MiniMax Drops New Model: New Architecture, and It's Open Source | Yunqi Capital

Becoming the "Ready Player One" of the Agent Era

On January 15, MiniMax — a Yunqi Capital angel-round portfolio company and a leading domestic large-model startup — released and open-sourced its MiniMax-01 series, comprising the foundation language model MiniMax-Text-01 and the vision multimodal model MiniMax-VL-01.
The new series marks significant advances in long-context capabilities — a "must-have" for complex Agents — and innovatively adopts a brand-new model architecture. Thanks to architectural innovations and other factors, MiniMax's text and multimodal understanding API pricing also hits the industry's lowest range. Read on with this edition of "Yunqi Capital" for more details.
On MiniMax's technical roadmap and vision for future model capabilities, founder & CEO Junjie Yan previously shared detailed insights in an in-depth conversation with Yunqi Capital — 👉🏻click here to revisit.
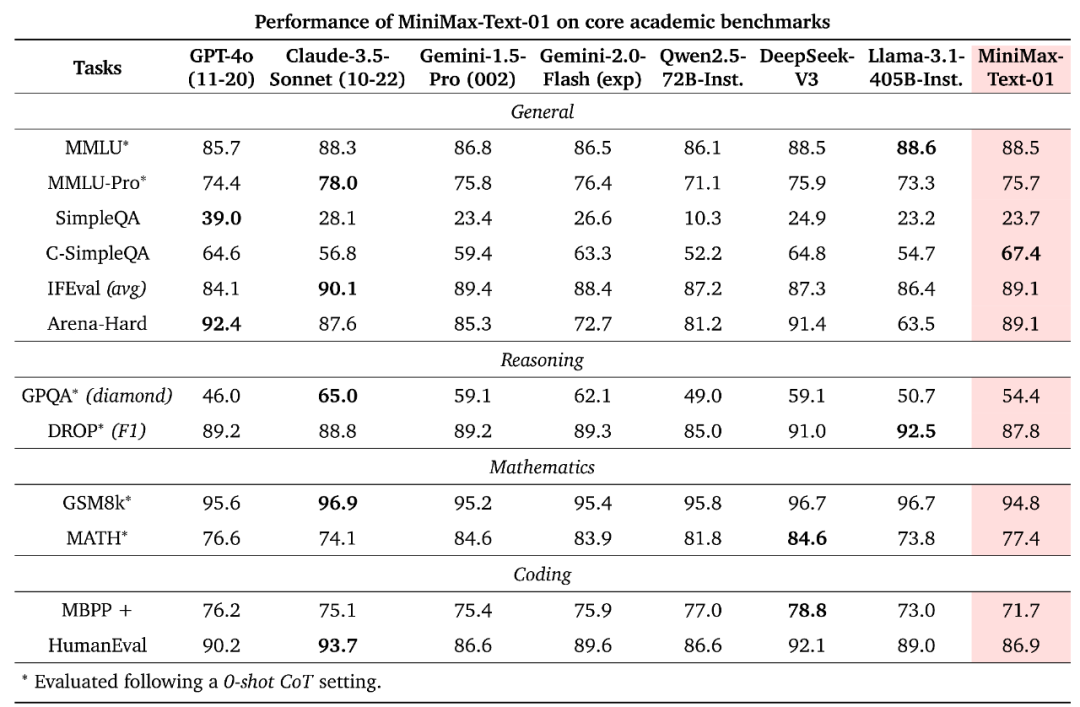
Performance on Par with GPT-4o
Long-Context Processing Leaps Forward
First, a key metric: parameter count. According to MiniMax, the new series boasts 456 billion total parameters, with 45.9 billion activated per forward pass.
Based on mainstream industry benchmarks for text and multimodal understanding, the MiniMax-01 series matches or approaches the two most advanced overseas models — GPT-4o-1120 and Claude-3.5-Sonnet-1022 — on most tasks.
Notably, the new models' long-context capability stands out: efficiently processing contexts up to 4 million tokens globally, 32x that of GPT-4o and 20x that of Claude-3.5-Sonnet. As Agent-based AI applications develop rapidly, advancing long-context capabilities is critical.
