Is There a Cure for LLM "Hallucinations"? Here's the Prescription — | Yunqi Science Chat

To prescribe the right medicine, you first need to understand the pathology.

Outside the specific context of NLP, psychology defines hallucination as "a false perception that feels real." Typically, we think of hallucinations as something troublesome.
LLM hallucinations are indeed one of the problems AI companies are now throwing their full weight behind solving. At root, the source of "hallucination" lies in how GPT searches for evidence relevant to a question — unable to accurately distinguish between sources that offer different, inconsistent, or even contradictory answers, it becomes confused and stitches together passages from different responses on its own. In other words, what the model generates doesn't align with real-world facts or the user's input.
But this very quality of being "hard to control" is also creating new opportunities for startups. In our previous article on AIGC+Game, we highlighted novel gameplay mechanics built on LLM hallucinations and the fresh experiences they delivered to users.
To gain further control over "hallucination," we need a clearer understanding of exactly how it works. Recently, the Harbin Institute of Technology and Huawei jointly published a 49-page survey on large model hallucinations, sparking considerable discussion online. In this edition of "Yunqi Science Chat," we explore the definition, taxonomy, causes, and solutions for large model hallucinations.
The following content is republished from QbitAI
This latest "Survey of Large Model Hallucinations" from the Harbin Institute of Technology and Huawei has generated significant buzz online.

Specifically, the paper proposes a new categorical framework for defining model hallucinations, dividing them into two major types: factuality hallucination and faithfulness hallucination.
It also identifies three primary sources of model hallucinations — data source, training process, and inference — and provides corresponding strategies for mitigating them.
A preview in one image ↓
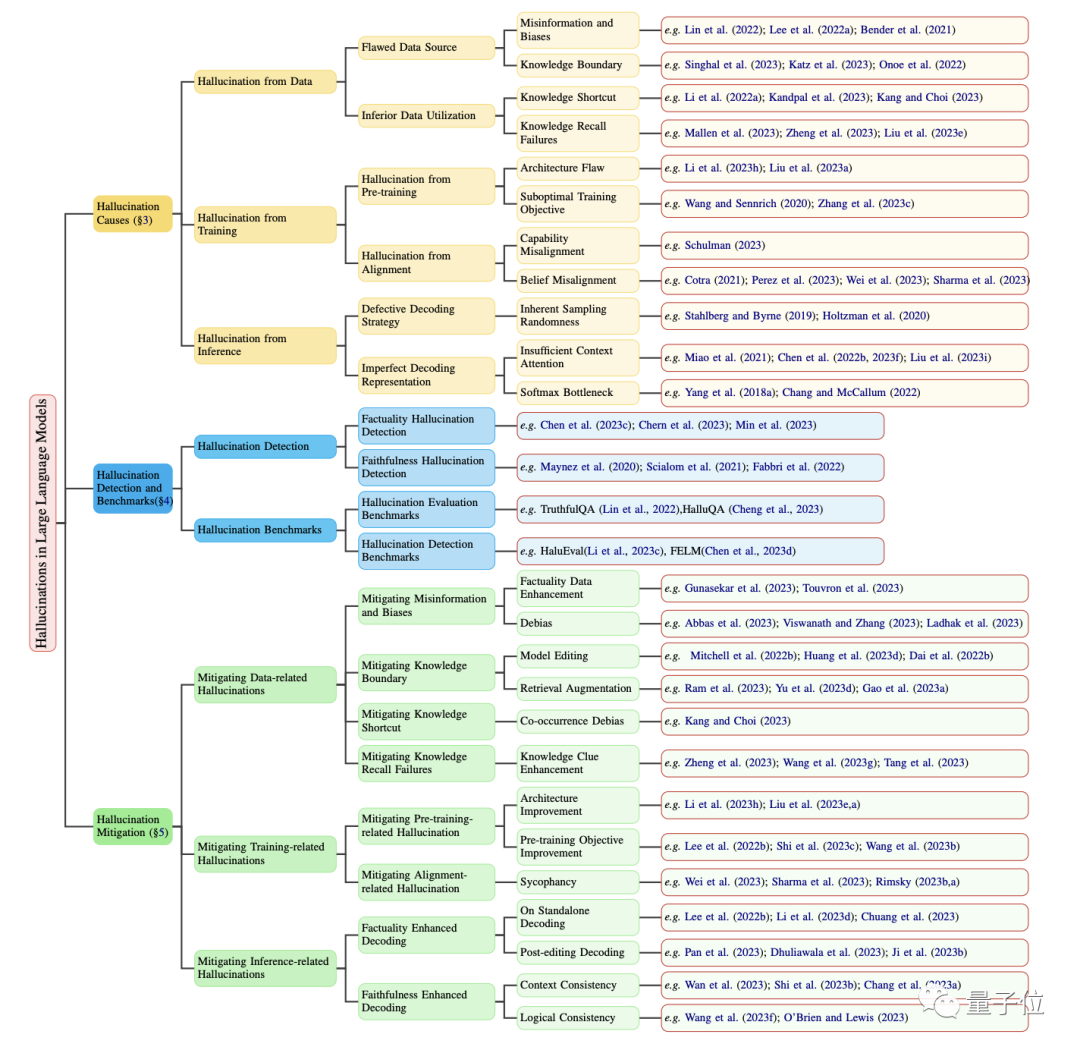
Hallucination, as a chronic condition of large models: identify the root cause, and you can prescribe the right treatment.
Bin Dong, a mathematics professor at Peking University, once remarked that as a researcher, he actually quite likes large model hallucinations:
Because the line between hallucination and creativity/innovation is razor-thin.
So how exactly does this survey dissect the phenomenon of large model hallucinations? Let's take a look.

The "Pathology" of Large Model Hallucinations
When large models hallucinate, put simply, they're "talking nonsense."
In the paper's terms, this refers to the phenomenon where model-generated content is inconsistent with real-world facts or user input.
As mentioned above, the researchers divide large model hallucinations into factuality hallucination and faithfulness hallucination.
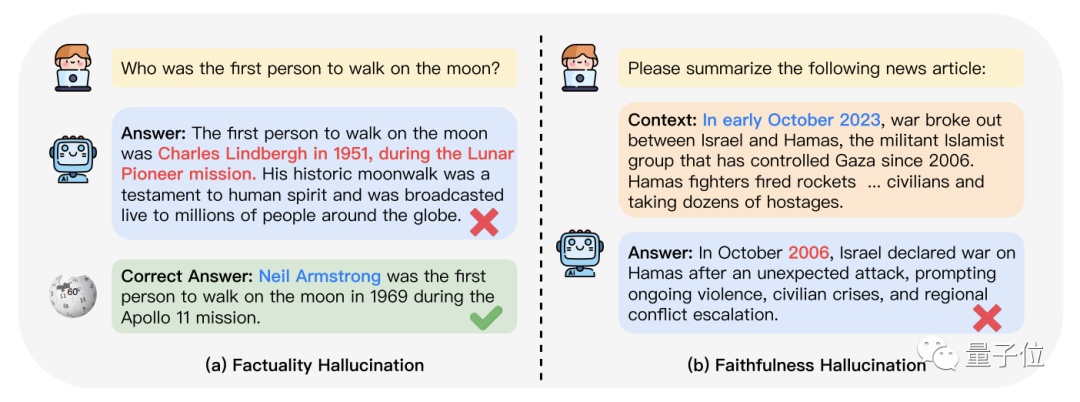
Left, factuality hallucination; right, faithfulness hallucination
Factuality hallucination refers to model-generated content that is inconsistent with verifiable real-world facts.
