Zilliz × Nvidia GTC: Launching the World's First GPU-Accelerated Vector Database | Yunqi Capital

Vector Databases Enter a New Era of GPU Acceleration
On the morning of March 20, San Francisco time, Zilliz and NVIDIA jointly unveiled Milvus 2.4 at GTC 2024.
This is a revolutionary vector database system — the first in the industry to leverage NVIDIA GPU's efficient parallel processing capabilities and the newly launched CAGRA (CUDA-Accelerated Graph Index for Vector Retrieval) technology from the RAPIDS cuVS library, delivering GPU-based vector indexing and search acceleration. Powered by NVIDIA CUDA, performance has improved 50-fold.
In 2017, Yunqi Capital led Zilliz's angel round and has continued to invest in multiple subsequent rounds. As a critical middleware layer for large language models, Zilliz has emerged as a standout in the open-source infrastructure software space and has played a significant role in driving continuous innovation in vector database systems.

The GPU acceleration performance gains in Milvus 2.4 are remarkable.
Benchmark tests show that compared to the most advanced CPU-based indexing technology currently on the market, the new GPU-accelerated Milvus delivers up to 50x improvement in vector search performance.
The open-source version of Milvus 2.4 is already available.
For enterprise users looking for a fully managed cloud database service, there's more good news: Zilliz Cloud, the commercial fully managed cloud service based on Milvus, plans to roll out GPU acceleration later this year.

To date, Zilliz has become the world's first vector database company to offer multi-cloud services both domestically and internationally.
Zilliz Cloud has achieved full coverage across 13 nodes on 5 major global clouds — Alibaba Cloud, Tencent Cloud, AWS, Google Cloud, and Microsoft Cloud. Beyond its 5 domestic service regions in Hangzhou, Beijing, and Shenzhen, 8 nodes are distributed overseas, including Virginia and Oregon in the US, Frankfurt in Germany, and Singapore.
1. What is Milvus?
Milvus is an open-source vector database system designed for large-scale vector similarity search and AI application development. Originally initiated by Zilliz, it was open-sourced in 2019 and graduated from the Linux Foundation in 2020.
Since its launch, Milvus has gained significant traction and widespread adoption in the AI developer community.
On GitHub, Milvus has garnered over 26,000 stars and more than 260 contributors, with over 20 million global downloads and installations, making it one of the most widely used vector databases worldwide.
Currently, Milvus has been adopted by more than 5,000 enterprises, serving industries including AIGC, e-commerce, media, finance, telecommunications, and healthcare.

Partial list of Milvus enterprise users (Source: Milvus official website)
2. Why GPU Acceleration?
In today's data-driven era, rapidly and accurately retrieving massive amounts of unstructured data is critical for supporting cutting-edge AI applications. Whether it's generative AI, similarity search, recommendation engines, or virtual drug discovery, vector databases have become core technology for these advanced applications.
However, the demands of real-time indexing and high throughput continue to challenge traditional CPU-based solutions.
Real-Time Indexing
Vector databases typically need to continuously and rapidly ingest and index new vector data. The ability to index in real time is essential for keeping the database synchronized with the latest data, avoiding bottlenecks or backlogs.
High Throughput
Many applications using vector databases — such as recommendation systems, semantic search engines, and anomaly detection — require real-time or near-real-time query processing. High throughput ensures that vector databases can handle large volumes of concurrent queries, delivering high-performance service to end users.
The core operations of vector databases include similarity computation and matrix operations, which are highly parallelizable and computationally intensive. With their thousands of cores and powerful parallel processing capabilities, GPUs have become the ideal choice for accelerating these operations.
3. Technical Architecture
To address these challenges, NVIDIA developed CAGRA. This is a GPU-accelerated framework that leverages GPU high-performance capabilities to deliver high throughput for vector database workloads.
Let's examine how CAGRA integrates with the Milvus system.
Designed for cloud-native environments, Milvus adopts a modular architecture that divides the system into multiple components handling client requests, data processing, and vector data storage and retrieval.
