Heading into 2024: How We Think About AI Startup Investing | FreeS Fund Year-End Special

From 2023 to 2024: AI's Advances, Challenges, and New Opportunities
In December 2023, Nature published its annual "10 People Who Mattered in Science" list. For the first time ever, the selection included something "non-human" — ChatGPT. Nature noted: "Although ChatGPT is not a person and does not fully meet the selection criteria, we decided to make an exception to acknowledge that generative AI is fundamentally altering the trajectory of scientific development."
 ▲ Image source: Nature
▲ Image source: Nature
On the 2023 tech landscape, generative AI undoubtedly marked a pivotal inflection point. Its development has not only drawn widespread industry attention but also exerted profound influence on the global economy, social structures, and even our expectations for the future.
This is an AI revolution that every ordinary person can participate in. From the continued evolution of large language models to the broad application of AI technology across industries, to the ongoing tug-of-war between open-source and closed-source strategies, every step of AI's development is sketching the contours of future trends.
Facing this surging wave, the Chinese government has rolled out a series of policies supporting AI development through documents such as the 14th Five-Year National Informatization Plan and Guiding Opinions on Accelerating Scenario Innovation to Promote High-Quality Economic Development Through High-Level AI Application. China's AI industry has also grown rapidly, giving rise to a cohort of internationally competitive AI enterprises.
At year's end, we look back on the development of generative AI in 2023, examining its impact on humanity, industry dynamics and future trends, and entrepreneurial and investment opportunities. This is not merely a retrospective of the past year in AI, but also a meditation on where AI is headed.
First, the core takeaways:
- Before a truly valuable AI application ecosystem flourishes, betting on core technology sources like foundation models and "pick-and-shovel" companies makes a certain amount of sense. But the AI applications currently thriving are equally a wellspring of value creation and the starry sea we should be striving toward.
- Closed-source large language models like OpenAI's charge application fees to apps that plug into their APIs. To reduce this traffic cost burden, app companies have two main options: use open-source models to train their own smaller models, or optimize their business models to offset these fees.
- As AI technology advances, the nature of work will transform. AI may restructure not only how people work, but also how the language models themselves work.
- Learning to wield a tool as extraordinarily intelligent as AI is an enormous challenge for humanity. But we needn't be overly pessimistic — AI's capabilities have boundaries.
- In AI technology, the US and China have each carved out distinctive development paths. The top tier of American large language models has largely solidified, while China's foundation model landscape has blossomed in a hundred flowers. For China, the more important priority is to vigorously develop its AI application ecosystem.
- AI Agents represent a noteworthy entrepreneurial direction. An AI Agent is intelligent software capable of autonomously executing tasks, making independent decisions, proactively exploring, self-iterating, and collaborating with other agents.
- Although large language models have achieved numerous technical breakthroughs, many areas remain ripe for iteration and improvement: reducing hallucinations, extending context length, achieving multimodality, embodied intelligence, complex reasoning, and self-iteration, among others.
- Several key points for entrepreneurship in AI applications: create high-quality native new application experiences; be more forward-looking, identify non-consensus views, and be disruptive; focus on user growth and commercialization potential; seize macro trend dividends; maintain a safe distance from foundation models and develop your own operational depth; above all, the team matters most.
- Startup companies must dare to do what is right rather than what is easy, in domains where consensus has yet to form.
We hope this offers fresh perspectives. If you are an entrepreneur or practitioner in the AI field, you are welcome to contact the author of this article, Chen Shi, Investment Partner at FreeS Fund (chenshi@freesvc.com).


Engagement Giveaway Looking back at 2023, what new opportunities have you observed in the AI field?
We welcome your thoughts in the comments. Through 17:00 on January 3, 2025, the 5 readers with the most thoughtful comments will receive a copy of The Deep Learning Revolution: From History to the Future. This book was selected for Douban's annual book list.


/ 01 / What Was New in AI in 2023?
From an industry perspective, AI development to date can be divided into two phases: the 1.0 phase focused primarily on analysis and judgment, while the 2.0 phase emphasizes generation. The representative models of the 2.0 phase are large language models and image generation models, with the Transformer and Diffusion Model algorithms driving the advancement of generative AI. (For more thoughts on generative AI, please read "After the ChatGPT Explosion, Where Is AIGC Headed? | FreeS Report 28")
For most of 2023, the products of startup OpenAI held the top spot for high-performance large language models, particularly after the March release of the GPT-4 language model, when it virtually lapped the field. But Google successfully launched its latest large language model Gemini in December, creating a duopoly with GPT-4.
In the AI field, the open-source model community has never been absent. Supported by Meta's (formerly Facebook's) open-source large language models LLaMA and LLaMA 2, the open-source community has pursued intensive research and engineering iteration — for instance, attempting to achieve capabilities comparable to large models with smaller ones; supporting longer context windows; and employing more efficient algorithms and frameworks for model training, among other efforts.
Multimodality (images, video, and other media formats) has become a hot research topic in AI. Multimodality encompasses both input and output dimensions. Input refers to enabling language models to comprehend information embedded in images and video; output refers to generating media formats beyond text, such as text-to-image generation. Given that human capacity to generate and acquire data is finite and may not sustainably support AI training, future language models may need to be trained on synthetically generated data.
In AI infrastructure, NVIDIA has emerged as the industry leader by riding massive GPU demand, joining the $1 trillion market cap club. However, it will face fierce competition from old rivals AMD and Intel, as well as from tech giants Google, Microsoft, and OpenAI and other foundation model upstarts.
Beyond foundation models, the industry has strong demand for various types of AI applications. Generative AI has made significant strides in images, video, programming, voice, and intelligent collaboration applications, among other domains.
