When a Billion AIs Simulate the Future Together: The New Bet Fei-Fei Li and Karpathy Are Both Making | 5Y Research

When One Billion AIs Simulate the Future Together: A New $1 Billion Series A Track, Co-Bet by Fei-Fei Li and Karpathy
In this research piece, we're trying to map out an AI frontier that I find deeply fascinating but am still learning to understand — Multi-Agent simulation for prediction.
I remember when the "Stanford Town" paper came out in 2023, I specifically went to Michael S. Bernstein, Joon Sung Park's advisor, to pick his brain. He shared a number of striking findings. But tokens were so expensive back then that it could only be treated as an academic experiment.
After that conversation, I was so captivated that I built a simulation environment myself. I used Habitat, a 3D simulation platform from Meta, designed a living room scene — sofa, TV — and gave the characters Friends backstories to see what they'd do.
What I really wanted to test was: Can AI simulate human drama? The emotional ups and downs, the suspicion, the probing between people — that kind of social reasoning where "I pull out a knife without moving it, and you're already thinking about running." And interesting things did happen. Two virtual characters started chatting, proactively turned on the TV, and then one of them actually asked the other: "Do you ever feel like we're being simulated?" The other replied: "No way." That moment felt surreal.
Of course, looking at this direction today, "world simulators" aim to model far more than drama — group decision-making, information propagation, emotional contagion, social emergence. But back in 2023, that small experiment gave me firsthand conviction: this is doable. AI can genuinely capture the irrational, subtle dimensions of human nature.
In today's landscape of world models, there's actually a missing piece. We've poured enormous research into embodied world models; in biology there are virtual cells, which are essentially world models at that level. But what is the "world model" for human social organization?
What world models do has never changed: predict how a system will evolve when perturbed. In reinforcement learning terms, it's "roll out" — unfold the future many times inside the model, see which path yields better outcomes, then distill the good experience back into optimal practice. This is already happening in physics and biology, but in social science, we're just getting started.
That's why Multi-Agent simulation for prediction deserves serious attention right now. It's not just a faster research tool. It may be our first real opportunity to build a repeatable "world model" for human society.
Our understanding of this direction is still developing. This piece is more about organizing the clues we've gathered so far, hoping to spark broader conversation. We've been exploring a number of AI frontiers this year and will gradually share them as research pieces. If you have deeper thoughts on any of these directions, we'd love to exchange ideas — we're always online.
— Xing Meng (Partner, 5Y Capital)
When Donald Trump survived an assassination attempt during the 2024 U.S. election, a swarm of "virtual AI voters" inside the system of a startup called Aaru rapidly swung toward him. But hours later, as more information about the gunman emerged, many of those virtual voters changed their minds and drifted back to the Democrats. In this system, there were no phone pollsters, no traditional focus groups — just thousands of AI agents configured to "think and be influenced by information like real voters," living in a virtual world, experiencing the same news cycle as us in real time, running through one simulation after another in 30 to 90 seconds.
Aaru's bet is that the most valuable predictions of the future won't come from painstakingly surveying what real people think, but from first building a "digital society" that changes, propagates, and influences itself — rehearsing it thousands of times, then seeing where the highest-probability outcome leads.
In early 2026, Aaru closed its Series A at a $1 billion valuation. Its clients include McDonald's, EY, Bayer, and the film studio A24. An EY executive called it: "A strategic weapon."
In Silicon Valley today, a phrase is catching on: Simulation is the next frontier of AI.
Beyond young radicals like Aaru, another more academically grounded approach is also taking shape. Simile, born from the "Stanford Town" project and spun out of Stanford's computer science department, raised $100 million in Series A funding. Its individual investor list features two prominent names: Fei-Fei Li and Andrej Karpathy.
Andrej Karpathy, assessing Simile, said: The essential form of a pretrained large language model is a "simulation engine" trained on the text of a highly diverse population on the internet — so why simulate only one "person" and not try to simulate a group?

Simile's goal is to first create AI agents that can faithfully represent real individuals, then have them interact with one another — ultimately turning corporate research, earnings call rehearsals, election polling, and even larger-scale social forecasting into repeatable computer experiments.
That's why calling this emerging trend merely "AI prediction" is already somewhat insufficient. The more accurate term might be Multi-Agent simulation for prediction.
From the perspective of an optimistic investor, we think what this track is selling isn't even "prediction" — it's "wholesale regret medicine." In the real world, making one mistake can be costly; in a digital world, making a thousand mistakes might cost no more than a meal. If this logic holds, it doesn't just change the efficiency of one industry — it changes the economics of trial-and-error for human society as a whole.
01 | The "Progress Curve" of AI Prediction Looks a Lot Like DeepMind Cracking Protein Structure in 2018
Over the past two years, AI's performance in prediction has transformed dramatically. In the prediction world, there's an international forecasting tournament called Metaculus, where participants give probabilistic judgments on 60 events spanning geopolitics, sports, technology trends, and more.
Before 2025, no AI had ever placed in such competitions. But 2025 changed that. A London startup named Mantic put its AI prediction engine into the arena and placed 8th out of more than 500 competitors — the best AI result in history. A few months later, in the fall cup, Mantic's model upgraded and climbed further to 4th place.
This progress curve evokes DeepMind's history in the protein structure prediction competition CASP — from an unremarkable early entrant to gradually achieving overwhelming dominance.
And Mantic isn't even taking the Multi-Agent simulation route. Its CEO Toby Shevlane (formerly a research scientist at Google DeepMind) describes its architecture as a kind of "scaffolding": multiple large language models orchestrated into a team, each with a specialty — one focused on election data, one scanning weather information, one processing economic indicators — collaborating to generate a composite prediction. This represents the more straightforward path in AI prediction: rather than simulating population behavior, it has AI directly read and process massive amounts of information to output probabilistic judgments.
This means that as foundation model reasoning capabilities improve, even this relatively direct "multi-LLM orchestration" approach can already achieve stunning progress in top-tier human prediction competitions. And compared to "LLM orchestration," the even more cutting-edge new approach — Multi-Agent simulation for prediction — is developing in a far more radical direction.
