Looking Ahead to 2026: What Innovation Opportunities Await the AI Industry? | Frees Report

From Large Models to World Models: Where Will AI Head in 2026?
This marks the third consecutive year we've published an annual review and outlook for the AI industry.
In 2023, OpenAI dominated the model landscape with little real competition. In 2024, OpenAI spent most of the year "being challenged." 2025 became China's "breakthrough year" for large models — DeepSeek burst onto the scene, shaking up the global large model race and carrying the "open source" banner worldwide.
Looking back at 2025, the global AI industry entered a period of rapid transformation. With the restructuring of model paradigms, accelerated compute buildouts, and the divergence of applications, the emergence of world models and physical AI brought intelligence closer to "actionable" and "simulatable."
Two throughlines stood out this year: first, the US and China became the "dual engines" driving global AI development, each with distinctive paths; second, key technologies like on-device models, agent capabilities, and world models began accelerating into the engineering phase — moving from "capability demos" toward "system integration."
One possible disappointment: much like 2023 and 2024, 2025 remained a year where "model capability gains" and "application deployment friction" coexisted. Models kept improving, but as the industry's keyword shifted from "large models" to "AI+," expectations for AI transformed from frontier technology to real-world delivered value. While 2025 saw notable bright spots on the application side, significant challenges persisted.
In this report, we examine the industry from three angles — model evolution, the industrial chain and infrastructure, and the application ecosystem — offering an investor's-eye baseline of the 2025 AI landscape. We aim to address:
- Where is model technology evolution pushing the industry?
- How is the AI value chain reorganizing upstream and downstream?
- For AI entrepreneurs, what innovation opportunities exist now and ahead, and how should moats be built?
This is not merely a retrospective on AI's past year, but a meditation on where AI is heading. As 2025 draws to a close, we're also curious:
- What new variables will shape AI in 2026?
- In which domains will "AI+" make major strides first?
- Can AI break the "productivity paradox"?

We hope this offers fresh perspective. We continue to track AI's development closely. If you're an AI founder or practitioner, feel free to reach out to Chen Shi, investment partner at FreeS Fund (chenshi@freesvc.com).

AI Industry Annual Outlook Outlook 2025: What Innovation Opportunities Await in AI? | FreeS Report Toward 2024: How We Think About AI Venture Investing | FreeS Report
Engagement Perk What do you think the AI industry will look like in 2026? Share your thoughts in the comments. By 17:00 on December 4, 2025, the two most thoughtful commenters will each receive a book recommended by FreeS.

/ 01 /
Global Large Model Landscape: Dual-Engine Drivers, Open Source Rising
The global large model landscape currently exhibits a "dual-engine" dynamic. This manifests both in technical path selection — with closed-source and open-source advancing in parallel — and in geopolitical reality, with the US and China as the two core forces propelling AI forward.
I. Dual-Engine Drivers: Where Technical Paths and Geopolitics Converge
From a technical standpoint, the "dual engines" first point to two fundamentally different development paradigms. Closed-source large models, led by tech giants (exemplified by OpenAI), emphasize performance leadership, product闭环, and commercial monetization. Open-source large models, initially led by resource-rich organizations (exemplified by DeepSeek), rely on community collaboration, ecosystem co-construction, and transparent iteration — and have demonstrated formidable vitality in recent years.

From a global competitive standpoint, the US leverages its long-standing accumulation in compute, algorithms, and talent to dominate the closed-source domain. In China, open source has become a critical direction for AI development. Open source helps address supply chain uncertainties and external constraints, while also enabling key breakthroughs in China's AI competition. Europe and other regions have made moves, but generally remain in catch-up mode, lacking model systems with global influence.
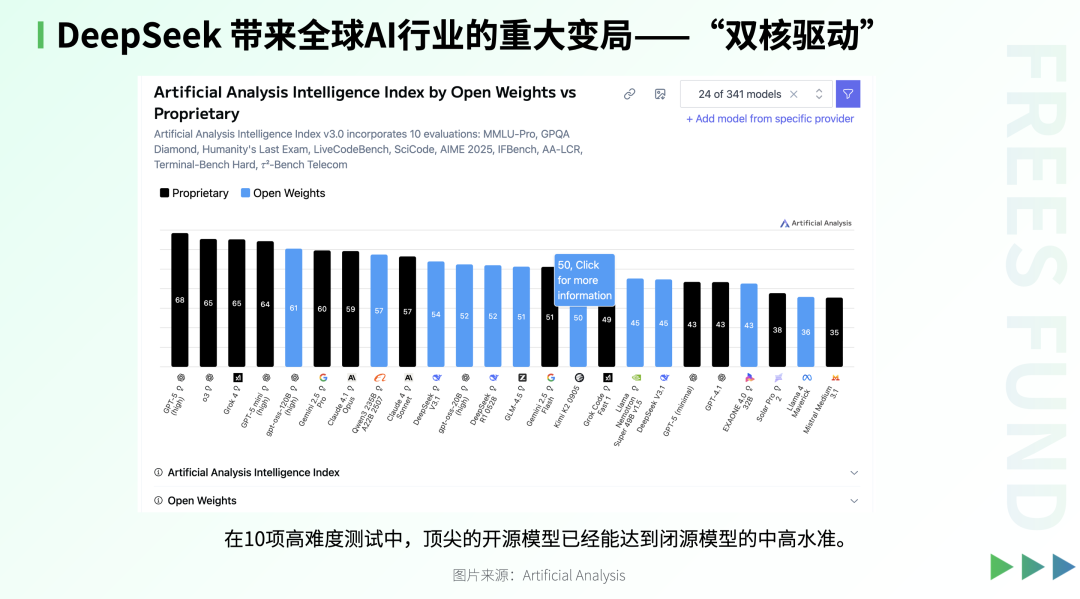
Thus, the main engines of AI development have concentrated in the US and China — one pushing the innovation frontier through closed source, the other building ecosystem depth through open source.
