5Y View | Predictive Biology: AI-Driven Biology's New Paradigm from "Reductionism" to "Emergence"

Predicting a system's future state is, in itself, understanding the system.

Recommended by

Yunfeng Shi, Executive Director at 5Y Capital
"Predicting the future state of a system is itself understanding the system."
Today's article comes from Jacob Kimmel's personal blog, Creode. Jacob is the co-founder and chief scientist of NewLimit, a biotech company dedicated to developing epigenetic reprogramming therapeutics for aging. He was previously a principal scientist at Calico, an anti-aging biotech company backed by Google. His research has consistently focused on the intersection of molecular biology and computer science.
In this piece, he introduces a concept that defines what "AI-driven life science research" looks like today: Predictive Biology. Several core ideas: 1) New biological research is driven by machine learning and AI; 2) Predicting a system is understanding it, rather than obsessing over constructing causal diagrams; 3) An epistemology of emergence rather than reductionism; 4) This new paradigm of biological research will emerge from industry/for-profit companies rather than non-profits and academia.
A startup currently embodying the Predictive Biology paradigm — or what might be called "TechBio" — is NVIDIA-backed Recursion. Their compute center, model stack, and automated labs have been focused on generating massive amounts of biological and chemical data, exceeding 50 PB, encompassing various multi-omics data, toxins, pathogens, genetic variants, and how candidate drug molecules affect and interact with single-cell phenotypic omics data. In short, they're betting on collecting and producing vast, multi-dimensional data, letting AI handle inference and prediction, while human scientists provide oversight and tackle what machines can't do well.

Two other representatives of the "Predictive Biology" paradigm are Arc Institute and FutureHouse, both new research institutions founded in the past two years, corresponding to this new biological paradigm.
We can imagine biology as a massive maze, most of it pitch black. Traditionally, scientists have held candles, then flashlights, groping step by step at symbols on the walls (molecular functions and partial instruction manuals for living systems). Predictive biologists possess a dynamic map (an AI model) that can predict where the next corner lies based on paths already taken, and deduce where hidden shortcuts and mechanisms lurk throughout the maze — even if they've never walked there. The maze changes dynamically (though in the dark, we couldn't see this before), and this new map updates along with those changes. The future is certainly bright, but we must endure the biting cold of dawn. Life science needs such new tools to unlock biotechnology's truly unlimited potential, rather than getting stuck in various "local minima." But professionals on the front lines should understand the bitter truth in this meme. If a new technology can easily produce pleasing results and is easily "pushable," that means it's still circling within the old system.
So perhaps "Deductive Biology" is a more accurate name than Predictive Biology for the present moment (because I'm thinking about the distinction between "deduction" and "inference"), since relying on AI capabilities alone cannot yet achieve "predicting" biology. Deep learning still needs to converge with genuine physics simulation and better experimental architectures — a collaboration between virtual and physical realms.
Predictive Biology
An emergent epistemology
Author: Jacob Kimmel
Editor: Fan Yang
Publication Date: August 30, 2024
Long read alert: Predictive Biology is an emerging paradigm in life science at the intersection of molecular biology and machine learning. Predictive Biology focuses on measuring mutual information between biological entities and argues that predicting the outcome of an unknown experiment is equivalent to understanding a system. The field's new tools have unlocked previously intractable questions and led to the formation of new institutions. Unlike previous paradigms in life science research, for-profit companies may lead the frontier of this new domain.
Calling someone a biologist doesn't actually tell you very much about their skills, daily work, or epistemic principles. Are they a biologist who studies the migration patterns of African elephants during the dry season, or a biologist who studies the structural basis for regulation of TGF-beta ligand activity in a dark crystallography room?
Over the past century, biology has gradually differentiated into multiple branches addressing different problems, much as physics and chemistry did during their development. Many of these branches have become sufficiently independent to form their own bodies of knowledge. They not only concern themselves with different questions, but approach problems using different cognitive tools. If you call someone a molecular biologist, this implies not only that they possess the technical skills to manipulate nucleic acids, but also that they tend toward a bottoms-up, reductionist approach to epistemology.
