Google vs. GPT-4o: What Should We Care About? | Yunqi Capital "Future Scope"

The race for native multimodal large models is heating up
The boundaries of large model capabilities keep expanding.
In the early hours of May 14 Beijing time, OpenAI unveiled its new model GPT-4o. Focused on end-to-end multimodality and cross-modal reasoning across voice, text, and vision, GPT-4o stunned audiences during its brief 26-minute launch event with human-like video conversations and real-time translation.
Yunqi Capital, which has long been immersed in AI, held discussions on the day of GPT-4o's release. Our take:
➤ Ultra-fast and ultra-cheap pricing, emotionally expressive real-time voice interaction, and real-time video interaction were GPT-4o's three most eye-catching highlights. These capabilities stem from GPT-4o's algorithmic unification at the model level — discrete steps like ASR (automatic speech recognition) and TTS (text-to-speech) were merged into one.
➤ However, GPT-4o's actual model improvements were limited in scope. This update felt more like application-focused innovation within existing technical constraints, reflecting OpenAI's product-thinking mindset. At the same time, the iteration of end-to-end native multimodal large models represented by GPT-4o will open up greater imaginative space for application-layer innovation.
Just one day after GPT-4o's debut, Google fired back. At Google I/O 2024, held in the early hours of May 15 Beijing time, the company announced major updates to multiple AI products, directly challenging OpenAI. How innovative was Google's "AI full-stack" offering? This edition of Yunqi Capital's "Future Scope" breaks it down.
Source: Founder Park
Original title: Google I/O Mentioned AI 121 Times — What Products Did It Launch to Counter OpenAI?
In the early hours of May 15 Beijing time, the day after OpenAI's spring launch event, Google I/O 2024 kicked off. It was an AI-saturated conference, with Google announcing major updates across its AI product lineup — from the foundational Gemini model to the new AI assistant Astra, the new text-to-video model Veo, and the more powerful text-to-image model Imagen 3.
And finally, Google decided to AI-ify Search. It redesigned how search results appear and will soon roll out AI Overviews to users in the US.
1
Gemini Updates: Longer Context,
Lightweight Version, Personalized Bots
First, Gemini 1.5 Pro. Its 1 million token long-context capability is now available in AI Studio, open to all developers.
Gemini 1.5 Pro is also coming to Google Workspace, where users can leverage AI for email summarization or PDF text analysis — for instance, searching across all emails and displaying summaries to speed up inbox processing.

The biggest update is still to come — Google announced it will double the model's existing context window later this year, reaching 2 million tokens. This will enable processing of 2 hours of video, 22 hours of audio, over 60,000 lines of code, or more than 1.4 million words — twice the context length of Claude 3.
Beyond longer context windows, Google stated that Gemini 1.5 Pro has been "enhanced" over the past months through algorithmic improvements. It now performs better at code generation, logical reasoning and planning, multi-turn conversations, and audio and image understanding. In the Gemini API and AI Studio, 1.5 Pro can now reason across audio, in addition to images and video, and can be "steered" through a feature called system instructions.
For Gemini subscribers, Google introduced "Gems" — a feature for creating different kinds of chatbots, similar to making bots on Character.AI, a service that lets users chat with AI versions of popular characters, celebrities, or even AI doctors. Google said users can turn Gemini into a workout partner, chef, coding buddy, creative writing guide, or anything else they can imagine.
Gems is somewhat analogous to OpenAI's GPT Store.
Lightweight Gemini: Gemini 1.5 Flash
Possibly for cost considerations, Google released a new lightweight model alongside the existing Nano, Pro, and Ultra tiers: Gemini 1.5 Flash, giving developers more options.

This is a streamlined version of Pro — cheaper and lighter, but equally capable. Google achieved this through "distillation," transferring the most essential knowledge and capabilities from Gemini 1.5 Pro to a smaller model. This means Gemini 1.5 Flash gets the same multimodal features as Pro (analyzing audio, video, and images) and the same length of context window.
Google claims Flash is suited for tasks like summarization, chat, image analysis, video captioning, and extracting data from long documents and tables. It's currently available to developers via API; the Flash model is not offered to general consumers.
Staff detailed pricing for Gemini 1.5 Pro and Flash. Gemini 1.5 Flash is priced at 35 cents per 1 million tokens — far cheaper than GPT-4o's $5 per 1 million tokens.

Some other AI-powered application updates:
-
Ask Photos with Gemini: In Google Photos, users can search images using conversational queries like "the best photo from every national park I've visited." Currently prioritized for One subscribers.
-
Desktop Chrome with built-in Gemini Nano: Starting with Chrome 126, Gemini Nano will be directly integrated into the desktop version of Chrome, with subsequent API rollouts enabling features like translation, captions, and text transcription.
