Getting the Spatial Intelligence Flywheel Spinning: Manycore Tech Drops Major New Release | Yunqi Capital

**One-sentence space redesign? AI's generative capabilities keep pushing the boundaries of what's imaginable.**

Redesign a space with a single sentence? AI's generative capabilities are continuously pushing the boundaries of what's possible.
At its inaugural Tech Open Day on August 25, Manycore Tech, a Yunqi Capital portfolio company, unveiled new additions to its spatial intelligence family: open-sourcing the 3D scene generation model SpatialGen, announcing the upcoming open-source release of spatial language model SpatialLM 1.5, and sharing for the first time an AI video generation solution based on SpatialGen.
From leading the market in spatial design tools to advancing large models that help AI better enter the physical world, Manycore Tech continues to forge ahead, charting a new course for spatial intelligence. This edition of "Yunqi Capital" brings you the latest updates.
Author: ZeR0 | Source: "Zhidx" (ID: zhidxcom) | Original title: "Another 'Hangzhou Six Little Dragons' Member Goes Open Source! Redesign Spaces with a Sentence, AI Video Generation Agent Coming This Year"
AI can do more than generate articles, images, and videos — it can now generate interactive interior spaces. Simply describe a 3D space in text or upload a floor plan, and AI will create an interactive 3D interior for you.
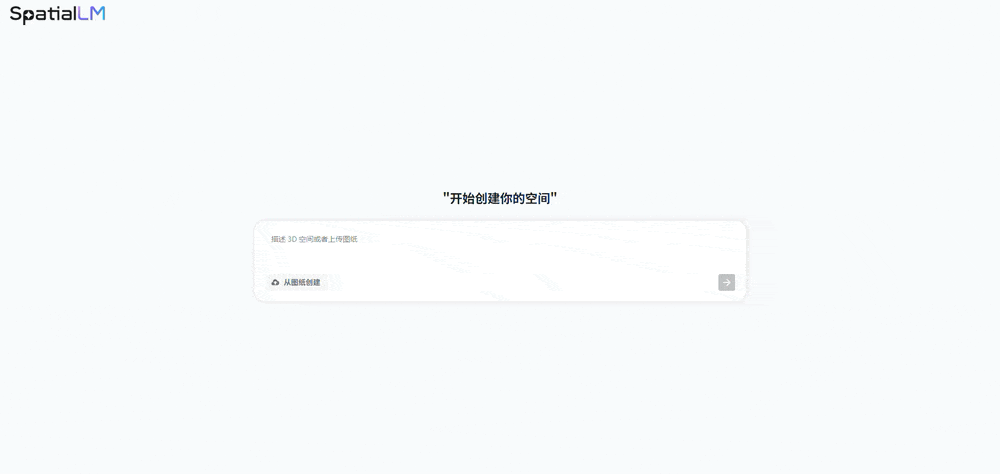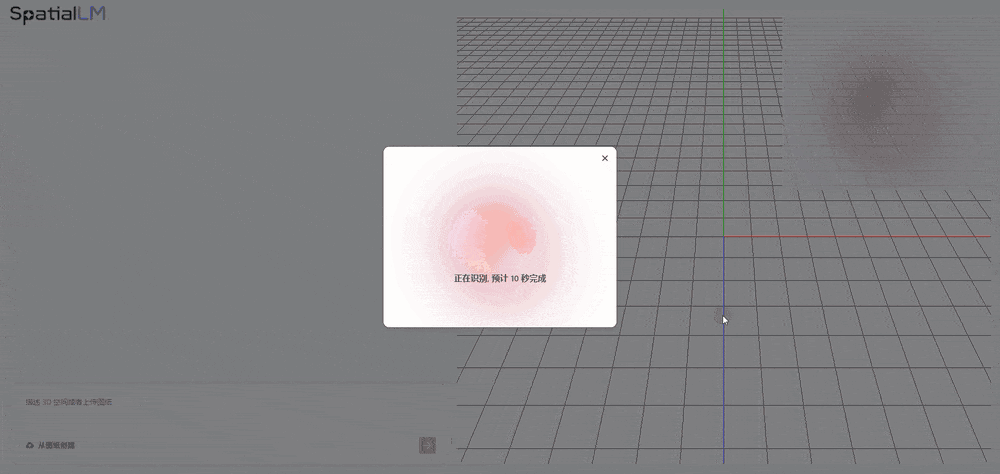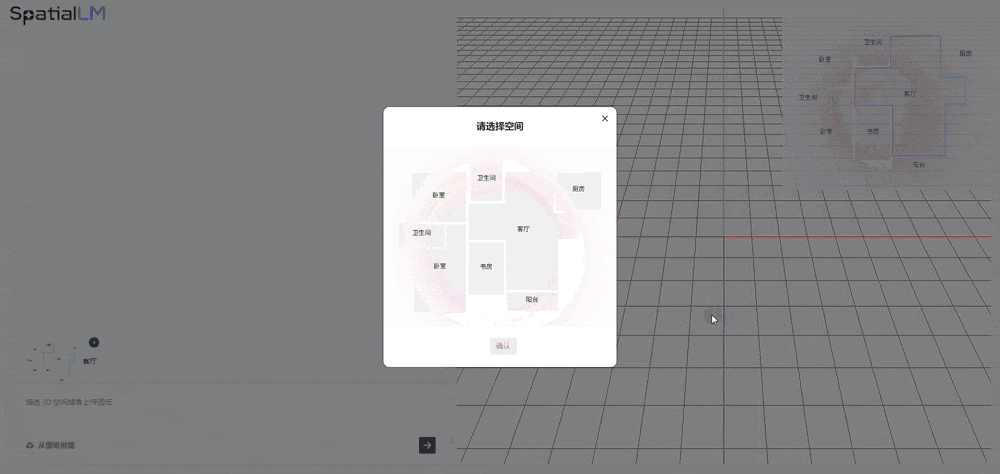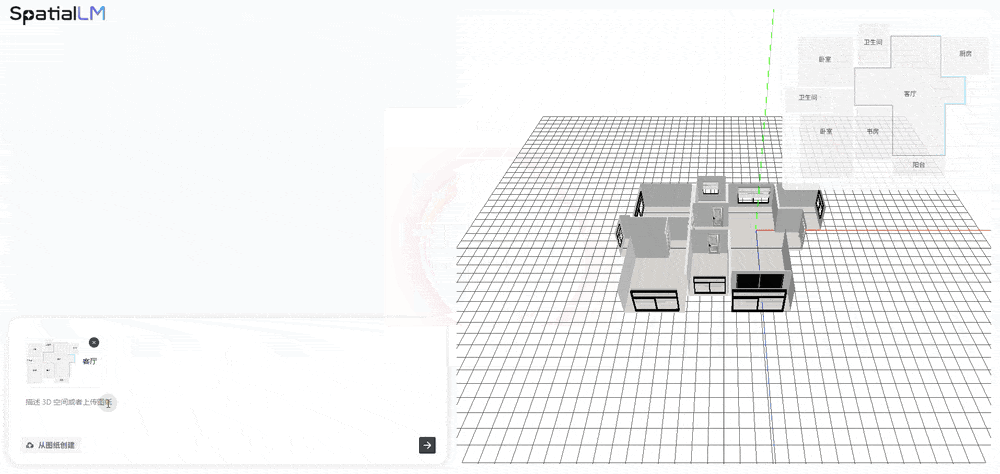
Ask how many doors the living room has, and AI quickly answers "6 doors." You can also raise the difficulty — ask it to generate a living room suitable for elderly residents in a single sentence:
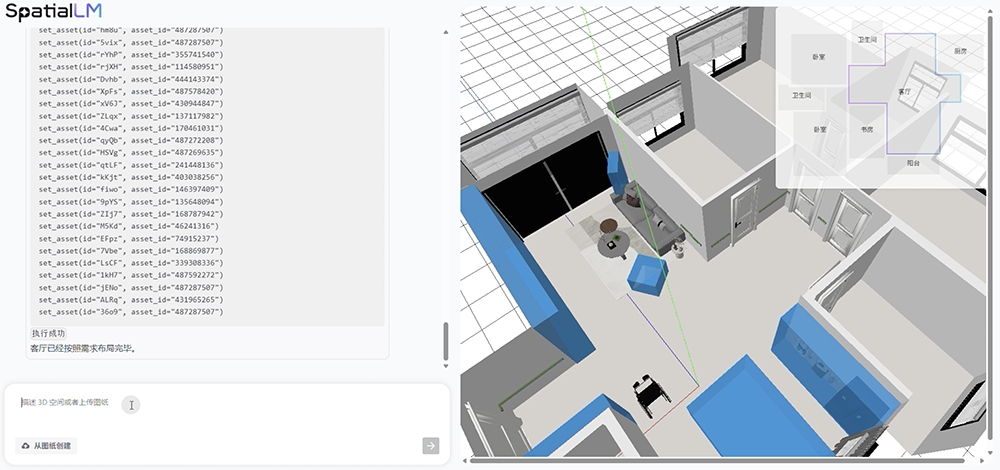
AI recognizes what "elderly-friendly" means — anti-slip handrails, furniture placement — and acts as a virtual interior designer, arranging handrails, tables, chairs, curtains, refrigerators, and floor lamps for you.
