When Google "Reinvents Itself": I/O 2025 Developer Conference Quick Take | Yunqi Capital Tech π

Self-Reinvention in the AI Paradigm

How does a search giant that's dominated the market for over two decades defend its moat under a new AI paradigm? Google is trying to provide an answer.
In the early hours of May 21 Beijing time, at the I/O 2025 developer conference, Google unveiled a series of product updates — spanning improved foundation model efficiency, advanced multimodal interaction, and new AI glasses — but the highlight was AI Mode, an AI-powered overhaul of its search business widely seen as Google's act of self-disruption.
What other signals of self-reinvention did this launch — more than just a flex of technical muscle — send out? This episode of "Yunqi Tech π" breaks it all down with you.
Source: WeChat account "QbitAI" | Original title: "Google's Annual Big Move: Every AI Model Gets a Full Upgrade! Gemini 2.5 Pro and Flash Take Top Two Spots, New Video/Image Models Debut"
What happens when you integrate native multimodal input and output, agents, and web search — every cutting-edge AI capability — into one system?
The latest version of Google's Project Astra shows what the ultimate AI assistant can do: observe its surroundings in real time, search for information to guide a delivery guy through fixing a bike, and automatically call nearby stores to check stock when a part is missing.
At the latest I/O conference, Google unleashed a flurry of announcements as if they were free. Every existing AI model got updated, every legacy product got rebuilt with AI, and a whole basket of experimental new products launched too.
- Preview versions of Gemini 2.5 Pro and Gemini 2.5 Flash have already claimed the top two spots on the arena leaderboard.
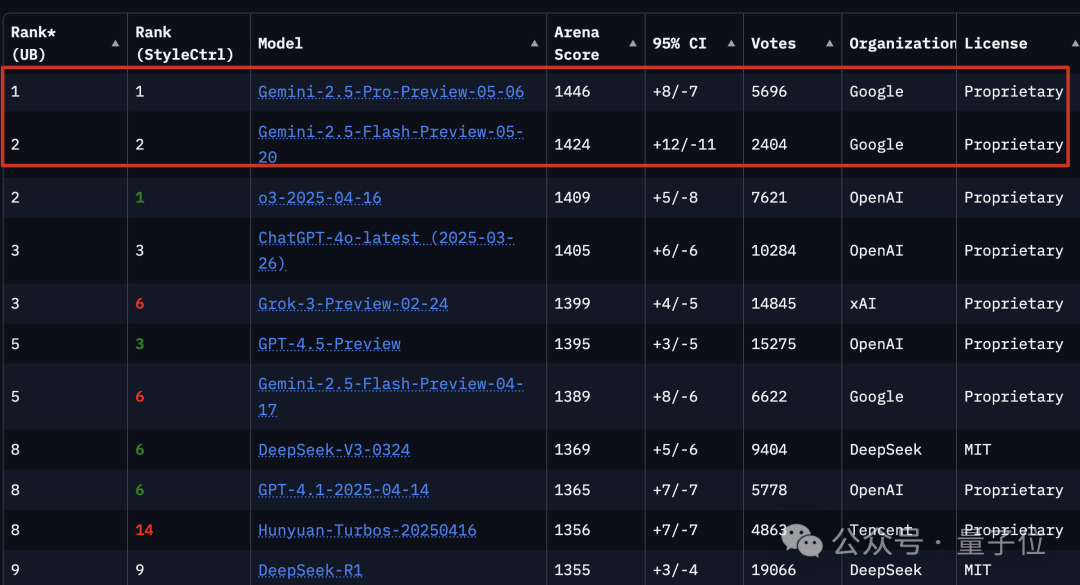
-
Veo 3, a video generation model, achieves native integration of video and audio — generating not just music and sound effects but even dialogue between characters, with lip-syncing to match.
-
Imagen 4, an image generation model, produces richer images with more nuanced colors and more realistic details.

-
On the legacy product front, Google Search adds an end-to-end AI search mode, integrating reasoning and multimodal analysis capabilities to break questions into sub-queries and issue multiple searches simultaneously for deeper web exploration.
-
Google Meet now supports real-time bilingual translation with voice dubbing that preserves each speaker's tone. English-Spanish is live now, with more languages to follow.
-
Chrome browser gets direct Gemini model integration, enabling quick content summarization or context-aware task completion based on the current webpage — no tab-switching required.
-
On the new product front, Project Starline, formerly a glasses-free 3D video calling system, has evolved into Google Beam, an AI-powered 3D video communication platform. It uses a series of cameras to capture footage from multiple angles, then leverages AI to merge the video streams and render them on a 3D light-field display — with millimeter-precision head tracking and frame rates up to 60 fps. The combination of AI video models and light-field display technology creates a sense of dimension and depth, enabling eye contact, subtle expression reading, and the building of understanding and trust — just like being face-to-face.

- There's also Jules, an asynchronous AI coding assistant that runs in the background while human users focus on other tasks.