Horace Freeland Judson, the historian of molecular biology, precisely captured these cultural and intellectual divisions:
Fields are often born at the confluence of two ancestral disciplines. Molecular Biology emerged from physics and biochemistry; Systems Biology arose from the combination of genomics and statistical mechanics.
Here, I propose that Predictive Biology is a new field that has emerged in the last five years with roots in molecular biology and machine learning.
Predictive Biology focuses on inferring the outcomes of future experiments using quantitative models trained on a corpus of past data. In this framework, Predictive Biologists implicitly assume that biological systems contain substantial mutual information, such that the current and future state of one system (a cell's shape) can be predicted from the description of another (a cell's gene expression profile).
If Molecular Biology is often reductionist, Predictive Biology is emergent, arguing that many complex biological phenomena cannot be explained in isolation from the interactions of multiple components.
If Systems Biology argues that mapping the individual interactions within a system will yield understanding, Predictive Biology counters that predicting the future state of a system is understanding. Where Molecular Biology was enabled by nucleic acid biochemistry and Systems Biology by early computers, Predictive Biology is built on artificial intelligence tools that learn to explain biology from data.
Predictive Biology is not superior or inferior to its predecessors, but it is distinct. These distinctions have enabled scientists to ask new questions, build new institutions, and found new companies. Perhaps for the first time in the history of biology, a frontier field may be dominated primarily by for-profit ventures rather than traditional academic institutions.
I believe these methods will shape the future of biology, and so it is worth examining Predictive Biology's origins, research directions, and open questions in depth.
Epistemic lineage

Summary of disciplines that gave rise to Predictive Biology, read from left to right
Molecular Biology & the beginning of modernity
The roots of modern biomedicine can be traced to the intersection of chemistry and physiology that gave rise to biochemistry. Biochemistry was perhaps the first subfield dedicated to the study of living systems as complex but fundamentally physical entities, rather than "vital" elements with a wholly different set of governing principles. Beginning in the 1930s, molecular biology emerged from biochemistry as an independent discipline. Today, the trajectory of nearly every modern biotech company can be traced, in some way, back to molecular biology.
Molecular biology has always been difficult to pin down. Francis Crick, co-discoverer of the structure of DNA, once quipped:
The definition of molecular biology is: anything that excites Nature is molecular biology.
But he also offered a more precise definition:
The central task of molecular biology is to discover the molecular and chemical explanations of living systems.
At its core, molecular biology explains living systems through a fundamentally reductionist approach. The questions researchers asked typically revolved around the function of individual molecules, and which molecules determined a given biological process.
Implicit in this mode of inquiry was a central assumption — most molecules have a small number of functions, and most functions are controlled by a small number of molecules. For the reductionist approach to succeed, this assumption had to hold at least some of the time.
Though this approach may seem overly simplistic, the breakthroughs it enabled were staggering! It successfully explained the molecular mechanism of heredity and information transfer, the Central Dogma: DNA replication, transcription, translation. Likewise, much of what we know about cell communication, organismal development, and pathobiology was derived by picking a molecule, breaking it, and interpreting its role based on what happened.
