The Mid-Game Battle for Vector Databases: How Long-Term Player Zilliz Breaks Through | Yunqi Tech π

Building the "New Infrastructure" for the AI Era

The arrival of the AI era has sparked surging demand for new infrastructure. Compared to GPUs and large models, vector databases may be the least familiar among AI infrastructure components to most people. Yet as the catalyst for large models to truly achieve intelligence, they are indispensable.
In 2019, before ChatGPT set off the generative AI wave, Yunqi Capital's early-stage portfolio company Zilliz wrote the first line of code for what would become the world's first vector database. Five years later, Zilliz has grown into a "leading player" in the global vector database industry, notching a阶段性 victory.
In the journey toward large model intelligence, what will enable vector database startups like Zilliz to continue breaking through? This edition of "Yunqi Tech π" takes you inside.
This article is republished from "Synced" (机器之心)
The gears of fate began turning on March 23, 2023, with a routine update from OpenAI.
That day, OpenAI's ChatGPT released a plugin feature called chatgpt-retrieval-plugin. In the official plugin's standard examples, OpenAI specifically noted that vector databases are an essential component for large model products to develop long-term memory.
Coincidentally, three days earlier at NVIDIA GTC 2023, NVIDIA founder Jensen Huang had also highlighted vector databases. During the event, Zilliz — a previously little-known vector database startup — was invited on stage to speak three times. Vector databases and large language models became the most discussed keywords at that year's GTC, second only to chips.
From that day forward, attention toward all vector database projects across global open-source communities and venture capital markets instantly traced a steep growth curve.
Zilliz's flagship Milvus saw its GitHub stars surge from 10,000 to 30,000 over the following two years. In what had been a relatively barren赛道, "dedicated vector databases" like Pinecone and Weaviate sprouted up like bamboo shoots after rain within just over a month, with billions in hot money wired to startup accounts.
Intense heat, flowers in brocade — but alongside the enthusiasm came reckless management:
Jeff Delaney, a Google Developer Expert and creator of the YouTube channel Fireship, pushed his Rektor vector database startup to a $420 million valuation with zero revenue, zero business plan, and zero demo code. A star startup publicly admitted its product was merely ClickHouse and HNSWlib with vector search and Python packaging layered on top, then pushed to market.
In public markets, even traditional database operations companies would see consecutive 20% daily limit-up stock moves the moment they announced vector database R&D. One major tech company went from project initiation to product launch in under three months with its self-developed vector database.
At the time, everyone believed that every era has its signature infrastructure: coal, water, and electricity for the Industrial Revolution; IOE plus Wintel for the Information Age; Qualcomm plus Android plus Snowflake for the mobile era. So why wouldn't the AI era be defined by GPU plus large model plus vector database?
Holding vector database source code meant lining up for the dream team en route to a hundred-billion-dollar market cap in the AI era.
What everyone forgot was that violent delights have violent ends — just as database wars have played out repeatedly throughout history. In a market with massive scale effects, the Pareto principle had already written the ending for all players.
01
A New Trillion-Dollar Blue Ocean
Before understanding the market's狂热 for vector databases, we need to clearly explain what they are and their relationship with large models.
As the name suggests, vector databases store and manage vectors. Their conceptual counterparts are traditional relational databases like Oracle and MySQL, and NoSQL databases like PostgreSQL and MongoDB that emerged during the Web 2.0 era.
Compared to the latter two, vector databases excel at storing and managing unstructured data — the images, videos, audio, and documents that cannot be precisely described in tabular (structured) formats.
In traditional databases, data management and retrieval resemble Excel: we categorize data and perform exact searches and operations. Finding all "chocolate" on supermarket shelves is easy. But finding products with certain characteristics — say, "items that can quickly replenish blood sugar" — defeats keyword-based precise search.
Vector databases store and manage data based on "feature" similarity. A chocolate photo, after AI model feature extraction and storage in a vector database, becomes a series of distinctive "feature codes" like "high-fat," "snack," "high-sugar," "brown," "originated in Central and South America" — enabling responses to feature-based queries like "blood sugar replenishment."
