Can Scaling Lead to AGI? | 5Y View

A primer and discussion on Scaling Laws.

Almost every discussion about LLMs inevitably circles back to scaling laws. They're seen as OpenAI's core technology, and Sora's emergence is viewed as yet another scaling law success story. At the same time, debate over whether scaling can remain effective continues to unfold. If AGI is the goal, is scaling the master key that will get us there?
This article is adapted from tech blogger Dwarkesh Patel's personal blog. It begins by sorting through the key controversies and questions surrounding scaling laws in the current community discourse, then interprets and analyzes both the supportive and skeptical voices. Dwarkesh estimates there's roughly a 70% probability that people will achieve more powerful AI through scaling before 2040 — AI capable of automating substantial cognitive labor, which in turn would accelerate further AI development. But if scaling laws break down, the path to AGI becomes long and arduous.
To present the full spectrum of perspectives on scaling laws, this article is structured as a debate between "optimistic" and "pessimistic" viewpoints.
Originally published by Overseas Unicorn
Author: Dwarkesh Patel
Translated by: Lavida, Chenxin
01.
Debate 1: Will We Run Out of Data?
Pessimistic view: By 2024, high-quality language data will be exhausted.
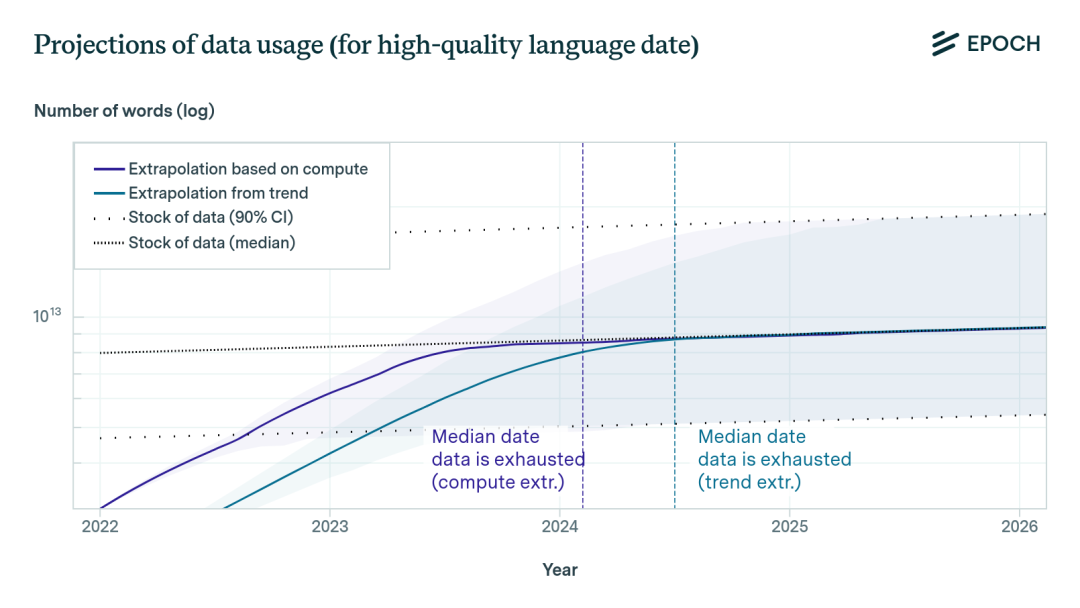
According to scaling law curves, we'd need roughly 1e35 FLOPs to train an AI smart enough to write academic papers, and then build on that to automate AI research itself, continuing to iterate even when scaling laws no longer apply.
In other words, we need five orders of magnitude more data than currently exists.
Original note: Per Chinchilla Optimal Scaling principles, while we can train models suboptimally, this only compensates for modest data shortfalls — not a five-order-of-magnitude gap. Chinchilla Optimal Scaling comes from DeepMind research; put simply, efficient scaling requires simultaneously increasing both training data volume and model parameter count, finding the balance between the two. Focusing on just one limits performance gains.
Note that "five orders of magnitude" doesn't mean five times. "Five orders of magnitude short" means existing data may be just 1/100,000th of what's actually needed. While we can improve data efficiency through multimodal training, token recycling, curriculum learning, and other methods, meeting scaling laws' exponentially growing data demands remains extremely difficult.