Companies like Simile and Aaru represent a methodological shift: instead of "computing" the future, they "simulate" it. They construct miniature societies of thousands of AI agents, endow each agent with personality, memory, and behavioral logic, let them freely interact, evolve, and game-play in a virtual world, then run thousands of "parallel universes" to observe which outcomes emerge with highest probability.
The ultimate ambition of this track: to simulate all of human society.
02 | What Is Multi-Agent Simulation for Prediction?
To understand this space, we first need to distinguish three different levels of "understanding the future."
The first is traditional predictive models: read historical samples, extract features, fit relationships, then extrapolate into the future — essentially finding a pattern in past data and extending it forward.
The first wave of AI prediction from 2022 to 2024 was largely built on this paradigm. Its strength is mathematical clarity and interpretability. Its limitations: limited information dimensions, inability to model interaction effects between people, and a fundamental assumption that while the world is complex, it can still be stably mapped onto an outcome function.
The second is prediction markets: for example, Polymarket, which rose to prominence during the 2024 U.S. election. Prediction markets price future event probabilities with real money. Participants vote with their wallets, and the resulting "wisdom of crowds" is often more accurate than any individual expert.
But prediction markets require sufficient liquidity and participation, and can only answer binary questions like "will it happen" — they struggle to answer "why."
The third, our focus today, is Multi-Agent simulation for prediction. It aims at something different. It doesn't care about single-point mapping; it cares about process generation.
If you place a group of agents with preferences, memories, personalities, information intake paths, and social relationships into an environment, then feed in news, policies, price changes, ad campaigns, competitor moves, even a sudden crisis — how do these agents react? How do they propagate information among themselves? Which emotions spread? Which positions and coalitions form? What macro-level outcomes ultimately emerge?
The seeds of this approach were already visible in the 2023 "Stanford Town" paper: researchers built a pixel-art virtual town, populated it with 25 AI agents, and let them live and spontaneously organize activities — all social behavior emerged naturally.

The original "Stanford Town," source: paper: Stanford University: Generative Agents: Interactive Simulacra of Human Behavior
Over the following two years, the Stanford team pushed this line further toward "real human simulation": expanding from 25 virtual characters to 1,052 digital twins of real individuals. The validation results were striking — these digital twins demonstrated highly realistic behavioral reproduction across multiple social science tests.
So on the surface, this track looks like prediction. But substantively, it's closer to social modeling: taking "how people think," "how people choose," and "how people influence each other" — variables that previously relied on questionnaires, statistics, and expert judgment — and turning them into a system that can be run repeatedly in a machine.
Percy Liang, Simile co-founder and Stanford professor, offers a precise framework for understanding this new paradigm. In the arc of AI development, he argues, we've already lived through the "prediction era" (training general-purpose models to classify text and images) and the "reasoning era" (getting models to solve complex multi-step problems in math, programming, and the like).
But the thorniest problems in the real world — "How would productivity change if our organization allowed remote work?" "How would millions of students respond if we redesigned third-grade math curricula?" "What would happen to hospitals if doctors were evaluated on team outcomes rather than individual performance?"
The answers to these depend on emergent results from many people interacting over time. To answer them, we need to move AI into the simulation era — "What would have happened if we'd made a different choice?"
This is a dimension that traditional prediction models and prediction markets simply cannot reach. So Polymarket is a market-based prediction; Multi-Agent simulation prediction is generative prediction.
Of course, the two aren't mutually exclusive. One very likely future scenario: Multi-Agent simulation prediction generates finer-grained mechanistic insights and conditional distributions, while prediction markets provide final calibration under real capital constraints. One acts like a "scenario engine," the other like a "settlement engine." The former answers "what happens under what conditions"; the latter answers "what probability does the market ultimately converge on."
But the concept of Multi-Agent simulation isn't new — it's been discussed in academia for years. So why is it heating up specifically in 2025 and 2026? The critical variable is compute cost.
Three years ago, million-agent simulation was pure academic fantasy, prohibitively expensive. Today, LLM inference costs have dropped roughly 50x. MIT's AgentTorch achieved 8.4 million agent simulation through prototype clustering, at just $0.10–$0.20 per step. At the current rate of cost decline, it'll drop another order of magnitude in 18 months. So our read on this track's anchor isn't "is it mature enough now?" but "how fast is it maturing?" — after all, the use case that seems implausible today may well be viable next year.
For the future of Multi-Agent simulation prediction, here's an imprecise but vivid analogy: this is fundamentally a new cognitive tool. Previously, humans understood the future through either equations (weather forecasting, financial models) or by asking people (surveys, interviews, focus groups). Equations can't handle human irrationality and "contagion"; asking people misses the second-order effects of group interaction — like how a rumor spreads from three people to three million.
For the first time, this offers a possibility: let millions of AIs with memory, personality, and social capacity evolve autonomously in a virtual environment, then observe the results from a god's-eye view. This isn't an upgrade to existing tools — it's a new category, something like the telescope to astronomy or the microscope to biology. Of course, when the telescope was first invented, it too was dismissed as a curiosity toy for quite some time.
03. How Big Is the Market? Who's in It?
If you understand this purely as "an AI replacement for market research," you'll underestimate it considerably.
That said, market research may indeed be the first industry to get disrupted. In a 2025 research note, a16z pointed out that global market research spending reaches $140 billion annually — the vast majority of it still going to traditional methods: months-long surveys, expensive focus groups, and consulting reports costing millions of dollars. Traditional labor-intensive consulting giants like Gartner and McKinsey belong to this market.
AI simulation offers companies a faster, cheaper shortcut.
