Geoffrey Hinton: Going All-In on Bigger Models to "Predict the Next Word" | 5Y View

Digital systems have advantages that humans simply cannot match.

Recommended by

Yuan Ye, Partner at 5Y Capital
In this interview, Turing Award winner Geoffrey Hinton shares not only his insights on large language models and multimodal learning, but also his profound reflections on consciousness and emotion in intelligent systems. Hinton recounts how he identifies and cultivates top talent — such as his first meeting with Ilya Sutskever — and how to develop good intuition and learn to trust it. He also shares his research philosophy: how to select and dive deep into problems that initially seem dubious yet may overturn existing understanding. Hinton's reflections are rich with wisdom and critical thinking. His approach to designing research organizations from the perspectives of technology and talent offers equally illuminating guidance for today's AI startups in navigating choices around technology, talent, and commercial/product strategy. Highly recommended.
In the interview, Hinton covers a wide range of topics, including the current technical trajectory of large models, the importance of multimodal learning, digital computation and shared knowledge, consciousness and emotion in intelligent systems, and his collaborators and outstanding students...
Hinton believes that large language models encode by finding common structures across different domains — a capability that enables them to compress information and form deep understanding, discovering connections between things in the real world that humans have yet to find. This, he argues, is the source of creativity. He also notes that by predicting the next token, models must in fact perform a certain degree of reasoning, contrary to the common claim that large models lack reasoning ability. As models scale up, this reasoning capability will only grow stronger. This is a direction worth committing everything to.
Recalling his collaboration with Ilya as teacher and student, Hinton mentions that Ilya had excellent intuition. He foresaw early on that scaling up models would be useful, even though Hinton himself was skeptical of the idea at the time. It turned out that Ilya's intuition was spot-on.
The interview spans a considerable period, so to help set the context, let's first review Hinton's career:
- December 6, 1947: Hinton born in Wimbledon, UK.
- 1970: Earned BA in Experimental Psychology from University of Cambridge.
- 1976–1978: Research Fellow in Cognitive Science, University of Sussex.
- 1978: Earned PhD in Artificial Intelligence from University of Edinburgh.
- 1978–1980: Visiting Scholar, Department of Cognitive Science, UC San Diego.
- 1980–1982: Scientific staff, MRC Applied Psychology Unit, Cambridge, UK.
- 1982–1987: Assistant Professor, then Associate Professor, Department of Computer Science, Carnegie Mellon University.
- 1987–1998: Professor, Department of Computer Science, University of Toronto.
- 1996: Elected Fellow of the Royal Society of Canada.
- 1998: Elected Fellow of the Royal Society (UK).
- 1998–2001: Founding Director, Gatsby Computational Neuroscience Unit, University College London.
- 2001–2014: Professor, Department of Computer Science, University of Toronto.
- 2003: Elected Fellow of the Cognitive Science Society.
- 2013–2016: Distinguished Researcher, Google.
- 2016–2023: Vice President and Engineering Fellow, Google.
- 2023: Resigned from Google.
The Interview:
Starting Point: Understanding How the Brain Works
Hinton: I still remember when I first came to Carnegie Mellon from the UK. At British research institutions, everyone would go to the pub at 6 p.m. for a drink. But at Carnegie Mellon, a few weeks in, it was a Saturday evening and I didn't have any friends yet, didn't know what to do, so I decided to go to the lab to program. Because I had a list machine, and you couldn't program that at home. So I went to the lab around 9 p.m. on a Saturday, and it was packed — all the students were there. The reason they were there was because what they were doing represented the future. They all believed that what they were doing next would change the course of computer science. That was very different from the UK, very refreshing.
Hellermark: Let's go back to the beginning — to you at Cambridge. At that time, you were trying to understand how the brain works. What was that like?
Hinton: It was a very disappointing time. I was mainly studying physiology. In the summer term, they were going to teach us how the brain works. What they taught was just how neurons conduct action potentials, which is very interesting, but it doesn't tell you how the brain works. So that was very disappointing. Then I turned to philosophy. The idea was that perhaps philosophy would tell us how the mind works. That was equally disappointing. I ended up going to University of Edinburgh to study AI, which was more interesting. At least you could simulate things, so you could test theories.
Hellermark: Do you remember what got you interested in AI? Was it reading a particular paper? Or a specific person who introduced you to these ideas?
Hinton: I think it was a book by Donald Hebb, the Canadian psychologist and pioneer of cognitive psychophysiology, that had a big influence on me. He was very interested in how connection strengths are learned in neural networks. I also read von Neumann's book — the father of computing — who was very interested in how the brain computes and how it differs from ordinary computers.
Hellermark: In those Edinburgh days, did you have a conviction that these ideas would work? Or what was your intuition at the time?
