MiniMax Open-Sources Its First Unified Visual RL Framework, Launches Orsta Model Series | Yunqi Capital

Recently, **Yunqi Capital portfolio company MiniMax**, a leading domestic model startup, officially open-sourced its first unified framework for visual-task reinforcement learning (RL) — **V-Triune** — and simultaneously released the new **Orsta model series (7B–32B)** trained on this framework, which demonstrated significant performance gains on the MEGA-Bench Core benchmark.

Recently, Yunqi Capital portfolio company MiniMax, a leading domestic model startup, officially open-sourced its first unified visual reinforcement learning (RL) framework — V-Triune — and simultaneously released the new Orsta model series (7B–32B) trained on this framework, achieving significant performance gains on the MEGA-Bench Core benchmark.
In this edition of Yunqi Capital, we explore how MiniMax is building general visual capabilities and strengthening multimodal AI through a unified visual RL framework.
The following content is republished from QbitAI.
Can a single reinforcement learning (RL) framework unify all visual tasks? Existing RL approaches force a choice between reasoning and perception tasks, but MiniMax, one of the "Big Six" model startups, says: I'll take both!
The newly open-sourced V-Triune (Visual Triune Unified Reinforcement Learning System) framework enables VLMs to jointly learn and master both visual reasoning and perception tasks within a single post-training pipeline for the first time.
