"Independent Variable Robotics" Releases WALL-WM, the World's First "Event-Level" World Model: Teaching Robots to Ignore "Nonsense" | Yunqi Partners

Turning "Events" Into Units of Thought

When does a robot truly "understand" an action?
Most robot models work in a more "mechanical" way than you'd expect — they predict the next move frame by frame from camera footage, locked to a fixed rhythm. It's like a student reading a text by staring at every single word, never knowing which sentence matters and which paragraph can be skipped. Plenty of information gets processed; almost none of the useful stuff actually gets through.
Yunqi Capital portfolio company Independent Variable Robotics recently released WALL-WM with a different approach: instead of training on "frames," it trains on "events" — reaching, grasping, placing — these semantically complete action fragments become the model's smallest unit of learning.
This change looks like a simple granularity adjustment, but it points to a more fundamental question: what should the model actually learn? Read on with this issue's Yunqi Partners for the full story.
The following is republished from Independent Variable Robotics
The world never unfolds uniformly. Some moments decide everything; others don't matter at all. Yet today's world models predict every moment with the same rhythm.
Fixed-frequency prediction forces models to repeatedly "refresh" across countless irrelevant instants, while constantly missing what actually matters in the gaps between frames. They appear to predict the future, yet never learn to distinguish what's worth predicting in the first place.
Independent Variable Robotics introduces WALL-WM — the first world model with "event-level prediction capability." Breaking from the old paradigm of "uniform temporal sampling," the model no longer mechanically predicts every frame, but judges which instants truly matter.
A Neglected Fundamental Problem
Nearly every mainstream VLA in the industry today does the same thing: starting from video or multimodal foundation models, it directly predicts fixed-length action sets.
But the Independent Variable team explicitly identifies the hidden cost of this paradigm in WALL-WM — text, vision, and action simply don't live on the same manifold. Text is low-entropy discrete semantic intent; vision is a high-dimensional continuous observation stream; actions are constrained by physics and contact. The three share neither "neighborhoods" nor temporal scales. Joint optimization distorts the inherited capabilities from the video foundation model during adaptation.
This is why many VLAs perform far worse on real hardware than their base VLM should allow — prior knowledge gets degraded in transfer.
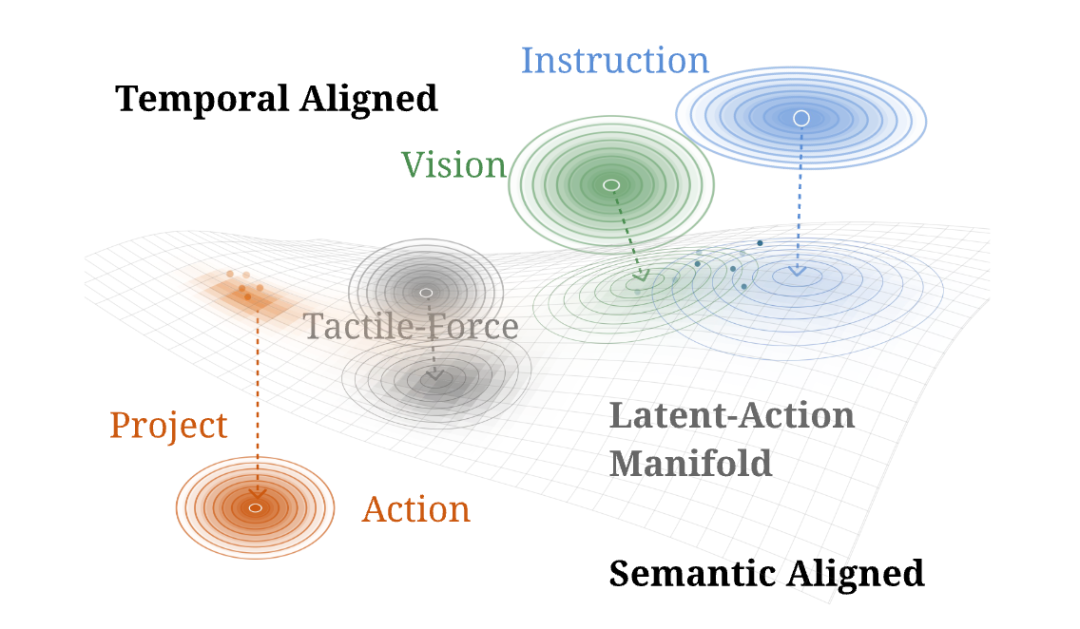
WALL-WM's Foundational Paradigm Shift: Making "Events" the Atomic Unit of Alignment
What is the smallest semantic unit for video-action learning?