Global users have shown tremendous enthusiasm for generative AI. ChatGPT reached 100 million monthly active users in just two months. By comparison, smartphone-era super apps required substantial marketing budgets and took far longer: TikTok took 9 months, Instagram 2.5 years, WhatsApp 3.5 years, and YouTube and Facebook 4 years each.
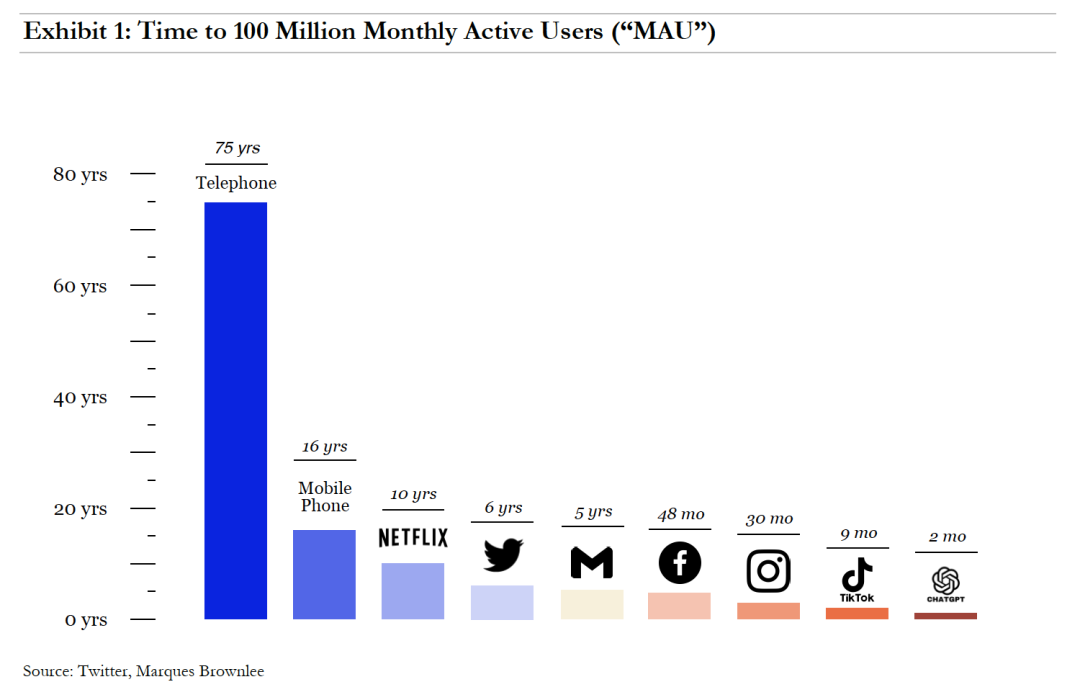
▲ Time for different types of tech applications to reach 100 million monthly active users. Image source: 7 Global Capital
Venture capital institutions are also pouring significant capital into supporting AI progress. According to statistics from US investment firm Coatue, through November 2023, VC institutions had invested nearly $30 billion in AI, with approximately 60% going to foundation model upstarts like OpenAI, about 20% to infrastructure supporting and delivering these models (AI cloud services, semiconductors, model operations tools, etc.), and roughly 17% to AI application companies.
▲ Image source: Coatue
Before a truly valuable AI application ecosystem flourishes, this investment logic of betting on core technology sources and "pick-and-shovel" companies makes a certain amount of sense. But the AI applications currently thriving are equally a wellspring of value creation and the starry sea we should be striving toward.
Multiple Technical Breakthroughs in Multimodal Generation
In 2022, following the open-source release of Stable Diffusion, we saw a flood of text-to-image products hit the market. That year could be considered the year the image generation problem was solved.
Then in 2023, AI technologies for voice recognition and audio production also made significant strides. Today, AI speech recognition and synthesis are highly mature — synthesized voices are nearly indistinguishable from human ones.
As technology continues to advance, video generation and processing will be the next frontier for AI development. Already, we've seen multiple technical breakthroughs in text-to-video, with AI demonstrating real potential and possibility in video content creation. Using emerging AI video tools like Runway Gen-2, Pika, and Stanford University's W.A.L.T model, users can input a description of an image and receive a video clip in return.
NVIDIA engineer Jim Fan believes that 2024 will likely be the year AI makes major progress in video.