Through a three-layer component design and dynamic Intersection over Union (IoU)-based reward mechanisms, it fills the gap where traditional RL methods could not handle multiple task types simultaneously.

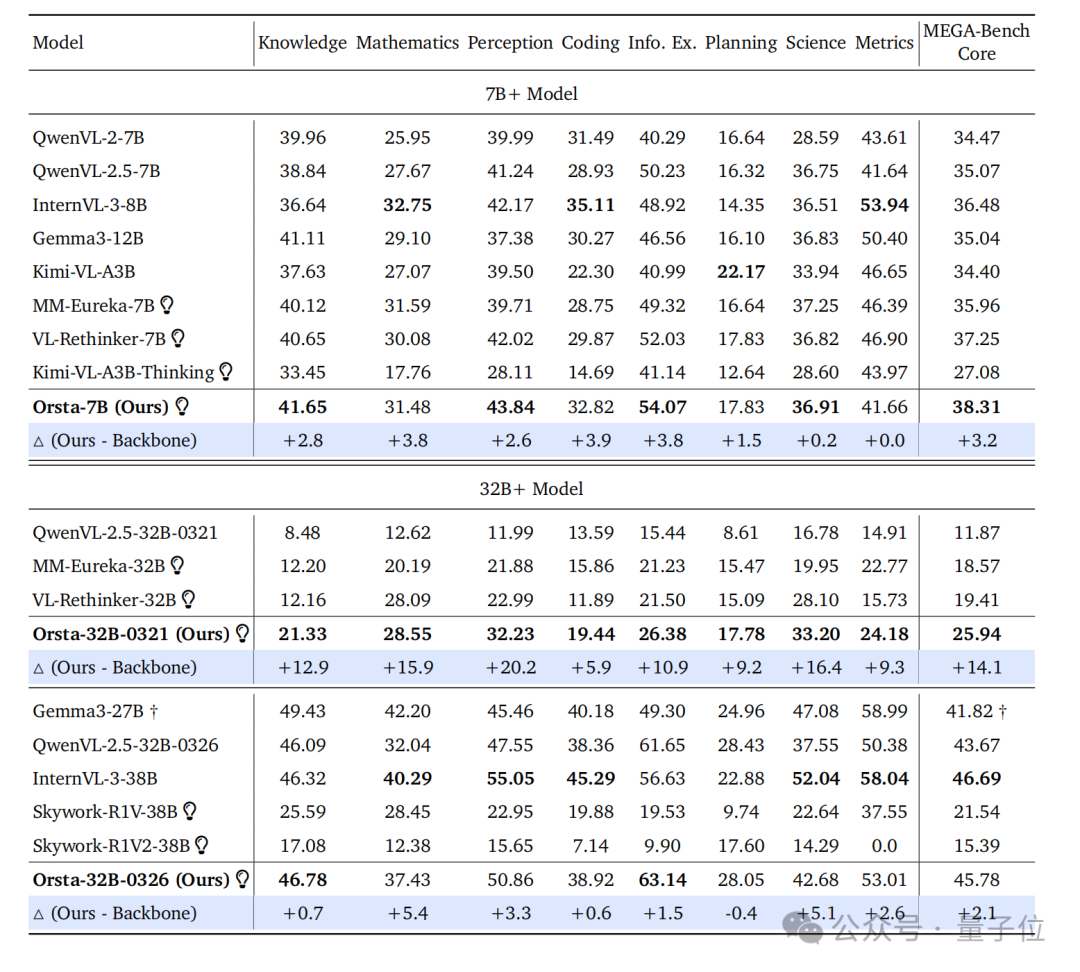
Going even further, MiniMax has conveniently developed the new Orsta (One RL to See Them All) model series (7B to 32B) based on V-Triune, improving from +2.1% to +14.1% on the MEGA-Bench Core benchmark.
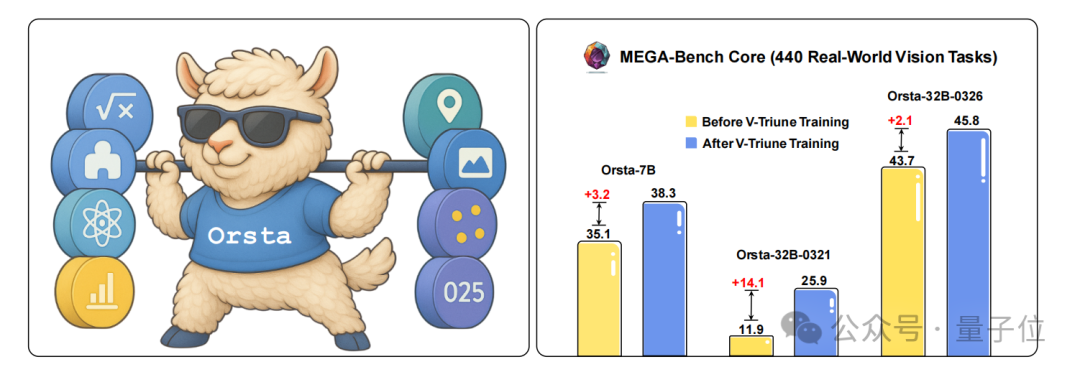
Notably, Junjie Yan, MiniMax's founder and CEO, is listed among the paper's authors.

Both the V-Triune framework and Orsta models are now fully open-sourced on GitHub — click the links at the end to access them directly.
Grasping Both Reasoning and Perception
Visual tasks fall into two categories: reasoning and perception. Currently, RL research has focused mainly on visual reasoning tasks such as mathematical QA and scientific QA.
Visual perception tasks like object detection and grounding, however, have lacked good solutions due to their need for unique reward design and training stability guarantees...
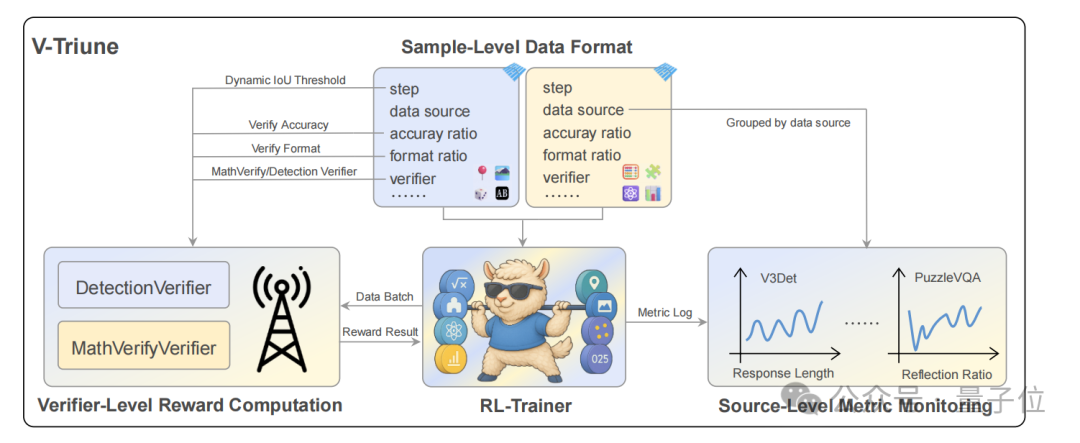
To address these issues, MiniMax has introduced V-Triune as the first unified RL system for VLM post-training, cleverly balancing both through three complementary core components.
