Wang Qian, Invariant Robot: How Far Is Embodied Intelligence's Scaling Law? | Yunqi Capital Doers Series

Embodied Intelligence ≠ Stuffing DeepSeek into a Unitree Robot

Amid the embodied intelligence boom, "stuffing a large model into a robot" has become the default technical path for some. But at the recently concluded IROS — a top global academic conference in robotics — Wang Qian, founder of X-Variable Robotics, a Yunqi Capital portfolio company, offered a different perspective: "General-purpose robots are not an extension of language models," and foundation models for the physical world are entirely independent of language and multimodal models in the virtual world.
In this episode of "Yunqi Tech π," we explore the fresh thinking of this founder on the front lines of embodied intelligence.
Author / Robo Xiao Cao
Reprinted from the WeChat account "RoboX"
Presentation: October 20, 2025 — IROS Meituan Robotics Research Institute Academic Annual Meeting
Many people view embodied intelligence as an AI application — essentially "putting DeepSeek into a Unitree robot." But Wang Qian and X-Variable firmly reject this view.
When he first entered the machine learning field, he already believed the overarching direction was flawed: neural networks needed to see ten thousand static images of dogs before they could recognize one. But a human might only need to see a dog once to recognize it forever.
Especially after working on robotics, he concluded that methods must completely break away from static data, because the physical world has one very "bad" characteristic: its enormous randomness, which simply doesn't exist in the virtual world.

For example, on certain special tablecloths, pushing a cup ten times with the same angle and force might land it in ten different places each time.
What X-Variable is building is a foundation model for the physical world — one that is entirely independent of language models and multimodal models in the virtual world.
"To do robotics in the physical world, certain parts of CV need to truly break away from static-data methods."

Why Must We Break Away from Static Data?
Today, robot locomotion is already quite good, and navigation has entered a convergent phase. But manipulation is just getting started.
"Because manipulation involves the most interaction with the physical world. When we do locomotion, we don't worry about being two centimeters off course, and the gravity environment is constant."
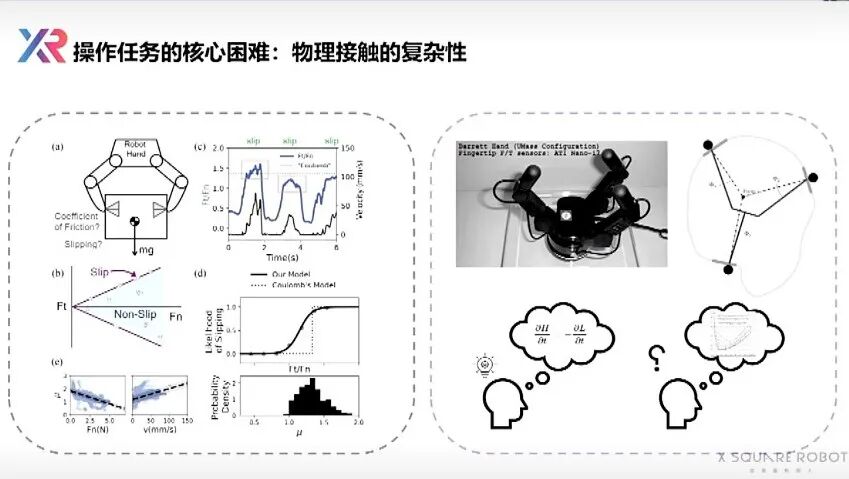
Wang Qian explained that in physical-world manipulation, robots encounter massive amounts of random friction and deformable objects. Even a water bottle with a loose cap could leak due to such tiny details, causing failure.
"Many people think we can just take existing language models and multimodal models as the backbone and keep building from there. But in reality, this path may actually be more difficult. Even the best language and multimodal models today perform very poorly on physical-world tasks."

He pointed out that using other modalities to describe motion is fundamentally impossible. Take stir-frying: what force to use, which direction to flip the wok, how to move the spatula — trying to describe this with precision is clearly unrealistic.
"Later, people came up with many approaches, including quite a few papers at IROS in recent years, such as using images to describe motion. But that runs into massive occlusion problems."
Embodied Intelligence Is Naturally Suited to End-to-End
Methodologically, the first approach to emerge was end-to-end.
Wang Qian said that people initially thought this approach seemed simple, but later realized it wasn't. A core reason is that the complexity of physical contact rules out the possibility of layered models.
"If reconstruction is slightly imperfect, with a 1% error, it might have zero impact in autonomous driving and very little impact on locomotion. But in manipulation, it compounds and amplifies rapidly."

