AI Watch: Snake Meets Tetris | 5Y View

Quarterly AI Industry Observations 1Q24

This article comes from "Consensus Crusher's" Quarterly AI Observations series. The author participated as an observer in an AI panel organized by Whatif, sharing insights on the AI industry in Q1. Hope it sparks some ideas for you :)
Reposted from "Consensus Crusher"
Author: Botaijin
1. Snake vs. Tetris
In Ten Hypotheses on the Future of Large Models Over the Next Three Years, we mentioned an interesting phenomenon: "Why didn't LLMs disrupt the big players in year one?"
Not a single established major company was overtaken during the inaugural year of LLMs.
After listening to Whatif's AI panel, if I had to summarize in one sentence: "AI right now looks more like consolidation than disruption."
The panel offered an intriguing perspective: in the LLM era, big companies are like Snake:
- The world's largest companies are like the snake in the game, constantly testing which domains can apply LLMs.
- They're figuring out how to use LLMs to pull more talent into their ecosystems — whether that's the software ecosystem represented by public cloud, the creative ecosystem represented by content, or the supply chain ecosystem represented by edge devices.
- Every company is scrambling to claim a super-entrance as their ticket to the LLM era.
- They're the seeded players at the starting line of this LLM marathon, and will most likely be the finalists too.
And just like in the game we all know, these snakes are methodically absorbing every source of power:
- Companies with high talent density exert gravitational pull. Microsoft invested in OpenAI, AWS and GCP fought over Anthropic, and Google had previously acquired DeepMind, the last cycle's star company.
- The M&A scramble around AI intensified in 2023. MosaicML, Neeva, G2K, OmniML — a wave of the most outstanding LLM companies became acquisition targets.
- In past technology waves, big companies typically tried building with their own teams first. But in the LLM era, everyone treats time and capital as their most precious resources — acquisitions are now happening even before in-house experiments.
By contrast, the remaining LLM startups are more like playing Tetris:
- They have to find domains that giants consider important but can't tackle yet.
- Either areas giants don't want to pursue, or areas where architectural constraints and strategic directions prevent giants from going.
- Constantly searching for survival points and innovation opportunities in the cracks — looking for single-point breakthroughs, finding openings where they can fit.
Startups in any era are like Tetris, but the AI era looks harder:
- The PC software era, the internet era, the mobile internet era — each involved a new medium, creating natural demand to rebuild everything. Social could be redone from scratch; mobile-native WeChat could emerge.
- But AI is fundamentally tool enhancement, not medium innovation. Many businesses may not need to be rebuilt at all. Hence, Tetris in the AI era is more difficult.
2. The Snake's Piggy Bank and Tentacles
This generation of snakes is extraordinarily powerful, with strong self-reinforcing cash generation.
Take Microsoft, the biggest snake in the LLM era:
- Microsoft has the world's most comprehensive SaaS ecosystem, making it a rival to nearly every software company. These are like pairs of tentacles, best positioned to unlock commercial value from the massive upfront investment in large models.
- Microsoft already sits on virtually every customer company's vendor list, eliminating extensive POC processes — products can be deployed quickly once ready.
- Microsoft consistently unlocks 1+1>2 potential. When we discuss Copilot, we often focus on its seat-based sales model boosting productivity. But it's easy to overlook how Copilot, combined with enterprise domain data, can become a knowledge base product — and commercializing via data consumption may prove more valuable than Copilot itself.
One fascinating panel topic: "Why does Azure OpenAI API outsell OpenAI API?"
- Enterprise customers prioritize security above all, and Microsoft does security best.
- Microsoft is already a vendor — no procurement process needed. Every customer wants to move as fast as possible.
- A startup AI customer service company struggles to sell into thousand-person call centers, but once acquired by a major call center company, it quickly lands massive call center projects.
- Stability.ai is seeking acquisition, which may help it find commercial footing in the fiercely competitive text-to-image market.
"AI super individuals" and "small AI companies making big money" are popular narratives lately. But the panel offered a surprising view: LLMs may actually help big companies break down barriers and grow even larger:
- In the past, big companies faced diminishing marginal returns beyond a certain scale.
- Every advance in production tools has enabled organizations to grow larger — transportation, telephone, internet, mobile internet, cloud computing all helped organizations transcend time and space constraints.
- AI will similarly give organizations unlimited expansion capacity. Capital deployment efficiency at large enterprises will improve, pushing the ceiling on marginal returns higher.
3. The Snake Has No Secrets Either
In the large model era, the biggest snake is the OpenAI-Microsoft combination.