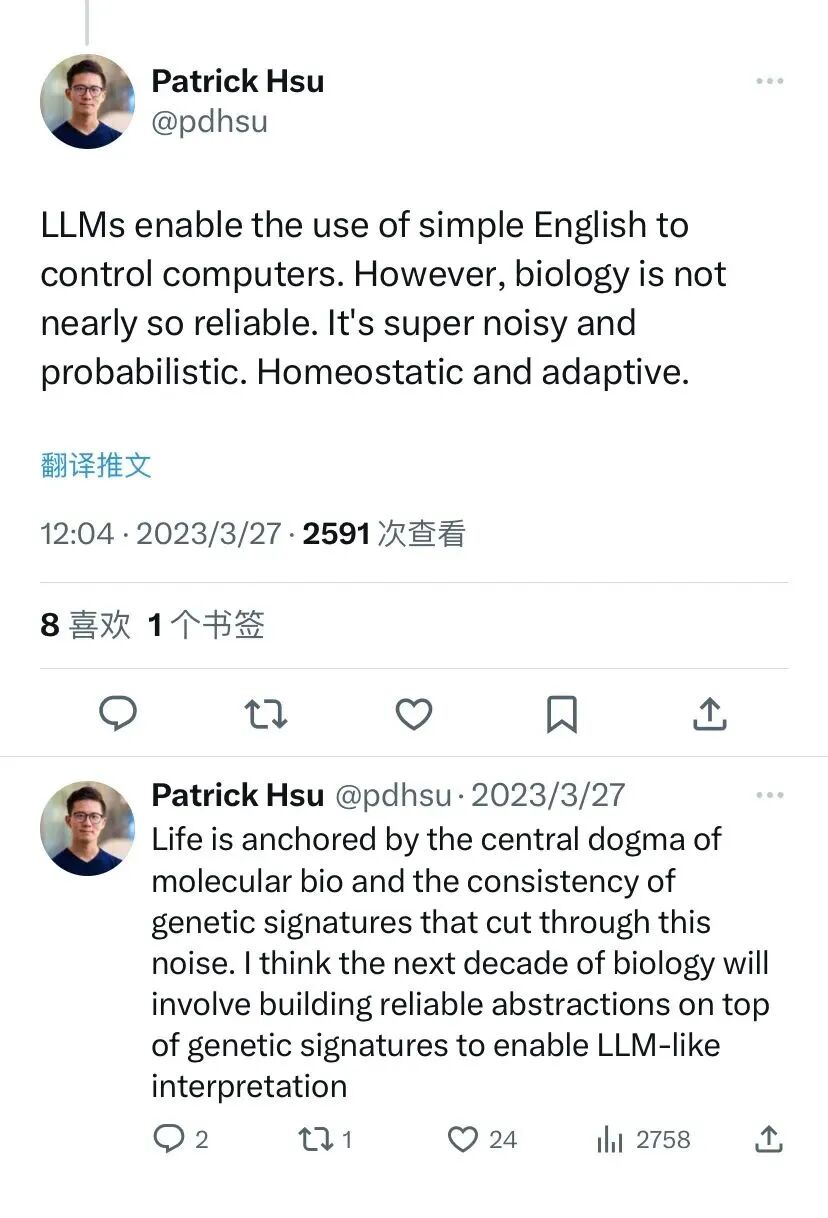
Molecular Biology favored the reductionist approach as much by necessity as from a desire for epistemic parsimony. After all, in its early days, molecular biology's technical toolkit was extremely limited. Isolating even a single protein from the "cellular soup" of life was a formidable challenge!
Sequencing a gene or protein was once a multi-year endeavor, sufficient for a doctoral thesis. Interrogating the interactions of many genes or their products was intractable. Even if these interactions could be measured, interpreting their meaning remained a formidable challenge. Biologists typically relied on the "eyeball test" to observe binary phenotypes, or performed manual calculations with pen and paper. Advances in both measurement and computation enabled a new generation of biologists to begin probing at the phenomena that resist explanation by a handful of molecules.
Systems Biology & the limits of reductionism
Systems biology attempts to understand the behavior of complex biological systems, rather than the function of individual molecules.
— Leroy Hood
Systems biology is the study of all the elements in a system, not just one element.
— Sydney Brenner
Systems biology may be even harder to define than molecular biology. Historically, there has been considerable tension between the two fields, and Sydney Brenner himself was known to level some criticism at early systems biologists.