II. Leading Large Models: A Three-Way Standoff with Strategic Divergence
Among large model camps, OpenAI, Anthropic, and Google form a "troika," each pursuing differentiated strategic paths.
OpenAI's GPT series maintains advantages in comprehensive capabilities. It continues to lead the technical frontier (pioneering long-chain reasoning paradigms, releasing video generation models, etc.) while reaching end users through products like ChatGPT, demonstrating a vision of building a "one-stop AI platform."
By contrast, Anthropic focuses more on professional scenarios and vertical applications — code generation, cybersecurity, and the like — with its Claude series models and Claude Code tool. Recently, Anthropic has also increased investment in developer tools and enterprise scenarios, attempting to seize the initiative at the application layer.
Google's Gemini path previously seemed oriented toward "comprehensive and balanced" capabilities, with strengths in long context, multimodal input, and dual research/creative orientation. In the past six months, Google has sought to break into vertical creative and image generation tracks through popular models like Nano Banana Pro, accelerating the formation of differentiated brand identity.
III. The Rise of Open Source: China's Strategic Breakthrough and Ecosystem Restructuring
If closed-source models represent "elite innovation," open-source models more closely resemble a "mass collaborative engineering innovation" led by pioneering institutions. China is leveraging this model for strategic breakthrough.
2025 stands as China's "breakthrough year" for large models, with DeepSeek's emergence as the landmark event. The industry had broadly assumed China would "build applications first, tackle models later," but DeepSeek not only delivered high-performance foundation models ahead of schedule — it also became the first globally to reproduce large models with "long-chain reasoning" capabilities through open source.
Critically, DeepSeek innovated on training mechanisms to dramatically compress token costs during inference, achieving high performance while significantly lowering deployment barriers. This "low cost, long reasoning" paradigm quickly ignited the developer community.
Beyond DeepSeek, domestic large models including Qwen and Moonshot AI have successively open-sourced or released open weights, collectively exploring a new open-source path combining technical depth with ecosystem breadth.
Notably, for China, open source represents far more than a technical choice — it may be a systemic strategy.
On one hand, because external closed-source models face barriers to large-scale entry into the Chinese market, domestic open-source models naturally gain vast proving grounds. B-side enterprises may prefer open-source solutions for their fine-tunability, auditability, and customizability — matching urgent demands for data security and technological autonomy.
On the other hand, open source activates China's vast engineer dividend. Under real constraints on compute access, the state can concentrate limited resources on a small number of quality open-source models (such as DeepSeek and Qwen), achieving efficient coordination of compute, data, and talent.
Unlike closed-source models' reliance on small elite teams, the open-source ecosystem allows universities, SMEs, and even individual developers to contribute algorithmic optimizations and application innovations across different model sizes. This "many hands make light work" collaboration mechanism is essentially an open innovation paradigm akin to academic research — transparent technical details, rapid dissemination of results, mutual community advancement — forming a powerful positive feedback loop.
However, open-source large model development is no easy path. Its business model faces inherent challenges: long monetization cycles, difficulty achieving scaled revenue in the near-to-medium term, and heavy dependence on substantial funding support and ecosystem coordination.
One viable approach may be: open-source model vendors not only release model weights and code, but also provide token-based cloud services — open source yet收费, "eating the fish twice." Currently, both Qwen and DeepSeek offer cloud services simultaneously. But this model also faces intense competition from cloud service providers, compressed profit margins, and rising operational costs.
IV. The Rise of On-Device Models: A Path Beyond the Cloud
In 2025, "on-device inference" has emerged as a critical battleground for model deployment. On-device inference is not a new feature at the application layer, but rather the result of stratification in model form factors. Against the backdrop of increasingly expensive cloud training, rising rather than falling inference costs, and constraints on power supply and data center expansion, a portion of inference workloads is migrating to device-side execution.