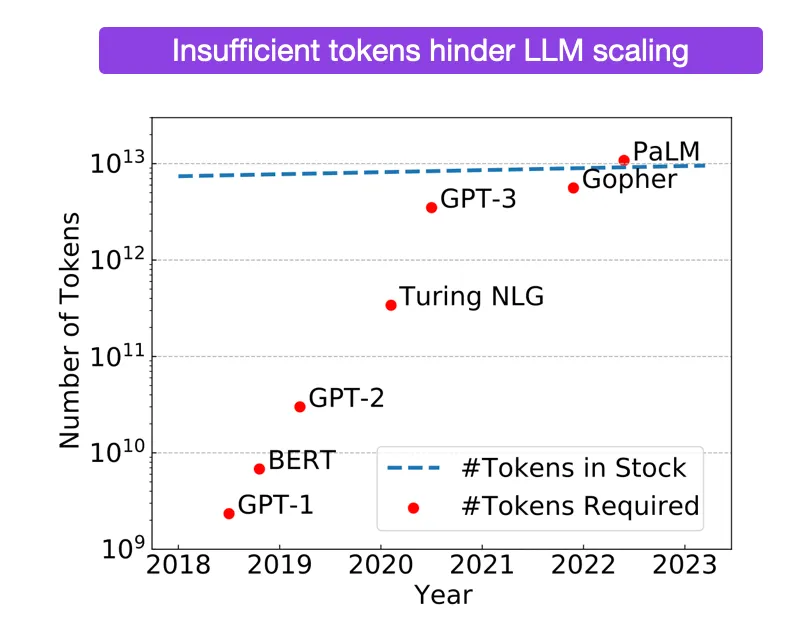
Comparison of token requirements across different models
So some propose using self-play and synthetic data methods, but self-play faces two major challenges:
-
Evaluation: AlphaGo could use self-play because in Go, the model could self-evaluate based on "did I win the game." But many current reasoning tasks lack such clear-cut standards, so LLMs cannot correct their own reasoning errors.
-
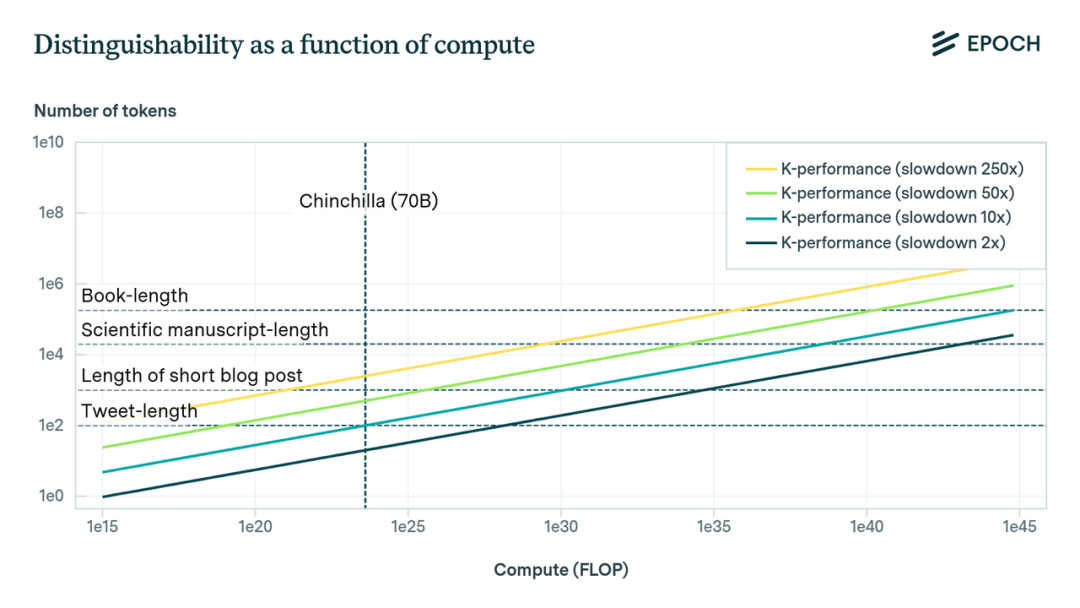
Computation: In AlphaGo and similar math or coding approaches, various tree search techniques are often used, running the LLM multiple times at each node of the tree. Even in relatively bounded tasks like Go, AlphaGo's computation was already substantial. To search through all possibilities of human thought processes, handling more data and more complex parameters, the computation would only grow more massive. Human-equivalent cognitive computation is roughly 1e35 FLOP — nine orders of magnitude beyond today's largest models. Even with future hardware and algorithmic improvements, is a nine-order-of-magnitude boost really feasible?