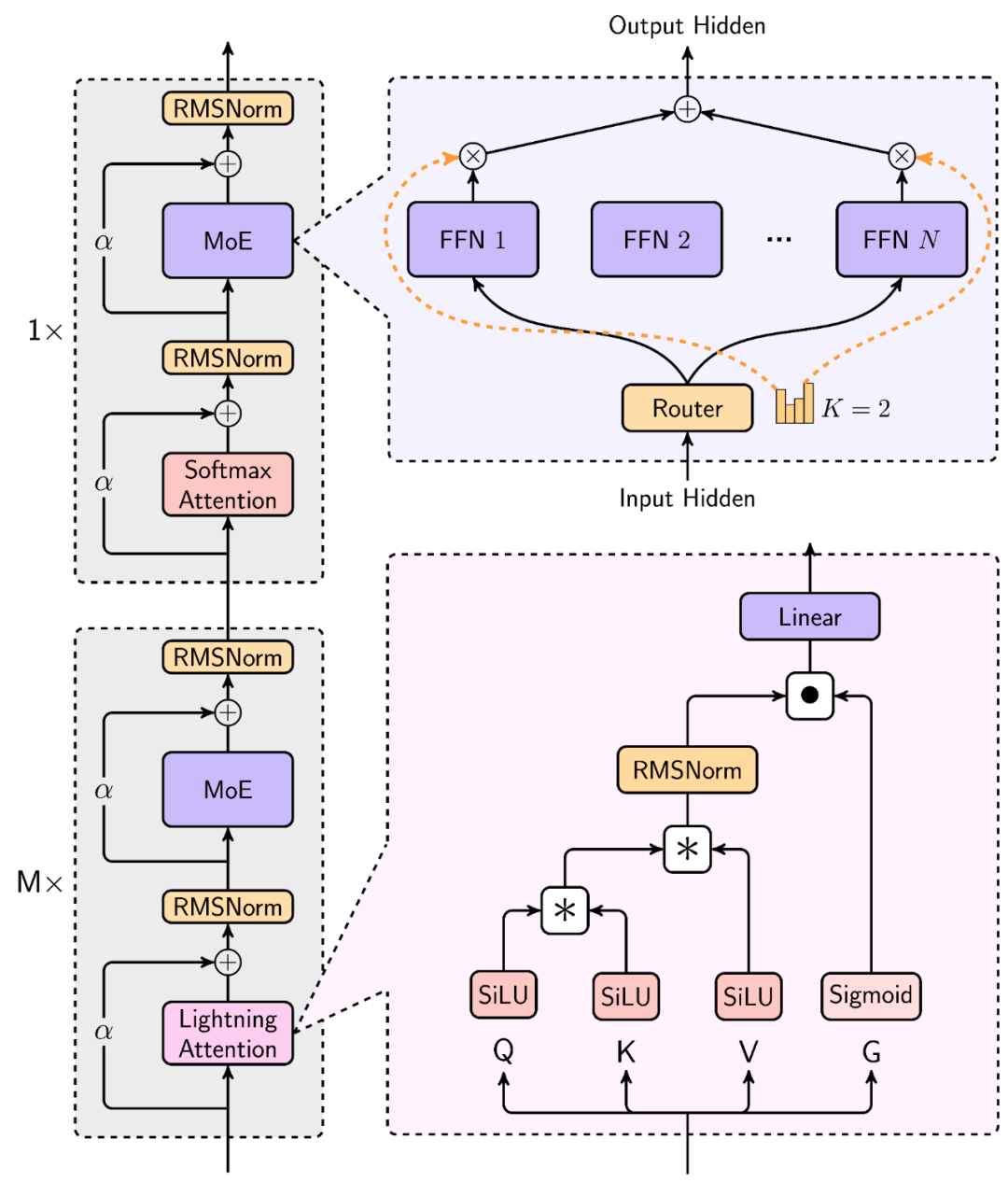
Architectural Innovation
First Large-Scale Commercial Use of Linear Attention
Architecture is another highlight of MiniMax-01. MiniMax has scaled linear attention mechanisms to commercial-model levels, making it the industry's first large-scale model centered on linear attention. Per MiniMax's published architecture, 7 out of every 8 layers use Lightning Attention-based linear attention.
Around this innovation, MiniMax essentially rebuilt its training and inference systems, including more efficient MoE all-to-all communication optimization, longer-sequence optimization, and efficient kernel implementations for linear attention at inference time.
Highly Cost-Effective APIs
Full Model Weights Open-Sourced
MiniMax also announced API pricing for text and multimodal understanding: standard pricing at RMB 1 per million input tokens and RMB 8 per million output tokens. This represents the industry's lowest price range, driven by architectural innovation, efficiency optimization, integrated training-inference cluster design, and extensive internal concurrent compute reuse at MiniMax.
Additionally, MiniMax open-sourced full weights for both new models (https://github.com/MiniMax-AI). "First, we believe this may inspire more long-context research and applications, accelerating the arrival of the Agent era. Second, open-sourcing pushes us to innovate more and conduct higher-quality subsequent model R&D," MiniMax explained.
In a late-2024 in-depth conversation with Yunqi Capital, Junjie Yan noted that whether developing B2B or B2C products, error rates, unlimited-length input/output, and multimodality are all critical metrics for model capability.
Yunqi Capital believes that as Agent, audio-video generation, and other AI application forms develop rapidly, refining "infrastructure-layer" long-context processing and multimodal capabilities is essential. We look forward to the new possibilities that MiniMax's breakthroughs on this front can unlock for application-layer innovation.
New model paper:
https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
MiniMax Open Platform: https://www.minimaxi.com/platform
MiniMax Open Platform (Global): https://www.minimaxi.com/en/platform
The MiniMax-01 series is open-sourced at https://github.com/MiniMax-AI, with ongoing updates to follow.





