The Pros and Cons of OpenAI's New o1 Model, Explained | Yunqi Tech π --- On September 13, Beijing time, OpenAI released its long-awaited new model series, o1-preview and o1-mini — the first fruits of its "Strawberry" project. This represents a significant departure from the GPT series, with o1 built on an entirely new training paradigm. ## What Makes o1 Different? The core innovation is **test-time compute scaling** — essentially, giving the model more time to "think" before responding. o1 spends seconds to minutes internally reasoning through problems, testing different approaches, and correcting its own mistakes before delivering an answer. This mimics how humans tackle complex problems: we don't always blurt out the first thing that comes to mind. We pause, consider alternatives, backtrack when stuck. o1 does something analogous, using a **chain-of-thought** process that's hidden from the user. ## Where o1 Shines **STEM domains, particularly math and coding.** OpenAI's benchmarks show dramatic gains: - **International Mathematical Olympiad (IMO) qualifying exam**: GPT-4o solved 13% of problems; o1 reached **83%** - **Codeforces competitive programming**:

Where's the ceiling for large language models?
The capability curve of large language models continues to extend.
In the early hours of September 13 Beijing time, OpenAI unveiled its next-generation model family, OpenAI o1. This new model, starting fresh from "1," marks OpenAI's first foray into reinforcement learning training, delivering notable leaps in reasoning and mathematical capabilities.
But o1 is no all-purpose model. In this edition of "Yunqi Tech π," we break down the strengths and weaknesses of OpenAI o1 through the lens of the OpenAI team's own commentary and independent model evaluations.
Before we dive in, here are our two key takeaways:
-
Foundational model capability is the core bedrock determining AI application performance. The prevailing trajectory in AI right now is continuous capital investment to compensate for foundational model limitations, while refining application outcomes that better serve diverse scenarios and customer needs on top of that base.
-
o1 is not an all-purpose model. Its standout reasoning capabilities will bring more pronounced benefits to specialized domains like scientific research, software development, and mathematical computation. However, its weaknesses in natural language processing make it less practical than GPT-4o for everyday tasks. This may reflect OpenAI's evolving model development philosophy: not striving to do everything at once, but staying closer to real-world deployment scenarios.
This article is republished with permission from Founder Park.
Original title: "The Big Move Is Here! OpenAI Releases Its Strongest Reasoning Model o1 — It Actually Thinks, But the API Costs Several Times More Than 4o"
OpenAI's reasoning model, the long-anticipated Strawberry, has arrived!
In the early hours of September 13, OpenAI announced the official release of OpenAI o1-preview, a reasoning model, alongside a smaller, lower-cost version — o1 mini.
OpenAI is calling this a "preview" release, emphasizing that o1 remains in early stages.
OpenAI's API lead posted: "If you had a product idea in the past where the model just wasn't good enough, wasn't smart enough — try it again now."
On access rollout, OpenAI is taking a phased approach:
- ChatGPT Plus and Team users can access o1-preview and o1-mini immediately.
- Enterprise and Edu users will gain access next week.
- Developers at API usage tier 5 (having spent $1,000 and more than 30 days since first payment) can use both models starting today, with a rate limit of 20 RPM.
- OpenAI also plans to open o1-mini access to all free ChatGPT users in the future.
For developers, using o1 via API doesn't come cheap. o1-preview is priced at $15 per million input tokens and $60 per million output tokens — far above GPT-4o's pricing ($5 per million input tokens, $15 per million output tokens).
01 OpenAI Staff:
o1 Redefines the Game
In tweets from OpenAI employees, you can see their enthusiasm for o1's capabilities and some key upgrade highlights.
Tweet from Michelle Pokrass, OpenAI API Lead:
o1-preview and o1-mini models are now live. They are our best reasoning models to date, and we believe they will unlock entirely new use cases for the API.
If you had a product idea whose time had not yet come, where the model just wasn't smart enough — try again.
These new models are not a full replacement for 4o.
You need to prompt them differently and architect your applications in new ways, but we think they will help close the intelligence gap and enable you to build better products.