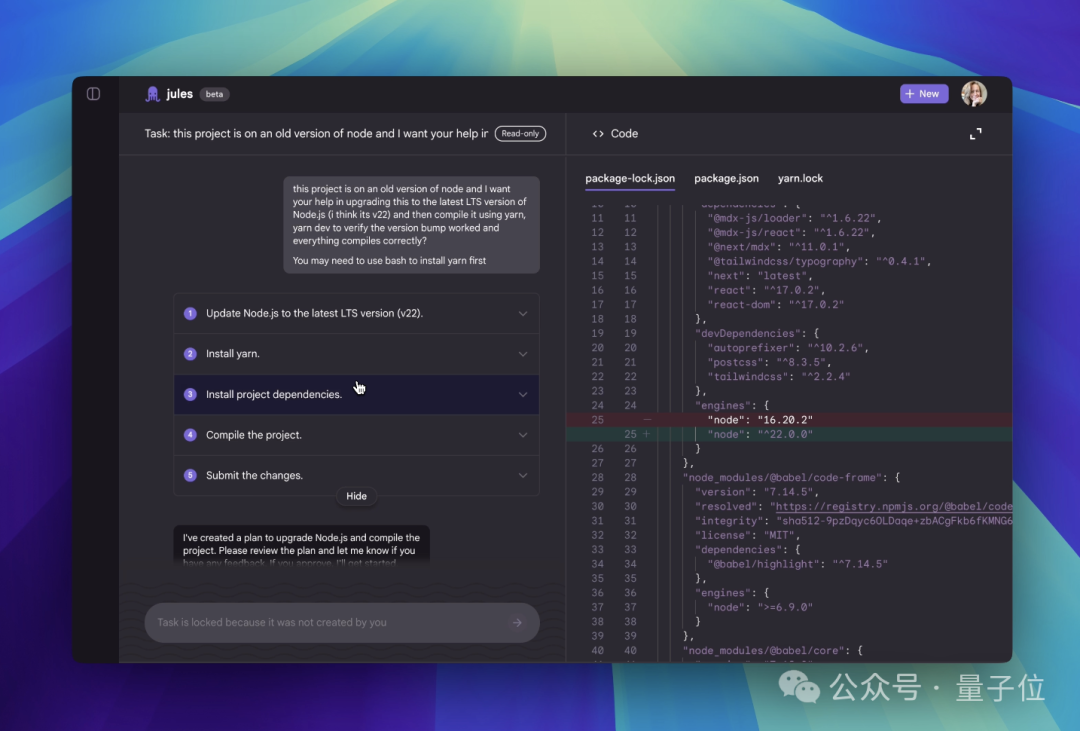
-
Flow, an AI filmmaking tool that integrates multiple multimodal models to turn creative ideas into stories.
-
AI glasses built in partnership with eyewear brands Gentle Monster and Warby Parker, equipped with cameras, microphones, and speakers that work with your phone — no need to pull it out of your pocket to access apps. Powered by the Gemini model, the AI glasses can see and hear everything you do, understand your situation, remember important things, and assist you throughout the day.

Here's a detailed look at each part.
Gemini 2.5 Series Gets a Full Upgrade
Both Gemini 2.5 Pro and Flash received upgrades. First up: Gemini 2.5 Pro. Beyond strong performance on academic benchmarks, it now leads the popular coding leaderboard WebDev Arena with an ELO score of 1415 — a 142-point improvement over the previous version:
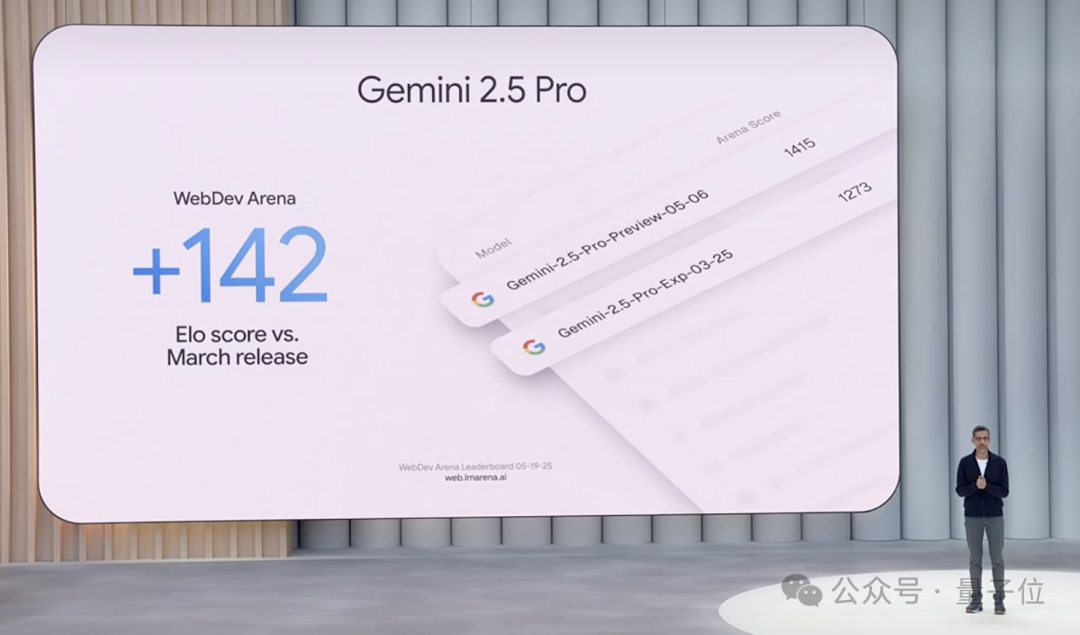