Hinton: It seemed to me that the brain must have some way of learning. The brain doesn't learn by having everything pre-programmed and then applying rules of logical inference — that approach seemed crazy from the start. So we had to solve the puzzle of how the brain learns to adjust connections in neural networks so that it can do complicated things. It was the same for von Neumann and Turing. Both were extremely good at logic, but they didn't believe in this logical approach.
Hellermark: How did you separate the idea of studying neuroscience from just doing AI algorithms that seemed to work? How much inspiration did you get from the early days?
Hinton: I never did much neuroscience. I was always inspired by my understanding of how the brain works — that there's a bunch of neurons doing relatively simple operations. They're nonlinear, but they collect inputs, weight those inputs, and the output depends on those weighted inputs. The question is, how do you change those weights so that the whole system does something good? That seemed like a fairly simple problem.
Hellermark: Do you remember your collaborators from that time?
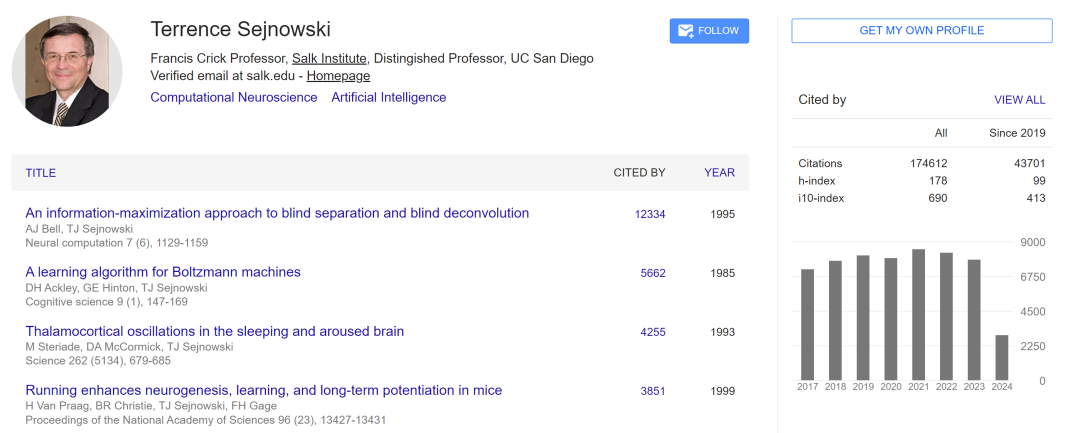
Hinton: My main collaborator at Carnegie Mellon wasn't actually at Carnegie Mellon. I had a lot of interaction with Terrence Sejnowski at Johns Hopkins University in Baltimore. About once a month, either he would drive to Pittsburgh or I would drive to Baltimore. It was 250 miles. We'd spend a weekend together, working on the machines in Baltimore. It was a great collaboration. We both believed that was how the brain worked. It was the most exciting research I had ever done, producing a lot of technically very interesting results, but I don't think that's how the brain works.
I also had a very good collaboration with Peter Brown, who was an excellent statistician working at IBM on speech recognition. He came to Carnegie Mellon as a mature student to get his PhD. He already knew a lot. He taught me a lot about speech, taught me about hidden Markov models. I think I learned more from him than he learned from me. That's the kind of student everyone wants. When he taught me about hidden Markov models, I was doing backpropagation with hidden layers. It wasn't called hidden layers yet. I thought the name used in Markov models was a good name for those variables where you don't know what they're doing. So that's where the name "hidden layer" in neural networks came from.
On Ilya: He Had Good Intuition
Hellermark: Take us back to when Ilya showed up at your office.
Hinton: It was probably a Sunday. I was programming, and then someone knocked on the door. Not a casual knock, but an urgent one. So I went to open the door, and there was a young student. He said he had been frying chips all summer, but he'd much rather work in my lab. I said, why don't you make an appointment and we'll talk? And Ilya said, "How about now?" That's Ilya for you.
We talked for a while, and I gave him a paper — the backpropagation paper published in Nature. We scheduled another meeting for the following week. He came back and said he didn't understand it. I was very disappointed. I thought he seemed like a smart person. The paper I gave him only covered the chain rule; it wasn't hard to understand. Then he said, "No, I understood that part. I just don't understand why you don't give the gradients to a reasonable function optimizer." That question kept us thinking for years. That's Ilya for you — he had good intuition, and his ideas were always good ones.
Hellermark: What do you think gave Ilya that intuition?
Hinton: I don't know. He always thought for himself. He'd been interested in AI since he was a kid, and he was good at math.
Hellermark: How did the two of you work together? What role did you play, and what role did Ilya play?
Hinton: Working with him was a lot of fun. I remember once we were trying to make data maps using a complicated method. I had a mixture model where you could make two maps from the same set of similarities. So on one map, a bank might be close to a green space, and on another map, the same bank might be close to a river. Because on a single map, you can't have it close to both, right? Since the river and the green space are far apart.
