It's 2026, and we're still evaluating World Models the way Edison tested filaments.

A Serious Discussion on World Models
Last month, 5Hz — the 5Y Signal Station — was still debating what Sora's "death" meant. Today, multimodal has nearly vanished from the AI hype cycle, and World Model has become the most closely watched next frontier: academics are publishing papers at a furious pace, industry is validating on real hardware, and investors are asking the same question: does this track actually have a Scaling Law?
Three "Futures" of World Model — the generation school, the JEPA school, and the spatial intelligence school — are betting on different versions of AGI. Their endgame may be an efficiency competition over compression ratios.
At the second 5Hz event, we brought together researchers and founders from embodied intelligence, autonomous driving, visual representation, Agents, AI infrastructure, and other fields for a deep discussion on how to define World Model, its technical paths, benchmarks, and real-world applications. This article distills that conversation. Sign up for our next session to share your own frontier perspectives.
5Y Signal Station | 5Hz is a small-scale closed-door seminar series initiated by 5Y Capital, focused on the practical application of technology and business. — "See it before consensus forms."
Highlights:
- World Model is not video generation; the core distinction lies in action-conditioned state prediction and multi-step causal reasoning;
- The three technical paths each have strengths and unresolved problems (the generation school lacks logic, JEPA lacks real-world deployment, spatial intelligence lacks time); they may not be competing on the same track at all, but rather betting on different paths to AGI;
- "JEPA is a beautiful dream that everyone believes is correct, but no one can actually build";
- World Model is fundamentally an efficiency competition: whoever achieves higher compression ratios gains the advantage;
- Evaluating world models is an order of magnitude harder than evaluating LLMs; game-like difficulty gradients may be the breakthrough approach;
- Embodied progress is driven by data, not models; Ego-View may be the critical step toward generalization.
Discussants | 5Y Community, ResearchAI+ Community
Compiled by | Yiming Liu
Insight 01
How to Seriously Define World Model
1. The term "world model" is heavily misused in the embodied intelligence field. One fairly strict way to distinguish it is whether it's genuinely action-conditioned: if video prediction is simply used as an auxiliary loss added to action learning — where the model predicts next actions while incidentally predicting upcoming video frames — then the input isn't truly action-conditioned. It's just using video prediction to enhance representational capacity.
A more fundamentalist definition: a world model must accept action inputs — if a robot moves left or up, how does the world change? Or in a game, how do W/A/S/D commands alter the world? Only systems that accept action inputs and predict state changes should be called action-conditioned world models.

2. But rather than arguing over "what exactly is a world model," it's better to answer a more fundamental question first: what do you want a world model to do? The purpose defines the model, which defines the technical path, which ultimately defines the benchmark.
In embodied scenarios, the core pursuit is having a world model that can directly make decisions and act in the physical world. The difference from VLA-style direct-action paradigms is this: before acting, there's an additional layer of imagination about the world — if I move this way, what will change? This multi-step reasoning ability is what truly distinguishes world models from other architectures.
3. World models aren't exclusive to embodied intelligence. Zoom out, and AlphaGo's value network is essentially a world model too — an action comes in, it disturbs the board state, predicts what happens next, and scores it. Virtual cells in biology are world models: administer a drug, what happens at the cellular level? Autonomous driving simulators are world models too — deterministic rather than generative, but still predictions about that world. The only difference is that traditional simulation systems have limited generalization; they can only predict what their designers thought to design in.
Today we want world models that truly capture the world, not ones bounded by their designers' own conceptual limits. From this perspective, world models represent a leap from "deterministic" to "probabilistic" — we want them to model futures that even their creators never anticipated.
4. Ultimately, a rigorous definition of world model can converge to a single formula: a predictor that forecasts the transition from state S to S' conditioned on action.
All remaining disagreements are essentially different answers to three questions: What is state? How is the predictor designed? How is action expressed? State can be pixels, latent representations, 3D geometry, or a set of molecular states in a cell. Action can be robot end-effector pose, keyboard WASD, latent actions, or even natural language instructions.