Apple Intelligence, Google's Gemini Nano, and certain small-parameter domestic models have made on-device deployment initially viable.
On-device models typically range from hundreds of millions to several billion parameters, enabling low-latency response, strong privacy protection, and negligible operating costs. For the model ecosystem, this signals a shift from "one-size-fits-all large models" to a multi-scale "cloud-device collaborative" architecture: the cloud handles complex reasoning and cross-task coordination, while the device processes immediate tasks and proximal sensing.
Home and office scenarios are becoming typical carriers for on-device models. Security cameras, household robots, appliance control modules, and desktop assistants increasingly rely on local inference for visual understanding, device orchestration, and task execution; the cloud intervenes only when deep reasoning is required. For model vendors and application developers, on-device AI represents not merely a change in deployment method, but a new battle for entry points — inference is flowing back from cloud centers to local environments.
/ 02 /
Key Technical Evolution in Large Models: Multimodality, Reasoning, Contextual Memory, and Agentic Capabilities
In recent years, large model development has advanced from single-text capabilities toward more complex, more intelligent integrated forms. Four major technical trends are currently reshaping the industry landscape: native multimodal fusion, reasoning capabilities, long-context windows and memory mechanisms, and agentic AI. These advances not only enhance foundational model capabilities but are redefining the boundaries of human-machine interaction.
I. Multimodality: From "Text-Centric" to "Native Fusion"
In the past, multimodal systems typically relied on text as an intermediary — for example, using models like CLIP to map images, audio, and other modalities into a unified text semantic space before processing. While effective, this approach was still fundamentally text-centric, with other modalities in a "being translated" position.
Today, frontier large models are shifting toward native multimodal architectures. "Native" here means that the model is designed from the ground up to embed image, speech, text, and even video modalities into a single shared vector representation space, enabling natural alignment and seamless switching between modalities without text mediation, for more efficient and consistent understanding and generation.
Multimodal generation models are also entering a rapid development phase, moving from experimental exploration toward application-oriented deployment. For instance, Sora 2 has achieved breakthroughs in video and audio generation with physical realism, camera control, and sound effect synchronization; Nano Banana Pro has made significant strides in image generation and editing, supporting multi-image fusion, 4K output, logical consistency, and multilingual text rendering.
II. Reasoning Capabilities: From "Answering Questions" to "Thinking Processes"
If multimodality expands a model's perceptual boundaries, then reasoning capability marks a leap in its cognitive depth. A defining feature of large models in 2025 is that "reasoning capability" has officially become a core standard feature.
Previously, large language models focused primarily on generating text based on contextual cues; now, the trend is shifting.
On one hand, during training, models no longer simply learn "what's the next word" but rather "how to think step by step" — through chain-of-thought, structured reasoning data, and reinforcement learning fine-tuning, enabling models to decompose complex problems and reason progressively.
On the other hand, during inference, models increasingly employ mechanisms such as "extended thinking time" or "dynamic invocation of additional compute resources" (i.e., test-time compute / inference-time scaling) to improve judgment quality.
Thus, today's advanced models not only "give you the answer" but also "show you how they think," improving accuracy and enhancing interpretability, enabling better performance on complex tasks such as mathematical proofs, code generation, and scientific reasoning.
III. Context and Memory: Making AI Truly "Know You"
Beyond perception and reasoning, another "game-changing" advance is the introduction of long-context windows and memory mechanisms (context + memory).
Traditional AI conversations were one-off affairs: the user asks, the model answers, and the session is forgotten once ended. New-generation models, by supporting ultra-long contexts (e.g., million-level tokens) combined with external memory storage and retrieval mechanisms, can continuously track user identity, project history, goal evolution, and personal preferences across multiple interactions. This means AI is no longer a "forgetful tool" but is gradually becoming a digital companion with long-term cognitive capabilities.
This capability is particularly important for productivity tools, personalized services, and complex collaboration scenarios. For example, in software development, AI can remember an entire project's architecture and coding style; in health management, it can track a user's long-term symptom changes.
IV. Agentic Capabilities: From "Generating Responses" to "Autonomous Execution"
Beyond multimodal perception, advanced reasoning, and memory mechanisms, another key direction for large model development in 2025 is "agentic capabilities." So-called agentic capabilities mean that models can not only understand and generate content, but also actively plan, invoke tools, execute multi-step tasks, and to some extent autonomously make decisions and interact with their environment.
Under this paradigm, AI's role is no longer limited to a Q&A assistant of "you ask, I answer," but upgrades to an execution partner of "you set the goal, I'll get it done." Faced with a complex task, for instance, the model can automatically decompose objectives, select appropriate tools (such as database queries or API calls), coordinate the execution sequence of multiple subtasks, monitor intermediate results, dynamically adjust strategies based on feedback, and even collaborate with other agents or humans.
