How to Tackle Management Challenges in the Startup Journey? | 5Y View

The road ahead is shrouded in fog, and complexity never stems from a single cause.

In a startup's journey, scaling is a phase that's both exhilarating and full of challenges. As the organization grows, founders and teams face a whole new set of management problems.
Building a company is hard. The path forward is foggy, it can stretch on for years, and complexity rarely stems from a single cause. This article explores common pitfalls startups encounter as they grow, offering practical strategies and insights — hope you find something useful here :)
Reposted from 36Kr's "Shen Yi Bureau" (Divine Translation Bureau)
Author: Jason Cohen
Translator: Boxi

Idealistic founders believe that even as they get big, they'll still be able to break the rules. They won't become one of those "typical big companies."
What they mean: no dumb rules that assume employees are stupid or evil, nothing takes ten times longer than it should, no endless meetings, and no hiring of "average" or "normal" people.
In other words, the startup's existing processes have served them well so far, and by tweaking these processes, they hope to preserve the positive traits of a small organization while avoiding the common problems of large ones. We'll keep doing the same things, just with more people, and as always, we'll figure it out as we go.
But why do they never succeed? Why can't these smart, well-intentioned founders run a 500-person organization the way they ran a 50-person one? What are these inevitable forces of scale?
Are they truly inevitable?
The Two Fundamental Challenges of Scale
Once we understand these two primary drivers, we can see how they explain challenges that crop up in every corner of the business.
Rare Events Become Common
As scale increases, rare events become common. Rare events are hard to predict and usually hard to prevent. Before scaling, these were so infrequent that they barely mattered — but when they start happening daily, the need for new processes becomes glaring.
For example, with 1,000 servers, a failure rate of once every three years per server translates to one failure every single day. Customers are impacted and complaining daily. Even though each individual event is rare, you can't predict or prevent it. Automation helps, but doesn't solve the problem.
This math is inescapable — no one in the industry can avoid it.
Complexity Exceeds Human Comprehension
The human mind has limited computational capacity. Beyond a certain point, a system simply cannot be fully understood.
"Complicated" systems can be understood. These are intricate, but they exhibit properties that let you tame the beast. Components of complicated systems can be isolated, developed and tested independently, then assembled; thus, divide-and-conquer is a useful technique here. The challenge is difficult but solvable, especially if you've faced similar challenges before; therefore, "experts" (in the sense of specialists) can crack it. Repeatable processes can monitor the system.