We were doing this in MATLAB, which involved a lot of code restructuring to get the matrix multiplications right. And he got fed up. So one day he said, "I'm going to write an interface for MATLAB. I'm going to program in this different language, and I have something that can convert it to MATLAB." I said, "No, Ilya, that'll take you a month. We have to keep going on this project. Don't get distracted by that." Ilya said, "It's fine, I did it this morning."

Hellermark: That's incredible. In those years, the biggest shift wasn't just algorithms — it was scale. How have you thought about scale over the years?
Hinton: Ilya had that intuition very early. He was always saying, you just make it bigger and it'll work better. I always thought that was a bit of an evasion — you need new ideas too. It turns out his intuition was basically right. New ideas helped. Things like the Transformer helped a lot. But the real issue was the scale of data and the scale of computation. At the time, we had no idea computers would get a billion times faster. We thought maybe 100 times faster. We were trying to solve problems by coming up with clever ideas, but if we'd had bigger data and bigger computation, those problems would have solved themselves.
Around 2011, Ilya, myself, and another graduate student named James Martins published a paper on character-level prediction. We used Wikipedia and tried to predict the next HTML character. It worked remarkably well. We kept being surprised by how well it worked. It used a fancy optimizer on a GPU, and we could never believe it understood anything, but it looked like it did — it seemed incredible.
"Predicting the Next Word" Requires Reasoning
Hellermark: How do these models predict the next word? And why is that a wrong way to think about them?
Hinton: I don't actually think it is the wrong way. In fact, I think I made the first neural net language model that used embeddings and backpropagation. The data was very simple — just triples. It converted each symbol to an embedding, then let the embeddings interact to predict the embedding of the next symbol, and from that predict the next symbol, and it learned these triples by backpropagating through the whole process. I showed it could generalize.
About ten years later, Yoshua Bengio used a very similar network and showed it could handle real text. About ten years after that, linguists started believing in embeddings. It was a slow process.
The reason I think it's more than just predicting the next symbol is: if you ask, what does predicting the next symbol require? Specifically, if you ask me a question and the first word of the answer is the next symbol, you have to understand the question. So I think predicting the next symbol is very different from old-style autocomplete. In old-style autocomplete, you store triples of words. Then if you see a pair of words, you look at how often different words appear in the third position, and that lets you predict the next symbol. That's what most people think autocomplete is. It's completely not that anymore.
To predict the next symbol, you have to understand what's being said. So I think by making it predict the next symbol, you're forcing it to understand. And I think that's how we understand too. A lot of people will tell you these things aren't like us, they just predict the next symbol, they don't reason like we do. But actually, to predict the next symbol, it has to do some reasoning. We're seeing now that even without adding any special reasoning components, just by making big models, they can already do some reasoning. I think when you make them bigger, they'll be able to do more reasoning.
Hellermark: What do you think I'm doing right now, besides predicting the next symbol?
Hinton: I think that's how you learn. You're predicting the next video frame, you're predicting the next sound. But I think it's a pretty reasonable theory of how the brain learns.
Hellermark: What lets these models learn across such vast domains?
Hinton: What these large language models do is find common structures. They can use common structures to encode things, which is much more efficient.
For example, if you ask GPT-4 why a compost heap is like an atomic bomb, most people can't answer that. Most people haven't thought about it — they'd assume an atomic bomb and a compost heap are completely different things. But GPT-4 will tell you that their energy scales are vastly different, their time scales are vastly different. But what they have in common is that when a compost heap gets hotter, it produces heat faster; when an atomic bomb produces more neutrons, it produces neutrons faster too. So you get the concept of a chain reaction. I believe it understands both chain reactions, and it uses this understanding to compress all this information into its weights. If it's doing that, then it'll do the same for everything we haven't seen yet. That's where creativity comes from — seeing analogies between things that seem completely different on the surface.

So I think as GPT-4 gets bigger, it'll eventually become very creative. The idea that it's just repeating things it learned, just pasting together stuff it already learned, is completely wrong. It'll be more creative than humans.
Hellermark: You're saying it won't just repeat human knowledge developed so far — it could make bigger advances. I don't think we're seeing that fully yet. We're starting to see some examples, but at scale it stays at current scientific levels. What do you think it would take to push it beyond that level?
Hinton: We've seen this in more limited situations. For instance, in the famous match between AlphaGo and Lee Sedol, on move 37, AlphaGo played a move that all the experts thought was definitely wrong, but later they realized it was a brilliant move. That's creativity within a limited domain. I think as models scale up, we'll see more of that.
Hellermark: The difference with AlphaGo was that it used reinforcement learning, which let it go beyond the current state. It started with imitation learning, watching how humans play, and then through self-play, developed far beyond that level. Do you think that's the missing standard component?