Agentic capabilities have fairly broad application scenarios: productivity automation, such as automatically generating analysis reports and cross-platform task scheduling; enterprise process optimization, supporting automatic orchestration and execution of cross-departmental collaboration workflows; and personalized intelligent assistants, helping users manage long-term projects, formulate learning plans, and other sustained objectives.
If agentic capabilities are deeply integrated with multimodal perception, logical reasoning, and long-term memory, large models could potentially build a complete intelligent closed loop of "perceive — understand — remember — act."
However, current agentic capabilities remain in early development. Many applications are still at the pilot or proof-of-concept stage, and their large-scale commercial deployment faces multiple challenges, including tool invocation stability, reliable orchestration of task workflows, and institutional and technical difficulties in governance, accountability attribution, and system reliability.
03
New Directions in Large Model Evolution: Training Paradigm Shifts, Exploration of New Architectures
As large model technology enters deeper waters, the industry is undergoing a series of structural transformations: from shifts in training focus, to complex cost dynamics in usage, to diverse experiments at the architecture level. These changes not only reflect the evolution of the technology itself but also foreshadow more possibilities for future AI development paths.
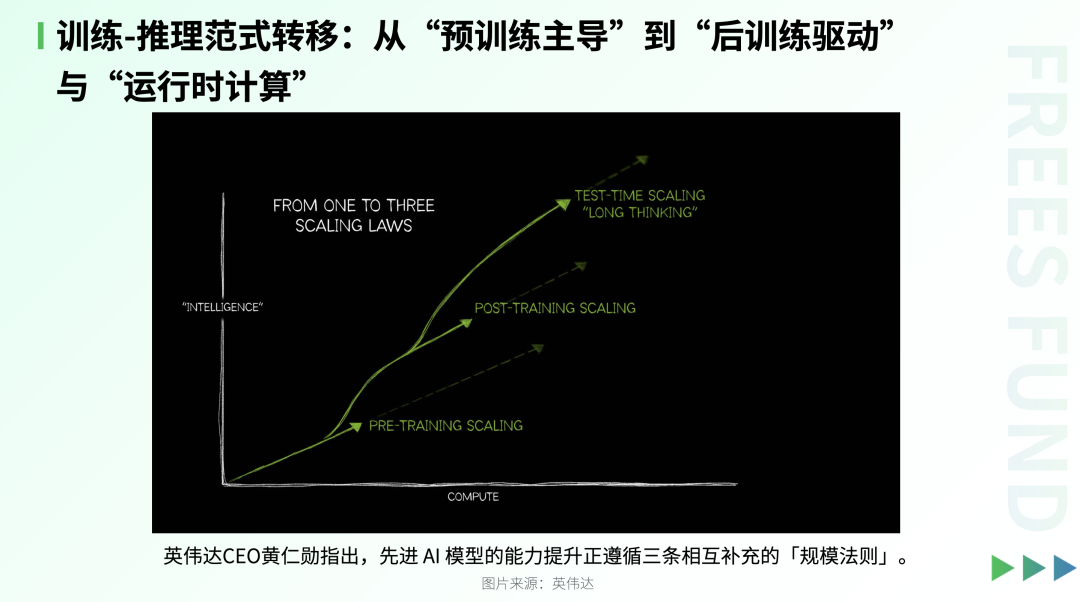
I. Training-Inference Paradigm Shift: From "Pre-training Dominant" to "Post-training Driven" and "Runtime Compute"
Currently, large language models are undergoing a paradigm shift: from the past single path centered on large-scale pre-training, gradually evolving toward a multi-stage collaborative system that integrates post-training fine-tuning and runtime compute enhancement.
As NVIDIA CEO Jensen Huang has pointed out, the capability improvement of advanced AI models is following three mutually complementary "scaling laws":
1. Pre-training Scaling Law
Through massive text data and ultra-large parameter models, using ultra-large-scale computational resources, to build powerful foundational language understanding and generation capabilities. This is the "foundation" of model generalization ability, determining its breadth of knowledge and initial performance ceiling.
2. Post-training Scaling Law
On the basis of pre-training, through supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), reasoning alignment, and other techniques, injecting task-oriented behavioral patterns and value alignment. This stage moves models from "able to generate" to "capable of thinking, collaboration, and rule-following."
3. Test-time / Inference-time Scaling Law
During inference or deployment, by increasing computational investment — such as enabling chain-of-thought, multi-step reasoning, internal search, self-verification, or tool invocation mechanisms — allowing the model to "spend more time thinking," thereby improving accuracy and logical depth.
II. Diverse Exploration of Model Architectures: Transformer Remains Mainstream, but Boundaries Are Expanding
At the underlying architecture level, although Transformer remains the absolute mainstream, researchers over the past year have also been actively exploring various alternative or hybrid approaches, such as:
- Linear Attention models: By simplifying attention computational complexity, significantly improving inference speed while maintaining performance, becoming an important direction for lightweight deployment.
