"Zilliz": Eight Predictions for the Vector Database Industry in 2023 | Yunqi Capital

The Future Outlook for Vector Databases

"Yunqi Tech π" shares updates from Yunqi Capital's portfolio companies, exploring how frontier technology pushes the boundaries of real-world applications and tracking the present and future of tech commercialization. In this edition, we bring you the latest from Zilliz.
➤➤➤ Yunqi Capital led the angel round in Zilliz, a pioneer and global leader in vector database systems that develops vector databases for AI production systems. As the vector database sector exploded and players navigated technological upheaval and capital flows, Zilliz partner and technical director Xiaofan Luan looked back on the industry's 2022 and offered eight predictions for 2023. Read on:

2022 was absolutely the year the vector database sector exploded. That year, the Milvus community officially released Milvus 2.0, a cloud-native vector database. Over ten open-source vector database products also appeared on GitHub, including Vald, Weaviate, Qdrant, Vespa, Vearch, AquilaDB, Marqo, and others. Database vendors Elastic and Redis formally entered the fray, adding vector search capabilities. In the cloud, Zilliz — the team behind Milvus — officially launched Zilliz Cloud, a fully managed DBaaS offering, competing against SaaS companies like Pinecone and cloud vendors like Google Vertex AI.
The capital markets were equally tumultuous in 2022, with major vector database companies completing new funding rounds at the tens of millions of dollars level. It's foreseeable that 2023 will be another year of rapid growth for vector databases, and the year this emerging technology matures from development into something more established.
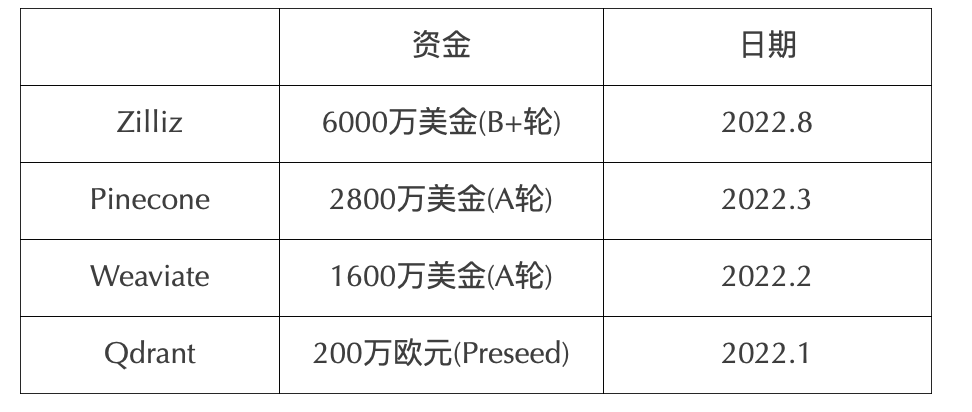
Vector Database Vendor Funding in 2022
Over the past two years, I've had the privilege of participating deeply in the design and development of next-generation cloud-native vector databases as a Milvus community maintainer, witnessing this field's rapid evolution. As an entrepreneur, I've also spoken with numerous investors, founders, and candidates in the database and AI spaces. Here are my eight predictions for the vector database industry in 2023:
1
Vector databases begin to diverge and stratify
Unlike the previous pattern of moving forward in lockstep with homogeneous development, the influx of capital and talent alongside rapidly evolving application scenarios will drive different vector database vendors to focus on distinct use cases, including but not limited to:
▲ Online Serving Versus Offline Processing
Vector databases have historically targeted search, advertising, and recommendation scenarios, characterized by high real-time online requirements and relatively small data volumes. The primary demands were high performance and availability, with less emphasis on scalability and functional complexity. As applications in image, video, autonomous driving, and NLP continue to expand, data volumes have grown from tens of millions to tens of billions, placing ever-higher demands on vector databases' offline ingestion and batch processing capabilities.
▲ Logical Instance Versus Physical Instance
Vector databases like Milvus, which we call physical instances, primarily address low-cost vector storage and efficient retrieval without getting heavily involved in vector generation. Some vector databases on the market go beyond vector processing to also encompass vector generation capabilities across various data modalities.