The greatest distinction from its predecessor is that systems biology focuses on the emergent properties of complex biological systems, which cannot be captured by reductionist experimental methods. Human biology provides a compelling case for why this approach is necessary.
Our bodies are extraordinarily complex, yet humans have only about 20,000 genes. The basic concept of one gene, one function falls apart when you realize there are far, far more functions than there are discrete genes! Clearly, there are interactions among these molecules whose effects are far greater than the sum of their parts.
Until the mid-1990s, biologists were largely forced to ignore these interactions. Even if you wanted to explore the nonlinear logic of how genes X, Y, and Z interact, the available tools offered no effective way to do so. Automated DNA sequencing and synthesis technologies drove the development of systems biology, providing the first tools capable of measuring many molecules simultaneously. Genomic, transcriptomic, and proteomic tools of this era enabled researchers to measure the sequences and abundance of all the genes in an organism simultaneously.
Systems biologists try to understand systems by taking these unbiased data and building minimal models of a behavior of interest. If we assume we're studying the cell cycle, systems biologists might create a differential equation incorporating the abundances of many cell cycle genes to explain cell behavior. For these models, simplicity and parsimony are often more important than predictive performance. Systems biologists want to learn the mechanism of a complex process in terms of simple rules that can be written down on a napkin.
One way to frame the long-term direction of the field is in terms of a causal graph. If we imagine all the nodes in a graph as biological molecules, systems biologists hope to measure and annotate all of the edges between nodes. By quantifying all these connections, systems biologists hope that one day we'll be able to design systems from scratch in a sister field known as synthetic biology.
Predictive Biology & embracing emergence
Unfortunately, the tools of systems biology failed to scale beyond simple interactions among a few molecules. In practice, it was difficult to predict complex cellular behaviors like development, immunity, or drug responses with differential equations at a precision that was meaningfully useful. Noble in theory, in practice biologists struggled to build large enough sets of simple rules at the microscopic level to explain dramatic, macroscopic biology.
Predictive Biology defines prediction as the core task of a biological study, rather than cataloging the functions and relationships of molecules. Implicitly, both molecular biology and systems biology attempted to move from these cataloging principles toward predictive tasks. If we know what a gene does and how it relates to other genes, the hope was that we could infer what would happen if we activated or inhibited it. Predictive biologists are willing to eschew the intermediary catalogs in pursuit of the understanding that arises from predictive power.
In other words, predictive biologists are more concerned with measuring the mutual information between two biological phenomena than they are with measuring direct causality. Molecular biology drew inspiration from the epistemology of classical physics, while Predictive Biology borrows cognitive tools from computer science and information theory.
Editor's note: Mutual information (MI) is a concept from information theory used to measure the mutual dependence between two random variables. It quantifies the "amount of information" obtained about one variable by observing the other. Simply put, mutual information is a tool for measuring how strongly two things are related — if the relationship is strong, the value is large; if there's little connection, the value is small. It's more powerful than simple correlation because it can capture more complex relationships, allowing you to predict one phenomenon from another even when they appear to have no direct connection.

The implementation of this approach became possible with the emergence of modern machine learning (ML) methods. Until roughly the 1990s, learning models from large, complex datasets remained practically challenging. Thanks to computing power driven by Moore's Law and algorithmic improvements, well-performing models became more available during this period.
The first generation of these models enabled researchers to extract more insights from emerging high-throughput experiments, but in most cases, they could not predict experimental outcomes from input data alone. Early DNA sequence models helped researchers search for and align similar sequences, but could not predict the effects of previously unobserved mutations. Simple gene expression models could infer cell type or cancer outcomes, but could not predict how inhibiting a particular gene would affect cellular function.
If machine learning had existed since the 1990s, why did Predictive Biology only rise in the last decade? Early computational constraints prevented models from capturing sufficient biological context, whether from long DNA sequences or high-resolution microscopy images. Without this context, models could only make relatively local predictions, limiting their application to biology's most complex problems.
