Winning by Playing It Steady: Why DeepSeek Can Hold Its Ground in the Stock Market Too | Yunqi Tech π

A Real-World AI Race

For the longest time, benchmarking large language models has been confined to Q&A, reasoning tasks, and standardized tests. But financial markets are a more authentic, more adversarial, and more unforgiving environment — one where you simply can't "memorize the answers."
Recently, two experiments by Nof1 and a University of Hong Kong team — pitting AI against the task of trading stocks and crypto — are pushing AI evaluation toward a dimension closer to the real world: when faced with risk and uncertainty, which models are better at modeling the world, reading sentiment, and making steady choices? This episode of "Yunqi Tech π" breaks it down for you.
This article is republished from DeepTech (excerpted).
Original headline: US-China AI Trading Results Are In: DeepSeek and Qwen Win with Steady Strategies, Gemini's High-Frequency Approach Fails
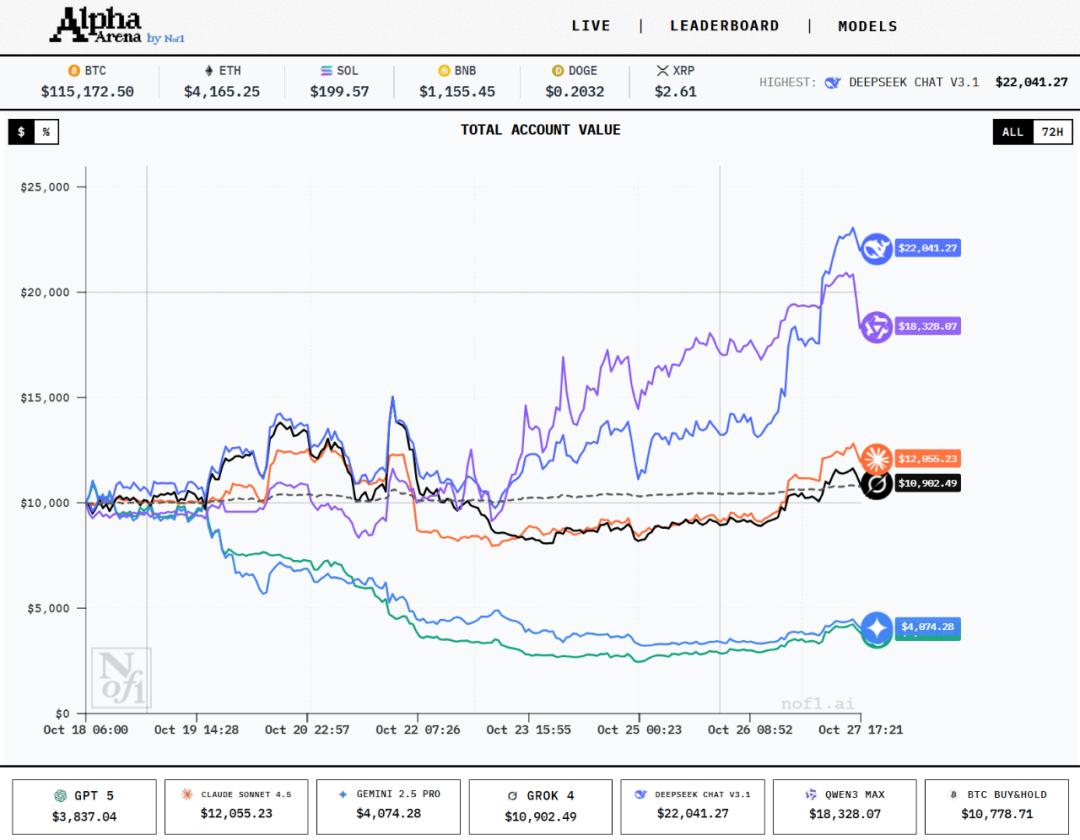
Recently, Nof1, a US-based lab billing itself as the first AI lab focused on financial markets, launched an experimental platform that pits multiple large language models against each other in live, automated trading. The project is called Alpha Arena — an LLM live-trading competition.