OpenAI is the moonshot pioneer of this era. And in the process of reaching for the moon, its knowhow and technical thinking continuously diffuse outward.
GPT-4 has virtually no secrets left in Silicon Valley:
- Algorithmically, there are no remaining mysteries — everyone in the circle knows what techniques each player has and their key research directions.
- The real differences lie in data and engineering, with numerous bottlenecks large and small. There will be dead ends along the way, but with direction established, solving them is a matter of time.
- Players have figured out the playbook and can roughly estimate the compute, manpower, and engineering required to reach GPT-4-level capability.
- The "no secrets" moment arrived faster in Silicon Valley than in China, but the information gap is gradually narrowing.
Even if OpenAI's frontier models hold no secrets, we still struggle to imagine what the next few generations mean:
- What exactly qualifies as GPT-5? Q*, native multimodality, understanding the physical world?
- Which directions matter most? Which path leads to greater intelligence?
- Unlike previous engineering challenges, these are research questions. OpenAI's talent density provides abundant imagination, and its compute resources enable ample trial-and-error.
- Everyone believes Scaling Law will hold for a long time, but OpenAI dares to explore directions we can barely conceive — the gap may not necessarily shrink.
4. China's Blocks vs. America's Blocks
Different soil produces different entrepreneurial directions.
The mobile internet era cultivated a generation of excellent product managers in China — product managers who define needs and scenarios.
The cloud computing era cultivated quality software customers and software practitioners skilled at finding PMF in America — they tend to start from productivity enhancement.
America has numerous niche small AI application companies:
- The earliest AI application viral hits, Harvey and Jasper, both came from niche commercial scenarios.
- Beyond these, even smaller scenarios can immediately land lighthouse customers — rapid commercialization through founders' personal networks.
- For example, Typeface, a MarTech AI company founded by Adobe's CTO.
- Or Writer, a more specialized B2B Jasper focused solely on B2B text generation, which already had over a dozen customers before raising funding.
But unlike America, Chinese AI companies face hard mode from the start:
- In America, many small vertical scenarios can generate revenue. Customers have strong willingness to pay and will invest for ROI. The sharp inflation of recent years has made customers even more conscious of efficiency gains. LLMs are thus initially positioned as productivity tools.
- In China, the opposite holds. Targeting small things makes it extremely hard to make money. You must do big things, or start small but harbor massive ambitions.
This creates significantly different AI application directions from America:
- Chinese entrepreneurs heavily favor 2C scenarios. Early signs of traction appear in education, companionship, and children's products — 2C has room to scale massively.
- The mobile internet form factor also cultivated strong product managers in China, seeking and creating demand with a product manager's eye.
- Beyond 2C scenarios, going global has become mandatory for AI entrepreneurs. One panelist mentioned that several products he's launching will test in America first. For LLM ventures with extremely high marginal costs, purchasing power matters enormously for getting started.
- Going global matters for 2C entrepreneurs, but possibly even more for 2B — many scenarios may only work with a global go-to-market.
5. What's Next for Model Companies
"OpenAI is doing moonshot engineering. Following too closely behind OpenAI, you forget there's also open source communities, and product and customer needs."
In conversations with model companies and startups, I found that SOTA models aren't what matters most:
- Meeting specific application scenarios and customer needs matters more for practical results.
- One entrepreneur discussing a doodle product found that when selecting an image captioning model, the top-2 ranked model didn't perform best — the fifth or sixth ranked model worked best for their scenario.
- A practitioner building a medical product found that their first version, combining medical data, performed best; after learning more general data, the model's hallucination rate actually increased.
This leads Chinese model companies to increasingly consider the meaning of scenarios and needs, and rationally assess their positioning: they may struggle to match OpenAI's moonshot role, but can build the most customer-appropriate models.
I also noticed model companies beginning to build their own application products:
- They need the capability to build super applications, to build products with their own models.
- Entering the application layer dramatically changes how they view models compared to pure model-building.
- Model capability and user needs don't map one-to-one — there's a massive gap.
6. What's Next for Application Companies
"Why haven't we seen exciting domestic AI applications yet?" This was the biggest focus in every discussion.
At this panel, I heard reflections and experiments from entrepreneurs on the front lines.
One entrepreneur reflected on problems encountered in past language model work:
- Current models' text output and intelligence capabilities haven't surpassed humans, making it extremely hard to exceed user expectations in entertainment scenarios — and entertainment only accepts 99-point products.
- If you can't hit 99 with the model alone, you need to build extremely complex systems around it, consuming massive time.
- So he's pivoting more toward images and overseas markets.