Hinton: I think it may be the missing part. The self-play in AlphaGo and AlphaZero is a large part of why they could make these creative moves. But I don't think it's completely necessary.
There's an old experiment where you train a neural network to recognize handwritten digits. I love this example. You give it training data where half the labels are wrong. The question is: how well can it learn? And these wrong labels are fixed — every time it sees a particular sample, it's paired with the same wrong label, so it can't average out the errors by seeing the same sample multiple times with sometimes correct and sometimes wrong labels. There are 50% wrong labels in the training data, but if you train the neural network with backpropagation, its error rate can drop below 5%. In other words, it gets better results even from incorrectly labeled data. It's able to recognize errors in the training data. It's like a smart student being smarter than their tutor. The tutor tells them lots of things, but half the information is wrong, and the student can figure out which half is wrong and only listen to the correct half — ending up smarter than the tutor. So these large neural networks can actually do better than their training data. Most people don't realize this.
Hellermark: So how do you think these models will incorporate reasoning? I mean, one approach is adding heuristics on top of the model — a lot of research is doing this now, where you can add some thinking to the model and feed reasoning back into the model itself. Another way is scaling up the model. What's your intuition?
Hinton: My intuition is that as we scale these models up, they'll get better at reasoning. If you ask how people work, roughly speaking, we have these intuitions, and we can use reasoning, and we use reasoning to correct our intuitions. Of course, during reasoning we also use intuition. But if the conclusion of reasoning conflicts with our intuition, we realize we need to change our intuition. This is very much like in AlphaGo or AlphaZero, where you have an evaluation function that just looks at the board and says, how good is this for me? But when you do Monte Carlo rollouts, you get a more accurate idea, and that corrects your evaluation function. So you can train it to agree with the result of reasoning.
I think these large language models are going to have to start doing this. They're going to have to start training their raw intuition about what to do next by reasoning about it and realizing that it's wrong. That way, they can get much more training data than just imitating people. This is exactly why AlphaGo was able to come up with this creative Move 37. It had much more training data because it was using reasoning to figure out how to move.
Models can learn a lot from language, but learning from multimodal data is much easier
Hellermark: How do you think about multimodality? When we bring in images, video, and sound, how do you think that will change the models?
Hinton: I think it will make a huge difference. I think it will make models much better at understanding spatial things. For example, understanding some spatial things from language alone is quite difficult, though surprisingly, even before becoming multimodal, GPT-4 could do this. But when GPT-4 becomes multimodal, if you also have it doing vision and touch, reaching out to grab things, it will understand objects much better.
So although you can learn a lot from language, learning is much easier if it's multimodal. In fact, you need much less language. For example, there are lots of YouTube videos where you can predict the next frame. So I think multimodal models will obviously dominate. You can get much more data, and you'll need less language. So it's a philosophical point that you can learn a perfectly good model from language alone, but it's much easier to learn it from a multimodal system.
Hellermark: How do you think this will affect reasoning in models?
Hinton: I think it will make them much better at spatial reasoning. For example, reasoning about what happens if you pick up an object. If you actually try to pick up objects, you get all sorts of training data.
Three Views on "Cognition"
Hellermark: Do you think the human brain evolved to work well with language, or did language evolve to work well with the human brain?
Hinton: On the question of whether language evolved to fit the brain, or the brain evolved to fit language, I think that's a very good question. I think both happened.
I used to think we did a lot of cognition without language at all, but I've changed my mind. I'll give three views on language and its relationship to cognition.
The first is the old-fashioned symbolic view, that cognition consists of strings of symbols in some cleaned-up logical language, with no ambiguity, and you apply rules of inference. So cognition is just symbol manipulation of things like strings of linguistic symbols. That's one extreme view.
The other extreme view is: once you get inside the brain, everything is vectors. Symbols come in, you convert these symbols into large vectors, and all the insight is done with large vectors. If you want to produce output, you produce symbols again. So there was a moment in 2014 in machine translation where people were using recurrent neural nets, words would come in, they'd have a hidden state, and they'd accumulate information in this hidden state. So by the time you got to the end of the sentence, there was a big hidden vector that captured the meaning of the sentence. And then that could be used to produce words in another language, and this was called a thought vector. That's the second view of language.
There's a third view, which is what I now believe, that the brain converts these symbols into embeddings, and uses multiple layers of embeddings. So you get very rich embeddings. But the embeddings are still associated with the symbols, in the sense that the symbol has its corresponding large vector. These vectors interact to produce a vector for the next symbol. So understanding is knowing how to convert symbols into vectors, and how the elements of vectors interact to predict the vector for the next symbol. That's how understanding works in large language models, and in our brains. You keep the symbols, but interpret them as large vectors. All the work and all the knowledge is in which vectors to use and how the elements of these vectors interact, not in rules of symbols. But it's not that you get rid of symbols entirely — you convert symbols to large vectors, but you preserve the surface structure of the symbols. That's how large language models work. And now I think this seems like a much more plausible model of human thought as well.
