MiniMax Founder Junjie Yan: First Principles on the Path to AGI | Yunqi Capital

What really needs to be done is to make technology and product iterate fast enough.
The AI industry is getting more "cutthroat" by the day. How do first-tier LLM founders see it?
Recently, MiniMax founder Junjie Yan, whose company received angel-round investment from Yunqi Capital, sat down with GeekPark to discuss the real challenges facing the AI industry. His responses reveal the calm beneath the noise at this high-profile startup, and point to the "first principles" he keeps returning to: user satisfaction, penetration rate, and technological progress.
This aligns with Yunqi Capital partner Chen Yu's first impression of Yan: "A very rounded person." When they first met in 2021, they discussed not just technology but commercialization too. Yunqi Capital went on to become the only early-stage institution in MiniMax's angel round, accompanying the company as it advanced on both technical and commercial fronts.
This edition of "Yunqi Capital in Action" brings you the full transcript of Yan's conversation with GeekPark. A closer look at the people and stories Yunqi Capital chooses to back.
This article is republished with permission from GeekPark.
Interviewer: Zhang Peng
Writer: Li Shiyun
Editor: Jing Yu
Original title: "Dialogue with MiniMax's Junjie Yan: Today's AI Apps Won't Become Super Apps, But That Doesn't Matter"
Like most people, MiniMax founder and CEO Junjie Yan's first reaction to OpenAI's newly released "AI intelligent assistant" GPT-4o was "stunning." He too was captivated by the demos—the silky-smooth voice interaction, real-time visual understanding, language processing that even picked up on "breathing sounds."
As one of China's first-tier LLM entrepreneurs and among OpenAI's most important pursuers, he quickly saw through the "magic trick." Two days after the launch event, this practitioner known for his mystery and low profile made a rare appearance on GeekPark's livestream, spending nearly two hours in real-time conversation with GeekPark founder and president Zhang Peng.
Using this launch as a starting point, he discussed technology and costs, industry inflection points, the open-source versus closed-source debate, paid acquisition and PMF, super products, and other key issues.
In his view, the technical difficulty of what OpenAI demonstrated this time wasn't particularly high (for instance, the voice model processes at lower speeds, easily aligning with the language model to achieve smooth voice interaction). What struck him was that this rival took an important step toward the industry's most important mission—making AI accessible to more ordinary people.
He explained that GPT-4o is essentially progress in multimodality (text, voice, vision). And he recognized early on that every advance in multimodality for large models would improve user experience and achieve higher user penetration. For example, when GPT-4o features smoother voice interaction (reduced latency, added emotion, etc.), it reaches more people.
This was also his motivation for founding MiniMax in late 2021. At the time, ChatGPT didn't yet exist, and no one in the industry believed in large models. What drove him to start a company was that "making artificial intelligence general and serving the masses is something important."
Driven by this goal, MiniMax is one of the few companies in the industry working on both models and products. Currently, it's among the most outstanding AI product companies domestically. Its products fall into two main categories: entertainment products represented by STARFIELD, which benchmarks against Character.AI and currently leads domestically; and efficiency products represented by Hailuo, which benchmarks against ChatGPT, still in early stages but currently his most valued product.
The GPT-4o release clarified Hailuo's R&D direction going forward. He said the goal for the second half of the year is to integrate previously independent multimodal large models. And he believes this will become a "required question" for the industry going forward—efficiency products must keep pace. However, he believes that in the long run, the essential direction for efficiency products remains raising the ceiling of the base language model. Because its most important metric is user satisfaction with responses, and even ChatGPT's response satisfaction is only at 60% currently.
Despite AI attracting global attention over the past year-plus, it remains far from a future where ordinary people can use it. Yan did some calculations: currently the best efficiency product domestically has only 4 million DAU, and abroad it's 10 million, meaning AI penetration on mobile may be less than 1%. There's still much work for practitioners to do.
User satisfaction and penetration rate, and the technological progress required behind them, seem to have always been the "first principles" guiding his thinking. And when we discussed costs, commercialization, industry competition, and other key issues, his answers all revolved around this point. For example, he said, "paid acquisition happens because the technology gap isn't wide enough," "don't overthink PMF—actually, if you have user time spent, you'll have commercial value," "if entrepreneurs haven't made enough innovation, this is something big tech should do"... In this conversation, we see this technically-oriented CEO's rare "simplicity" and uncommon "candor."
So, when will we ultimately see the Super App of the large model era, truly popularizing AI? He said perhaps none of today's products show this possibility, but that's not an important question. The reason: the path to AGI is long, many things can't be seen clearly now, and there's no need to put so much pressure on oneself. The same answer as before—do well on technology and products, have the ability to keep pace with generation after generation of innovation, and only then will there be a chance to see that day arrive.
Below is the full transcript of this live conversation, edited and published by GeekPark:
01 On Voice Assistants: Stunning Effects, Boosts User Penetration, and Not Technically Difficult to Achieve
Zhang Peng: You must have followed both the GPT-4o and Google I/O launches quite closely. Their styles are actually quite different—which left a deeper impression on you personally? Which did you prefer? Could you share your reasons?
Junjie Yan: On one hand, I'm actually a user myself, using these AI products daily. On the other hand, I'm also an industry practitioner, so I have these two strangely different perspectives.