For example, when asked "Who was the first person to walk on the moon?", the model responds "Charles Lindbergh was the first to walk on the moon during the 1951 Lunar Pioneer mission." In reality, the first person on the moon was Neil Armstrong.
Factuality hallucination can be further divided into factual inconsistency (contradicting real-world information) and factual fabrication (something that simply doesn't exist and cannot be verified against real-world information).
Faithfulness hallucination, on the other hand, refers to model-generated content that is inconsistent with the user's instructions or context.
For example, asking the model to summarize news from this October, but the model talks about events from October 2006 instead.
Faithfulness hallucination can also be subdivided into instruction inconsistency (output deviates from user instructions), context inconsistency (output doesn't match contextual information), and logical inconsistency (inconsistency between reasoning steps and final answer).
So what causes large models to hallucinate?
First, "disease enters through the mouth" — the data that feeds large models is a major cause of hallucination.
This includes data flaws and low utilization of factual knowledge captured in the data.
Specifically, data flaws divide into misinformation and bias (repetition bias, social bias). Additionally, large models have knowledge boundaries, leading to domain knowledge gaps and outdated factual knowledge.
Even when large models consume vast amounts of data, problems arise in how they use it.
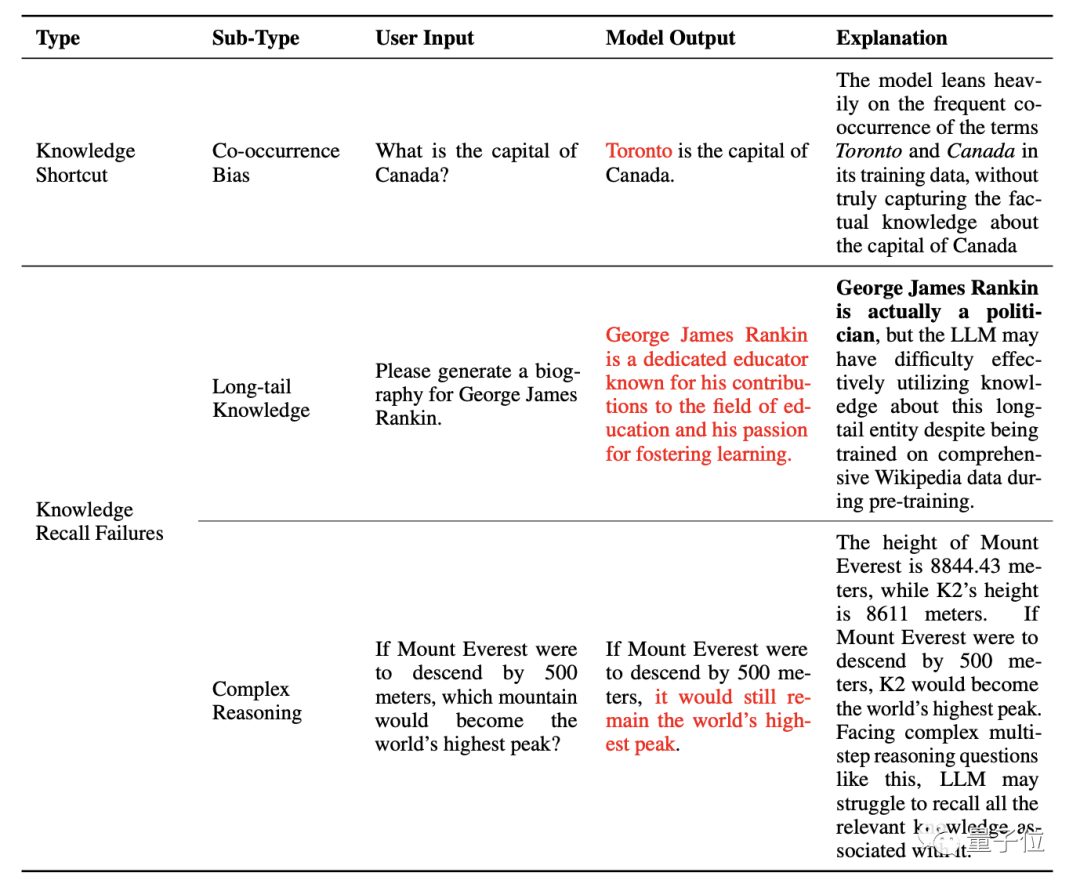
Large models may over-rely on certain patterns in training data, such as positional proximity, co-occurrence statistics, and correlated document counts, leading to hallucinations. For instance, if "Canada" and "Toronto" frequently co-occur in training data, the model may incorrectly identify Toronto as Canada's capital.