Classical biochemistry offers an analogy. Linus Pauling and Max Perutz solved biochemical structures using precise, physical models of the underlying atoms. These tools could reveal secondary structures like protein alpha-helices and the DNA double helix, but could not predict the more complex tertiary structures of proteins, which required simulating physical properties at larger scales.
Around the 2010s, deep representation learning tools powered by GPU computing broke through the second barrier. Now, researchers could learn models that capture rich input context — such as long sequences of the code of life, thousands of expression profiles and covariates of paired drug treatments, and images capturing hundreds of cells across a half-dozen different phenotypic dimensions.
By capturing more detailed portraits of biological systems, second-generation predictive biology models enable in silico hypothesis testing. In addition to extracting more insights from experiments in the world of atoms, these models allow researchers to perform many experiments in the world of bits.
These capabilities have changed not only the questions predictive biologists explore, but also the experimental methods they use to render new truths from a range of latent possibilities.
Further reading: Models of Life | Asimov Press Exclusive
Unlocking larger questions
Biology is full of hypothesis spaces that are too large to ever search exhaustively. For example, testing the enhancer activity (the ability to promote gene expression) of all possible 100bp DNA sequences would require 4^100 ≈ 10^60 experiments. Simply testing all combinations of perturbing just 2 genes in a simple cell line would require (20,000 choose 2) ≈ 10^8 experiments.
Traditional tools in molecular and cell biology are insufficient to explore all these possibilities — the gap is many orders of magnitude. Simple-sounding questions like "What is the strongest possible enhancer?" or "Which genes are essential for cell division?" turn out to be surprisingly difficult to solve.
Molecular biology and its direct descendants made progress against these daunting numbers through local search. Because hypothesis spaces are too vast to exhaustively search, researchers use their intuitions and prior knowledge to guess at which hypotheses are the most fruitful to test.
Naturally, this leads researchers to explore hypotheses that are in an abstract sense "close" to our existing knowledge. Perhaps we cannot test the enhancer activity of every 100bp DNA sequence, but if we know a few strong enhancers of roughly that length, a clever molecular biologist might try testing mutants derived from these promising starting points, with a reasonable chance of success.
The very best researchers have a taste that allows them to guess correctly which hypotheses will be fruitful further away from our prior knowledge. I was trained in this tradition: a researcher's analytical abilities do not improve beyond a certain point of proficiency; they simply get better at choosing which hypotheses to test. However, if the space of known strong enhancers is actually quite far from the global optimum, even good molecular biologists are unlikely to find sequences close to the true strongest enhancer.
Predictive biology models allow researchers to do things differently. Rather than using intuitions to navigate a local hypothesis space, researchers can focus on gathering data to train models that enable a global search.
The experiments conducted for this purpose may differ from those of traditional molecular or systems biologists. Roughly speaking, a predictive biologist might devote more experimental budget to gathering diverse data that spans the range of possibilities within a hypothesis space, whereas a molecular biologist might adopt a "greedy algorithm strategy," focusing on testing hypotheses close to the current frontier of knowledge.
Fanyang's note: A "greedy algorithm" is a method that makes the locally optimal choice at each step. It does not consider future consequences — it simply picks the best option available in the present moment, hoping this will lead to a globally optimal solution. If you are climbing a mountain to reach the highest peak for the best view, but each time you climb in the steepest visible direction, you might end up on a small hill rather than the true highest peak, because you never accounted for the possibility of higher summits further ahead.
To return to our 100bp enhancer example: a predictive biologist might conduct an experiment testing thousands of random sequences for their gene expression-promoting activity, then train a model to predict activity directly from sequence. They could then use this computational model to search across the entire possibility space for optimal sequences, predicting the global optimum. With these tools, predictive biologists would likely discover new potent sequences far from what is currently known. While this example is idealized, real-world experiments designing new proteins have already achieved analogous results.