"Complex" systems have components that interact with each other, often in cyclical ways. So while developing and testing components independently remains useful, the interactions between components are still complex. In fact, most of the difficulty lies in these interactions. The human brain is made of relatively understandable neuron "components"; yet it is precisely through complex, multidirectional, cyclical interactions that everything interesting and difficult to understand emerges. Large-scale effects like "consciousness" are completely beyond our understanding because they arise from complexity we don't yet comprehend.
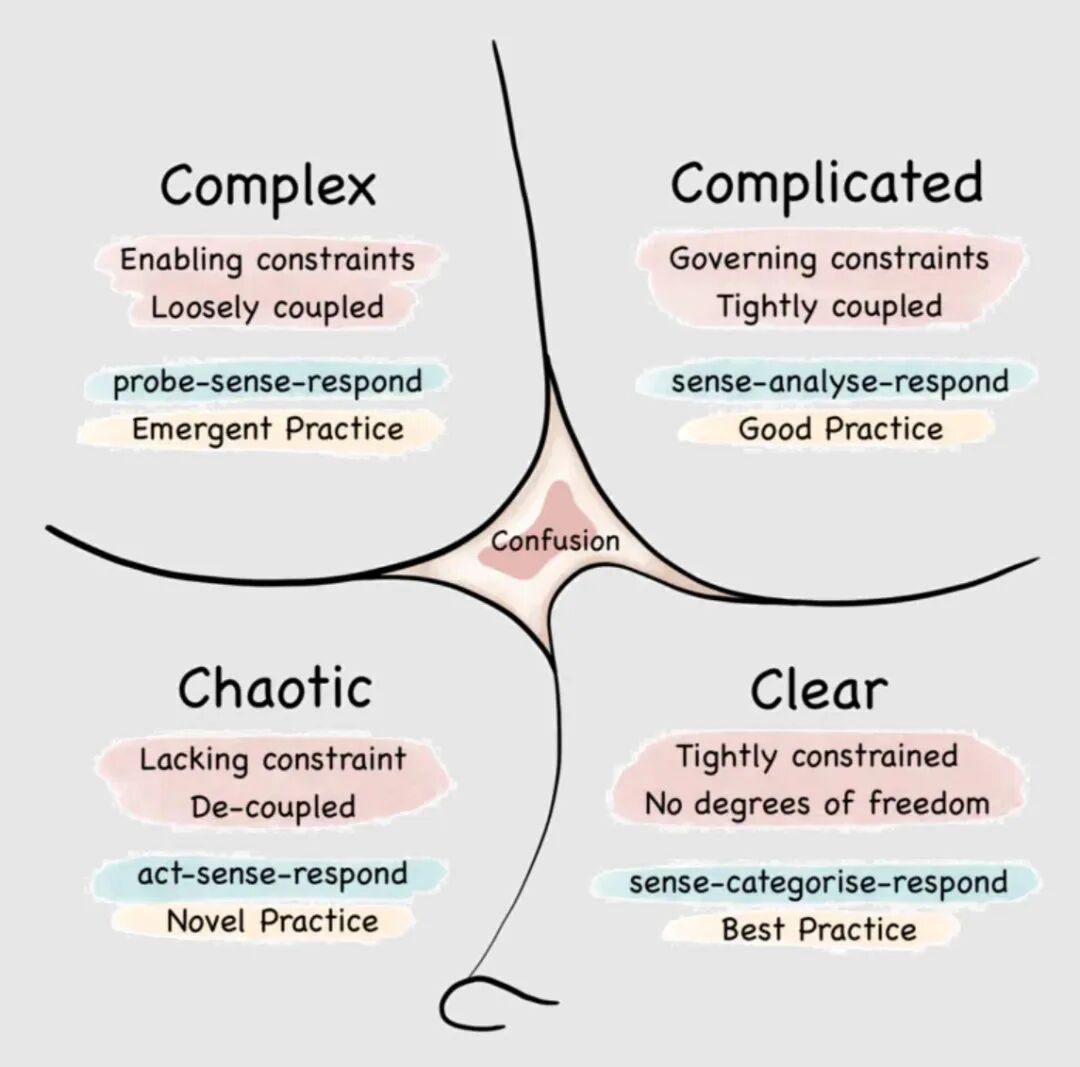
This terminology comes from the Cynefin framework for decision-making.
As companies grow, various systems exist, but fundamentally complex systems are difficult — and that difficulty never changes. As organizations expand, the challenges they face grow nonlinearly. Even our own unimaginably complex human brains cannot fully comprehend these systems.
With these two foundational principles in mind, let's examine the specific challenges of scaling in detail.
The Human Cost of Resilient Teams
Measured by "output per person," a one-person team is the fastest, most efficient team possible. No communication, no meetings, decisions made instantly. Small companies must operate this way, and it works. It's a major reason they're nimble and, as people like to say, "punch above their weight."
But illness means product velocity or customer service quality plummets. For a small team, losing one person costs you six months of progress to rehire and ramp up. Or, with no processes or documentation, you fall twelve months behind or have to rewrite everything entirely... because with one person, you didn't need those things — after all, we move fast, and there's no one to communicate with.
Or it could be fatal, because the person who left was a co-founder. "Founder disaster" is a leading cause of startup death (note: though data also shows that single-founder companies are more likely to fail. So which is better? To me, it depends on the person — some genuinely want to go it alone, while others want to share the burden).
In other words, a one-person team moves fast but is fragile. When small, trading stability for speed is a good bargain, because speed is critical for overcoming the factors that constantly threaten to kill the company — lack of customers, lack of market attention, lack of core features, and so on. At scale, with annual employee turnover of 15-25%, not to mention illness, vacations, and family issues taking people out of commission, someone is leaving (temporarily or permanently) every single day — rare events become commonplace. Maintaining the same attitude as when you were small is disorganized and irresponsible; the company simply won't function.
