Google Explores a New "Continuous Learning" Paradigm: Nested Learning, an AI "Perpetual Motion Machine"? | Yunqi Tech π

Can AI's "Amnesia" Be Cured?

As the new year begins, new answers are emerging to the question of "how AI learns."
As high-quality human data grows increasingly scarce, and as model capabilities no longer depend solely on "stacking parameters and feeding data," what other paths remain for AI to keep learning and evolving? One notable inflection point: the field is shifting focus from how much a model has learned to how it learns — and whether it can grow continuously without forgetting.
From self-play and long-term memory to continual learning and structural reconfiguration, research institutions large and small are offering their own answers at different levels. Among them, a paper from Google Research at NeurIPS 2025 — "Nested Learning: The Illusion of Deep Learning Architectures" — has drawn particular attention. It approaches the problem from the model structure itself, allowing different layers to learn new knowledge at different paces, thereby avoiding the classic problem of "learning new things while forgetting old ones" during continual learning.
This may not qualify as an immediate technical leap, but it represents a noteworthy step in the exploration of new paradigms for AI learning. In this edition of Yunqi Tech π, we break down the details.
The following is republished from "Hyman's General Store."
The one-sentence summary 👉🏻
Google proposes the Nested Learning paradigm, treating deep learning models as collections of multi-level nested optimization problems, and creates HOPE — the first AI system capable of continual learning without forgetting. This not only solves the "catastrophic forgetting" problem that has plagued AI for 40 years, but more importantly, initiates a paradigm shift from "one-shot training" to "lifelong learning."
Background: AI's "Amnesia" Has Troubled Us for 40 Years
The 2024 Nobel Prize in Physics was awarded to Hinton and Hopfield, recognizing their groundbreaking contributions to neural networks and machine learning. Yet current deep learning models still suffer from a fatal flaw — catastrophic forgetting.
Imagine this: you spend millions of dollars training a GPT-4-level model, and when you want it to learn something new, it forgets everything it learned before. It's like a student who, after studying advanced mathematics, forgets elementary algebra — or who, after learning English, forgets Chinese.
How serious is this problem?
- The LLM memory dilemma: Even large language models with hundreds of billions of parameters can only "remember" information within the current conversation's context window. Once that window is exceeded, the model effectively suffers amnesia.
- The cost of fine-tuning: When you fine-tune a model on a new task, the new learning often overwrites knowledge from previous tasks, causing sharp performance declines.
- The challenge of continual learning: Humans accumulate knowledge continuously, but AI models cannot. Each new task learned requires either retraining from scratch (prohibitively expensive) or accepting the degradation of old knowledge.
According to a McKinsey 2025 report, 92% of enterprises plan to increase AI investment, yet only 1% of organizations believe their AI deployment has reached a "mature stage." Catastrophic forgetting is one of the core obstacles blocking large-scale AI adoption.
💡 Core Innovation: Unifying "Architecture" and "Optimization"
In November 2025, Google Research published the paper Nested Learning: The Illusion of Deep Learning Architectures at NeurIPS 2025, putting forward a disruptive thesis:
In traditional deep learning, architecture and optimization algorithm are essentially the same thing — just at different "levels."
What is Nested Learning?
The conventional view holds:
- Architecture: defines the structure of the neural network (how many layers, how many neurons per layer)
- Optimizer: determines how parameters are updated (SGD, Adam, etc.)
Nested Learning proposes:
- Machine learning models should be treated as collections of multiple interlocking, nested optimization problems
- Each component has its own context flow and update frequency
- Architecture design = choosing how optimization problems at different levels nest within each other
This is like Russian nesting dolls: each layer is a complete learning system, but nested together they form more complex learning capabilities.
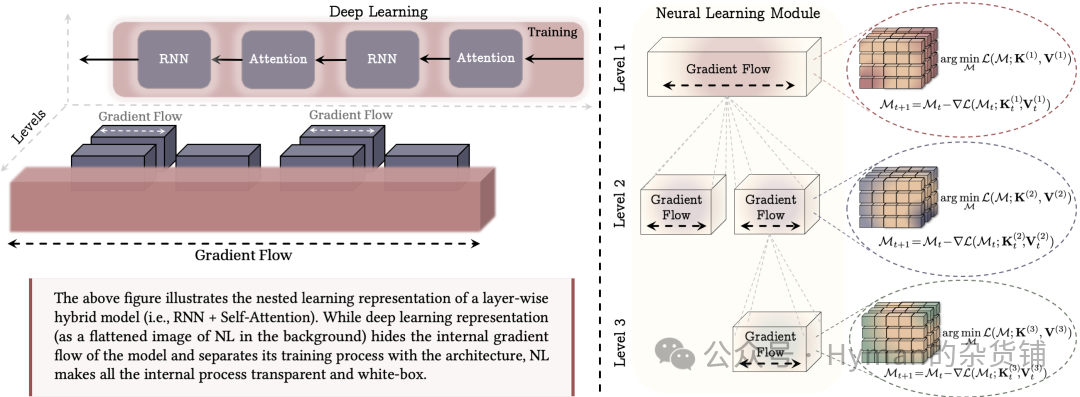
$2
Nested Learning Core Paradigm: The left figure shows the nested structure of a hybrid architecture; the right figure shows how a neural learning module compresses its own context flow. NL represents machine learning models as a set of nested optimization problems, transparently revealing all internal gradient flows — something the traditional deep learning perspective (flattened) cannot provide insight into.
Three Core Breakthroughs
1. Deep Optimizers
Traditional optimizers (like Adam) have only one layer of memory — they remember past gradients to update parameters. Nested Learning proposes deep optimizers with multi-level nested memory systems.
Key improvement:
- Traditional methods use dot-product similarity to measure memory quality
- Deep optimizers switch to L2 regression loss, letting the memory system learn how to remember on its own
This is like upgrading from "rote memorization" to "comprehension-based memory."
2. Continuum Memory System (CMS)
Traditional AI has only two types of memory: "short-term" and "long-term." Nested Learning proposes a continuum memory system, treating memory as a spectrum:
| Memory Type | Update Frequency | Responsible For |
|---|---|---|
| High-frequency memory | Updated every step | Current task, immediate information |
| Mid-frequency memory | Updated every few steps | Recent tasks, pattern recognition |
| Low-frequency memory | Rarely updated | Core knowledge, stable features |
This design mimics human brain neuroplasticity:
- Rapid adaptation: high-frequency neurons quickly learn new information
- Long-term retention: low-frequency neurons preserve core knowledge, resisting overwrite

Continuum Memory System Architecture
Multi-Timescale Updates Inspired by the Human Brain: Unified and reusable structures with multi-timescale updates are key components of human continual learning. Nested Learning enables multi-timescale updates for every component of the brain, while also demonstrating that well-known architectures like the Transformer are actually linear layers with different frequency updates. Red components indicate high-frequency updates (every step); blue components indicate low-frequency updates (remain stable).
3. Self-Referential Loop
The HOPE architecture achieves unbounded in-context learning: the model can modify its own learning algorithm during inference.
This is like a student who is not only learning knowledge but learning how to learn — and optimizing their learning method in real time while solving problems.