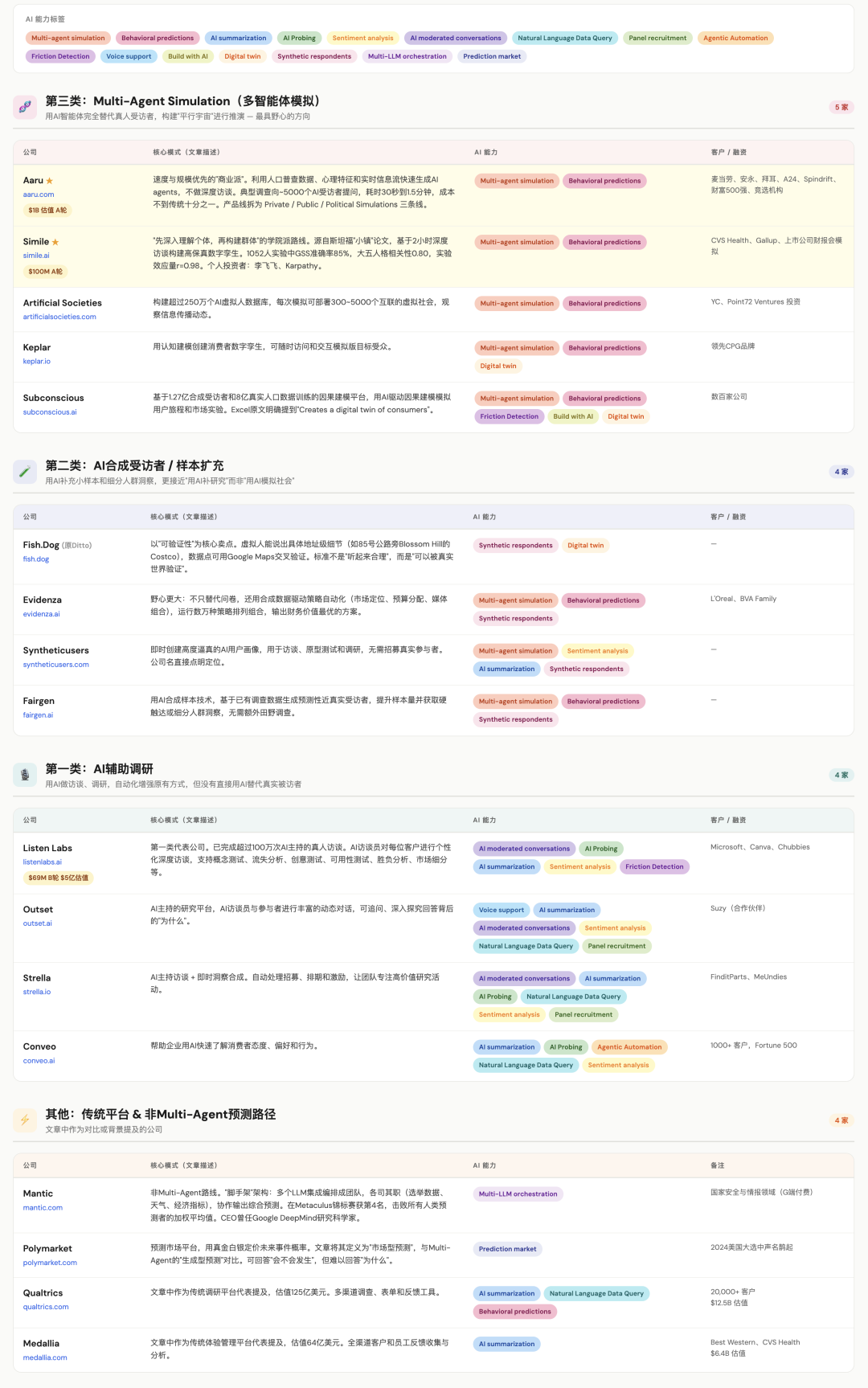
We studied the models of more than 30 startups in this space. Arranged by ambition from smallest to largest, they roughly diverge into three directions:
Data generation: Claude Code
The first category is AI-assisted research. These companies use AI to conduct interviews and research, enhancing traditional methods through automation — but without directly replacing real respondents with AI. The representative company is Listen Labs, which has completed over 1 million AI-moderated interviews with real people, raised a $69 million Series B in January 2026 at a $500 million valuation. Similar directions include Outset, Strella, Conveo, and others.
The second category uses AI-generated synthetic respondents for sample augmentation. AI's role here is mainly to supplement small samples and provide insights on niche demographics. Typical examples include Fish.Dog, Evidenza, Synthetic Users, Fairgen, and others. They're closer to "using AI to augment research" rather than "using AI to simulate society."
Take Fish.Dog (formerly Ditto), which makes "verifiability" its core selling point. In one demonstration, its virtual persona didn't just know "San Jose people shop at Costco" — it could say "I go to the Costco on Blossom Hill off Highway 85, then stop at the Mexican grocery on Monterey Highway for cilantro because the price is better, and the cashier naturally switches to Spanish" — data points you could cross-check on Google Maps. The standard for synthetic research shouldn't be "sounds plausible," but "can be verified against the real world."

Google satellite map verification: inside the California Market on Monterey Highway in San Jose — location and details match the virtual persona's description, countering a common criticism of virtual personas for research: "They're just language models, generating statistically plausible text based on training data, knowing nothing about the real world and unable to provide anything beyond what a generic GPT wrapper could offer." Source: FishDog
Evidenza has bigger ambitions: not just replacing surveys, but using synthetic data to drive strategy automation across market positioning, budget allocation, media mix, and more. Evidenza's ultimate goal is to run tens of thousands of strategic permutations and output the financially optimal solution.
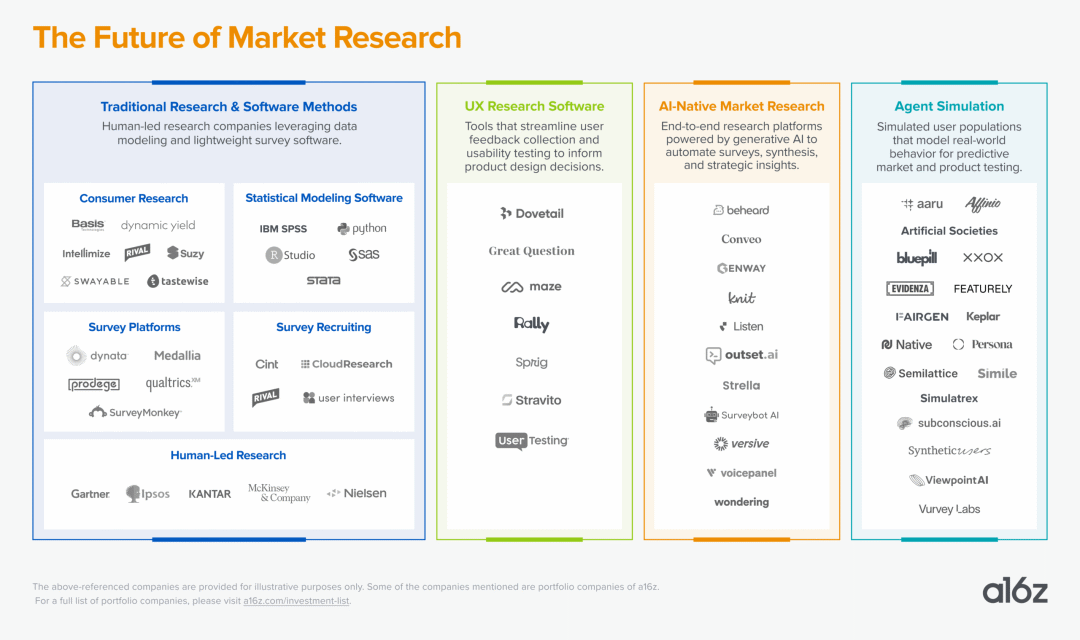
a16z's view of the future market research landscape; source: a16z (2025)
The third category is Multi-Agent Simulation — also the most ambitious. These companies attempt to completely replace real respondents with AI agents.