Therefore, once at scale, no project can have fewer than three dedicated people, plus management, and likely some form of product or project management. But a 4-5 person team won't be 4-5x as productive as a solo operator; per-person productivity drops, but resilience and continuity increase. On the flip side, where a small company might lose nine months or even implode from losing one key employee, a large company is like the tortoise — slow, but adding thousands of customers like clockwork every month, ultimately winning the race.
The High Cost of Resilient Systems
You might think software systems wouldn't be as fragile as human systems, since we have automation and DevOps and such. Unfortunately, robust software costs more and is more complex too.
Consider how to serve a website (don't worry, you don't need to be a software engineer to follow this example). Say you have an internet connection, a server running your website software, and a database storing your content. We have one server, and most of the time it works. Let's assume it's up 99.9% of the time — sounds pretty good, right?
Not really. A 0.1% failure rate means over 500 minutes of downtime per year — unacceptable. This happens because rare events (0.1% failure rate) become common (at 1,000 servers, roughly 500,000 minutes of downtime per year).
What if we deploy two servers? Then when one fails, the other is still available. The site only goes down if both fail simultaneously, which happens with probability 0.1% × 0.1% = 0.0001%, or about 30 seconds per year — so that's great (note: sadly, this isn't how the world actually works. Failures are usually correlated or cascading. For illustration purposes, we'll keep it simple, but this complexity itself proves the point).
Okay, now it costs twice as much, because there are two servers, but the increased robustness makes it worthwhile (note: you might think you could save money by buying cheaper servers, since each only needs half the capacity. But you can't, because in failure mode, one server still needs to handle all traffic, so each must be powerful enough to work alone.) But wait — this still isn't enough, because traffic from the internet needs to be distributed across both servers, and you need some intelligence to route traffic to healthy servers so that if one fails, it doesn't keep receiving requests. This is called a "load balancer," every cloud infrastructure provider has one, and it costs more. So now we have another component to manage, generating more expense.
Wait, we haven't talked about the database. Both servers need to share a common content database, so that database needs to move to its own server. What if that server fails? Then we're down again. So the database server also needs redundancy.
Now we have four servers plus a load balancer, costing more than 4x the original. Robustness can be bought, but it's far more expensive than you'd think. We haven't even accounted for the fact that managing multiple servers is harder, or that communication between servers can fail, or that the load balancer itself could fail and take down the entire system (note: yes, there's a solution for this too — more redundancy at the network layer, typically from different providers, but again, more cost, more complexity) — all of which reduce our robustness and require more effort to achieve.
Robustness always comes at a price. Whether it's running four servers instead of one, or operating a four-person team instead of going solo, you're trading local inefficiency for organizational continuity.
Predictability
When you're small, there's no need to predict when features will ship. Marketing doesn't schedule launches, and recruiting doesn't set start dates for the next 50 customer service and sales hires. This means you can and should optimize for getting products to market faster, even if it's shortsighted.
Small companies constantly tout their speed as an advantage, and it is — but it's easy to see how a large company's advantage is different: massive execution leverage. Sure, when our company launches a new product, marketing needs to predict the release date, but that's because this team is skilled, well-funded, and coordinated, so we can coordinate press releases, events, marketing, social media, newsletters, and more, generating in one week more attention than a small company could attract in a year. We have global sales and support teams, so we immediately sell to 200,000 existing customers and thousands of new ones every month, meaning our monthly revenue additions exceed what a small company earns in a year.
But all this requires predictability. Without it, we can't schedule media, prepare sales materials, train hundreds of support reps, or ensure code quality is high enough to scale from day one. Predictability requires slowing down. Predictability requires estimation (takes time), coordination (takes time), planning (takes time), documentation (takes time), and adjusting all teams' plans when reality inevitably deviates from predictions (takes time).
When you hire many people, you need predictability. Consider the timeline for adding a technical support team member. First, recruiting sources candidates. Then interviews are scheduled and conducted. Then you wait for them to quit their job and take a week off. Then there's onboarding. From deciding to expand support to having a fully ramped person takes four to six months.