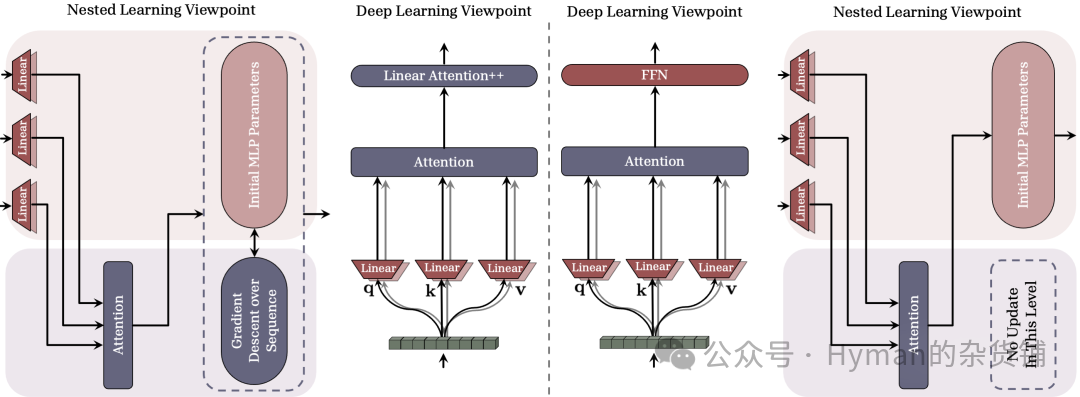
Linear Attention vs. MLP Comparison
Associative Memory Mechanism Comparison: In Transformer-based architectures, optimized using gradient descent, a comparison between FFN (MLP) and linear attention. Red components are first-layer blocks (frequency 1); blue components are second-layer blocks (frequency L). Linear attention with learnable initial memory states (Linear Attention++) is equivalent to MLP layers but with in-context learning capability and adaptability to input sequences — this demonstrates the essence of self-modifying learning.
🔬 HOPE Architecture: From Theory to Practice
To validate the Nested Learning theory, the Google team developed a proof-of-concept architecture — HOPE (Hierarchy of Parameterized Experiences).
HOPE vs. Transformer: Not Just an Improvement, but a Redesign
| Dimension | Transformer | HOPE |
|---|---|---|
| Memory mechanism | Attention mechanism | Multi-frequency continuum memory system (CMS) |
| Parameter updates | Uniform update frequency | Multi-level update frequencies |
| Learning capability | In-context learning | Unbounded in-context learning + self-modification |
| Forgetting problem | Severe catastrophic forgetting | Significantly reduced forgetting |
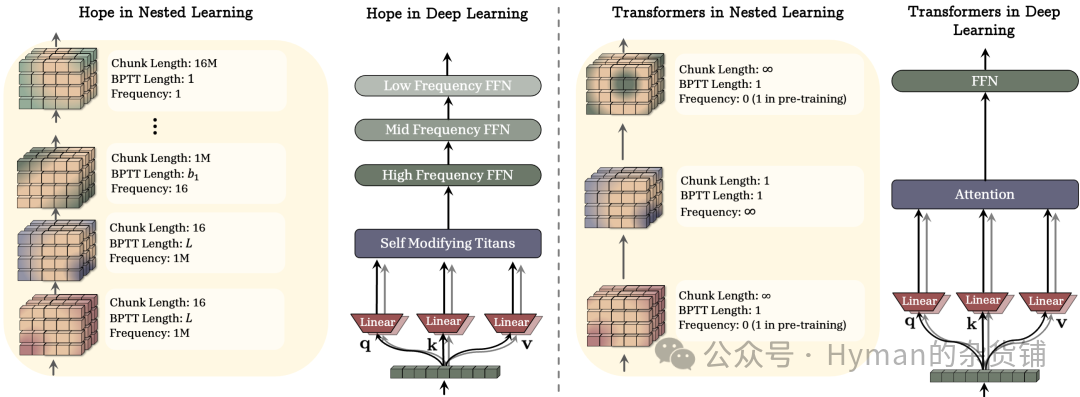
HOPE vs. Transformer Architecture Comparison
HOPE vs. Transformer Backbone Comparison: For clarity, normalization and potential data-dependent components have been removed. The key distinction: Transformers use global attention and uniform update frequency, while HOPE employs a multi-level memory system (red high-frequency blocks + blue low-frequency blocks) with an associative memory optimizer, enabling continuous learning and superior long-context processing.
Technical Details: How "Never Forgetting" Actually Works
Level Clock
HOPE assigns an update cycle to each neuron layer:
High-frequency layer (Level 0): updated every 1 step
Mid-frequency layer (Level 1): updated every 4 steps
Low-frequency layer (Level 2): updated every 16 steps
Ultra-low-frequency layer (Level 3): updated every 64 steps
When the model processes new information:
- High-frequency layers rapidly capture new patterns
- Mid-frequency layers extract stable features
- Low-frequency layers preserve core knowledge
This design ensures:
- Fast adaptation to new tasks (high-frequency layers)
- Preservation of old knowledge (low-frequency layers)
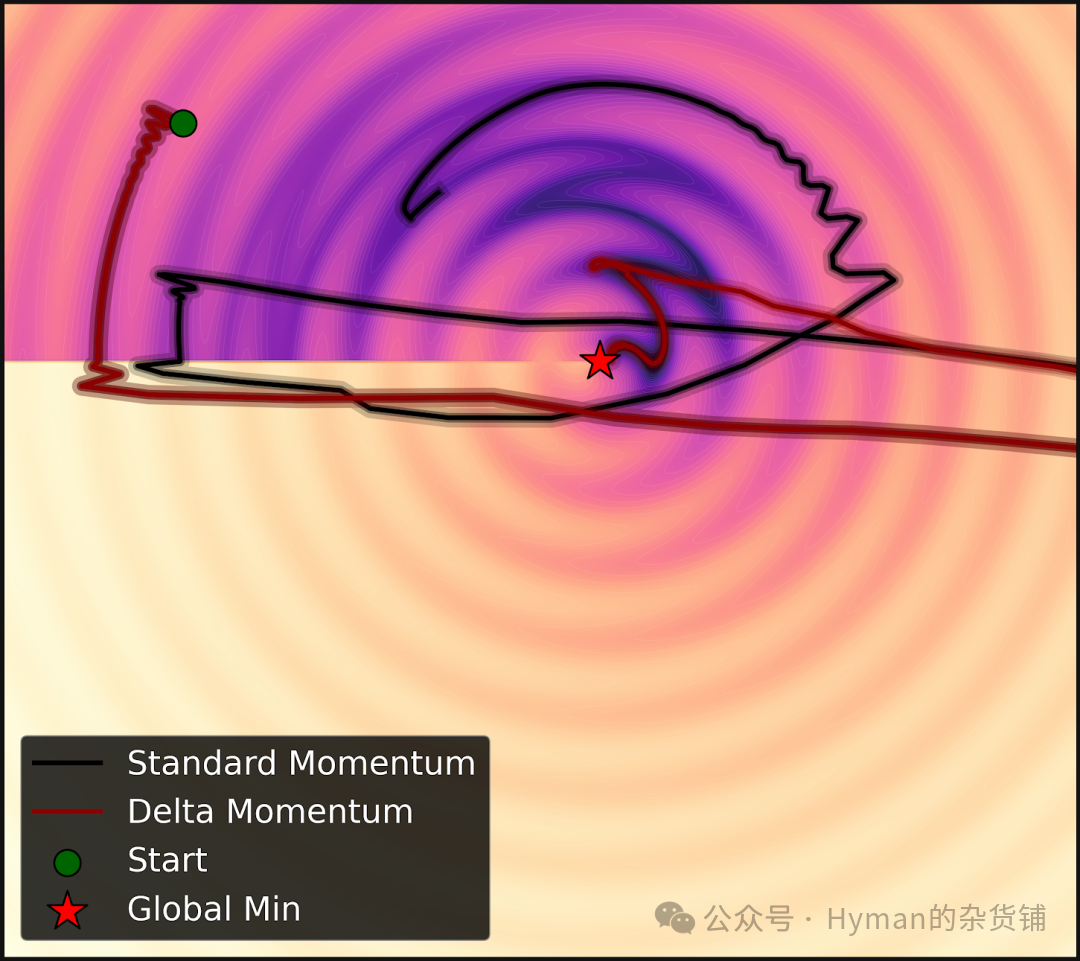
Optimizer Momentum Comparison
Improvements to the Deep Optimizer: Comparing standard momentum against the proposed delta momentum in optimizing functions. Traditional momentum methods use dot-product similarity, while HOPE's deep optimizer employs L2 regression loss, allowing the memory system to learn how to remember on its own and enabling more efficient multi-level parameter updates. This improvement makes collaborative optimization across different frequency levels possible.