It also dominates LMArena, which evaluates human preferences across multiple dimensions:
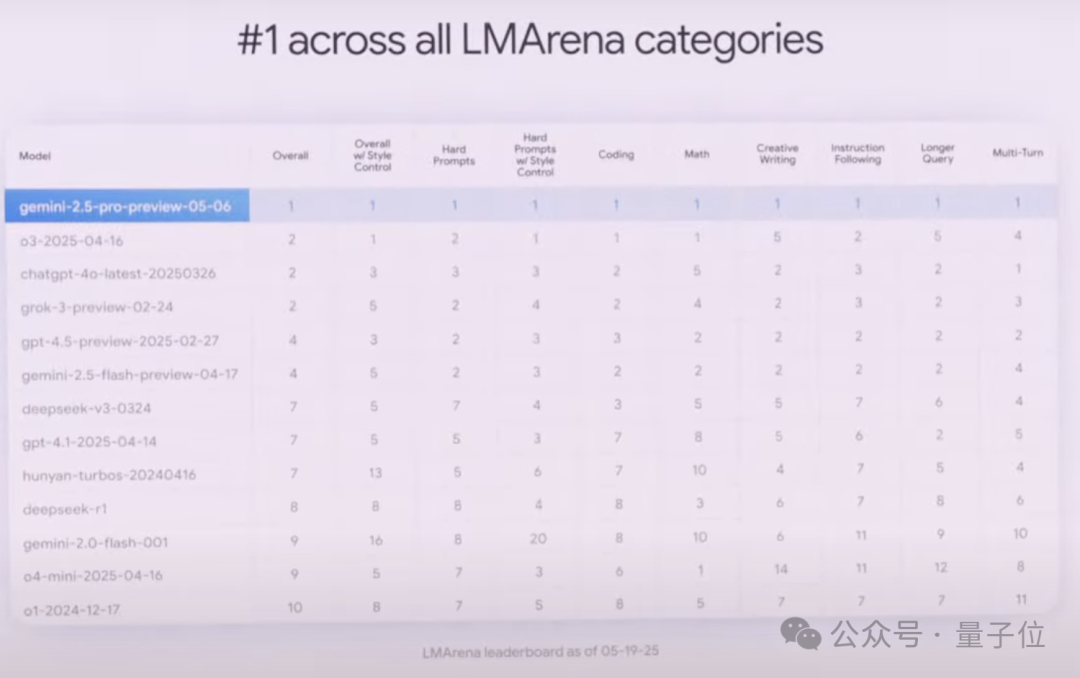
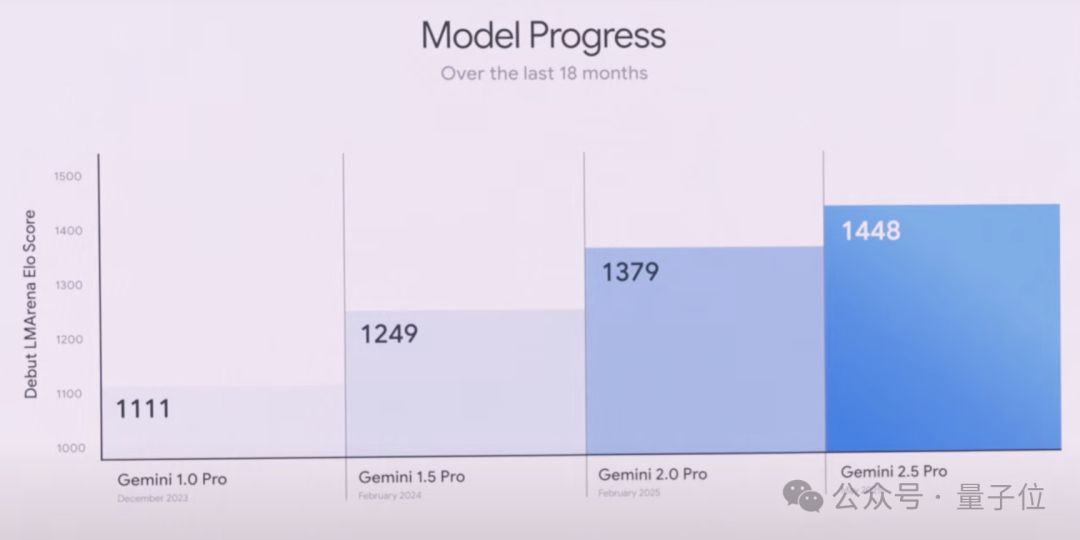
According to Google, with its million-token context window, 2.5 Pro delivers stronger long-context and video understanding performance. It also integrates the LearnLM model series, developed in collaboration with education experts — in direct comparisons evaluating teaching methodology and effectiveness, educators and experts preferred 2.5 Pro across various scenarios. More notably, 2.5 Pro introduces Deep Think, an enhanced reasoning mode. This mode uses new techniques that allow the model to consider multiple hypotheses simultaneously before responding. The results? 2.5 Pro posted impressive scores on ultra-difficult math benchmarks like 2025 USAMO, showed advantages on programming competition-level LiveCodeBench, and achieved 84.0% on the MMMU benchmark testing multimodal reasoning.