"Jensen Huang sent me a GPU"
Hellermark: You were one of the first people to think about using GPUs. I know Jensen loves you for that. As early as 2009, you mentioned that you told Jensen that using GPUs might be a very good idea for training neural networks.
Hinton: Actually, around 2006, I had a graduate student named Richard Szeliski. He's a very good computer vision person. I was talking with him at a conference, and he said I should think about using graphics processing units, because they're very good at matrix multiplication, and what you're doing is basically matrix multiplication.
So I thought about it for a while. Then we learned about Tesla systems with four GPUs. Initially we tried using gaming GPUs, and we found they made things run 30 times faster. Then we bought a Tesla system with four GPUs, and we did speech processing on it, and it worked very well.
Then in 2009, I gave a talk at NIPS, and I told 1,000 machine learning researchers that you should all go and buy NVIDIA GPUs. GPUs are the future. You need GPUs for machine learning. Then I actually emailed NVIDIA and said I told 1,000 machine learning researchers to buy your products, can you send me one for free? They didn't say no. Actually, they didn't reply. But later when I told Jensen this story, he sent me one for free.

Digital Systems Have Advantages Humans Can't Match
Hellermark: That's great. I think what's interesting is how the evolution of GPUs has been in sync with the development of this field. Where do you think we should go next in terms of computation?
Hinton: In my last few years at Google, I was thinking about how to try analog computation. That is, instead of using a megawatt of power, using 30 watts like the brain, and running large language models in analog hardware.
I never got that to work. But I came to really appreciate digital computation. If you're going to use low-power analog computation, each piece of hardware will be different, and you have to exploit the specific properties of the hardware. That's what happens with humans. All of our brains are different, so we can't take the weights out of your brain and put them in my brain. The hardware is different. The exact properties of individual neurons are different.
When we die, most of our knowledge and experience dies with us, because the way humans pass on knowledge typically involves language communication, which is relatively inefficient. Digital systems, however, are different — they can pass on knowledge by sharing weights, that is, learned data and parameters. Once a digital system has learned something, these weights can be saved and reused in any other identically configured system. This method not only ensures precise replication of knowledge, but also greatly improves the efficiency of learning and knowledge sharing. Therefore, digital systems have capabilities far beyond humans when it comes to sharing and diffusing knowledge.
Fast Weights Need to Be Taken Seriously
Hellermark: Many of the ideas behind AI systems already deployed in practical applications come from early neuroscience theories, and these ideas have been around for a long time. The question now is, what other neuroscience theories are underutilized and could be applied to the systems we're developing? This requires us to explore underexploited theories in neuroscience and translate them into technology to push AI development further.
Hinton: One important aspect where we still need to catch up, in the comparison between AI and neuroscience, is the time scale of change. In almost all neural networks, there are fast time-scale changes in activity — you put in data, and the embedding vectors change. And then there's the slow time scale, which is changes in weights, and that's long-term learning. The brain has both of these time scales too.
For example, if I suddenly say an unexpected word, like "cucumber," and five minutes later you put on headphones and are in a noisy environment, if there's very faint speech, you'll be better at recognizing the word "cucumber" because I said it five minutes ago. So where is that knowledge stored? In the brain. This cognition is clearly saved by temporary synaptic changes, not by specific neurons — we don't have enough neurons in our brains for that kind of thing. These temporary weight changes, which I call fast weights, are not used in our current neural models.
The reason we don't use fast weights in our models is that if temporary changes in weights depend on input data, then we can't handle many different situations simultaneously. Currently, we usually batch together many different pieces of data and process them in parallel, because this allows matrix multiplication, which is more efficient. It's this need for efficiency that prevents us from using fast weights. However, the brain clearly uses fast weights for temporary memory storage, and can achieve many things this way that we currently can't do.
I had high hopes for technologies like GraphCore (a British semiconductor company that develops AI and machine learning accelerators, introducing massively parallel intelligent processing units that keep complete machine learning models inside the processor) — if they took a sequential approach and only did online learning, then they could use fast weights. But this approach hasn't succeeded. I think it will eventually succeed when people start using conductances as weights.
Some of Chomsky's Theories Are Nonsense
Hellermark: How has understanding how these models work, and how the brain works, affected the way you think?
Hinton: I think it has had a huge impact, at a fairly abstract level. For a long time in AI, there was a widespread view that simply relying on massive amounts of training data to let a large random neural network learn complex things was impossible. If you talked to statisticians, linguists, or most people in artificial intelligence, they would say this was just a pipe dream — that without extensive built-in architecture, you couldn't learn truly complex knowledge.