Watching the GPT-4o launch, as a user, I found it very stunning. Especially those two demos—one where (the AI understood) breathing sounds, and one taking photos to do things. I thought, how can AI become this smooth? Everyone felt real-time voice interaction was being achieved for the first time. This was indeed very successful, and very clearly the buzz and reach of OpenAI's launch exceeded Google's. Users definitely found OpenAI's launch more impressive.
But that evening after the launch, I started thinking about how this was actually implemented. After about half an hour of thinking, it felt like actually a very straightforward thing. Why? Because speaking is much slower than typing. For example, normal language models today process roughly ten to twenty-something tokens per second. But speaking, you can only say 3-5 characters per second, roughly only 4-5 tokens. So voice speed is far slower than standard language model processing speeds.
This means, as long as you take the voice modality—like previously done with images and text—and align it to the language model, transforming it into a purely streaming interaction, this transformation is very natural.
So I feel this demonstrates two things: First, OpenAI can still think about this from a very fundamental level. Second, the technical difficulty of this is far less than Sora or the original GPT-4. That's my feeling about the OpenAI launch.
Zhang Peng: What about the Google launch?
Yan: I didn't watch Google's live, but watched the full two-hour video the next day. At the very beginning, the DeepMind lead talked about a lot of technical parts, which felt very much like a middle-aged man bringing his whole family to do research—he had to satisfy shareholders, satisfy users, and satisfy market expectations for Google.
Zhang Peng: And can't let society question your ethics.
Yan: Right, equivalent to drawing many targets, with a thousands-person R&D team working for about a year to produce many things. Each point probably wasn't the best, but being able to do so many things simultaneously—from chips to products—perhaps only Google has this much R&D strength.
But what impressed me was its AI search. AI search has been hot these past few months, with Perplexity overseas, including ChatGPT itself, and many assistants domestically, everyone doing search, even claiming to replace traditional search. Frankly, I feel there's still a very large gap between current products' search and what Google demonstrated.
Because I feel there's something very core that probably only Google has. For example, a lot of real-time local information—these have enormous value for some high-value scenarios. If I were a user, I'd actually be very willing to use such search, this experience absolutely isn't achievable by plugging in a third-party search engine inside ChatGPT. Frankly, I feel this is Google's real moat.
Second, among other AI search products people currently use, there's only single-step reasoning, while Google demonstrated multi-step reasoning, which still improves search experience quite significantly. Google was also first to do this. It's not inherently difficult, the original language model just needed to support it, but it shows Google has already thought very deeply.
Finally, possibly a unique Google advantage. Actually including OpenAI, almost all companies' video understanding is fairly mediocre. Even what GPT-4o demonstrated, its Camera wasn't actually processing video but still images. Truly achieving very smooth video understanding, with good results, seems to be only Google. Gemini 1.5 is quite good at this.
I was thinking why is this so important? Why did Google insist on doing this? It's understandable—Google has massive amounts of YouTube video, but these videos couldn't be surfaced before. Because previous search only had a title, or very simple tags. Now with this technology, these videos can be added to search results, which is very unique.
Overall, what impressed me was that with AI, search can really be qualitatively improved, and Google has already gone very far on this.
Zhang Peng: Feels like most of us are just audience members, going "wow" after seeing the "magic trick," but you're in the "magician's guild"—you watch and then think through how the "trick" works. Like the voice thing looks impressive but isn't as hard to implement as imagined. So some people say OpenAI's progress this time was mainly engineering, that it chose a clear target, maybe even did good imagination for launch scenarios, then its engineering capability combined with technical capability to perfectly nail this point. Unlike Sora last time which was an essential technical change. Is this understanding correct?
Yan: Different people probably have very different understandings of systems, algorithms, and engineering. Let me share my technical understanding.
I don't know exactly how OpenAI did it either, but I suspect their voice technology can be broken into two steps: first, using a large model for speech synthesis; second, combining that speech synthesis model with a language model. The first step actually saw a lot of progress last year, but the problem was that during interaction, you had to convert speech to text first, then use the language model to generate a response, then run it through the synthesis model again.
Zhang Peng: So it wasn't end-to-end at the time — it took several steps.
Yan: Right, and that caused latency and information loss. This time OpenAI took it a step further and directly merged the voice model with the language model.
Technically this is relatively straightforward, since both speech and language models are Transformer-based. Essentially you're aligning the speech model's encoder to the language model. This already happened with images; now they've just swapped images for sound. And because speech processing speed is much slower than text processing, converting it to streaming is very natural.
The result is that previously, voice interactions with ChatGPT — including with Hailuo AI — had about two seconds of latency. Now with pure streaming, it's down to 300 milliseconds, roughly the duration of a single syllable.
Zhang Peng: So this voice technology approach isn't actually difficult, and was proven feasible and well-defined quite early. Does that mean it won't remain OpenAI's exclusive technology, but will quickly spread to more companies?
Yan: I think if a company or organization could independently build a good language model, and could independently build a speech model using this LLM approach — if they have both — then combining them is relatively easy. Though behind this there are still many engineering pipeline optimizations involved.
But the more core question is: what's your goal? For example, why did OpenAI reduce voice latency to 300 milliseconds? Fundamentally, on mobile devices, every reduction in latency brings particularly large improvements to user experience. Why can't online meetings replace in-person meetings? The core reason is that they have several seconds of delay. And the limit of latency optimization is the duration of one syllable — 300 milliseconds. With that as your goal, you'll end up deriving the most reasonable technical approach.