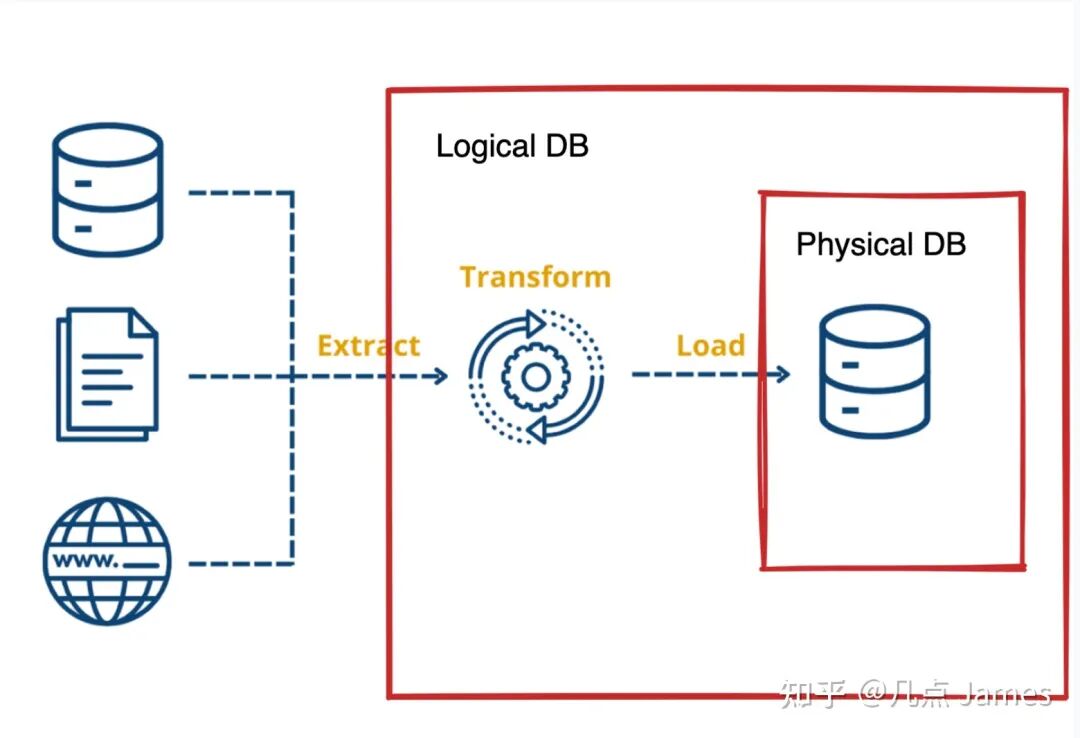
Logical Vector Database Vs. Physical Vector Database
Logical instances are more user-friendly and avoid complex deployment and dependencies. Physical instances offer greater flexibility, allowing users to choose the most suitable inference engine and model for their needs. Personally, I prefer the Physical DB + Embedding ETL approach, separating vector generation and vector retrieval into two distinct stages. The main reason is that upstream application scenarios for vector databases are extremely complex. As a database product, abstraction level matters — focusing too early on too many business details can easily derail a product's generality and foundational capabilities.
▲ Single-Node Versus Distributed Cloud-Native
Distributed and single-node architectures aren't purely substitutive. At least for now, most distributed databases perform worse, with higher maintenance and design costs. For many open-source users with smaller scale, a stable, efficient MySQL/PostgreSQL remains a solid choice — not every need demands a deliberately scaled-out NewSQL database.
In the vector database arena, scalability approaches currently divide into two camps. One builds on single-node engines, using Raft protocols for data consistency and a simple proxy for data routing (or even offering just a single-node solution, leaving users to shard data themselves for scaling). The other camp, represented by Milvus 2.0's cloud-native design, leverages cloud infrastructure (cloud disks, S3, message queues) for data persistence, with storage-compute separation and microservices for elastic scaling and resource pooling.
Neither camp has come close to hitting its ceiling yet — at least through 2023, we'll need to let things play out. But user demand for massive data won't wait. Users' scalability needs for compute and memory will determine that distributed vector databases become mainstream.
▲ Different Index Implementations
After five years of rapid development, vector indexes have gradually consolidated from Faiss-style IVF approaches to graph-based approaches represented by HNSW and NGT. Graph indexes, despite relatively poorer interpretability and higher memory consumption, have been widely adopted for their high performance and recall rates.
As commercial companies behind vector databases grow, more are building proprietary execution engines, meaning vector database products will diverge across performance, functionality, and resource consumption. Another development to watch is Google's ScaNN technology — next-generation quantization techniques showing very strong benchmark metrics, which we'll soon integrate into Milvus's execution engine Knowhere.