The mainstream answer is "fixed-duration action chunks," but action chunks are arbitrary temporal definitions that may span two fundamentally different physical phases like "approaching" and "contact," forcing the model to learn through ambiguity.
Wall-WM's answer is Action-Grounded Semantic Events: reaching, grasping, lifting, moving, placing — temporally coherent, executable behavioral segments. They can be precisely described in language, covered by video timelines, and executed through action trajectories — a natural hub connecting all three modalities.
More critically, event-level world prediction lets the model learn not a reactive "instruction → action" mapping, but how the physical world will evolve and how the model should act given this event — the true form a world model should take.
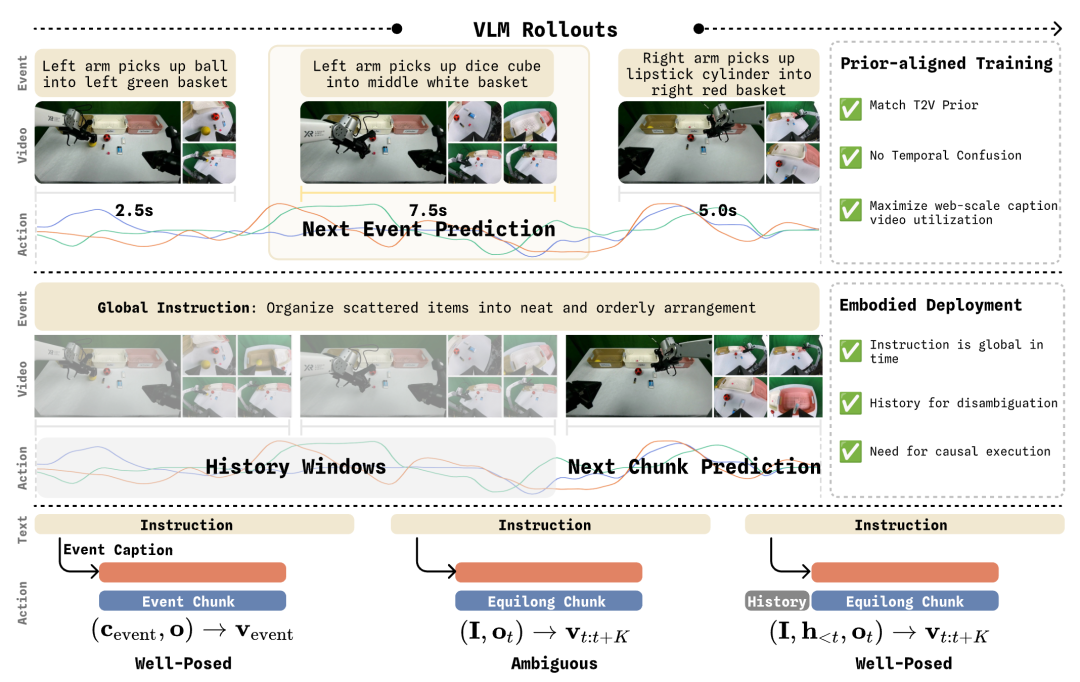
From Core Insight to Architecture: Three Key Design Moves
1. Prior-aligned video-action joint denoising.
The vision module carries internet-scale visual dynamics priors; the action module is randomly initialized and unidirectionally coupled with the vision module at every layer; cross-view fusion branch output projections are zero-initialized, ensuring training starts equivalent to the original single-view prior.