- Hybrid Attention mechanisms: Combining traditional attention mechanisms with other efficient modules (such as state space models / SSM, convolutions, etc.), attempting to achieve better balance between long-sequence modeling and computational efficiency.
- Text Diffusion Models: Borrowing ideas from diffusion models in image generation for language generation. Unlike Transformer's word-by-word prediction, diffusion models can predict multiple positions in parallel, theoretically offering higher throughput efficiency. In 2025, research from Apple and Ohio State University showed that at small parameter scales, their generation speed advantage is significant. However, they have not yet been widely adopted by leading large models and remain in the exploration stage.
Additionally, some frontier projects have even attempted to incorporate world model concepts into architecture design, such as building internal environmental representations through multimodal perception and dynamic simulation.
04
Physical AI and World Models: A New Paradigm for Intelligence
Over the past few years, the development focus of artificial intelligence has been concentrated on language models and digital content generation. AI learned to "read," "write," and even "look at images to generate images or video." However, with the rapid evolution of technologies such as intelligent driving and embodied robotics, AI is facing a more complex challenge: it must not only process text and images but also "see," "act," and "understand" the environment in the real physical world. This means AI needs to truly enter and adapt to the physical world.
Against this backdrop, world models and Physical AI have gradually become industry focal points. So-called Physical AI refers to intelligent systems capable of perceiving real environments, understanding physical laws, and taking effective action accordingly. Industry experts such as Yann LeCun and Demis Hassabis have stated: "The truly valuable AI of the future will be systems that can understand and obey the laws of physics."
I. What Is a World Model? Why Is It Core to Physical AI?
A world model is "a miniature world constructed in the AI's mind." It not only records information currently captured by sensors—such as images, sounds, and position—but can also simulate and predict future states: if a certain action is taken, how will the environment change?
In other words, AI is no longer simply mapping from "input" to "output." It now possesses the capacity for "internal simulation—rehearsal—planning." For instance, AI can first experiment in a virtual environment: "If I push this chair, what will happen?" "If the vehicle turns at this moment, will it lose control?" This "mental rehearsal" mechanism enhances a system's generalization capabilities, safety, and long-term planning.
Humans have had this mechanism all along. As the cartoon below illustrates, when riding a bicycle, humans don't rely solely on the scene before their eyes to make decisions. They also depend on a continuously updated "internal world model" in the brain to predict the outcomes of actions like turning or colliding, thereby avoiding the realization of danger only after actually falling.
II. VLA and World Models: Differences in Technology and Application Scenarios
Currently, the core technical approaches in Physical AI center on two main directions: first, end-to-end perception-action models represented by VLA (Vision-Language-Action models), and second, environment modeling and prediction systems centered on world models.
VLA is one of the important branches of Physical AI, representing the extension of traditional multimodal large models toward action capabilities. It fuses vision, language, and action instructions to build an end-to-end system of "multimodal input → action output," suitable for task scenarios requiring "see + understand instruction → execute immediately." For example, robots completing grasping or搬运 operations based on visual and textual prompts. Such scenarios place high demands on semantic understanding and cross-scene generalization.
By contrast, world models place greater emphasis on internal environment modeling and dynamic prediction capabilities. They focus not merely on current perceptual data, but construct representational systems encompassing hidden states, dynamic laws, and causal relationships—enabling intelligent agents to simulate multiple future scenarios "in their minds" and evaluate the potential consequences of different actions.
When environments are complex, situations uncertain, and planning or adaptation required, world models may demonstrate stronger flexibility and robustness. However, the technical approach to world models remains immature, with challenges still to be resolved regarding simulation-to-reality gaps, physical consistency, and long-term planning stability.
At the application level, VLA is better suited for short-term operations with clear structure, well-defined tasks, and rapid response requirements—such as warehouse logistics and assisted driving. World models are more applicable to complex tasks requiring deep reasoning, dynamic adaptation, and long-term goal orientation, such as autonomous navigation, multi-step robotic manipulation, and human-robot collaboration.
In short, VLA is more "see and do," fitting stable, structured tasks; world models are more "think first, then do," fitting complex, variable scenarios requiring prediction and planning.
Of course, recent research (such as World VLA) has shown that VLA and world models are not mutually exclusive paths, but can be integrated into unified systems. This enables AI/agents to both directly generate actions through vision + language (VLA) and leverage world models to predict environmental states and future changes—thereby achieving an integrated intelligent closed loop of perception—planning—execution.
III. 2025: Research Progress and Application Exploration of World Models
In 2025, the world model field saw multiple landmark advances.
In August, DeepMind released Genie 3, demonstrating the ability to generate interactive 3D environments from text—regarded as a key experiment in "interactive world generation."