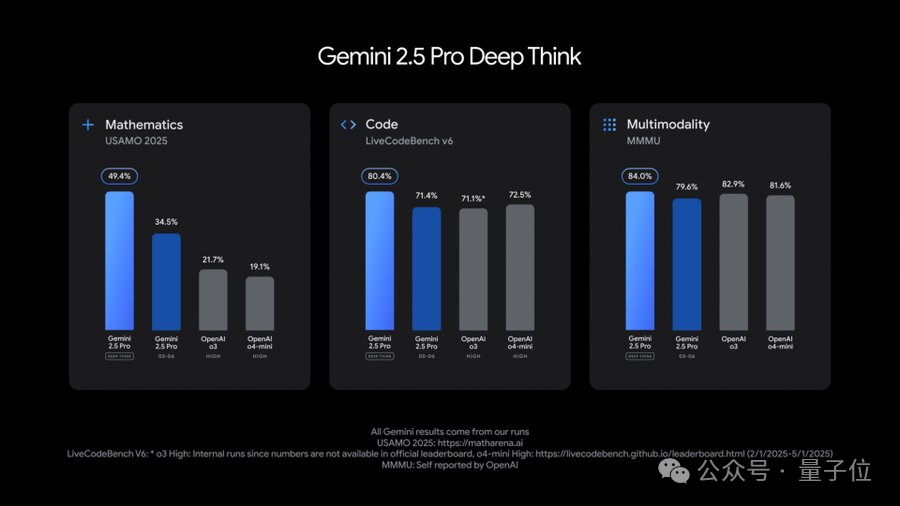
However, Google notes that Deep Think requires additional time for frontier safety evaluations and will initially only be available to trusted testers through the Gemini API. 2.5 Flash was also upgraded, with improvements across key benchmarks including reasoning, multimodal capabilities, coding, and long-context — while also being more efficient, using 20-30% fewer tokens in Google's evaluations. The new 2.5 Flash is now available in preview in Google AI Studio, Vertex AI, and the Gemini app.
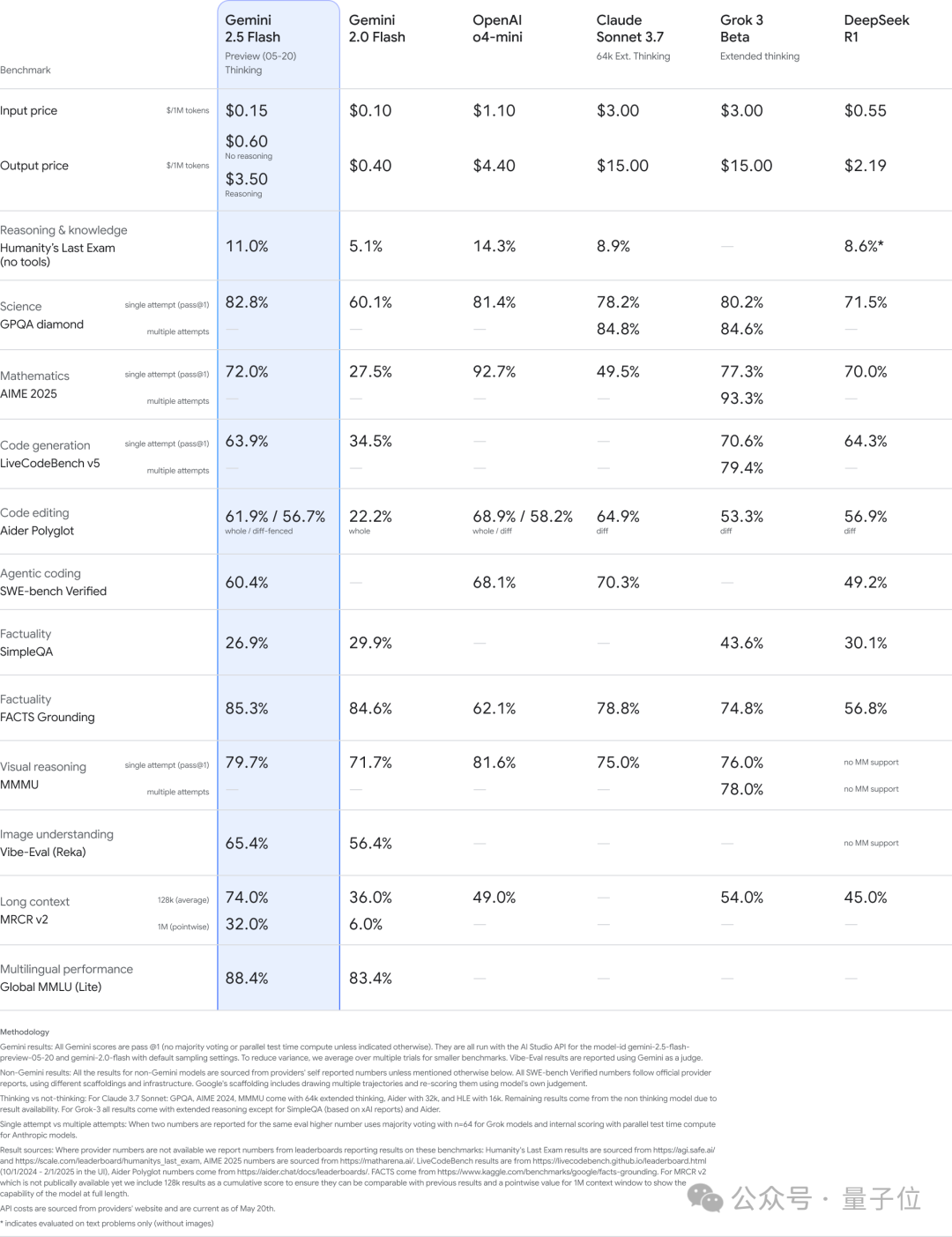
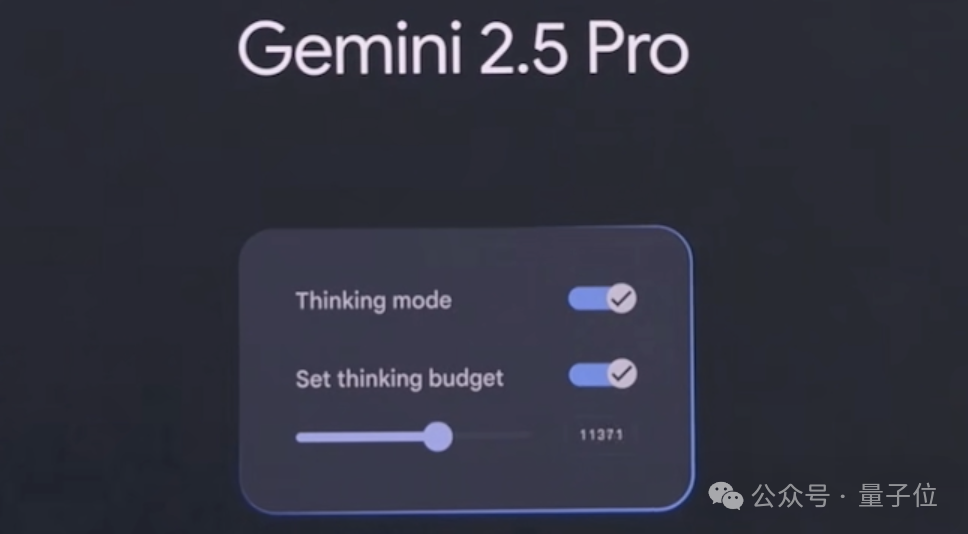
That's not all — the Gemini 2.5 series also introduced several new features. 1. Native audio output & Live API improvements The Live API launched a preview of audiovisual input and native audio conversation, enabling developers to build more natural, expressive Gemini conversational experiences. The model can adjust tone, accent, and speaking style on request — emotional variations you can actually hear. Google also rolled out new text-to-speech (TTS) capabilities for 2.5 Pro and 2.5 Flash. For the first time, it supports multiple speakers through native audio output, enabling dual-voice synthesis that simulates two distinct voices speaking simultaneously or in alternation, across 24 languages. This TTS feature is now available in the Gemini API. 2. Computer use capabilities Google is bringing Project Mariner's computer use capabilities to Gemini API and Vertex AI. It supports multitasking — up to 10 simultaneous tasks — and adds a "Learn and Repeat" feature that lets AI automatically handle repetitive tasks. 