Yunqi Capital | MiniMax M2 Goes Open Source, Another Leap for AI Productivity

Built for Agents and Code, at Just 8% the Price of Claude Sonnet

Building on its vision of "Intelligence with Everyone," MiniMax takes another step forward.
Today (October 27), MiniMax released M2, an open-source model purpose-built for agents and coding. At just 8% the price of Claude Sonnet, with 2x the speed — free for a limited time.
From AGI to agents, from dev tools to productivity leaps — another surprise from MiniMax. Here's the details with Yunqi Capital.
The following is adapted from MiniMax.
From Day 1, we've held to our vision: "Let everyone have abundant intelligence" (Intelligence with Everyone).
Today, we're officially open-sourcing and launching MiniMax M2, built for agents and code, at just 8% the price of Claude Sonnet, 2x the speed, free for a limited time.
- Top-tier coding capability: Designed for end-to-end development workflows, with excellent performance in Claude Code, Cursor, Cline, Kilo Code, Droid, and other applications
- Strong agentic performance: Excels at planning and reliably executing complex, long-chain tool-calling tasks, coordinating Shell, Browser, Python executors, and various MCP tools
- Extreme cost-performance & speed: Through efficient activated-parameter design, achieves the optimal balance of intelligence, speed, and cost
Our internal team has been building all kinds of agents to help tackle challenges during the company's rapid growth. These agents are increasingly capable of handling complex tasks — from analyzing online data, researching technical issues, and daily programming, to processing user feedback and even HR resume search and screening.
These agents work alongside our team to drive the company forward, building an AI Native Company, progressing from developing AGI to advancing together with AGI. We've increasingly come to see that AGI is productive force, and agents are an excellent vehicle for it — representing an upgrade from the simple Q&A of conversational assistants to agents independently completing complex tasks.
But we found that no existing model fully met our needs for these agents. The challenge is that a good model must strike the right balance across quality, price, and inference speed — almost an "impossible triangle": the best overseas models can deliver good results, but they're very expensive and relatively slow; domestic models are cheaper, but lag on quality and inference speed.
This has led to existing agent products that prioritize quality being quite expensive or relatively slow. Many agent products charge monthly subscriptions of tens or even hundreds of dollars, and completing a task often takes hours.
We've been exploring whether we could build a model that strikes a better balance across quality, price, and speed — so more people can benefit from the intelligence boost of the agent era, continuing our Intelligence with Everyone vision. This model needs highly diverse capabilities: programming, tool use, reasoning, knowledge, and more. It also needs very fast inference speed and very low deployment costs. That's why we developed MiniMax M2, and open-sourced it.
Looking first at the three most important capabilities for agents — programming, tool use, and deep search — we compared against several mainstream models:
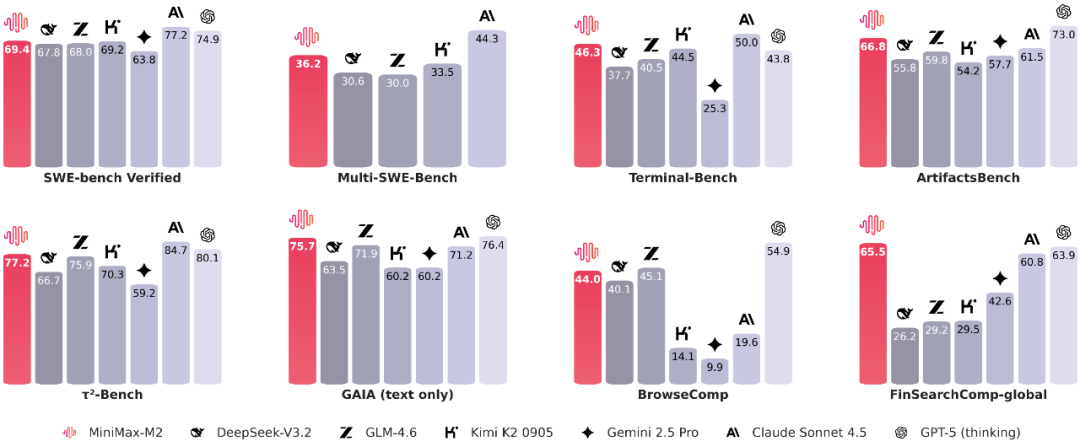
We found that the model's tool-use and deep-search capabilities are very close to the best overseas models. On programming it falls short of the best overseas models, but is already in the top tier domestically.
There are some algorithmic and conceptual improvements here that we'll share in more detail going forward. But the core point is simply this: to build a model that meets these requirements, we first had to use it ourselves. To that end, colleagues from development to business to backend worked alongside our algorithm team, investing significant effort in building environments and benchmarks, and increasingly integrating the model into daily work.