Therefore, compared to traditional databases, vector databases have a closer relationship with today's booming large models.
One typical application is RAG.
RAG, short for Retrieval-Augmented Generation, is widely used for building domain-specific knowledge bases, addressing large models' hallucinations, lack of domain knowledge, and inability to dynamically update knowledge.
In recent years, large models like ChatGPT have dramatically improved AI's general knowledge and reasoning capabilities. However, their biggest flaw is the lack of professional domain knowledge and long-term memory, plus a tendency to hallucinate. We often see large models writing complex programs while failing elementary school math Olympiad problems. Some, after training on erroneous or "toxic" data, confuse "Southern Tang" with "Tang Dynasty" or misattribute Li Bai's works.
Meanwhile, in finance and other fields, we need the latest first-hand data and knowledge for analysis. Yet once trained, a large model's knowledge is fixed, lacking dynamic supplementation of market information and other knowledge.
Through vector databases, enterprises can connect their domain-specific and proprietary knowledge to large models via RAG mode, enabling rapid mastery of medicine, law, automotive, and other specialized fields, plus real-time knowledge updates.
Thus, large models have撬动了 market demand for vector databases; vector databases have become the catalyst for large models' path to intelligence. The market snowballs, growing ever larger in this perpetual-motion expansion.
But vector databases' potential extends far beyond large models. Personalized multimodal content search, recommendation systems, precision marketing, risk control, fraud detection, cybersecurity, autonomous driving, and virtual drug screening are also core application scenarios.
The explosion of downstream applications has driven further market expansion: DB-Engines data shows vector databases have been the most popular database category over the past three years; Gartner predicts that by 2026, 30% of enterprises will integrate vector databases into their generative AI models.
Northeast Securities has made further market size calculations: by 2030, the global vector database market could reach $50 billion, with China's domestic market exceeding 60 billion RMB.
History has taught us that in every boom, selling shovels is the surest bet.
And the vector database is the golden shovel of the large model era.
02
The Factions of Vector Databases
Barring surprises, the birth of a hundred-billion-dollar enterprise in this赛道 is only a matter of time.
Under this irresistible temptation, the market quickly divided into three factions:
First faction: independent vector database startups.
Their strength lies in productization. Compared to traditional single-machine plugin databases, vector databases can increase retrieval scale by tenfold, supporting peak capabilities of millions of queries per second (QPS) with millisecond-level latency.
Their weakness is that some startups, having been founded relatively recently, lack foundational database capabilities like backup/recovery/high availability, batch update/query operations, and transactions/ACID. Additionally, cross-database data asynchronization is a non-negligible issue. If a user deletes data in the original PostgreSQL without real-time synchronization to the vector database, data inconsistency arises, impacting production environments.
Second faction: traditional database players like Oracle and MongoDB, which add vector search plugins to traditional databases, thereby granting them vector retrieval capabilities.
Their advantage is that data no longer needs to sync, flow, or process across multiple databases. Their disadvantage is that traditional databases have inherent limitations in processing and supporting massive unstructured data. Building an image library application for billion-level visual search, with each image corresponding to 128-dimensional Float vectors, would require server memory of up to 480GB — far exceeding single-machine memory limits. In other words, traditional database add-ons can support certain user needs at the million or ten-million data scale; but reaching hundred-million or billion-scale data requires professional enterprise-grade distributed vector databases.
Third faction: cloud service giants. Represented by AWS and Microsoft, they incorporate self-developed vector database products into their cloud service portfolios, with the advantage of "buy one, get one free" service continuity. Their disadvantage is that cloud giants are often simultaneously building large models, applications, cloud services, and vector databases — acting as both referee and player. Under these circumstances, how can enterprises confidently place their proprietary knowledge bases on the cloud? This becomes a new concern.