(Rolling out now for API tier 5 users; broader access coming soon)

Tweet from Greg Brockman:
OpenAI o1 — our first model trained with reinforcement learning, which thinks deeply before answering. Incredibly proud of the team's work!
This is a new paradigm full of massive opportunity. This is apparent quantitatively (e.g., reasoning metrics are already way up) and qualitatively (e.g., faithful chain of thought makes the model legible, since it lets you "read the model's mind" in simple English).
Think of it this way: our models do System 1 thinking, and chain of thought unlocks System 2 thinking. People have already found that prompting the model to "think step by step" improves performance. But training the model to do this from scratch, through trial and error, is more reliable and — as we've seen in games like Go or Dota — can produce extremely impressive results.
o1 technology is still early. It presents new safety opportunities that we are actively exploring, including reliability, hallucinations, and robustness to adversarial attacks. For example, we've already seen big safety improvements by letting the model reason through our safety policy via chain of thought.
There is also much room for accuracy improvement — e.g., from our launch post, our model scored 49th percentile / 213 points at this year's International Olympiad in Informatics (IOI) under human conditions (50 submissions per problem). But allowed 10,000 submissions per problem, the model scored 32.14 points — above the gold medal threshold. So the model is capable of much more output than it initially appears.
Tweet from OpenAI Researcher Jason Wei:
o1 is a model that thinks before giving its final answer. In my own words, here is the biggest update to the field of AI:
Instead of merely performing chain of thought via prompting, use RL to train the model to do chain of thought better.
Throughout the history of deep learning, we have always tried to scale training compute, but chain of thought is a form of adaptive compute that can also be scaled at test time.
The AIME and GPQA results are very strong, but they don't necessarily translate to something users can feel. Even working here, it's hard to find prompt slices where GPT-4o fails, o1 does well, and I can grade it. But when you do find such prompts, o1 feels completely like magic. We all need to find harder prompts.
AI models that use human language for chain of thought are great in many ways. The model does lots of human-like things, such as breaking down tricky steps into simpler ones, recognizing and correcting errors, and trying different approaches. Strongly encourage everyone to look at the chain of thought examples in the blog post.
The game has been completely redefined.
02 A New Leap in AI Capability, Hence the Name o1
o1 is trained using reinforcement learning techniques, specifically designed to handle complex reasoning tasks. Unlike traditional models, o1 has the ability to "think deeply" — before producing its final response, it can engage in extended chains of logical reasoning and internal deliberation, ensuring the quality and depth of its answers.
Through carefully designed training processes, these models have learned not only how to optimize their thinking processes, but also to flexibly employ different problem-solving strategies and to self-correct.
The test results are encouraging. In the upcoming model update, it performed at PhD-level equivalence on complex benchmark tests in physics, chemistry, and biology.
Particularly noteworthy is its outstanding performance in mathematics and programming. For example, in the qualifying exam for the International Mathematical Olympiad (IMO), our new reasoning model correctly solved 83% of problems, far surpassing GPT-4o's 13%. In programming capability, evaluated through Codeforces competitions, the new model outperformed 89% of participants.
As a model in early stages, it currently lacks some of ChatGPT's practical features, such as web browsing, file uploads, and image processing, and its performance on world factual knowledge also falls short of the latter. In the near term, for everyday application scenarios, GPT-4o may still be more practical.
However, in complex reasoning tasks, this new model represents a major leap in AI capability. Based on this breakthrough, we have decided to reset the counter to 1 and name this entirely new model family OpenAI o1, underscoring its pioneering significance.
We developed an innovative large-scale reinforcement learning algorithm that efficiently leverages data while effectively training the model to use its chain of thought for productive reasoning. The core of this training method lies in teaching the model "how to think," rather than merely storing and retrieving information.
Through continued research, we have identified two key factors that significantly improve o1 model performance:
1. Increasing reinforcement learning compute (i.e., training-stage computational investment)
2. Extending the model's "thinking time" (i.e., giving the model more computation time during testing or application)
This approach exhibits scaling characteristics fundamentally different from traditional large language model pre-training. Conventional pre-training is primarily constrained by the acquisition and processing of massive text data, while our method relies more heavily on computational resources and algorithmic optimization. We are currently investigating the scaling limits of this new approach, with the aim of achieving greater breakthroughs in the future.