Thanks to this modular design, Milvus can easily update or upgrade specific modules without changing interfaces between them, making the integration of GPU acceleration straightforward and feasible.
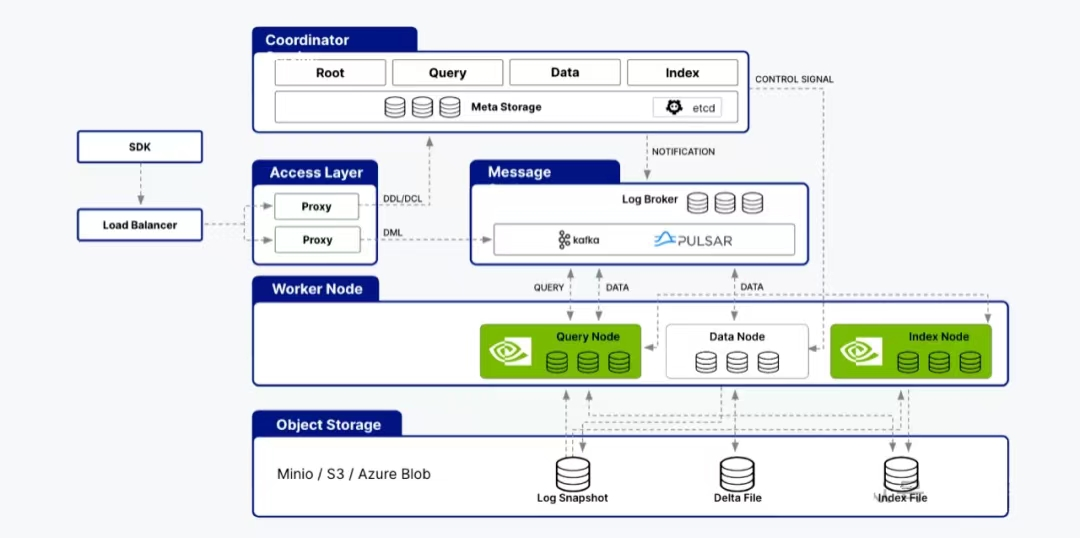
Milvus 2.4 architecture diagram
The Milvus 2.4 architecture includes coordinators, access layers, message queues, worker nodes, and storage layers. Worker nodes are further divided into data nodes, query nodes, and index nodes. Index nodes are responsible for building indexes, while query nodes handle query execution.
To fully leverage GPU acceleration capabilities, CAGRA is integrated into both Milvus's index nodes and query nodes. This integration allows compute-intensive tasks such as index building and query processing to be offloaded to GPUs, harnessing their parallel processing power.
In Milvus's index nodes, CAGRA is integrated into the index building algorithm, using GPU hardware to efficiently build and manage high-dimensional vector indexes, significantly reducing the time and resources required to index large-scale vector datasets.
Similarly, in Milvus's query nodes, CAGRA is used to accelerate complex vector similarity queries. With GPU processing power, Milvus can perform high-dimensional distance calculations and similarity searches at unprecedented speeds, reducing query response times and improving overall throughput.
4. Performance Benchmarks
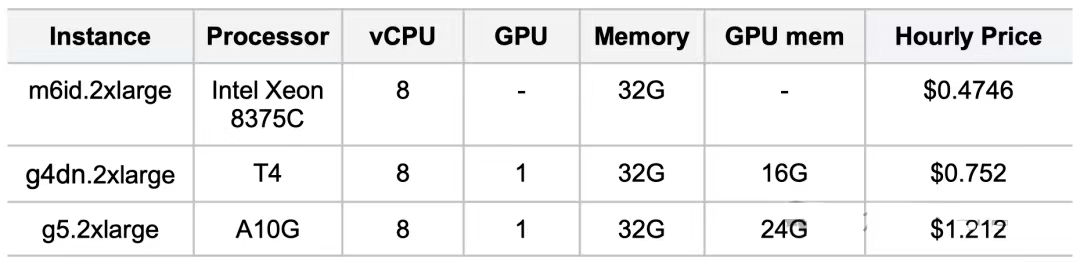
For performance evaluation, we used three publicly available instance types on AWS:
- m6id.2xlarge: CPU instance with Intel Xeon 8375C processor
- g4dn.2xlarge: GPU-accelerated instance with NVIDIA T4 processor
- g5.2xlarge: GPU-accelerated instance with NVIDIA A10G processor
We used these different instance types to evaluate Milvus 2.4's performance and efficiency across various hardware configurations, with m6id.2xlarge serving as the CPU-based performance baseline, and g4dn.2xlarge and g5.2xlarge used to assess GPU acceleration advantages.