-
Gemini Advanced based on Gemini 1.5 Pro: The upgraded Gemini Advanced can process "multiple large documents totaling up to 1,500 pages, or summarize 100 emails." It supports 35+ languages and 150+ countries and regions. An "upcoming" feature will enable processing "an hour of video content or over 30,000 lines of code."
Open-source Model Gemma 2 Coming in June
Gemma is Google's family of open models, built with the same technology as Gemini models. This time, Google announced Gemma 2 on top of the existing models. Gemma 2 features a new architecture designed for breakthrough performance and efficiency, and will be offered in a 27B parameter size.

Currently available is PaliGemma, billed as the first vision LLM in the Gemma family. Reportedly, PaliGemma was inspired by Google's PaLI-3 and handles image captioning, visual question answering, and object recognition.
2
Finally Taking on Search: AI Overviews
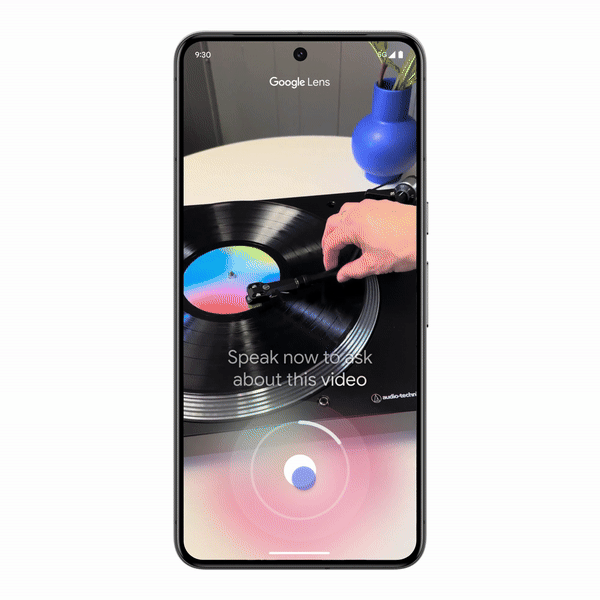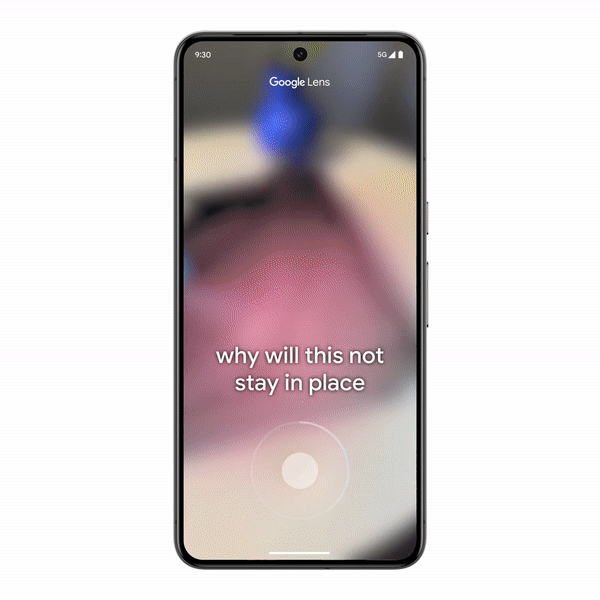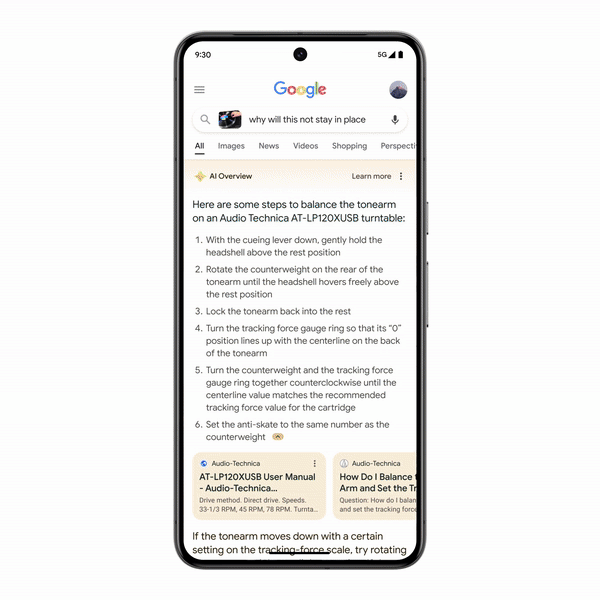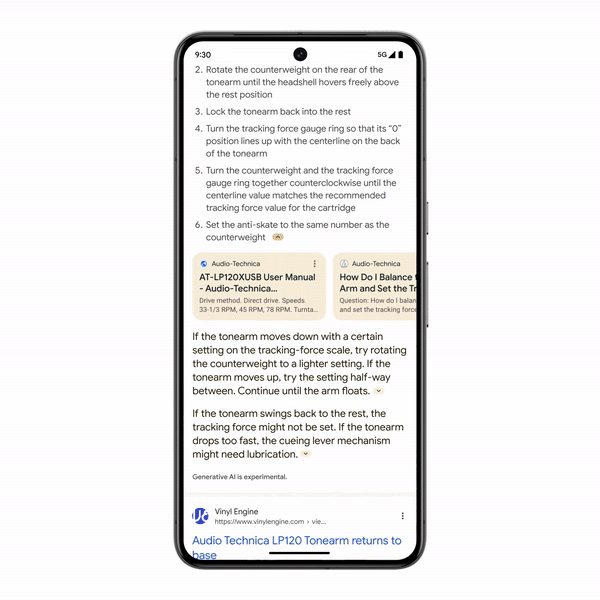
Google will incorporate AI-generated results into Search: AI Overviews, which provide AI-generated answers at the top of the page when users ask questions.