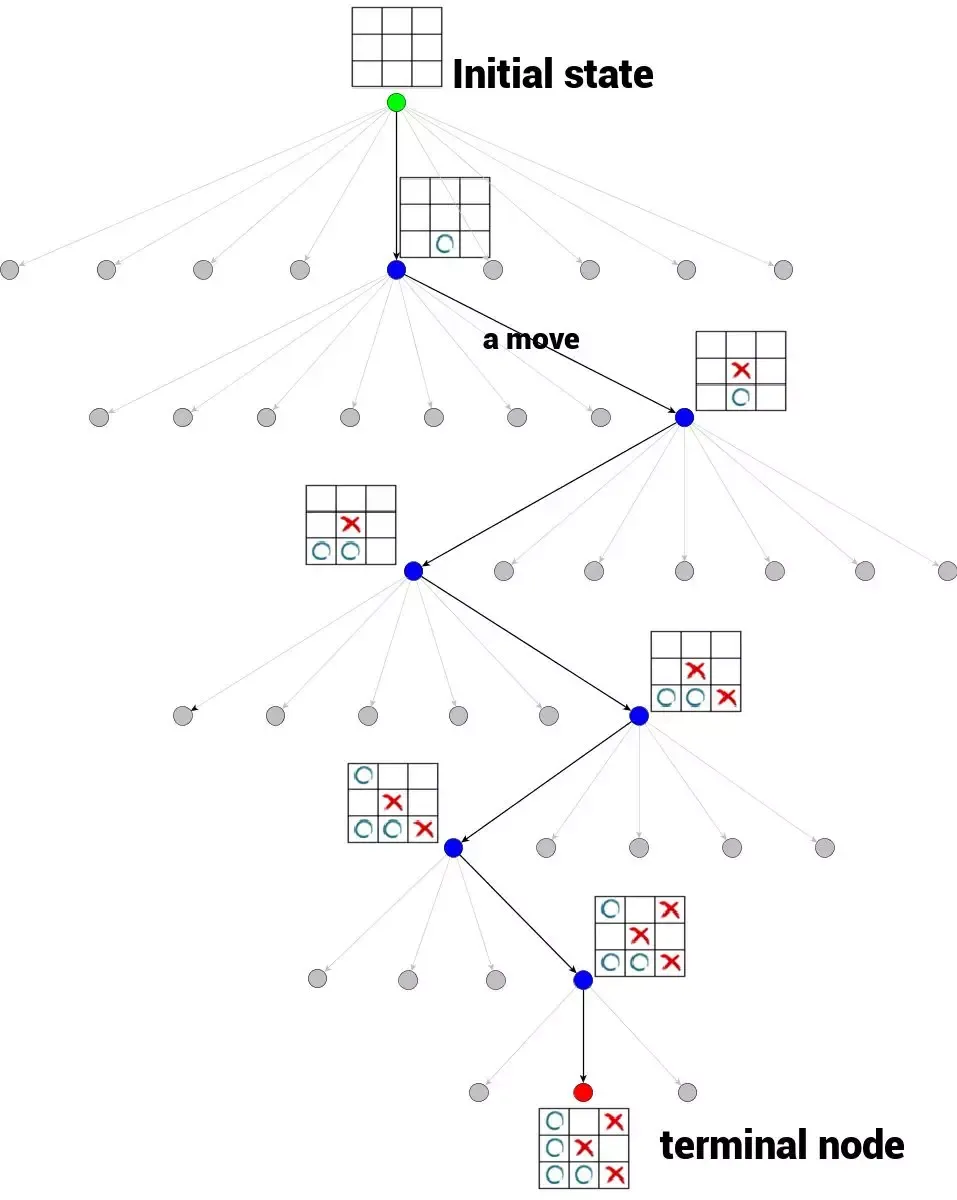
Monte Carlo Tree Search (MCTS)
Optimistic view: If data scarcity is the only reason to doubt scaling laws, then the thought shouldn't be "I used to think continuing to scale transformer models would achieve AGI, but the problem is we'll run out of data soon." Rather, it should be: "So as long as internet data is sufficiently abundant, continuing to scale would train an AI with human-level intelligence."
LLMs process data inefficiently because most training samples are low-quality text like e-commerce junk*, and next-token prediction makes models even less efficient. If evaluated by loss function, this has nothing to do with the actual work we expect intelligent agents to perform in economic activity. Yet using this method, with an investment equivalent to 0.03% of Microsoft's annual revenue scraping data from the internet, we trained a proto-AGI — GPT-4.
*Original note: Compared to humans, LLMs are indeed less sample-efficient. GPT-4 processes far more data than a person sees from birth to adulthood, yet isn't as intelligent. But this assessment overlooks something: human genes contain knowledge accumulated over hundreds of millions of years of evolution — highly condensed,精华 information, the result of our ancestors interacting with their environment through Natural Selection over vast timescales. This inherited knowledge provides us with a fundamental understanding of the world that we're born with, something LLMs lack.
Given how simple AI's evolutionary methods have been so far, we shouldn't be surprised if synthetic data works too. After all, "the models just want to learn" (note: originally quoted from Dwarkesh's interview with Anthropic CEO Dario Amodei, who mentioned this was something Ilya said to him before OpenAI was founded, and it inspired him greatly).
Eight months after GPT-4's release, other AI labs only then began rolling out models matching its capabilities — meaning researchers are only now starting to use this generation of models for self-play. In summary, the absence of public evidence that synthetic data works at scale doesn't mean it can't work.
Once foundation models can occasionally produce correct answers, reinforcement learning becomes more viable. Task success rates gradually climb from 1% to 10% to 90%, at which point more complex tasks become possible — like 1,000-line pull requests. Models not only succeed more often but can self-correct when they fail, with performance improving through such iterative loops.
Looking back at human evolution, we find striking parallels with how models now use synthetic data for self-improvement. Initially, our ancestors struggled to rapidly grasp and apply new knowledge. But once humans developed language, genetic and cultural co-evolution emerged — remarkably similar to LLMs' synthetic data and self-play loops. Models grow more intelligent through analogous processes, better understanding the complex symbolic outputs of similar models.
Self-play doesn't require models to perfectly judge their own logical reasoning — only to do better than reasoning from scratch, which is exactly what we observe. See Constitutional AI, or try GPT yourself: it's better at analyzing where users went wrong than independently arriving at correct answers.
Original note: If the evaluator is also a performance-limited model like GPT-4, self-play loops may actually work better. In GANs, if the Discriminator is far more powerful than the Generator, it stops providing feedback entirely because it cannot give imperfect but directionally correct signals.
In other words, if the discriminator and generator are too far apart in capability, learning stalls. The discriminator needs enough capacity to recognize generated data, but not so much that it leaves no room for failure — otherwise it cannot provide the generator with useful directional signals to guide optimization.
