This Generation of Robots Is Finally Done Being "Parrots" | Yunqi Capital π

Astribot Lumo-1 and the Robot Version of "Master of Reasoning"

When you first started cooking, you might have run into something like this —
You're standing at the stove, carefully stirring, and the recipe says "turn to low heat." You do exactly that, only to watch the oil lose its temperature and the vegetables refuse to cook through.
Turns out, "low heat" in a recipe conceals a chain of information you can only grasp through experience: Is the pan hot enough yet? Is the oil barely rippling? Will this batch of vegetables overcook? The real challenge for beginners was never the physical action itself, but reasoning through why you're doing it.
Embodied robots now struggling to find their place in the world are hitting the same wall.
They can mimic the motion of "turning down the flame" without grasping the intent behind it. They can follow a demonstrated trajectory to "put something inside" without understanding why the door needs to open first. They can perform actions, but they can't infer implicit conditions from context the way humans do.
Astribot, an embodied intelligence startup and Yunqi Capital angel portfolio company, is proposing a solution with its newly released full-body VLA model Lumo-1.
Through an efficient training architecture, structured reasoning mechanisms, and a SAT action dictionary that breaks human motion trajectories into "action words," Lumo-1 is teaching robots to let reasoning drive action — using why to power how.
Crossing this threshold is also a critical step toward improving the generalizability of embodied intelligence. In this issue of Yunqi Tech π, we'll unpack Lumo-1's training logic and real-world performance.
Teaching a Robot to Heat Bread

Despite never having seen this particular loaf, the robot reasons out what it is, infers that heating means using a microwave, and executes the full sequence — open door, pick up, place inside, close door, turn knob, wait, remove — all through reasoning, with zero programming required for this long-horizon task.
"Organize the Stationery"

Quickly locating stationery scattered across a cluttered desk
Handling items of varying shapes, materials, and sizes with precision ⚡️
"Put the Coke in the Blue Plate"