2
A standardized query language begins to take shape
Current vector database APIs haven't converged on a unified query interface. Most offer custom Python SDKs or RESTful APIs. At Google Next 2022, BigQuery's BigLake release seemed to push SQL forward significantly as the primary language for unstructured data and vector processing. SQL's target user base differs substantially from traditional deep learning developers, and past attempts at SQL-based machine learning or deep learning haven't achieved major success, so SQL as a vector database query language remains to be seen.
Beyond SQL, we're also seeing attempts based on GraphQL query languages and custom DSLs. Regardless of which interface users ultimately embrace, my prediction is that 2023 will see one interface emerge as the de facto standard for vector databases, with multiple products implementing similar interfaces.
3
Further convergence between vector databases and traditional databases
Two years into their development, vector databases have long since moved beyond simple Faiss wrappers. Scalar field filtering and indexing, plus CRUD capabilities for streaming data, have become table stakes. Traditional database components — parsers, optimizers, memory management, concurrency control — are increasingly appearing in vector databases. Conversely, many OLAP and NoSQL databases have integrated vector search capabilities, becoming significant players in this space.
I've long held the view that one size cannot fit all. Traditional database vendors struggle to do vector search well — this involves both people issues and architectural limitations. But 2023 won't be the decisive battle. We'll see more traditional database vendors enter vector search because this opportunity is simply too attractive. On the other side, vector databases will continue learning from the database field, gradually shifting their DNA from AI infrastructure toward databases. Vector search scenarios demand greater generality and stability than traditional AI infrastructure, which tends to be more flexible and scenario-specific. Barring surprises, 2023 will bring more talent with traditional database backgrounds (spanning TP, AP, search, and caching) into the vector database track.
4
Vector database costs will drop 3-5x
Cost and performance have been major barriers to vector search displacing traditional keyword search. Currently, most vector databases are memory-only — storing tens of billions of vectors would require dozens of terabytes of memory. Additionally, since most distributed databases must balance query performance against index build speed, they generally adopt divide-and-conquer strategies, partitioning data into shards for index building and merging TopK results from each shard during queries. As data volumes grow, query CPU overhead rises linearly, making the compute resources needed for high QPS at large scale difficult to sustain.
2023 will be a year of dramatic cost and performance improvements for vector databases. Here are the opportunities I see:
1) Widespread ARM architecture adoption in the cloud, offering 2-3x better price-performance than x86 for simple compute
2) Booming heterogeneous hardware with memory/VRAM and bandwidth far exceeding what GPUs can provide
3) Quantization technology advances, particularly large-scale application of 4-bit quantization in vector search
4) Disk-based ANNS indexes becoming a mainstream research direction
5) NVMe disks delivering exciting performance, with AIO and io_uring enabling millions of IOPS
6) Growing understanding of vector databases enabling pruning techniques using metadata and traditional database approaches, so queries no longer need to scan all shards
7) Machine learning-based index parameter and model parameter selection appearing in production for the first time
8) Vector data, like traditional scalar data, exhibiting clear hot-cold patterns
5
The first serverless vector database will emerge
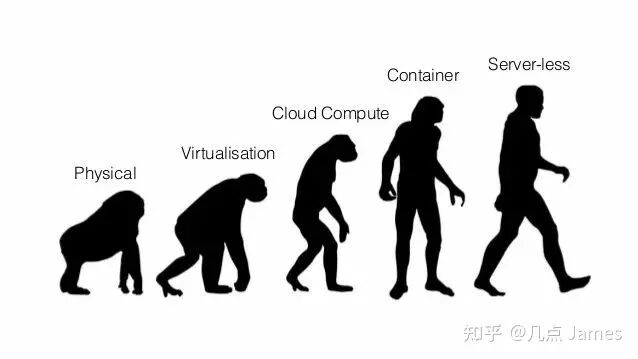
From Physical Machine Deployment to Serverless
Serverless's elasticity and pay-as-you-go model are highly attractive for vector database cloud-hosted service users. Vector search scenarios are complex, spanning both offline and online workloads with high variability and frequent multi-tenancy. Serverless greatly reduces complexity for capacity planning and business isolation. Technically, vector databases' availability and consistency requirements are generally less stringent than critical OLTP workloads, making serverless vector databases more feasible to implement.
