Jina AI Launches World's First Open-Source 8K Vector Model | Cloud News · Open Source

Currently, only two AI technology companies — OpenAI and Jina AI — have released 8k embedding models.

Jina AI, a seed-round portfolio company of Yunqi Capital, has officially released its self-developed second-generation text embedding model: jina-embeddings-v2, the world's only open-source vector model that supports 8K (8192) input length.
According to the MTEB leaderboard, jina-embeddings-v2 is neck and neck with OpenAI's proprietary model text-embedding-ada-002 in terms of performance. Currently, only two AI technology companies — OpenAI and Jina AI — have released embedding models with 8K length.
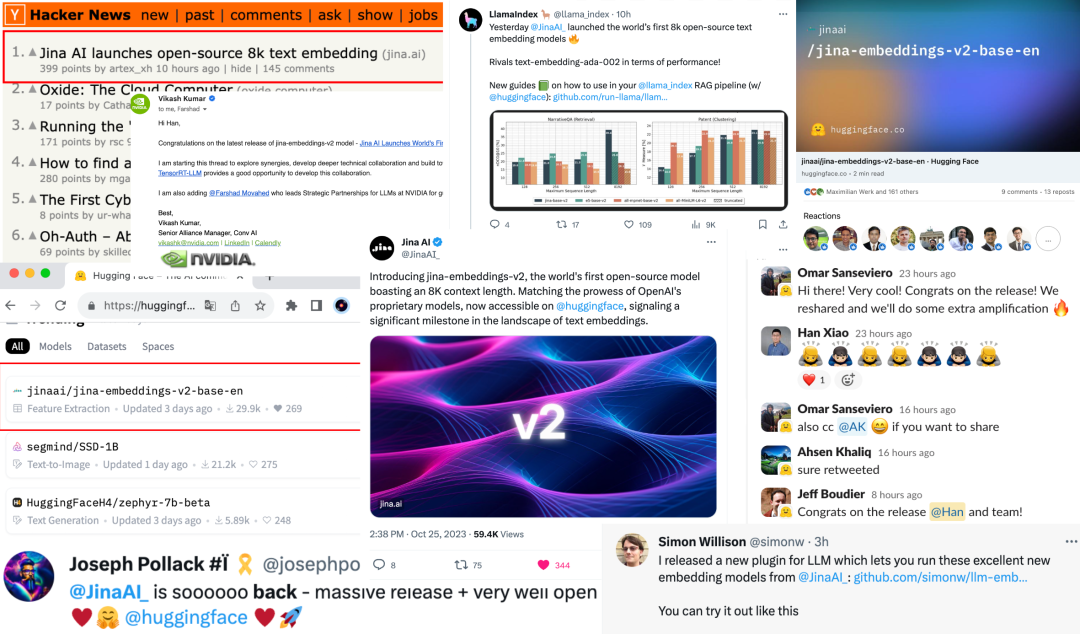
Since its release, the model quickly shot to the top of HackerNews, sparking widespread discussion among industry professionals globally.
The "8K length" and "open-source" aspects have drawn particular attention from the industry. As one HackerNews commenter put it, jina-embeddings-v2's support for 8K input length strikes a welcome balance between expressiveness and computational efficiency. The key to this lies in its distinctive advantage — achieving efficient representation with smaller dimensions.
While text-embedding-ada-002 has been widely deployed across various scenarios, its 1536-dimensional output is less than ideal for developers dealing with massive data volumes and cost sensitivity. jina-embeddings-v2 offers developers greater flexibility by providing two output dimension options: 768 (base) and 512 (small). This means developers can achieve lower computation and storage costs, making it suitable for more real-world deployment scenarios.