You can also request detail changes, like adding some decorative paintings:
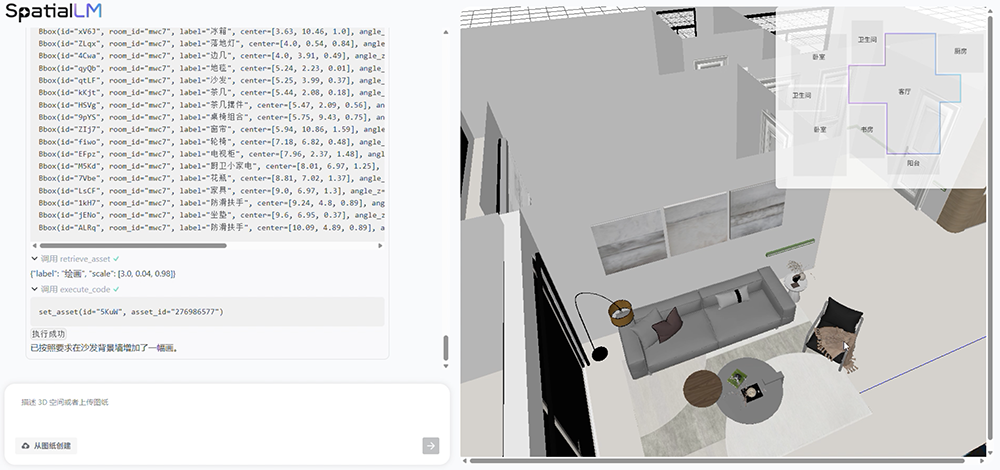
Or make more specific requests. For example, ask AI to generate an elderly-friendly bedroom with a single bed that has handrails, and it will immediately produce a new layout that meets your requirements:
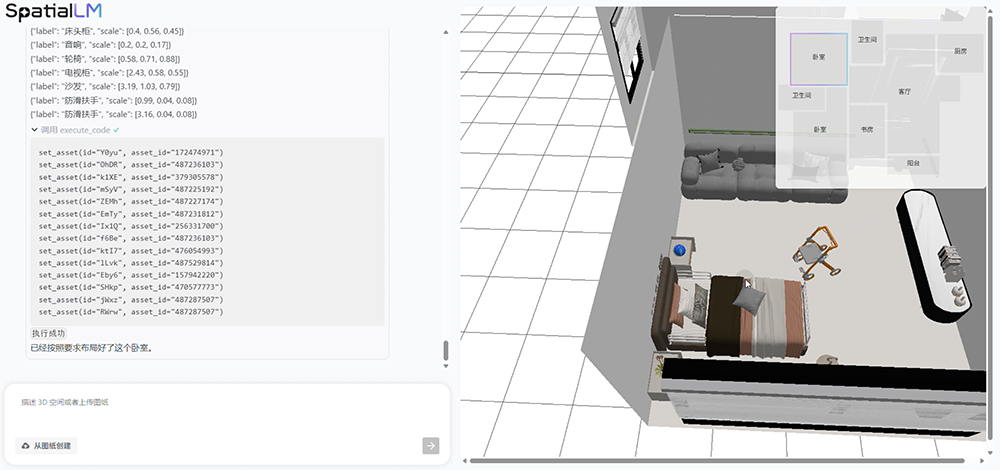
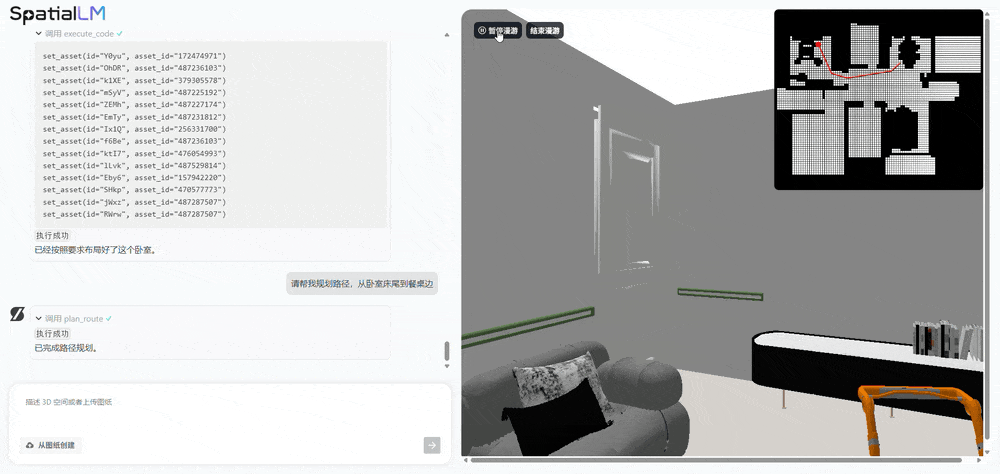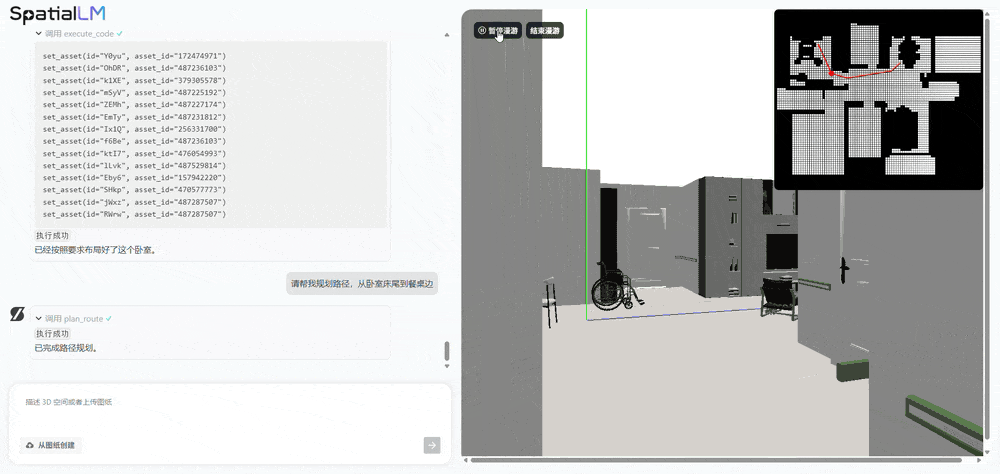