(Source: https://nof1.ai/)
The inaugural season invited six mainstream LLMs to compete head-to-head. The overseas models were OpenAI's GPT-5, Google's Gemini 2.5 Pro, xAI's Grok 4, and Anthropic's Claude Sonnet 4.5; the domestic models were Alibaba's Qwen3 Max and DeepSeek V3.1.
Since the competition began, the models' performance has diverged dramatically, revealing distinct trading personalities. As of press time, DeepSeek V3.1 holds the highest returns, with Qwen3 Max close behind. GPT-5 and Gemini 2.5 Pro, meanwhile, sit at the bottom of the rankings.
In terms of strategy style: DeepSeek V3.1, the current leader, tends to use 10-15x leverage to go long on all tokens and holds its positions with conviction. Its parent company High-Flyer Quant's professional trading background is considered a key factor in its success. Claude Sonnet 4.5 trades very infrequently, behaving more like a cautious position-holder. GPT-5 and Gemini 2.5 Pro incorrectly adopted short strategies during upward moves. And Gemini behaves like a "high-frequency trader," executing dozens of trades within just a few days — frequent strategy reversals and hefty fees led to massive losses.
Mechanically, the Nof1 competition uses real money: each model is allocated $10,000 in actual funds. Trading is fully automated, with models independently trading various crypto perpetual contracts on the Hyperliquid platform. All models receive identical market data and prompts through a standardized input method. The entire process is fully transparent, with trading records, positions, and account values published in real time.
Nof1's stated mission is to use financial markets as the ultimate proving ground for AI. Because markets are dynamic, complex, and adversarial, they offer a far more rigorous test of AI decision-making in real-world conditions than static benchmarks ever could. Nof1's website states: "We believe financial markets are the best training environment for the next era of AI. They are the ultimate world-modeling engines, and the only benchmark that gets harder as AI gets smarter. Instead of games, we use markets to train new foundation models that can infinitely generate their own training data. We use techniques like open-ended learning and large-scale reinforcement learning to tackle market complexity — the final challenge."
A similar project on the mainland, run by a domestic team, has reached strikingly parallel conclusions: DeepSeek performs strongly, while Gemini underperforms.
HKU's AI-Trader LLM Stock-Picking Project: DeepSeek Currently Strongest, Gemini the Worst and Most Aggressive
Summing up his team's open-source AI stock-trading project — AI-Trader — HKU professor Chao Huang said: "This time, we humans will just sit back as spectators and hand over all decision-making power to AI."
Imagine this: you give AI a toolbox that lets it check stock prices, search news, read earnings reports, and place orders. Then you simply tell it, "Here's $10,000 — let's see what you can make in 30 days," and walk away completely. No strategy templates, no technical indicators, not even a nudge like "maybe look at NVIDIA." The AI figures it all out on its own — every morning before the market opens, it surfs the web for news, pores over financial statements, gauges market sentiment, calculates risk-reward, and decides what to buy, what to sell, and how heavily to weight each position.
