MiniMax Releases Next-Generation Voice Model, Claiming Top Spots on Two Global Benchmarks | Yunqi Capital

Recently, **Yunqi Capital portfolio company MiniMax**, a leading domestic AI model startup, released its next-generation text-to-speech system **MiniMax Speech-02**, which **ranked first on both** the authoritative international benchmarking platforms Artificial Analysis Speech Arena and Hugging Face TTS Arena, comprehensively surpassing Ope

Recently, Yunqi Capital portfolio company MiniMax, a leading domestic model startup, released its next-generation text-to-speech system MiniMax Speech 02, which ranked first on both the international benchmarking platforms Artificial Analysis Speech Arena and Hugging Face TTS Arena, surpassing mainstream models from OpenAI, ElevenLabs, and others.
Thanks to its "learnable timbre extractor" and flexible architecture design, MiniMax achieved breakthroughs in audio quality, expressiveness, and generation cost. In this edition of "Yunqi Capital", we bring you the details.
First Place on Both Global Benchmarks
Built on an AR Transformer architecture with strong generalization capabilities, the model supports speech synthesis in 32 languages, with different accents and emotions, and features Zero-Shot high-fidelity voice cloning.
On two global authoritative speech benchmarks — Artificial Analysis Speech Arena and Hugging Face TTS Arena — MiniMax Speech (listed as Speech-02-HD) surpassed top-performing models worldwide including OpenAI and ElevenLabs, taking first place on both.
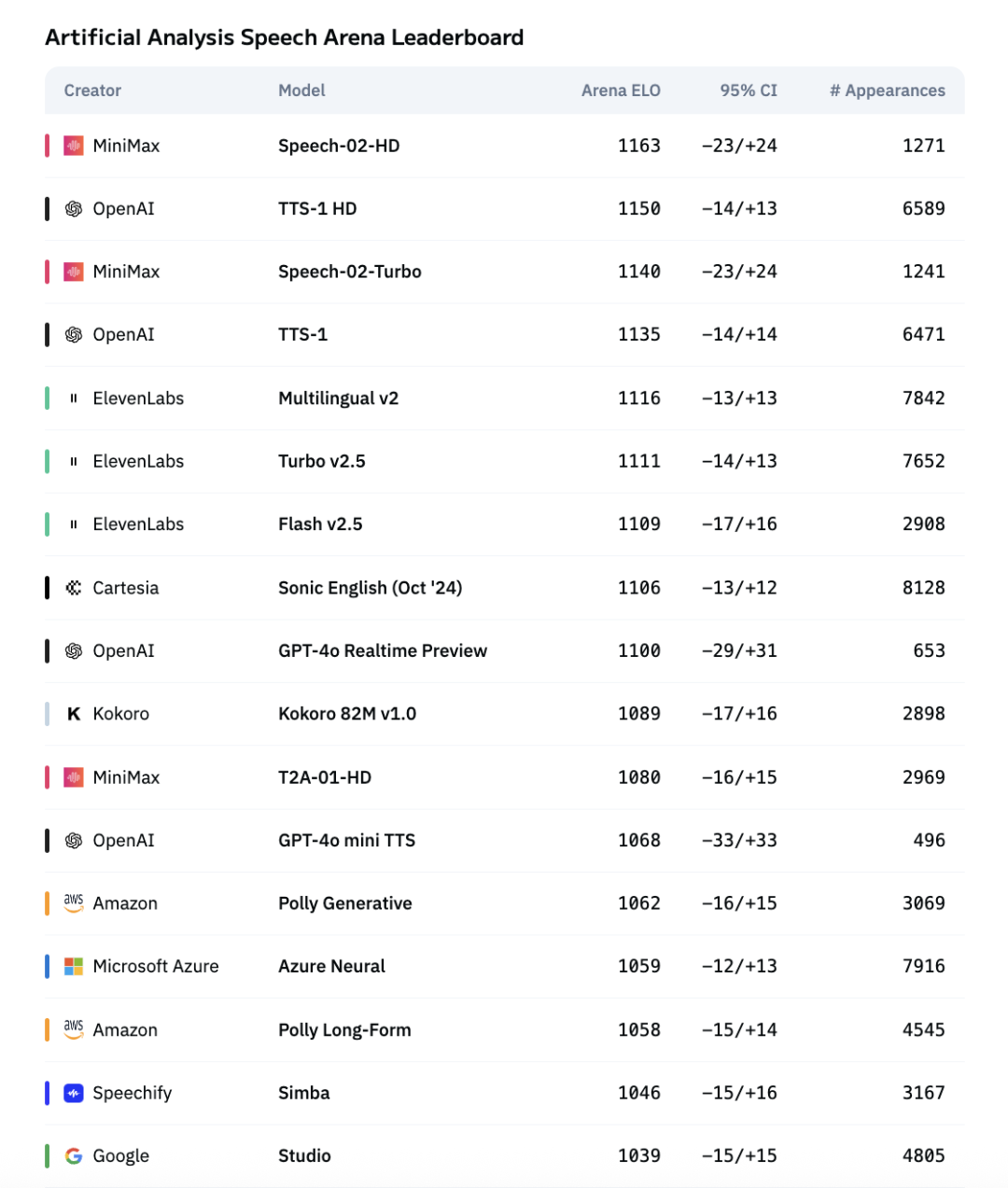