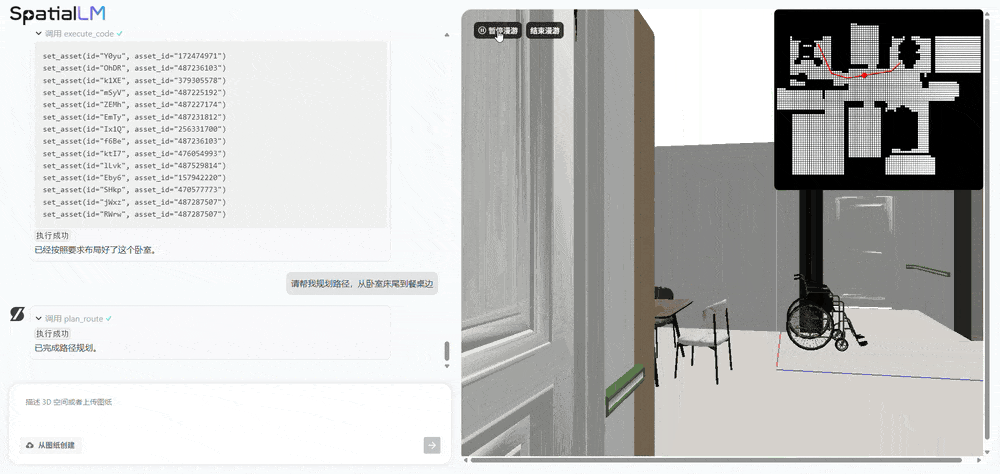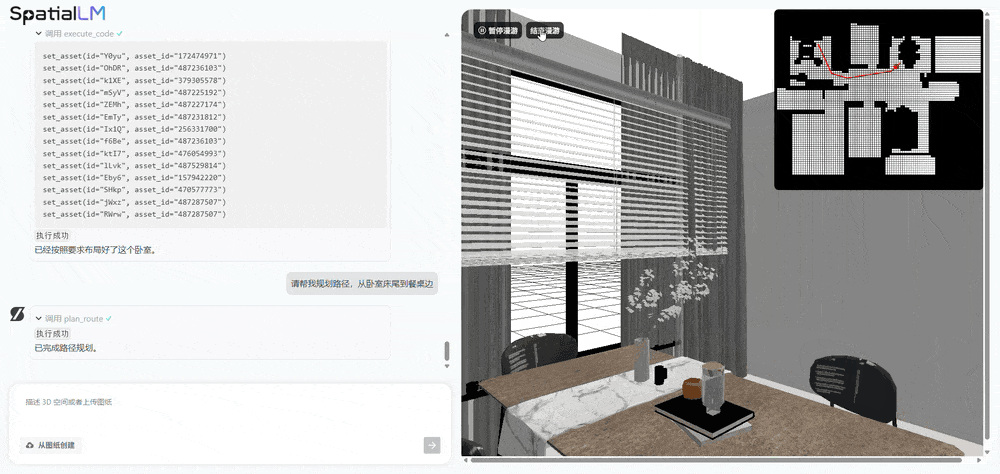
Ask AI to plan a path from the foot of the bedroom bed to the dining table, and it can directly generate a dynamic 3D spatial walkthrough:
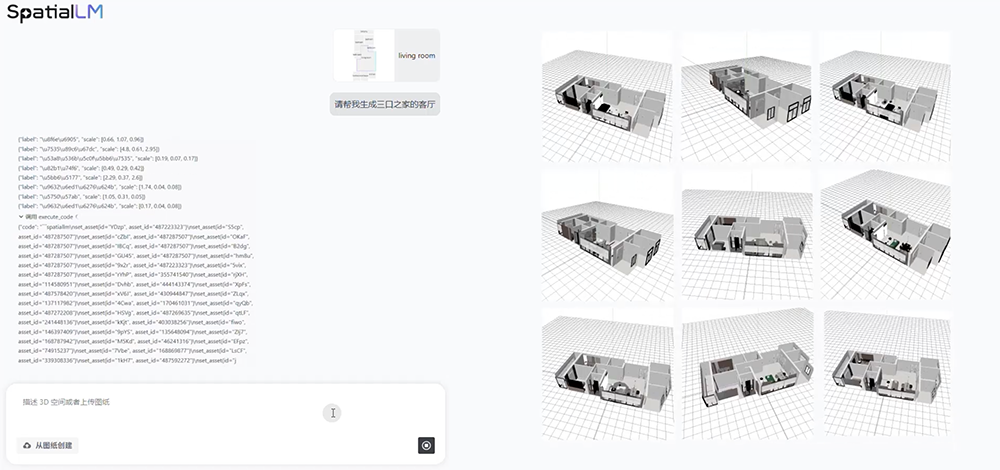
Batch generation is also possible. For example, have AI generate a living room for a family of three, then freely choose from the diverse design drafts it outputs.