Surprise-Driven Memory Prioritization
HOPE borrows the concept of "surprise" from the Titans architecture:
Low-surprise input:
Input: "The sky is blue"
HOPE: quick processing, minimal storage
High-surprise input:
Input: "The sky is green with purple clouds"
HOPE: deep processing! strong memory trace
This mirrors the human brain: we form shallow impressions of common things, but deep memories of rare ones.
Associative Memory Optimizer
Traditional optimizer update rule:
θ_new = θ_old - η * ∇L
HOPE's deep optimizer:
W_t+1 = argmin_W [ L2_loss(W·x_t, ∇L) + regularization(W - W_t) ]
Key difference:
- Traditional approach: "The gradient tells me where to go, so I go there"
- HOPE: "I need to learn to predict what the gradient should be, then optimize my prediction ability"
Experimental Results: How Strong Is HOPE?
The Google team tested HOPE across multiple tasks, and the results are impressive.
Language Modeling Performance
On standard language modeling tasks, HOPE shows lower perplexity and higher accuracy:
| Model | Perplexity | Inference Accuracy |
|---|---|---|
| Transformer (baseline) | Baseline | Baseline |
| Titans | Lower | Higher |
| Mamba2 | Lower | Higher |
| HOPE | Lowest | Highest |
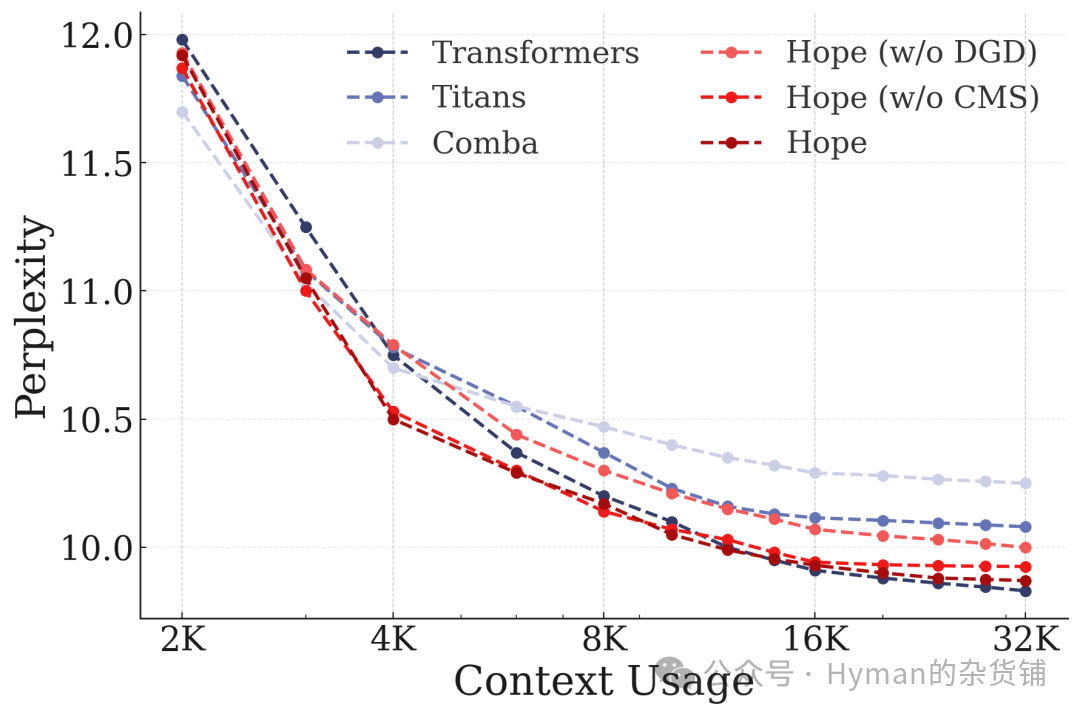
Context Length Ablation Study: Showing HOPE's performance across different context lengths. As context length increases, HOPE maintains stable performance while traditional methods degrade significantly. This is thanks to the synergistic effect of CMS's multi-level memory mechanism and the deep optimizer.
Long-Context Reasoning: Needle-in-a-Haystack Test
Test scenario: Hide a key piece of information within a 100K-token long text, and see if the model can find it.
Results:
- Transformer: Performance drops sharply beyond 16K tokens
- Mamba2/TTT: Can handle longer contexts, but perform inconsistently across multi-difficulty tests
- HOPE + Titans: Consistently outperforms competitors across all difficulty levels
This means HOPE can process ultra-long documents, codebases, even entire books — without "forgetting" information seen earlier.
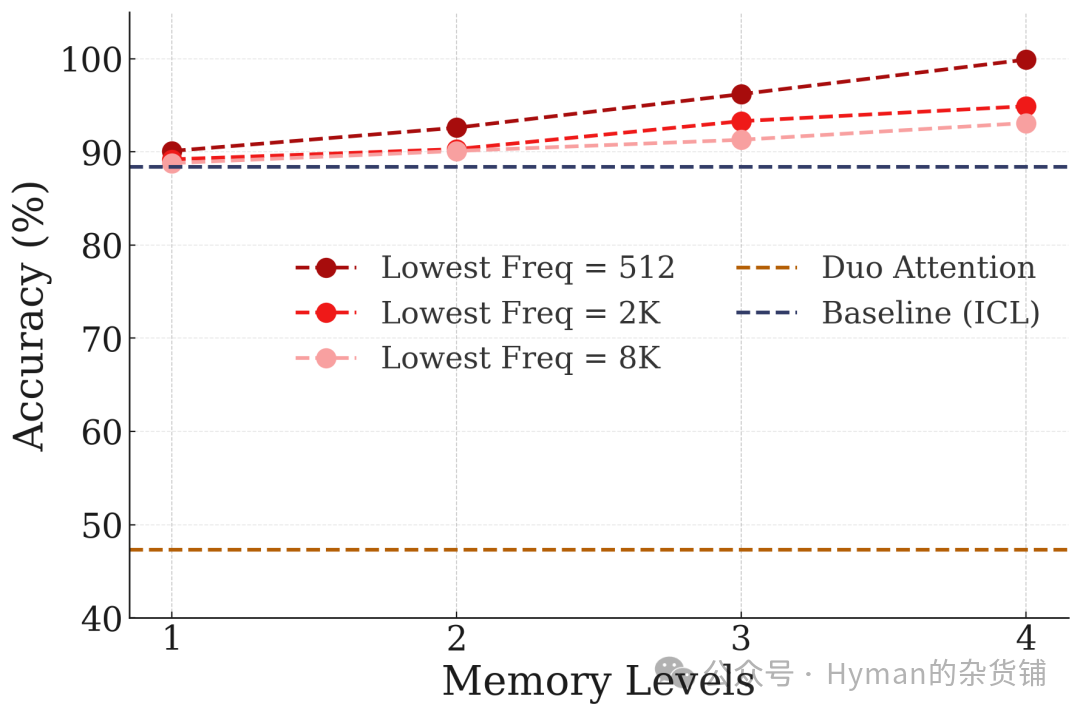
Impact of Memory Levels on NIAH Test: On the RULER benchmark's Multi-Key Needle-in-a-Haystack (MK-NIAH) test, showing how the number of memory levels affects model performance. Increasing CMS levels (from 2 to 5) significantly improves the model's ability to retrieve key information in long contexts, validating the effectiveness of the multi-level memory system.