Furthermore, large models may exhibit insufficient recall of long-tail knowledge and struggle with complex reasoning.
Beyond data, the training process itself can cause large models to hallucinate.
Problems mainly arise in two stages: pre-training (where large models learn general representations and acquire world knowledge) and alignment (where models are fine-tuned to better match human preferences).
Pre-training stage issues include:
-
Architectural flaws. Predicting the next token based on previous tokens — this unidirectional modeling hinders the model's ability to capture complex contextual relationships; the self-attention module has defects, with attention to different positions diluted as token length increases.
-
Exposure bias. Training strategies are also flawed — during inference, the model relies on its own generated tokens for subsequent predictions, and erroneous tokens generated by the model cascade into compounding errors throughout subsequent tokens.
Alignment stage issues include:
-
Capability misalignment. There may be misalignment between a large model's intrinsic capabilities and the functions described in annotation data. When alignment data demands exceed these predefined capability boundaries, the model is trained to generate content beyond its own knowledge boundaries, amplifying hallucination risk.
-
Belief misalignment. Fine-tuning via RLHF and similar methods makes model output more aligned with human preferences, but sometimes the model tends to cater to human preferences at the expense of factual accuracy.
The third key factor in large model hallucinations is inference, which presents two problems:
-
Inherent sampling randomness: generating content probabilistically at random.
-
Imperfect decoding representation: insufficient contextual attention (over-focusing on adjacent text while neglecting source context) and the softmax bottleneck (limited expressive capacity of output probability distributions).

Diagnosing the Model's Condition
Having analyzed the causes of large model hallucinations, the researchers also provide a benchmark for detecting them.
For factuality hallucination, two methods already exist: retrieving external facts and uncertainty estimation.
Retrieving external facts involves comparing model-generated content against reliable knowledge sources.

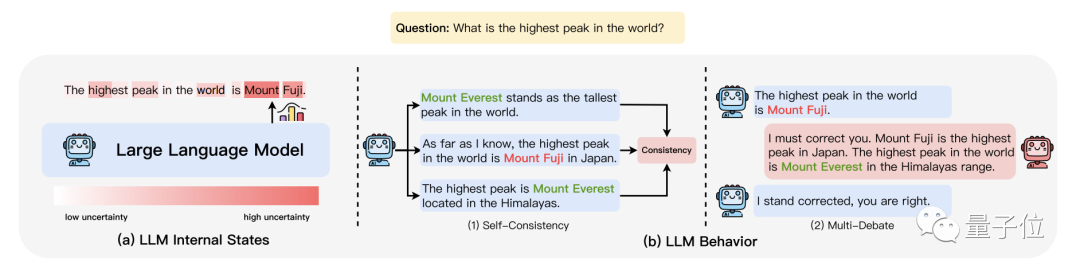
Uncertainty estimation-based hallucination detection methods fall into two categories: internal-state-based methods and behavior-based methods.
Internal-state-based methods primarily rely on access to the large model's internal states. For example, determining model uncertainty by considering the minimum token probability for key concepts.
Behavior-based methods primarily rely on observing the large model's behavior without requiring access to its internal states. For example, detecting hallucinations by sampling multiple responses and evaluating consistency of factual claims.