3. To improve the developer experience, Gemini 2.5 adds three practical features: Thought summaries, which organize the model's raw reasoning into a clean format with headers, key details, and model actions (like tool calls), giving developers more transparency into how the model thinks. Thinking budgets, letting developers control how many tokens the model uses for reasoning. Gemini SDK compatibility with MCP tools, enabling easier integration with open-source tools.
As for what's next for Gemini, Google DeepMind CEO Demis Hassabis said they're working to scale their best Gemini model into a "world model" — one that can plan and imagine new experiences by understanding and simulating the world, much like the human brain.
Asynchronous Coding Assistant Jules
The asynchronous coding assistant Jules has officially entered public beta, available to developers worldwide with no waitlist. Jules clones your codebase into a secure Google Cloud VM, fully understands project context, and can write tests, build new features, provide audio update logs, fix bugs, and update dependencies. It works asynchronously so you can focus on other tasks, then presents its plan, reasoning, and changes when done. Work in private repos stays private by default — Jules won't train on your private code. Powered by Gemini 2.5 Pro, Jules features state-of-the-art coding reasoning capabilities. Combined with its cloud VM system, it can handle complex multi-file changes and concurrent tasks. It's completely free during the public beta, though usage limits apply; paid plans are expected once the platform matures.
Google Search Introduces AI Mode