The action stream reads visual-language representations without backpropagating gradients to contaminate the video prior. This shared latent space functions as an implicitly width-adjustable action representation: no need to guess codebooks in advance, achieving both "prior preservation" and "continuous action capability growth" through large-scale training — something most VLAs fail to do at scale.
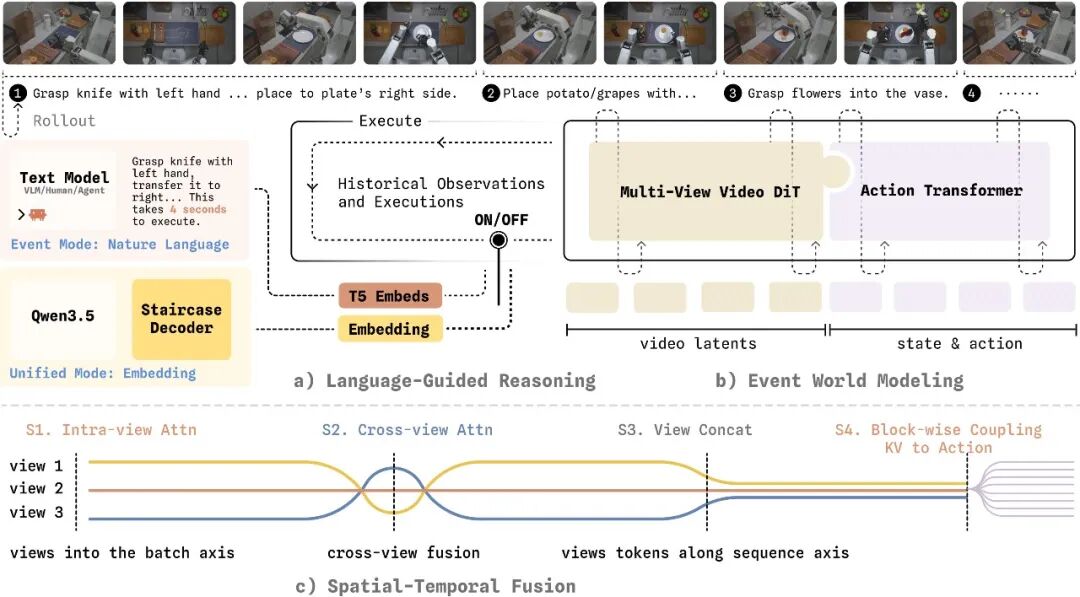
2. Multi-view attention lets the model exchange information across multiple cameras, rather than treating each view as an independent video stream.
Specifically, the model preserves Wan's original single-view spatiotemporal attention to inherit existing video generation priors; then adds cross-view attention within each DiT block, bringing spatial tokens from different cameras at the same timestep together for information exchange. This leverages geometric complementarity across views without disrupting the pretrained backbone's single-view capabilities.