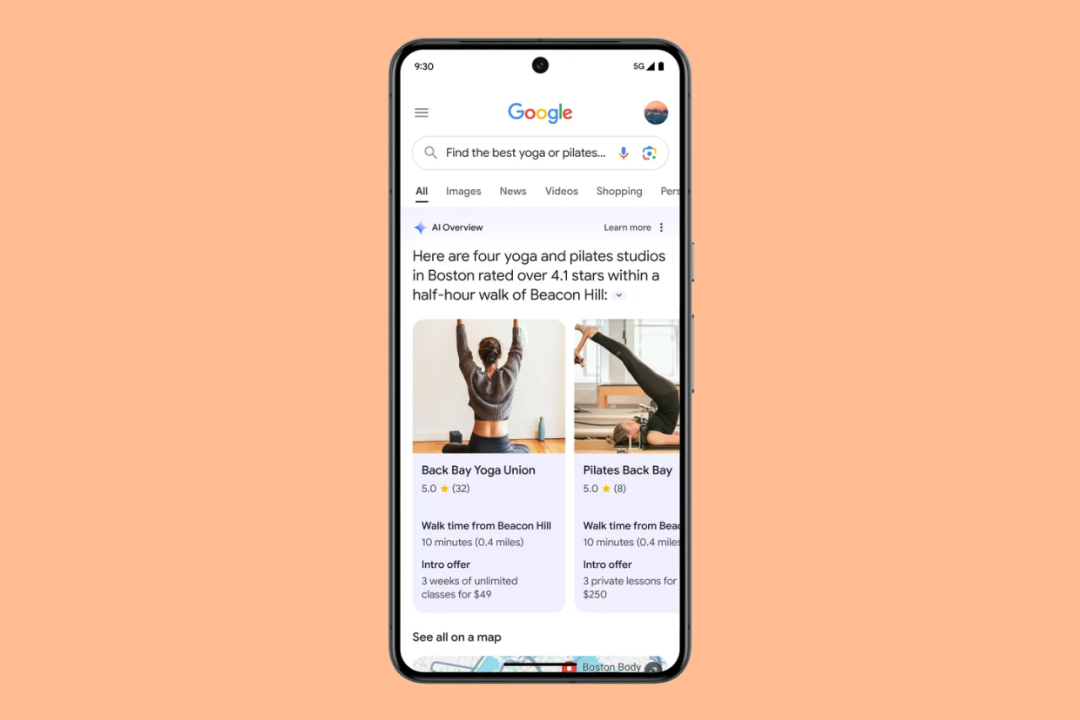
Google staff noted that AI Overviews won't appear for every search — they're primarily aimed at more complex queries. Each time a user searches, Google runs an algorithmic value judgment in the background to decide whether to serve an AI-generated answer or stick with traditional web links.
Google is rolling out AI Overviews to US users this week, with broader international expansion by year-end. The feature launches across all platforms — web, app, and Android devices.
Also coming soon: trip planning features. You can ask Google to create meal plans or find a nearby Pilates studio offering discounts. In Google's vision, AI agents can aggregate nearby studios and user reviews, and map out walking times — something other AI search products can't yet do, thanks to Google's massive data holdings.
Google Lens also got a notable update: you can now search by recording video. Previously Lens only captured still images; now it supports video and voice queries.
3
Astra: Converging with ChatGPT from a Different Path
Google's latest AI voice assistant — Astra — can identify objects, code, and various things through a camera. This concept was actually promised by DeepMind head Demis Hassabis when he first unveiled the Gemini model last December.
Astra can identify objects and scenes through a device's camera and interact via natural language. Google stated that Astra uses an advanced version of Gemini Ultra.
In demos, users wearing Google's smart glasses could interact with Astra — seen as a potential revival opportunity for Google Glass.