Virtually every AI researcher I've spoken with is bullish on self-play, though confidentiality prevents them from sharing specifics; they've only hinted at many promising directions to explore. As Anthropic CEO Dario Amodei told me in an interview: "For various reasons I can't go too deep, but there are abundant data sources in the world and many ways to generate data. Personally, I don't think this will be a bottleneck. Actually, it would be better if data were a bottleneck, but it won't be."
Pessimistic view: Constitutional AI, RLHF, and other RL and self-play based methods can both unlock model potential and constrain it when necessary, but no one has yet proven that RL can genuinely improve a model's underlying capabilities.
If self-play or synthetic data approaches fail, breaking through the data bottleneck becomes extremely difficult. Pinning hopes on new architectures is equally unrealistic — a new architecture would need to dramatically improve sample efficiency, and by a margin far greater than the leap from LSTM to Transformer. Yet LSTM has been around for 20 years; the low-hanging fruit was picked long ago, and further breakthroughs are hard-won.
While LLM proponents and stakeholders speak positively about model scaling, this doesn't change the objective fact that we still lack evidence that RL can solve the problem of insufficient data scale.
Moreover, LLMs trained on enormous volumes of data still demonstrate only mediocre reasoning ability, suggesting the models have yet to acquire genuine generalization capability. If a model cannot leverage the equivalent of 20,000 years of human-accumulated data to achieve near-human performance, then even 200 million years of data would not suffice — just as no amount of jet fuel will get an airplane to the moon.
02.
Debate 2: Has Scaling Law Ever Actually Worked?
Optimistic view: This is beyond doubt. Across various benchmarks, model performance has steadily improved across eight orders of magnitude. Even with a million-fold increase in compute, performance degradation remains precisely measurable to multiple decimal places.
GPT-4's technical report notes that they could predict the final GPT-4 model's performance from smaller experimental models trained with similar methods but with far less compute — perhaps one ten-thousandth of the full model's resources.
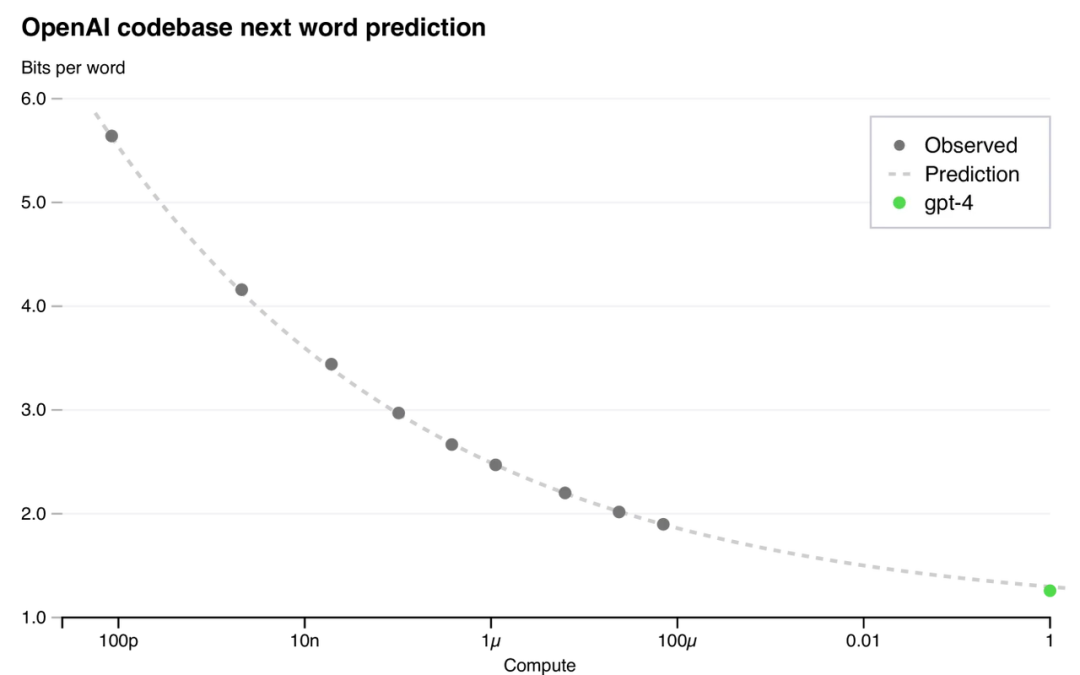
GPT-4 performance prediction
To date, LLMs have maintained remarkably stable performance gains across eight orders of magnitude, and this trend will continue. With the next eight orders of magnitude of scaling, combined with algorithmic and hardware advances, we will likely obtain far more capable models to accelerate AI research itself.
Pessimistic view: We don't care how well models perform at predicting the next token — they're already superhuman at that. What matters is whether the scaling law curve on this task actually indicates meaningful improvement in generalization capability.
Optimistic view: As models scale, benchmarks like MMLU, BIG-bench, and HumanEval all show clear performance gains across diverse tasks.