- Sample-level data formatting
Each sample customizes its reward settings and verifier, supporting dynamic routing and weight adjustment to handle diverse task requirements. The data schema, implemented based on HuggingFace datasets, contains three fields:
- reward_model: Defines reward type and weight at the sample level.
- verifier: Specifies the verifier and its parameters.
- data_source: Identifies the sample's origin.
This enables seamless integration of diverse datasets while supporting highly flexible reward control.
- Verifier-level reward computation
An asynchronous client-server architecture decouples reward computation from the main training loop.
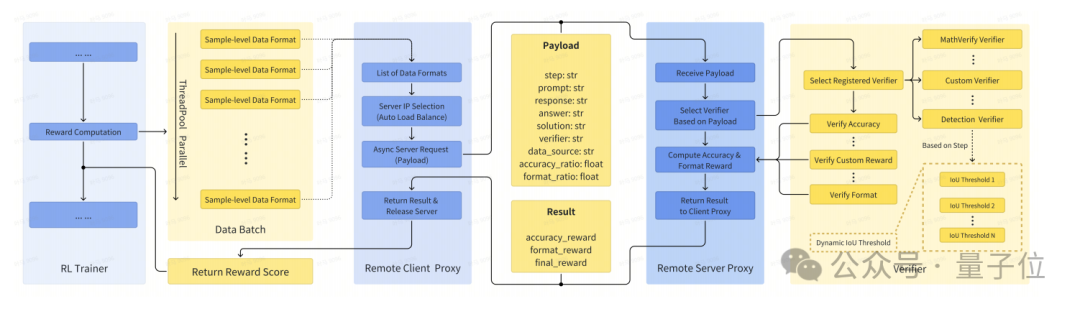
The client sends requests asynchronously through proxy workers, while the server routes them to dedicated verifiers based on the "verifier" field.
Two main verifier types are used:
- MathVerifyVerifierr: Handles reasoning, OCR, and counting tasks.
- DetectionVerifier: Handles detection and grounding tasks, applying dynamic IoU rewards.
This allows flexible extension to new tasks or updates to reward logic without modifying the core training process.
- Data-source-level metric monitoring
During multi-task, multi-source training, the following metrics are recorded by data source:
- Reward values: Tracking dataset-specific stability.
- IoU and mAP (perception tasks): Recording IoU and mAP at different thresholds.
- Response length and reflection rate: Tracking response length distribution, truncation rate, and the occurrence proportion of 15 predefined reflection words (such as "re-check").
This monitoring mechanism helps diagnose model behavior (such as overthinking or superficial responses) and ensures learning stability.