By comparison, large language models like GPT-5 show clear limitations in outputting visualizable spatial layouts.
This powerful spatial generation and editing capability comes from SpatialLM 1.5, the spatial language model just released by Manycore Tech — one of the "Hangzhou Six Little Dragons."
Previously, Manycore Tech's flagship product was Kujiale, the world's largest spatial design software. Now, this Hangzhou AI company — racing to become the "first spatial intelligence stock" on the STAR Market — is telling a new story.
At Manycore Tech's inaugural Tech Open Day on August 25, the company announced the open-sourcing of 3D scene generation model SpatialGen, the upcoming open-source release of spatial language model SpatialLM 1.5, and for the first time shared an AI video generation solution based on SpatialGen — aimed at solving spatiotemporal consistency challenges.
Manycore Tech co-founder and chairman Huang Xiaohuang unveiled the company's spatial intelligence panorama.
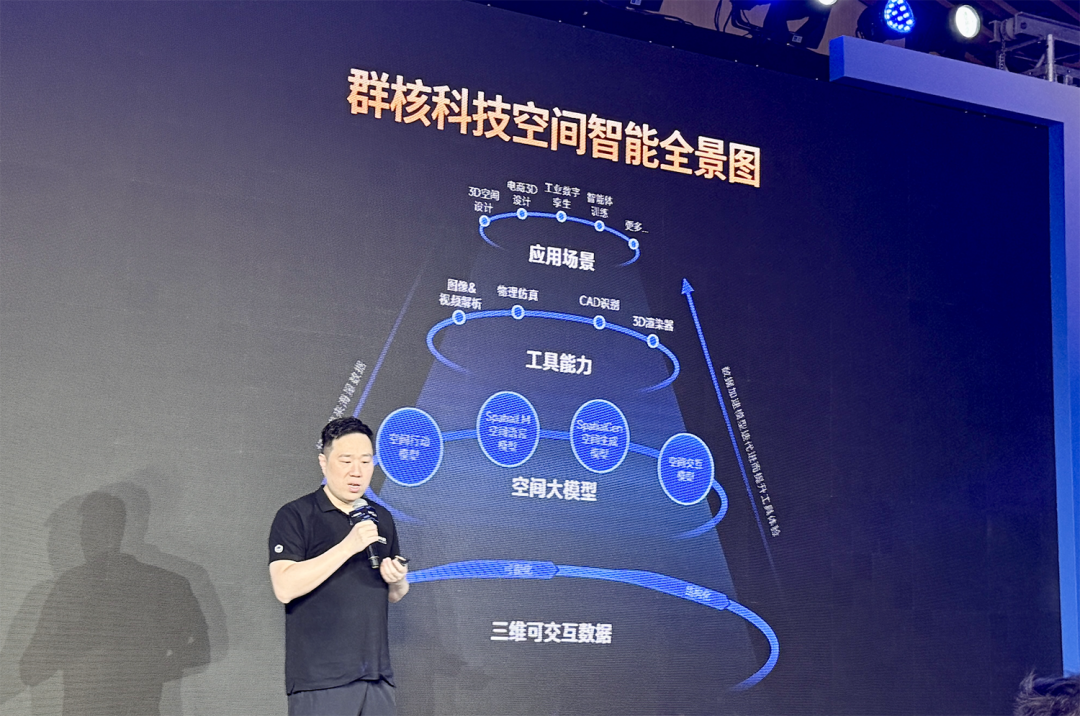
Traditional large language models have limitations in understanding the geometry and spatial relationships of the physical world. SpatialLM 1.5, however, can not only comprehend text instructions but also output "spatial language" containing spatial structure, object relationships, and physical parameters — usable for virtual training of embodied intelligence robots to solve data scarcity problems.
In March this year, SpatialLM 1.5's predecessor, the open-source spatial understanding model SpatialLM 1.0, ranked among the top three on the model trends list of Hugging Face, the world's largest AI open-source platform, alongside DeepSeek-V3-0324 and Qwen2.5-Omni.
SpatialLM 1.5 will soon be open-sourced in the form of spatial language dialogue agent "SpatialLM-Chat."
SpatialGen is already open-sourced on Hugging Face, GitHub, and ModelScope.
Hugging Face: https://huggingface.co/manycore-research/SpatialGen-1.0
GitHub: https://github.com/manycore-research/SpatialGen
ModelScope: https://modelscope.cn/models/manycore-research/SpatialGen-1.0
Manycore Tech AI product director Long Tianze revealed that the company is working on an internal confidential project codenamed X, combining "SpatialGen + AI video creation."
Its AI video generation product based on 3D technology is planned for release this year and could become "the world's first AI video generation agent deeply integrated with 3D capabilities."