In September, OpenAI launched Sora 2, strengthening "text → video/physical scene" generation capabilities. Though not a complete world model, it has preliminarily demonstrated joint modeling capabilities for actions, scenes, and physical states—viewed as an important step toward world models.
In November, World Labs—co-founded by Fei-Fei Li—released Marble, supporting the generation of high-fidelity, editable 3D worlds from text, images, video, and even rough 3D layouts. The industry has called this an exploration of "spatial intelligence infrastructure."
Additionally, NVIDIA Isaac Sim, as a key platform integrating Physical AI, high-fidelity simulation, and world models, is gaining increasing industry attention. It provides realistic physics engines, sensor simulation, and synthetic data generation capabilities—offering powerful support for robot training, algorithm validation, and pre-deployment testing.
These advances may indicate that world model research and application is starting from "visual/3D world construction," with potential to gradually advance toward the stage of "simulation—physical environment—actual system deployment."
IV. Application Prospects for Physical AI and World Models
In the future, world models will evolve toward three directions: first, interactivity—supporting dynamic interaction between users or agents and virtual worlds; second, plannability—possessing long-term goal-oriented reasoning and action capabilities; third, physical consistency—strictly adhering to physical laws in generation and prediction.
Physical AI is poised to become new infrastructure for fields such as robotics, autonomous driving, game engines, and digital twins. As multimodal training efficiency improves and lightweight inference technology matures, world models may gradually move out of laboratories and achieve scaled industrial deployment.
05
Industry Chain and Infrastructure:
From "Single Winner" to Ecosystem Collaboration
I. Infrastructure: The Shift from "Single Winner" to "Multipolar Coexistence" Remains Slow
At the compute infrastructure level, NVIDIA's leading position remains solid. Its market capitalization once surpassed $5 trillion, making it the most core hardware engine of the AI era. The long-anticipated shift from a "single winner" to a "multipolar coexistence" landscape is progressing relatively slowly.
Multiple tech giants and emerging vendors are actively布局 alternative solutions, including Google's TPU, AMD's Instinct MI chips, Huawei's Ascend, and specialized accelerator chips from startups. Currently, Google's TPU has achieved scaled deployment in Google Cloud and its own AI infrastructure; AMD's MI300 series has also been adopted by certain data centers and cloud service providers.
However, at present, the vast majority of AI services still rely on NVIDIA-dominated GPUs. Although viable alternatives exist in the market, they have yet to form comprehensive infrastructure ecosystems on a global scale. In other words, while a diversified ecosystem has begun to sprout, it remains far from mature.
II. Capital Circulation in the Industry Chain: Multiple Parties "Infusing Blood" to Build a New Collaborative Ecosystem
At the industry ecosystem level, a noteworthy phenomenon is emerging: the AI industry is shifting from reliance on support from a few cloud vendors toward a "circular capital support" model with multiple participants.