On the search front, this I/O conference announced the official rollout of AI Mode into Google Search, now fully open to users in the US.

AI Mode is a search engine rebuilt around Gemini 2.5, integrating Gemini's most advanced capabilities to deliver end-to-end AI search. It uses query fan-out technology to automatically decompose questions into multiple sub-topics and search them simultaneously, enabling deeper and more comprehensive web exploration than traditional search. Google previewed a series of upcoming AI Mode features, including: Deep Search, which can automatically launch hundreds of searches, synthesize information across domains, and generate extensively cited expert-level reports — saving massive amounts of manual research time.
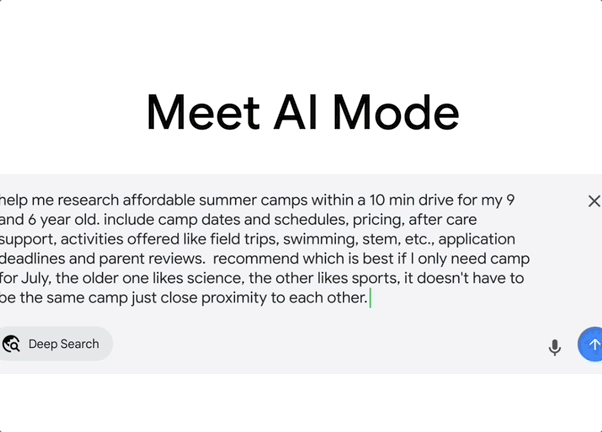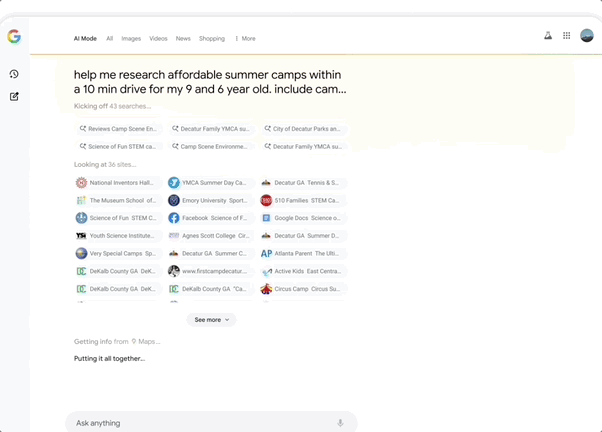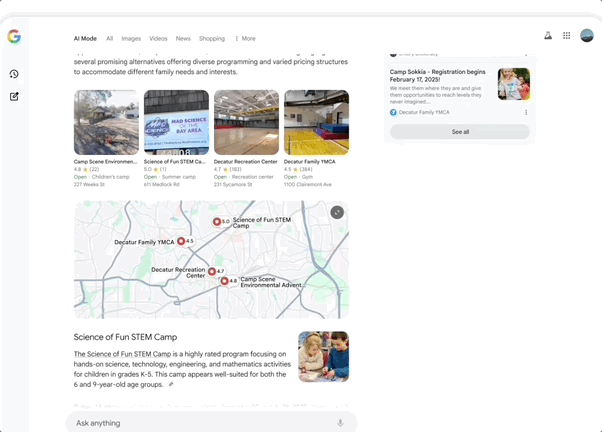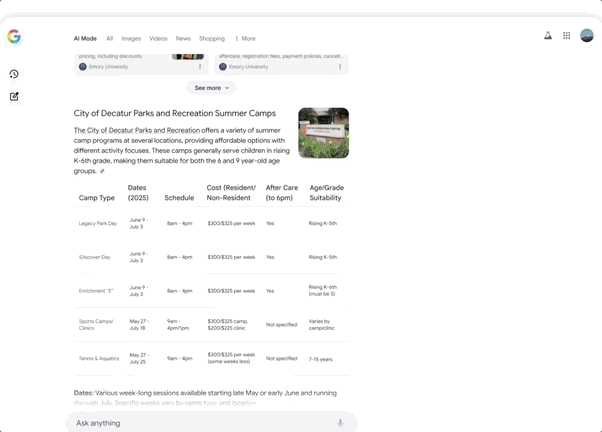
Search Live, a real-time interactive search feature where users simply tap the "Live" icon in AI Mode, point their phone camera, and ask questions — the AI understands what's in frame and provides real-time spoken answers with relevant resource links.
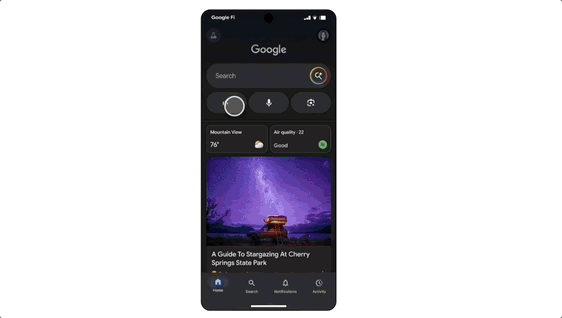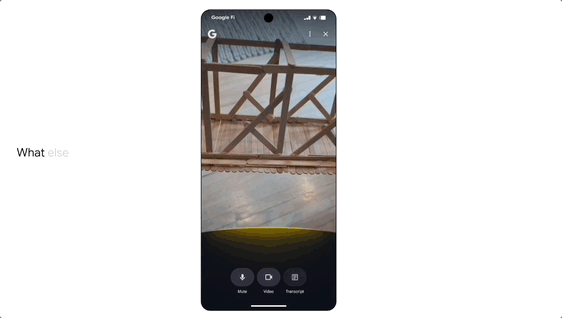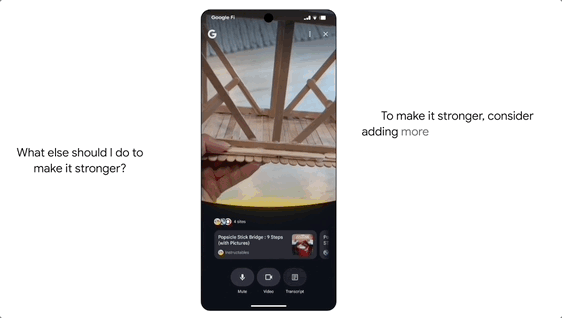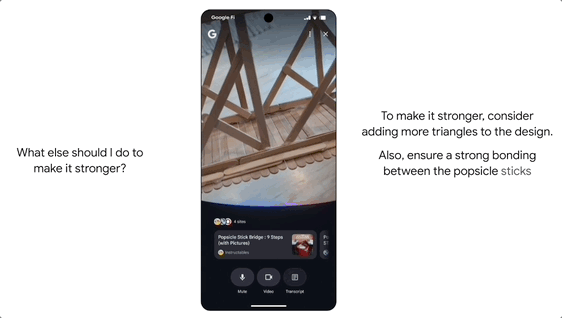
There's also agent capability: want to buy concert tickets? Just say the word, and AI Mode will scour ticketing sites across platforms, lock in the best option, and fill out the order details. Users simply confirm the option that meets their needs and complete the purchase on their preferred site.