He also played a funny video on stage, generated using the tool, showing the three co-founders of Manycore Tech dancing in different scenes.
The video demonstrated several characteristics: precise consistency across more than ten shots, no broken movements, accurate beat-matching, reasonable content under complex camera movements, and controllable content.
Long said Manycore Tech's vision is to enable anyone with creative ideas who wants to visualize them to unleash their creativity using AI 3D+ video products.
After the event, Manycore Tech chief scientist Zhou Zihan further explained the technical details and characteristics of Manycore's spatial large models in detail.
01. Launching the Spatial Intelligence Flywheel Strategy, Moving Toward the "DeepSeek Moment" for Spatial Large Models
Current AI remains largely confined to two-dimensional interaction domains like text and images, capable of tasks such as writing and drawing. But achieving three-dimensional spatial operations like household assistance still requires considerable progress.
Manycore Tech co-founder and chairman shared the company's latest thinking on spatial intelligence layout.
Huang noted that spatial intelligence is the critical bridge for AI to move from the digital world to the physical world. Current spatial large models still face three major technical challenges: indoor spatial data is harder to acquire than outdoor data, spatial structural complexity is high, and interaction demands in scenarios like embodied intelligence are more stringent.
Based on Kujiale, the world's largest spatial design platform, Manycore Tech has built a "spatial intelligence flywheel" of "spatial editing tools — spatial synthetic data — spatial large models," where tools accumulate data, data accelerates model training, models enhance tool experience, and widespread tool use in turn accumulates richer scenario data.

As of June 30, 2025, Manycore Tech's assets include over 441 million 3D models and over 500 million structured 3D spatial scenes.
Manycore Tech began open-sourcing in 2018, gradually opening up its data and algorithm capabilities.
"Open source is one of our important strategic keywords," Huang said. "Compared to large language models, spatial large models are still in their early stages. We hope to accelerate global spatial intelligence technology through open source, become a global spatial intelligence service provider, and help bring about the 'DeepSeek moment' for spatial large models as soon as possible."
02. How Are Spatial Large Models Different from Video Models and World Models?
According to the company, Manycore's spatial large model is the industry's first large model focused on 3D indoor scene cognition and generation, trained on large-scale, high-quality 3D scene data. With world model research proliferating in recent years, what distinguishes spatial large models from world models and video models? Manycore Tech chief scientist Zhou Zihan offered an explanation.
Video generation models and world models face two major challenges: spatial consistency and viewpoint flexibility. Video generation models like Sora and Genie3 can reproduce seemingly rich visual effects, but still fall short in visual consistency and controllability.
3D scene models like World Labs and Hunyuan 3D world models can guarantee viewpoint consistency but suffer from limited viewpoint flexibility. Moreover, these models are typically trained on game data, making it difficult to achieve true realism.
Compared to world models, Manycore Tech's spatial large model has three core advantages: photorealistic holographic roaming, structured interactivity, and complex indoor spatial scene generation capability.
(1) Photorealistic holographic roaming scenes: Due to the scarcity of open-source 3D scene data, existing work is algorithmically constrained, typically distilling 2D generation models and resulting in insufficient visual realism. Based on the Manycore dataset, we designed and trained scene-oriented multi-view diffusion models to generate high-quality images.
(2) Structured interactivity: Can generate scene language rich with physical parameter information including spatial structure and spatial relationships. Compared to traditional large language models, it can precisely parse spatial layouts and object relationships, support parametric scene generation and editing, and provide necessary scene interactivity information for tasks like robot path planning.
(3) Complex indoor spatial processing capability: As the world's largest spatial design platform, it has accumulated hundreds of millions of 3D models and spatial scene assets. Its InteriorNet also became the world's largest indoor spatial deep learning dataset at the time. Manycore's advantage in indoor spatial data enables its spatial large model to handle more complex in-scene generation and interaction.

Thanks to these advantages, Manycore's spatial large model can handle more complex in-scene generation and interaction, precisely parse spatial layouts and object relationships, and support parametric scene generation and editing — providing necessary scene interactivity information for tasks like robot path planning.
Currently, the model has open-sourced two core sub-models: the spatial language model SpatialLM (structured interactivity) and the spatial generation model SpatialGen (photorealistic holographic roaming).

03. Spatial Language Model SpatialLM 1.5: Generate Structured 3D Scenes from a Single Sentence, Solving Robot Training Data Scarcity
The newly released SpatialLM 1.5 is a spatial language model trained on large language models, supporting end-to-end generation of interactive scenes through the conversational interaction system SpatialLM-Chat.
SpatialLM 1.5 can not only understand text instructions but also output "spatial language" containing spatial structure, object relationships, and physical parameters. For example, with simple text descriptions, SpatialLM 1.5 can generate structured scene scripts, intelligently match furniture models, and complete layouts. It also supports Q&A or editing of existing scenes through natural language.