Of course, vector databases remain far from mature serverless implementations. No product has yet invested heavily in elasticity, flow control, or multi-tenant isolation. I expect 2023 will first see vector databases that, like AWS Aurora, use container-based single-node architectures capable of dynamic scale-up/down. Truly distributed serverless databases remain a long way off.
6
A suite of open-source tools will emerge around vector databases
The unique nature of vector data means this space requires creative development of many new tools. For data visualization, traditional tabular approaches only suit character and numeric types — vector data distributions and query paths need more intuitive visualization.
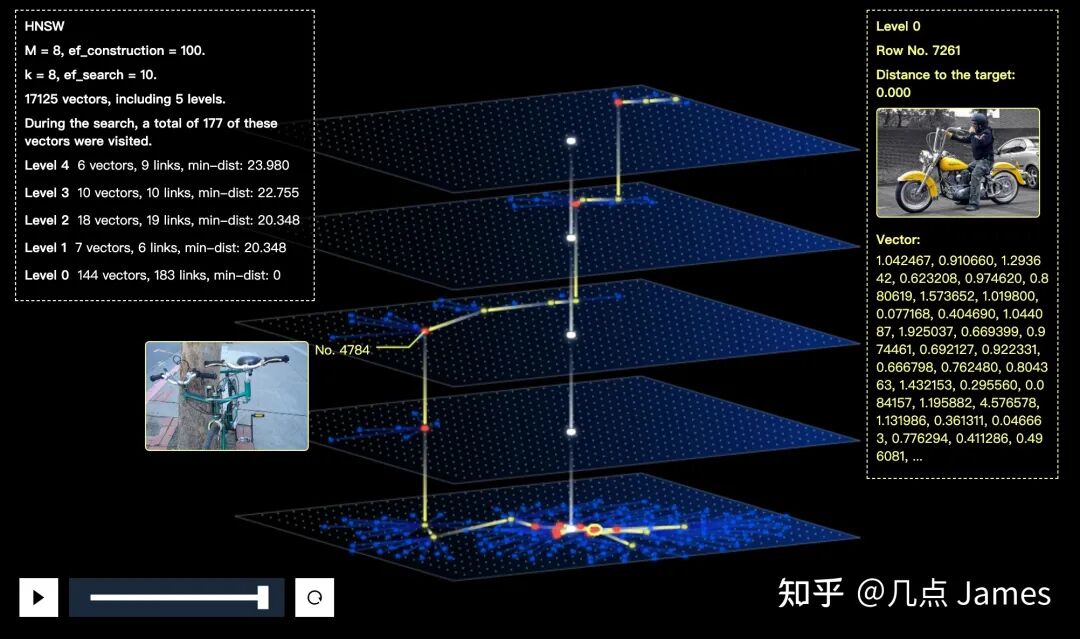
Feder visualizing HNSW index query process
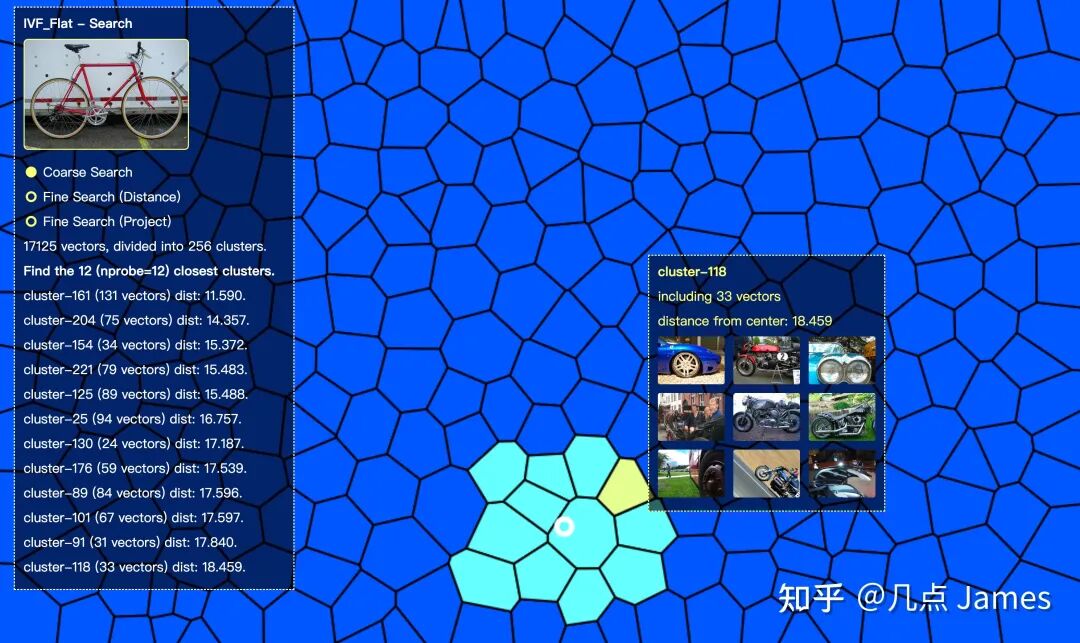
Feder visualizing IVF FLAT index data partitioning
Another interesting track is data transmission pipelines, including backup, migration, and ingestion capabilities. As vector database varieties multiply, we'll need transmission tools connecting different data sources and upstream/downstream systems. In the future, cross-cloud and cross-datacenter vector database replication, plus batch vector data generated from Spark, PyTorch, and TensorFlow, will flow continuously into vector databases through these tools.