So we must predict support needs four to six months in advance, because we need to hire to meet that demand. If we underestimate, our support staff is overwhelmed with too much work; their quality of life suffers, and service to every customer degrades. If we overestimate, we hire too many people, creating a cost penalty. Of course, both are failure modes, and the latter is preferable, but neither is optimal — and the solution is predictability.
Inspired by lean and agile thinking and the facts, small companies insist: "The future is fundamentally unpredictable." Indeed, blue-sky invention and execution are unpredictable. But this is also a self-fulfilling prophecy. Insisting the future is unpredictable leads to neglecting the work that could make it more predictable, which actually makes the future unpredictable for that person.
Small companies lack the data, customers, institutional knowledge, expertise, and often the personal experience and skill to predict the future, so they're usually right that they can't predict it. But is this impossible in principle, or impossible for them? As companies scale, predictability becomes essential. Not because Wall Street demands it, not because investors demand it, not because of any other excuse given by unpredictable organizations, but because it's critical for healthy scaling.
Materiality Threshold
If Google launches a new product generating $10 million in annual revenue, is that good? No, that's a failure. They could have taken the tens of millions in product development costs and improved existing operational efficiency by 0.01%, earning far more.
With over $100 billion in annual revenue (in fact, Google's 2023 revenue approached $300 billion), Google can only view products with potential for $1 billion in annual revenue as the absolute floor, with upside potential to $10 billion per year if things go well. YouTube, Cloud, and self-driving cars fall into this category.
This principle is called the "materiality threshold" — the minimum contribution a project must make to have a material impact on the business.
For small businesses, the materiality threshold is approximately $0. A new feature that helps attract some customers this month is worth trying. A marketing campaign that increases sign-ups by two per week is a success. Almost anything you do matters. This is great — the feeling of constant forward momentum is wonderful.
The financial success of large companies dictates that the materiality threshold cannot be trivial. This is hard. Even a mid-sized company needs new products generating millions in revenue, optimistically perhaps tens of millions. Few products create revenue at this scale, whether built by agile, innovative startups or steady, mature companies. As evidence, consider that the vast majority of startups never reach $10 million in annual revenue, even with good products and highly dedicated, capable teams.
Yet this is the job of a product manager at a mid-sized company: to invent, discover, design, implement, and nurture such products — something most entrepreneurs never succeed at. The task is formidable.
Talent Acquisition
Employee #2 joins a startup for the experience. Even with a significant pay cut, even if the company fails (the most likely outcome), it's worth it for the story, the impact, the potential, the excitement, the sense of control, the camaraderie, and the cocktail party conversation.
Employee #200 doesn't join for these reasons. Employee #200 has a different risk profile for life and career. Employee #200 is interested in solving different types of problems — like those listed in this article — not in figuring out why the next three people didn't buy after the first seven did. Employee #200 won't work for you if you pay below market.
Small companies treat this as an advantage, and recruiting great talent below market rate is certainly beneficial. But today our hundreds of employees are far more skilled in their specialties than people I've encountered at small startups (including my own). Why?
One reason is that people with substantial experience are often at a different life stage, where family and other needs mean they want predictable, well-defined work with predictable, higher pay. When you combine their advanced skills with the raw materials of a scaled company — customers, brand, capital, teams capable of executing bigger ideas — they can create enormous value while still being home to tuck their kids in at night.
Another reason is that after developing expertise in certain areas, they find joy in applying their skills in larger contexts. For example, some advanced marketing techniques would never work for small companies but are interesting, challenging, and revenue-impacting for large ones. Some talented people love this challenge. This affects many things: compensation, how to find talent, and why this person wants to work at your company rather than the one next door willing to pay a bit more. Therefore, it's critical to have a genuinely important mission, with meaningful and interesting work to do, connecting each person's work to something greater than any of us. These factors become more important at scale, because this is why talent joins and stays.
Communication
If a company has four people, any information everyone needs to know is simply told to the other three. Everyone can know everything. If there's a 5% chance of significant misunderstanding, it doesn't happen often.