In the past, the entire ecosystem was primarily sustained by leading cloud service providers such as Microsoft, Google, and Amazon, which supplied compute and capital. But now, an increasing number of participants are beginning to反向 "transfuse blood"—not merely receiving resources, but actively injecting momentum into the ecosystem. For example, NVIDIA has become an important source of capital and compute output for the industry through investments, partnerships, and ecosystem support.
This relationship of mutual support and mutual endorsement has formed a complex circular network of capital and resources.
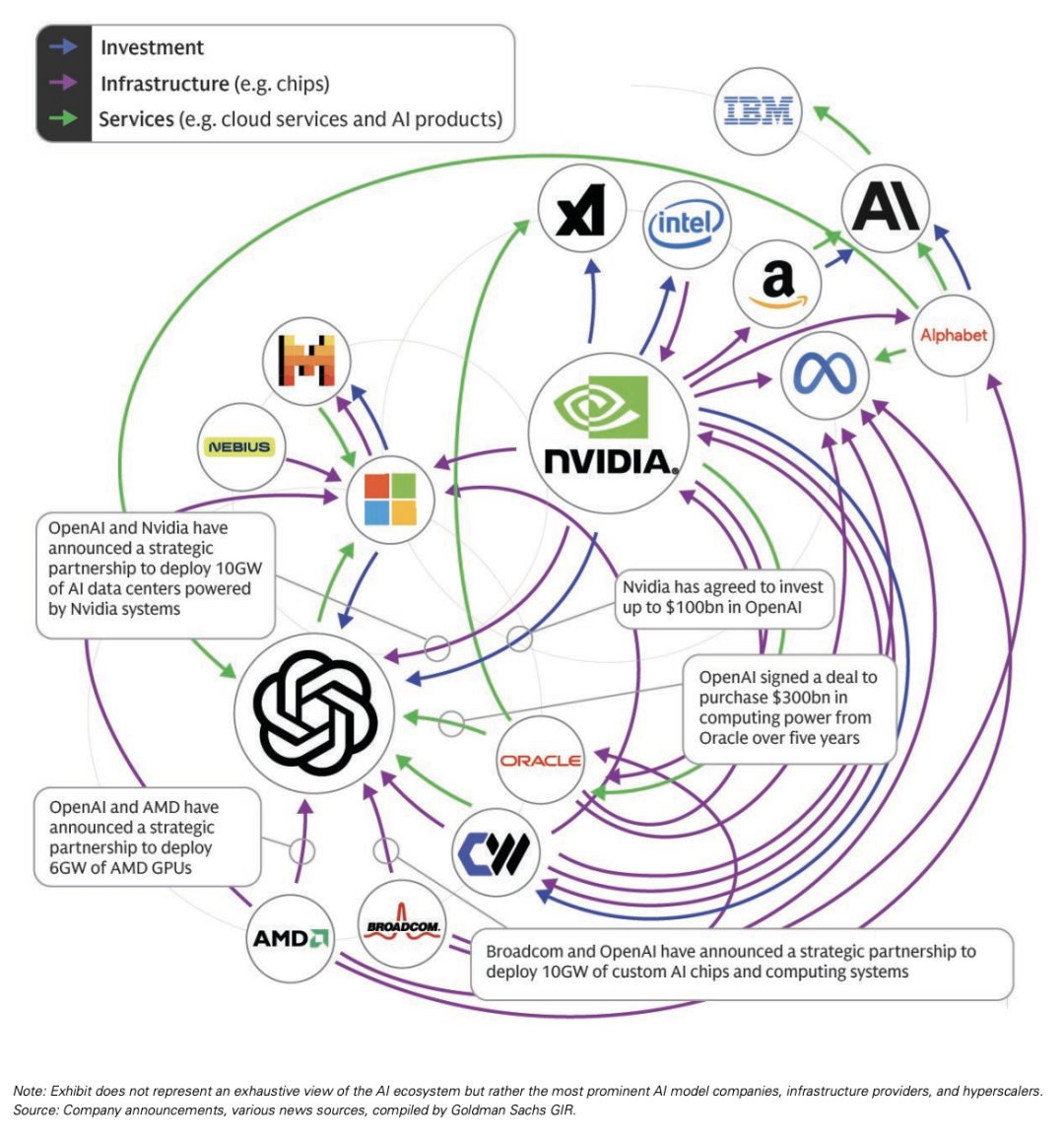
Source: Goldman Sachs report "Top of Mind: AI: in a bubble?"
Notably, this ecosystem currently displays a "dual-center" structure: NVIDIA represents the hardware end, OpenAI represents the software and model end. These two companies somewhat resemble the "Intel + Microsoft" of the AI era, together forming the "software-hardware dual core" driving the entire industry's operation. Around these two cores, numerous enterprises continuously inject vitality into the ecosystem through investment, cooperation, procurement, and joint construction.
However, such massive investment has also sparked industry discussions about an "AI bubble." According to a Goldman Sachs report, as of August 2025, global AI applications' annual recurring revenue (ARR) stood at approximately $30 billion. Yet Sequoia Capital previously estimated that, if full-chain costs are included—encompassing chips, data centers, personnel, and R&D—the industry would need to reach roughly $600 billion in annual revenue to achieve reasonable returns. This implies that the current AI industry still faces a deficit gap of hundreds of billions of dollars.
06
Boundaries and Opportunities at the Application Layer:
Large Model Companies vs. AI Application Startups
As large model capabilities continue to leap forward, an unavoidable question arises: if the vast majority of capability comes from the model, then what is the "moat" for AI applications? This concerns not only the choice of entrepreneurial direction, but also profoundly affects the future power distribution of the AI ecosystem.
I. Strategic Positioning of Large Model Companies: From "Super Assistant" to "Gateway Controller"
Large model companies, with OpenAI as the representative, are building moats through dual positioning. On one hand, they create "super assistants" covering daily tasks such as schedule management, information queries, and content generation—emphasizing generality and ease of use. On the other hand, they cultivate a "T-shaped talent" image, providing advanced skills atop foundational capabilities, such as complex programming, deep research, and knowledge integration—demonstrating professional-grade intelligence.
However, OpenAI's ambitions extend far beyond this. To truly transform such capabilities into user stickiness and commercial value, it has not only launched ChatGPT as a core interaction hub, but has also successively deployed developer tools, knowledge acquisition products (such as DeepResearch), AI search, and even self-built compute infrastructure.
By doing so, OpenAI can not only directly connect with users and rapidly monetize, but also feed back the data loop required for model iteration. To some extent, this resembles the "Android model" of the mobile internet era: operating system vendors dominate the entire ecosystem's direction by embedding core services. Therefore, large model companies don't merely want to be "technology suppliers"—they aspire to become gateway controllers of the next-generation human-computer interaction.