Artificial Analysis Speech Arena benchmark rankings
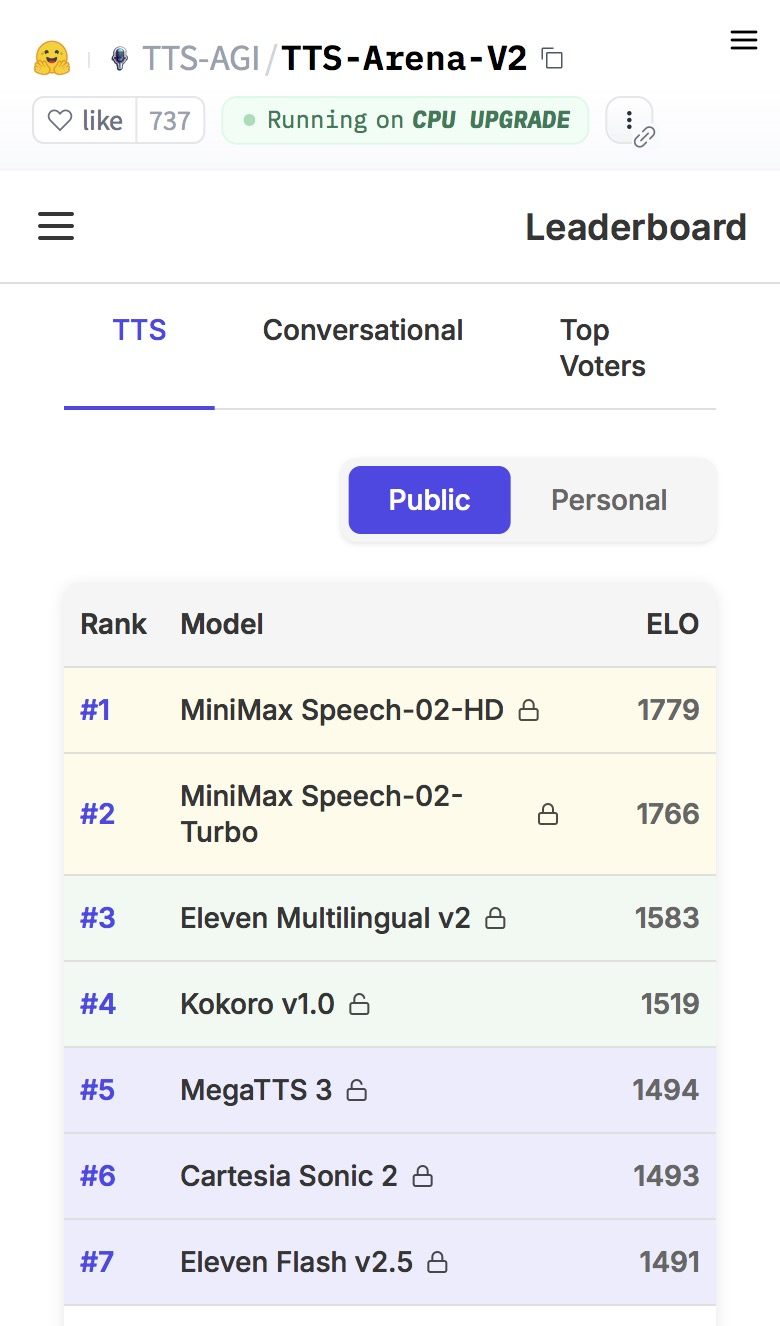
Hugging Face TTS Arena benchmark rankings
While delivering superior audio quality, MiniMax Speech 02 also comes at a lower price — half that of ElevenLabs Flash V2.5 and one-quarter that of Multilingual V2.
Architectural Flexibility
MiniMax revealed that its "learnable timbre extractor" is essentially a speaker encoder, which can convert audio clips of any length into fixed-size conditional vectors, enabling high-quality, flexible voice expression.

MiniMax explains: First, Zero-Shot enables hyper-realistic voice timbre — only a reference audio clip is needed, with no corresponding text required, and the output rivals human speech while being more consistent than a real person. Second, because the speaker encoder can be trained on all languages covered in the training dataset, MiniMax Speech inherently supports 32 languages with superior cross-lingual performance. Finally, because the conditional vectors produced by the speaker encoder are themselves disentangled, this gives MiniMax Speech flexibility for downstream applications, enabling features such as flexible emotional expression in any voice, voice generation from text descriptions, and enhanced cloning for specific speakers.
Multilingual Benchmark
High-Quality Synthesis in 32 Languages
MiniMax Speech supports synthesis in 32 languages. To evaluate its multilingual performance, MiniMax built a dedicated test set and conducted comparative evaluations against ElevenLabs' multilingual_V2.