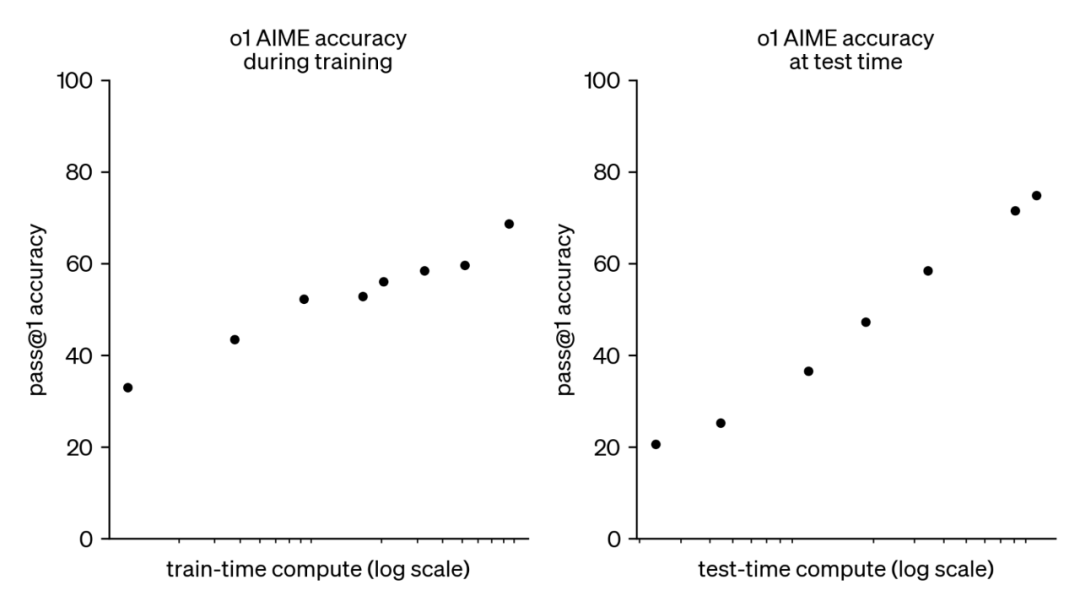
o1's performance improves smoothly as training-time and test-time compute increase.
03 Mathematics: Completely Outclassing 4o,
Ranking Among Top 500 Nationwide
To highlight o1's significant advances in reasoning capability over GPT-4o, we designed a comprehensive and rigorous evaluation framework. This framework includes various human professional exams and widely recognized benchmark tests in machine learning, covering broad knowledge domains and complex reasoning tasks.
The results are encouraging: on the vast majority of tasks requiring deep thinking and complex reasoning, o1 demonstrated clearly superior performance to GPT-4o. This strongly validates o1's exceptional capability in handling difficult, multi-step reasoning problems.
Notably, unless otherwise specified, all o1 evaluations were conducted with maximized test-time compute resources. This means we fully unleashed o1's potential, giving it ample "thinking time" to process these complex tasks.
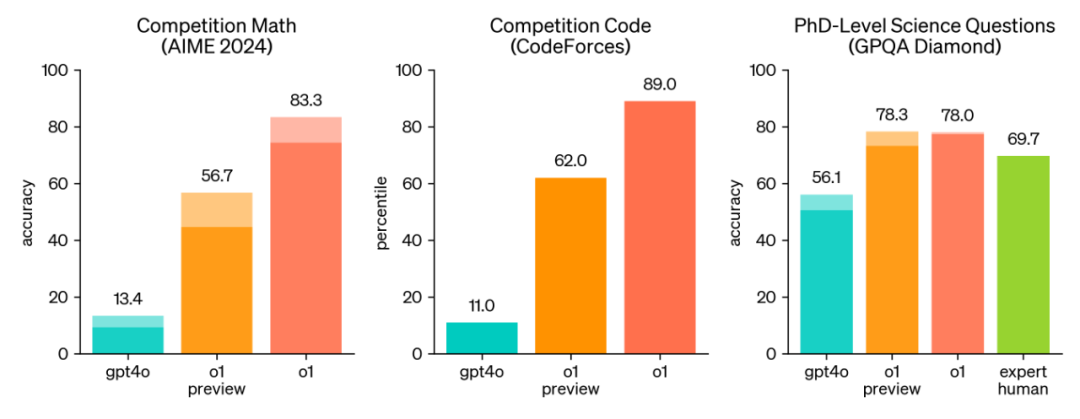
o1 significantly outperforms GPT-4o on challenging reasoning benchmarks. Solid bars indicate pass@1 accuracy, shaded regions show majority vote (consensus) performance across 64 samples.