Representative companies include Aaru, valued at $1 billion (generating agents from public and private data, emphasizing speed and scale); Simile, which raised $100 million (building high-fidelity digital twins from in-depth interviews with real people, emphasizing precision and verifiability); Artificial Societies (building a database of over 2.5 million AI virtual people, deploying 300 to 5,000 interconnected virtual societies per simulation to observe information propagation dynamics, backed by YC and Point72 Ventures); Keplar (creating consumer digital twins through cognitive modeling); Subconscious (a causal modeling platform trained on 127 million synthetic respondents and 800 million real population data points); and more than ten others.
But the potential applications of Multi-Agent simulation prediction extend far beyond market research. Digital marketing and ad effectiveness prediction (global digital ad market exceeds $700 billion), election polling and political consulting, corporate strategic decision-making and scenario planning, financial market sentiment analysis, policy simulation and public administration, and more.
Particularly in national security and intelligence, AI prediction is drawing increasing attention. Top-tier human prediction (such as RAND Corporation outputs) is extraordinarily expensive and slow, while a reliable AI predictor can track hundreds of questions simultaneously and continuously update its judgments. The aforementioned Mantic currently focuses mainly on national security and intelligence, primarily funded by government clients (though Mantic isn't Multi-Agent — it's multi-LLM integrated orchestration).
In short, any scenario requiring understanding and prediction of "collective human behavior" is a potential market for this track — essentially a complete "ex-ante decision infrastructure."
Of course, the market remains full of disagreement, centering on one fundamental question: Can virtual people truly replace real people? Multi-Agent Simulation is the most radical bet; the other two categories take a more gradual route, arguing that AI should augment rather than replace human participation.
This debate is far from settled, but venture capital has already started placing bets.
04. Two Paths: A Deep Read of Simile and Aaru
Currently, the two most heavily funded and highest-profile companies in the market are Simile and Aaru — both commanding lofty valuations and backed by prominent figures.
While both fall under the most central and controversial direction of Multi-Agent Simulation, they represent two distinct technical approaches. Understanding their differences is key to understanding the entire field:
4.1 Simile — The Academic Path of "Understanding Individuals Deeply First, Then Building the Collective"
Simile's story begins with a paper that shook the AI research world in 2023. That year, Stanford University PhD student Joon Sung Park, together with advisors Percy Liang, Michael Bernstein, and others, published Generative Agents: Interactive Simulacra of Human Behavior — the "Stanford Smallville" paper. In this pixel-art virtual town, they placed 25 AI agents, each given a backstory: coffee shop owner, pharmacy clerk, college student. Then the researchers simply watched what would happen.
The results were astonishing. When one agent was set with the goal of "wanting to throw a Valentine's Day party," other agents spontaneously began passing invitations, making new friends, coordinating meetups, and showing up at the right place at the right time. No one had programmed them to do this. All social behavior emerged naturally from the "memory stream–reflection–planning" architecture. The paper won the Best Paper Award at ACM UIST and became one of the most influential achievements in AI agent research.
In November 2024, the team scaled this architecture from 25 virtual characters to 1,052 real individuals. They recruited a demographically representative sample of the United States across age, gender, race, region, education level, and political orientation. Each person underwent a two-hour in-depth voice interview, producing an average of roughly 6,500 words of transcript.
These transcripts were then fed into a large language model to create a "generative agent" for each person — a digital twin capable of thinking and responding like that individual.
The validation results were impressive. On the General Social Survey (GSS), the most widely used survey in the social sciences, these AI agents achieved 85% normalized accuracy in predicting real people's responses. As a control, real people retaking the same questions two weeks later only achieved 81.25% self-consistency.
On the Big Five personality test, normalized correlation reached 0.80. In replications of five classic social science experiments, the correlation between agent and human effect sizes was r = 0.98.
More importantly, agents built from in-depth interviews significantly outperformed those based solely on demographic descriptions or brief character sketches across all dimensions — by 14 to 15 percentage points. This means: the deeper you understand a person, the more realistic the digital twin you create.
From Simile's published papers, the process of building a person (or in trendier terms, distilling a person) essentially draws on four perspectives: psychologist (personality, motivation, self-determination needs), behavioral economist (financial decisions, risk preferences, tradeoffs in life satisfaction), political scientist (ideology, party identification, and the contradictions and hybridity within them), and demographer (occupation, income, family structure, social mobility).
And from the perspective of data richness, three layers of comparative experiments proved the progressive relationship that "deeper understanding yields more accurate digital twins":
Layer 1: Demographic description (shallowest) — only age, gender, race, political orientation. Normalized accuracy: 0.71.
Layer 2: Character description (medium) — participants wrote a self-introduction including personal background, personality, and demographic information. Normalized accuracy: 0.70.
Layer 3: In-depth interview (deepest) — a two-hour semi-structured interview using the American Voices Project interview script, covering: life story (childhood, education, family and relationships, major life events), views on current social issues (race, economy, etc.), and social/political/personal values. Normalized accuracy: 0.85.
