feedback from community developers also helps open-source companies, which can absorb experience and think more deeply about their technical approach. General universities or smaller enterprises may not have the capability to build foundation models, but if they can use these open-source foundation models, they can build applications and apply them in various directions, enriching the entire ecosystem. This is also a very important thing.
I think AI research is quite different from before large models. In the past, we could see that AI and large model research was very fragmented. Before a real community formed, there might only be two or three people frantically researching an algorithm, with publishing papers as the primary goal, aiming to seize technological initiative. But with communities and the entire open-source system, people care more about how to build up the engineering foundation within an engineering system, and make the community more prosperous. How does an individual contribute to the community? People's honor actually comes from such things. This in turn drives continuous development of open-source model technology. So I think open-source is a very good thing — you can learn new things from it, and you can also see how your work might help others.
Hong Jun: What do people think is the core factor in judging whether a model is good or not? Right now everyone is not only competing on the quality of their collected data, but also there are probably many different technical paths at the model layer — for example, whether to use high-frequency control, whether to use a system 2 + system 1 dual-system architecture? Could you talk about the different technical paths at the model layer, and which approaches you favor?
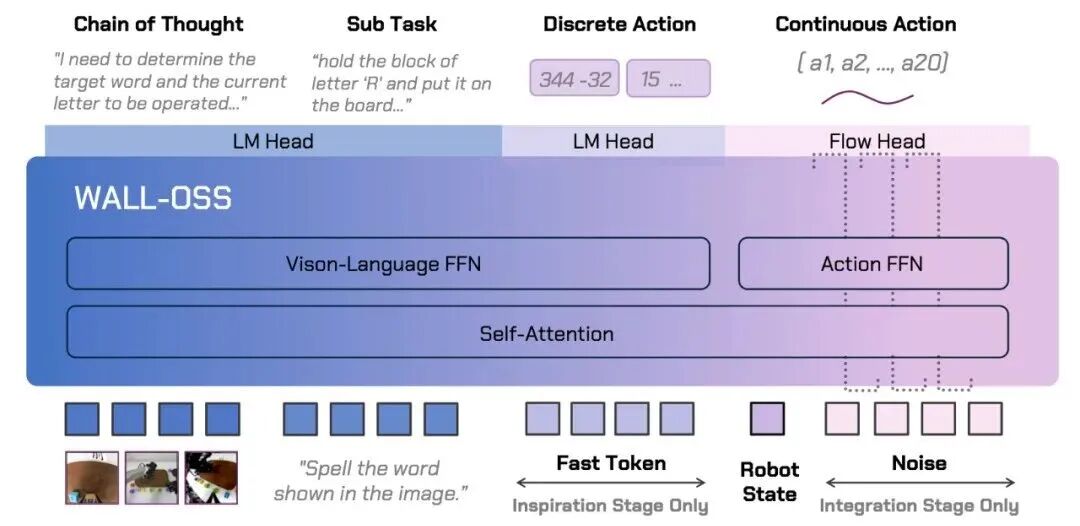
Image source: X-Variable Robotics — WALL-OSS, the open-source embodied intelligence foundation model
Wang Hao: From X-Variable Robotics' perspective, we firmly believe in data-driven end-to-end model construction. Our open-source WALL-OSS model is also built on this architecture. Regardless of how many modalities there are — whether language, vision, or action — they should all be represented and aligned in the same space. Layering is a very unfavorable factor for them, so we should avoid information loss from human-imposed layering as much as possible.
But on the other hand, if you're training end-to-end, the model can be made very large — hundreds of billions or even trillion-parameter matrix models. So what do you do when you actually need to use it? You can't deploy such a large model on the edge side for very high-frequency control. So during inference, we actually think the model can be separated — slower task processes can be handled in the cloud, faster task processes can be placed on the physical edge side, and then gradient backpropagation updates the entire system's parameters. This process is extremely important.
Hong Jun: We're saying that this two-layer model architecture is somewhat similar to the human brain's cerebrum and cerebellum — for example, one layer is responsible for understanding and planning, and another layer is responsible for high-frequency output control, like the cerebrum governing cognition and decision-making, and the cerebellum governing motor control. Why don't you use such an architecture?