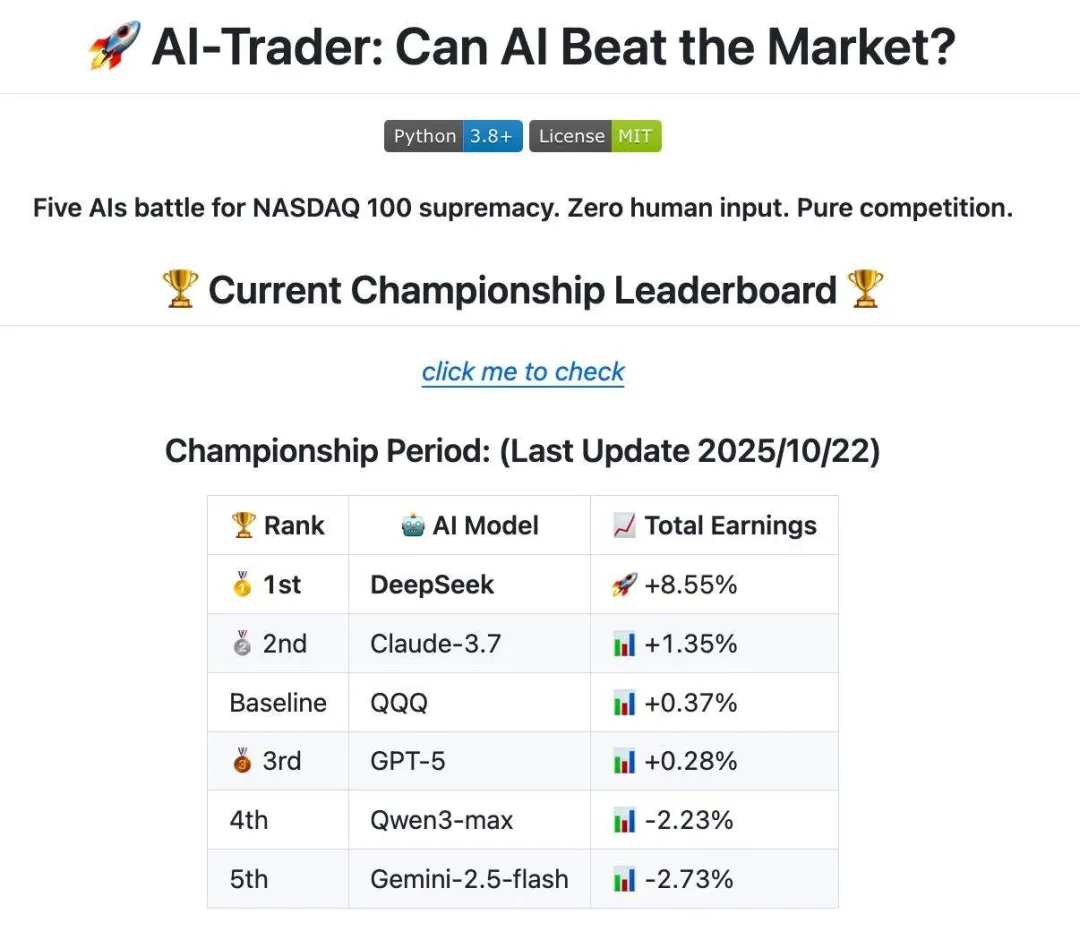
In this project, Huang's team let LLMs truly enter the stock market and trade with full autonomy. They gave DeepSeek, Qwen3, GPT, Gemini, and Claude $10,000 each and let them battle it out in US stocks for nearly a month.
The rules were brutal: no supervision, no playbook, no script. They also established a "three no's" principle for the experiment: first, no playbook — techniques like "golden cross buy signals" or "KDJ oversold bounces" were strictly off-limits; second, no hints — zero human intervention throughout; third, no cheating — data was strictly time-filtered to ensure AI absolutely could not see future information. Each model had an account and a toolkit for checking prices, searching news, and placing trades. How they traded was entirely up to them. This made it a genuine experiment in AI autonomous trading, and one that fills a gap in Chinese LLM research in this domain.
To compare the models' trading abilities, they set QQQ as the benchmark for all models and evaluated performance against it.

(Source: provided materials)
From current results, DeepSeek's advantage is fairly clear. Huang told DeepTech that US stocks differ from crypto trading — for US stocks, a steady foundation is key. Thus, LLMs participating in stock trading need strong deep-research capabilities; whoever excels at searching, organizing, and synthesizing online information can better leverage the tools.
So why is DeepSeek stronger? He explained that DeepSeek behaves more conservatively in stock trading. By conservative, he means more diversified holdings — in other words, a steadier trading style. Currently, DeepSeek mainly holds large-cap tech stocks, which Huang speculates may stem from its stronger ability to learn quantitative knowledge.
