MiniMax Open-Sources Ultra Cost-Effective Reasoning Model, With Four Days of Back-to-Back Releases Ahead | Yunqi Capital

Innovation never stops.

Innovation never stops evolving. A month after rolling out voice models and the Orsta series, Yunqi Capital portfolio company and large-model unicorn MiniMax announced it would release major updates for five consecutive days. The opening salvo: MiniMax-M1, its first open-source reasoning model.
This is also the world's first open-source large-scale hybrid-architecture reasoning model, surpassing or matching DeepSeek-R1, Qwen3, and other open-source models on multiple benchmarks. And thanks to two major technical innovations, MiniMax-M1 achieves industry-leading computational efficiency — serious bang for the buck. Here's the breakdown in this edition of "Yunqi Capital Partner."
Yunqi Capital portfolio company and large-model unicorn MiniMax open-sources its latest reasoning model.
On June 17, MiniMax released MiniMax-M1, the world's first open-source large-scale hybrid-architecture reasoning model, and announced four more consecutive updates over the following workdays.
According to MiniMax, M1 ranks in the top tier of open-source models for productivity-oriented complex scenarios, outperforming domestic closed-source models and approaching the most advanced overseas models, all while remaining highly cost-effective.
Long-context capability is one of M1's standout strengths. It supports up to 1 million tokens of context input — the highest in the industry, 8x that of DeepSeek-R1, and on par with the closed-source Google Gemini 2.5 Pro — with a reasoning output ceiling of 80,000 tokens, the longest available.
"Unlimited long-context capability is a critical dimension that the MiniMax team has been refining," said Yunqi Capital partner Yu Chen at the Waves 2025 conference forum in mid-June. "It's crucial technology for social applications, emotional companionship apps, and agents."
MiniMax-M1's long-context prowess stems from a key technical innovation — a hybrid architecture centered on Lightning Attention. This architecture gives M1 standout computational efficiency advantages for both long-context input and deep reasoning. MiniMax notes that when performing deep reasoning with 80,000 tokens, M1 requires only about 30% of the compute used by DeepSeek-R1.
The second major innovation is the reinforcement learning algorithm CISPO, which improves RL efficiency by clipping importance sampling weights (rather than traditional token updates). Combined with the hybrid architecture breakthrough, this enabled M1's highly efficient reinforcement training process. Tech media outlet QbitAI reported that the MiniMax team revealed the RL training phase took just three weeks, 512 H800 GPUs, and only $534,700 (about ¥3.839 million) in rental costs.
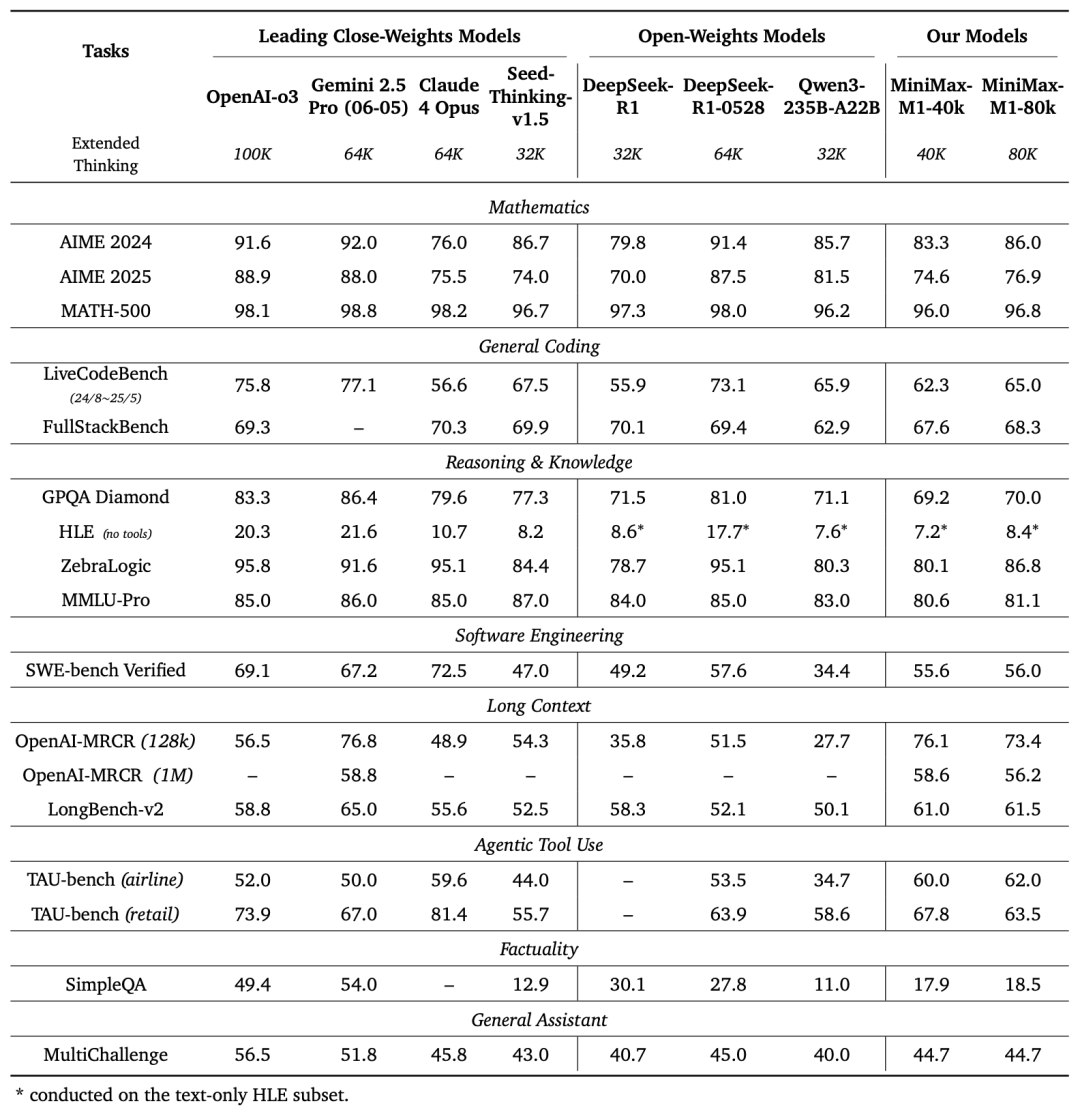
- M1's results on 17 mainstream industry benchmarks
Building on this relatively efficient training and inference compute, MiniMax announced that M1 remains unlimited and free to use on the MiniMax app and web, with API pricing at the industry's lowest rates on its official website — offering users a more cost-effective solution than DeepSeek-R1.
Winds change, but patterns endure. Even as the AI industry shifts by the day, opportunity belongs to the pragmatic doers who keep pushing technological boundaries. Stay tuned for more updates from MiniMax over the next four days, and look forward to more AGI innovation from the team!