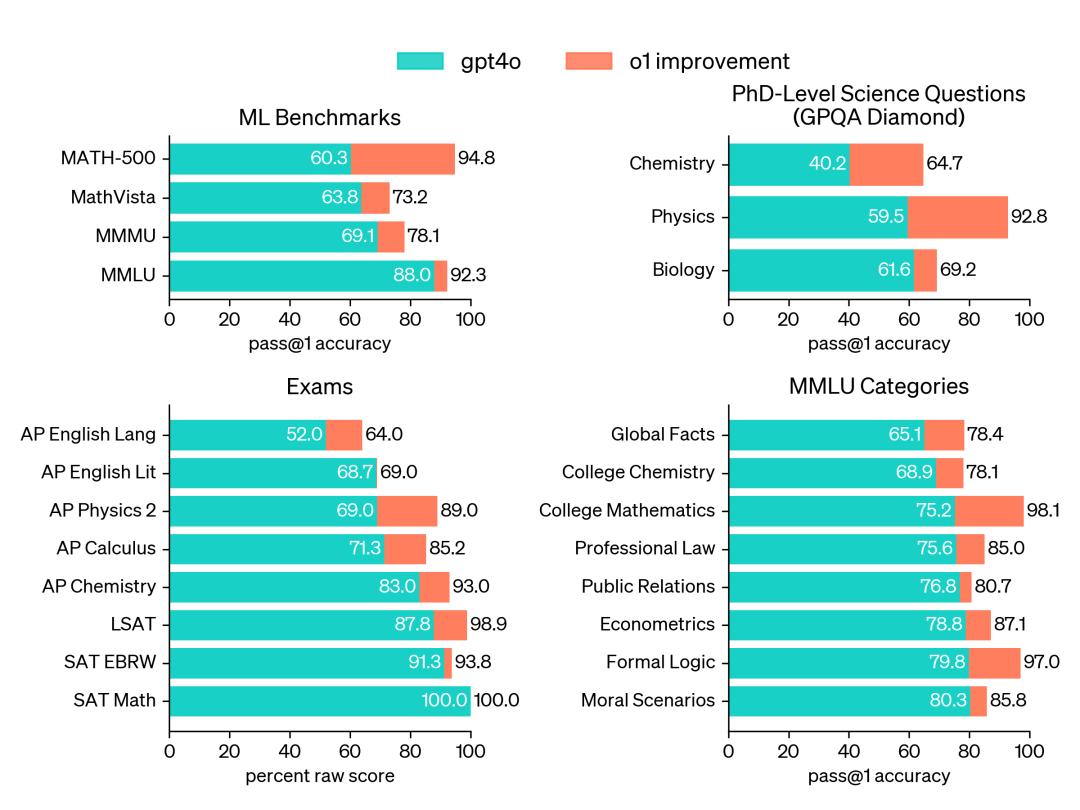
o1 surpasses GPT-4o across a wide range of benchmarks, covering 54 of 57 MMLU subcategories.
The o1 model has demonstrated human-expert-level performance on numerous benchmark tests requiring complex reasoning — a remarkable achievement. Notably, some top AI models have recently performed so well on traditional math tests like MATH2 and GSM8K that these tests no longer effectively differentiate between models.