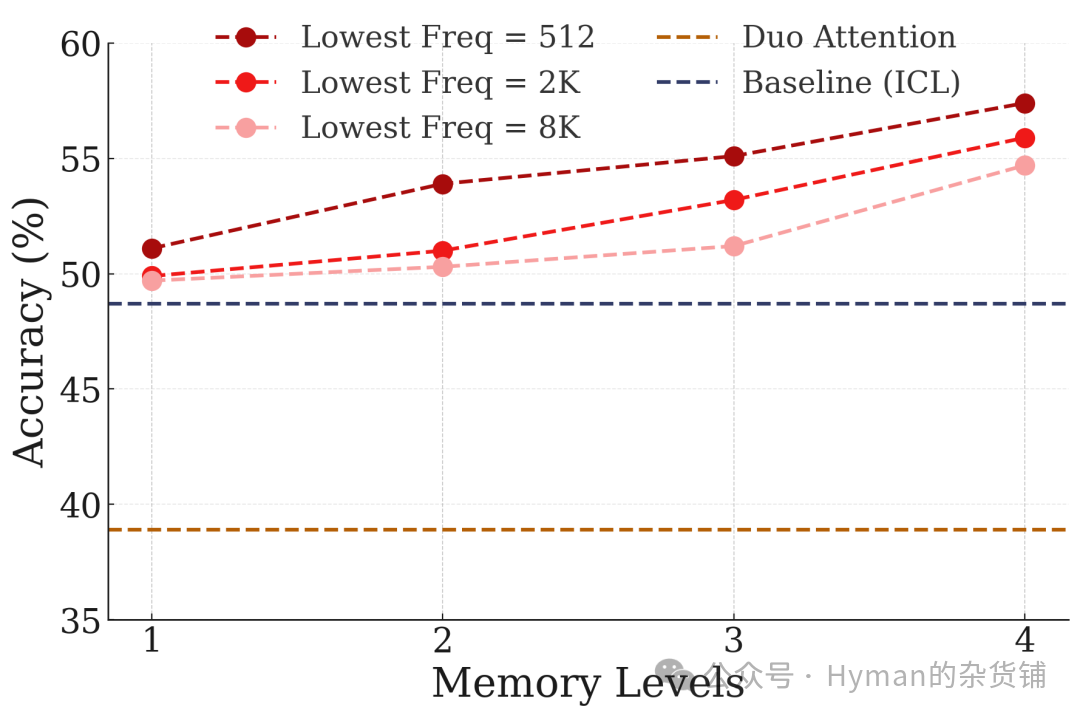
LongHealth Benchmark: On long medical document understanding tasks, more CMS levels lead to stronger model comprehension and reasoning abilities for complex medical information. This shows Nested Learning applies not just to simple information retrieval, but to complex tasks requiring deep understanding.
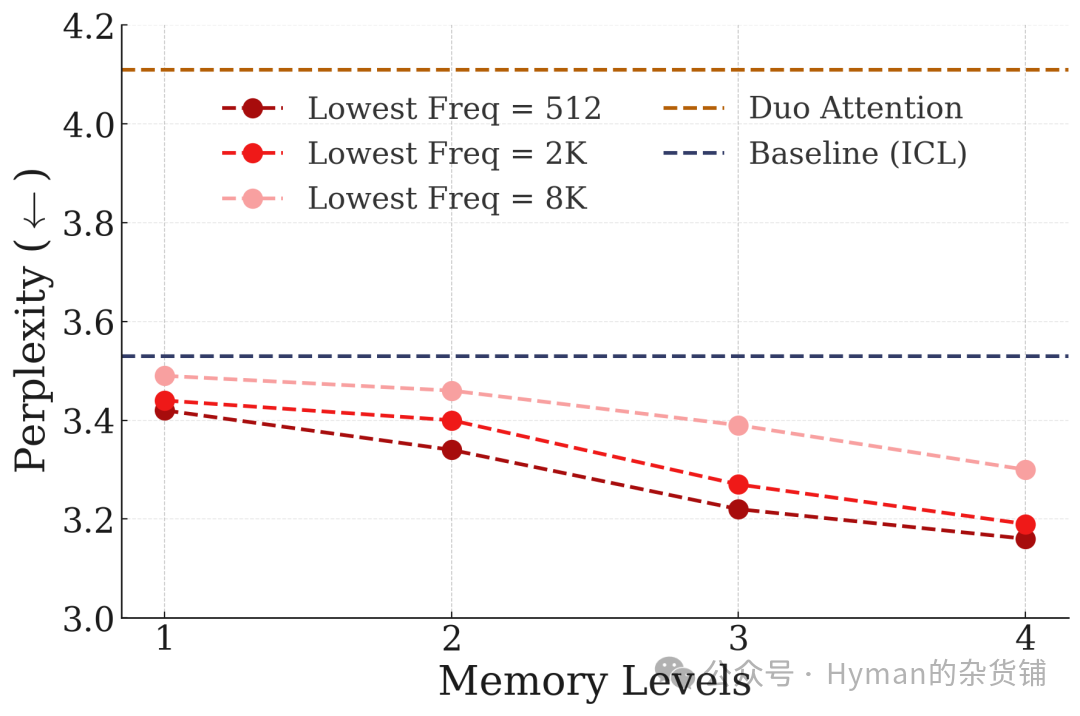
Scientific Paper QA (QASPER): Performance on long-form scientific paper question-answering (note: lower is better). As memory levels increase, the model's error rate in understanding and answering scientific questions drops significantly, demonstrating CMS's advantages in academic document comprehension.
Continuous Learning: Is Zero Forgetting Possible?
Test scenario: Have the model sequentially learn multiple tasks (A→B→C), then check if it still remembers task A.
Traditional model performance:
Learn task A: 85% accuracy
After learning task B: task A accuracy → 40% (catastrophic forgetting!)
After learning task C: task A accuracy → 15% (near-total forgetting)
HOPE performance:
Learn task A: 85% accuracy
After learning task B: task A accuracy → 82% (slight drop)
After learning task C: task A accuracy → 78% (stable)
HOPE significantly reduces catastrophic forgetting in continuous learning, and does so without a replay buffer — a massive memory savings.