He stated that while some propose making the most of existing VLM and language model capabilities, from an AI perspective, the right approach is to create a system that learns through bodily experience, collecting data and growing intelligence. And this new data can also deepen understanding of language and vision.
"From this perspective, we shouldn't be building layered models at all, because embodied intelligence is a domain naturally suited to end-to-end methods."
Generalist Models
Two years ago, people still thought specialized models were better. They reasoned that with the same budget, focusing on just one thing would naturally yield the best results.
But with the explosion of language models, people discovered the advantages of generalist models: doing multiple tasks usually works better than doing just one. The reason is that generalist models truly learn the common structure across different tasks.
"If you have it learn language, it grasps logic and common sense; if you build an embodied model in the physical world, it learns the laws of physics. Once the model masters these things, we can see the developmental trajectory that large models have gone through today — from full-scale learning to the emergence of 'in-context learning,' the most obvious manifestation of what we call 'emergence.'"
Wang Qian said that once a model learns these fundamentals, the amount of data needed to learn new things drops dramatically. At the same time, it can break through previously most difficult tasks. Only then can it be called artificial general intelligence, and only through it can general-purpose robots be achieved.
A General-Purpose Robot Model Must Be VLA
With generalist models and end-to-end approaches comes the concept of "foundation models." Foundation models are needed because the complexity of the physical world is largely hidden beneath multiple modalities.
Machine learning, deep learning, and large models work because they can extract the structure and core laws of the world through compression. But the timescale of language processes and the timescale of physical processes are different.
So Wang Qian reiterated that we must completely leave behind the familiar methods from the virtual world and truly enter the physical world.
"Why is VLA so hot? Because a truly general-purpose robot model must be a VLA model, and it should also be a true generalist model and a true end-to-end model."
Wang Qian said he hopes the foundation model can do more than just control robots.
"We want its outputs to include language as well — a VLM that can converse with people. We also want it to have specialized intelligence: give it an image or a video, and it can reconstruct a 3D environment or object. It could also be a video generation model, a world model, and so on. All these capabilities should be concentrated in a single system."
He believes that despite all the arguments over technical approaches today, everyone is actually converging toward unification, toward generality, toward foundation models. On the path to unification, people are trying different things, but the ultimate methodology is a foundation model for the physical world.