Zhang Peng: I deeply relate to the latency issue. Previously a voice-track entrepreneur told me that if latency exceeds one second, users will sense that the other person isn't in the same space talking with them. So when a voice assistant has no latency, you feel like it's moved from the cloud into your room — that feeling is incredibly striking. How strong is the improvement to user experience? Will voice become the mainstream interaction method?
Yan: Over the past year, a very obvious change has been in cars — you can see that voice penetration in new energy vehicles has significantly increased. This shows that in a given scenario, if you can make voice interaction very usable and practically valuable, user penetration will increase. At least this has already been achieved in smart cockpits. The same will happen in daily life, which is why AI companies are increasingly emphasizing voice interaction.
Over the past year, large models have been a very hot term, but currently only about 40 million people worldwide use AI products daily. Of those 40 million, over 30 million are using ChatGPT, with 20 million on web and over 10 million on mobile. Yet there are probably 400 million people using mobile phones daily worldwide. So AI penetration on mobile is probably less than 1% — that's an extremely low number. Truly mainstream products, like short video, long video, or social media, all have penetration rates of 50% or above.
I think companies aspiring to build AI products in the future must think through one logic: how to increase user penetration. Really the only way is to make more scenarios available and more people able to use it. I think voice should align with this trend — it can bring in people who find typing inconvenient, and pull in more scenarios. This is one effort AI companies can make to increase penetration.

At the OpenAI launch event, a researcher converses with GPT-4o | Image source: OpenAI
Zhang Peng: Do you think this will increase stickiness among existing users, or acquire more incremental users?
Yan: Both could happen. We've found that many scenarios genuinely only occur with voice. For example, within Hailuo AI, many parents have it tell bedtime stories to their children. This clearly expands the user base.
Another example: we've found many users use it to practice English speaking. From this dimension, it should increase user activity. There's also my personal example — this past Spring Festival I visited my grandfather in my hometown. He's 80 years old. He installed Hailuo AI on a very old Android phone, and would talk with it for long periods, discussing historical figures. Previously you'd never imagine an 80-year-old using AI this way.
And when they use this product, they genuinely treat AI as a person. For instance, he'll say "can you speak louder" — subconsciously treating it as human.
This is also why we so believe in general intelligence: it's something that serves ordinary people. The problem is that the industry's overall penetration really isn't that high, and simpler interaction is a very important piece of that.
Zhang Peng: You've said you believed in multimodality very early, because every time a product expands its modalities, it can expand to a new batch of users. After ChatGPT improves its voice technology, what changes do you predict for its DAU, user duration, and other metrics?
Yan: Actually it's impossible to guess now, since it hasn't launched yet. I think usage duration will increase, but whether user penetration will change significantly — I'm actually somewhat skeptical.
Zhang Peng: Voice interaction does have a threshold for people. Many previous-generation voice interaction entrepreneurs have reflected that after opening a voice assistant, people suddenly don't know what to say and just stop. This actually has nothing to do with technology. It requires users to have fairly strong intent and willingness to use it.
Yan: Right, I think it's more friendly to younger or older users, but less so to those in between. The reason is that people willing to use AI, or who have heard of AI, have probably at least tried something already.
02 On Industry Inflection Points: Multimodal Fusion Is a "Must-Answer Question" for the Large Model Industry, Determining the Success of Productivity Products
Zhang Peng: You're also an entrepreneur in the large model space, actively benchmarking your technical capabilities against OpenAI and Google. After watching these two launch events, do you feel more excitement or more challenge?
Yan: I think having someone running ahead of you is a good thing — it shows this industry's ceiling is far from being reached.
I personally very much hope OpenAI will release GPT-5 or other things. Even as an industry insider, I hope OpenAI can maintain this pace of progress. There's no competition anyway, actually no competition at all. But this isn't because we don't want to compete with them — they're too strong to constitute competition.
At least currently, the ones truly consolidating algorithms into products and truly expanding AI's boundaries are mainly OpenAI. If they can very quickly expand AI's boundaries, at least it shows that AI user penetration has underlying momentum, and that this momentum is sustainable.
OpenAI probably has 10 times the R&D resources of Chinese companies. If even they can't produce innovation, that would be the truly scary thing for this industry.
Zhang Peng: Do you have methods, a path, a plan — will we see user experiences similar to what OpenAI showed today in your products in the future? Roughly how long until they're visible?
Yan: First, I definitely think this is visible. Though I don't know how they did it, I think my analysis just now should be correct — at least that method can achieve it, at least there's a relatively clear path.
Actually for me, the main challenge isn't the voice model — it's mainly making the language model as good as possible. The real reason is that current multimodality still uses the language model as core. Earlier this year when we were working on the previous version ABAB 6.5, we actually got trillion-parameter-scale MoE working — and this was still a language model.
Additionally, last year each of our modalities was independent. Though they shared the same framework, all Transformers inside, similar code, their data and models were separate. Now as I'm designing the next version of the model, our core focus for the second half of this year is how to have a language model with higher ceiling, and how to merge these different modalities together.
We haven't fully completed the design yet; there are still many experiments needed. But it's basically already visible. The next model will go through two phases: first, design phase, with many hypotheses that require many experiments to validate. Second, assuming your hypotheses are sufficiently validated, combining these elements and finally training the model.
The trade-off here is: how good do these hypotheses, or these validation experiments you've designed, need to be? This is something we're currently going through.