Even reasoning to use the left arm first, then switching to the right when obstructed for faster completion
From walking and dancing to backflips, motion imitation has taught robots how to move. But when it comes to complex operations like carrying plates, sorting fruit, or heating food, robots can't simply imitate — they must recognize complex environments, understand the task intent behind why something is done, and translate that into coherent physical execution.
Human action is generally grounded in context and intent, with reasoning at its core. For robots, while large-scale internet data has given models like GPT and DeepSeek decent reasoning capabilities, getting AI to "move accurately" through reasoning in the real physical world — especially when handling multi-step long-horizon tasks, ambiguous instructions, and unseen scenarios — remains deeply challenging.
Mainstream vision-language-action (VLA) models rely on "trajectory memory," learning mappings of "see A + hear B → do C" from massive datasets. This approach works adequately in standard scenarios, but exposes three major flaws in open environments: abstract concept failure (understanding "Coke" but not "energy-boosting drink"), poor environment generalization (trained on white tables, failing on wooden ones), and long-horizon task collapse (microwave heating requires coherent multi-step operation — one error and the whole sequence falls apart).
AI robotics company Astribot proposes an end-to-end full-body VLA model — Lumo-1, designed to let robots unify mind and hand, think clearly then get to work. Through embodied VLM, cross-embodiment joint training, reasoning-action real-robot training, and reinforcement learning calibration and alignment — combined with high-quality real-robot training on its cable-driven S1 robot — it translates large model "cognition" into smooth full-body-to-fingertip operation.
Project page: $2*$2**$2*
Technical report: $2
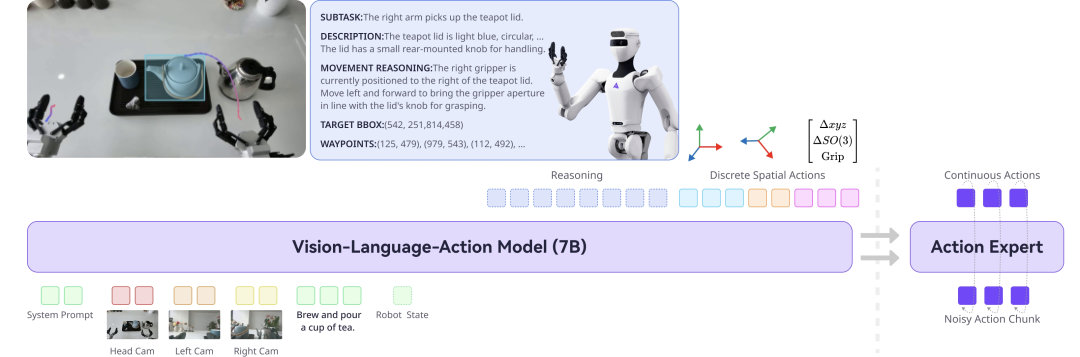
Lumo-1 demonstrates strong operational intelligence and generalization capabilities, surpassing advanced models including π0 and π0.5 across all three core robot manipulation task categories: multi-step long-horizon tasks, fine dexterous manipulation, and generalizable pick-and-place. Its advantages are particularly pronounced in out-of-distribution (OOD) scenarios involving unseen objects, environments, and instructions, as well as abstract, ambiguous commands requiring extended reasoning.
01
From "Memorizing Recipes" to "Understanding Cooking"
When humans execute complex tasks, they don't simply call up an "action library" — they perform real-time multi-level reasoning: interpreting abstract semantics, decomposing subtasks, perceiving spatial relationships, planning motion paths. The more robots can reason like humans, the more they can act like them.
Teaching robots to think and reason is just as important as feeding them data. Lumo-1's three-stage training architecture moves from embodied VLM, to cross-embodiment joint training, to reasoning-action real-robot training, and finally reinforcement learning for calibration and alignment between reasoning and action.
Like moving from "reciting recipes" to "understanding cooking principles," robots begin to acquire the capacity to "make decisions."
Lumo-1 demonstrates strong operational intelligence and generalization capabilities, surpassing advanced models including π0 and π0.5 across all three core robot manipulation task categories, with particularly pronounced advantages in out-of-distribution (OOD) scenarios involving unseen objects, environments, and instructions, as well as abstract, ambiguous commands requiring extended reasoning.
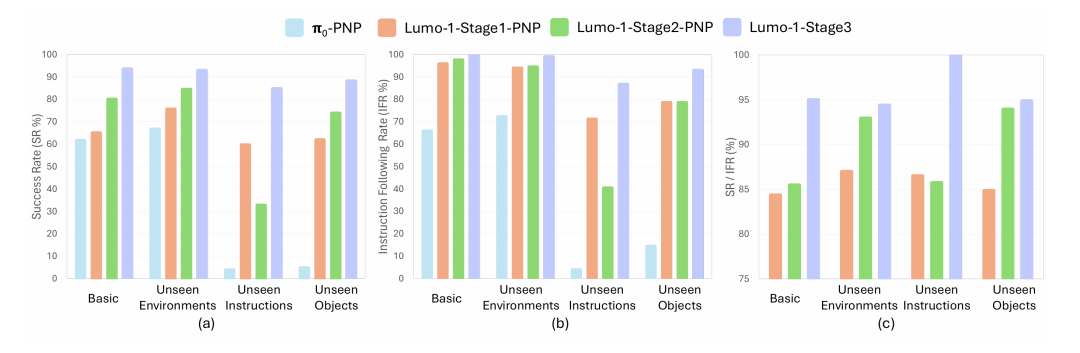
General pick-and-place test results
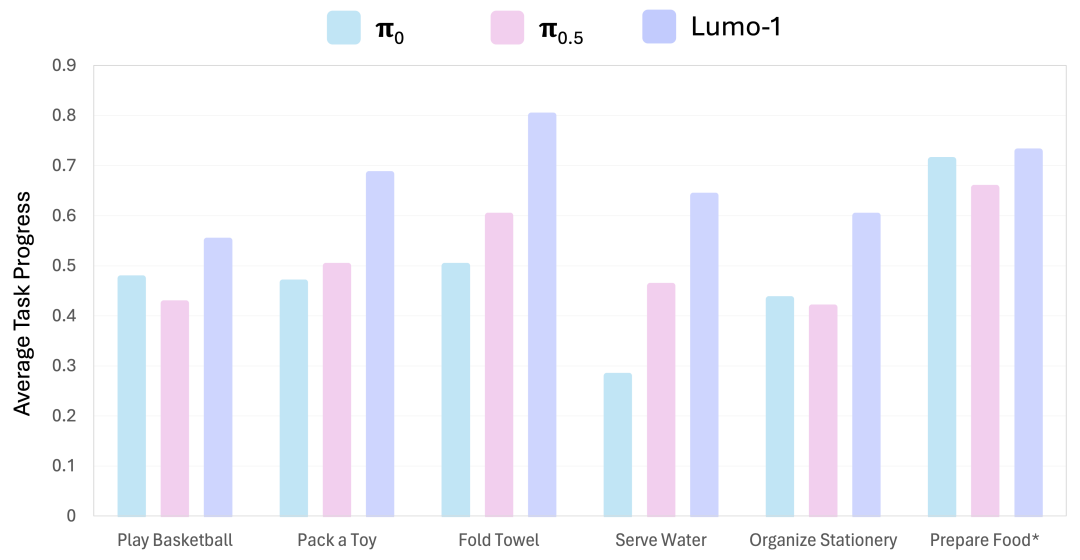
Long-horizon and dexterous manipulation task comparison results
02
Three-Stage Training: Converting VLM Cognition into VLA Intelligence
Lumo-1's training isn't about scaling for scale's sake — it's a carefully designed "intelligence transfer" process.
Stage 1: Embodied VLM. Continued pre-training on curated vision-language data gives the model spatial understanding, planning, trajectory inference, and other "embodied semantics." It outperforms specialized models like RoboBrain-7B and Robix-7B on most of 7 classic embodied reasoning benchmarks.
The curated dataset is designed to strengthen core embodied reasoning capabilities without damaging the general multimodal understanding and reasoning abilities of the pre-trained VLM.
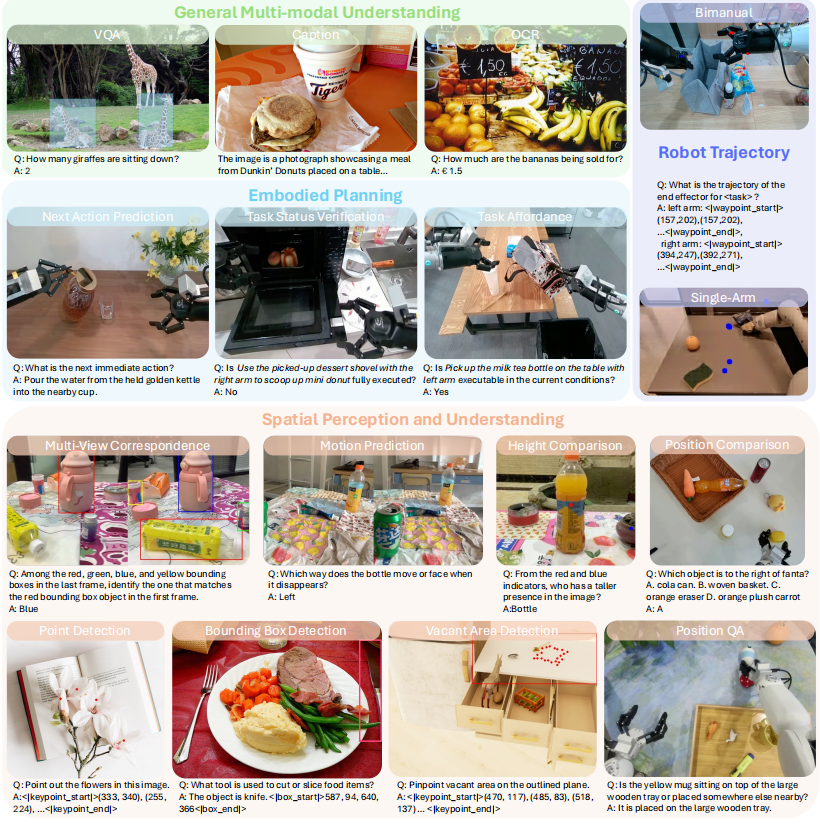
The curated dataset is designed to strengthen core embodied reasoning capabilities without damaging the general multimodal understanding and reasoning abilities of the pre-trained VLM.
Stage 2: Cross-Embodiment Joint Training. Joint training across diverse robots, multi-view trajectories, and VLM data strengthens instruction following, object localization, and spatial reasoning — the model begins understanding what actions are and how they relate to instructions and observations.
Stage 3: Real-Robot Reasoning-Action Training (S1 Trajectories). Using highly human-like demonstration trajectories from the cable-driven Astribot S1 robot, the model undergoes action training with reasoning processes, learning executable action patterns in the real world: how to handle objects with bimanual coordination, how to execute long-horizon sequences, how to translate reasoning step-by-step into trajectories.
Sample tasks collected on the Astribot S1 robot. These tasks cover a wide range of daily activities, captured with diverse objects, lighting conditions, and environmental settings. Each task involves complex, long-horizon behaviors that naturally decompose into multiple subtasks, containing diverse primitive action units such as sweeping, peeling, pouring, scrubbing, folding, pressing, and rotating.