AWS-based benchmark environment
For benchmarking, we selected two publicly available vector datasets from VectorDBBench to evaluate Milvus's performance and scalability across different data volumes and vector dimensions:
- OpenAI-500K-1536-dim: 500,000 vectors with 1,536 dimensions, generated by OpenAI language models
- Cohere-1M-768-dim: 1 million vectors with 768 dimensions, generated by Cohere language models
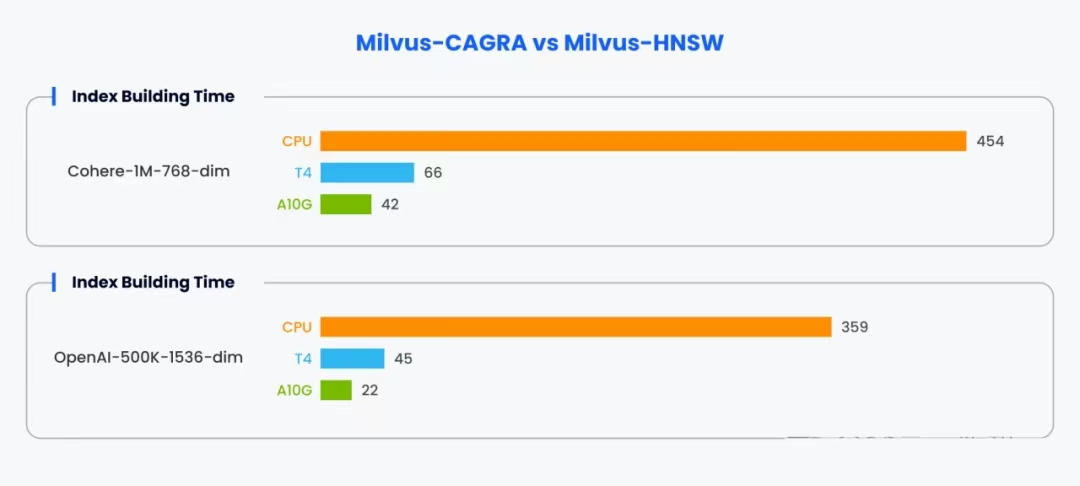
Index Build Time
In index build time benchmarks, we found that for the Cohere-1M-768-dim dataset, CPU-based (HNSW) index building took 454 seconds, while T4 GPU (CAGRA) took only 66 seconds, and A10G GPU (CAGRA) was further reduced to 42 seconds.
For the OpenAI-500K-1536-dim dataset, CPU (HNSW) index building took 359 seconds, T4 GPU (CAGRA) took 45 seconds, and A10G GPU (CAGRA) took just 22 seconds.
Benchmark: Index build time
These results clearly demonstrate that the GPU-accelerated CAGRA framework significantly outperforms CPU-based HNSW for index building, with the A10G GPU being the fastest on both datasets.
Compared to the CPU implementation, CAGRA's GPU acceleration reduces index build time by an order of magnitude, showcasing the advantages of leveraging GPU parallelism for compute-intensive vector operations.