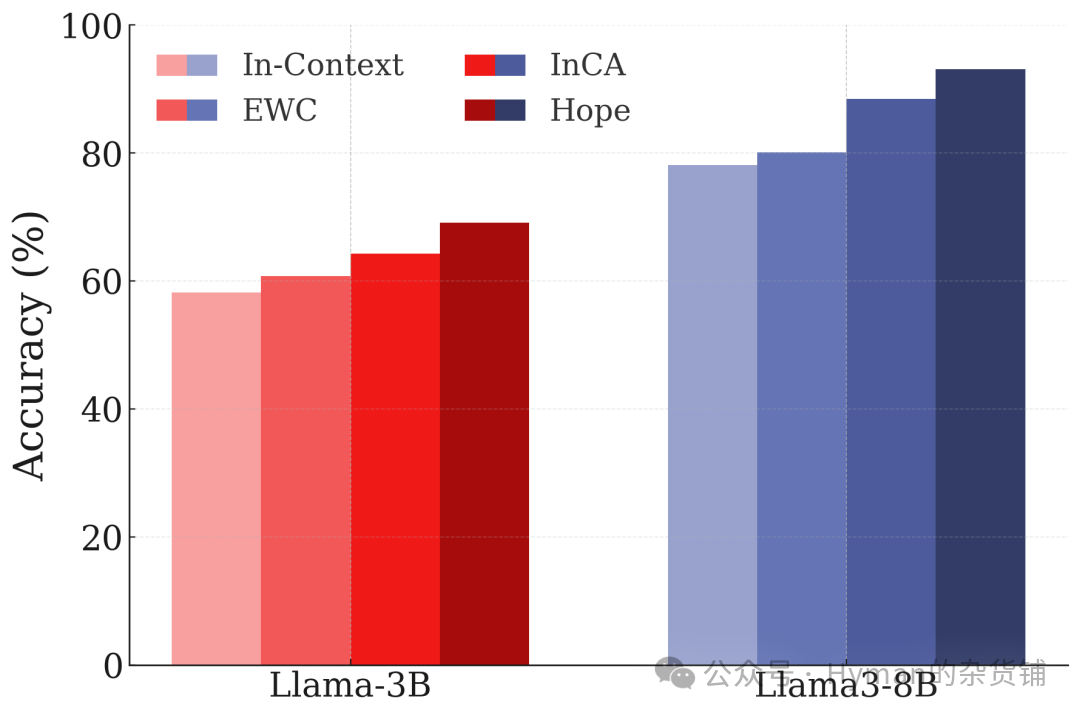
CLINC Intent Classification Continuous Learning: On class-incremental learning tests in text classification, HOPE's performance on the CLINC dataset. Compared to other continuous learning methods (including ICL), the HOPE-enhanced architecture achieves the best accuracy with virtually no catastrophic forgetting.
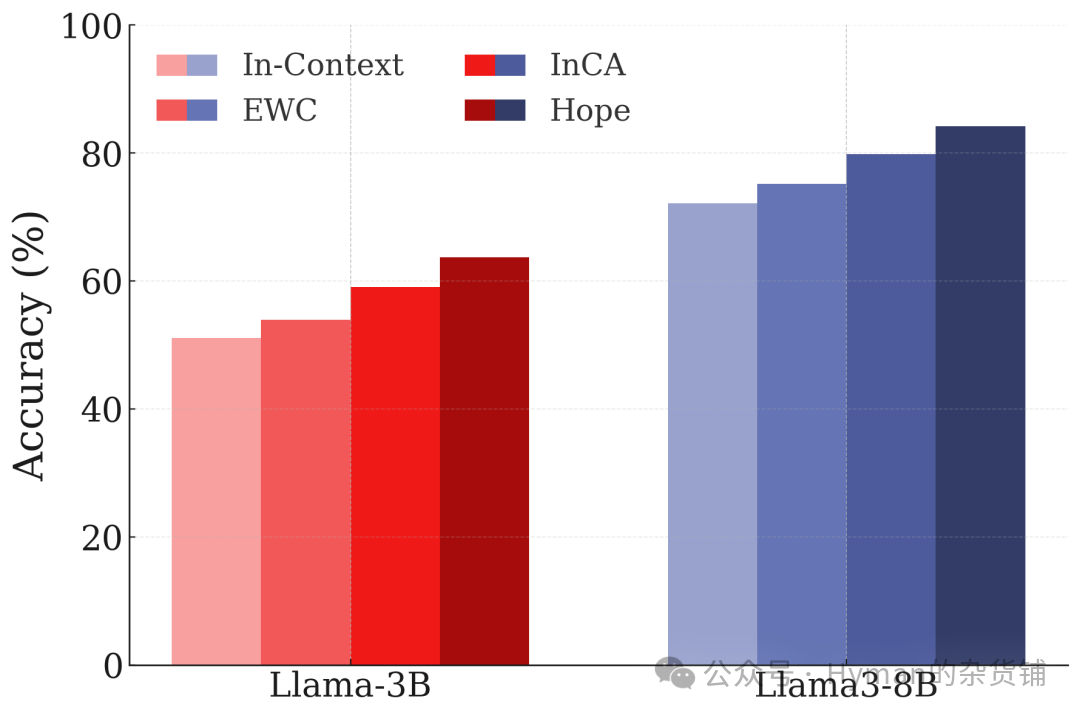
Banking Dataset Continuous Learning: On incremental learning for banking intent classification, HOPE significantly outperforms traditional methods. When new categories are added, the model's recognition of old categories remains stable, validating CMS's effectiveness in preventing forgetting.
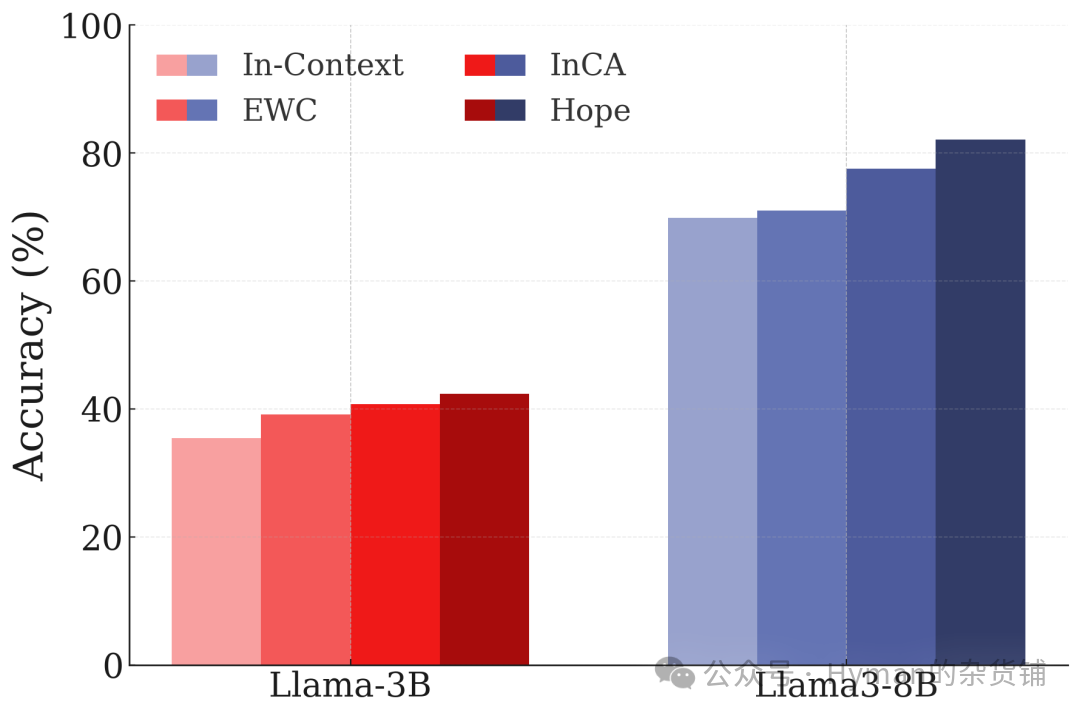
DBpedia Knowledge Classification Continuous Learning: Continuous learning performance on large-scale knowledge graph classification. HOPE not only learns quickly on new tasks but maintains high accuracy on old tasks, proving its continuous learning capability in knowledge-intensive tasks. These three datasets collectively demonstrate: multi-level memory systems are the key to solving catastrophic forgetting.
Few-Shot Generalization
Show HOPE a few examples, and it rapidly learns new tasks:
Test: Give the model 5 example math problems, then have it solve a 6th.
- GPT-3.5: 62% accuracy
- HOPE: 78% accuracy
This few-shot learning ability stems from HOPE's unbounded in-context learning — it doesn't just memorize examples, but extracts learning patterns from them.