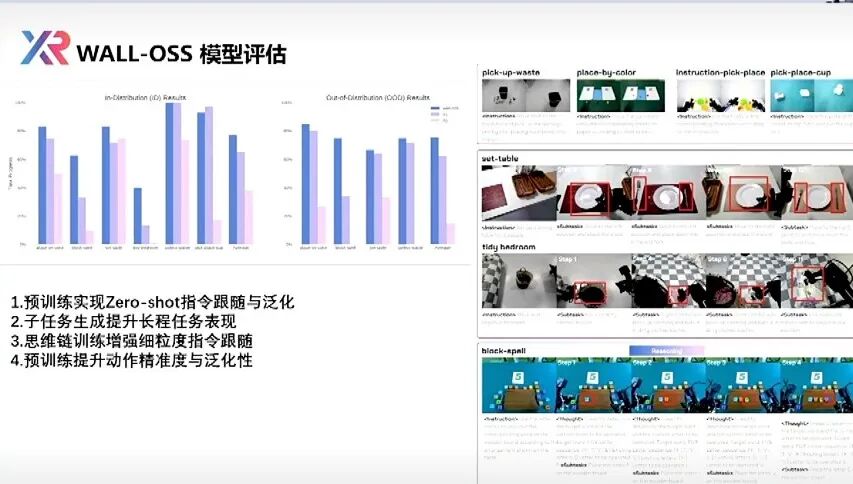
In X-Variable's open-source model WALL-OSS, beyond conventional robot control, it also includes long-sequence chain-of-thought, simultaneous use of language and sub-tasks, and will eventually open-source other specialized intelligence capabilities on world models.
"At least in terms of zero-shot CoT capability, we can achieve a leading level. In pure controlling, our results are not behind current PI."
Virtual World Data Is Nearing Exhaustion
When it comes to Scaling Law, many believe that brute force leads to miracles. But in Wang Qian's view, not necessarily.
Many think we're undergoing a paradigm shift — from algorithm-centric to data-centric. But "data-centric" doesn't just mean "more data"; it means shifting most of the know-how, techniques, and work content from models and algorithms to data.
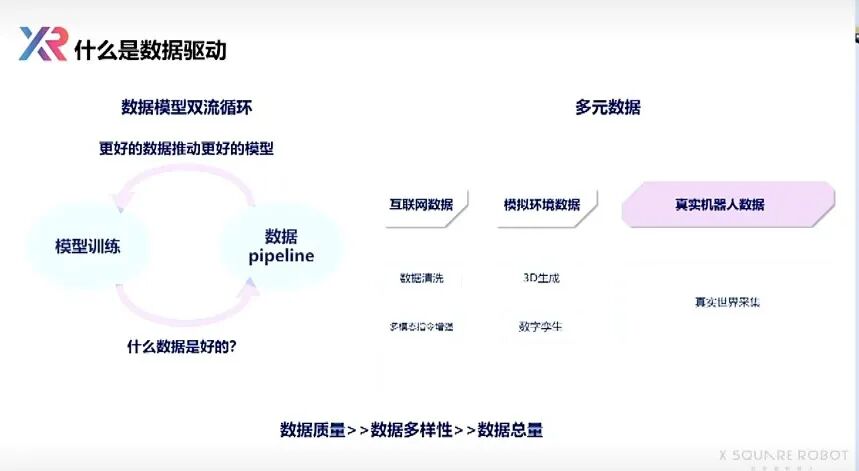
Wang Qian said that far more can be done with data than with models. Especially now, as people move toward increasingly unified models with less and less human intervention, most attention has shifted from models to data.
People often say that they don't seem to see Scaling Law in robotics — that's usually because the data work is too poor. If data efficiency is a thousand times worse than normal, Scaling Law gets completely drowned out by noise.
"Simply increasing data volume, building data factories, purely scaling up — I don't think that has much meaning."
He explained that the reason simulation and Sim2Real haven't achieved great success in manipulation is that their data quality is orders of magnitude worse than data collected in the real world.

"So in this situation, real-world data actually becomes a cheaper, more efficient approach — for the same training outcomes, we find that data produced through simulation is actually more expensive and slower. This is something we should pay very close attention to when shifting from traditional robotics methodology to foundation model methodology."
According to Wang Qian, X-Variable's model also follows this methodology, training primarily on self-collected data, with good results.
"The two-stage methodology of pre-training and post-training can achieve very good results. Compared to the data collection phase, X-Variable's robot demonstration speed is now 2-3x faster, and we've significantly improved success rates through reinforcement learning."
Beyond pre-training and post-training, X-Variable also wants the model to achieve inference-time learning, which inherently matches the natural properties of robots.
Previously, the industry was doing unified centralized training and centralized inference, so robots couldn't learn experientially like a human child.
Now, he believes virtual world data is nearly exhausted — if not this year, then next year or the first half of the year after.
Though some have proposed synthetic data, Wang Qian believes that the essence of human intelligence is rooted in the physical world, so physical-world data will definitely be the core element of AGI.
Embodied Intelligence Will Far Exceed Imagination
Many people think robots are just about replacing factory workers or household help. But Wang Qian believes embodied intelligence goes far beyond that — it may be the biggest revolution in human history.
Wang Qian noted that through four industrial revolutions, human productivity and energy acquisition have grown exponentially. But to this day, there is no product that can be made without human manual labor.
"If we can truly achieve a general-purpose robot that can completely replace human manual labor, I believe everything will advance at exponential speed. The state we can reach with embodied intelligence should far exceed what people generally imagine."
He believes that very smart AI can invent even smarter AI, which in turn invents yet another level of AI... So someday, humans will be completely left behind. Before this singularity arrives, people will still need to rely on more compute, more data, and more energy — using these physical-world resources to push AI forward.
"The exponential explosion of productivity growth that we create in the physical world is the main driving force that can propel humanity toward AGI, toward superintelligence, and into the next era."