If a company has four hundred people, reliably communicating a message to everyone in a short time is impossible. A 5% misunderstanding rate means 20 people are confused. This assumes they read what was communicated, or listened to the entire presentation on Zoom. What's the probability of that? Don't ask.
"Slack" is not the answer. "Email" is not the answer. The answer is: repeat simple messages constantly.
"Repetition" is the answer to "I didn't see it." Many leaders repeat things at different times in different forms. Gradually push communication coverage toward 100%, though this creates collateral damage among those who actually read and listened to everything — they're tired of hearing the same thing and wonder why they're punished for being the ones who actually pay attention.
"Simplicity" is the answer to "I don't understand / I don't remember." As with strategic simplicity, you must accept that some people won't read, some won't remember, some will be thinking about other things, some may not comprehend language as well as you'd hope, and what you wrote may not be as clear as you intended.
But does this mean you can't communicate complex things clearly to 1,000 people? Yes, that's exactly what it means. Communication at scale is hard.
Technology and Infrastructure
In the cloud era, managing 10,000 virtual servers sounds easy. Automate everything, and any process that works for 100 servers can work for 10,000 by repeating the same operations — which is what computers are good at.
It never works this way. One problem is bottlenecks. All hardware and software systems have them. At small scale, you don't hit bottlenecks, or can solve them with simple techniques like adding capacity. Eventually, you hit hard limits that require architectural redesign.
Another is Hickam's Dictum (the counter to Occam's Razor): complex system problems rarely have a single root cause. Consider a software upgrade that causes problems for seven customers but goes undetected. What's the "root cause"?
- We didn't detect the bug; if we had, we'd roll back the upgrade immediately.
- We didn't test the failing part; if we'd tested more, this never would have reached customers.
- We didn't document the problematic code well; if the code were clearer, humans wouldn't have made coding errors.
- Our code review was wrong; if we'd used the right checklist to review the code, we'd have caught the error before deployment.
Like "Five Whys," there's always a deeper cause, and different causes. Unlike "Five Whys," there isn't one "root" cause — many things interact with many other things. This doesn't mean it's hopeless, just that analysis is complex, deciding what to do is complex, and Occam's Razor doesn't apply.
All of this slows development and increases investment. Entire teams must be dedicated to infrastructure, scaling, deployment, cost management, development processes — none of which are directly customer-visible or customer-driven, but are necessary for managing the complexity of scale.
Big Companies Aren't Just Small Companies × 100
These forces make large companies fundamentally different from small ones. This is neither good nor bad. It's something else.
Some idealistic founders believe the root cause of scaling problems is "command and control" organizational structures. But none of the examples above mention any organizational structure. These are universal phenomena, independent of org charts. Trying new organizational structures may be a fine idea, but these fundamental forces won't be eliminated by rearranging roles and power structures.
Scaling is hard. The path forward is foggy and winding, stretching over years. The people you need may be different. No one emerges unscathed. So if you find wrestling with these forces difficult, it's not a sign of disaster. Everyone finds it equally hard.
When is it a disaster? When a company is scaling, but its leaders don't understand these fundamental forces, don't continuously work to adapt the organization as circumstances change, don't bring in experienced talent, and believe they can solve everything without help — that's when disaster strikes. Instead, scaling should mean new people, new roles, new values, new processes, new hiring, new stories, new constraints, new opportunities.
Too many founders and leaders want to believe:
We got here because we're important, we're special, and therefore we should preserve everything. Other companies failed because they "acted like big companies," but we'll avoid all that because we're smarter than them. As evidence of our acuity, simply look at our success to date. Going forward, it'll be more of the same, victory after victory.
They're wrong. Some values should indeed persist. Otherwise none of this means anything. But the details must change.
Many founders and leaders can't make this transition. It hurts the company, sometimes kills it. The horror stories are legion. It's tragic, because this waste of opportunity, sometimes the loss of hundreds of person-years of effort, could have been avoided.
Don't be one of those cautionary tales.




5Y Capital seeks out, supports, and inspires lone entrepreneurs, providing support from spiritual to all operational aspects. We believe that if the "crazy" you in others' eyes begins to be believed in, the world will become a different place.
BEIJING · SHANGHAI · SHENZHEN · HONG KONG