MiniMax's productivity product "Hailuo AI" | Image source: MiniMax
Zhang Peng: Recently I've heard Google mention "One network, Multi-modality" quite a lot — multimodality achieved within a single neural network. Now MoE is a very effective method for training trillion-parameter models, but for the next step of multimodal fusion, how will the approach differ from before?
Yan: These are two dimensions. First, the intermediate step involves massive transformers. To improve efficiency — both training and inference efficiency — the mainstream choice is a MoE architecture, like GPT-4. Rumor has it Gemini-1.5 looks like this too. If you're building a model of several hundred billion parameters, this is basically the inevitable choice.
Second, you have different modalities — how do you merge them into this large backbone model based on MoE? That's multimodality. What's already known is how to merge visual understanding with the backbone model, like GPT-4V: you start with a massive MoE, then align vision to it, and you can get reasonably good visual understanding.
The unknowns are two:
First, what GPT-4o demonstrated: aligning sound into it as well — that's one of the things GPT-4o did.
Second, the generation part — for instance, can image generation and video generation be integrated? At least for now, video hasn't been achieved. Sora, for example, is a standalone model. Why is that? The reason is that video tokenizers involve lossy compression; you basically need diffusion to recover something reasonably normal, and that can't be done yet. Of course many people are working on it, and maybe it'll all be integrated next year. But for now, how to integrate video generation remains unknown.
As for image generation, I'm not sure. Back with the previous generation DALL-E 3, it wasn't integrated either — it was also a standalone model. But looking at GPT-4o this time, I feel like they seem to have integrated it, though I'm not entirely certain. I think that's basically the underlying technology.
Zhang Peng: So will unified multimodal fusion become the next-stage goal for the large model field, especially for Chinese startups? Is this something everyone must catch up on, a problem everyone has to solve?
Junjie Yan: I think it's something that must be done. Actually this splits into two product categories. Currently there are two types of AI products: those that satisfy entertainment needs, and those that satisfy efficiency needs. Entertainment I won't go into — that's more about operational attributes, product attributes, more about comprehensive product capabilities.
Efficiency-oriented ones definitely need multimodality, because historically, for all efficiency products, people basically end up using only the best one. Say there are two products: one can do many things, one can only search text — people will definitely use the one that can do everything. Of course this presupposes that this multimodal track actually exists. Whether this track exists also requires a lot of effort.
Zhang Peng: Can I understand it this way: Sora is an "optional question" — you can skip it — but unified multimodal fusion is a "required question," and if you don't answer it well, you're out?
Junjie Yan: I think your summary is quite good, hadn't thought of it that way before, but it really is more like a required question.
Sora actually has different use cases — there's PGC usage, tool-attribute usage, and UGC usage, which involves a lot of product and content things. Not all of these are things AI companies need to do.
But for tool-type, efficiency-type, assistant-type products, once any company achieves multimodality, other companies must follow. Because there's basically just this much technology.
03 On Ecosystem: The "Intelligent Voice Assistant" Battle — Complex Coopetition Between Giants and Startups
Zhang Peng: This time we see the voice assistant matter — Apple wants to use it in Siri, Google wants to deeply integrate it into the Android system. It seems like it could become a very important entry-level thing. Will this ultimately be a giants' game? Can entrepreneurs still do anything?
Junjie Yan: First, nearly all user experience of this product comes from model capability. It doesn't depend on whether the product is from a giant or a startup, only on what technical level is behind it. It tests whether you can build a model with the best experience. This involves how you build your technical model, how to do good alignment, how to optimize latency, how to improve engineering efficiency, how to reduce compute costs, and so on.
Second, at the business level, this product will definitely consume costs. Because the essential difference between current AI products and early mobile internet products is that before we didn't need to consider daily costs to maintain users, now we do. So how to monetize this generation of products is relatively direct. And the commercial value of phone products largely depends on how much user time they capture, because user time always has standardized monetization methods.
If such a product can satisfy most needs — say when I want to search, I don't need to open Baidu. Or when I need to watch a video, I don't need to watch it in Douyin. As long as it captures enough user time, its monetization efficiency will be high enough; its monetization is proportional to time spent.
This ultimately becomes: product competitiveness depends on technical capability, business competitiveness depends on how much user market you occupy.
Zhang Peng: Let me make it more concrete. Apple is a complete controller from hardware to software. Android has natural advantages at the operating system level. OpenAI is a new type of startup based on large model capabilities. If all three companies are competing for this most critical voice assistant entry point in the future, who is most likely to be the winner? Can startups win this position?
Junjie Yan: I think there are all kinds of games and coopetitive relationships here, which have already happened in search. We can see that Apple has integrated Google's search, and Google pays Apple a lot of money every year. Why is Google willing to pay? Obviously because the commercial value of Google doing search within Apple is greater than what Google itself pays.
But I think regardless, if we look at first principles, whoever can actually build this thing and make the experience significantly better — at least you should have a place in there.
I think this favors device-owning companies more. Why? Say I buy a Xiaomi phone — I only pay Xiaomi once. After that, whatever value this Xiaomi phone creates basically has nothing to do with Xiaomi. The only relation is that Xiaomi's app store distribution has revenue sharing; everything else basically doesn't matter.
Zhang Peng: There are also some negative-one-screen content ads, but they're pretty thin.
Junjie Yan: The content quality on negative-one-screen is obviously not as high as Douyin or Xiaohongshu. Actually phones provide a lot of user time. Say I install Douyin on a Xiaomi phone, a user spends a lot of time on Douyin, but all the money has nothing to do with Xiaomi — it's all captured by Douyin.