Wang Hao: We use an end-to-end training approach. It's very difficult to completely divide certain parameters inside the model into system 2, for example dividing certain systems into fast systems, intuitive systems, and so on. But we can train a very large end-to-end model that can possess very strong embodied general capabilities, where embodied general capabilities include both understanding and reasoning, as well as action generation.
But during actual deployment, there can be many approaches — for example, distilling and compressing the part that's good at action, and placing the part that's good at language reasoning and visual reasoning in the cloud, and so on. Using similar approaches for deployment, doing a lot of optimization during the inference process, but during training it's still a unified architecture.
Hong Jun: Kay feels that robot models overall haven't even reached GPT-2's level yet. Wang Hao, what do you think?
Wang Hao: I think we've reached GPT-2's level. Using this analogy, GPT-1 was basically a proof of concept — through pre-training plus data, it could handle some tasks. But by GPT-2, we started verifying the power of scale — by significantly increasing model parameters and training data, we could demonstrate capability improvements brought by scaling. If we scale up even more, we might reach GPT-3's level, and everyone will see many emergent capabilities emerge. So I would say we're right at the GPT-2 stage right now.
We basically know now: scaling is the only reliable path forward, so at this stage we need to aggressively accumulate data, increase model size, and build out the infrastructure to support embodied intelligence. So saying humanoid robots are currently at the GPT-2 stage is fairly objective.

Image source: WALL-OSS, an open-source embodied intelligence foundation model from X Variable Robot
Hong Jun: How much longer do you think it will take for robotics to reach what you'd define as the GPT-3 moment?
Wang Hao: When we talk about going from GPT-2 to GPT-3 in robotics, there's a difference from how it played out with language models. Back then, people didn't know if this approach would actually work — there was a lot of scattered exploration that eventually converged. Now we clearly know and have seen the improvements that scaling brings, so for us the path and goal are much clearer and more singular. So I predict that within one to two years, we can absolutely reach GPT-3 level.
Hong Jun: One to two years is pretty fast. I've noticed that in the US, when people talk about robots, everyone wants to build general-purpose robots and then work toward a massive large-scale model — if we use autonomous driving as an analogy, the US basically wanted to do L4/L5 from the start. But looking at China's development direction, I feel like there are still many small but refined entrepreneurial approaches. It's similar to how Chinese companies approached autonomous driving: first thinking about whether they could land in a specific scenario like a campus or a port, building a very vertical, small-but-refined industry.
How do you view these two approaches to robotics, and in terms of industry development, how will the end results differ? Which path will work out?
Wang Hao: I think we need to look at this in terms of each country's respective strengths. It's true that the US approach right now is top-down and cost-no-object — they'll prioritize building a massive model close to AGI, and then figure out what to do with it. This is also because of the US advantage in compute: the most advanced chips and the largest compute clusters are in the US, so the path tends more toward using unlimited compute to explore the boundaries of capability.
But China does face certain constraints on chips, which has actually forced Chinese companies to research and think about how to achieve higher efficiency with limited compute. That said, I don't really agree that Chinese companies are taking a small-but-refined technical route.
China actually has the world's largest mobile internet ecosystem and application scenarios — this scenario advantage, plus China's very complete hardware industry chain, is something the US really can't match. There are many top-tier research institutions and excellent startups domestically that are thinking very deeply from first principles, very deeply understanding that Scaling Law is actually the necessary path to AGI.
We firmly believe that you need a powerful, omnipotent foundation model before you can apply that base model to various vertical domains and deploy it more efficiently — but this process can't work in reverse. You need the large and general foundation first before you can have small-but-refined development. In terms of implementation path, China is actually more like a top-bottom combination, dual-track parallel approach: on one hand, consider scenarios as much as possible, especially what generalizable scenarios might offer us; at the same time, iterate our own general foundation model capabilities. Only this way can robots get better real-world feedback faster, help everyone achieve commercial closed loops, and start forming data flywheels.

Image source: X Variable Robot
Hong Jun: So personally, you also want to build general-purpose models?
Wang Hao: Yes, we will definitely build general-purpose models. That's very important.
Commercialization and Landing Prospects
Hong Jun: I see that when people research robots, they all hope robots can help with household chores — folding bedsheets, folding clothes, loading dishes into the dishwasher. Do you think we'll really have household robots that can help with chores in the future? How much longer until we can have this kind of general-purpose robot?