Demis said in a previous interview that text chat is merely a transitional phase toward more sophisticated AI assistants; voice and vision are likely the future. This is why Gemini was built as a natively multimodal large model from the ground up.
4
Challenging Sora: Veo Video Generation Model
Google hopes to challenge OpenAI's Sora with Veo, which can generate 60-second 1080p video clips from prompts, capturing different visual and cinematic styles including landscape shots and time-lapses.
Veo was trained on massive amounts of footage. This is how today's large models are trained: feed them example after example of data, and the model finds patterns in that data, enabling it to generate new data — in Veo's case, video. Google staff acknowledged that some data came from YouTube.
Like Sora, Veo has some understanding of physics — fluid dynamics, gravity, and so on — which helps it generate more realistic video.
Veo also supports masked editing of specific regions in videos and can generate video from static images, similar to generation models like Stability AI's Stable Video. Most strikingly, given a series of prompts that tell a coherent story, Veo can generate longer videos — exceeding one minute in length.
Imagen 3 Text-to-Image Model
DeepMind head Demis Hassabis claimed that compared to Imagen 2, Imagen 3 understands text prompts more accurately and generates more creative, detailed images.

"This is our best model for text rendering, which has always been a challenge for image generation," Demis added.
Furthermore, Google stated that Imagen 3 will use SynthID, a watermarking method developed by DeepMind, to apply invisible, cryptographic watermarks to generated images. SynthID will be deployed across all AI-generated images, video, and music.
5
Android 15 with Deep AI Integration
At I/O, Google discussed the upcoming new Android version — an AI-centric Android. Three breakthroughs are coming this year: better search on Android, Gemini becoming the AI assistant, and on-device AI unlocking new experiences.
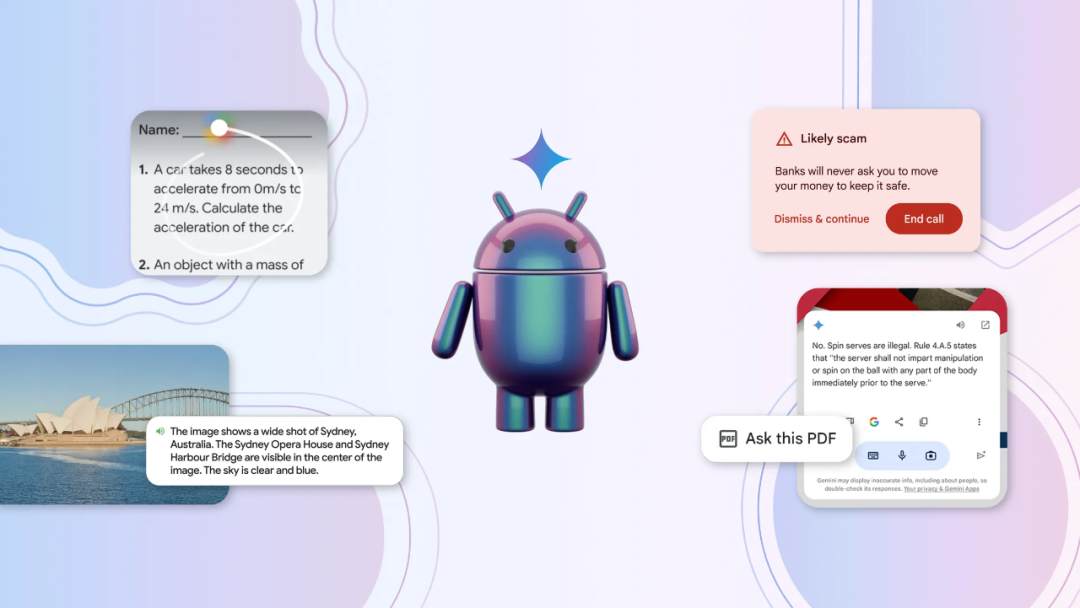
Deeper integration with the underlying operating system enables some cooler capabilities. Gemini on Android has stronger contextual awareness and can overlay on top of any app you're using, so you don't need to switch back and forth. One neat feature: users can generate images with Gemini and drag them directly into apps like Gmail or Google Messages.
Google is also experimenting with new ways to search on phones: Circle to Search. Like Now on Tap, it's more interactive and highly intuitive.
Google demonstrated different ways to use Gemini directly through the Google Messages app on Pixel 8a. This includes analyzing PDFs or videos and asking Gemini questions, getting clear (and cited) responses. These features will come to more devices "in the coming months."
If users set Gemini as their Android phone's default assistant, it can summarize webpages or screenshots or answer questions about them. Soon, it will also be able to detect when there's a video on screen and interact with users about it.
Perhaps a phone assistant with Gemini integrated is the fully realized version of Google Now, released all those years ago.
This article was first published on the WeChat account: Founder Park
For reprint requests, contact: geekparker