Once we got these complex scenarios right, we found that applying our accumulated methods to traditional LLM tasks — knowledge, math, and so on — naturally yielded very strong results. On Artificial Analysis, a popular benchmark aggregating 10 test tasks, we ranked in the global top five:
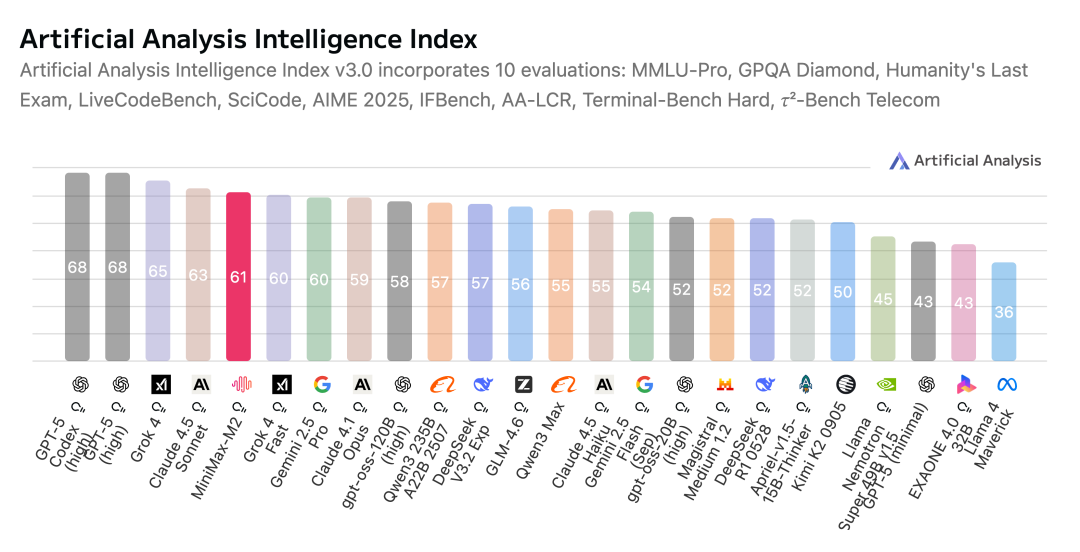
We've set our API pricing at $0.30 per million input tokens / ¥2.10 RMB, and $1.20 per million output tokens / ¥8.40 RMB, while offering online inference service at around 100 TPS (tokens per second, still improving rapidly). This price is 8% of Claude Sonnet 4.5, with nearly double the inference speed.
This past weekend, many enthusiastic developers at home and abroad tested the model extensively with us. To make it easier for everyone to explore its capabilities together, we're extending the free testing period to November 6. We've also open-sourced the full model weights on Hugging Face — interested developers can deploy it themselves, with support already available from both SGLang and vLLM.
At this price and inference speed, we believe M2 represents a very compelling choice among current mainstream models. Here's the analysis from two angles.
First, price vs. quality. The right model should deliver strong results at an accessible price — landing in the green zone below. Here we use the average score across 10 test sets on Artificial Analysis to represent quality:
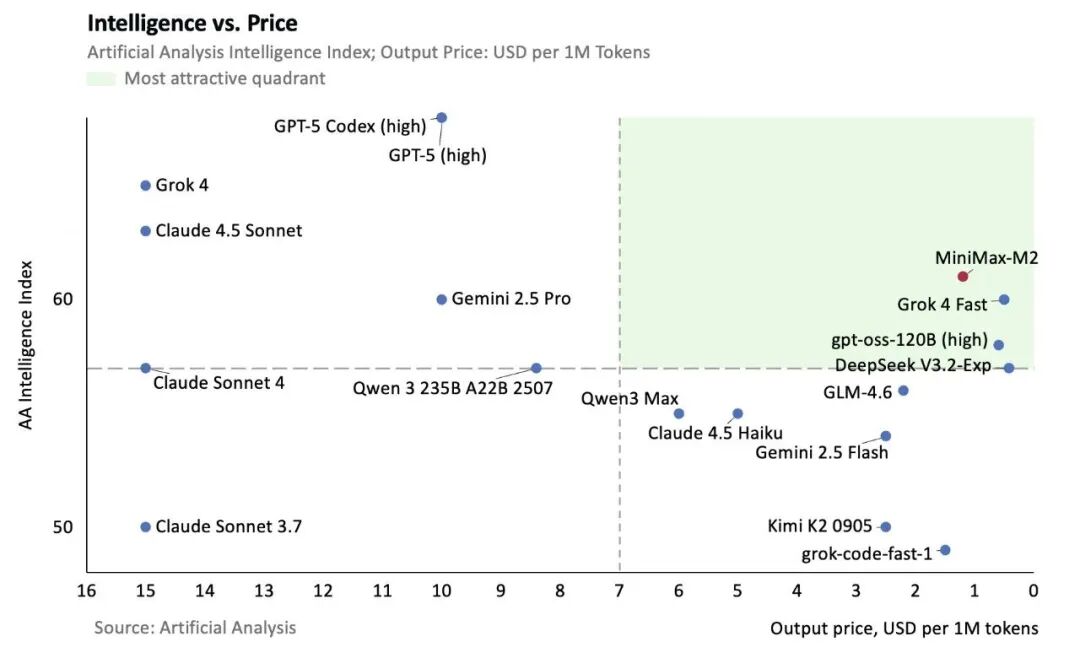
Then, price vs. inference speed. In model deployment, there's often a tradeoff where slower inference can yield lower prices. The right model should be both affordable and fast. Here's our comparison against several representative models:
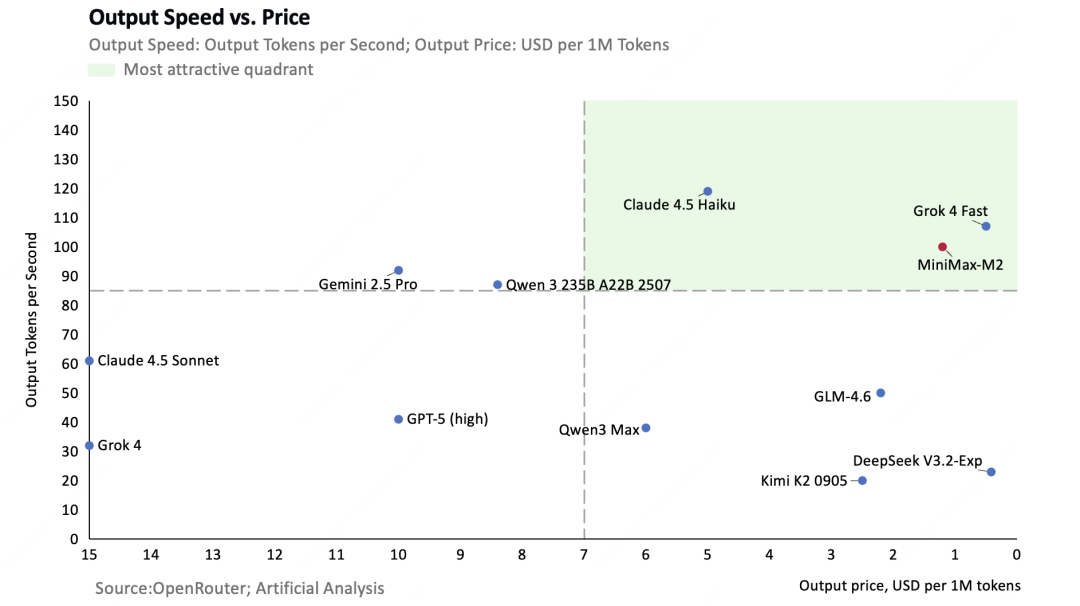
Beyond these standard benchmarks, we also ran 1v1 practical comparisons against Claude Sonnet 4.5 and several open-source models:
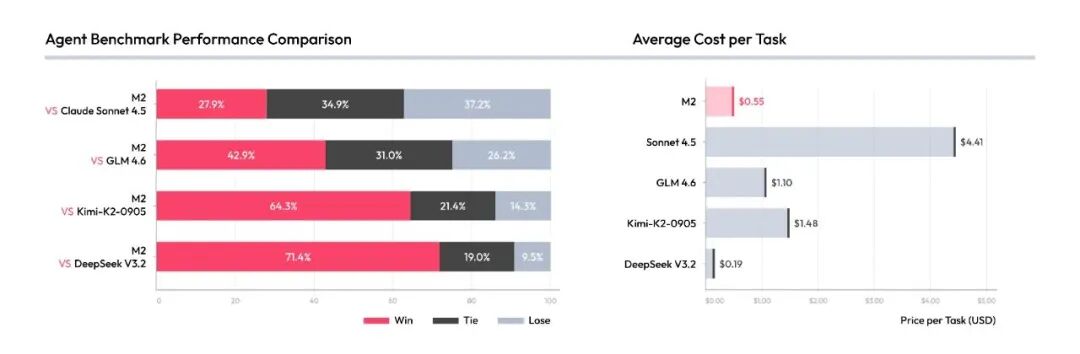
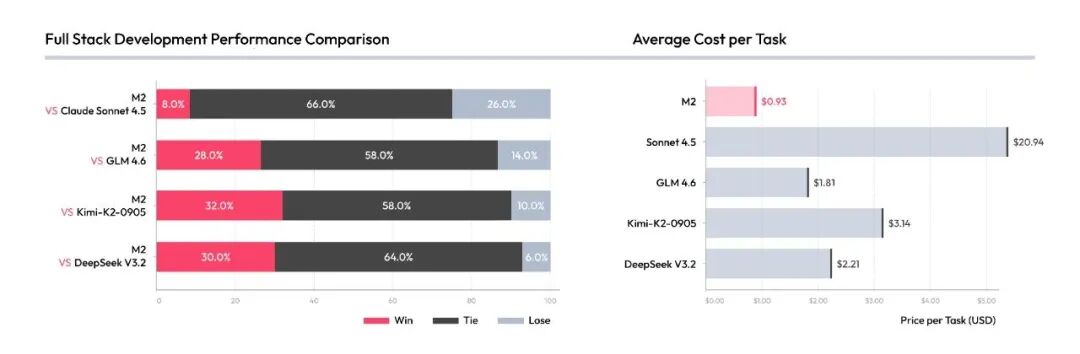
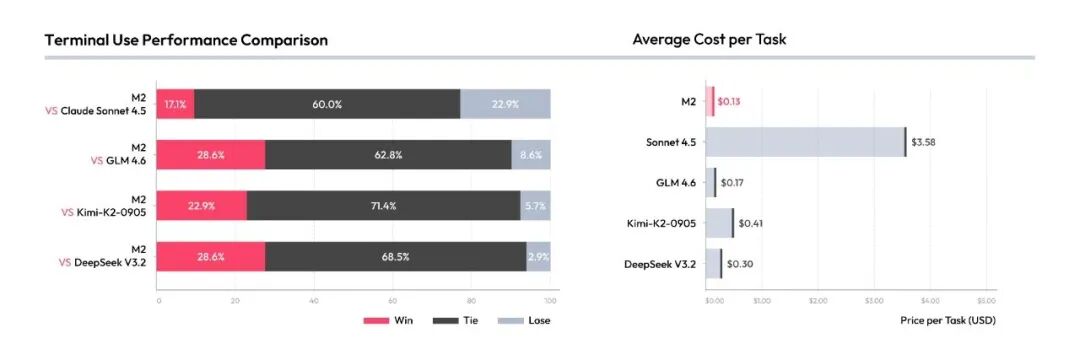
These test sets will be published on GitHub this week.
To make agent capabilities more accessible, we've launched our M2-powered agent product domestically, with an upgraded version for overseas users. In MiniMax Agent, we offer two modes:
- Lightning mode: Highly efficient, ultra-fast agent, with rapid output for conversational Q&A, lightweight search, and lightweight coding scenarios, while upgrading the conversational product experience with strong agentic capabilities.
- Pro mode: Professional agent capabilities, with best-in-class performance on complex long-horizon tasks, excelling at deep research, full-stack development, PPT/report writing, web page creation, and more.