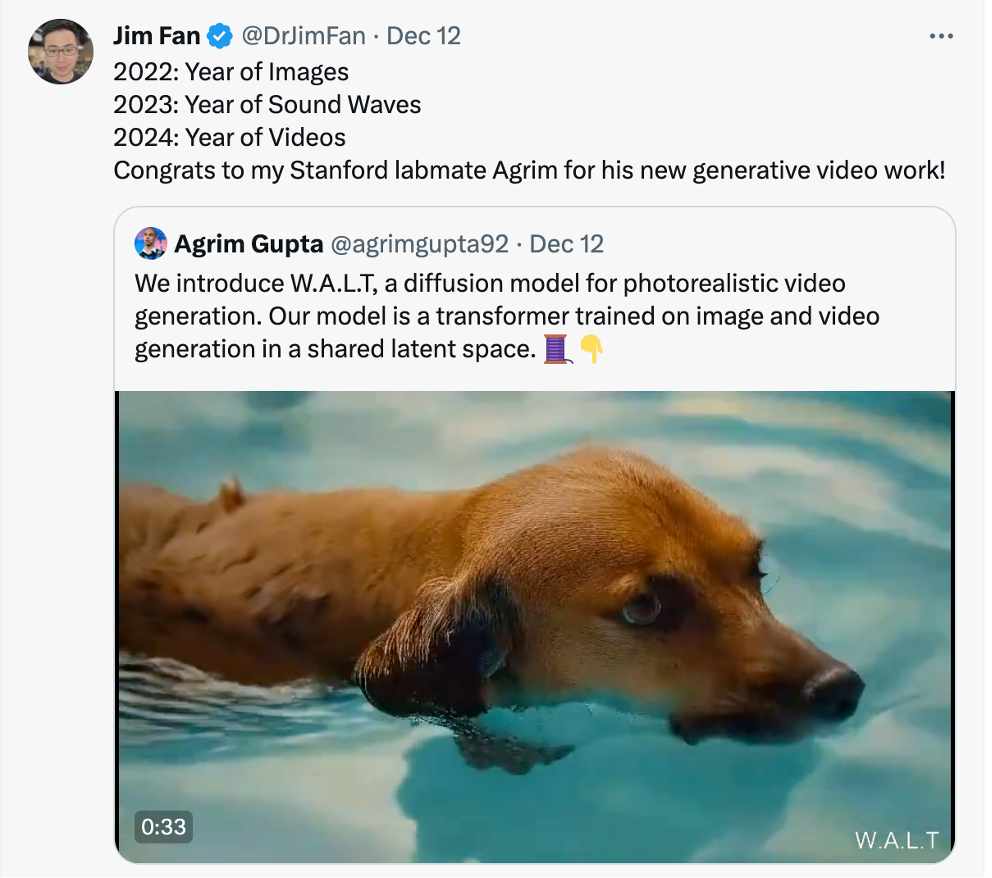 ▲ Image source: X.com
▲ Image source: X.com
If we think about media formats along a different dimension, a two-dimensional image becomes video when you add a time dimension. Add a spatial dimension, and it becomes 3D. Render that 3D model, and you get video with far more precise controllability. AI may eventually conquer 3D modeling too, though that will take longer.
"Compression Is Intelligence"
In 2023, OpenAI Chief Scientist Ilya Sutskever presented an idea in an external talk: "compression is intelligence" — the higher the compression ratio a language model achieves on text, the more intelligent it is.
Compression as intelligence may not be rigorously precise, but it offers an intuitively compelling explanation: the most extreme compression algorithms, to squeeze data to its limits, must necessarily abstract higher-level meaning on the basis of thorough understanding.
Take Llama 2-70B, Meta's 70-billion-parameter language model — one of the largest open-source language models available.
Llama 2-70B was trained on roughly 10 terabytes of text, and the resulting model is a 140 GB file — a compression ratio of about 70x (10T/140G).
In everyday work, when we compress large text files into Zip archives, we typically get compression ratios of about 2x. The contrast gives some sense of Llama 2's compression power. Of course, Zip uses lossless compression while language models use lossy compression, so it's not an apples-to-apples comparison.
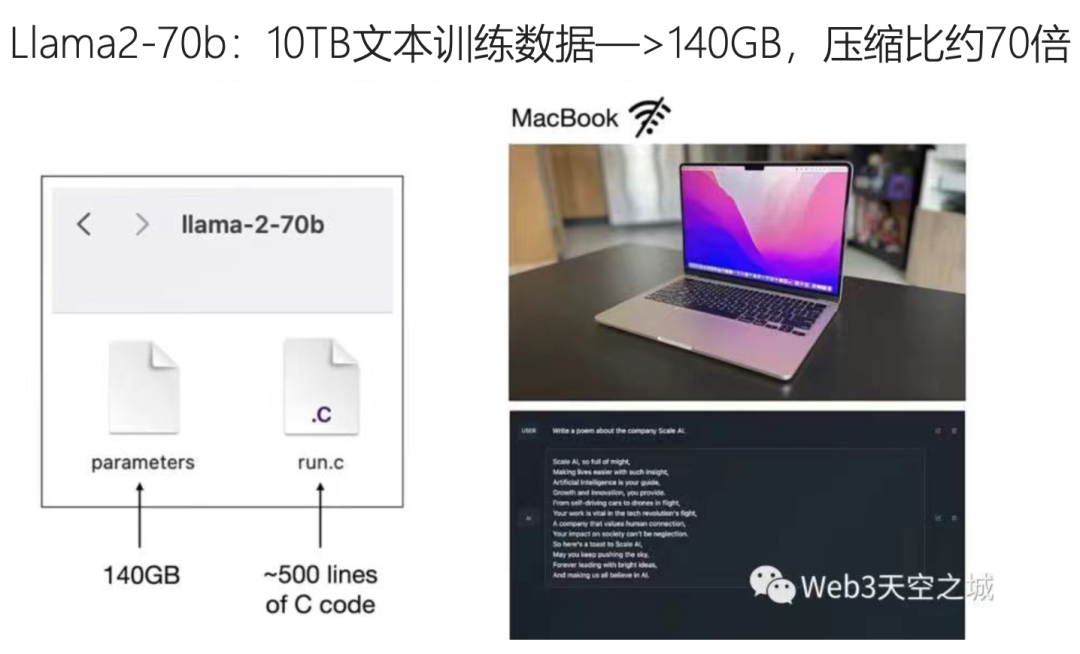
▲ Screenshot from OpenAI VP Andrej Karpathy's presentation. Image source: Web3 Sky City
The remarkable thing is that a 140 GB file can capture human knowledge and intelligence. Most laptops can store 140 GB. With sufficient computing power and VRAM, plus a roughly 500-line C program, you can run a large language model on a laptop.