To more rigorously assess o1's mathematical capabilities, we selected the American Invitational Mathematics Examination (AIME) as our benchmark. AIME is a highly challenging exam designed to test the nation's best high school math students, better suited to probing a model's limits.
On the 2024 AIME exam, we compared o1 and GPT-4o's performance:
-
GPT-4o's performance: Solved an average of only 12% of problems (1.8 out of 15).
-
o1's performance: a. Single attempt: Solved an average of 74% of problems (11.1 out of 15) b. 64 samples with consensus: Accuracy improved to 83% (12.5 out of 15) c. 1,000 samples with learned reranking: Accuracy reached 93% (13.9 out of 15)
o1's best score of 13.9 is a stunning result. This score not only places o1 among the top 500 students nationwide, but exceeds the cutoff for the USA Mathematical Olympiad. This means that if o1 were a high school student, its mathematical ability would qualify it for the nation's highest-level math competition.
We further applied the o1 model to the GPQA diamond test, an extremely challenging intelligence benchmark specifically designed to evaluate model expertise in chemistry, physics, and biology. For fair human-AI comparison, we specifically invited domain experts with PhDs to participate in the test.
The results are exciting: o1 not only completed the test successfully, but surpassed human expert performance, becoming the first AI model to defeat human experts on the GPQA diamond benchmark. This breakthrough marks a new height for AI capability in specific professional domains.
However, we must interpret this result cautiously. o1 surpassing human experts does not mean it is stronger than PhD-holding experts in all respects. Rather, it indicates that o1 has demonstrated extraordinary proficiency and efficiency in solving certain specific types of problems — namely those typically requiring doctoral-level expertise.
Beyond GPQA diamond, o1 has also achieved breakthrough progress on multiple other machine learning benchmarks, pushing the industry's technical frontier:
-
With vision capabilities enabled, o1 scored 78.2% on MMMU (multimodal understanding). This makes o1 the first AI model capable of competing with human experts in this domain, demonstrating its exceptional performance in multimodal tasks.
-
On MMLU (Massive Multitask Language Understanding), o1's performance is even more striking. Across 57 subcategories in total, o1 surpassed GPT-4o on 54. This fully validates o1's comprehensive advantage across broad knowledge domains and task types.
These test results together paint a comprehensive capability map of the o1 model: it not only matches human experts in depth of specialized domain knowledge, but also demonstrates outstanding performance across broad knowledge domains and multimodal tasks. These achievements mark major breakthroughs in AI technology for both general intelligence and specialized domain applications, opening new possibilities for future AI deployment in more complex tasks.
04 Programming: Competitive Programming
Better Than 93% of Competitors
Based on deep optimization and specialized training of the o1 model, we successfully developed an AI model with exceptional performance in programming. This model demonstrated remarkable capability at the 2024 International Olympiad in Informatics (IOI), scoring 213 points and ranking in the top 50% of competitors — fully proving AI's potential in high-difficulty programming tasks.
Competition Setup and Challenges:
-
Competition environment: The AI model competed under exactly the same conditions as human participants.
-
Task difficulty: Required solving 6 high-difficulty algorithm problems within 10 hours.
-
Submission limits: 50 submission attempts allowed per problem.
We developed a unique test-time selection strategy that significantly enhanced the model's competitiveness:
-
Diverse sampling: The system generated numerous candidate solutions for each problem.
-
Intelligent filtering: Selected the best 50 solutions for submission based on IOI public test cases, model-generated test cases, and a specially designed scoring function.
-
Strategy effectiveness: Compared to random submission, this strategy improved scores by nearly 60 points on average, fully proving its value in strict competition environments.
Breakthrough Performance:
-
Astonishing results with relaxed limits: When 10,000 submissions per problem were allowed, even without any test-time selection strategy, the model achieved 362.14 points — exceeding the gold medal threshold. This demonstrates the model's potential under more relaxed conditions.
-
Exceptional performance on the Codeforces platform: a. Simulated environment: We simulated real competitive programming contests on the Codeforces platform, strictly following competition rules with 10 submissions per problem. b. Remarkable breakthrough: Our new model achieved an Elo rating of 1807, surpassing 93% of human competitors. c. Significant improvement: By comparison, GPT-4o had an Elo rating of 808, surpassing only 11% of human competitors. The new model not only far exceeded GPT-4o, but also substantially outperformed o1.