7
Beyond DB4AI, vector databases will be among the first to productionize AI4DB
AI4DB has been proposed in the database field for years but has struggled to achieve broad deployment. The core bottleneck is that relational databases demand high correctness and interpretability — even if AI delivers gains in 90%+ of scenarios, 10% bad cases can prevent real-world adoption.
Vector databases break this constraint to some degree because they're inherently probabilistically optimal, with query results evaluated by recall rate rather than 100% accuracy. On this foundation, AI4DB can be applied more aggressively to automatic parameter tuning, query rewriting, learned indexes, and other domains. Our testing shows that model-predicted query parameters can deliver over 2x performance improvement on large datasets. If we can tune indexes and query parameters based on datasets and limited query samples, even more dramatic gains should be possible.
8
A second commercial company building on open-source Milvus will emerge
Milvus is the world's first vector database and currently the most advanced cloud-native vector database. Over the years, excellent open-source projects have often been built by multiple commercial companies — Hadoop, Presto, and ClickHouse all show similar patterns. As the Milvus open-source project matures, the probability of success for building a vector database from scratch that surpasses it has grown increasingly slim. However, opportunities remain for building SaaS services on top of vector databases. As an open and inclusive open-source community, I expect Milvus will attract more co-builders who collaborate on the project while competing in commercialization.
The deep development of large models in recent years has expanded vector database application scenarios, while compute has advanced significantly through GPUs and specialized hardware. 2023 is a year of great promise for the entire industry and open-source community.
Zilliz is a pioneer and global leader in vector database systems, developing vector databases for AI production systems. With a mission to unlock the value of unstructured data, Zilliz is dedicated to building next-generation database technology for AI applications, helping enterprises develop AI applications with ease. Zilliz's products significantly reduce the cost of managing AI data infrastructure, enabling AI technology to empower more enterprises, organizations, and individuals.
Yunqi Capital remains focused on "technology innovation, industry enablement," with open source and foundational software among its sustained areas of focus. In 2017, Yunqi led Zilliz's angel round and has continued to invest in subsequent rounds. Beyond Zilliz, Yunqi made early lead investments in industry leaders including PingCAP, Jina AI, and Singularity, and has been invited to share commercialization perspectives at world-class industry summits including Amazon Web Services Summit, China Open Source Conference, VMware Intelligent Cloud-Edge Open Source Summit, and Huawei Partner & Developer Conference.
As a professional investor in China's open-source industry, Yunqi has received multiple industry recognitions including "Sci-Tech Innovation China" Open Source Innovation awards. Yunqi's investors have been uniquely recognized as domestic open-source pioneers in the industry.
Yunqi actively promoted open-source development over the past year. In early 2022, Yunqi partnered with Kaiyuanshe ("Open Source Society"), China's most influential open-source community, to officially release the "2021 China Open Source Annual Report," presenting China's open-source development across multiple dimensions.
Additionally, Yunqi joined the OpenCloudOS operating system open-source community as a founding member, committed to working with community partners to build a fully neutral, comprehensively open, secure, stable, and high-performance operating system and ecosystem, jointly advancing open-source ecosystem development.
Follow the Yunqi WeChat official account and reply with "open source report" to read the complete Chinese version;
Reply with "open source report foreign language version" to view the English and Japanese versions~