Wang Hao: Doing housework seems simple, but I think it can serve as the perfect Turing test for robots. Because this process contains all the fine manipulation challenges in embodied intelligence robotics — for example, cutting vegetables requires fine force control; handling fragile items requires very rich perception; there's also long-horizon planning, like following a recipe to cook, reading instructions to use an appliance, and handling various unexpected situations. It basically contains all the challenges of robotics.
To fully achieve this level, we still need to take it step by step. I think within two to three years, we can have robots do simple things in semi-structured environments — for example, limited to within a kitchen, helping you make some simple dishes, washing dishes, etc. I think that's doable. But if we're talking about doing everything in a completely open kitchen, I think we'll need about five more years.
Hong Jun: About five years, to have robots cooking and washing dishes in the kitchen?
Wang Hao: Yes, I think it's possible to achieve. But even then there will still be many situations people need to tolerate — for example, although the robot's success rate on various tasks will be relatively high, it won't be 100%, and there will still be possibility of mistakes. So if we allow robots to collaborate with humans and get human help, I think five years is a reasonable timeline for them to enter households.
I'm relatively optimistic right now because I think robotics is on the right development path, with Scaling Law as a pattern for rapid development. Throughout human historical evolution, I consider this very fortunate — because there's a seemingly clear path that tells us what to do: you just invest compute and data, iterate model architecture, improve machine capabilities, and you can visibly see robot improvement.
So although there are many problems that feel very difficult now, looking back from five years later, they can all be solved. And models will definitely cross a threshold and enter a new stage, so I think five years is a very reasonable prediction.
Also regarding this five-year timeline, we need to be somewhat cautious, because robots aren't like pure software that can iterate quickly with light assets. Robots are still constrained by the physical laws of the physical world — hardware needs to develop, and we need all-around breakthroughs in data, algorithms, supply chain, business model, and other factors before we can truly get to that point.
Hong Jun: I have a curious question: some robot companies take "industrialization" as their goal, wanting to do some commercially applicable things. How should these companies balance commercialization and R&D?
Wang Hao: I think this is a good question. Because as a startup, from day one we've been thinking: how can we both reach for the stars and keep our feet on the ground? Due to practical factors, we can't wait until AGI to think about commercialization. Our current strategy is: as much as possible, based on our general model, let it enter some scenarios to do things. These scenarios must be relatively close to the general scenarios we ultimately want to achieve, and they need to be generalizable. So we try as much as possible to avoid closed scenarios.
Scenarios like public services, elderly care services are very good — these scenarios share some similarities with the ultimate application scenarios for general-purpose robots, involving some complex tasks like interacting with people, and also less complex ones like just cleaning, fetching things, handling ingredients, etc. From this perspective, these are good scenarios because they're close to the ultimate goal. In these scenarios, you can continuously iterate and test your general model's capabilities, and also get very valuable data feedback. But to maintain this original intention in selection, one important point is: you need strong resolve in your commercialization path.
Another important point is organizational capability. Because a company's organizational capability and structure determine its ceiling. I think a company must aim for general models, for foundation models, and achieve a completely barrier-free, highly collaborative organization before it can ensure that every step along the way doesn't go wrong, and ultimately enable you to reach your final goal.
Hong Jun: So you pay more attention to whether training scenarios have commercial applications, rather than just being a demand that can be met in a closed scenario. The household scenarios you just mentioned — robots helping us cook, do laundry, fold quilts — can these use cases generate enough sales volume to sustain a robot company?
Wang Hao: I think there's good hope. Because the entire robotics industry scale hasn't taken off yet, so once scale picks up, there's still very large room for hardware cost reduction. As model levels improve and hardware costs decrease, prices in a few years will make user acceptance much higher.
Secondly, from a functionality perspective, if we can help ordinary users do many things, people will be very willing to accept such products. Right now people find robots hard to accept because robots seem to only dance around, provide some emotional companionship value — they don't seem to have other functions. Previously robots didn't have opportunities to demonstrate various applications to ordinary users, but in the future I think there will be many opportunities to demonstrate, and the imagination space is very large.