These results clearly demonstrate the major breakthrough our AI model has achieved in programming. It can not only compete alongside human experts in world-class programming competitions, but in certain aspects shows potential to surpass human capability.
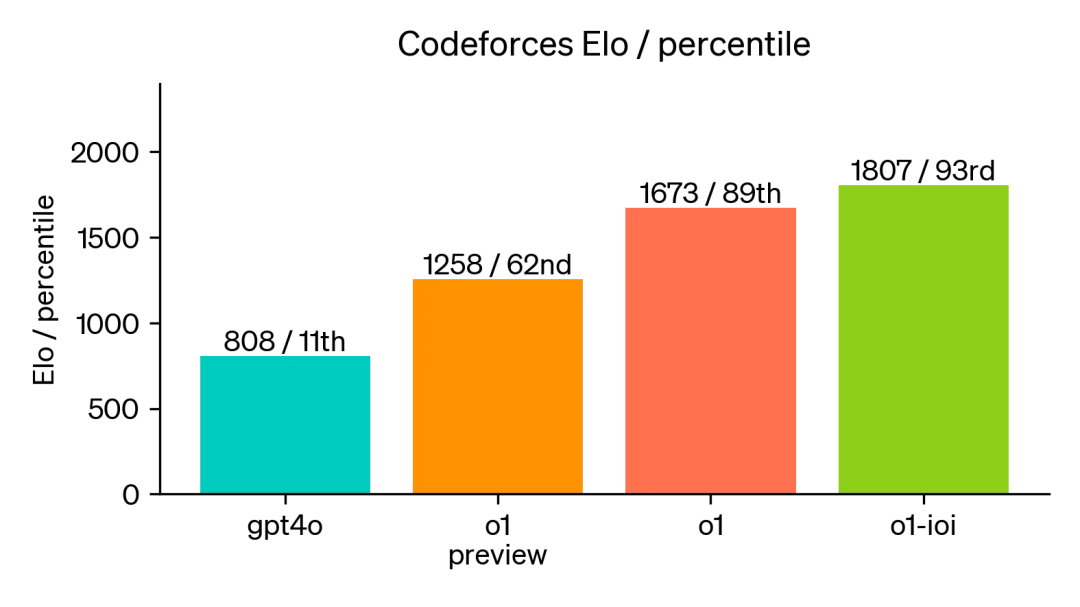
Further fine-tuning o1 on competitive programming improved performance. Under competition rules, the improved model ranked at the 49th percentile at the 2024 International Olympiad in Informatics.
05 Human Preference Evaluation:
GPT-4o Still Holds Advantage in Text Generation
To comprehensively evaluate AI models' real-world application effectiveness, we conducted an innovative human preference evaluation in addition to traditional exam scores and academic benchmarks. This evaluation compared o1-preview and GPT-4o's performance on complex, open-ended problems across various domains.
Evaluation Method:
-
Broad scope: Covered challenging problems across multiple different domains.
-
Open-ended prompts: Used open questions to test model flexibility and creativity.
-
Anonymous comparison: Showed human evaluators anonymous responses from both models.
-
Human judgment: Trained human experts voted on which response they considered superior.
Key Findings:
-
o1-preview's advantage domains: a. In domains requiring deep reasoning capability, o1-preview performed outstandingly, significantly leading GPT-4o. b. These domains mainly include: data analysis, programming, and mathematics. c. The advantage is pronounced, showing o1-preview's exceptional capability in handling complex logic and abstract thinking.
-
GPT-4o's advantage domains: a. In certain natural language processing tasks, GPT-4o still maintains advantage. b. This suggests language models may be more advantageous in handling everyday communication and text generation tasks.
-
Differences in model applicability: o1-preview, despite excelling in certain domains, is not all-purpose. This finding emphasizes that different AI models have different strengths in different tasks, suggesting that future AI applications may require task-specific model selection.