Different combinations of these three determine different technical paths and application scenarios.
Language models stand on the shoulders of carbon-based life — the abstraction, representation, and understanding that carbon-based life accomplished. If language models are "intelligence after language," then what world models must do is replace the entire living organism in summarizing the signals of sound, light, and electricity in the world.
5. The ultimate form of world model may be a kind of world intelligence: a different type of intelligence from language reasoning, chess, or search. Humans convert touch, hearing, smell, and vision into text; text is a good state for humans, but not necessarily for robots. A system with true world intelligence needs to find better representation spaces for sensory signals — internal abstractions of the world — rather than converting everything to text. This is why representation may be the hardest and most core problem for world models today.
Insight 02
Three Technical Paths, Betting on Different AGIs
6. Current world models can be roughly divided into three technical paths. They rest on different core assumptions, excel at different things, and have different critical vulnerabilities.
- The first school is generative models, represented by Sora and Sora-like systems, including Genie and Decart. This school evolved from Midjourney, Stable Diffusion, and similar image generation products, naturally extending from image to video. But early video generation models were essentially linear extrapolations of images — they might produce a person making slight movements, with beautiful visuals, but lacking long-horizon logic. Their requirements were image quality and aesthetics, text-following ability — completely different demand levels from the abstraction and logic that world models need today. Genie and Decart attempted to incorporate autoregressive components to create second-to-second coherence, but results show that when time scales from seconds to hours, these models remain weak.
- The second school is JEPA (Joint Embedding Predictive Architecture), proposed and championed by Yann LeCun. JEPA's core methodology operates in latent space for compression and abstraction: rather than predicting every pixel, it predicts a higher-level representation, discarding irrelevant noise and retaining only information truly important for understanding world changes. Methodologically, this goal is admirable. But the specific methods — the fusion of contrastive learning and masked modeling — have produced unsatisfying results in practice. Based on how little Meta and LeCun himself have emphasized this specific path recently, they may be reconsidering it internally. LeCun has since left Meta to found AMI Labs, raising $1 billion to pursue scaling in this direction, but results remain to be seen.
- The third school is spatial intelligence, represented by World Labs, starting from 3D geometry. This approach prioritizes XYZ — building three-dimensional spatial modeling first, perhaps adding time T later to become XYZt. But time hasn't been introduced yet, leaving it at the most primitive stage for temporal modeling. Yet world models have an invariant core: they always model transitions over time. Regardless of input format or whether action is input or output, time t is the foundational dimension. Other paths are already working with XYT (video) or XYD (video with depth); World Labs is still at XYZ, so they must figure out how to introduce T. Of course, this school may have deployment advantages — mesh generation, 3D assets — these create value without requiring time.
7. Only the first school has been truly validated in vehicles. The second (JEPA latent rollout) has theoretical upper-hand advantages but hasn't been realized. Under the one-stage end-to-end autonomous driving paradigm, the first path — generative co-training — has been proven to work: during training, video prediction is added as co-training to enhance backbone representational capacity, but at inference, the video generation component is discarded to meet real-time requirements. JEPA's latent rollout theoretically could be superior — if all representations could be rolled out long-horizon in latent space, the potential for long-horizon tasks is enormous. But in practice, no one has achieved results matching or exceeding the first path.
8. One researcher offered a pointed take: "JEPA is a beautiful dream that everyone believes is correct, but no one can actually build." The best recent paper from V-JEPA World Model ultimately only achieved Push-T — a trivial task solvable with an MLP. When the Veo 3 team was asked how they achieved such good results, their answer was just two words: diffusion plus scaling.
Meanwhile, the video generation field itself is undergoing architectural shifts: according to non-public rumors mentioned in the discussion, Veo 3's multimodal joint generation team may have been split and merged into the Omni team, and Sora 2 is publicly experimenting with mixing AR and diffusion. But these are closer to multimodal generation models — still far from true world models.
