"Self-Variable Robotics" Explores a New Paradigm for Embodied Intelligence: From "Building Blocks" to "Native Integration" | Yunqi Capital

Getting AI to Put Down Heidegger's Hammer

True intelligence is not stronger recognition, but more natural action.
Current mainstream embodied intelligence remains stuck at the stage of tool cognition, yet to reach the level of intuition. Yunqi Capital portfolio company and embodied intelligence startup X Variable Robotics has chosen a different path: instead of bridging visual, language, and action modalities, they are breaking down boundaries to build a unified embodied intelligence architecture, achieving true perception-reasoning-action coupling within a unified representational space. This represents not only a fundamental paradigm leap for embodied intelligence, but also a new exploration of the future capability boundaries of robotics.
This edition of Yunqi Capital takes you inside X Variable Robotics' exploration.
The following is republished from "X Variable Robotics"
When a skilled carpenter picks up a hammer, the hammer disappears — not physically, but as something that can be used effortlessly without conscious thought. Yet today's most advanced robots still cannot "put down" this "hammer." They remain trapped in loops — recognizing the hammer, planning how to use it — every interaction requiring them to "pick up" the tool anew as a cognitive object. This fragmented approach ensures AI will never achieve the intuitive tool use that comes naturally to humans.
The breakthrough in embodied intelligence will not come from patching existing vision-language foundation models, but from an architectural revolution.
We argue that the patchwork paradigm centered on "multimodal module fusion" must be abandoned in favor of an end-to-end unified architecture. This architecture aims to completely dissolve the artificial boundaries between vision, language, and action, reducing them to a single information stream for processing.
The Fundamental Limitations of the Current Paradigm
Existing mainstream approaches treat different modalities as independent modules — pretrained ViTs for visual information, LLMs for language understanding — connected through fusion layers. This "committee"-style design has inherent flaws.
First is the representation bottleneck problem. As information passes between modality-specific encoders, inevitable compression losses occur. It's like describing an oil painting to a blind person, who then conveys the scene to a deaf person — each conversion loses critical details and relationships. These losses prevent the model from achieving deep cross-modal understanding of the physical world.
Most critically is the failure to emergent capabilities. Structural fragmentation makes it difficult for models to learn the intuitive, cross-modal causal laws that span modalities in the physical world. Just as one cannot learn to ride a bicycle from textbooks alone, true physical intelligence requires holistic, embodied understanding, not modular knowledge stitching.
Unified Architecture: From Divide-and-Conquer to Integration
Our proposed unified modality architecture stems from a core insight: true embodied intelligence should not be the collaboration of multiple specialized modules, but should, like human cognition, simultaneously process perception, reasoning, and action within a unified computational framework.
The core of the architecture is unified representation learning. We convert all modality signals — vision, language, touch, action — into a shared high-dimensional token sequence, eliminating artificial boundaries between modalities.
The key breakthrough lies in using multitask multimodal generation as the supervision mechanism: the system must learn to generate content in any modality from any other modality, forcing the model to establish deep cross-modal correspondences.
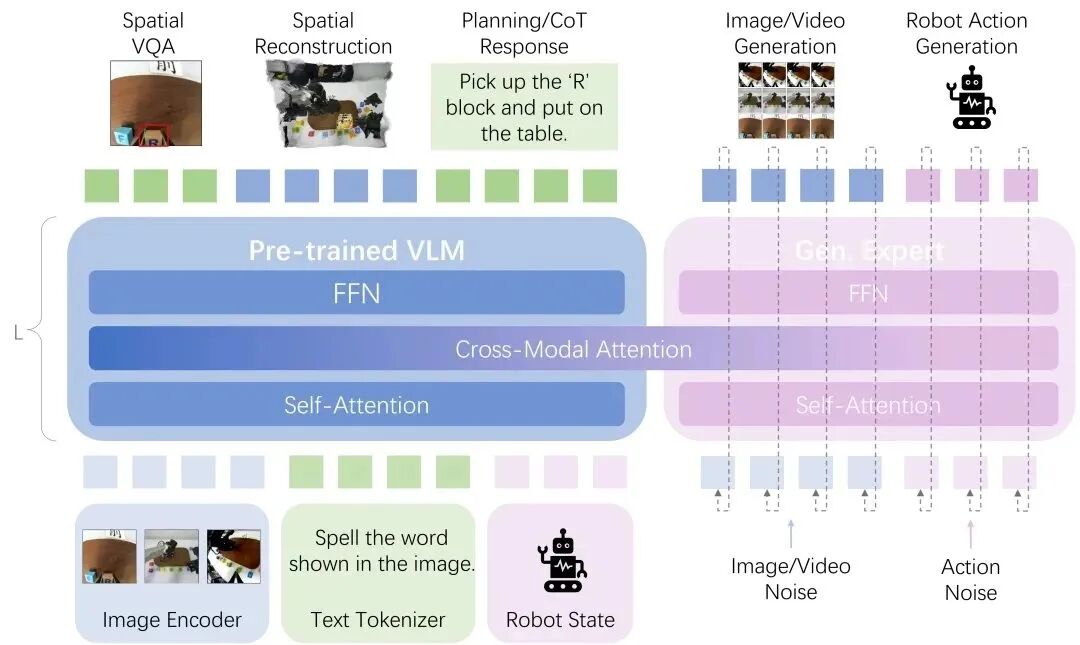
Specifically, we transform all input modalities — including multi-view images, text instructions, and real-time robot states — into unified token sequences through their respective encoders. These sequences are fed into a Transformer core. A pretrained multimodal understanding model integrates information to complete spatial perception understanding and task reasoning planning, while a Generative Expert (Gen. Expert) predicts future images and videos, and directly generates executable robot actions. The two are deeply coupled through a Cross-Modal Attention layer, enabling perception, reasoning, and action information flows to interact bidirectionally and co-evolve losslessly at every computational layer, thereby achieving end-to-end unified learning.