But reality has completely overturned this view. It turns out you can take a large random neural network, train it on vast amounts of data, adjust the weights using stochastic gradient descent, and it will learn complex things. This discovery has significant implications for how we understand brain structure, showing that the brain doesn't need to have all structural knowledge built in from birth. Of course, the brain does have plenty of innate structure, but it clearly doesn't need to rely on that structure to learn things that are readily learnable.
This view also challenges Chomsky's linguistic theory — that complex language learning must depend on structures hard-wired into the brain from birth, waiting to mature. That idea is now obviously nonsense.
Hellermark: I'm sure Chomsky thanks you for calling his views nonsense.

Intelligent Systems Can Have Feelings Too
Hellermark: What do you think it would take for these models to simulate human consciousness more effectively?
Hinton: I think they can have feelings too. We tend to use what I call the "inner theater model" to explain perception and feeling. If I say I feel like punching Gary in the nose, let's try to abstract that from the inner theater concept. That's usually interpreted as some kind of internal emotional experience. But that model may not be accurate. In reality, when I express this feeling, what I really mean is that if it weren't for my prefrontal cortex inhibiting me, I might actually take that action. So-called feelings are essentially actions we would take if we weren't constrained.
In fact, these feelings aren't unique to humans — robots or other intelligent systems could potentially experience emotions too. For example, in 1973 in Edinburgh, I saw a robot display emotion. This robot had two grippers and could assemble toy cars on green felt, as long as the parts were laid out separately. But if you piled the parts together, its vision system wasn't good enough to make sense of the situation, so it would appear confused and scatter the parts, then try to assemble them again. If a human did this, we might think they were frustrated at not understanding the situation and destroyed it in response.
Hellermark: That's impressive. You've described both humans and large language models as analogy machines. What would you say is the most powerful analogy you've discovered in your lifetime?
Hinton: One analogy that influenced me greatly in my life — though it's a bit of a stretch — is the similarity between religious belief and symbolic processing. I was born into an atheist family, and when I first encountered religious belief as a very young child in school, it struck me as complete nonsense, and I still think so today. When I learned about symbolic processing being used to explain human behavior, I found it just as absurd as religious belief. But I no longer think it's complete nonsense, because I do believe we perform symbolic processing — it's just that we do it by giving embeddings to these symbols. We are actually doing symbolic processing, just in a completely different way than people originally imagined. People used to think symbolic processing was simply matching symbols, where a symbol has only one property: it's either identical to another symbol or it isn't. That's not how we work at all. We use context to provide embeddings for symbols, and then we think by having the components of these embeddings interact with each other.
But there's a very good researcher at Google named Fernando Pereira, who said that we do have symbolic reasoning. The only symbols we have are natural language. Natural language is a symbolic language, and we use it to reason. I believe that now.
Stay Skeptical of Conventional Wisdom, Then Prove It Wrong
Hellermark: You've done some of the most consequential research in the history of computer science. Could you walk us through, for example, how you pick the right problems to work on?
Hinton: I did many of the most consequential things with my students. This was mainly due to good collaboration with students and my ability to pick excellent students. This was because in the 1970s, 80s, 90s, and into the 21st century, very few people were studying neural networks. So the small number of people working on neural networks could pick the best students, plus you needed a bit of luck.
But my approach to picking research problems is basically this: you know, when scientists talk about how they work, they have theories about their working methods that may not have much to do with reality. But my theory is that I look for something that everyone agrees with, but that feels slightly off. Usually there's a subtle intuition that something's wrong somewhere — just a faint sense that things don't quite add up. Then I work on that problem, trying to explain in detail why it's wrong. Maybe I can make a small demonstration with a little computer program showing that it doesn't work the way you might expect.
Let me give an example. Most people think that if you add noise to a neural network, its performance gets worse. Actually, we know that if you do this, its generalization gets better. This can be proven with a simple example — that's the beauty of computer simulation. You can show that your original idea — that adding noise makes things worse, that making half the neurons stop working makes things worse — is true in the short term. But if you train it this way, eventually it works better. You can demonstrate this with a small computer program, and then you can think carefully about why this happens. That's my working method: find something that sounds suspicious, then study it and see if you can use a simple demonstration to show why it's wrong.
The Unsolved Mystery Hinton Wants to Keep Pursuing: How the Brain Works
Hellermark: Recently, what has struck you as suspicious?
Hinton: That we don't use fast weights — that seems wrong. We only have these two timescales, which is obviously incorrect. This is completely different from how the brain works. In the long run, I think we're going to need many more timescales.
Hellermark: If you were leading a group of students right now, and they came to you and said, given everything we've discussed, what's the most important problem in your field? What would you advise them to work on next? We talked about timescales for reasoning. What would be your top priority?