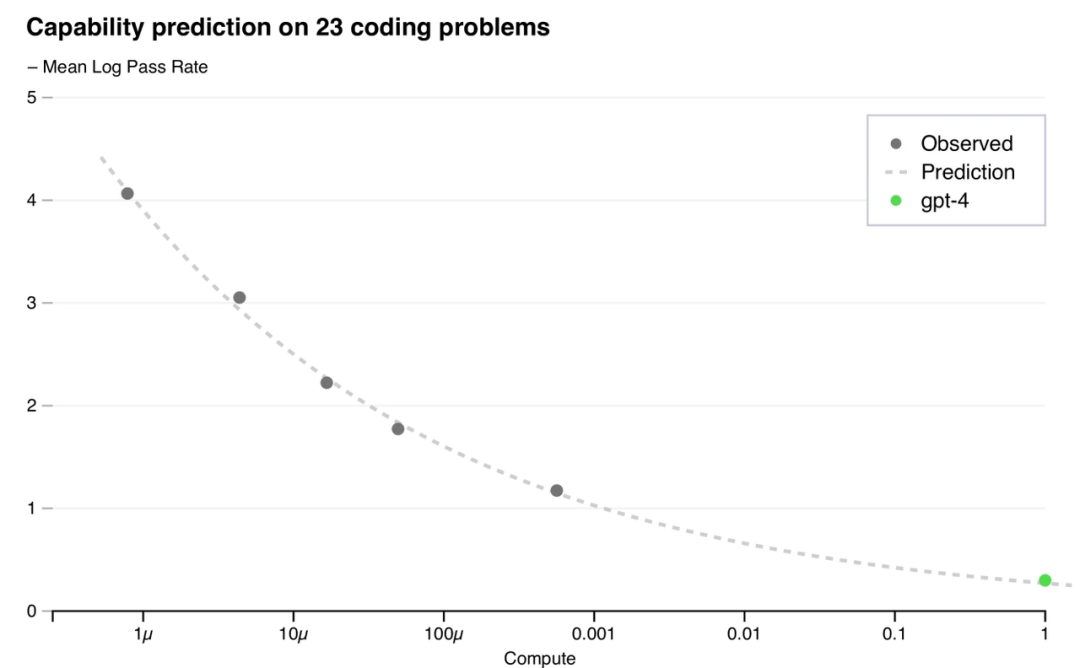
HumanEval benchmark
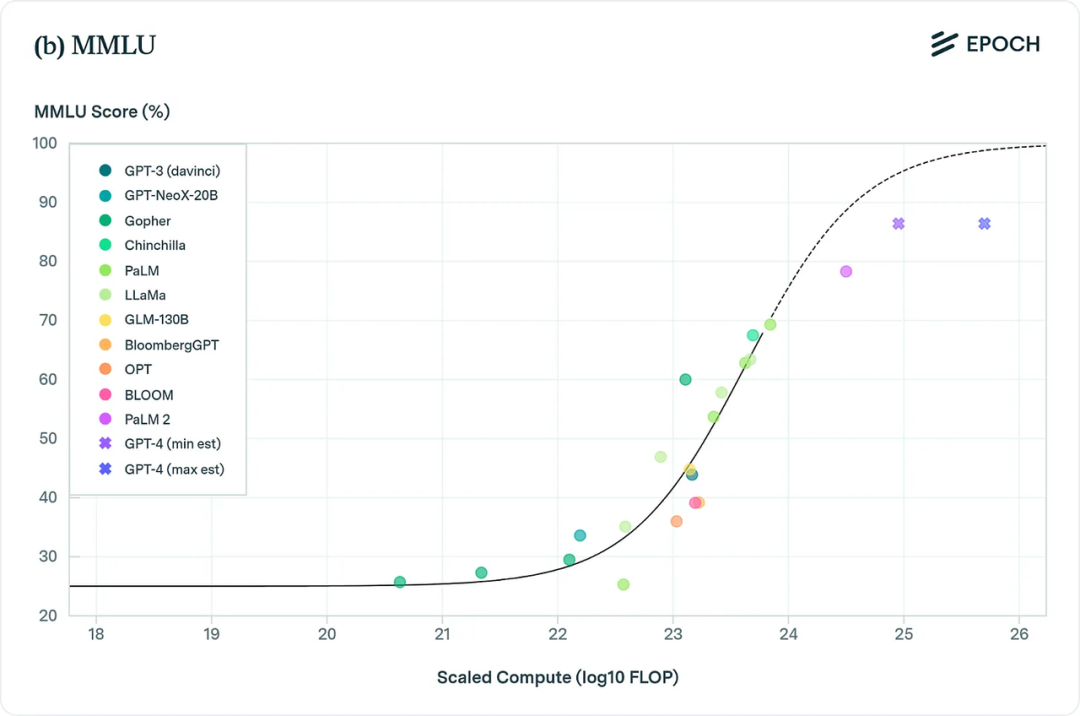
MMLU benchmark
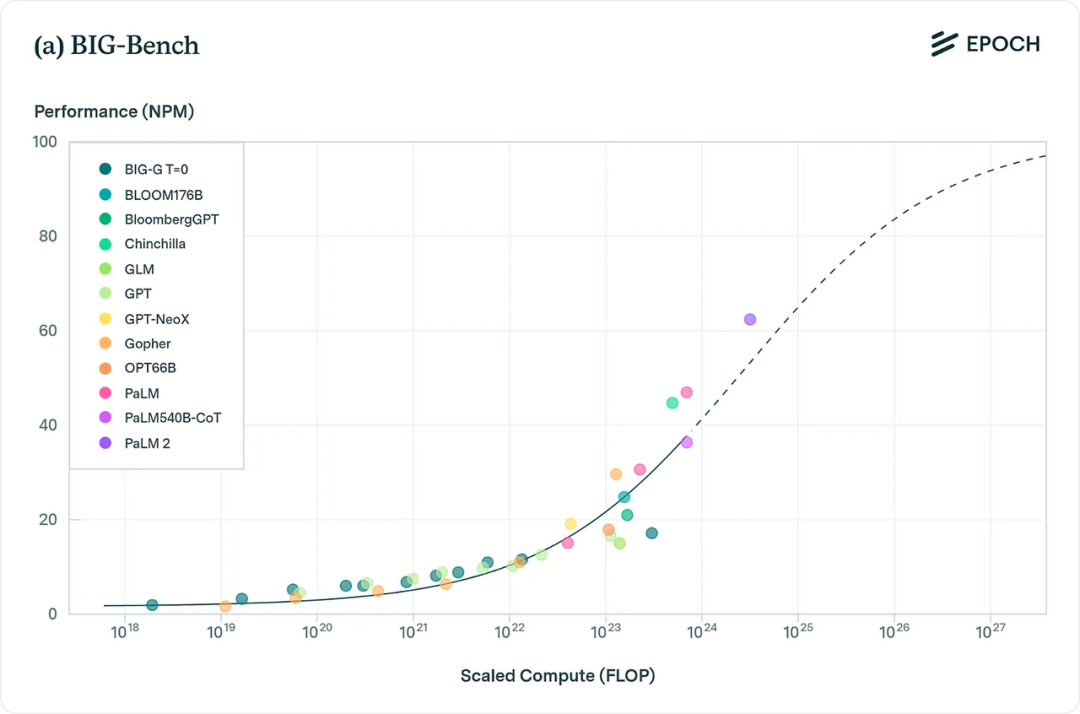
BIG-Bench benchmark
Pessimistic view: But glance at any MMLU or BigBench sample and you'll find answers practically Google-able. These problems test memory more than intelligence. Here are some randomly selected MMLU questions — all multiple choice, with the model simply selecting from four options:
Q: According to Baier's theory, what is the second step in determining whether an act is morally permissible?
A: Determine whether the moral rule prohibiting the act is a genuine moral rule.
Q: Which of the following is always true of a spontaneous process?
A: The total entropy of the system plus surroundings increases.
Q: Who was the U.S. president when Bill Clinton was born?
A: Truman.
The internet is full of miscellaneous text and random facts — fragmented information points detached from specific context. Models trained on this data simply memorize and regurgitate. Does this demonstrate intelligence or creativity?
Performance gains on these artificial benchmarks are already showing plateaus. Despite Google Gemini Ultra having nearly 5x the compute of GPT-4, its performance on standard benchmarks like MMLU and BIG-bench is roughly equivalent to GPT-4's.
Existing benchmarks typically don't measure performance on long-horizon tasks — say, completing a project over the course of a month. Because models are trained on next-token prediction, they have virtually no effective data points for learning extended tasks. SWE-bench (which tests whether LLMs can autonomously complete pull requests) shows poor performance on complex information spanning long timeframes. GPT-4 scored just 1.7%; Claude 2 fared slightly better at 4.8%.
There are essentially two categories of benchmarks today:
-
Those evaluating memory, recall, and interpolation ability — MMLU, BIG-bench, and HumanEval. On these, models match or exceed average human performance, but this is no accurate measure of intelligence, as current models remain far inferior to humans in actual intellect.
-