This architecture enables emergent embodied multimodal reasoning. When facing new tasks, the system can process holistically like humans — visual understanding, semantic reasoning, physical prediction, and action planning occur in parallel and influence each other within unified space, rather than being processed serially.
Through this end-to-end unified learning, the system can ultimately think and work like humans: no longer relying on modular information transfer, but conducting cross-modal causal reasoning and action decision-making directly in deep representational space.
Emergent Capabilities: Embodied Multimodal Reasoning
This unified architecture aims to unlock comprehensive embodied multimodal reasoning capabilities that current modular systems cannot achieve.
The first is symbolic-spatial reasoning capability.
When a human casually draws geometric shapes, the robot first understands the complex geometric patterns, then performs multi-level reasoning in the unified representational space: deconstructing abstract two-dimensional graphics into specific letter combinations, understanding the spatial arrangement logic of these letters, and inferring the complete words they form. Simultaneously, the robot can directly translate this abstract symbolic understanding into physical operations in three-dimensional space, precisely reproducing the spatial arrangement of letters with building blocks.
The entire process demonstrates the deep integration of visual perception, causal reasoning, and spatial manipulation.
[Video Demo 1: Robot spells corresponding words based on hand-drawn graphics]
The second is physical spatial reasoning capability.
When we show the robot building block operation steps, the robot can directly perform visual spatial logic reasoning and causal relationship deduction within its unified latent space. In this process, the robot understands how each block placement affects overall structural stability, infers the engineering logic behind the operation sequence, and predicts the consequences of different operation paths. Simultaneously, the robot can externalize this physical reasoning process as a chain of language thought, clearly expressing its understanding of spatial relationships, gravity constraints, and construction strategies.
Ultimately, based on this deep physical understanding, the robot can independently complete complex three-dimensional structure construction, demonstrating the organic combination of physical intuition and reasoning capability.
[Video Demo 2: Observing building block operation steps and constructing corresponding spatial shapes]
The third breakthrough is autonomous exploration capability with reasoning chains.
Facing complex environments, the system can integrate visual observations, spatial memory, and commonsense knowledge to construct coherent reasoning chains. The entire process demonstrates seamless integration of perception, memory, reasoning, and action, as well as flexible decision-making based on commonsense knowledge.
This reasoning process is a natural emergence of end-to-end learning.
[Video Demo 3: Object search with reasoning process]
The final demonstration showcases robot learning from video and collaborative reasoning capabilities.
When observing human operation videos, the robot infers the deep intentions and goal states behind the actions. This capability transcends simple action imitation, demonstrating video learning, understanding of human intentions, inference of collaborative goals, and autonomous collaborative decision-making — showcasing true autonomous learning and human-robot collaboration capabilities.
[Video Demo 4: Inferring action intentions from video and autonomous execution]
What these demonstrations reflect is a fundamental paradigm shift.
Traditional multimodal systems decompose the world into independent representational modules, but physical world interaction is continuous, real-time, and multimodally coupled — when a robot grasps a fragile object, visual judgment, force control, and safety prediction must occur simultaneously; any delay or information loss between modules could lead to failure. Our unified architecture was born precisely to meet the demands of this kind of embodied interaction.
The significance of this shift lies in enabling robots to seamlessly integrate perception, understanding, and action like the skilled craftsman Heidegger described.
Robots no longer need to endure the lengthy serial processing of "visual recognition → language planning → action execution," but are directly understood in unified representational space as the medium for achieving specific intentions — the robot can simultaneously "see" physical properties, "understand" their role in the task, "perceive" operational spatial constraints, and "plan" corresponding action sequences.
It is precisely this parallel fusion processing of multimodal information that enables embodied multimodal reasoning capabilities to emerge naturally, allowing robots to ultimately interact with the physical world as fluently as humans.
We argue that the future path of embodied intelligence is to shift from designing systems with "fragmented representations" to building unified systems capable of true embodied multimodal reasoning. This is not an incremental improvement, but the architectural evolution necessary for AI to possess cross-modal causal reasoning, spatial logic deduction, and general-purpose embodied intelligence.