Open-Source Ecosystems and the LLM Traffic Tax
Open Research and Open-Source Ecosystems Are Critical Drivers of AI Development
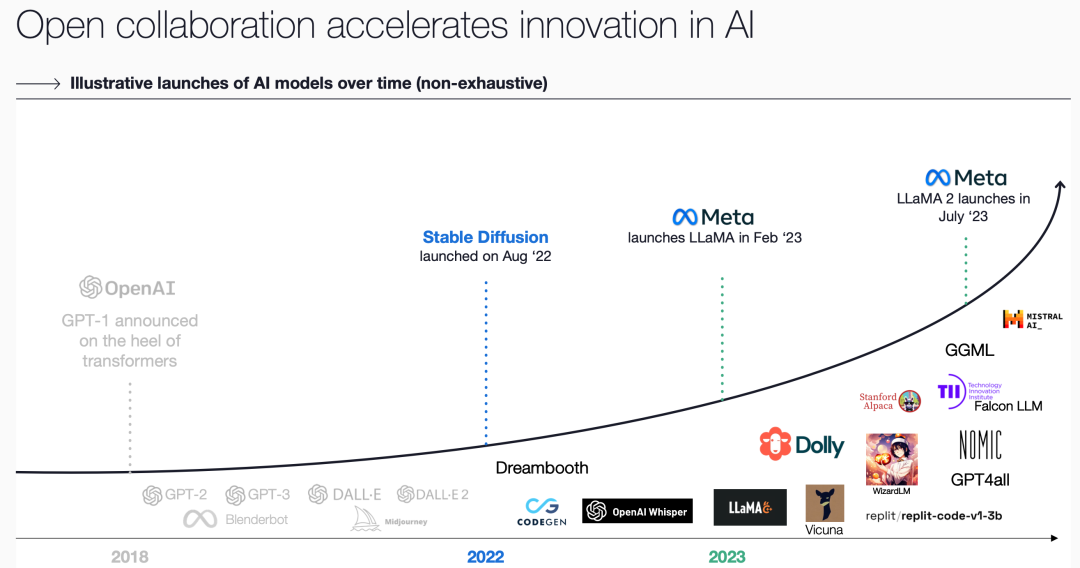 ▲ Open-source ecosystems drive AI technology innovation. Image source: Coatue.com
▲ Open-source ecosystems drive AI technology innovation. Image source: Coatue.com
Open research is the foundation of AI's technological progress. The world's top scientists and engineers publish extensively on sites like arXiv, sharing their technical practices. Whether it was the early AlexNet convolutional neural network, Google's Transformer that established the algorithmic foundation, or the model practice papers from OpenAI, Meta, and others — each represented a major breakthrough in research and technology, guiding the direction of AI development.
The evolution and iteration of open-source communities deserve particular attention. Supported by open-source large language models, researchers and engineers can freely explore new algorithms and training methods. Even closed-source large language models learn from and draw upon the open-source community.
In a sense, the open-source community has achieved a kind of technological democratization, allowing people worldwide to share the latest advances in AI.
The "Traffic Tax" of Large Language Models
Returning to commercial fundamentals, training large language models is extraordinarily expensive. Take GPT as an example: according to Far Eastern Research Institute statistics, training GPT-3 cost over $10 million, GPT-4 cost over $100 million, and the next generation could reach $1 billion. Beyond that, running these models and delivering services externally consumes substantial computing power and energy.
The business model for large language models is MaaS (Model as a Service). It charges for intelligence output based on input/output traffic (measured in tokens). Given the steep training and operating costs, these traffic fees are likely to keep climbing.


▲ Image source: openai.com
OpenAI's pricing for some models is shown above. One rough estimate suggests that at median GPT-3.5 Turbo usage levels, an AI app would need to pay OpenAI roughly 0.2 RMB per daily active user per day. Extrapolating from there, an app with ten million DAU using GPT's API would face a daily traffic bill of 2 million RMB to OpenAI.
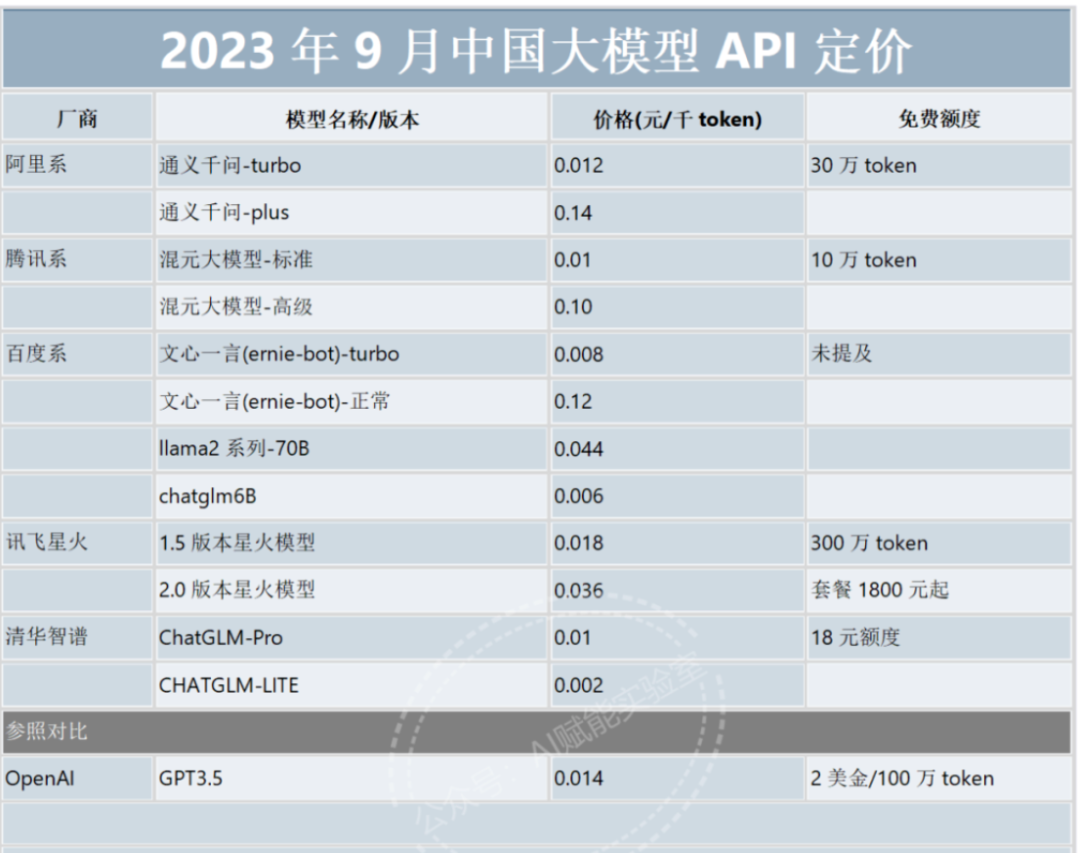 ▲ Image source: WeChat public account @AI Empowerment Lab
▲ Image source: WeChat public account @AI Empowerment Lab
Domestic Chinese LLM pricing, shown above, is roughly comparable to OpenAI's. Some smaller models are cheaper, but with performance trade-offs.