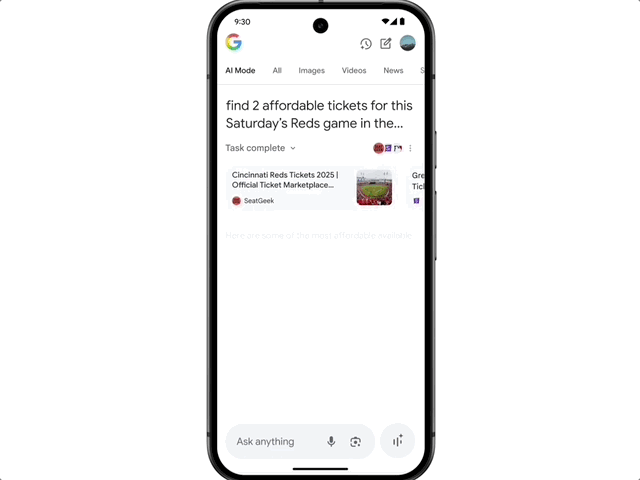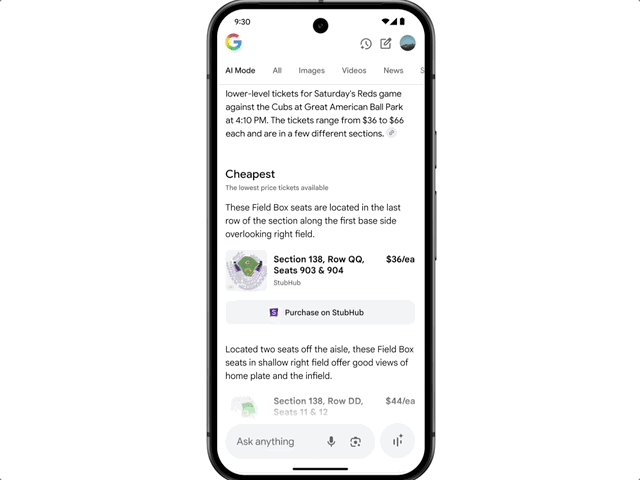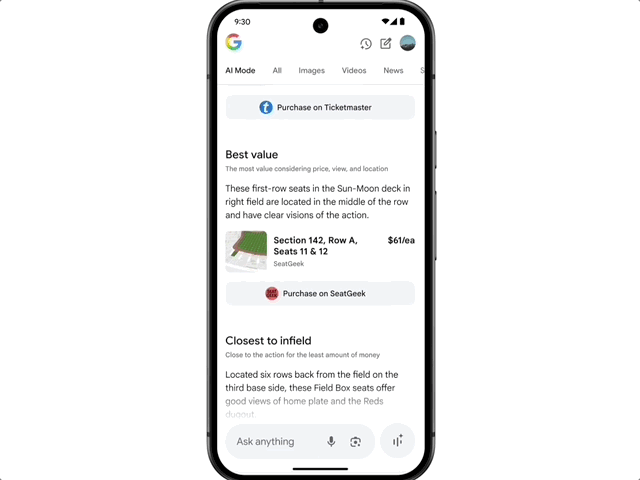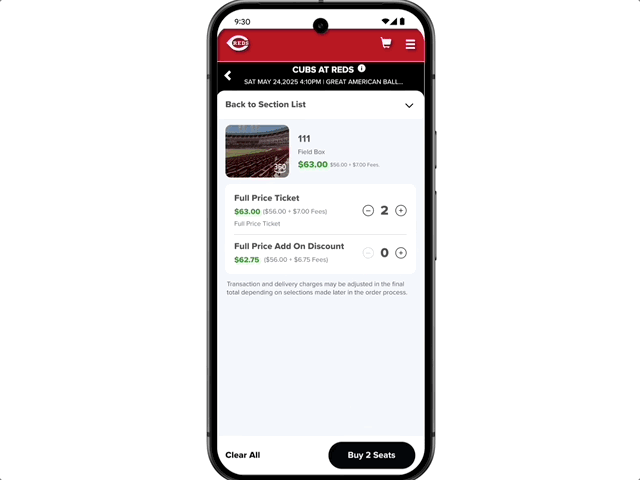
Google also highlighted the new shopping experience enabled by AI Mode. The new experience combines Gemini's intelligence with the Shopping Graph, integrating 50 billion+ product listings to help users browse, clarify needs, and filter products. When users decide to buy, a new smart checkout feature completes transactions at budget-compliant prices with ease. Simply click "track price" on any product page, set size, color, and budget, and get notified when the price drops. After confirming purchase details, click "buy for me" — the system automatically adds the item to cart and securely completes checkout via Google Pay.
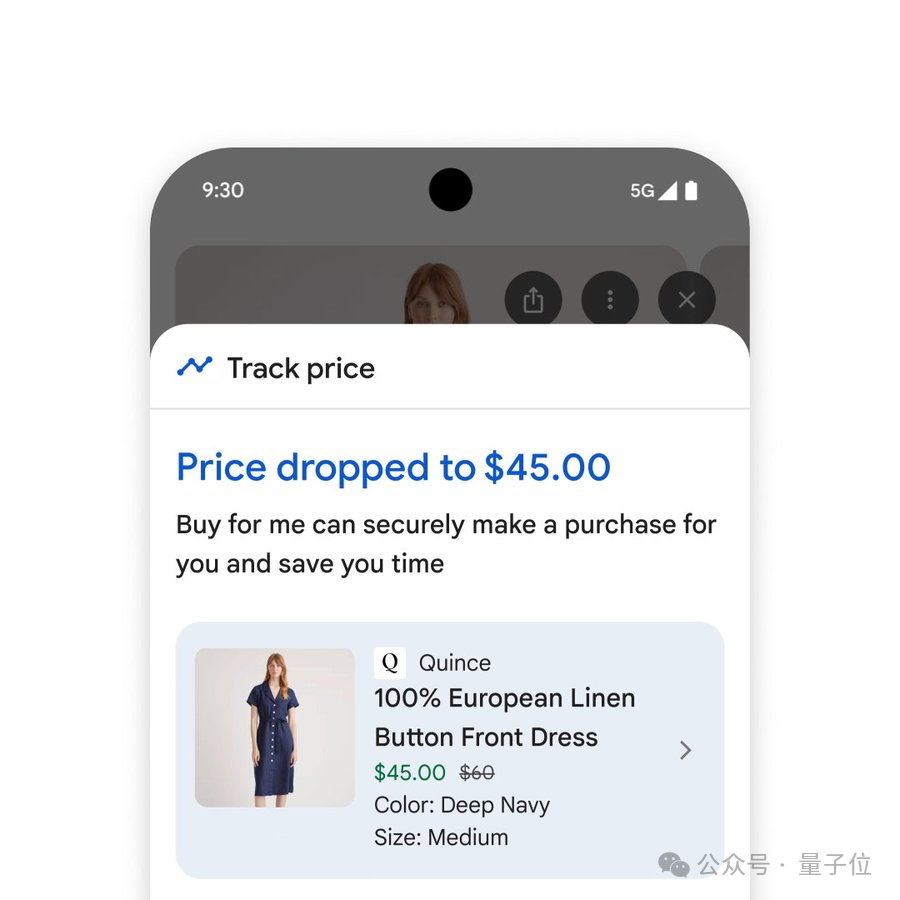
For clothing purchases, there's also a virtual try-on tool that works with user selfies. Just upload one photo and try on countless outfits — the AI model accurately replicates how different fabrics drape and fold.