In February 2026, this team emerged from stealth and officially launched. CEO Joon Sung Park, Chief Scientist Percy Liang (Associate Professor of Computer Science at Stanford University, originator of the term "foundation model," and founder of Stanford's Center for Research on Foundation Models, CRFM), CPO Michael Bernstein (Associate Professor of Computer Science at Stanford University), plus CCO Lainie Yallen (early employee at Hebbia, who helped grow its revenue 15x) handling commercialization.
Simile's product is already deployed across multiple scenarios. For example, CVS Health, the largest pharmacy chain in the US, is using Simile to build simulations of hundreds of thousands of customers to test new products, new store layouts, and new concepts. With over 9,000 stores, a single bad shelving decision carries enormous costs.

Gallup, the long-established polling organization, is already collaborating with Simile to create digital human replicas. When real human respondents cannot be reached for various reasons, these digital replicas can serve as substitutes.
Another remarkable use case: Simile can also be used to simulate earnings calls for publicly traded companies. You can input all historical earnings call data and build AI agents of the analysts who ask questions, predicting what they will ask on the next call. Simile claims it can predict 8 out of 10 questions on average, and simulate how the CEO and CFO's conversations will unfold under different response strategies — allowing companies to "rehearse" repeatedly before the actual earnings call.
Joon revealed an interesting detail on the TBPN podcast (recently acquired by OpenAI): before his own appearance on the podcast, he used Simile to simulate the directions the host might take with questions, so he could better prepare. "Several of you are quite well-known online," he said, "so we could indeed simulate how your interview would unfold."
This may be the most vivid self-proof that "simulation is everywhere."
Joon Sung Park, co-founder and CEO of Simile; Source: TBPN
4.2 Aaru — The "Commercial Faction" Prioritizing Speed and Scale
If Simile takes the academic path of "understanding individuals deeply first, then building the collective," Aaru has chosen a radically different road: no in-depth interviews, but instead using census data, psychographic data, and real-time information feeds to rapidly generate AI agents.
In the US election polling scenario, for example, Aaru's method works like this: use census data to replicate voters in different districts, then endow each agent with hundreds of personality traits, from personal ambition to family relationships. Then inject real-time information feeds — these agents can continuously "browse" the internet according to the media consumption habits of the humans they replicate, reading which newspapers, visiting which websites, watching which TV stations. This sometimes causes them to shift their preferences.

A typical survey polls roughly 5,000 AI respondents, taking 30 seconds to 1.5 minutes, at less than one-tenth the cost of traditional human surveys.
This speed advantage is extremely attractive in commercial scenarios. When sparkling water brand Spindrift needed to evaluate new product concepts for seltzer, tea, energy drinks, and smoothies, Aaru constructed its target demographic in detail: consumers aged 25 to 35 with household income over $100,000. In less than a week, it selected fruit tea as the best direction.
Spindrift's traditional consumer research reached the same conclusion in two months with 500 people. Spindrift ultimately launched a line of non-carbonated iced tea products.
EY is also experimenting with Aaru for high-net-worth client research. EY's project aimed to replicate a global wealth research report covering 3,600 high-net-worth investors across 30+ markets that had taken a year to complete. Aaru finished in one day, with median correlation exceeding 90%.