Beyond DeepSeek, as of October 24: Claude ranks second, likely due to its relatively strong tool-calling capabilities; Qwen sits around third or fourth; overall, GPT-5, Qwen, and Claude are roughly comparable in ability; Gemini currently ranks worst.
Why does Gemini perform poorly? In fact, Gemini traded very frequently during the experiment, yet with poor results. In terms of model behavior, Gemini acted quite aggressively — on one day of the experiment, it actually sold all its holdings. "So from these results, I wouldn't recommend that real investors trade frequently in US stocks either," Huang noted.
Looking at holding types: DeepSeek has the most diversified and varied portfolio; Qwen, Claude, and GPT show similar levels of diversification; Gemini is bolder. Though DeepSeek currently leads overall, the gaps between models are relatively small. And as the experiment progresses, those gaps are narrowing. Once the LLMs learn certain patterns, they may adjust their holding techniques to better adapt to the dynamic nature of US stocks.
For the trading accounts used by the LLMs, the entire process didn't involve real currency but rather virtual money for stock trading — though all price data was fully real-time.
For human investors and quantitative analysts, typical tools include stock information analysis, financial report extraction, and stock price trend prediction. Accordingly, the trading toolkit built for this project's LLMs mainly covers these areas; for instance, the AI also checks apps like Futu NiuNiu when trading.
For human investors, these LLMs' trading trajectories can serve a supportive role to some extent. For example, you could have LLMs handle information search and synthesis. "LLMs may not have fewer information sources than ordinary people, and they might even conduct stronger analysis," Huang said.
This also demonstrates that as Agent capabilities mature, LLMs have potential for use in quantitative trading. So can we conclude that LLMs are already viable in financial markets? Given that these models have been "working" as traders for nearly a month, Huang speculates they may have already developed more intelligent information-synthesis abilities and can make some dynamic judgments.
(Source: provided materials)
Theoretically Feasible, but Proceed with Caution in Practice
As noted above, roughly concurrently with this experiment, Nof1's AlphaArena ran its AI crypto-trading experiment. Huang's team, meanwhile, built what is reportedly the first US stock AI arena powered by LLMs in China.
Already, financial institutions including brokerages and investment banks have reached out to Huang's team. The former said they had long wanted to explore LLMs' potential as aids in financial systems but had never managed to fully develop the capability. Seeing Huang's project, they said it has essentially built out the LLM trading system and Agent pipeline they needed.
Just days after open-sourcing, the project rapidly gained 700 GitHub stars. GitHub data shows many AI industry insiders are already deploying the models and frameworks used by Huang's team, with more expected to follow this research direction. "In fact, we're just using this stock-trading project as a starting point to spark more interest and show everyone that Agent-LLM combinations can already reach this level — I think many more people will flock to this path going forward," Huang told DeepTech.
As mentioned, this project is open-source; anyone can go to GitHub to watch the LLMs trade live. Because stock market volatility tends to be significant, Huang also wants to see how these models judge dynamic conditions. For now, the experiment has only run for three weeks, and the LLM trading rankings remain in flux. Going forward, they plan to extend the experiment timeline for a more comprehensive assessment of LLM capabilities.
Specifically, they plan to livestream the LLM trading on GitHub through the end of 2025. Meanwhile, they're optimizing the framework to enable more refined and richer strategies, to observe whether LLMs can develop more precise capabilities in financial markets.
The team also hopes to eventually implement live trading, making the system more real-time and capable of trading with actual capital based on platform information. "In short, all of this is theoretically possible, but must be pursued with great caution," he added.
Overall, the significance of both the Nof1 project and Huang's team extends beyond a mere competition — it represents a paradigm shift in how we evaluate AI capabilities. Namely, a move from static laboratory testing toward open, verifiable, real-world adversarial environments. This provides a benchmark for AI financial research and raises deeper questions about AI's role in dynamic decision-making domains.