Further reading: The Next Frontier of AI Is Life Sciences: Starting with the Protein Magician
Proteins Are a Strange Foreign Language, and AlphaFold Is the Spark That Will Transform Research
Creating new institutions
Disciplines beget institutions in their image.
Molecular biology gave rise to the MRC Laboratory of Molecular Biology, Cold Spring Harbor Laboratory, and the original four biotech companies — Genentech, Biogen, Genzyme, and Amgen.
Systems biology spawned the Broad Institute, UW Genome Sciences, Illumina, Millennium Pharmaceuticals, and Myriad Genetics.
The representative institutions of predictive biology are still being rendered. Previous disciplines typically germinated in academic centers before spawning commercial enterprises. Predictive biology may offer a counterexample.
Currently, very few academic institutions are dedicated to exploring this intersection, but new institutions like the Arc Institute and the Schmidt Center point toward what may come. By contrast, TechBio companies have already emerged across multiple directions, including diagnostics (Freenome, GRAIL) and therapeutics (BigHat, Dyno, Enveda, Excentia, Generate, Recursion, Xaira).
Further reading: Deep Dive: Arc Institute and Convergent Research on FROs, the Metascience Movement, ARPAs, and Rapid Funding
That private sector growth is outpacing traditional academic environments may reflect the unique resource requirements of predictive biology. Unlike molecular biology problems, which could often be solved by individual researchers on limited budgets, predictive biology is most productive when generating data at scale and with abundant computational resources.
These conditions are more readily achieved in for-profit enterprises. Predictive biology may become the first biological discipline truly driven by industrial rather than academic scientists.
Coda
I feel fortunate to witness the phase transition of my own field. From the earliest dawn of biotechnology, scientists have dreamed of manipulating biology to create a better world. We have extended lifespans and achieved miracles once unimaginable, yet we have not fully conquered disease or designed our environments.
Even the simplest cell is more complex than our most sophisticated computers. There are far more layers of abstraction than a human mind can conceive. The hope of predictive biology is this: perhaps we need not be limited by the human mind's ability to connect nodes on a causal graph, but can instead rely on our ability to perceive patterns, with sufficient will and vitality to guide the direction of exploration.
P.S. A valuable reader comment at the end:
Jeremy Zucker:
Fascinating and thought-provoking. I agree with the author's framing that a key distinguishing question for predictive biology is:
Can we predict the outcome of experiment Y based on observable feature X?
However, if this is the core question driving predictive biologists, then the following statement cannot be true:
"Predictive biologists are more concerned with measuring the mutual information between two biological phenomena than with measuring direct causal relationships."
Allow me to explain why.
Suppose I have two molecules, A and B, with high mutual information between them. I then perform intervention experiments on A and B separately. Four scenarios may arise:
When B is intervened upon, A changes; but when A is intervened upon, B does not change.
When A is intervened upon, B changes; but when B is intervened upon, A does not change.
Neither changes regardless of whether A or B is intervened upon.
Both change regardless of whether A or B is intervened upon.
I believe you would agree that prediction based solely on mutual information cannot distinguish among these four outcomes. But with causal information, we can.
So what is causal information? It turns out that those wiring diagrams of systems biology, constructed from painstakingly acquired molecular biology experimental data, happen to provide the causal hypotheses needed to distinguish these four possible outcomes.
In other words, without the causal hypotheses encoded in these systems biology models, data-driven machine learning alone is insufficient to successfully predict the outcomes of unknown experiments.
Therefore, I would argue: predicting the outcomes of unknown experiments is fundamentally a causal estimation problem, not merely a machine learning prediction problem.
Original link:
https://blog.jck.bio/p/predictive-biology#footnote-10-140332568




5Y Capital seeks out, supports, and inspires lone entrepreneurs, providing them with support from the spiritual to the operational. We believe that if the you whom others see as crazy begins to be believed in, the world will become a different place.
BEIJING · SHANGHAI · SHENZHEN · HONG KONG