Sample tasks collected on the Astribot S1 robot. These tasks cover a wide range of daily activities, captured with diverse objects, lighting conditions, and environmental settings. Each task involves complex, long-horizon behaviors that naturally decompose into multiple subtasks, containing diverse primitive action units such as sweeping, peeling, pouring, scrubbing, folding, pressing, and rotating.
Finally, Reinforcement Learning Reasoning-Action Alignment (RL Alignment) is introduced to calibrate and align high-level reasoning with low-level action, designing multi-dimensional reward signals for visual, action, and reasoning consistency, action execution, and reasoning format. Through a GRPO-based learning scheme, the model is encouraged to select more accurate, coherent, physically plausible actions. Experiments show this approach significantly surpasses raw imitation of expert demonstrations in task success rate, action plausibility, and generalization.
03
Three Technical Deep Dives
Layer-by-Layer "Reasoning-Action" Engine
Action Space Modeling: From "High-Frequency Noise" to "Key Path"
In Lumo-1, through Spatial Action Tokenizer (SAT), the robot converts action trajectories into a reusable, composable "action word library" — capable of combining actions like writing sentences, or reusing, interpreting, and predicting actions. Technically, SAT compresses continuous action trajectories into shortest-path waypoints, and clusters rotational/translational incremental actions into compact tokens, reducing irrelevant noise introduced during data collection while preserving action space meaning — more compact and stable than FAST and bucketing methods.
Structured Reasoning: Giving Robots Common Sense and Thinking Ability
Lumo-1 decomposes reasoning into two dimensions: textual reasoning and visual reasoning.
The model performs multiple forms of embodied textual reasoning:
(1) Abstract concept reasoning integrates visual observations and instructions to infer implicit semantics ("low calorie" → exclude Coke);
(2) Subtask reasoning aims to infer optimal intermediate steps toward the final goal (microwave heating → open door → retrieve item → place inside → close door → turn knob → remove);
(3) Visual observation description emphasizes accurate identification and analysis of salient scene features and actionable objects;
(4) Motion reasoning includes textual inference of gripper spatial relationships and articulation of movement directions.
It then proceeds to visual reasoning for perception-based inference and motion estimation.
Through Structured Reasoning, the robot brain no longer memorizes trajectories by rote, but forms structured reasoning chains that explain actions — moving from executing motions to "executing ideas," making why precede how. Ultimately, it maps visual understanding to waypoint prediction, letting 2D predictions naturally land in 3D control, enabling more purposeful, contextually grounded action generation.
This capability shines in S1 real-world deployment. Asked to "put the flower representing love into the vase," S1 grasps the cultural metaphor of roses. When the instruction becomes "put the things from KFC into the blue container," it reasons out associated items like fried chicken and burgers. For "put the tool for drawing oceans into the green plate," it accurately locates the blue paintbrush.

