Speed Up LLM Apps 100x With Just a Few Lines of Code! How Yunqi Capital Helps Large Models Cut Costs and Boost Performance | Riding the AGI+ Wave

Who's Helping Large Models Cut Costs and Boost Speed?
To be updated)

How Our Portfolio Company Built a ChatGPT Caching Layer in Two Weeks
After OpenAI announced ChatGPT's web browsing capability, it listed six vector databases capable of effective retrieval. Both Zilliz and Milvus (the vector database developed by Zilliz) made the cut, invited to become inaugural partners.
Vector databases are becoming standard infrastructure for large model applications. To date, Milvus has earned the trust of over a thousand enterprise users worldwide, including NVIDIA, eBay, Shopee, Walmart, Kuaishou, and IKEA, with its largest deployments exceeding one billion vectors.
In 2017, Yunqi Capital led Zilliz's angel round and has continued to invest in subsequent rounds. A partner at Yunqi Capital stated: "We believe in and are bullish on Zilliz's potential to become a standout in open-source infrastructure software and a driving force in AGI application development, thanks to its breakthrough innovations, deep industry expertise, and global perspective." The following content is from the WeChat account "QbitAI" (ObitAI)
**ChatGPT went viral, so why haven't large models seen widespread adoption?
The answer is simple: performance and cost constraints.
Recently, one project has drawn industry attention and discussion —** GPTCache (https://github.com/zilliztech/GPTCache).
It uses vector database technology to provide a semantic caching layer for various LLM applications, storing LLM responses to dramatically reduce retrieval time, lower API call costs, and improve application scalability.
Put simply, with GPTCache, LLM applications previously constrained by performance optimization and costs can break free from these shackles, truly achieving savings in money, time, and effort.
AIGC folks, rejoice!

And the mastermind behind it is Zilliz — a global leader in vector databases.
As early as 2019, it open-sourced Milvus, the world's first vector database project, which now serves over 1,000 enterprise users globally.
Last November, it launched Zilliz Cloud (https://zilliz.com/cloud), a fully managed vector database service. Its release immediately garnered widespread attention and adoption from LLM and AI developers worldwide.
Just last month, NVIDIA's Jensen Huang gave it a strong endorsement at GTC 2023. It was also officially designated by OpenAI as a technology provider for the ChatGPT Retrieval Plugin.
So what exactly is this project? And why did Zilliz build it? To answer these questions, we spoke with Xiaofan Luan, Zilliz partner and technical director, who leads the GPTCache project. He shared the story behind it.

** Born from a Lunchtime Chat **GPTCache's origins trace back to a casual conversation over lunch.
Before diving in, some context. My team is responsible for developing and maintaining the open-source project Milvus. We frequently answer questions from community users, often fielding basic documentation queries and repeat questions. With new users constantly joining, this created a loop of "ask, answer, ask again, answer again." From the users' perspective, Q&A isn't always synchronous or instant (despite our best efforts, 24/7 availability remains elusive). During urgent situations, they might not get timely, useful responses at all.
This is how OSSChat came about. As an integrator of open-source project knowledge bases, it builds on ChatGPT to help users solve various problems with open-source projects on GitHub — documentation lookups, installation guides, and other fundamental questions.

After OSSChat launched, we were thrilled — this was an application that could truly benefit developers everywhere. But the team soon faced a new challenge: as OSSChat's user base grew, we realized ChatGPT itself could become a bottleneck hindering OSSChat's performance.
**First, ChatGPT's instability dragged down OSSChat's response times.
Second, every ChatGPT API call incurred fresh costs, steadily driving up OSSChat's operating expenses.**
This also confirmed a hypothesis I'd held: Why, despite ChatGPT's explosive popularity, haven't LLMs achieved truly widespread adoption? The answer lies in performance and cost constraints — or rather, performance and cost are the chief culprits preventing LLMs from scaling, gaining traction, and growing their user base.
Back to OSSChat: how to boost performance while cutting costs became an urgent problem. The team was so preoccupied with finding a solution that meals became joyless affairs.
So I instituted a rule: no work talk during lunch. One day, as usual, the team was shooting the breeze. You know how it goes when programmers gather — three topics: computers, real estate, and kids. The conversation drifted to the evolution of computing: under von Neumann architecture came CPU, memory, controllers... As CPU and memory speeds diverged, multi-level caches emerged above the CPU. The analogy to the AI era was obvious: large models are the new CPU, vector databases the memory. When system performance lags...
That's it! The cache layer! When system performance lags, the importance of a cache layer becomes self-evident!
So why not add a caching layer to store LLM-generated responses? This would simultaneously improve OSSChat's response speed and reduce costs.
And that's how GPTCache was born.