More notably, where AI simulation diverged from traditional research, the AI simulation more accurately predicted real behavior. For example, 82% of family heirs in traditional research claimed they would retain their parents' financial advisors, while AI simulation predicted a 43% retention rate. But real-world data showed actual retention was only 20% to 30%.
Humans sometimes lie in surveys, whether intentionally or not — inaccurate memory, or distorted true thoughts under social pressure. This is also the core reason traditional polling institutions have repeatedly failed in recent US elections, and it is precisely Aaru's central value proposition.
Aaru's product line is already extensive, serving not only corporate research but split into three lines: Private, Public, and Political Simulations. Users can configure different news, events, and information environments, then predict how different populations will react under specific conditions. Aaru's clients already include some Fortune 500 companies, campaign organizations, and think tanks.
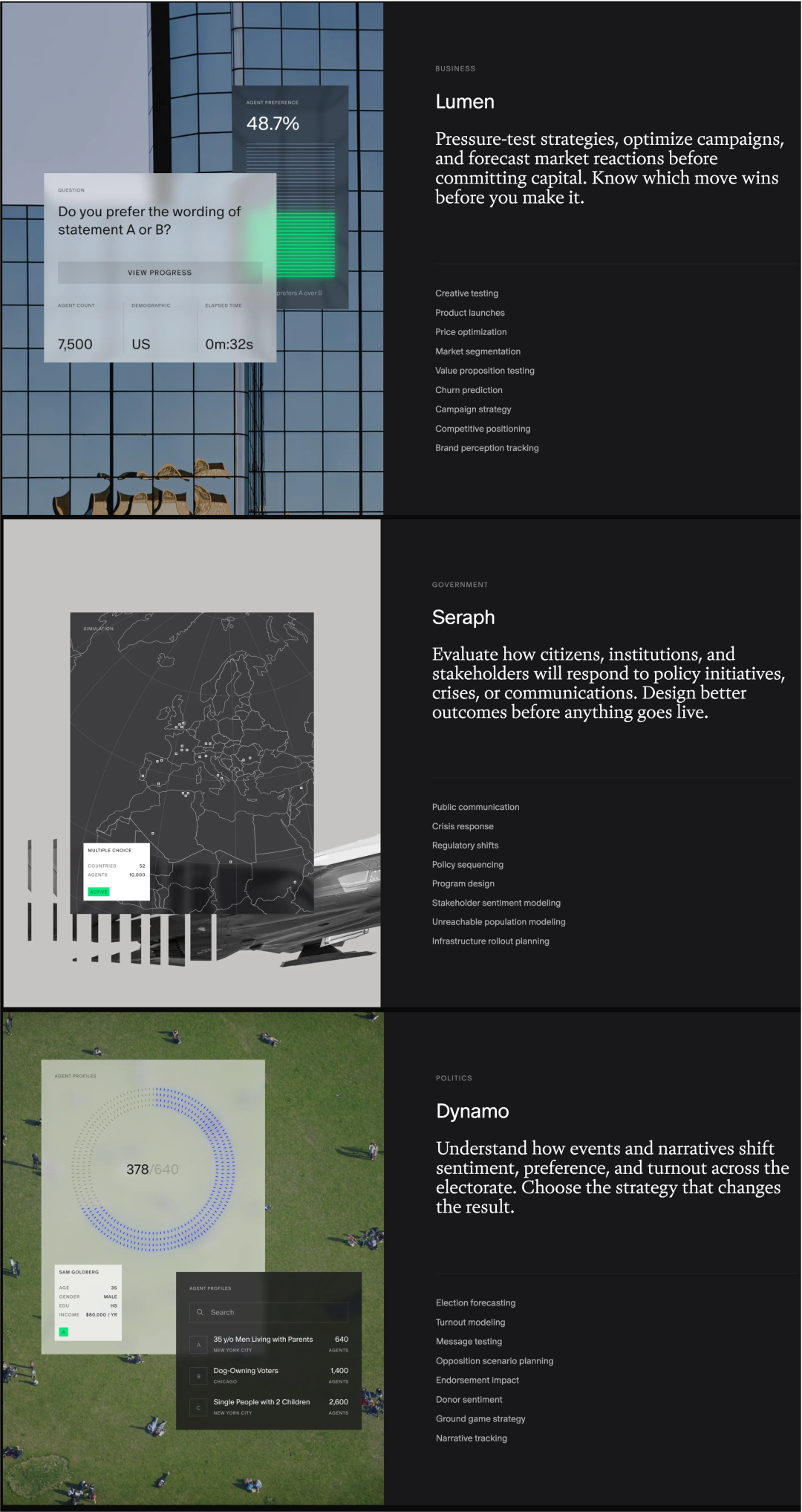
Aaru's three product lines; Source: Aaru
If Aaru's products mature further, their applications would naturally spill over into digital marketing, creative testing, product concept validation, pricing strategy, customer churn prediction, wealth management, earnings call rehearsals, policy simulation, election polling, issue propagation, PR crisis testing, and even broader organizational behavior simulation.
This is what the category is really selling: not "a cheaper survey tool," but "a simulator that lets you run the world once before making a decision."
That said, Aaru hasn't succeeded yet. On the political prediction front, Aaru ran a public test during the 2024 U.S. election. Its predictions for the New York Democratic primary were fairly accurate, but it got the final outcome wrong on whether Trump or Harris would win—though by a somewhat smaller vote-margin error than traditional polling institutions.
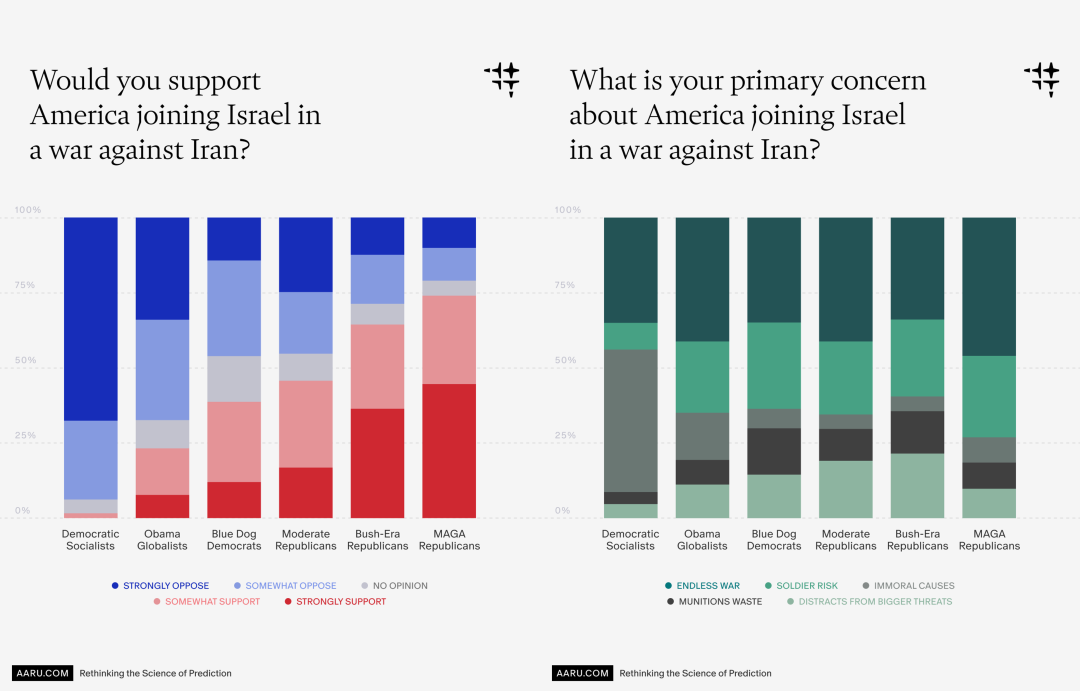
Aaru's latest virtual survey: attitude predictions across U.S. political factions on whether to support American involvement in Israel's war against Iran. Source: Aaru
4.3 The Core Difference Between the Two Paths
The divergence between Simile and Aaru is fundamentally a debate over what data allows AI to truly understand humans.
Simile believes you must conduct in-depth interviews with real people and obtain rich individual-level data to create sufficiently realistic digital twins. Stanford's experiments have provided some evidence that agents built on deep interviews outperform those based solely on demographic and personality data.
Aaru argues that you don't need human participation at all—behavioral outcome data and real-time information flows are sufficient to calibrate models. They call this "ground-truth training," using measurable real-world behavioral outcomes rather than self-reported attitudes as anchors.
When asked about moats in an interview, Simile's co-founder's response revealed how the company understands its own differentiation: they're not building super-rational intelligence, but simulating the "irrational half of the human brain"—values, preferences, tastes.
The direction of large model optimization is to make AI smarter and more rational; Simile's direction is to make AI more human, including human hesitation, contradiction, and irrationality.
My personal take: these two paths will likely converge in three to five years. The logic is straightforward—macro events are ultimately the emergent outcome of countless individual decisions. Simile starts from "precisely understanding the individual" and can theoretically scale up to macro simulation; Aaru starts from "scale and speed" and will eventually need to understand the micro behavioral mechanisms that drive macro outcomes. The only difference is which end you start running from and who gets there first. In a few years, they'll probably collide head-on in the same arena.