No matter how exquisite the visuals, it doesn't mean anything. What we really want is: I knock over a cup, it falls on me, I jump and get hurt — so working backward from the result, I shouldn't do such an inconsiderate thing. This long-horizon causal reasoning is the essential dividing line between world models and video generation.
9. Looking at all three paths together, world models are fundamentally an efficiency competition. Suppose we had infinitely large models, infinite data, and all of Earth's electricity to run world models — any path could scale to an invincible world model. But we don't have those resources.
At the robot level, you can deploy at most a 7B model at the edge, with latency requirements of 50-100 milliseconds. Under this constraint, the core architectural question becomes: who achieves higher compression ratios? Who can pack more knowledge about the physical world into fewer parameters and less computation? The path that aligns with the Bitter Lesson will ultimately win this efficiency competition.
World model inference costs are indeed high right now. According to The Information, Odyssey's world model requires a full H200 chip per user, costing several dollars per hour, while running a 70B text model costs only cents per hour. MoE Capital's review similarly notes Genie 3's operating cost at roughly $100/hour. These numbers make "compression ratio" an especially urgent problem.
10. These paths may not be competing in the same arena at all. More likely, they'll differentiate by application scenario: the 3D path may end up building game engines and digital assets; generative models may be better suited for content creation; while robotics scenarios with the strictest physical world requirements may need a special hybrid architecture — say, a 20B encoder plus a 5B predictor.
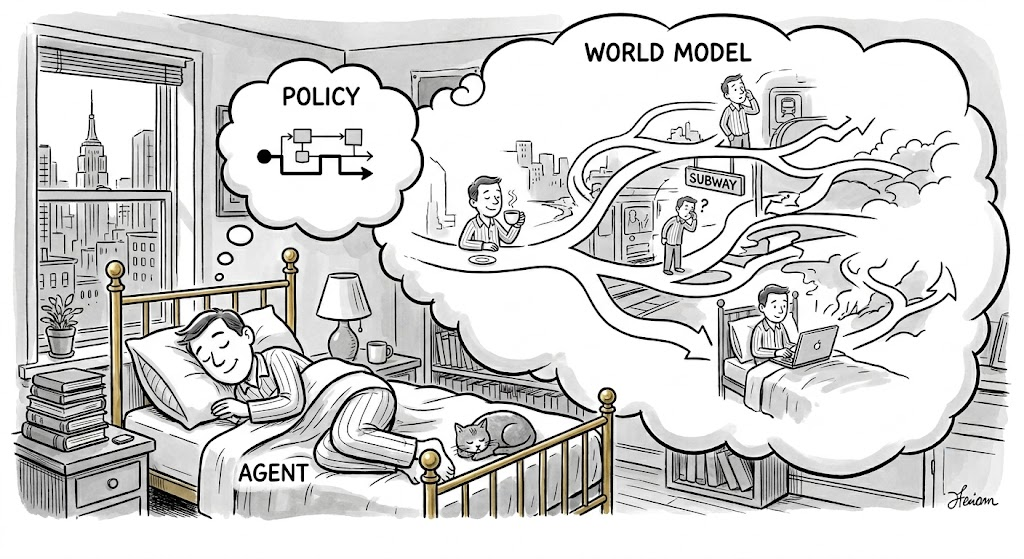
A more fundamental framing: world model is the dream, policy is the strategy, agent is the dreamer. The dreamer acts, the dream responds; the dream responds, the dreamer acts again. And action is the "cheat code" that bypasses traditional simulation computation costs — in conventional engines, simulation cost rises sharply with object count and interaction complexity; the more complex the scene, the slower the engine. But world models absorb the world's operating patterns into their weights during training, making inference a fixed-cost forward pass — no matter how complex the scene, the engine doesn't slow dramatically. (Not Boring × General Intuition, World Models: Computing the Uncomputable)
Insight 03 Benchmark: Why Evaluating World Models Is an Order of Magnitude Harder Than Evaluating LLMs
11. Language model benchmarks are relatively uniform — do next-token prediction well, and few-shot is solved. But world model task forms are inherently more complex: states are multimodal, actions are heterogeneous, and time scales span from milliseconds to minutes. This makes few-shot far harder in world models than in language models, and benchmarks correspondingly more complex.