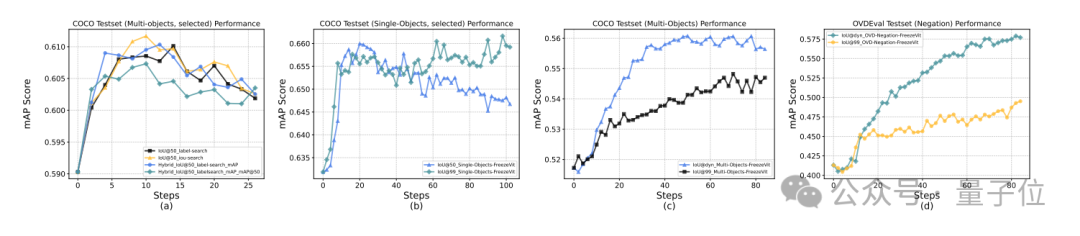
- Dynamic IoU reward
Additionally, for detection and grounding tasks, the team innovatively proposed dynamic IoU rewards, adjusting thresholds in phases to alleviate cold-start problems while guiding the model to gradually improve localization accuracy:
- Initial 10% of training steps:
- 10%-25% of training steps:
- Remaining training steps:
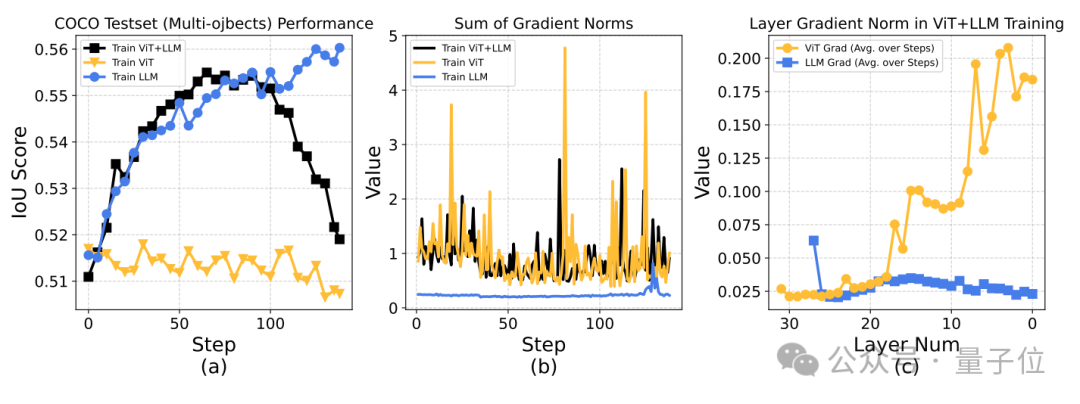
While V-Triune provides a scalable framework for data, tasks, and metrics, early experiments showed that joint training could lead to instability such as degraded evaluation performance and sudden gradient norm spikes. The team gradually resolved these through the following adjustments:
- Freezing ViT parameters to prevent gradient explosion.
- Filtering pseudo-image special tokens to ensure input feature alignment and improve training stability.
- Constructing a randomized CoT prompt pool to reduce prompt dependency.
- Since V-Triune is implemented based on the Verl framework, the main node faces significant memory pressure, requiring decoupling of the testing phase from the main training loop to manage memory.
- Orsta models
Also worth noting: based on the open-source Qwen2.5-VL model, the team trained 7B and 32B Orsta models.

Using training data across four reasoning tasks (math, puzzles, science, chart analysis) and four perception tasks (object detection, object grounding, counting, OCR), they applied two-stage filtering and training optimization by rule and difficulty. The result: on the MEGA-Bench Core benchmark, Orsta achieved a +14.1% improvement over the base model, with particularly significant mAP gains in perception tasks — proving the effectiveness and scalability of this unified approach.
MiniMax's Multimodal Push
MiniMax, one of the "AI Big Six" with a SenseTime background, has been making frequent moves in the multimodal space lately, with models spanning language, audio, and video.

Examples include MiniMax's S2V-01 video model, MiniMax-VL-01 visual multimodal model, and MiniMax-T2A-01 language model series.
Especially noteworthy is the widely praised MiniMax-01 series, which includes both a base language model and a visual multimodal model. Matching the performance of top domestic and international models like DeepSeek-V3 and GPT-4o, it also achieved the first large-scale implementation of the novel Lightning Attention architecture.