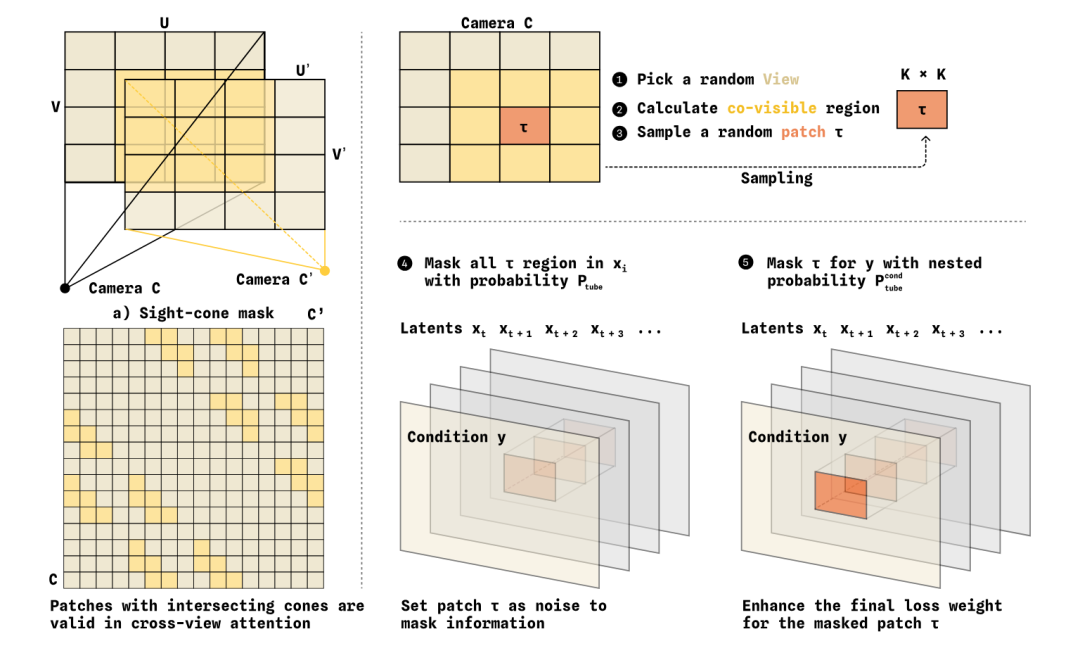
Training is paired with a sight-cone mask that constrains cross-view tokens to communicate only in geometrically co-visible regions, reducing meaningless cross-camera mixing. The overall effect improves multi-view consistency, 3D perception, and occlusion robustness in robotic manipulation scenarios.
Geometry-aware multi-view fusion. Real robots typically come with head + dual-wrist multi-camera setups; naive cross-view attention easily degenerates into a "generic feature blender." Wall-WM proposes a complementary pair of mechanisms: view-frustum masks and tube masks.**
View-frustum masks use camera calibration to topologically prohibit physically impossible associations;**
Tube masks randomly mask spatiotemporal tube regions in a view, forcing the model to recover through other views.**
View-frustum masks constrain where attention can go, while tube masks force it to go there. Cross-view attention is thus forged from an "underfitted latent capability" into a "frequently exercised geometric correspondence." With learnable camera rotation positional encoding, it natively supports large-scale training across multiple embodiments and multiple views.**
3. Staircase Decoding (staircase chain-of-thought decoding).
CoT improves decision quality, but token-by-token decoding is too slow for robot operations. Mainstream Latent CoT compresses thinking into continuous vectors for speed, at the cost of never seeing what the model is thinking again. WALL-WM's approach: run the base layer once, unfold higher layers in parallel like a staircase.
CoT remains discrete, readable text (a frozen LLM can fully reconstruct it), but decoding latency drops dramatically, natively compatible with KV-Cache — balancing interpretability and real-time performance.
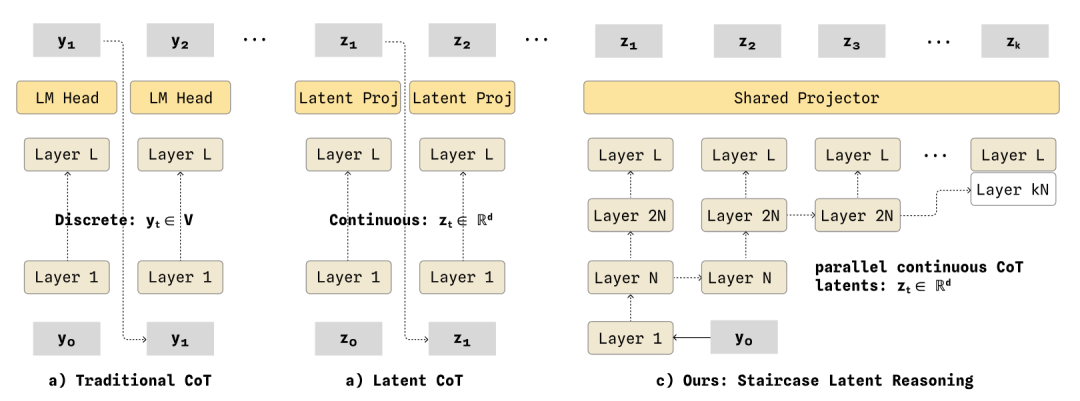
One Base Model, Two Inference Modes
WALL-WM supports two deployment modes on the same weights, for different use cases:
-
Event Mode: conditioned on "next event description," outputs variable-length action chunks. Suitable when an upper-level planner already exists that can break tasks into clear sub-events. Predicts one complete action unit at a time, naturally aligned to event boundaries.