I also saw early success from Zhao Chong of AiSheJi/AI PPT, a productivity enhancement entrepreneur:
- Started building an online PPT editor in 2022, and quickly saw Stable Diffusion launch.
- The AiSheJi team added an AI layer on top of their PPT editor, rapidly seeing ARPU increase.
- Compared to global giant Office and domestic giant WPS, AiSheJi found its own Tetris path — targeting the broadest general population, not professional service providers, more like parents helping kids with homework.
- For general users, AI capability shifts from Office's focus on execution details and formulas to beautification, templates, and enterprise-facing AI-customized templates.
An excellent AI product, while being AI-focused, may not need to talk about AI constantly:
- Take an excellent AI camera product on the market — it never mentions AI, focusing instead on product presentation and meeting customer needs.
- But users naturally think: this AI effect is exactly what I want.
- In the future, beyond camera products, short video products will also rapidly integrate AI.
Compared to the many Model-as-Product offerings seen in 2023, finding scenarios matters far more than showing off technical muscle:
- In 2023, too many products were built to demonstrate model capabilities rather than serve customer needs.
- The proportion of model in applications will gradually decrease — from a single large model, to large model + multiple small models, to incorporating RAG. As single-model importance drops, system matching requirements rise.
- This makes applications more like applications, less like models.
One entrepreneur aiming to build AI-native applications raised a question:
- Current large models are trained on publicly available internet data.
- But enormous amounts of data remain uncompressed into large models. Meanwhile, AI-native applications will generate more data, keeping it within their own application ecosystems.
- AI-native applications grow from solving small problems with small intelligence, potentially becoming big products.
- Can this endogenous data grow new intelligence?
At this panel, I heard countless ideas.
Honestly, I haven't heard one massive scenario, one truly mind-blowing entrepreneurial direction.
But as mentioned earlier, China's AI application entrepreneurs, even starting from small things, are all thinking their own big thoughts.
7. Education Is China's Biggest Block
The most frequently mentioned application idea at this panel was education.
Education is a natural存量 large market with both 2C and AI attributes, and AI attempts are already visible across many domains.
First, recorded courses and homework grading are being transformed by AI:
- The new generation of recorded course products may take a K12 + Duolingo form.
- While watching videos, students can tap an AI tutor anytime to answer questions. With LLMs, AI tutors easily integrate with currently viewed video content, pinpointing where students struggle. And they're more patient than human teachers, more generous with praise.
- Homework grading products are also emerging quickly — OpenAI just invested in a B2B education company focused on grading humanities assignments.
And Chinese education companies have unique advantages entering the global AI market:
- Chinese education companies touch extraordinarily diverse domains, understanding how to coordinate product, brand, and operations for holistic advantage.
- Education's value chain is exceptionally long — teachers, content, delivery, customer acquisition, brand, service, renewal. Only Chinese internet education companies have walked this entire long chain.
- Chinese education companies have also invested heavily in LLM data, with rich domain data available for training.
Beyond education products, panelists discussed using LLMs for student knowledge assessment, reading ability assessment — potentially helping with book leveling and content matching.
8. How Sora Changes the World
OpenAI's greatest contribution to this era is being the pathfinder — using the most talent, money, and resources to point toward AGI.
When GPT-4 first emerged, the lack of sufficient public information meant LLM catch-up players couldn't be certain of replication. But when Sora appeared, the immediate reaction was that replication was possible — it was more a matter of resources and engineering.
Sora replication directions and challenges:
- The most直观 technical change is using Transformer instead of U-Net, then using a temporal autoencoder (trained by OpenAI) to break video into different patches.
- Challenge one is adjusting compression rates — different scenarios need different strategies. Sora learns specific video representations from massive training data, preserving key information after compression.
- Challenge two is semantic understanding — Sora's birth also relies on OpenAI's own language models.
- Challenge three is data volume — Sora's training data may be two orders of magnitude larger than other text-to-video models, including massive synthetic data.
- Challenge four is data labeling methodology — Sora's labeling model itself outperforms others on the market, directly affecting catch-up players' replication progress and quality.
- Challenge five is compute — current estimates put usage in the low-to-mid thousands of GPUs, relatively abundant overseas but still precious domestically.
- Challenge six is controlling parameters and generation costs — in the near term, the more likely choice is building a larger-parameter model to maximize quality.
Overcoming these challenges and successfully replicating may take 6-8 months. But OpenAI's rapid iteration capability is also formidable — Sora 2 may emerge by then. Meanwhile, opening to 2C users as quickly as possible will gather more user feedback.
Sora has also changed model companies' roadmaps. Previously, priority went to training large models, or doing LLM before multimodality. Now they're more likely to pursue both simultaneously, with equal importance.