Multimodal Models Upgraded Across the Board
On the multimodal front, Google also unveiled its latest video generation model Veo 3 and image generation model Imagen 4.
Veo 3 achieves native synchronized audio-video generation for the first time — whether it's city street traffic, birdsong in a park, or even character dialogue, all can be generated from text prompts. Users simply describe a short story in a prompt, and the model generates vivid video clips. From text/image prompts to real-world physics simulation and precise lip-syncing, Veo 3 excels across dimensions. Veo 3 is now available to US Ultra subscribers, with enterprise access through Vertex AI. Alongside the new model, Veo 2 also gained several new features: reference-driven video generation, camera control, frame extension, and object addition and removal. These are available in Flow now, coming to the Vertex AI API in the coming weeks, and will be integrated into more products in the coming months. Google's latest image generation model Imagen 4 combines speed and precision — 10x faster than its predecessor while delivering stunning fine detail, from complex fabrics and water droplets to animal fur, equally adept at photorealistic and abstract styles.

Imagen 4 supports multiple aspect ratios and resolutions up to 2K, with significantly improved text spelling and typography capabilities, making it easy to create greeting cards, posters, and comics.

Imagen 4 is now live in the Gemini app, Whisk, and Vertex AI.
Beyond this, Google introduced Flow, a next-generation AI filmmaking tool designed for creatives, integrating Google's strongest visual models (Veo, Imagen, and Gemini).
Flow features exceptional prompt adherence and outputs stunning cinematic footage. Under the hood, the Gemini model makes prompt input intuitive — users can describe their creative vision in everyday language, import their own materials to create characters, or use Imagen's text-to-image capabilities to generate story elements within Flow. Once a character or scene is created, it can be reused coherently across different clips and scenes, or a single scene image can launch a new shot.
Starting today, US Google AI Pro and Ultra subscribers get first access to Flow.
One More Thing
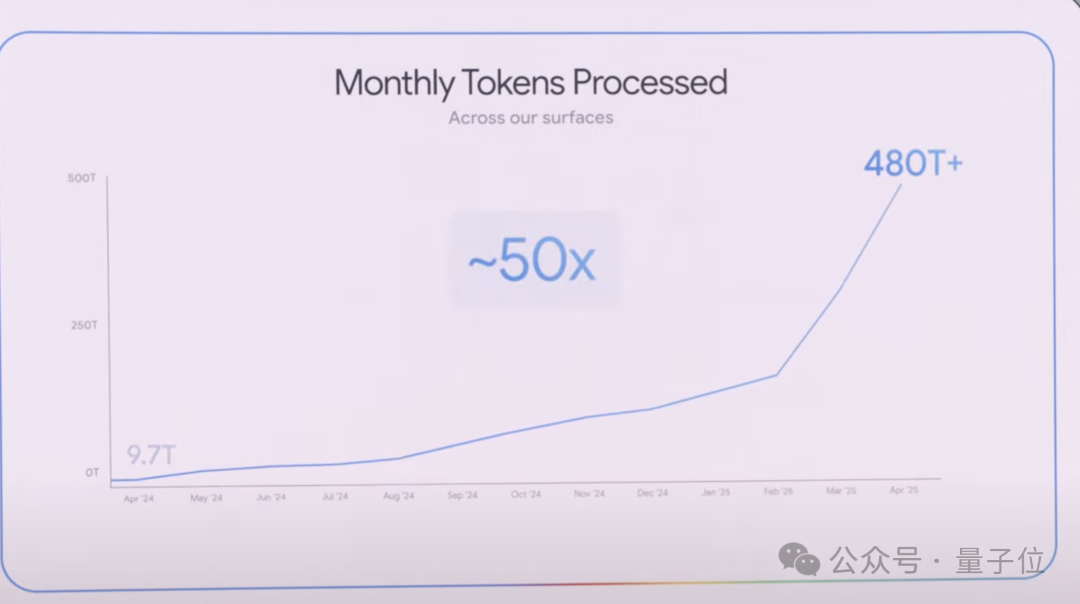
At the conference, CEO Sundar Pichai shared one striking data point. Last April, Google's products and model APIs combined processed 9.7 trillion tokens per month. One year later, that number has grown 50x to 480+ trillion tokens per month.
Video replay: https://www.youtube.com/watch?v=o8NiE3XMPrM Reference links: https://google-i-o-2025-press-site.prezly.com/