05 What Is the Moat?
Though this category is still in early development, we've been thinking hard about what success factors will matter. At least four layers stand out so far.
The first is data moats. Especially for Simile, the key isn't how much public text you have, but whether you have authorized, sustainably updated, behaviorally calibratable deep interviews—plus purchased secondary data, first-hand research data, historical data with real responses, and so on. An asset like CVS Health's 2.9 million answers with over 400,000 real human permissions is a moat that others would struggle to replicate in the near term.
The second is human fidelity. It's not about making an agent sound human, but about having it stably reproduce real individual behavior across surveys, trade-off games, and continuous interactions. The significance of Stanford's 1,052-person experiment is that it established a testable framework for "how digital humans can actually become like humans."
The third is multi-agent system construction. Getting a single agent to output human-like text isn't that hard. The real challenge is running thousands or tens of thousands of agents in the same environment over extended periods without memory explosions, drift, absurd behaviors caused by minor bugs—while maintaining memory, goals, constraints, and relational propagation.
The fourth is the fusion of technology and product. To succeed in this space, you can't just have research breakthroughs; you need to know how to productize and get enterprises to buy. Simile, for instance, repeatedly emphasizes one advantage: their team sits at both the model frontier and the product frontier, and better models directly mean better results.
Not every AI startup can claim this. Simile's team comprises three Stanford AI frontier researchers plus one commercialization operator, backed by prominent individual investors Fei-Fei Li and Andrej Karpathy. By contrast, Aaru's combination is three prodigies under 20 plus industry advisors like renowned pollster Frank Luntz—a "speed + business intuition" style. Which model goes further remains anyone's guess.
The bottleneck we care most about, frankly, isn't technical—it's the validation loop. This category has an awkward property: to verify whether a prediction was accurate, you have to wait for the thing to actually happen. This means feedback cycles are inherently long, and data flywheels spin slowly. What's worse, the real value of this direction lies in predicting things that haven't happened—how society reacts to a new policy, how users choose when a new product launches. For these "things that haven't happened," you can never prove in advance that the simulation was right. So whoever designs a shorter validation loop first gains the leading weapon in this category.
06 Cold Water: Problems and Skepticism
Being broadly bullish doesn't mean ignoring problems. In fact, skepticism around multi-agent simulation and prediction is equally intense—and that's precisely what makes this a fascinating non-consensus bet.
6.1 The Election Prediction Failure—The Most Glaring Stress Test
Before the November 2024 U.S. election, Aaru publicly released predictions for seven swing states, forecasting overall that Harris would win Michigan, Nevada, Pennsylvania, and Wisconsin to secure victory. The actual result: Trump swept all seven swing states. Aaru's predictions were broadly off.
Co-founder Fink defended the results by arguing that AI predictions had lower error rates than traditional polls—though this was partly because traditional polling institutions were even more wrong, while AI was faster and cheaper.
Ashlee Adams, Coca-Cola's Open Innovation Director, also acknowledged that the industry still has reservations about whether this method can provide more accurate insights than real human research.
Of course, this was November 2024, when model technology itself wasn't as mature as it is today. Don't forget how fast large models iterate.
Before the 2024 U.S. election, a paper used GPT-4o (based on the multi-step reasoning framework V3 Pipeline) to predict the election, with the model outputting Trump 268, Harris 259. The model didn't incorporate real-time public sentiment or demographic dynamics, which constituted its main limitation. Although the final outcome was directionally correct, it severely underestimated Trump's margin of victory and showed significant deviation on some key swing states. Overall, the model exhibited a clear systematic bias toward Democrats; the paper also noted GPT-4o's liberal tendency, leading to systematic underestimation of Republican support. Source: USC, Arima, CMU: Will Trump Win in 2024? Predicting the US Presidential Election via Multi-step Reasoning with Large Language Models
6.2 Systematic Critique of Synthetic Samples
The sharpest and most empirically grounded criticism of AI polling comes from polling expert G. Elliott Morris. Morris collaborated with polling firm Verasight on a rigorous benchmark test: creating a "digital twin" for 1,500 real American adults (based on gender, age, race, education, income, state of residence, ideology, and partisanship), then asking the model to answer the same questions as that person would.
The results were sobering.
At the aggregate level, large models' predictions for Trump support and generic congressional ballot deviated from true population proportions by between 4 and 23 percentage points. Even the best-performing model overestimated opposition to Trump. At the demographic subgroup level, errors amplified further: errors for key groups like Black respondents reached as high as 15 percentage points, while Asian and Pacific Islander group errors hit a staggering 30 percentage points.
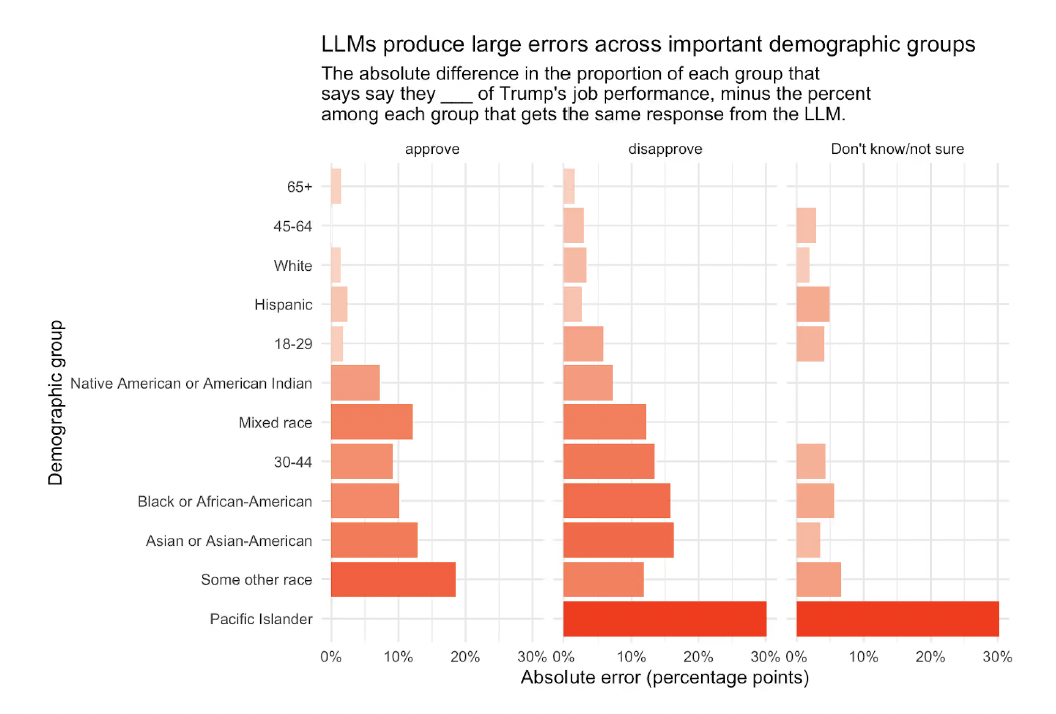
Errors were particularly large for minority groups. Source: Your Polls On ChatGPT, By G. Elliott Morris and the Verasight data team
Moreover, nearly 3% of real respondents selected "don't know" (representing roughly 8 million American adults), but AI models almost never gave this response. And human uncertainty is itself an important component of political attitudes. Morris argues that AI eliminates uncertainty because, fundamentally, it isn't trained to imitate the human brain—it's trained to predict the next word in a text sequence.