12. Current embodied benchmarks suffer from two typical problems: either tasks are "anti-human" — like making a robot play soccer with one arm, which reflects no real operational need; or once tasks are designed realistically — like having robots complete long-horizon instructions in home environments — all frontier models achieve success rates of only around 22%, including Dreamer Zero and π0.5. When "everyone is terrible," benchmarks lose their ability to discriminate. A good benchmark (like Mandarin) should bias toward common human operations, neither designing to frustrate robots nor shooting pretty demos with only the simplest pick-and-place tasks.

13. From a technical evaluation perspective, there are three main current approaches to assessing world models, each with its own gap: using VLMs for direct understanding (but VLMs can't observe subtle deformations or delicate physical quantities), using latent-space models like JEPA for latent distance calculation — "surprise values" (but latent representations lack interpretability), and using pixel-level tracking like CoTracker for motion analysis (but heavily compromised by viewpoint changes and lighting). None of these alone suffice; they need to be combined into an agent system for comprehensive evaluation. But such a system doesn't yet exist.
14. Long-horizon rollout without collapse is a critical evaluation dimension. If a world model can sustain minute-level autonomous rollout without collapsing, it can serve as a safe simulation environment, replacing real-world RL. This means running large-scale parallel reinforcement learning inside the world model, trading compute for simulation, just as LLMs do with RL. But this is a chicken-and-egg problem: to prevent collapse, you need massive corner-case data (what happens when a cup falls and shatters, when a table gets smashed) — data extremely rare in normal operations.
Collecting such data may require deploying large numbers of robots to rollout in the real world first, but large-scale deployment isn't commercially viable. In autonomous driving, this long-tail data collection is much easier — mass-produced vehicles are naturally data collectors, and shadow mode is already mature. For humanoid or wheeled robots, this contradiction is hard to resolve in the near term.
One sharp analogy from this discussion: we're trying to scale to AGI-level super-intelligence, but we're evaluating it with Edison's lightbulb methodology from 300 years ago — trying a different filament each day, for three years, until finally discovering tungsten is best. Training models really comes down to three things: what is the data, what model to build, and finally how to benchmark. And benchmark efficacy directly determines the ceiling on iteration speed.
15. One possible breakthrough approach is gamified benchmarks. Puzzle games naturally have mathematical difficulty gradients — maze complexity rises exponentially with level, Tower of Hanoi can scale to 5 layers, 10 layers, 100 million layers, giving you infinite OOD (out-of-distribution) samples. This design doesn't depend on accuracy rates (you don't need 99.9% success to benchmark a model); instead, capability is measured by "how many levels can you clear" — like the role math problems play for language models: a golden playground with natural gradients. If world model benchmarks could shift from accuracy to level-clearing capability measurement, model iteration efficiency would accelerate dramatically.
16. From a test-time scaling perspective, do world models have the "think longer, do better" property that language models exhibit with o1? The intuition suggests yes: give models more test-time compute, like rolling out 100 times and selecting the best result, and quality should improve. Experiments have confirmed this: using video generation models plus multimodal LLMs to generate 100 times and pick the best does improve results. But the critical bottleneck is the critic model: after test-time scaling, how do you judge which rollout is best? The prerequisite isn't mature yet — we can generate a person walking calmly for 10 minutes, but can't yet generate a person encountering unexpected situations on the road and producing a cascade of reactive changes.
17. However, from an embodied perspective, a form of implicit test-time scaling is already happening. Robots have a fundamentally different property from language models: whether your action output at any step is right or wrong, the real world returns an observation that is necessarily true (because you have cameras). This means all history stored in the robot's context consists of things that actually happened in this world.