Thus, the world divided into three. Traditional database players battle on multiple fronts across NoSQL, graph databases, relational databases, and vector databases. Cloud giants卡位 the traffic end, making vector databases a freebie in their overall cloud operations. Startups distinguish themselves through product excellence and压强式 investment in performance and service.
03
The Mid-Game Report
While major players were still heads-down sprinting, Forrester had already this Q3, through its "Forrester Wave™: Vector Databases, Q3 2024" report, ranked 14 leading vector database players across 25 dimensions covering product capabilities, business strategy, and market presence.
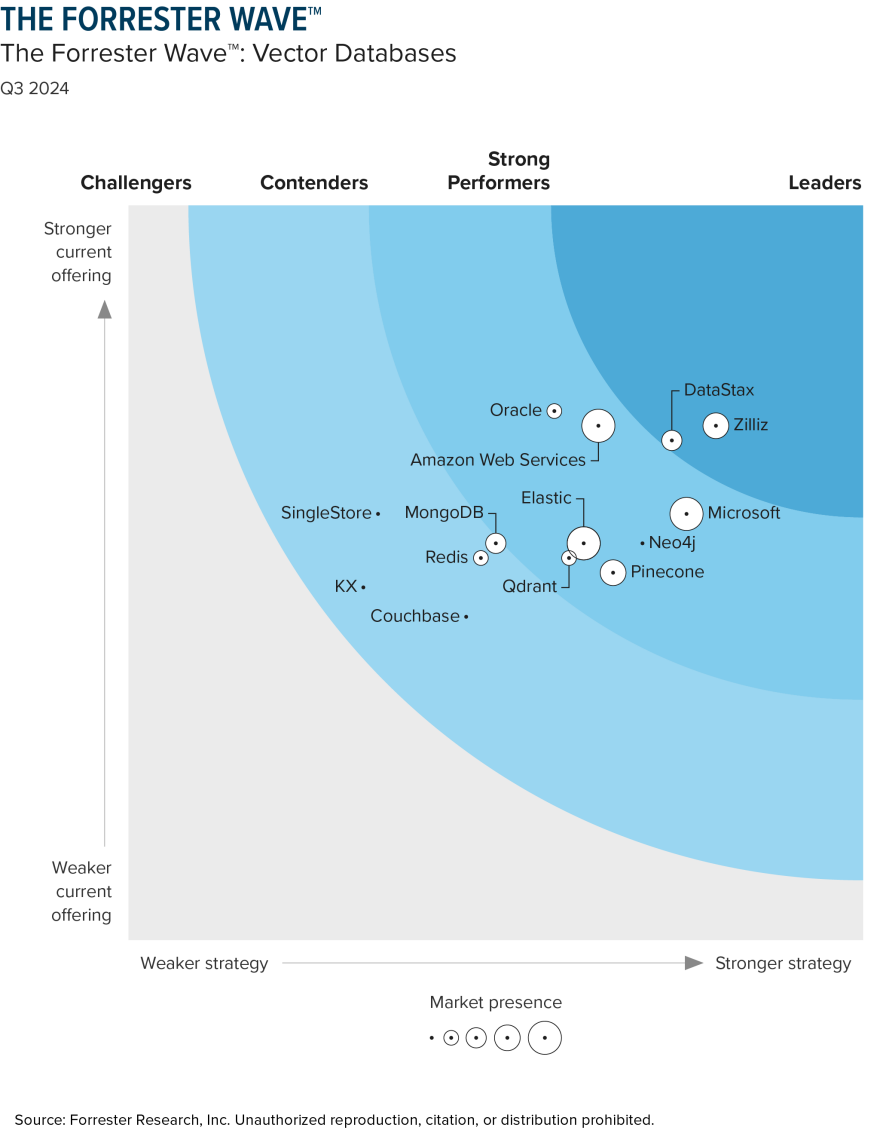
In Forrester's ranking, the leader in the Leaders quadrant was Zilliz — representing the first faction of vector database startups. The second tier included Oracle, Microsoft, AWS, and Pinecone; the third tier included MongoDB and others. Overall, vector database startups held the most advantageous positions in both ranking and number of entrants. Traditional database players and cloud giants showed mixed results. Forrester's criteria for ranking players was straightforward: excellent vector database vendors should possess: 1) complete vector database functionality including vector indexing, metadata management, vector retrieval, and hybrid search; 2) complete data management capabilities including vector storage, real-time data updates, data integration, resource optimization, data integrity and consistency, concurrency control, and elastic scalability; 3) user-friendly UI design and comprehensive, usable APIs; 4) scalability to hundred-million-level data scales and GPU integration support.