Its core technical approach builds on GPT and other large language models (LLMs), constructing an enhanced model by integrating 3D spatial description language capabilities — enabling it to both understand natural language and comprehend, reason about, and edit indoor scenes in structured ways similar to programming languages (like Python). According to Zhou Zihan, SpatialLM 1.5 uses Qwen as its base model, with additional spatial data training. DeepSeek wasn't chosen because an extremely large base model wasn't needed — what was required was a "small but beautiful" model.
Because SpatialLM 1.5 generates scenes rich with physically correct structured information, and can rapidly batch-output large quantities of diverse scenes meeting requirements, it can be used for robot path planning, obstacle avoidance training, and task execution scenarios — effectively solving the current "data scarcity" problem in robot training.
Leveraging SpatialLM's spatial parametric generation capability, embodied intelligent robot training scenes with physical accuracy can be efficiently created: first generating structured spatial plans based on natural language descriptions, then automatically matching asset libraries to build 3D environments, and finally outputting interactive scenes for robot path simulation.

On stage, Zhou demonstrated an application in robot eldercare scenarios. When given the instruction "go to the living room dining table to get medicine," the model not only understood the relevant objects but also called tools to automatically plan the optimal action path — demonstrating robots' potential to execute tasks in complex home environments.
04. Multi-View Image Generation Model SpatialGen: Solving Spatiotemporal Consistency, Building Freely Roamable 3D Worlds
While SpatialLM solves "understanding and interaction" problems, SpatialGen focuses on "generation and presentation."
SpatialGen is a multi-view image generation model based on diffusion model architecture. It can generate spatiotemporally consistent multi-view images from text descriptions, reference images, and 3D spatial layouts, and supports further derivation of 3D Gaussian Splatting (3DGS) scenes and rendering of roaming videos.
The model draws on Manycore Tech's massive indoor 3D scene data and multi-view diffusion model technology. Its generated multi-view images ensure that the same object maintains accurate spatial attributes and physical relationships across different camera angles.
Based on 3DGS scenes and photorealistic holographic roaming videos generated by SpatialGen, users can freely move through generated scenes as if in real space, gaining an immersive experience.

By comparison, other open-source video models generate hallucinations during movement.

SpatialGen has three core technical advantages:
(1) Large-scale, high-quality training dataset: Due to scarce open-source 3D scene data, existing work is algorithmically constrained, typically distilling 2D generation models and resulting in insufficient visual realism. Based on the Manycore dataset, Manycore Tech designed and trained scene-oriented multi-view diffusion models to generate high-quality images.

(2) Flexible viewpoint selection: Existing methods based on panoramic image generation have poor 3D scene completeness; those based on video base models cannot support camera movement control. SpatialGen has advantages in this regard.

(3) Parametric layout controllable generation: Based on parametric layout generation, it can support richer structured scene information control in the future.

Its workflow is: given a 3D spatial layout, first sample multiple camera viewpoints in space, then based on each viewpoint convert the 3D layout into corresponding 2D semantic maps and depth maps.

Together with text and reference images, these pass through a multi-view diffusion model to generate RGB images for each viewpoint, as well as semantic maps and depth maps (projections of floor plans, furniture objects, etc. from the camera viewpoint). Finally, 3DGS of the scene is obtained through reconstruction algorithms.

Manycore Tech found that based on SpatialGen's capabilities, it can rapidly compensate for spatial consistency problems that existing video generation capabilities cannot solve.
For example, with some video generation models, object shapes and spatial relationships cannot remain stable and coherent across multiple frames. AIGC usable for commercial short drama creation requires not only that each frame "looks reasonable," but that the entire video sequence "reasonably exists" in space like the real world.
05. Deep 3D Capability Integration, First AI Video Generation Agent Releasing This Year
Manycore Tech is developing an AI video generation product based on 3D technology, planned for release this year.
"This could be the world's first AI video generation agent deeply integrated with 3D capabilities," revealed Manycore Tech AI product director Long Tianze.
By building an integrated generation pipeline combining 3D rendering and video enhancement, the product is expected to significantly compensate for the current deficiency in spatiotemporal consistency in AIGC video generation.
Spatial consistency means that during video generation, object shapes and spatial relationships remain stable and coherent across multiple frames.
According to Long, spatial consistency is fundamental for humans but difficult for AI.
In current AI video creation, viewpoint switching often causes object position shifts, spatial logic confusion, and occlusion errors. The underlying reason is that most video generation models are trained on 2D image or video data, lacking understanding and reasoning capability for 3D spatial structure and physical laws. Images lack the depth cues humans rely on for spatial perception, making it difficult for AI to establish precise spatial relationship cognition from natural language alone.
Based on SpatialGen's spatial generation capability, Manycore Tech has built an efficient and user-friendly spatial video creation tool that allows AI video generation to bypass the "spatiotemporal consistency" trap, naturally possessing spatial logic and truly understanding the rules and intrinsic logic of 3D spatial operation.

Manycore builds controllable video generation through a "trinity" approach:
(1) SpatialGen: Provides powerful understanding and generation capabilities, enabling low-threshold acquisition of highly realistic 3D scenes. Users need only provide simple inputs, and the tool intelligently generates 3D objects, spatial relationships, and motion trajectories that conform to real physical laws and specific user requirements. It provides a high-quality, structured, reliable 3D information foundation for subsequent video generation models.