Those testing genuine long-horizon task execution or complex concept manipulation — SWE-bench and ARC — where models perform poorly.
When a model has been trained on data equivalent to 20,000 years of human input yet still cannot grasp simple logical relationships like "Tom's mother is Mary, so Mary's son is Tom," and when its answers depend heavily on how questions are phrased and ordered, how should we evaluate it?
So I see no point debating whether scaling will work in the future — it's questionable whether scaling has ever worked at all.
Optimistic view: Some argue Gemini Ultra has hit a plateau, but this is deeply unreasonable. Before GPT, some questioned connectionism and deep learning; GPT-4 shattered that skepticism. Gemini's limited improvement over GPT-4 stems primarily from Google lagging behind OpenAI in algorithmic advancement.
Connectionism is a theoretical framework in cognitive science that posits mental functions can be explained through interconnected networks of simple computational units (typically neurons), with applications in psychology, AI, machine learning, and cognitive neuroscience.
Connectionist models are typically implemented through neural networks (biological or artificial), simulating the complex network structures of neurons in the brain. In AI, connectionism has evolved into modern deep learning, where multi-layer neural networks have become powerful tools for solving complex problems like image recognition and natural language processing.
If deep learning and LLMs had fundamental limitations, these would have been visible before they developed common sense and abstract reasoning — not now.
GPT-4 made enormous strides over GPT-3 through 100x scaleup. One hundred times sounds like a lot, but future models may scale to 10,000x — GPT-6 level — at a cost below 1% of world GDP. And this doesn't account for other performance multipliers: improved pretraining compute efficiency (MoE, flash attention), new training methods (RLAI, chain-of-thought fine-tuning, self-play), and hardware advances. Combined, these could yield massive improvements. By this calculation, we might build a GPT-8-level model for just 1% of global GDP.