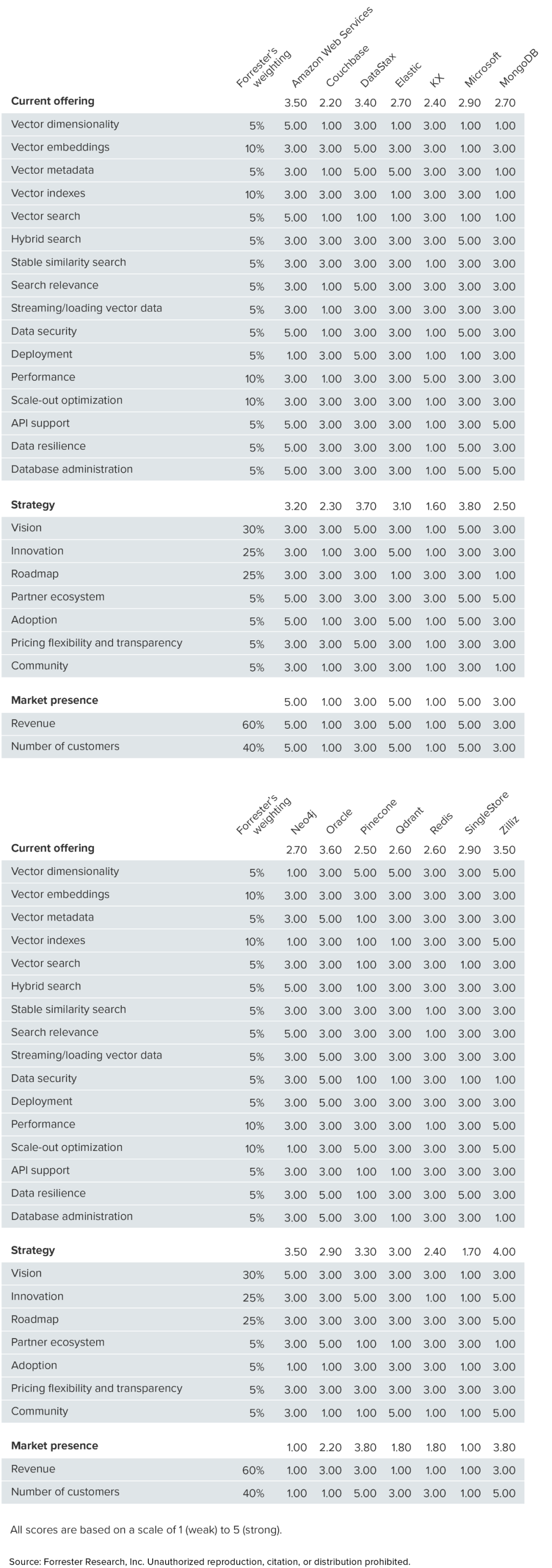
Take Zilliz, the established player and vector database pioneer that entered the Leaders quadrant. Forrester's assessment was that Zilliz excels overall in managing massive vector data volumes. It performs particularly well in vector dimensions, vector indexing, performance, and scalability, making it especially suitable for customers prioritizing high-performance, low-latency access to large vector data volumes for advanced AI applications.
Specifically, at the vector indexing level that Forrester cares most about, native vector databases like Zilliz have inherent advantages over traditional databases with added vector capabilities in basic vector indexing, metadata management, vector retrieval, and hybrid search.