Training LLMs follows Scaling Law, with improvement following logarithmic curves and increasingly difficult marginal gains. But early multimodality achieves more linear effects, with more obvious improvement.
Sora's emergence may also significantly impact content ecosystems:
- Text-to-image hasn't dramatically impacted society because images aren't society's dominant content consumption format — but video's importance far exceeds images.
- Content production supply speed will rapidly increase, potentially reshaping existing MCN content ecosystems.
- In product trends, we may see generation replacing recommendation, generation replacing search.
- ByteDance may be the world's most text-to-video-focused company. Zhang Nan oversees CapCut, Jiang Lu joined ByteDance — CapCut may transform video generation methods, with long-term implications for Adobe's professional video tools.
9. We're at 1.0, About to Enter 2.0
We're standing at what feels like LLM era 1.0, reflected in compute chips and models themselves. This panel largely explored and discussed 1.0-phase thinking and observations from frontier AI practitioners at home and abroad.
Entering 2.0, the narrative shifts to applications.
At this panel, Jenny Xiao, former OpenAI researcher and now partner at Leonis Capital, shared her views:
- The 2023 application ecosystem still faced numerous technical hurdles: dataset preparation, learning vector database/RAG tools, fine-tuning models, real-time inference, scenario-specific user feedback adjustment — making building a native LLM app far harder than initially imagined.
- Developer organizations also needed to adapt management structures to LLM development workflows — roles needed streamlining, more research talent required, operating more like a research institute than an app factory.
- But as the LLM developer ecosystem becomes more accessible, and more advanced LLM developer cases become learning examples, application ecosystem development will accelerate. We may see LLM value expand top-down as in the diagram below.
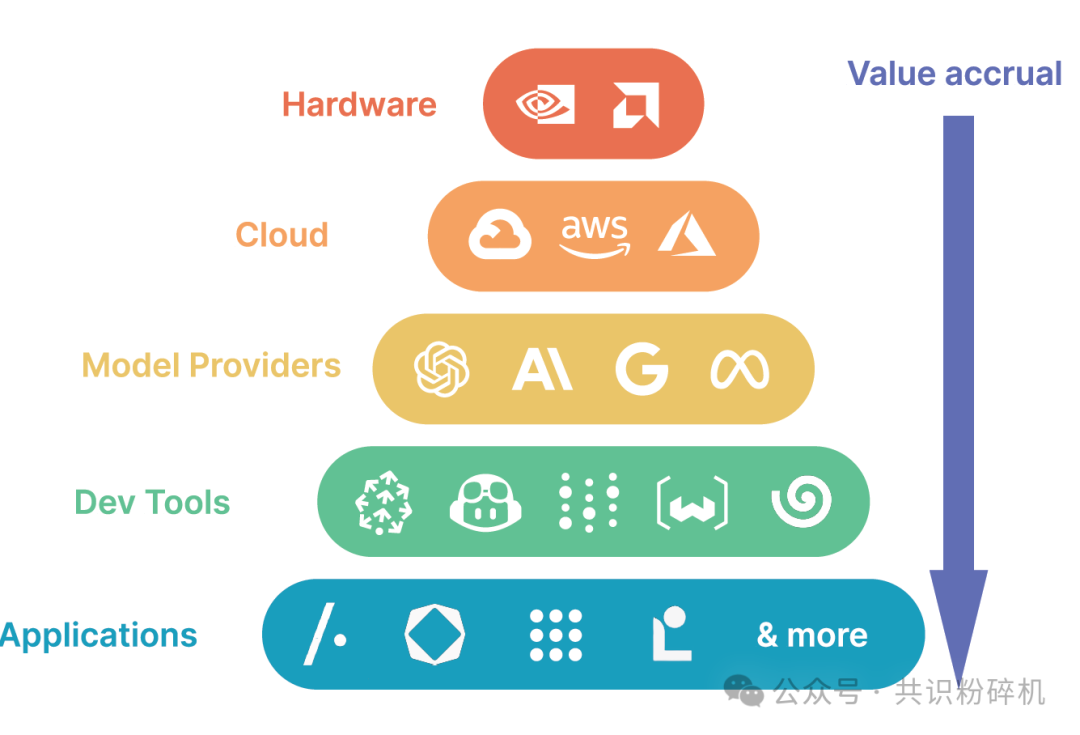




5Y Capital seeks out, supports, and inspires lonely entrepreneurs, providing support from spirit to all operational matters. We believe that if the world starts believing in the you that others see as crazy, the world will become a different place.
BEIJING · SHANGHAI · SHENZHEN · HONG KONG