So Morris's conclusion is: You can ask a person how they feel about a political question. You cannot do this with a robot.
Here's a counterintuitive point worth making: in agent simulation, smaller models may be more useful than larger ones. Heavily RLHF-aligned large models exhibit a kind of "mode collapse" when simulating human behavior—all agents tend to converge on similar "correct" answers, flattening the natural diversity and irrationality of human populations.
Research suggests that 2 genuinely differentiated agents can outperform 16 homogeneous agents. Smaller, less-aligned models are more easily shaped by different character prompts, producing more realistic behavioral divergence. This implies something important for investors: the technical trajectory of this category may diverge from the mainstream "pursue bigger and stronger models" direction. It doesn't need the smartest models; it needs the most diverse models. In other words, large model companies are unlikely to casually dominate this space—standalone startups have room to survive.
6.3 The Simile Team's Own Cautious Warnings
Worth particular attention is that even the most academically rigorous team in this category is actively calling for caution.
In their paper, Simile's researchers explicitly identify three categories of risk: decision-makers may place misplaced trust in results when simulation fidelity is insufficient; the interview data required to build agents is highly sensitive, and its leakage or tampering could cause severe reputational harm; and a series of ethical gray zones including simulating deceased persons, informed consent management, and agents being used for fraud.
That's why Simile doesn't open its agent library to the public, offering only controlled, research-grade API access. They've also proposed creating an audit log for every agent in their library, allowing individuals who participated in interviews to see what their digital twin is doing and withdraw authorization at any time.
Simile also bluntly advises that we should "carefully scrutinize analyses that overstate AI's current predictive capabilities."
Additionally, a paper from Dartmouth College offers another unsettling perspective: AI can corrupt public opinion surveys at scale. In seven major national polls ahead of the 2024 election, injecting just 10 to 52 fake AI responses — each costing only five cents — could potentially flip the poll's predicted outcome.
This points to an ironic paradox: replacing human research with AI simulation, and AI contaminating human research, are two sides of the same coin.
07. Where Does the Endgame Lead?
In its whitepaper, Aaru writes: "Within two years, we will simulate the entire Earth — from how crops are planted in Ukraine, to how that affects oil production in Iraq, trade through the Strait of Malacca, and the Baltimore mayoral election."
Simile CEO Joon Sung Park was even more direct in an interview: "If we can create a simulation of 8 billion people, the entire Earth, what does that mean? That's the future we're heading toward."
The quote Joon cited from The Matrix's The Oracle perhaps best captures this field's philosophy: "You didn't come here to make the choice. You've already made it. You're here to try to understand why you made it."
The value of simulation lies not only in predicting the future, but in understanding the present: creating traceable, verifiable "logs of social operation" that help us comprehend why complex systems evolve toward certain outcomes.
Of course, for any entrepreneurial team looking to enter this space, we believe the question most worth answering isn't "Can you simulate millions of agents?" but rather "Whose problem are you actually solving?"
Right now, this direction contains two completely different paths: one is the serious tool route (policy simulation, public opinion prediction, enterprise decision support), and the other is the experiential product route (letting ordinary people observe or even participate in the evolution of agent societies). The requirements for teams on these two paths are entirely different — trying to do both will likely result in neither being done well. Historically, the approaches with lasting value have tended to be the tool route (from Bloomberg Terminal to Palantir), but their maturation cycles span more than a decade. The experiential route is easier to break out with, but also easier to burn out quickly.
Moreover, amid all the excitement, a structural chasm is already in plain sight: all current simulations are built on large language models — simulations of human behavior at the text level.
But human society involves vast amounts of physical-level interaction: spatial movement, material consumption, physical contact, environmental constraints. Joon himself acknowledges this: to create a simulation of the entire world, we would need to "model not just people, but the environment and the entire world."
This requires a major breakthrough in "World Models" — AI capable of understanding and simulating causal relationships in the physical world. Yet world models remain in extremely early stages; major labs (from Meta's V-JEPA to Google's Genie) are all exploring them, but they're far from practical use. This means the grand vision of "simulating 8 billion people" still faces a long technical wait.
Today's multi-agent forecasting may be more like the internet of the 1990s: underlying technology is advancing rapidly, real commercial demand exists, early movers are already making money, but the ultimate promise remains distant.
This field's greatest opportunity lies not in perfectly predicting the future, but in rehearsing a thousand times in the digital world before trial-and-error in the real one.
And its greatest risk lies precisely here: as we grow increasingly dependent on "rehearsal" for decision-making, are we better understanding the world — or replacing a window with an exquisite mirror?
*If you're working on a related startup, have published academic research, or are deeply interested in this field, we'd love to hear from you. We're always online:




5Y Capital seeks out, supports, and inspires lonely entrepreneurs, providing everything from spiritual to operational support. We believe that if the you whom others see as crazy begins to be believed in, the world will become a different place.
BEIJING · SHANGHAI · SHENZHEN · HONG KONG