Consider historical government investment in new technologies:
-
In 1847, British railway investment peaked at 7% of GDP.
-
Following the 1996 U.S. Telecommunications Act, American telecom companies invested over $500 billion (equivalent to $1 trillion today) over five years, primarily laying fiber optic cables, adding switches, and building wireless networks.
I don't understand why people think GPT-8 might be only marginally better than GPT-4. By trend lines, GPT-8 should be 100 million times more capable than GPT-4, and models have already learned to think and understand the world at scales far smaller than this.
Here's how I imagine the future playing out: millions of GPT-8 instances working in concert, collaboratively refining core code, discovering better hyperparameters, and providing high-quality feedback for model fine-tuning. The economic and technical costs of developing GPT-9 would drop dramatically. If this trend continues, we might actually reach the singularity.
03.
Discussion 3: Can models truly understand the world?
Optimistic view: To predict the next token, an LLM must learn the underlying patterns of everything and grasp the relationships between tokens. For instance, the model needs to understand evolution before it can reason about what comes next in a passage from The Selfish Gene; in a short story, it must comprehend a character's psychology before it can guess the subsequent plot.
One interesting finding is that extensive code training can improve an LLM's language reasoning abilities, suggesting that models can extract general reasoning patterns from code. This implies not only that language and code share similar logical structures, but also that unsupervised learning can discover and exploit these structures to enhance LLM reasoning capabilities.
Gradient descent aims to find the most efficient way to compress data. The most efficient compression method is also the one that achieves the deepest understanding of that data. If you can compress a physics textbook exceptionally well, for example, you can predict what unwritten sections might contain — because you've fundamentally grasped the underlying scientific principles.
Pessimistic view: Intelligence includes but is not limited to compression, and compression does not equal intelligence. We consider Einstein brilliant because he developed relativity, but that doesn't mean Einstein plus relativity constitutes a more intelligent system. Nor can we say Plato was less intelligent than me simply because he lacked knowledge of modern biology or physics.
Original note: The "intelligence = compression" formulation isn't really accurate either. Information compression cannot capture Einstein's creativity and profound insight. Stochastic gradient descent (SGD) gradually summarizes semantic patterns within a smooth loss function, whereas Einstein found the correct equations of relativity amid a sea of incorrect permutations and variations. Scaling Law skeptics see no reason to believe SGD could become as intelligent as Einstein through "compression."
Therefore, if an LLM is merely the compressed output of another process (SGD), we have no way to assess the compression capability of the LLM itself, let alone judge its intelligence level.
Optimistic view: We don't currently need a perfect theory proving that scaling will remain effective. Looking back at history, we had steam engines for over a century before we fully understood thermodynamics. Technological progress typically produces inventions first, with theoretical refinement following later. We should expect the same for intelligence technology.
No law of physics guarantees Moore's Law will hold forever. As technology advances, we inevitably encounter new challenges — but that doesn't mean Moore's Law has failed. Going forward, the R&D teams at major companies like TSMC, Intel, and AMD will find new solutions to these problems, allowing scaling laws to continue driving progress for decades to come.
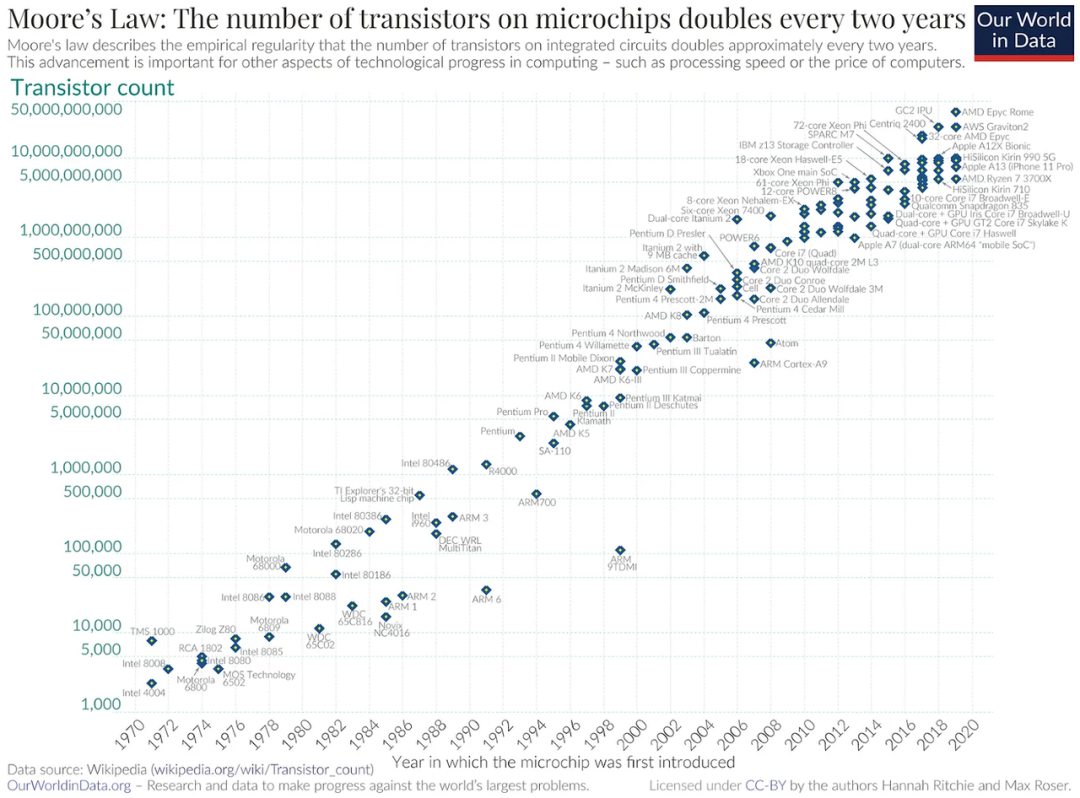
The continuation of Moore's Law
04.