I think one benefit of a strong AI assistant is that it can indeed let the phone's operating system layer capture a lot of user time, because it can satisfy many diverse needs. This is essentially pulling a lot of value from apps back to the phone.
Zhang Peng: Recently we've also seen rumors that Apple and OpenAI might collaborate at the intelligent assistant level. So according to your reasoning, a company that performs extremely well in large models, combined with a phone giant that controls the ecosystem hardware and software — ultimately coming together to generate new value distribution in the future ecosystem — this is logical?
Junjie Yan: Yes, it's actually about the distribution of user time, which again tests the technical and product capabilities behind it.
Zhang Peng: Conversely, if OpenAI doesn't collaborate with Apple but instead becomes the strongest Super App, challenging the existing ecosystem as an independent force and even reconstructing the original value chain — do you think this possibility exists?
Junjie Yan: This mainly depends on scale. An app with 10 million DAU is clearly not qualified. At Meta's level of 1 billion DAU, there would probably be fundamental changes. But even OpenAI is 100x away from this.
Zhang Peng: Right now, building a so-called unified Super App or super entry point is still very difficult to achieve. Today what's more realistic is how to grow DAU from 10 million to 100 million — this is also what's giving OpenAI a headache.
Junjie Yan: I guess this is also why they care so much about voice, because this thing really could improve penetration.
04 On Technical Route: Investing in General Foundation Models and Building General Products Lets You See the Real Future
Zhang Peng: Recently in the entrepreneur community, there was big debate around foundation models versus open-source models. The essence was: either you build your own intelligence engine, or you buy one and modify it. Actually model and product dual-wheel drive — simultaneously doing foundation models and products, rolling forward together — is best. But many entrepreneurs say this is very risky. One model iteration falling behind, or one product PMF failure, and you're done. What do you think of these two routes?
Junjie Yan: I think this is inherently very risky. Forget about doing both model and product simultaneously — doing only model, or only product, is already very risky.
Zhang Peng: Entrepreneurship is basically a game of life and death.
Junjie Yan: Yes, it's indeed very brutal. Looking at American companies, OpenAI does both. Anthropic previously only did models; yesterday they recruited Instagram's CTO — I wonder if they might also do products. I think at least for model-building companies, doing their own products is almost an inevitable choice. We're relatively resolute about this; some companies later became this way — it's inevitable.
Conversely, it's the same for product companies. On our domestic open platform, there are many product companies and clients, actually quite large in scale — roughly close to a thousand. There are big companies and small startups. Honestly, for all these companies, if their products get big, they also want to control their own models. This is also an inevitable path.
So the core consideration here is: if you think this is right, it's essentially about how many resources you have now and maximizing the objective you want to optimize. For us, our goal is to maximize user experience, and we think both things — model and product — are important. Only by doing both can we best match the objective we want to optimize.
Different people define different goals and different paths, and many different companies emerge.
Zhang Peng: So model-product integration is ultimately the final goal we pursue; it's just that based on today's existing resources, many people find it too costly and risky. But this is only a stage-specific choice.
Junjie Yan: There's also a more fundamental reason. For example, say there's a need to satisfy, and this thing needs to be satisfied through a model — if model and product are in one company, your path is just optimizing this business metric. But if model and product are in two companies, what you do is convert this metric into a requirement for the model, and have the company providing your model optimize this metric.
In between, a lot of information is lost, and the cycle becomes longer. This is definitely not the way to maximize business metrics.
Of course Microsoft is an exception here. The core reason is that Microsoft's scenarios — Bing search, Office — are all things that can become very standardized, basically mainly depending on the general capabilities of the model. OpenAI's general model is the best, so it can be used for these products. In this situation, separating model and product is reasonable, but in most situations it's not the optimal choice.
Zhang Peng: You raised a very good question: do we build products based on model capabilities, or modify models based on product goals? Let me use an analogy: if the model is a gun and the product is a target, do we today want to build a more general machine gun that can hit targets in more domains, or should we build a high-precision sniper rifle that hits one specific target?
Junjie Yan: Actually, there's a deeper implication here. At this point in time, AI is riding a wave of technological dividends. This dividend means that there are so many smart people, so many resources, so many communities around the world working on this. The value or capability of this collective effort far exceeds any single company, exceeds OpenAI, and obviously exceeds any individual Chinese startup.
So a company's R&D level isn't built in isolation—it's the company's own capabilities plus the integration of the entire industry. Different companies just leverage this integration with different efficiencies. Including OpenAI—much of what they have isn't original. Google may have developed it, but they integrated it well and scaled it up, and that's how they got to where they are.
Actually, making models general-purpose is a relatively easy way to absorb the progress of the entire community. There's enormous dividend in this.
Zhang Peng: Today you should stand in that position, put more capabilities out there, and let more people co-create with you—whether users or other entrepreneurs in the industry. OpenAI has that feel. But if today you're just building one product, tending your own "vegetable garden," you might lose the opportunity for the world to co-create with you.
Junjie Yan: Objectively speaking, it's not the world co-creating with us—it's us co-creating with the world.
Zhang Peng: I see Sam Altman also keeps reminding people not to patch today's models based on their specific current limitations, that it's a waste of time. Because technology keeps rolling forward, and by the time you've finished patching in this moment, the garment may have already changed—that kind of problem.