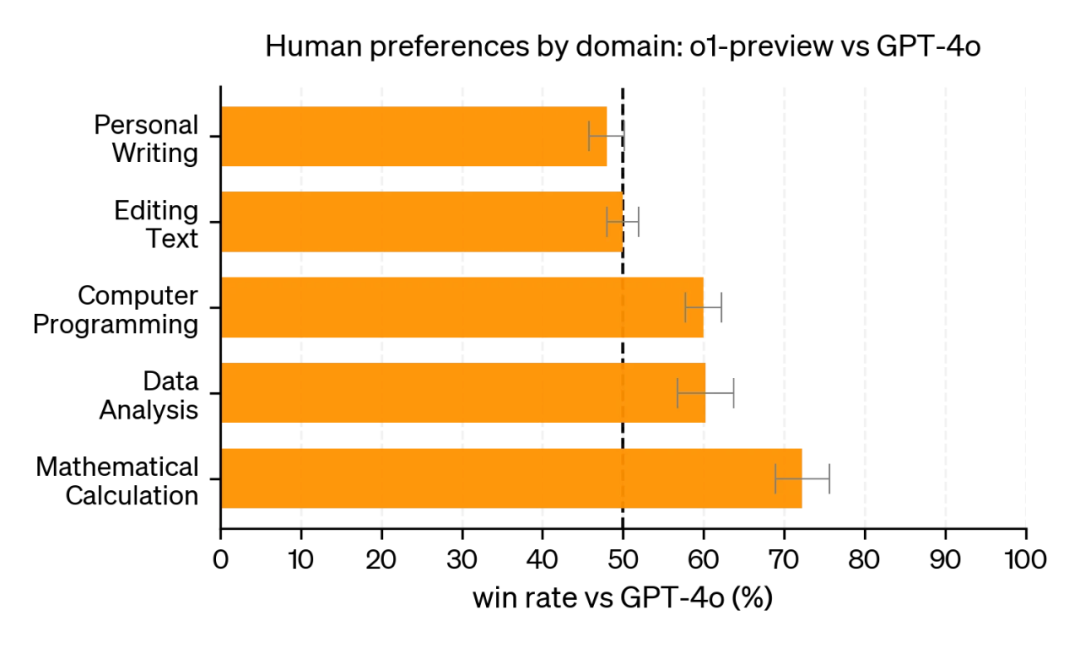
Conclusion: This evaluation not only demonstrates o1-preview's superiority in handling complex reasoning tasks, but also reveals the diversity of AI model capabilities. It reminds us that when selecting and applying AI models, we need to choose the most appropriate tool based on specific tasks and scenarios. At the same time, this also provides direction for future AI model development — namely, how to maintain strong reasoning capability while improving performance in domains like natural language processing.
06 Hallucinations Not Solved,
But Chain of Thought Is Powerful
In AI, "chain of thought" is an important concept representing the internal reasoning process an AI model uses when generating answers. This process, like human thinking, contains a series of logical steps from problem to solution. o1 employs the "chain of thought" method to process complex tasks. This approach not only mimics human thinking patterns, but is continuously optimized and improved through advanced reinforcement learning techniques.
o1's learning process embodies several key characteristics:
-
Chain of thought optimization: Through reinforcement learning, o1 continuously refines its chain of thought, improving problem-solving strategies.
-
Error recognition and correction: o1 has self-checking capability, able to identify and correct errors that arise during reasoning.
Problem decomposition capability: Facing complex problems, o1 has learned to break them down into simpler, more manageable sub-problems.
- Flexible method switching: When finding current methods ineffective, o1 can flexibly shift approach and try new solutions.
This multi-layered, adaptive learning process greatly enhances o1's reasoning capability, allowing it to demonstrate near-human flexibility and creativity when processing complex problems.