Hinton: For me, the problem is the same one I've been focused on for about the past 30 years: does the brain do backprop? I believe the brain gets gradients. If you're not getting gradients, your learning is much worse than if you are. But how does the brain get gradients? Is it implementing some approximate version of backprop, or is it using a completely different technique? That's a major unsolved mystery. If I were to continue doing research, this is what I would work on.
Hellermark: When you look back at your career now, you've been right about so many things. But what if a direction you committed to with very little time turned out to be wrong?
Hinton: There are two separate questions here. One: what did you get wrong? Two: do you wish you'd spent less time on it? I think my views on Boltzmann machines were wrong, and I'm very glad I spent a long time on them. There are more beautiful theories about how to get gradients than backprop — backprop is just ordinary and sensible, it's just a chapter. Both mechanisms are clever, and it's a very interesting way to get gradients. I wish the brain worked this way, but I don't think it does.
Hellermark: Have you spent much time imagining what happens once these systems are developed? If we can get these systems working well, we could democratize education, make knowledge more accessible, solve some intractable medical problems. Or is understanding how the brain works more important to you?
Hinton: Yes, I do feel scientists should do things that help society. But actually, you can't do your best research when it's driven by wanting to help. You just need to understand something. More recently, I've realized these things could cause a lot of harm as well as a lot of good. I've become more concerned about their societal impact. But that's not the motivation. I just want to know how the brain learns to do things — that's what I want to know. And in the process of trial and error, we got some decent engineering results.
Hellermark: Yes, that was a fortunate failure for the world. If you think about potentially massive positive impact, what do you see as the most promising application?
Hinton: I think healthcare is obviously a big area. In medicine, there's almost no limit to how much society can absorb. For an elderly person, they might need five full-time doctors. So when AI is better than humans at doing things, you want more resources in these areas — it would be great if everyone had three doctors. We'll get there.
Also new engineering, developing new materials — better solar panels, room-temperature superconductors, or just understanding how the body works. These will have huge impact. What worries me is bad people using them to do bad things.
Hellermark: Have you worried that slowing down the field might also slow down the positive aspects?
Hinton: Of course. I don't think the field is likely to slow down, partly because it's international. If one country slows down, others won't. There was a proposal that we should pause large model research for six months. I didn't sign it because I didn't think it would ever happen. I probably should have signed it, because even if it never happens, it makes a point. Sometimes it's good to use it to make a stand. But I don't think we'll slow down.
Hellermark: How do you think having assistants like ChatGPT will affect the AI research process?
Hinton: I think it will make AI research much more efficient. When you have these assistants to help you program, and also to help you think about problems, they might help you enormously with equations.
Picking Students: Intuition Matters Most
Hellermark: Have you given much thought to the process of picking people? Is it mostly intuitive for you? Like when Ilya Sutskever showed up at the door, did you think, "This is a smart guy, let's work together"?
Hinton: Sometimes it's obvious. After talking to him for a while, you can tell he's very smart. Talk to him more, and you realize he's clearly very smart and has good intuitions about math. So that was a no-brainer.
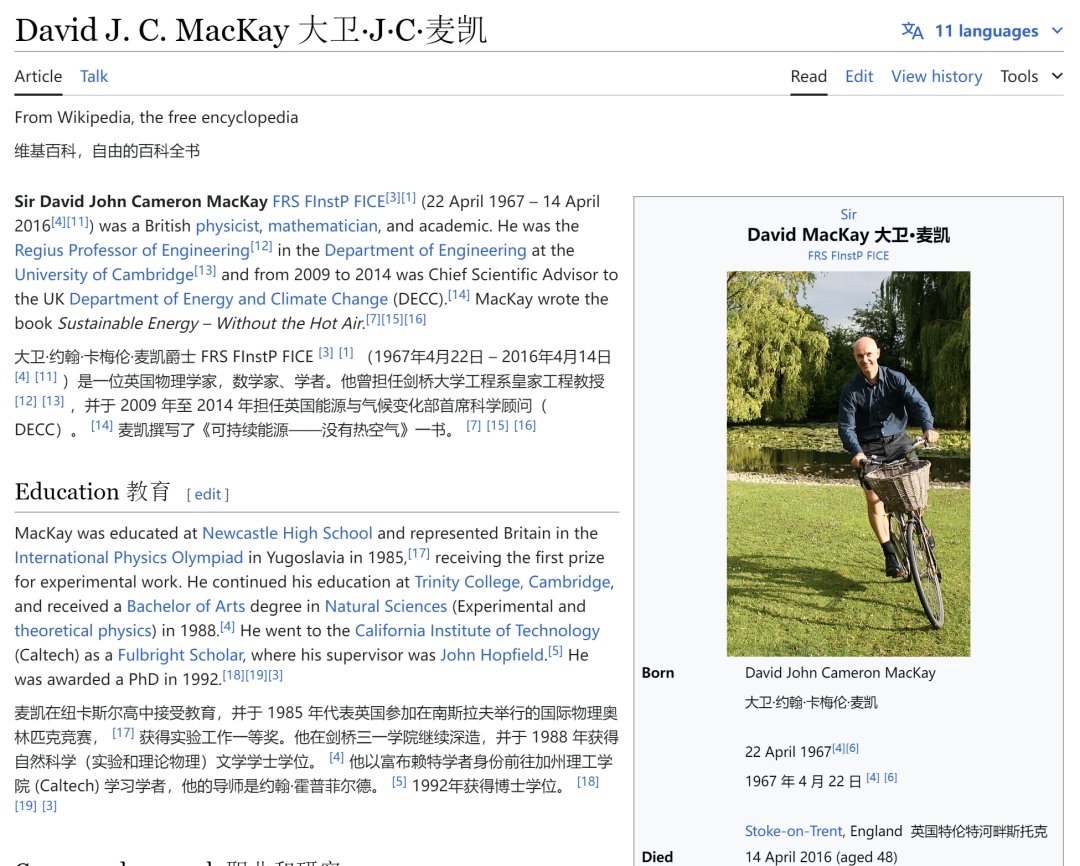
Another time, we had a poster at a NIPS conference, and someone came up and started asking us questions about it. Every question he asked was a deep insight into what we'd done wrong. Five minutes later, I offered him a postdoc. That was David McKay. Very smart. He's died, which is very sad, but he was clearly the kind of person you want.