Junjie Yan: Objectively speaking, what products can be built is determined by the technology cycle.
For example, in the current generation, virtually all the products we've seen are primarily text-based interactions, and product functionality is basically at the assistant level. Whether entertainment or productivity, it's basically the copilot framework. Different people, based on different understandings, resources, and teams, just assemble different things.
Suppose we had better models with significantly improved capabilities—say, all tests could be done very well, and they could work independently. Then it's not a copilot, maybe it's an auto-pilot. That would clearly produce completely different product forms.
But this isn't designed by product people—it's when you push technology to a certain stage that the product naturally becomes clear.
05 On Costs: Tech Costs Could Drop 100x in Two Years—That's Much Easier Than Pushing the Tech Frontier
Zhang Peng: I want to extend this to something very concrete. The other day I did some math with an investor: a product with tens of millions of DAU today is burning through maybe 2 million RMB per day in costs—that's high. For example, if GPT-4o today accommodated more users and gained greater user stickiness, how high would its daily costs be? You must have some judgment on cost structure—can you help us calculate?
Junjie Yan: Actually, voice is cheaper than text because voice is slower. For example, text generates 20 tokens per second, but voice is only 4-5 tokens per second. And people listen slowly too—I can read a thousand words in a minute, but listening to a thousand words takes a long time.
So assuming the same usage time, voice is actually cheaper.
Zhang Peng: That's quite counterintuitive.
Junjie Yan: You think sound is more expensive, but it's actually cheaper—that's the first point.
Second, optimizing or reducing costs has always been a very classic research area in academia. I myself did a lot of work in this area many years ago. But it's actually not the most cutting-edge field in industry—the most cutting-edge field is definitely about how to extend the boundaries of technology.
Once you can extend the technology boundary, how to reduce costs by 10x—from the earliest machine learning era, like when I was doing my PhD, to the 2012-2022 decade of using CNNs (convolutional neural networks)—quantization, pruning, distillation: there's a very standard pipeline for this.
In the Transformer generation, you can actually reuse the previous generation's pipeline. For example, doing quantization; when you have a very long context window (chat window), how to do caching more efficiently with lower latency; how to optimize your attention... there are many methods for this. It's actually not that hard—you just need to do each step well enough, and piecing them together brings huge changes.
Zhang Peng: So compared to exploring new continents, digging three feet deep to extract the ore is actually quite easy?
Junjie Yan: Just think about it—last March when GPT-4 first came out, it was slow and expensive. But now look at GPT-4o, and GPT-4 Turbo before it: cheaper, faster, better results. This all happened in just one year. Prices may have dropped 10x, but actually OpenAI's internal cost reduction is even greater than that.
We've roughly calculated that with two years, costs could drop by nearly 100x. I think the upper limit of technology is relatively uncertain and requires more exploration. But cost reduction—there's definitely a way to do it. This has already happened three times in academia.
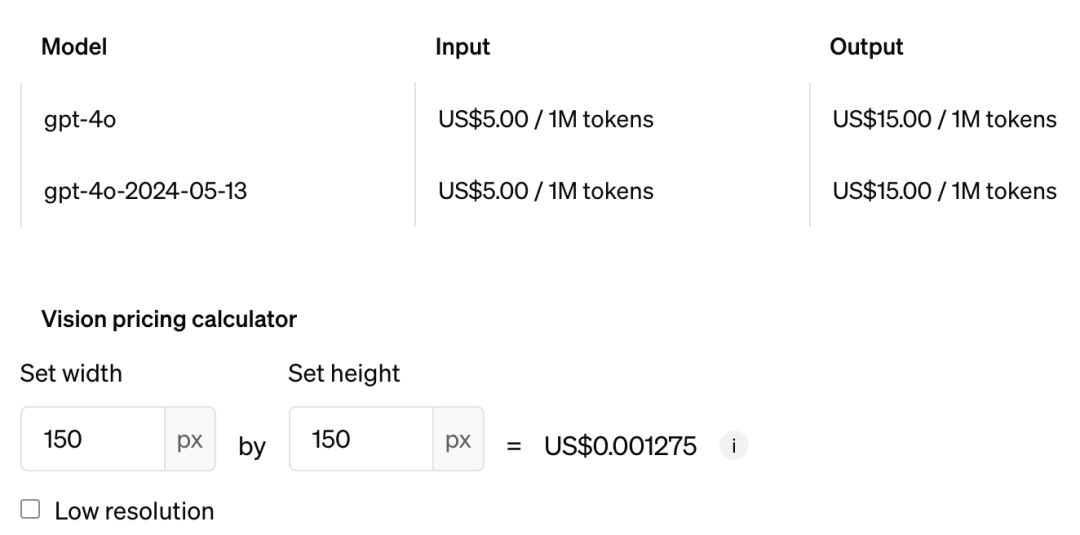
GPT-4o costs | Image source: OpenAI
Zhang Peng: Today some people are desperately optimizing tech costs, while others are desperately pushing model capabilities trying to reach the very top. In your view, is the latter more important?
Junjie Yan: I think from the outcome perspective, yes. But from the process perspective, the two transform into each other. This is actually a very important law in large models: efficiency and effectiveness can be converted into each other.
Assuming the same training precision, if your compute is 1/10 of someone else's, that means you've made your efficiency very high, and you must be able to push the model's upper limit high enough. Or conversely, if you want capability to reach that sufficiently high upper limit, you must make efficiency very high for that to be possible.