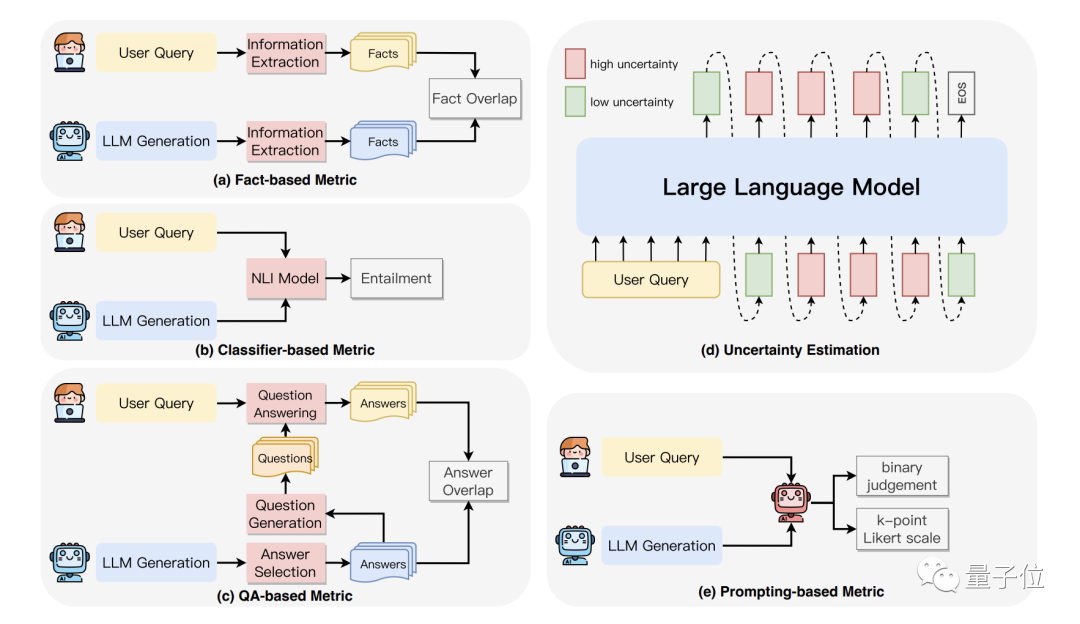
The researchers summarize five different methods for detecting faithfulness hallucinations in one diagram:
-
Fact-based metrics: assessing faithfulness by measuring factual overlap between generated content and source content.
-
Classifier metrics: using trained classifiers to distinguish between faithful and hallucinated model-generated content.
-
QA metrics: using question-answering systems to verify information consistency between source and generated content.
-
Uncertainty estimation: assessing faithfulness by measuring the model's confidence in its generated outputs.
-
Prompt metrics: using large models themselves as evaluators, assessing faithfulness of generated content through specific prompting strategies.
Once we understand how to measure hallucinations, we can move on to methods for mitigating them.

Prescribing the Right Treatment to Reduce Hallucinations
Based on the causes of hallucinations, the researchers provide a detailed summary of existing research on reducing them.
1. Data-Related Hallucinations
The most straightforward way to reduce misinformation and bias is to collect high-quality factual data and clean it to eliminate biases.
For knowledge boundary issues, two popular methods exist. One is knowledge editing, directly editing model parameters to bridge knowledge gaps. The other is retrieval-augmented generation (RAG), leveraging non-parametric knowledge sources.
Retrieval augmentation divides into three types: one-time retrieval, iterative retrieval, and post-hoc retrieval.