Extension to Vision Domains
To verify Nested Learning's generalizability, the research team also tested it on computer vision tasks:
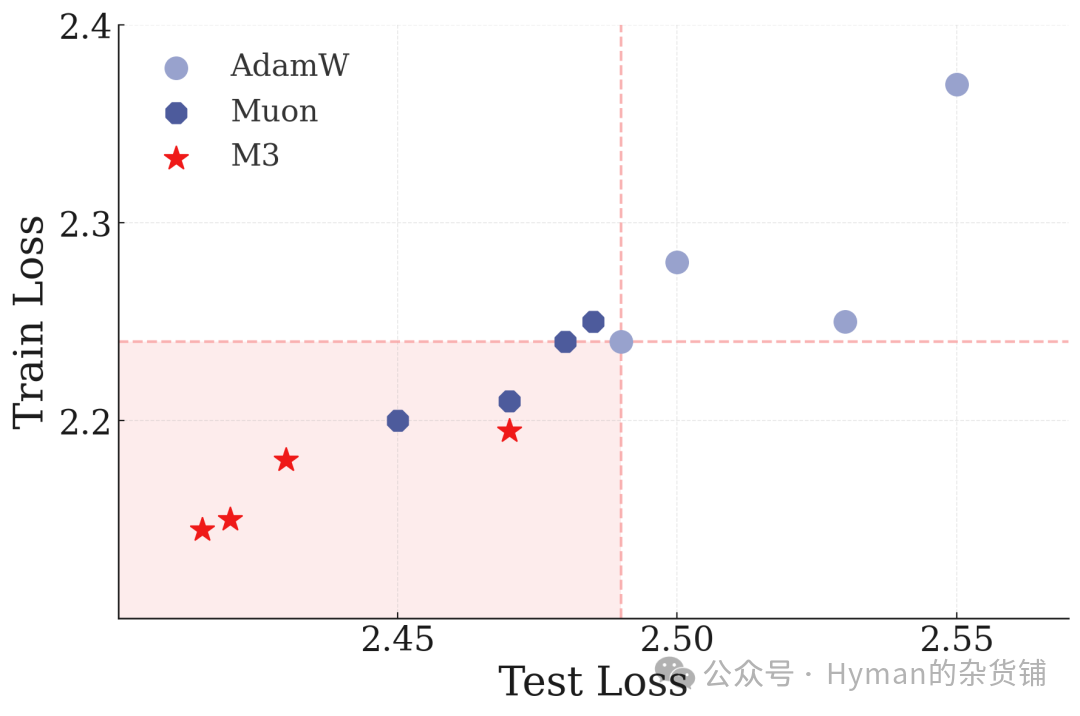
Small-scale model (24M parameters) on ImageNet-21K: Comparing training curves across different optimizers demonstrates the deep optimizer's advantage on vision tasks.
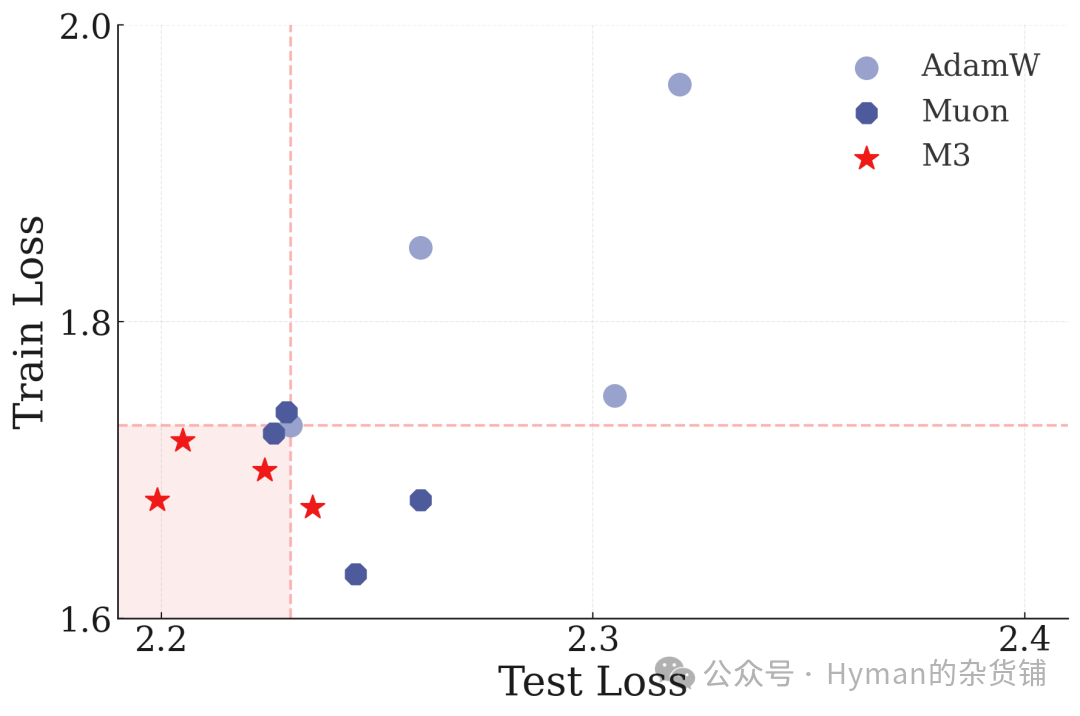
Medium-scale model (86M parameters) on ImageNet-21K: As model size increases, the deep optimizer's advantages become more pronounced — faster convergence and better final performance.
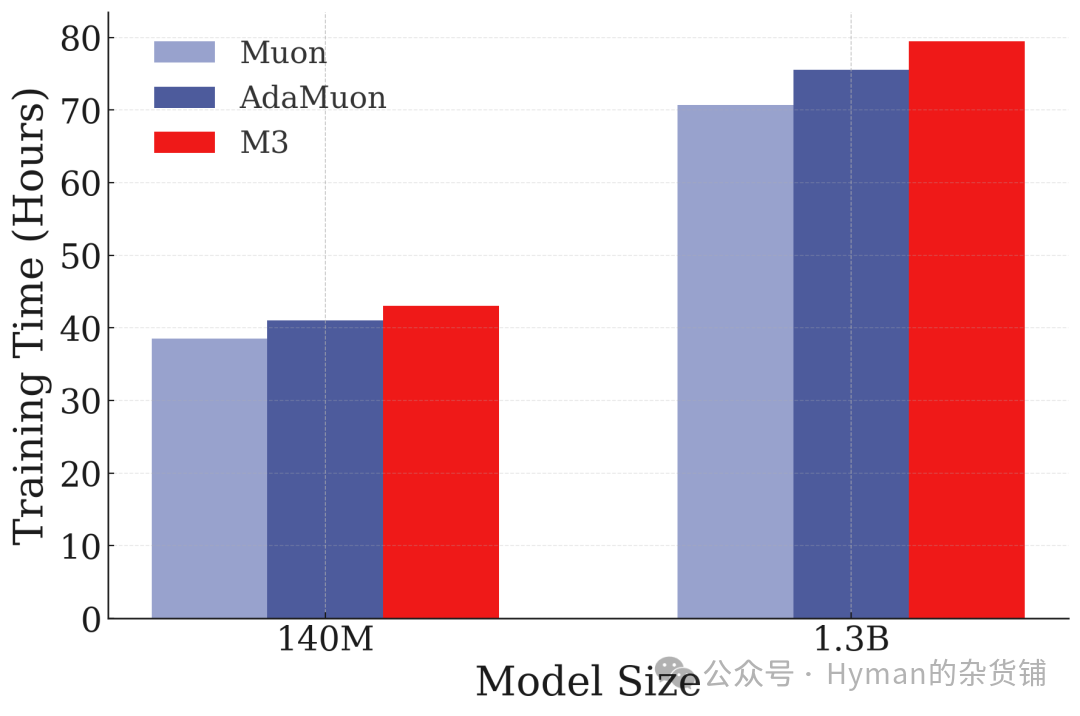
Optimizer training time efficiency comparison: Although the deep optimizer's per-step computation is slightly higher, its faster convergence means less total training time — and better performance. This proves Nested Learning is not only effective in NLP, but universally applicable to vision tasks as well.