Everyone's resources are limited—your upper limit can only be higher if your efficiency is high enough. It's not actually that you first rush to the boundary and then optimize; you have to do both sides together.
This is also why most R&D gets harder the higher you go—it requires comprehensive consideration.
Zhang Peng: So when Sam says "give me however many trillions and I can rapidly achieve AGI," is that unrealistic?
Junjie Yan: If we make an analogy: TSMC is currently at 7 nanometers, so next would be 5 nanometers, 3 nanometers, 2 nanometers, generation by generation. They can't skip 5 and 3 nanometers and suddenly say they can do 2 nanometers. I don't think that's right—you can't really skip the intermediate steps.
Zhang Peng: Grand goals still need to be walked step by step. You can't expect to reach the destination directly—that's also the essence of entrepreneurship.
Junjie Yan: Though maybe they're so strong that I haven't understood their essence. But under normal circumstances, it should be like this.
06 On Paid Acquisition and PMF: Domestic AI Products Are Forced to Buy Traffic Because the Tech Gap Isn't Wide Enough
Zhang Peng: Speaking of costs, we've seen recently that AI products in the industry have started buying traffic. I feel like in the mobile internet era, people would at least achieve PMF before amplifying with paid acquisition. Now products need to spend money just to test PMF. On one hand, all of China's internet traffic has consolidated around the giants. On the other hand, AI capabilities are limited and can't be pushed directly to users. Will this rise in PMF costs due to paid acquisition be a major challenge for this generation of AI entrepreneurship?
Junjie Yan: We've been burned by this. You find that in China, this is very different from the US. For example, American products—ChatGPT obviously didn't buy traffic, early Character.AI didn't buy traffic. More tool-oriented things like Midjourney obviously didn't buy traffic either, focusing more on operations. But conversely in China, basically all products buy traffic—this is actually a very obvious difference.
It's like American companies rely more on technical capability and product capability, and no one buys traffic. But there's actually a cost to this: R&D costs in the US remain very high. In China it's the reverse—China's engineer dividend and product dividend are relatively abundant, but China's traffic is consolidated at the top.
But the deeper reason for buying traffic is that so far, in assistant-type products, no company has been able to create enough distance from the others. Everyone is on the same dimension, products are relatively homogeneous, and technical capabilities are relatively homogeneous too. To acquire more users, you have to rely on buying traffic—this is the current predicament for this type of product.
Everyone has some explanations for this. For example, some people think acquiring queries (user inquiries) is relatively important, and if you convert the value of the query itself into money, then buying traffic is worth it. It depends on how you look at it. When the technology isn't outstanding, there's just no way around this.
Zhang Peng: I feel like you've chosen a certain kind of "simplicity"—make the technology the best, absolutely leading, and the world becomes simple too. If you can't simply lead on this, the world becomes complicated for you. You won't save much cost either; maybe the cost is even higher. It's just a matter of betting here or betting there.
Junjie Yan: Right, so we don't think we should spend money to buy user queries.
I think PMF works like this: generally when starting a company you write a BP (business plan) explaining what your PMF is. We actually didn't understand this at first, and still haven't written one. I think we can make some assumptions: the core is that for products like this, as long as there's user time, there's monetization. Essentially, PMF is quantified by user time—that's the relatively standard thing. Currently this type of product has no monetization logic, but if it can get bigger, or reach a certain state, something can emerge.
Zhang Peng: Actually I think at different stages, people need to face different things. It's not that if you have pure faith in technology, you must do PLG (product-led growth) and absolutely refuse to buy traffic. I also think back to how DiDi in many cities had no PMF and was burning money, and then one day it suddenly burned user habits and industry logic into existence, and PMF appeared. Do you think the AI industry will follow the same path as ride-hailing back then?
Junjie Yan: I don't think so, because ride-hailing is actually a very typical business with network effects—if you have more drivers, you get more users, and vice versa.
Junjie Yan: Large language model products don't have network effects so far. There might be weak economies of scale, but you still need to break it down by product type — productivity, entertainment — and look at them separately.
For pure productivity products, the improvement in user experience doesn't mainly depend on whether you have more users. It actually depends on R&D speed and model iteration efficiency. In other words, your technical improvement doesn't completely scale with your user growth. But for entertainment products like STARFIELD, if you have more and more content, the economies of scale are quite obvious.
Zhang Peng: I think starting a company today is genuinely harder than the mobile internet generation. If you try to buy traffic today, all the traffic is basically in the hands of the giants. Even your PMF is transparent to them — because if you're constantly buying traffic, it means you've found PMF, and they can follow you anytime. Entrepreneurs are always playing with their cards face up. The giants have more money, more people, and they own the traffic. You have to pay them "taxes" just to test your product. That's the very real truth of this world. As an entrepreneur, how do you maintain your hope?
Junjie Yan: This is indeed a critical question, and a very fundamental one.
At the level of belief, I think it's like this. If you haven't done much technical innovation or product innovation, or if you haven't found enough non-consensus in a reasonable amount of time, then this thing shouldn't be done by you — it should be done by the big companies. You can't blame the giants for monopolizing.
What we need to think about is: as an independent company, where can you actually innovate? Is it R&D efficiency, insight, product experience, or something else? If you don't have it, your startup deserves to fail, and you can't blame others.
Zhang Peng: Very pragmatic thinking. Competition from the big companies can actually verify whether a startup truly has value.