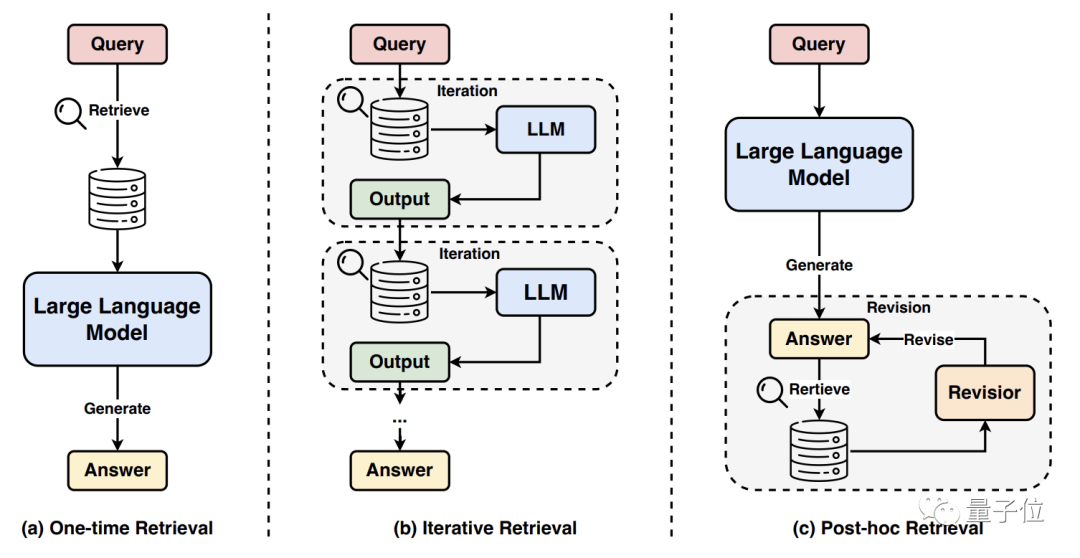
One-time retrieval directly prepends external knowledge obtained from a single retrieval into the large model's prompt; iterative retrieval allows continuous knowledge gathering throughout the generation process; post-hoc retrieval refines large model output through retrieval-based revision.
2. Training-Related Hallucinations
Based on the causes of hallucinations, defective model architectures can be improved — numerous relevant studies already exist.
Regarding the model pre-training stage, recent advances attempt to address this by improving pre-training strategies, ensuring richer contextual understanding, and avoiding biases.
For example, to address models' fragmented, disconnected understanding of document-style unstructured factual knowledge, one study appends a TOPICPREFIX after each sentence in a document, converting them into independent facts, thereby enhancing the model's understanding of factual relationships.
Additionally, alignment misalignment can be mitigated through improved human preference judgments and activation steering.
3. Inference-Related Hallucinations
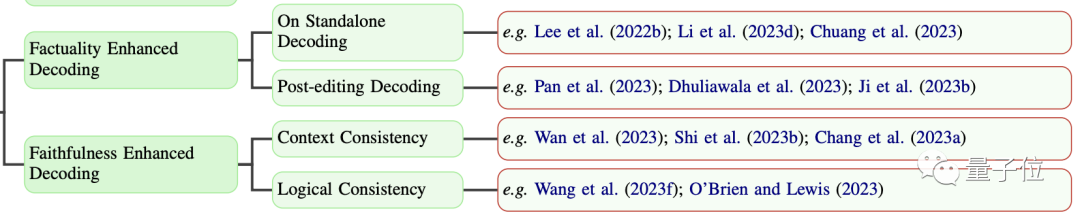
Imperfect decoding often causes model outputs to deviate from original context.
The researchers explore two advanced strategies: fact-enhanced decoding and post-editing decoding.
Furthermore, faithfulness-enhanced decoding prioritizes alignment with user instructions or provided context, emphasizing enhanced consistency in generated content. Existing work can be summarized into two categories: contextual consistency and logical consistency.
One recent study on contextual consistency is Context-Aware Decoding (CAD), which modifies output distributions by reducing reliance on prior knowledge, thereby promoting the model's attention to contextual information.
A recent study on logical consistency includes a knowledge distillation framework used to enhance the inherent self-consistency in chain-of-thought prompting.
Paper link: https://arxiv.org/abs/2311.05232