Other times it's less obvious. One thing I've learned is that people are different. There's not just one type of good student. Some students may not be that creative, but are technically very strong and can make anything work. Others are less technically strong but very creative. Of course, you want people who are both, but you don't always get that. But I think you actually need all different kinds of graduate students in a lab. I still go with my intuitions, though. Sometimes you talk to someone and they're just really smart, they can just follow the thread, and that's who you want.
Hellermark: Why do you think you have better intuition about some people? Or how do you cultivate your intuition?
Hinton: I think part of it is that they won't take nonsense. One way to get bad intuitions is to believe everything you're told. That's fatal. You have to be able to... I think some people do this — they have a complete framework for understanding reality. When someone tells them something, they try to figure out how it fits into their framework. If it doesn't fit, they reject it. That's a very good strategy.
People who try to absorb everything they're told end up with a very mushy framework. They can believe everything, which is useless. So I think actually having a strong view of the world and trying to fit incoming facts to your view — this can lead to deep religious convictions and fatal flaws, like my belief in Boltzmann machines — but I think it's right.
If you have good intuitions that are reliable, you should trust them. If your intuitions are bad, nothing can be done. So you might as well trust them.
Go All In: Train Bigger Models on Multimodal Data
Hellermark: That's a very good point. When you look at the types of research being pursued, do you think we're putting all our eggs in one basket? Should we be diversifying our ideas more within the field? Or do you think this is the most promising direction, so we should go all in?
Hinton: I think having large models and training them on multimodal data, even if it's just to predict the next word, is a very promising approach, and we should go all in. Obviously, lots of people are doing this now, and lots of people are doing things that seem crazy, which is good. But I think it's fine for most people to go down this road because it works so well.
Hellermark: Do you think the learning algorithm really matters that much, or is scale more important? Are there millions of ways we could get to human-level intelligence, or are there specific methods we need to discover?
Hinton: Yes, as to whether the particular learning algorithm matters a lot, or whether there are many learning algorithms that would do the job, I don't know the answer. But it seems to me that backprop is the right thing to do in some sense. Getting the gradient so you can change parameters to make it work better seems like the right thing to do, and it's had amazing success. There may be other learning algorithms that get the same gradient in a different way and would work too. I think it's all open, and a very interesting question, whether there's something else you could try to maximize that would give you good systems. Maybe the brain is doing this because it's easy. Backprop is the right thing to do in some sense, and we know it works very well.
Proudest Achievement in a Lifetime: The Boltzmann Machine Learning Algorithm
Hellermark: Last question. Looking back over decades of research, what are you most proud of? The students? The research?
Hinton: The Boltzmann machine learning algorithm. It's very elegant. It probably has no hope in practice, but it's the thing I enjoyed most, and I developed it with Terry, and that's what I'm most proud of, even though it was wrong.

Paper link:
https://www.cs.toronto.edu/~fritz/absps/cogscibm.pdf
Hellermark: What are you spending the most time thinking about right now?
Hinton: What to watch next on Netflix.
Interview video link:
https://www.youtube.com/watch?v=tP-4njhyGvo&t=660s




5Y Capital seeks out, supports, and inspires solitary entrepreneurs, providing them with everything from spiritual to operational support. We believe that if the "crazy" you — in others' eyes — starts to be believed in, the world will become a different place.
BEIJING · SHANGHAI · SHENZHEN · HONG KONG