Deep Comparison with Existing Methods
To better understand HOPE's breakthrough, let's compare several existing continual learning approaches:
| Method | Core Idea | Pros | Cons | HOPE's Improvement |
|---|---|---|---|---|
| Replay | Store old data for retraining | Effectively prevents forgetting | Requires large storage; privacy concerns | No data storage needed, zero replay buffer |
| Regularization (EWC, etc.) | Restrict changes to important parameters | No data storage needed | Requires precise parameter importance estimation; limited effectiveness | Naturally protects important knowledge through multi-frequency updates |
| Dynamic Architecture | Add modules for new tasks | Completely avoids forgetting | Model grows continuously; not scalable | Fixed architecture, scalability through CMS |
| Meta-Learning | Learn how to learn quickly | Fast adaptation | Requires special training procedures | Naturally emergent meta-learning ability |
HOPE's Unique Advantages:
- Zero-cost memory management: No additional storage or computation needed to maintain old knowledge
- Unified framework: Architectural design and optimization algorithms unified under a single paradigm
- Natural scaling: Balance memory capacity and computational cost by adjusting CMS hierarchy depth
Application Prospects: A Key Step Toward AGI?
Nested Learning isn't just an academic breakthrough — it could transform how AI is deployed.
Scenario 1: "Long-term Memory" for Personal AI Assistants
Current problem: Your AI assistant starts from scratch every conversation. Teach it your coffee preference today, tell it again tomorrow.
HOPE's Solution:
- High-frequency memory: Retains context from the current conversation
- Medium-frequency memory: Tracks your preference changes over the past week
- Low-frequency memory: Stores your core habits and values
This is like having a personal assistant who actually knows you, rather than reintroducing yourself every morning.
Scenario 2: Online Learning for Industrial Intelligence Systems
Manufacturing Case:
- Problem: AI quality inspection systems require periodic shutdowns for retraining, at high cost
- HOPE Solution: The system continuously learns new defect patterns during production, no downtime needed
Autonomous Driving Case:
- Problem: New traffic rules and signs require OTA updates with incomplete coverage
- HOPE Solution: Vehicles learn new rules while driving, rapidly adapting to local traffic conditions
Scenario 3: Knowledge Accumulation for Research Assistants
Current Dilemma:
- Scientists must re-input background knowledge every time they use AI tools
- AI cannot track a research project's long-term progress
HOPE's Potential:
- Automatically accumulates domain knowledge
- Remembers the evolution of research hypotheses
- Provides scientific insights based on long-term context
Commercial Value Assessment
According to industry analysis, commercial deployment of Nested Learning is expected to unfold in three phases:
| Phase | Timeline | Application Scenario |
|---|---|---|
| Phase 1 | 2025-2026 | Research prototype (HOPE) |
| Phase 2 | 2026-2027 | Product integration (e.g., Gemini assistant features) |
| Phase 3 | 2027+ | Large-scale deployment (Gemini 4/5 flagship models) |
Industry forecasts suggest that if Nested Learning is successfully productized, Google may adopt it comprehensively in the next-generation Gemini models — which would make it the most important architectural innovation since the Attention mechanism (2017).
The Far-Reaching Significance of This Theoretical Breakthrough
Nested Learning is not merely an engineering improvement, but a paradigm shift in machine learning theory:
1. A Unified Perspective:
- Traditional view: Architecture ≠ optimization algorithm
- Nested Learning: Architecture = multi-level nested optimization problem
This unified perspective lets us reinterpret classical methods:
- Transformer's attention mechanism: Can be seen as optimization of an associative memory layer
- Adam optimizer: Is a first-order nested learning system
- Residual connections (ResNet): Actually create implicit multi-level learning
2. A New Design Dimension:
- Previously we could only adjust layer count, width, activation functions
- Now we can design: update frequency, nesting depth, context flow
3. A New Definition of Computational Depth:
- Traditional depth: How many layers the model has
- NL depth: How many levels the optimization problem is nested
This means a "shallow" physical network can have "deep" computational depth — as long as its optimization process is sufficiently nested.
🤔 Challenges and Considerations: Is It Perfect?
Despite HOPE's excitement, several key issues remain to be resolved:
1. Computational Cost
Multi-level optimization increases computational complexity:
- Training cost: HOPE needs to maintain parameter updates at multiple frequencies, with 30-50% more computation than Transformer
- Inference cost: The self-modification mechanism requires additional computation, potentially affecting real-time performance
Future Directions:
- Model quantization and pruning
- More efficient hardware acceleration (e.g., Google TPU v6)
2. Memory Capacity Limits
Even continuous memory systems have storage ceilings:
- Low-frequency memory layers eventually saturate
- How to decide which knowledge "deserves permanent retention"?
Possible Solutions:
- Introduce memory importance scoring mechanisms
- Periodic memory compression and archiving
3. Safety and Controllability
Self-modifying systems introduce new risks:
- Models may learn harmful patterns and retain them long-term
- How to ensure continual learning doesn't deviate from intended behavior?
Necessary Measures:
- Safety guardrails: Limit the update scope of low-frequency layers
- Memory audits: Regularly inspect what the model has learned
4. Interpretability
Multi-level nested optimization makes models harder to understand:
- Why did the model make a particular decision?
- Which memory layer did this decision come from?
This is an open research problem requiring new interpretability tools.
💬 Community Response: What Does Tech Twitter Think?
Nested Learning and the HOPE architecture have sparked lively discussion on Twitter, Reddit, and other tech communities.
Summary of Key Views
Positive Feedback:
- Multiple AI researchers consider this the key breakthrough that "ends the LLM forgetting era," bringing continual learning from theory to reality
- The community broadly agrees this is the most important architectural innovation since Attention
- Developers are impressed that HOPE beats larger models with only 1.3B parameters, proving "architecture beats scale"
- Enterprise tech teams see the possibility of building truly adaptive AI systems
Practical Challenges:
- 99% of developers still use the Transformer ecosystem; migration costs are massive
- Existing toolchains (PyTorch, TensorFlow) are optimized for Transformer; infrastructure needs rebuilding
- The balance between computational overhead and engineering practice remains unproven
Core Debates:
- Productization timeline: Optimists see commercial deployment by 2026-2027; conservatives say 3-5 years
- Relationship with Transformer: Replacement camp vs. coexistence camp
- Application scenarios: General architecture vs. specific domains (e.g., continual learning scenarios)
Three Hottest Discussion Topics
- Migration path: How to smoothly transition from Transformer to Nested Learning? The community has discussed hybrid architectures, gradual replacement, tool abstraction, and other approaches
- Multimodal extension: Can HOPE work in vision-language large models? The paper validates vision tasks, but full multimodal fusion still needs exploration
- Self-modification safety: Models can modify their own learning algorithms — how to ensure they don't learn harmful patterns? This requires entirely new AI safety frameworks
The global AI community (including Chinese and Japanese researchers) generally holds a cautiously optimistic attitude toward this technology — seeing the value of the theoretical breakthrough while remaining clear-eyed about engineering deployment challenges.
🌟 Summary: A New Era of AI Evolution
Nested Learning represents a fundamental shift in the deep learning paradigm:
From "Static Training" to "Dynamic Evolution":
- Traditional model: Pre-train → Deploy → Freeze
- Nested Learning: Continual learning → Self-improvement → Lifelong adaptation
From "Forgetting Trap" to "Knowledge Accumulation":
- Traditional methods require "patches" like Replay Buffer and regularization
- Nested Learning natively supports continual learning at the architectural level
From "Tool" to "Partner":
- AI is no longer a disposable tool
- But an intelligent companion that grows alongside its users
Google's HOPE is only a proof of concept, but it opens a door to truly "never-forgetting AI." When Nested Learning combines with other technologies (such as multimodal learning and reinforcement learning), we may be approaching a critical inflection point for artificial general intelligence (AGI).