These traffic costs shape how AI applications design their business models. To reduce the burden, some startups consider leveraging open-source ecosystems to build their own medium or small models to handle the bulk of user requests, only calling on large language models when user needs exceed what the smaller model can handle.
Such smaller models may be deployed directly on the user-facing device itself — becoming "edge models." Edge models place heavy demands on hardware integration. Going forward, our computers and phones may more widely integrate GPU and similar chips capable of running small models locally. Google and Microsoft have already released small models that run on-device. Nano is the smallest version of Google's Gemini model, designed specifically to run on mobile devices without an internet connection, operating locally and offline.
How Is AI Affecting Human Society?
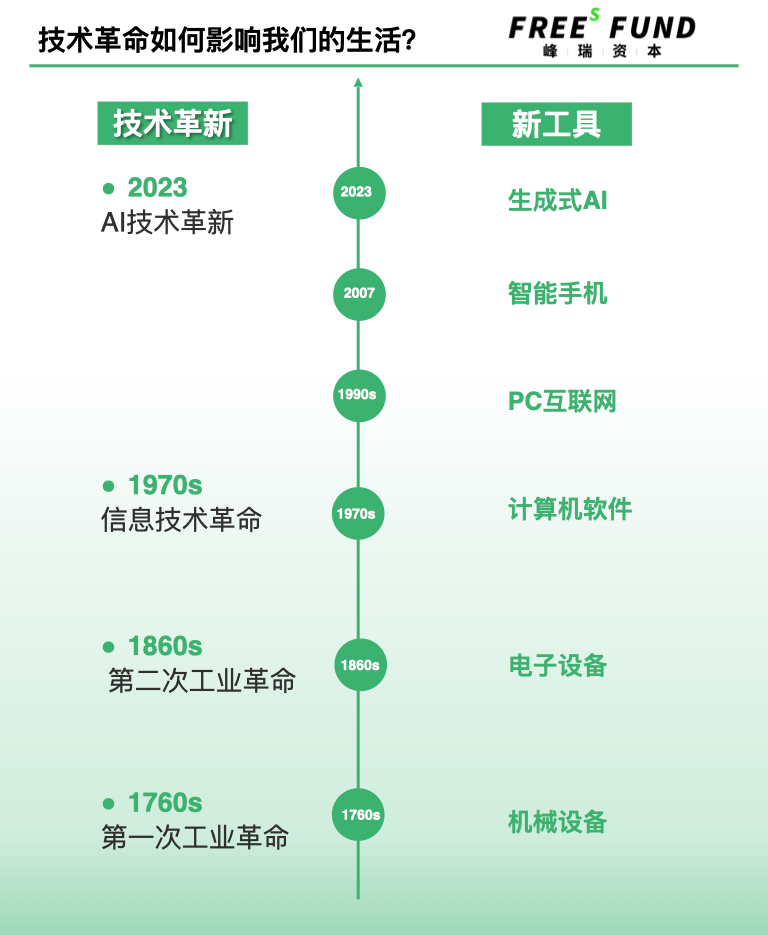
Every Technological Revolution Brings New Efficiency Tools
Human history has seen several major technological revolutions. The First Industrial Revolution around 1760 produced mechanical equipment. The Second Industrial Revolution after 1860 produced electronic devices. After 1970, we experienced three more waves — computer software, PC internet, and smartphones — collectively termed by some as the Third Industrial Revolution or the information revolution.
The generative AI revolution beginning in 2023 may qualify as a Fourth Industrial Revolution: we have created new intelligence. Generative AI is a new tool for human cognition and reshaping the world, a new layer of abstraction.
Historical experience shows that every technological revolution dramatically boosts human productivity. After the First and Second Industrial Revolutions, the natural world gained two abstract tool layers: mechanical and electronic. In the 1970s, the information technology revolution introduced a new abstraction layer — software. Through software, people began understanding, reshaping, and interacting with the world more efficiently. PC internet and smartphones then further advanced software technology.
How Will AI Affect People's Work?
Beyond efficiency gains, we must also attend to how machines replace human labor. Statistics show that before Britain's First Industrial Revolution, agricultural workers comprised roughly 75% of the population; after industrialization, this fell to 16%. After America's information revolution, industrial workers dropped from 38% to 8.5%, with most transitioning to white-collar roles. This AI intelligence revolution, however, strikes first at white-collar workers themselves.