**How Feasible Is an LLM Cache Layer?
** The idea of an LLM cache layer opened up more possibilities. GPTCache's logic resembles how we historically added Redis and Memcache layers to accelerate system queries and reduce database access costs. With a cache layer, testing OSSChat features no longer required additional ChatGPT API calls — saving time and effort, plain and simple.
However, traditional caches retrieve data only when keys match exactly, which doesn't work for AIGC applications.
AIGC requires semantically approximate caching. "Apple phone" and "iPhone" refer to the same thing, after all.
So we needed to design and build an entirely new cache specifically for AIGC applications — we named it GPTCache.
With it, we can perform vector similarity searches across millions of cached query vectors and extract cached responses from the database. This significantly reduces OSSChat's end-to-end average response time while cutting costs.
In short, it accelerates ChatGPT response speeds and optimizes semantic retrieval. With GPTCache, users need only modify a few lines of code to cache LLM responses, speeding up LLM applications by over 100x.
Of course, at this stage GPTCache remained a concept. Its feasibility needed validation. The team conducted multiple rounds of research on OSSChat. After several investigations, we found users indeed favored asking certain types of questions:
- Hot topic content
- Popular GitHub repos
- Basic "what is xxx" questions
- OSSChat homepage recommended questions
This meant AIGC application user access, like traditional applications, exhibits temporal and spatial locality. Thus, caching could perfectly reduce ChatGPT call frequency.
 Why Not Redis? **After validating feasibility came system construction. Here's a crucial point: Redis was not our first choice for building the ChatGPT caching system.
Why Not Redis? **After validating feasibility came system construction. Here's a crucial point: Redis was not our first choice for building the ChatGPT caching system.
Personally, I love Redis — it's performant, flexible, and suits various applications. But Redis's key-value data model cannot query approximate keys.
If users ask these two questions:
What are the pros and cons of all deep learning frameworks? Tell me about the differences between PyTorch vs. TensorFlow vs. JAX?
Redis would treat them as distinct questions. Yet they express the same intent. Whether caching entire questions or just tokenizer-generated keywords, Redis cannot achieve cache hits.
Different words in natural language may share identical meanings; deep learning models excel at handling semantics. Therefore, we should incorporate vector similarity search into our semantic caching system.
Cost is another reason Redis doesn't suit AIGC scenarios. The logic is straightforward: longer context means longer keys and values, and Redis storage costs can become prohibitively expensive. Thus, disk-based databases may be preferable for caching. Plus, since ChatGPT responses are slow, cache response speed requirements aren't particularly stringent.
 Building GPTCache from Scratch **Without further ado, here's the GPTCache architecture diagram:
Building GPTCache from Scratch **Without further ado, here's the GPTCache architecture diagram:
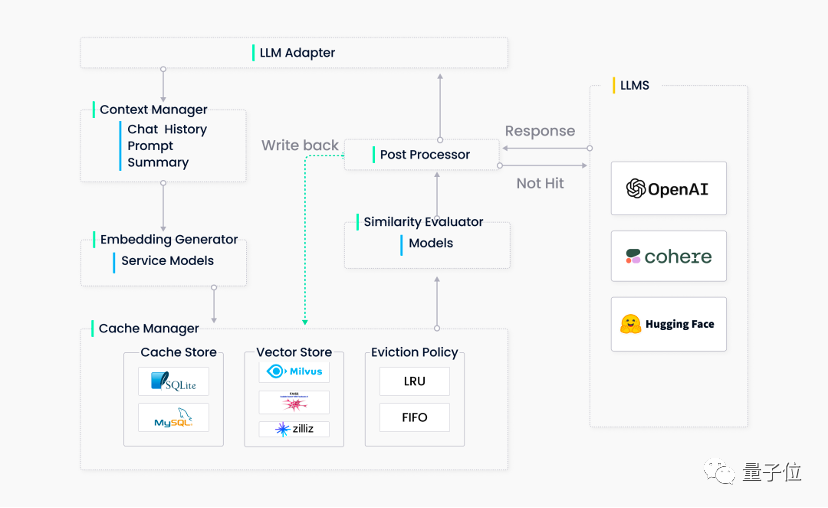
**To simplify the workflow, we ultimately decided to remove the context manager. The complete GPTCache system comprises five main components:
- LLM Adapter
The adapter converts LLM requests into cache protocols and converts cache results into LLM responses. Since we wanted GPTCache to be transparent (so users could easily integrate it into our system or other ChatGPT-based systems without additional development), the adapter should easily integrate all LLMs and flexibly extend to support more multimodal models in the future.
Currently, we've completed adapters for OpenAI and LangChain. Going forward, GPTCache's interfaces can further expand to access more LLM APIs.
- Embedding Generator
The embedding generator converts user queries into embedding vectors for subsequent similarity search. To meet diverse user needs, we currently support two embedding generation methods. The first generates embedding vectors through cloud services (such as OpenAI, Hugging Face, and Cohere). The second generates embedding vectors using local models on ONNX.
Going forward, GPTCache also plans to support PyTorch embedding generators to convert images, audio files, and other unstructured data types into embedding vectors.
- Cache Manager
The cache manager is GPTCache's core component with three functions:
Cache storage: storing user requests and corresponding LLM responses
Vector storage: storing embedding vectors and retrieving similar results
Eviction management: controlling cache capacity and clearing expired data according to LRU or FIFO policies when full
The cache manager uses a pluggable design. Initially, the team implemented SQLite and FAISS on the backend. Later, we expanded the cache manager to include MySQL, PostgreSQL, Milvus, and others.
The eviction manager frees memory by removing old, unused data from GPTCache. When necessary, it deletes data from both cache and vector storage. However, frequent deletion operations in vector storage systems can degrade performance. So GPTCache only triggers asynchronous operations (such as index building, compaction, etc.) when deletion thresholds are reached.
- Similarity Evaluator
GPTCache retrieves the top-K most similar answers from its cache and uses a similarity evaluation function to determine whether cached answers match the input query.
GPTCache supports three evaluation functions: exact match, embedding distance, and ONNX model evaluation.
The similarity evaluation module is equally crucial for GPTCache. After research, we ultimately adopted a fine-tuned ALBERT model. Of course, there's still room for improvement here — other language models or LLMs (such as LLaMa-7b) could also be used. Interested contributors, reach out!
- Post Processors
Post processors organize the final response returned to users. They can return the most similar response or adjust response randomness based on the request's temperature parameter. If no similar response is found in cache, post processors forward the request to the LLM to generate a response, which is then stored in cache.
Evaluation Next came the critical step of validating results! To evaluate GPTCache's performance, we selected a dataset containing three types of sentence pairs: positive samples with identical semantics, negative samples with related but not identical semantics, and intermediate samples with completely unrelated semantics.
Experiment 1
To establish baseline, we first stored 30,000 positive sample keys in cache. Then we randomly selected 1,000 samples and used their corresponding 1,000 paired sentences as queries.
Here are our results:

**We found that setting GPTCache's similarity threshold at 0.7 nicely balances hit rate and negative correlation ratio. Therefore, this setting was applied to all subsequent tests.
We used ChatGPT-generated similarity scores to determine whether cached results were relevant to queries. Setting the positive sample threshold at 0.6, we used the following prompt to generate similarity scores:

**(Note: The above prompt is a Chinese translation. For the original, see: https://zilliz.com/blog/Yet-another-cache-but-for-ChatGPT)
Experiment 2
Conducting queries with 50% positive and 50% negative samples, running 1,160 requests yielded these results:

**The hit rate nearly reached 50%, with negative sample ratios in hits similar to Experiment 1. This demonstrates GPTCache's strength in distinguishing relevant from irrelevant queries.
Experiment 3
Inserting all negative samples into cache and using their paired sentences as queries. Although some negative samples received high similarity scores (ChatGPT rated their similarity above 0.9), none hit cache. This may be because the model used in our similarity evaluator was fine-tuned on this dataset, so almost all negative samples received reduced similarity scores.
These represent the team's typical experiments. Currently, we've integrated GPTCache into the OSSChat chatbot and are actively collecting statistics from production environments. I'll release a benchmark report with real-world use cases — stay tuned!
For future plans, the team is working to integrate more LLM models and vector databases into GPTCache. Additionally, GPTCache Bootcamp is launching soon. Through bootcamp, you'll learn how to incorporate GPTCache when using LangChain, Hugging Face, and more, plus how to integrate GPTCache into other multimodal application scenarios.

One More Thing
In just two weeks, we built and open-sourced GPTCache. To me, this is remarkable, made possible by every team member's dedication. From them, I've repeatedly felt the drive of developers as a community and their belief in "technology changing the future" — it's deeply moving.
To developers beyond our team, I also have something to say. The purpose of this share is to offer an AIGC practitioner's perspective on developers' "zero to one" and "one to hundred" exploration journey and insights under the wave led by ChatGPT, hoping to spark discussion and mutual inspiration.
Of course, most importantly, I hope developers will participate in building GPTCache together. As a newborn, it has much to learn; and as a project born for open source, it needs your suggestions and corrections.
GitHub link:
https://github.com/zilliztech/GPTCache
Click "Read Original" or copy the link to join the GPTCache open-source project! (Absolutely, definitely remember to manage cache capacity!)