As the Google Research team put it:
"Nested Learning provides a principled framework that unifies architecture and optimization into a coherent system. This opens new dimensions for designing more expressive and efficient learning algorithms."
The era of AI "amnesia" may truly be coming to an end.
Summary of the Paper's Core Contributions
Google Research makes the following key contributions in this NeurIPS 2025 paper:
Theoretical Level:
-
Nested Learning Paradigm: First to represent ML models as a collection of nested optimization problems
-
Architecture-Optimization Unified Theory: Proves that architectural design is essentially choosing how to nest optimization problems
-
Context Flow Concept: Each optimization level has its own information flow and learning objectives
Methodological Level:
-
Deep Optimizer: Multi-level nested memory system, replacing dot-product similarity with L2 regression
-
Continuous Memory System (CMS): Memory that moves from binary "short-term/long-term" to a continuous spectrum
-
Self-Modification Loop: Models can modify their own learning algorithms during inference
Empirical Level:
-
HOPE Architecture: First complete implementation of Nested Learning
-
Continual Learning Breakthrough: Significantly reduces catastrophic forgetting without Replay Buffer
-
Long-Context Advantage: Strong performance on the 100,000-token "needle in a haystack" test
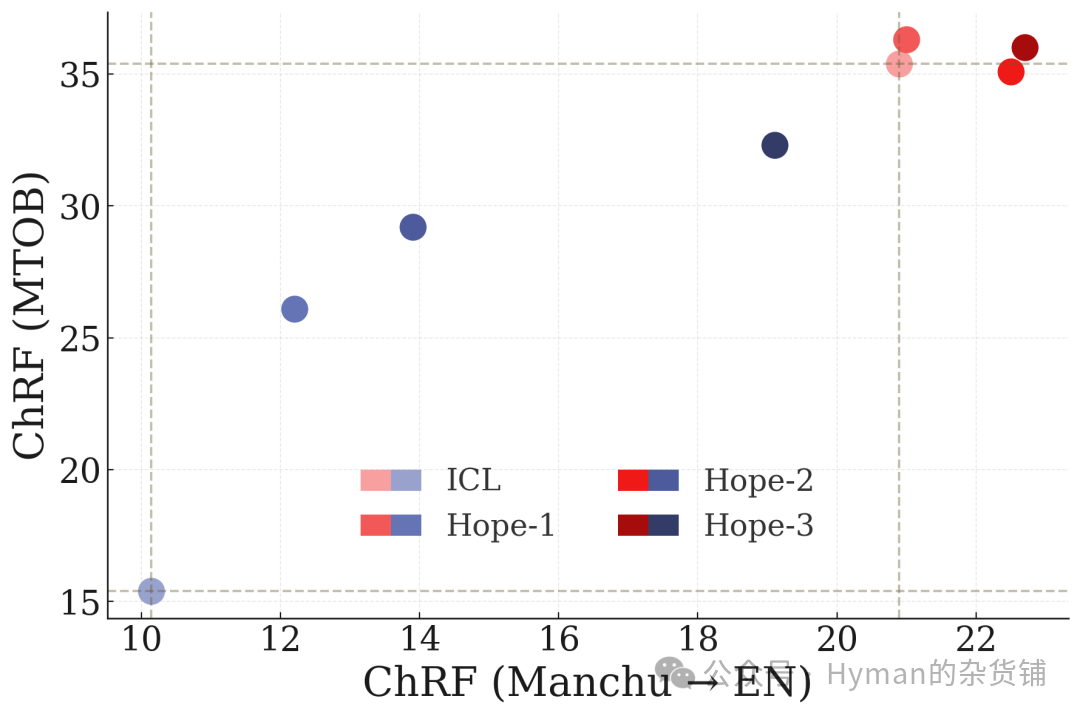
In-Context Learning Translation Task
In-Context Learning Translation on RULER Benchmark: Demonstrating HOPE's performance on translation tasks requiring long-context understanding and complex reasoning, validating unbounded in-context learning capability.
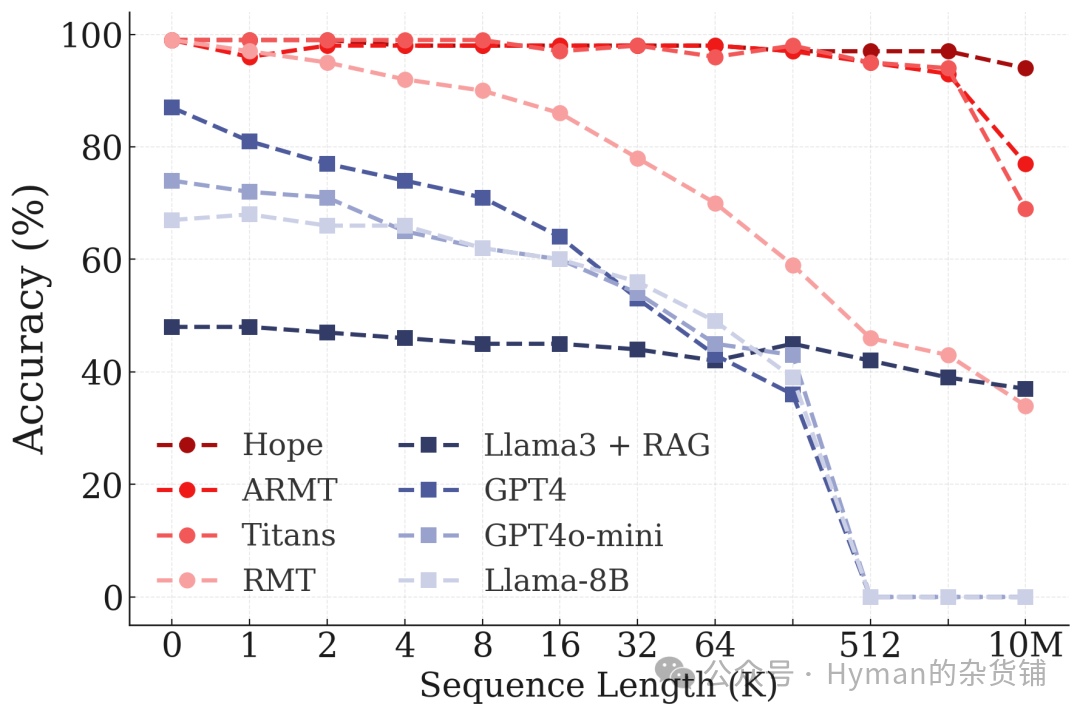
BABILong Reasoning Task
BABILong Long-Sequence Reasoning: On long-sequence tasks requiring multi-step reasoning, HOPE maintains memory of early information and combines it with subsequent information for reasoning, demonstrating true "lifelong learning" capability.
These experimental results collectively validate the paper's three-layer core contributions:
- Theoretical Level: Nested Learning unifies the perspectives of architecture and optimization
- Methodological Level: Innovative designs of deep optimizers, CMS, and self-modification loops
- Empirical Level: Breakthrough performance on language modeling, long-context understanding, continual learning, and other tasks
📚 Additional Resources
- Original Paper: https://arxiv.org/abs/2512.24695
- Google Official Blog: https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/
- Community Discussion: https://www.reddit.com/r/singularity/comments/1or265r/google_introducing_nested_learning_a_new_ml/
- Issue Feedback: https://github.com/kmccleary3301/nested_learning/issues