(2) Self-developed rendering engine: Manycore Tech's self-developed KooEngine uses ray tracing rendering technology to precisely simulate the physical trajectory of every ray of light, rendering 3D spaces and objects. Their texture, lighting, and atmosphere infinitely approach human visual observation in real life. This physically grounded realism provides AI models with reference data highly consistent with human visual cognition.
(3) DiT architecture AI video generation model: Combines the advantages of diffusion models in high-quality image generation with Transformer models' powerful capability in capturing long-sequence dependencies and complex spatiotemporal dynamics, enhancing video effect richness and diversity. Combined with user instructions, the model can flexibly generate creative video segments meeting requirements while guaranteeing spatial consistency, further depicting rich variations not present in 3D scenes (like twinkling stars, rippling water surfaces).
Future AI video creation tools could be applied to e-commerce, advertising, product demonstrations, and even short video and short drama creation.
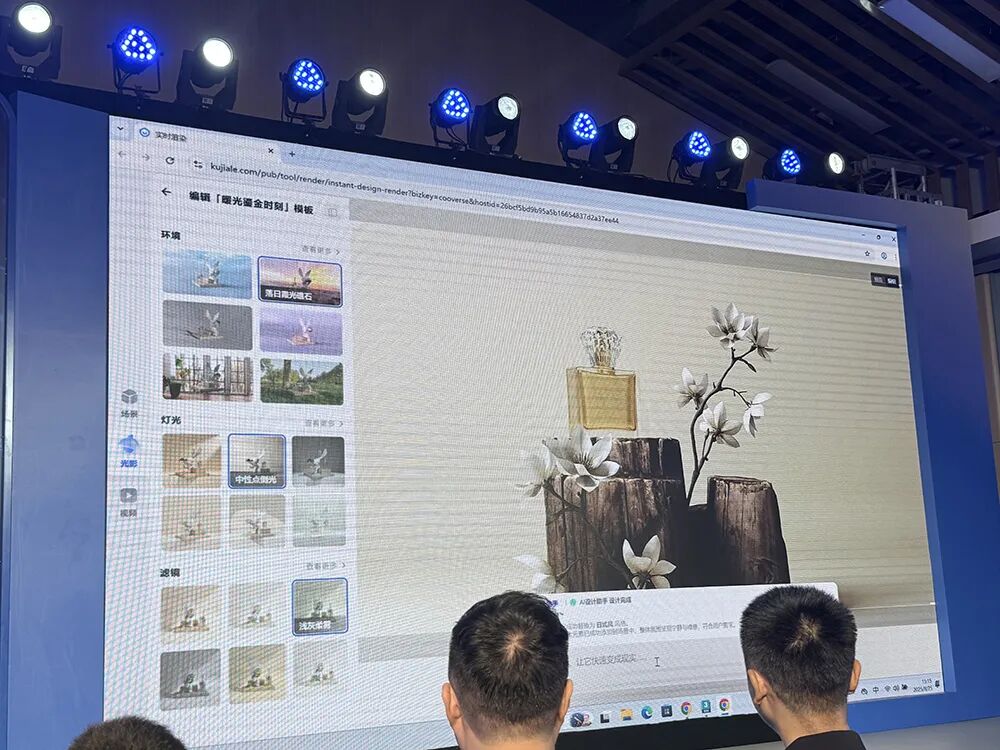
Long demonstrated a Kujiale rendering tool page on stage. The left side provides three categories of templates — scene, lighting, and video — which users can directly click, or choose the "AI Design Assistant" below, input requirements in the chat box, and it will perform rapid inference, then automatically call up corresponding templates matching the requirements.
06. Conclusion: Pushing AI Toward the Physical World
The Manycore Tech team believes that current spatial large models are at the GPT-2 to GPT-3 stage, and the "ChatGPT era for spatial large models" is still far from arriving.
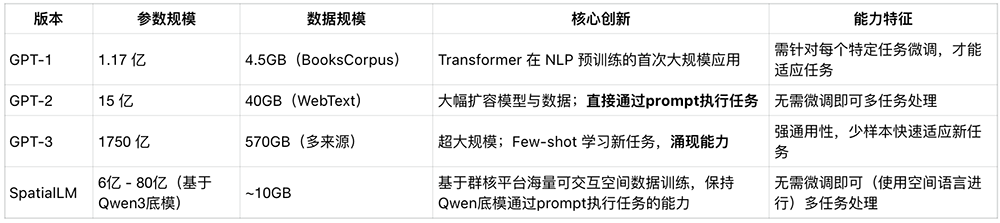
GPT-2's core was natural language modeling, first proposing the use of different prompts to describe different tasks. SpatialLM's core is spatial language modeling, training the model to use spatial language to complete different tasks based on input prompts.
Manycore Tech hopes that the capabilities it provides can help fill some gaps globally and contribute to the march toward AGI.