Models with memory/history can leverage this to supplement partial observation information. A classic example: opening a refrigerator. A memory-less VLA will try the right door every time, because it doesn't know it already tried and failed. But with history, the model knows "the right door didn't open," and tries the left. This process of exploring to supplement information is essentially test-time scaling — you spend more time exploring, but you solve the partial observation problem. Often what VLAs can't do isn't due to insufficient model capability, but insufficient information. Memory-based architectures are becoming a key paradigm to address this.
Insight 04 Data, Not Models, Drives Embodied Progress
18. What would it take to end the debate about world models? One fairly clear answer: true zero-shot or few-shot robotics. Today, all systems claiming to be "general robot models" are likely overfit: to complete a specific task on a specific body, you need data specific to that body and scenario. If someday a completely new body arrives, and the model can automatically infer how to operate it and complete unseen tasks from just a few demonstrations — that would be robotics' GPT-3 moment. GPT-3's paper title was "Language Models as Few-Shot Learners" — no retraining, no fine-tuning, direct few-shot on unseen tasks. This was language models' critical capability leap.
In world models today, some few-shot properties have been observed, but the tasks these few-shot properties cover may not yet be the most valuable ones. And world model few-shot is inherently harder than language model few-shot: language models have only one task form — text — so next-token prediction suffices; world models must simultaneously generalize to predicting next state, predicting next action, and various state-action combinations — inherently more complex task forms.
19. Reviewing embodied intelligence's progress history, every leap has been driven by data, not models. From teleoperation-collected data training large behavior models, to RT-X and similar projects aggregating multi-morphology robot data, to Physical Intelligence's large-scale real-world data collection driving π0.5, to body-agnostic collection methods like UMI increasing data volume 10-100x, to the rise of Ego-View heterogeneous data — NVIDIA's EgoScale and similar work validated critical scaling laws, proving that first-person human activity data can massively expand embodied data volume. Behind every leap was a data paradigm breakthrough, not model architecture innovation.
20. Ego-View may be the critical step toward true generalization, possibly the only viable path. The logic is simple: treat humans as another type of robot, put sensors on people, and collect large-scale data of humans interacting with the physical world in real environments. But the largest current Ego-View dataset is only around 100,000 hours — far from millions, tens of millions, or hundreds of millions of hours. If Ego-View doesn't work, it's hard to imagine what other path embodied intelligence could take to true generalization.
LeCun once pointed out a similar paradox: our AI is already as smart as a lawyer who passed the bar exam in some directions, but it can't do what a cat can do. Language model success was built on carbon-based life having already completed the task of "abstraction," while world models must learn the physical world's operating patterns from scratch — a far more difficult task.
21. A watershed moment for world models probably won't arrive this year. Heterogeneous data collection still needs time, and diversity matters more than quantity — simply scaling volume without scene and human pattern diversity has limited meaning. But the trend is positive: beyond VLA, robotics is seeing more technical paths to choose from, and world model is one of them. When different paths differentiate across scenarios and each finds its place, this seemingly vague concept of "world model" will finally land as a concrete, iterable set of engineering practices with Scaling Laws.
22. At the discussion's end, someone posed a Cixin Liu "seeking truth at dawn"-style question: if God could answer one question for you, what would you most want to know? Some wanted to know whether world models can truly reflect physical interactions — if you grasp objects of different softness with different forces, can it predict the corresponding deformation? If not, compared to traditional physics engines doing simulation, which is closer to real physics? Others wanted to know whether scaling Ego-View data to hundreds of millions of hours would truly elicit generalization in embodied systems, and if this path fails, perhaps no other path remains.
"If 'God' could answer one question for you, what would you most want to know?" — this question itself is the best footnote to this discussion. World models have no standard answers today.
We're still several orders of magnitude of data, several orders of magnitude of compression ratio, and several paradigm-level breakthroughs we can't yet imagine away from having machines truly understand the world. But at least, there's more than one path forward.


5Y Capital seeks out, supports, and inspires lonely entrepreneurs, providing support from spiritual to all operational aspects. We believe that if the "crazy you" in others' eyes begins to be believed in, the world will become a different place.
BEIJING · SHANGHAI · SHENZHEN · HONG KONG