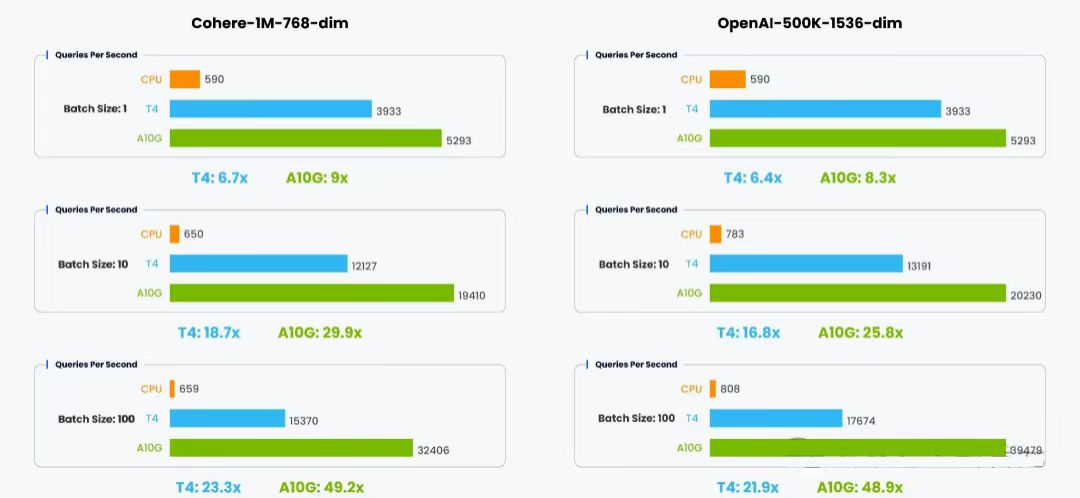
Throughput
For throughput, we compared Milvus with integrated CAGRA GPU acceleration against the standard Milvus implementation using HNSW indexes on CPU. The evaluation metric was queries per second (QPS), measuring query execution throughput.
In different vector database application scenarios, query batch sizes (the number of queries processed in a single batch) vary. During testing, we used three different batch sizes — 1, 10, and 100 — to obtain realistic and comprehensive benchmark results.
Benchmark: Throughput
From the evaluation results, for batch size 1, the T4 GPU was 6.4 to 6.7x faster than CPU, while the A10G GPU was 8.3 to 9x faster.
When batch size increased to 10, performance gains became even more pronounced: the T4 GPU was 16.8 to 18.7x faster, and the A10G GPU was 25.8 to 29.9x faster.
At batch size 100, performance improvements continued to grow: the T4 GPU was 21.9 to 23.3x faster, and the A10G GPU was 48.9 to 49.2x faster.
These results indicate that leveraging GPU acceleration for vector database queries can deliver massive performance improvements, especially for larger batch sizes and higher-dimensional data.
Milvus integrated with CAGRA unlocks GPU parallel processing capabilities, achieving substantial throughput improvements that make it ideal for vector database workloads in mission-critical scenarios demanding peak performance.
5. A New Era
The integration of NVIDIA's CAGRA GPU acceleration framework into Milvus 2.4 marks a major breakthrough in the vector database field.
By harnessing the massive parallel computing power of GPUs, Milvus has achieved unprecedented performance levels in vector indexing and search operations, ushering in a new era of real-time, high-throughput vector data processing.
Five years ago, Zilliz engineers wrote the first line of code in vector database history in a factory building in Shanghai's Caohejing district, embarking on an expedition to develop a new generation of databases for unstructured data management.
Today, Zilliz and NVIDIA's collaboration on Milvus 2.4 demonstrates the power of open innovation and community-driven development, bringing a new era of GPU acceleration to vector databases.
This milestone signals another technological transformation on the horizon: vector databases are poised to experience exponential performance leaps similar to how NVIDIA increased GPU computing power 1,000-fold over the past 8 years.
In the coming decade, we will witness a 1,000-fold leap in vector database performance. This will trigger a paradigm shift in data processing, redefining our ability to process and leverage unstructured data.
References:
https://github.com/rapidsai/raft
https://github.com/zilliztech/VectorDBBench