In complete data management functionality, Milvus and Zilliz Cloud are among the few products on the market offering vector storage, real-time data updates, data integration, resource optimization, data integrity and consistency, concurrency control, and elastic scalability. This stands in stark contrast to some marketed vector database products that, for considerable periods, lacked even the most basic backup and recovery functions.
For UI and API user experience, Zilliz Cloud provides out-of-the-box vector database services.
In scalability, Milvus can handle millions to billions of vectors, making it one of the most popular open-source vector databases; Zilliz Cloud offers users hundred-billion-level vector data retrieval in milliseconds. Meanwhile, in GPU integration, at GTC 2024, Zilliz partnered with NVIDIA to release the world's first GPU-accelerated vector database, powered by NVIDIA CUDA, achieving 50x performance improvement.
On the industry side, beyond being one of OpenAI's first official plugin partners, Zilliz has surpassed 10,000 global customers and partners, with deployments in image retrieval, video analysis, natural language understanding, recommendation systems, targeted advertising, personalized search, intelligent customer service, fraud detection, cybersecurity, and new drug discovery.
In summary, Milvus and Zilliz Cloud are among the few players on the market that, beyond basic vector management functionality, provide product-level support for massive data volumes and complete database capabilities.
Forrester's assessments of the other two factions can be glimpsed through its comments on AWS and Oracle.
For Oracle, its strengths in product capabilities and business strategy need no elaboration, but the report also straightforwardly notes at the outset that traditional databases have limitations in vector dimensions and similarity search.
Regarding AWS, Forrester finds it accomplished in vector dimensions, database management, API support, data security, and vector search, with its biggest weakness being that these services are limited to AWS cloud.
No one dislikes a complete ecosystem, but if choosing that ecosystem means binding your most core data resources to it, the decision scales will tilt the other way.
Epilogue
An Underestimated Market
As the undercurrents of vector database fragmentation swirled, a time lock has clearly come into view.
Historically, this is already the third war around databases.
In the 1980s, driven by U.S. military needs, Oracle was born amid IBM's iron walls, and using relational databases to process structured data became the mainstream for the following three decades.
Around 2010, the maturation of the internet caused humanity's historically generated data volume to膨胀 rapidly. Meanwhile, our data needs evolved beyond relational databases' "row-column" operations — storage, reading, and high concurrency became defining characteristics of this era. Thus NoSQL (non-relational databases) was born, with MongoDB as the representative player.
Then in late 2022, as large model technology matured, demand for vector-based similarity search exploded beyond traditional field-based precise search, and vector databases became white-hot. In the process, a wave of new "Davids" began challenging the Goliaths, with淘汰 and player梯队 rapidly producing阶段性 results within two years.
Why did the阶段性 victors turn out to be startups like Zilliz?
The answer is simple — respect for the market.
The first layer of respect is respect for the era's opportunity. Unlike any previous technology wave, standing on the shoulders of open source, the birth and普及 of large models has placed enterprises worldwide on the same starting line. Thus globalization became the common denominator for this cohort — from Zilliz's founding, all new product and technology releases were globally oriented, with team composition spread across China, the U.S., Europe, Japan, and Singapore.
The second layer of respect is respect for objective user needs, and the differentiation and massive potential of unstructured data. Facing user needs, Zilliz offers both Milvus, the open-source vector database with 30,000 GitHub stars, and Zilliz Cloud, focused on out-of-the-box deployment. It dared to build entirely new products and services from zero rather than simply adding to mature products.
The third and most important layer of this respect is persistence. As one of the earliest vector database companies, Zilliz wrote the first line of code for vector databases worldwide back in 2019, before large models became mainstream — both the market pioneer and long-term evangelist. This laid the groundwork for Zilliz later boarding the ecosystem ships of NVIDIA and OpenAI.
Who will be the next IOE to emerge from the storms? The market still needs time to verify, but the scales are already slowly tilting toward long-term players.