As AI technology advances, organizational forms and collaboration patterns in business society may undergo a series of changes.
First, companies may trend toward smaller sizes. Business outsourcing could become ubiquitous. For instance, companies might outsource R&D, marketing, and other functions.
Second, workflows themselves may be restructured — standard operating procedures (SOPs) could evolve. People vary in their abilities and energy levels, so workflows exist to help us work more efficiently and stay in our lanes. Researchers are already exploring how workflows should adapt when AI can substitute for certain functions. Current language models also have room for efficiency and capability gains; they too may need workflow orchestration to collaborate effectively.
Beyond technical skills, developing other capacities becomes essential. Cultivating taste and discernment, for instance, enables AI to assist you in generating better proposals or creative work. Sharpening critical thinking helps you better evaluate and verify AI-generated content.
We should embrace AI more proactively as an auxiliary tool in work and life — a copilot — fully leveraging its potential and strengths. (For more reflections on the future of work, see How Will Humans Work in the Future? | FreeS Report 26)
AI's Capabilities Have Boundaries
Amid rapid AI development, many have raised AI doomerism, worrying about negative impacts on humanity. It's true that we've invented tools that appear smarter than ourselves. Controlling such "silicon-based life forms" is undoubtedly a massive challenge for humanity. Scientists are working on solutions, and OpenAI has published papers exploring similar concerns.
But we needn't be so pessimistic. At least for now, the degree of digitalization in human society can limit AI's capabilities.
Today's large language models are trained primarily on vast amounts of text data. Text is highly digitized and, through human abstraction, information-dense — which is why AI trains so effectively on it.
Outside text space, however, AI intelligence faces significant constraints because it hasn't been trained on corresponding data. So we don't need to worry too much for the time being; AI isn't that powerful or comprehensive yet. We have ample time to familiarize ourselves with it and adapt, finding ways to coexist amicably with silicon-based intelligence.
Looking Ahead to 2024: How Will Large Language Models and AI Applications Evolve?
The Leading LLM Camp
Globally, large language models show pronounced regional characteristics. The U.S. and China, for example, have developed along distinct paths. America's leading LLM camp has largely solidified, concentrated among a few major tech companies or their alliances with top model startups. The U.S. AI sector has entered a high-cost arms race where new entrants face steep barriers.
China's large language model landscape, by contrast, has bloomed in a hundred flowers — with over a hundred projects claiming active LLM development. China may rely more heavily on open-source ecosystems, developing new language models through secondary innovation.
Currently, no country outside the U.S. has developed an LLM comparable to GPT-4. A gap remains between China and the U.S. in foundational model technology.
But the global AI contest is far from decided. For China, the most important priority is vigorously developing its AI application ecosystem. In the internet and digital economy eras, China was already a star performer in applications, exporting relevant practices overseas. Keeping pace with the latest LLM advances, then letting a flourishing application ecosystem drive reverse breakthroughs in underlying technology, may be one viable approach.
How Will Large Language Models Develop?
Despite numerous technical breakthroughs, many dimensions remain open for iteration and improvement: reducing hallucinations, extending context length, achieving multimodality, embodied intelligence, complex reasoning, and self-improvement.
First, hallucinations. These can be understood as erroneous outputs; Meta defines them as "confident falsehoods." The most common cause is insufficient knowledge or data density in what the language model has ingested. Yet hallucinations can also be viewed as creativity — just as poets produce marvelous verses after wine, AI's hallucinations may yield wondrous content.
Methods to reduce hallucinations include: training on higher-quality corpora; improving accuracy and adaptability through fine-tuning and reinforcement learning; and incorporating more background information in prompts so models can understand and respond to questions more accurately.
Second, extending context length. Context length is akin to a language model's brain capacity — currently typically 32K, with the highest at 128K, or less than 100,000 Chinese characters or English words. For language models to comprehend complex texts and handle complex tasks, this is far from enough. Next-generation models will likely prioritize expanding context length to enhance complex task processing.
Third, multimodality. Humans rely primarily on vision to acquire information, while current language models train mainly on text data. Visual data can help language models better understand the physical world. In 2023, visual data was scaled up for model training. GPT-4 introduced multimodal data; Google's Gemini reportedly used substantial image and video data. From Gemini's demo videos, its multimodal interaction appears noticeably improved, though gains in complex reasoning and general intelligence aren't yet evident.
Fourth, embodied intelligence — intelligent systems that perceive and act through physical bodies, gathering information from environments, understanding problems, making decisions, and taking action. The concept isn't that complicated: all life on Earth could be considered embodied intelligence. Humanoid robots, for example, are one form. Embodied intelligence essentially extends AI with movable "limbs."
Fifth, complex reasoning. Typically, GPT produces answers in one shot, without obvious multi-step reasoning or iterative backtracking. When humans tackle complex problems, we jot down steps on paper, working through them repeatedly. Researchers have devised methods like Tree of Thought to teach GPT complex multi-step reasoning.
Finally, self-improvement. Current language models still rely on humans to design algorithms, provide compute, and feed them data. Looking ahead, could language models achieve self-improvement? This may depend on new training and fine-tuning methods such as reinforcement learning. Supposedly OpenAI is experimenting with a training method codenamed "Q*" to study AI self-improvement, though concrete progress remains unknown.
Large models remain in a high-speed development phase with substantial room for improvement. Beyond what's listed, many issues await resolution: interpretability, safety enhancement, aligning outputs with human values, and more.