-
Unified Mode: an online vision-language model generates intermediate reasoning with staircase chain-of-thought decoding, and outputs conditioned on fixed-length action chunks. Suitable for end-to-end real-time deployment without an external planner, requiring constant control frequency.
Both modes share the same weights and can be switched segment-by-segment during execution, with no retraining needed. This means the same model can serve as a low-level executor working with a high-level planner, or run complete closed-loop independently. Deployment form is determined by the scenario, not by the model.
Data and Infrastructure: Systematic Support for an Event-Level Ecosystem
Pyramid data structure: The base is million-scale general internet video, narrowing to human manipulation video and first-person public data, then ascending through UMI-style embodiment-free collection (from Independent Variable's fully self-developed XRZero-G0 embodiment-free data collection device), heterogeneous teleoperation data, geometrically consistent self-collected data, with event-level takeover and correction data at the pyramid's peak. Each layer is a controlled relaxation of the layer above's constraints — higher layers closer to real deployment, lower layers closer to open-world visual priors.**

Data map: Training data is organized as a data-source map covering different views and action availabilities. Sources include general internet video, first-person/human manipulation video, UMI-style embodiment-free collection data (from Independent Variable's fully self-developed XRZero-G0 embodiment-free data collection device), and heterogeneous teleoperation and open robot data. General video provides large-scale visual and temporal dynamics priors; takeover and correction data serve as central recovery data sources, supplementing contact-dense regions and failure recovery behaviors, and can be combined with multiple sources for sampling.**