Put the stationery that can draw oceans into the green plate
Reinforcement Learning Reasoning-Action Alignment (RL Alignment)
Strong reasoning doesn't guarantee successful execution. Lumo-1's final stage introduces Reinforcement Learning Reasoning-Action Alignment (RL Alignment) to calibrate and align high-level reasoning with low-level action errors, iterating through feedback on real trajectories. Through multi-dimensional GRPO-style reward signals for visual, action, and reasoning consistency, action execution, and reasoning format, the model is encouraged to select more accurate, coherent, physically plausible actions.
Results and Impact
Scaling Law Validation
The team validated their training strategy using data-constrained scaling laws. Results show: with fixed model scale, data diversity (coverage of scenarios, objects, instructions) impacts generalization far more than data repetition. This points the industry in a clear direction — beyond simply scaling data volume, data quality matters.
Technical Results: Comprehensive Baseline Surpasses
Lumo-1 outperforms its backbone model Qwen2.5-VL-7B on 6 of 7 multimodal benchmarks, and surpasses specialized embodied models RoboBrain-7B and Robix-7B. More critically, incorporating action learning doesn't damage the model's core multimodal perception and reasoning capabilities — proving that "reasoning" and "action" aren't zero-sum.
In real-world validation, S1 demonstrates remarkable generalization: automatically adjusting arm posture for containers of different heights; accurately identifying ingredient pairings (sausage pasta, carrot beef brisket, etc.) even when menus switch from printed to handwritten text.
For example, in the task "put the Coke on the plate," when the Coke is near the left arm, it reasons to grasp with the left arm; when an obstacle is artificially placed between the left arm and Coke (an unseen scenario), it reasons in real time that "left arm obstructed → right arm detour has lower cost" and autonomously switches strategy.
In the plush toy pairing task, it reasons which animated characters different plush toys (Olaf, Minnie, Alien) belong with on the paper cutouts (Elsa, Mickey, Buzz Lightyear).

For more surprising demonstrations from this model, watch the video below.