Conclusion
Finally, I'd like to share my personal perspective. For those who have long believed in scaling laws, AI's development to date looks far more coherent. It's been suggested that GPT-4's superior performance stems from training with an idiom library or lookup table, but such tools are difficult to generalize — yet the pessimistic arguments above don't address this possibility.
People like Ilya, Dario, and Gwern, who have faith in scaling laws, foresaw the recent leap in AI capabilities as far back as twelve years ago. What seems certain is that appropriate scaling can indeed enable us to create a revolutionary AI — that is, if we reach the minimum irreducible loss on the curve (the error that persists even after optimal model training), we can train an intelligent AI capable of performing most cognitive work, including assisting in the iteration of higher-intelligence AI.
However, real life tends to be far more complicated than textbook theory. Some things that look feasible on paper — nuclear fusion, flying cars, nanotechnology — prove extremely difficult to actually achieve. Similarly, if self-play or synthetic data methods turn out to be unviable for improving model performance, models may simply be unable to optimize further and will fall short of the theoretical minimum loss point. Moreover, the theoretical basis for scaling's continued effectiveness remains unclear. While benchmark tests show scaling improves model performance, the standards of these tests themselves are contested.
Overall, my preliminary assessment is that two scenarios are likely: First, by continuing to scale and improving algorithms and hardware, we achieve AGI before 2040 — probability: 70%. Second, the LLMs and related technologies we're currently researching won't work, and we'll hit a bottleneck that's extremely difficult to break through — probability: 30%.
It should be noted that AI labs typically don't publish their research findings for confidentiality reasons, so there may be important information about AGI that I'm unaware of. And according to friends working at AI labs, currently published information isn't particularly valuable, so the assessment above may well be inaccurate.
05.
Appendix
Below are some additional questions I've considered, though I'm uncertain what they imply for scaling.
Can models achieve insight-based learning?
Optimistic view: With continued scaling, models will naturally develop more efficient meta-learning methods, analogous to human learning and "grokking" capabilities. This "grokking" typically occurs when models are overparameterized and severely overfit to data. This resembles how humans learn new things — we use intuition and existing knowledge frameworks to process new information, updating our frameworks as observations accumulate. When processing large volumes of diverse data, models identify the most general, most transferable methods. In this way, they can learn through this kind of "grokking," ultimately achieving deep understanding.
Pessimistic view: Neural networks do possess some degree of "grokking" ability, but their approach to learning new knowledge pales in comparison to humans. Tell a child that the sun is the center of the solar system, and she'll immediately understand what's happening with the stars she sees at night. But feed a model Copernican theory without prior astronomy training, and it won't instantly apply this new knowledge to related phenomena. Models need to learn repeatedly across many different contexts before slowly "grokking" these fundamental concepts.
So far, we haven't enabled models to achieve insight-based learning. And because we currently use simple optimization methods like gradient descent, I even doubt whether models can truly learn at all. We feed data to models again and again, letting them gradually approach an optimum. But enabling this kind of learning capability would be like asking a model to leap directly from flat ground to the summit of Mount Everest — a qualitative leap we currently cannot achieve.
Does primate evolution provide evidence for scaling?
Chimpanzees may have intelligence problems far more severe than the so-called "reversal curse," but this doesn't mean primate brains have fundamental defects, or that they couldn't resolve these issues through increased brain capacity and fine-tuning.
Suzana Herculano-Houzel's research shows that the number of neurons in the human brain roughly matches what you'd expect from proportionally scaling up primate brains. Rodents and insectivores are entirely different — even with larger brain volumes, these animals have far fewer neurons.
This suggests that compared to other species' brains, primate neural architecture possesses superior scalability in some respects, analogous to how Transformers scale better than LSTMs and RNNs. In the world primates inhabit, even modest intelligence gains significantly enhance competitive survival ability. This is because intelligence enables them to better understand information learned through observation, experimentation, and social interaction, thereby more effectively improving their survival skills.
Article republished from Overseas Unicorn, author: Dwarkesh Patel, translated by: Lavida, Chenxin




5Y Capital seeks out, supports, and inspires solitary entrepreneurs, providing everything from spiritual to operational support. We believe that if the "crazy" you in others' eyes begins to be believed in, the world will become a different place.
BEIJING · SHANGHAI · SHENZHEN · HONG KONG