Junjie Yan: Yes. However, domestic traffic is monopolized by giants, but overseas traffic is relatively more open — at least in many markets you can compete freely. So I think although it's very difficult, there is still space.
07 On Products:
Virtual Social Is More Popular Than Smart Assistants,
But the Super App May Not Emerge From Either
Zhang Peng: Speaking of products, MiniMax is also one of the earliest and best AI product companies in China. Could you introduce your two flagship products, "STARFIELD" and "Hailuo AI"? How are they developing?
Junjie Yan: STARFIELD is basically a fantasy-focused product. If you look at its session duration, user distribution, and retention data, it's actually very similar to novel/reading products.
For something like Hailuo AI, we call it a smart assistant, but it's actually undefined. The reason is that the largest products in this category right now only have about 4 million DAU — not really large enough to define the industry.
Our fantasy product is relatively leading. In terms of user volume, it's probably about 100x larger than assistant products. Our assistant product has just gotten started.
Zhang Peng: If the fantasy product is doing so well, what are its conversation turns and session duration like?
Junjie Yan: I think it's quite extreme — very long sessions.
Zhang Peng: Why did you decide to build a fantasy product like STARFIELD back then? What was the decision logic?
Junjie Yan: When we started the company over two years ago, large models weren't consensus yet. We believed that making AI general and serving the masses was important, and we happened to see a very clear technical inflection point, so we started. At that time, we didn't know what the technology would become, what the products would look like, or how commercialization would work.
The predecessor of STARFIELD was Glow. When we built Glow back then, there was neither ChatGPT nor Character.AI. We didn't do extensive analysis, discover an opportunity, and decide to build it. Our products were stumbled upon.

MiniMax's entertainment product "STARFIELD" | Image source: MiniMax
Zhang Peng: So it was: first you had faith in AGI, you built model capabilities, then you looked at what the model could do and did it — is that the logic?
Junjie Yan: The reality was this. Why did this product end up becoming Glow instead of ChatGPT? In October 2022, our first version of the model was only about 30B parameters. It could only do entertainment things because it wasn't that good.
Zhang Peng: You had to treat hallucination as an advantage, not a flaw.
Junjie Yan: The reality was, at the very beginning we only had pre-training; alignment hadn't been figured out at all. So this kind of thing was stumbled upon, very random, and it just turned out this way.
If we had been stronger then, we might have been able to build ChatGPT, but unfortunately, our capabilities just weren't that strong at the time.
Zhang Peng: Starting a company ultimately depends on actual conditions. Your technology wasn't ready then, so it was normal that you couldn't build it. This actually shows why technology is the most important part of AI products.
Junjie Yan: Right, because technological development has its dividends.
Zhang Peng: Now you have Hailuo AI — didn't you also change its name? I remember last year you were still called "Hailuo Wenwen"?
Junjie Yan: Indeed. We renamed it to make the product more mass-market. First, we felt "Hailuo Wenwen" was four characters; cutting two characters to "Hailuo AI" would give us higher user coverage. Second, we found that users' deeper needs didn't entirely come from Q&A, so we went with this name.
Zhang Peng: Deeper needs beyond Q&A — so were you already thinking about the future "smart assistant" direction at that point?
Junjie Yan: Yes.
Zhang Peng: With the releases of GPT-4o and Astra, the "smart assistant" space may see more and more competitors. How do you view the development goals for this category?
Junjie Yan: The core thing for this category should be just one: improving the efficiency with which users solve problems, or rather, response satisfaction.
Let's look at it objectively. If you ask ChatGPT a question, what's the probability it gives you a satisfactory answer? Our own testing shows it's only 60%. This is also why AI user penetration is only 1%. Probably only users who are particularly enthusiastic about AI will still choose to believe it, tolerate it, and even guide it to get some answers after it has given them countless wrong answers.
For example, when we use products with larger user bases — Baidu Search, Xiaohongshu Search, even Douyin Search — we can probably get what we want to see, and satisfaction is clearly higher than 60%. Only with this can products reach broader audiences.
This is also why, as a practitioner, GPT-4o didn't impress me that much. Because it didn't actually improve the metric that truly matters for this category: user satisfaction. If this metric goes from 60% to 90% or higher, it becomes a product you can trust. This is also the direction we're working toward with Hailuo AI.
Zhang Peng: I believe your ultimate goal is still to create a Super App, or to solve major problems for mainstream users in an AI-native way. Do you think products like STARFIELD or Hailuo AI today are candidates for Super App? Or do we not necessarily see the final form of Super App today — will it randomly emerge with future technological development, as you said?
Junjie Yan: Our basic assumption is actually this: First, existing products are not it. Second, we believe current individual products can grow to large enough user scale, bring greater value to users, and bring sufficient commercial success and returns to the company. This is also what we're working toward.
As for whether current products are the final Super App, I think it actually doesn't matter. Why? Because AGI is a long-cycle thing — clearly not happening in 2024 or 2025 — we don't actually need to put that much pressure on ourselves.
What we really need to do is: let technology progress fast enough, while products built on current capabilities can make the company run more efficiently, create certain value for users, and generate commercial returns for the company. At the same time, we can still have the capability to build more products, rolling generation after generation. That's enough.
American companies may not follow this path. But as a Chinese company, this is at least a path with precedent.
This article was first published on GeekPark. For reprints, please contact GeekPark editor on WeChat: geekparkGO