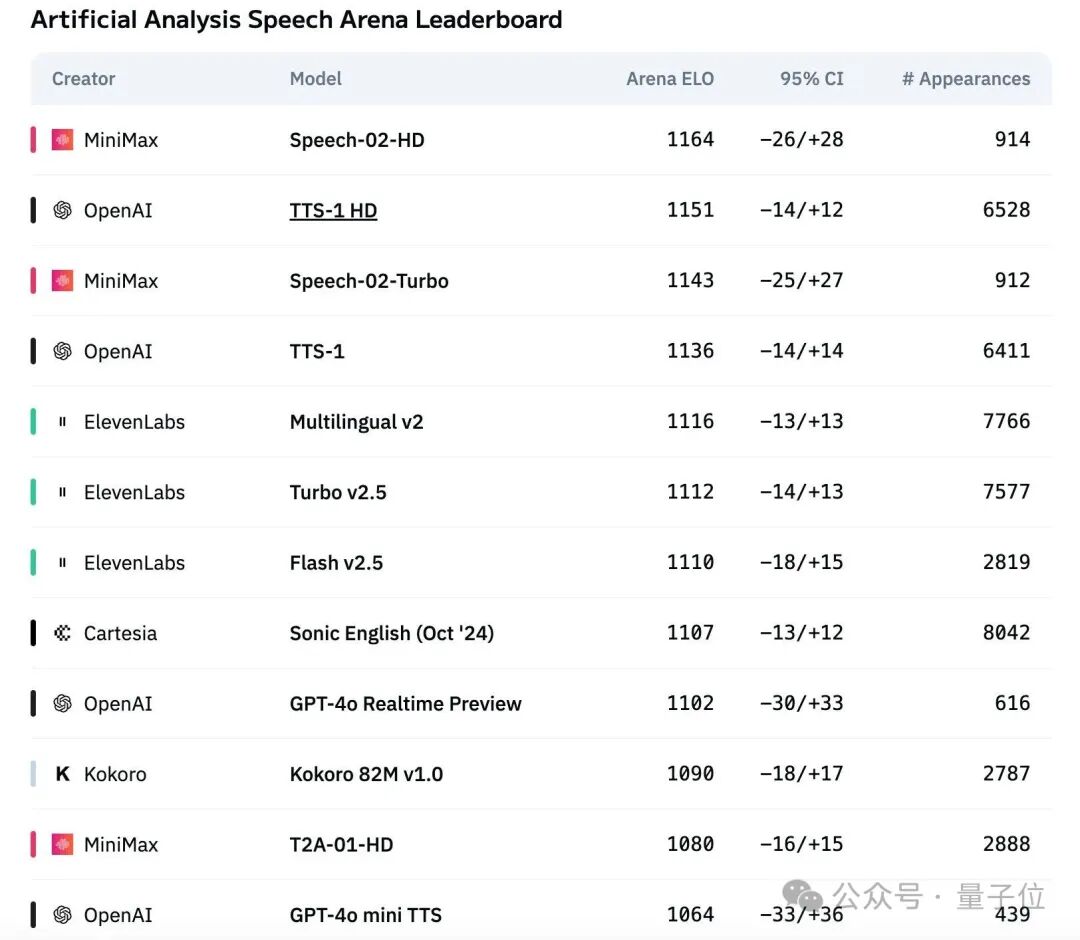
The recently released Speech-02 has also been dominant in AI speech generation, directly refreshing global authoritative speech benchmark leaderboards and breaking the industry duopoly of OpenAI and ElevenLabs.
It is understood that this unified visual task RL architecture is intended to pave the way for general visual capabilities in subsequent larger-scale models.
More open-source resources from MiniMax: Paper: https://arxiv.org/abs/2505.18129 Code: https://github.com/MiniMax-AI/One-RL-to-See-Them-All References: [1]https://x.com/MiniMax__AI/status/1926949919228600423 [2]https://huggingface.co/papers/2505.18129
We look forward to MiniMax continuing to refine general visual capabilities, using open-source as a foundation to accelerate the transition of multimodal AI capabilities from research to industrial application.