Future Application Software — AI Agent
In September 2023, Sequoia Capital published "Generative AI's Act Two" on its website, noting that generative AI had entered its second phase. The first phase focused on language models and simple surrounding applications; the second shifts toward developing genuinely novel intelligent applications that solve real customer needs.
Future application software may gradually transition toward AI Agent — intelligent software capable of autonomously executing tasks, making independent decisions, proactively exploring, self-improving, and collaborating with other agents. Existing traditional software may require corresponding adjustments. Compared to traditional 1.0 software, AI Agent can deliver more authentic, high-quality one-to-one service experiences.
The challenge in developing AI Agent is that language models remain too immature and unstable. To create good application experiences requires layering smaller models, rule-based algorithms, and even human-in-the-loop services atop the language model, delivering stable experiences in vertical scenarios or specific industries.
Multi-Agent collaboration has become a hot research direction. Based on standard operating procedures, multiple collaborating AI Agents can produce superior results compared to calling a language model alone. The intuition is straightforward: each Agent has its own strengths, weaknesses, and specializations — just like human division of labor. Combined through new SOPs, they perform their respective roles, inspire and supervise each other.
Entrepreneurship and Investment Opportunities
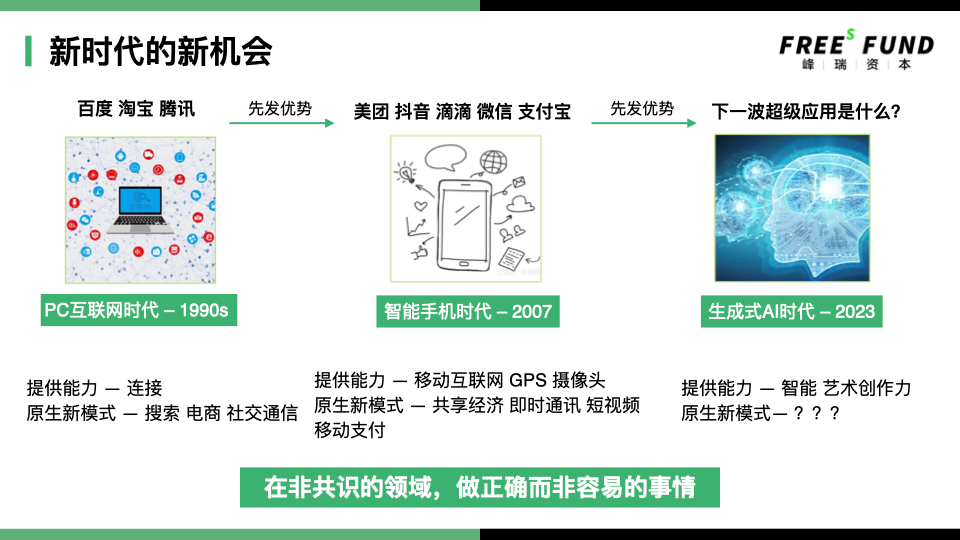
Doing What's Right, Not What's Easy, in Non-Consensus Domains
In a new era, startups need to think carefully about what natively new business models this technological revolution enables, and which opportunities belong to new entrants versus incumbent leaders.
We can look back at how the PC internet and smartphone eras created new opportunities.
The PC internet era offered primarily connectivity — global networking of PCs, servers, and other devices. Natively new models from this era included search, e-commerce, and social communication, producing industry leaders like Baidu, Alibaba, and Tencent.
The smartphone era offered a new foundation: most people now carried a mobile device with internet connectivity, GPS, cameras, and more. This enabled new models like the sharing economy, instant messaging, short-video sharing, and mobile financial payments. Incumbent leaders from the previous era had strong first-mover advantages, capturing many new-model opportunities — Tencent and Alibaba built WeChat and Alipay respectively. Yet we also saw newcomers like Meituan, Douyin, and DiDi achieve massive success. How?
I believe their success came down to this: doing what's right, not what's easy, in non-consensus domains.
Take Meituan and Douyin. Meituan's native new model was "food delivery," part of the "sharing economy" and "O2O (online-to-offline)" segment. On one side, countless restaurants; on the other, diverse consumers; in between, thousands of riders — a "heavy model." Early internet giants preferred and excelled at "light models." Entering the food industry was "non-consensus." The delivery fulfillment chain was too long, too hard to digitize, too difficult to operate with precision. But Meituan ultimately succeeded, and these hard things became its core competitive advantages and moats.
Douyin chose "short-video sharing," part of the then-trending "creator economy." Douyin's greatest "anti-consensus" move was bridging video creator economy with trillion-scale e-commerce GMV, achieving scalable, efficient conversion.
Before the rise of live e-commerce, there were two kinds of livestreaming: gaming streams and influencer streams, with monetization driven mainly by viewer tips. The economic scale of this model was tiny — it couldn't support that many talented creators. But through a combination of recommendation algorithms, creator ecosystem development, merchant ecosystem development, building the Douyin Shop closed loop, and optimizing content-to-commerce conversion, Douyin made the massive commercial flywheel of converting content into e-commerce actually work. Once it worked, Douyin could invite the largest number of the most talented creators in the country to produce content on its platform, rewarding them with enormous e-commerce sales revenue.
That's why when TikTok, Douyin's international version, expanded overseas, many local short-video and livestreaming platforms couldn't compete. Because TikTok isn't just a video content platform with creators on one side and consumers on the other — it's a new hybrid of creator economy and massive e-commerce GMV conversion. It's a new species with compound competitive advantages.
To sum up: startups should dare to choose and enter non-consensus fields, and in difficult environments, work hard to make things happen.