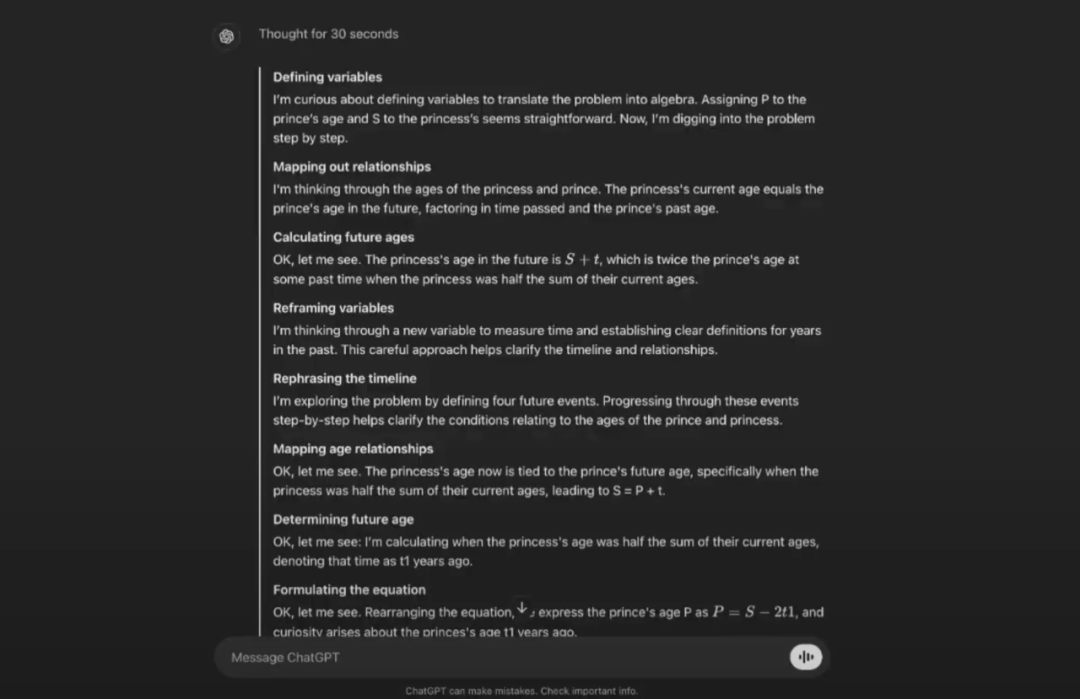
Phrases like "I'm curious about...", "I'm thinking", and "Okay, let me see" create a sense of deliberation.
Potential value of chain of thought:
-
Model monitoring: By analyzing chain of thought, we can deeply understand AI's "way of thinking."
-
Safety assurance: Future potential to use chain of thought to detect whether AI is attempting to manipulate users.
-
Transparency: Provides explainability for AI decisions, increasing trustworthiness.
Despite chain of thought's potential value, we have decided not to directly show users the raw chain of thought. This decision is based on the following considerations:
-
User experience: Raw chain of thought may be complex and difficult to understand, affecting user experience.
-
Competitive advantage: Protecting core technical details.
-
Monitoring flexibility: Preserving options for future chain of thought monitoring.
-
Safety considerations: Preventing unfiltered, potentially problematic thought processes from being directly exposed to users.
To balance hiding chain of thought with providing valuable information, we have taken the following measures:
-
Intelligent extraction: Training the model to extract useful information from chain of thought and incorporate it into final responses.
-
Summary generation: For the o1 model family, we provide model-generated chain of thought summaries, preserving key information while avoiding direct exposure of raw data.
07 Which Domains Suit o1 Best
With its exceptional reasoning capabilities, this generation of models will bring significant benefits to professionals in multiple domains, especially those facing complex challenges in scientific research, software development, mathematical computation, and related fields. Let's look at a few specific application scenarios:
-
Medical research: Bioinformaticians can use o1 to assist with cell sequencing data annotation, greatly improving genomics research efficiency.
-
Physics research: In cutting-edge fields like quantum optics, physicists can leverage o1 to generate complex mathematical formulas, accelerating theoretical research and experimental design.
-
Software development: Developers across industries can use o1 to build and execute multi-step workflows, simplifying complex programming tasks.
In summary, the o1 model provides a powerful intelligent assistance tool for professionals who need to handle highly complex problems, conduct deep analysis, or pursue innovative research.