Benefiting from M2's inherent inference speed, the M2-powered agent delivers not only strong cost-performance but also significantly smoother completion times for complex tasks.
We're currently offering MiniMax Agent for free — until our servers can't handle it anymore.
How to use
-
MiniMax Agent, the general-purpose agent product powered by MiniMax-M2, is now fully available and free for a limited time:
-
MiniMax-M2 API is now available on the MiniMax developer platform, free for a limited time:
-
MiniMax-M2 model weights have been open-sourced and can be deployed locally
Local deployment guide
Download model weights from the following Hugging Face repository:
https://huggingface.co/MiniMaxAI/MiniMax-M2
We recommend deploying MiniMax-M2 with vLLM or SGLang.
vLLM: Please refer to the vLLM Deployment Guide.
https://huggingface.co/MiniMaxAI/MiniMax-M2/blob/main/docs/vllm_deploy_guide_cn.md
SGLang: Please refer to the SGLang Deployment Guide.
https://huggingface.co/MiniMaxAI/MiniMax-M2/blob/main/docs/sglang_deploy_guide_cn.md
We recommend the following inference parameters for best performance:
temperature=1.0, top_p = 0.95, top_k = 20
Tool calling guide: Please refer to the Tool Calling Guide
https://huggingface.co/MiniMaxAI/MiniMax-M2/blob/main/docs/tool_calling_guide_cn.md
Intelligence with Everyone.