Startup Direction and Key Points

When it comes to startup direction, the large model space is dominated by giants, so it's unlikely to be entrepreneurs' first choice. Between large models and applications lies a "middle layer" — mostly infrastructure, application frameworks, and model services. This layer is vulnerable to being squeezed from both directions by models and applications, with giants already present in some areas, leaving limited room for startups.
Given the current technology and business environment, we tend to believe we should vigorously develop the AI application ecosystem.
The image above shows our generative AI-related portfolio companies, including: a new DevOps platform designed for language models, a social gaming platform, intelligent companion services, AI-assisted RNA drug development, automated store marketing, a global intelligent business video SaaS, a new online psychological counseling platform, and a remote hiring platform for Chinese and American engineers, among others.
We've summarized several key points for AI application entrepreneurship:
First, build high-quality native new applications. Seize the new capabilities that the AI intelligence era offers — namely, intelligence supply and artistic creative supply — to create high-quality, unique native application experiences. This is actually quite difficult. As we mentioned earlier, language model intelligence is still not mature or stable, with clear capability boundaries. Startups may need to choose relatively vertical, niche scenarios and employ various technical and operational means to deliver good experiences.
Second, be non-consensus, more forward-looking, and disruptive. Non-consensus means not following the crowd in赛道选择, daring to enter difficult fields, and "doing what's right rather than what's easy." More forward-looking means choosing challenging business and technical paths.
For example, adopt advanced technical architectures that are still developing: entrepreneurs should prioritize building Agents over Copilots, since Copilots are more like opportunities for industry incumbents (think Microsoft and GitHub). Another example: founding teams could consider designing applications ahead of time based on the capabilities of next-generation language models (like GPT-5).
Disruptive means ideally having a disruptive effect on the industry you're entering — for example, disruptive product experiences, disrupting existing business models, and so on. The benefit of such disruption is the possibility of getting ahead of industry leaders. For instance, FreeS Fund portfolio company Babel (Babie Technology) seized the still-maturing trends of "Serverless" and large language models, committed to reconstructing the production tools and factors of software development, letting AI handle programming, debugging, deployment, and operations.
Third, pay attention to user growth and commercialization potential. User growth potential is important and easily understood — even if you start from a niche market, you can scale up in the future.
Why should we focus on commercialization early on?
This goes back to the "traffic tax" of large models we mentioned earlier. If you choose to integrate with large models, from day one of your startup, you're paying a traffic tax to large models.
For consumer-facing applications, there are typically three paths to monetization at scale: front-end charging (like games, value-added services, etc.), advertising, and e-commerce. Only a very small number of applications can possibly make e-commerce work (like Taobao, Douyin, etc.). Charging users directly is hard for new applications — most entrepreneurs will be intimidated and consider more indirect approaches, hoping to scale up user base and then monetize through in-app advertising.
Looking at the smartphone era, aside from e-commerce apps, China's top few general information apps probably earned roughly 0.1 to 0.3 RMB per daily active user in advertising revenue — already the extreme of advertising monetization. Apps at more ordinary scale likely fall far short of 0.1 RMB.
As we discussed earlier, the "traffic tax" for language models costs roughly 0.2 RMB per user per day — advertising revenue typically struggles to cover this. The larger your user base, the worse your losses become, unless you reduce the "traffic tax" through means like on-device models that we mentioned earlier.
Therefore, AI applications may need to prioritize front-end charging in their business model design. Of course, in the new AI intelligence era, perhaps our entrepreneurs can find monetization paths beyond the three规模化 ones mentioned above — let's wait and see.
Fourth, capture macro trend dividends. Anticipate and seize China's macro trend dividends, such as product exports, video e-commerce, engineer dividend, and so on. We must strive to capture the β that belongs to our era.
FreeS Fund portfolio company Tec-Look is also seizing opportunities from trends like Chinese product exports and new video e-commerce, aiming to build a world-class business video SaaS platform through product and technology innovation, empowering overseas video creators and merchants.
Video source: Tec-Look
Fifth, maintain a safe distance from large models and have your own business depth. You've probably heard of safe distance — there are well-known overseas counterexamples, such as some commercial copywriting generation applications that achieved "flash in the pan" rapid growth but ultimately couldn't escape the two-way impact from large models and other startups. Additionally, business depth is important for startup projects — this means areas that large models can't reach, particularly scenarios that are difficult to digitize or insufficiently digitized.
Of course, the most important factor is still the team: strong technical capabilities, and team members who understand the industry and scenarios — what we call "technology first, scenarios heavy." We look forward to walking alongside innovators in the AI field, and welcome you to reach out.
Interactive Benefit Looking back at 2023, what new opportunities did you observe in the AI field?
We welcome you to share your thoughts in the comments. By 17:00 on January 3, 2025, the 5 readers with the most thoughtful comments will receive a copy of The Deep Learning Revolution: From History to the Future. This book was selected for the Douban Annual Book List.

▲ Embracing a New Cycle, Discovering New Paradigms | FreeS Fund 2023 Annual Investor Summit Recap ▲ After ChatGPT's Explosive Rise, Where Is AIGC Headed? | FreeS Report 28 ▲ How Will Humans Work in the Future? | FreeS Report 26 ▲ From Lithography to Nanoimprint: Challenges and Opportunities at the Semiconductor Industry's Inflection Point | FreeS VC Dialogue ▲ Deep Dive: Dissecting the Shifts and Opportunities in NEV Sales and Aftermarket Services | FreeS Report 35 ▲ "The Higher You Stand, the Farther You See": The Origins and Future of the Satellite Communications Space Race | FreeS Report 34 ▲ Amid the GPT Frenzy, Anxiety and Breakthroughs in China's Chip Market | FreeS Research Institute
Star the FreeS Fund WeChat Official Account for timely business insights delivered to your inbox.