The results show that on the SIM (Speaker Similarity) metric, MiniMax Speech 02 outperformed ElevenLabs across all languages; this indicates that MiniMax Speech 02 demonstrates stronger multilingual expressiveness under Zero-Shot conditions. Additionally, MiniMax Speech 02 showed excellent accuracy in major European and American languages including English, French, Italian, and Portuguese. By contrast, ElevenLabs' word error rate exceeded 10% on several Asian languages such as Cantonese, Thai, Vietnamese, and Japanese. This fully demonstrates that MiniMax Speech is more robust and reliable in multilingual adaptation.
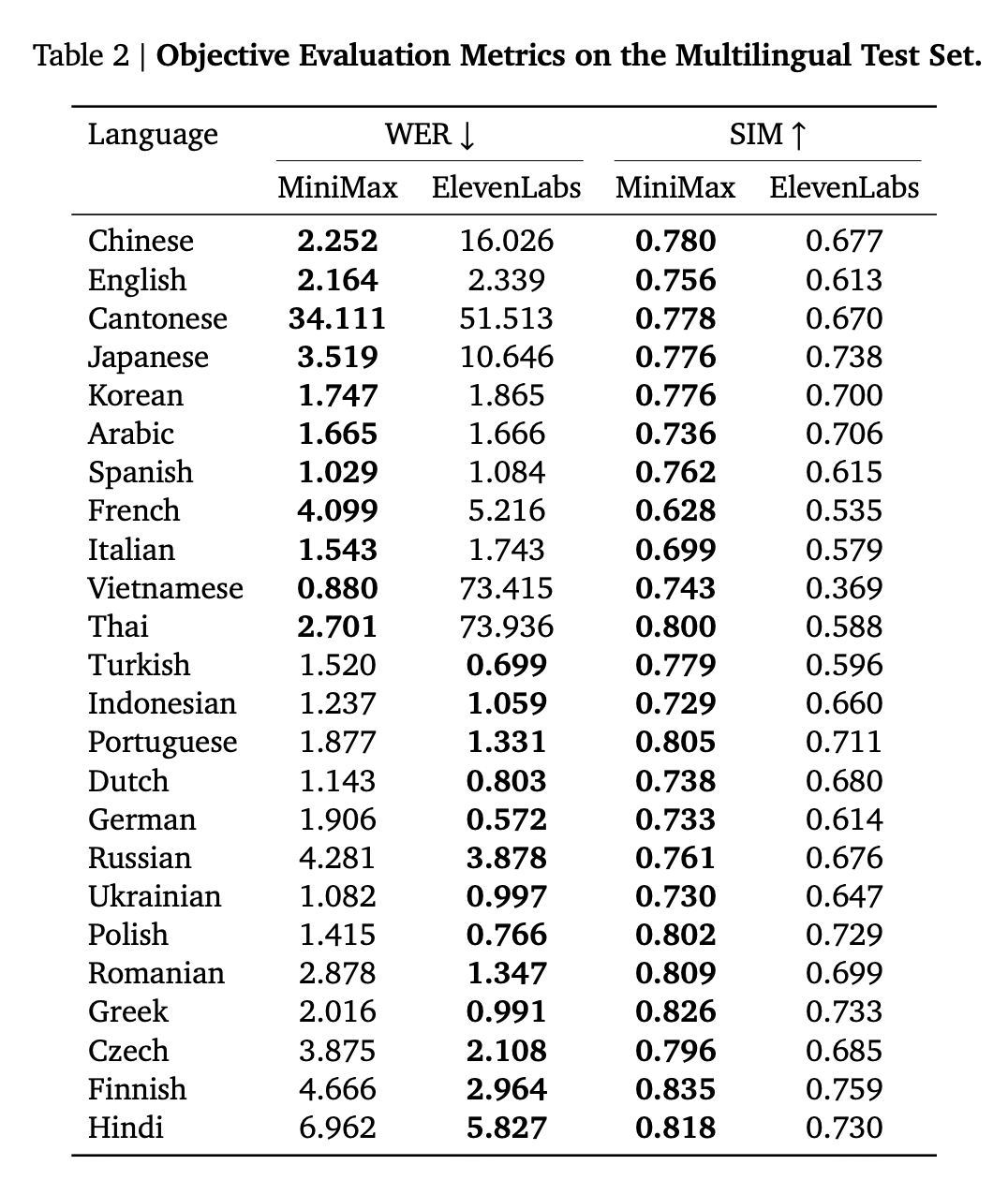
Enhancing Voice Quality
To optimize the texture of generated speech, MiniMax revealed that it uses Flow-VAE to compress audio into latent features, then models these latent features with a Flow Matching model. The combination of both enables MiniMax Speech 02 to express more detail during speech generation, delivering higher audio quality and greater speaker similarity in perceptual listening tests.
We look forward to MiniMax further improving model controllability and efficiency, using AI to bring multilingual voices to the world with the most authentic local pronunciation, so that every language globally is heard and every culture is understood.
MiniMax Open Platform: https://www.minimaxi.com/platform MiniMax Open Platform (International): https://www.minimaxi.com/en/platform
For more technical details, experimental comparisons, and the open-source multilingual test set, please see the technical report:
GitHub: https://github.com/MiniMax-AI/MiniMax- Hugging Face: https://huggingface.co/spaces/MiniMaxAI/MiniMax-Speech-Tech-Report