At Jina AI, we firmly believe in the catalytic power of open-source technology for innovation, collaboration, and community strength. That's why we open-sourced the model immediately, looking forward to building an open-source AI ecosystem together with the community.
Our model quickly topped the Hugging Face Trending list upon release. Model link: https://huggingface.co/jinaai/jina-embeddings-v2-base-en
Vector Models and 8K Input Length
In traditional natural language processing tasks, text is typically converted into a set of numbers for representation — that is, vectors. Vector models are used to generate these vector representations and are widely applied in retrieval, classification, clustering, semantic matching, and other tasks.
In the era of large language models, the importance of vector models has only grown. Especially in retrieval-augmented generation (RAG) scenarios, they have become a core component for addressing the context length limitations, hallucination issues, and knowledge injection challenges of large models. Because large models typically have context length constraints, we need an effective method to compress, store, and query vast amounts of information. This is where vector models come in. In RAG systems, documents are first converted into vectors. The large model can then rapidly query these vectors to find documents relevant to the current context, and generate responses based on those documents.
However, most current open-source vector models only support a maximum input length of 512 (roughly 500 Chinese characters), preventing developers from representing the semantics of long-form text. jina-embeddings-v2 supports a maximum input length of 8K, breaking through the bottleneck of long-text vector representation. This gives developers more freedom to create complete representations of textual information at varying semantic granularities, enabling more precise semantic expression. This not only helps developers improve the accuracy of large model responses in RAG scenarios, but also applies to various long-text processing use cases, such as handling multi-page report summaries and long-form story recommendations.
Comparison Testing with text-embedding-ada-002
Compared to OpenAI's text-embedding-ada-002, jina-embeddings-v2 demonstrates considerable strength. The table below shows a performance comparison between the two models.
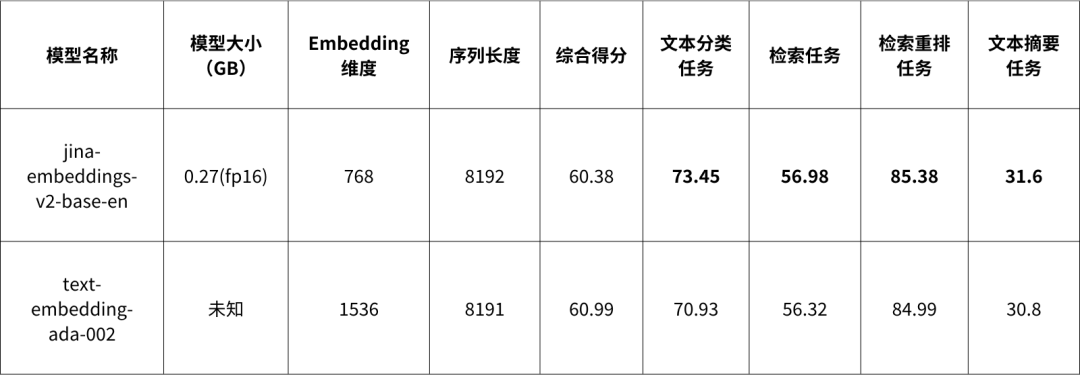
Notably, jina-embeddings-v2 outperforms text-embedding-ada-002 on text classification, retrieval, retrieval re-ranking, and text summarization tasks.
Embracing Open Source
OpenAI has already demonstrated the potential of 8K context length models, but jina-embeddings-v2 not only keeps pace with it — it goes a step further with a bolder decision: completely open-source! This means anyone can use, modify, and further optimize this model.
Moreover, when compared directly with OpenAI's model, jina-embeddings-v2 shows superior performance on multiple key metrics. Given that jina-embeddings-v2 is open-source, we firmly believe that through the collective intelligence and effort of the community, we will have the opportunity to surpass the current benchmark.
Precisely because we believe in the value of openness and sharing, we hope to work together with researchers, engineers, and AI enthusiasts worldwide to continuously refine and advance this model. We also plan to expand its capabilities going forward, such as adding support for more languages and developing a more powerful API platform.
Features and Advantages
The release of this new vector model once again proves our commitment to technological innovation. jina-embeddings-v2 is not a simple revision of its predecessor, but a completely new design born from in-depth R&D and optimization. Our team invested considerable effort — from data collection and processing to model tuning — enabling the v2 model to achieve a qualitative leap in performance.
Furthermore, jina-embeddings-v2's support for 8K input length gives it clear advantages over other leading vector models in long-text tasks, highlighting the practical value of extended context length. This characteristic also opens up more possibilities for many real-world applications, such as legal document interpretation, medical literature research, in-depth literary analysis, financial data insights, and chatbot response optimization.
For developers and researchers looking to use jina-embeddings-v2, we offer two model sizes on the Hugging Face platform to accommodate different scenarios and needs:
jina-embeddings-v2-base-en
- Size: 0.27G (fp16), 0.54G (fp32)
- Parameter count: 137 million
- Use case: Suitable for large-scale tasks requiring high precision
- Download link: https://huggingface.co/jinaai/jina-embeddings-v2-base-en
jina-embeddings-v2-small-en
- Size: 0.07G
- Parameter count: 33 million
- Use case: Specially designed for lightweight application scenarios, such as mobile applications or tasks on devices with limited computing power
- Download link: https://huggingface.co/jinaai/jina-embeddings-v2-small-en
Reflecting on this release, Dr. Han Xiao, Founder and CEO of Jina AI, said:
"In today's rapidly evolving AI landscape, staying at the forefront and making our latest research accessible to the public is our core pursuit. With jina-embeddings-v2, we've reached a significant milestone. We've not only developed the world's first open-source model with 8K context length, but its performance can also match industry giants like OpenAI. Jina AI's goal is clear: we want to democratize AI so that more people can access and benefit from it, not just large companies with abundant resources. Today, I can say with pride that we've taken a solid step toward this vision."
Looking Ahead
Jina AI deeply believes in the magic of open source and is committed to building cutting-edge, accessible tools for the AI community. Going forward, we will push forward with several important initiatives:
- Sharing academic results: To help the community better understand the performance and characteristics of jina-embeddings-v2, the team will soon publish a detailed academic paper delving into the model's technical details and comparative analysis with other models.
- API platform: We are working hard to build an embedding API platform with functionality similar to OpenAI's, helping users more easily use our vector models according to their needs.
- Multilingual support: Jina AI is working to introduce multilingual capabilities. Our next step is to launch German/English and Chinese/English bilingual models, further enhancing our model's capabilities.