Four-level hierarchical annotation + dual-cluster sampling: Every trajectory is annotated at task, subtask, action, and segment granularities. One notable finding in the report: when text descriptions are segmented by action boundaries, both language distribution and vision-language joint distributions become significantly more balanced. Long-tail rare instruction-scene combinations are naturally exposed to the training sampler. This is a latent benefit of the event-level paradigm at the data engineering level, not something deliberately engineered.**
Distributed Muon optimizer + FP8 deployment: On the training side, the team distributed the Muon optimizer, reducing its overhead in large-scale training from a "bottleneck" to negligible levels, naming this distributed implementation DMuon; they also feed data by "packing multiple events into one sequence," avoiding the waste of padding tokens when training by whole trajectories of varying lengths. On the deployment side, FP8 low-precision quantization plus distribution-matching distillation compresses diffusion model inference latency into ranges acceptable for real-time robot control: more efficient training, faster inference — both ends connected.**
Experiments:
Best large-scale real-hardware generalization
- Embodied Video Generation: Compared to Wan2.1/Wan2.2, WALL-WM leads across all three embodiment-relevant dimensions — Motion Quality, Semantic Consistency, Physical Plausibility;**

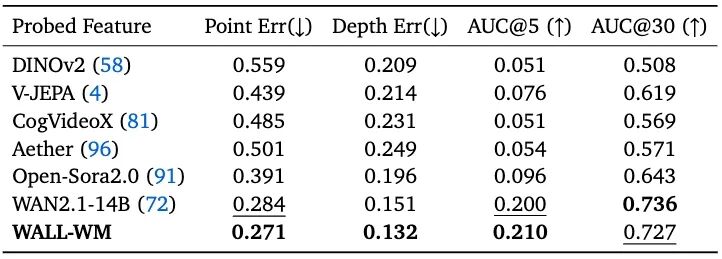
- 3D Awareness (CO3Dv2): Outperforms WAN2.1-14B, Open-Sora 2.0, V-JEPA, DINOv2 on Point Error and Depth Error;**
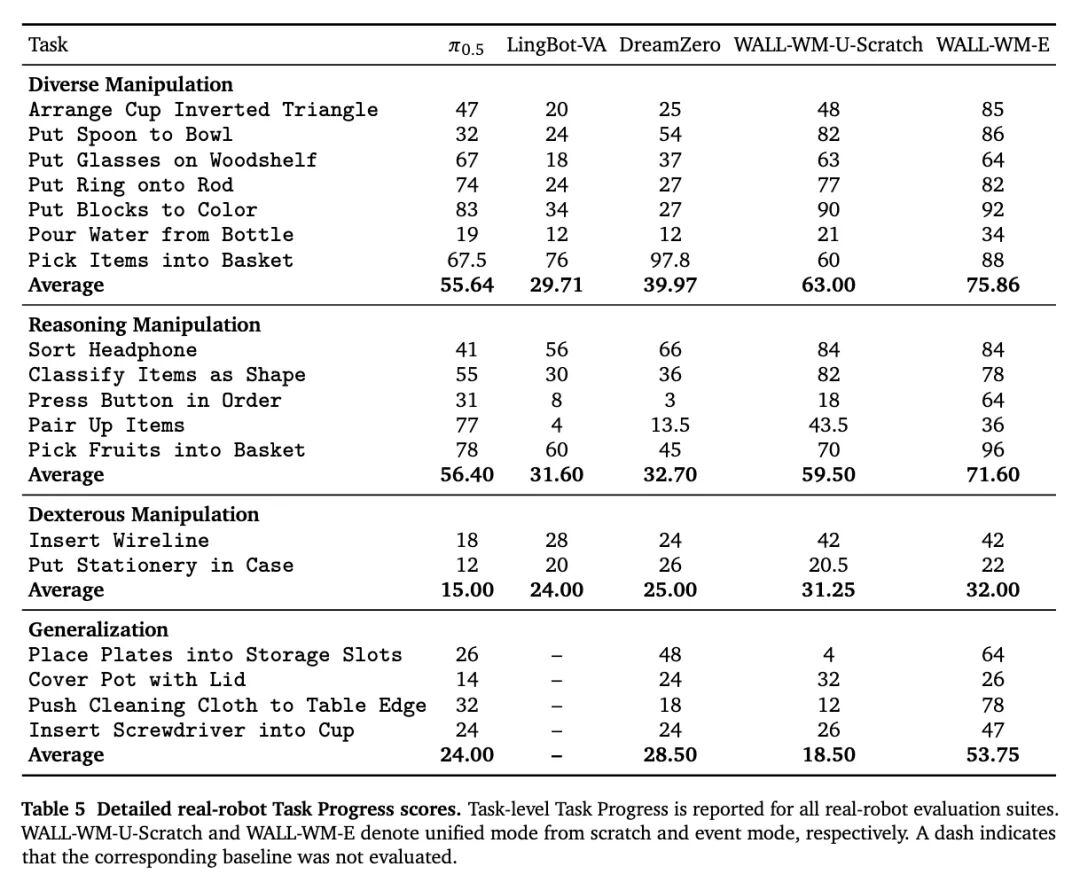
- Real-hardware Core15 L1 benchmark: Task completion scores across basic tasks, reasoning tasks, dexterous manipulation, and generalization scenarios significantly exceed π0.5, DreamZero, making it one of the highest-completion L1 models currently under abstract instruction settings.**
Conclusion
WALL-WM's real value lies not in yet another VLA with higher benchmark scores, but in offering a coherent, engineering-complete answer to the fundamental question of embodied foundation models: how to let models learn world prediction while preserving multimodal prior geometry:
Events are not merely an annotation granularity, but the unit of thought that world models should adopt.**
GitHub:
$2*
Project page:
**$2