II. Survival Space for AI Application Entrepreneurs: Beyond Boundaries, Within Depth
Faced with such aggressive expansion, do independent application companies still have room to stand? The answer is yes—but only if they find the right position.
Large model companies can hardly cover all applications. On one hand, deeply customizing models for every vertical scenario would entail enormous engineering and maintenance costs. On the other hand, many industries (such as healthcare, finance, and law) have strict requirements for data privacy, compliance, and localized deployment that general-purpose large models struggle to meet. Additionally, the rapid iteration demands of niche domains often exceed general platforms' response speeds.
Precisely for this reason, genuine opportunities lie precisely beyond the boundaries of large models, in vertical domains with business depth—scenarios requiring deep industry understanding, complex workflow integration, or strong user relationship accumulation. In these areas, application companies can not only avoid head-on competition, but also build unique value through profound scene insight.
III. Entrepreneurial Strategies: First-Mover Advantage, Adaptability, and Lightweight Architecture
So how should entrepreneurs break through in this landscape? Practice shows that successful paths typically encompass three key strategies.
First, "first-mover" model capability is crucial. Since "generational updates" of large models take time, entrepreneurs may—in capabilities not yet well-supported by models—use engineering means (such as rule engines + fine-tuning + toolchains) to achieve "good enough" in limited scenarios ahead of time. Once model capabilities mature, enterprises with existing user bases and product recognition can potentially rapidly amplify advantages and form first-mover barriers.
Second, build sufficiently flexible scaffolding. Applications should adopt lightweight, modular designs as much as possible, avoiding excessive dependence on specific model versions' internal structures. This maintains compatibility through continuous model upgrades, preventing forced large-scale reconstruction due to underlying changes.
Finally, as core capabilities among large models increasingly converge, competitive moats are more likely to shift toward the user data side. Whoever accumulates richer interaction histories, more precise preference profiles, and more stable usage patterns may have a better chance of winning. In other words, future success will depend less on "how powerful a model you use" and more on "whether you truly understand your users."
4. Top-Tier Application Ecosystem: Chinese Companies Shine Abroad, but Commercialization Remains Early-Stage
The AI application ecosystem has already taken initial shape, with several representative categories emerging: large-model productivity assistants (e.g., ChatGPT), companion applications (e.g., Character.ai), AI coding tools (e.g., Cursor, Lovable), and AI browsers and search (e.g., Quark, Perplexity).

Among these, Chinese teams have performed particularly well. Take Quark: according to August statistics from US venture firm a16z, its global web traffic already ranks ninth, while its mobile ranking (counting only iOS clients) places 47th — a figure likely to improve further once Android client data is included. Similarly, applications incubated by major Chinese tech companies such as DeepSeek, ByteDance, and Alibaba are rapidly penetrating overseas markets.

However, impressive user metrics do not equate to mature commercial revenue. According to a Goldman Sachs report, as of August 2025, annualized revenue for Chinese applications in global markets stands at approximately $1.5 billion, with over 80% coming from overseas.
For China's AI software companies, this reveals a somewhat awkward reality: monetization remains difficult in the domestic market. "Going global" may temporarily alleviate this predicament, but the real solution lies in unlocking viable B2B, B2C, or B2P commercial pathways — actually landing applications and getting users to pay for value. (For more, read Outlook 2025: What Innovation Opportunities Exist in AI? | Frees Report)
07
The Evolution Path of AI Applications:
From Copilot to Agent,
And the Real Challenges of Landing
AI applications are gradually advancing toward greater intelligence, evolving from passive conversational tools toward agents with goal-orientation and autonomy.
1. Evolution Path: From Conversation → Copilot → Limited Agent → Autonomous Agent
The trajectory of AI application development can be divided into four stages.
-
Conversation stage (Chatbot): AI applications exist in Q&A form — users input commands, and the model responds.
-
Copilot stage: AI becomes an assistant, completing specific tasks under human direction (e.g., code completion, document polishing). Typical representatives include GitHub Copilot, Cursor, and others.
-
Limited agent stage: AI begins to possess preliminary autonomy, capable of executing multi-step tasks within preset rules and safety guardrails, though still requiring human oversight.
-
Autonomous agent stage: The future direction is fully autonomous agents that can perceive environments, set goals, plan actions, invoke tools, and self-optimize — more like "living" digital entities.
Today, many AI applications are exploring the agent direction. While current agent capabilities remain immature, their core characteristics are becoming clear: rather than depending on step-by-step human guidance, they can proactively understand intent, decompose tasks, invoke external tools (such as Computer Use capabilities), and form closed loops of "planning — execution — feedback."
2. Paradigm Shift in Development: "Context Engineering" Becomes Core — Whoever Controls Context Controls the Future
As application forms upgrade, software development methods are undergoing fundamental transformation.
In the past, Software 1.0 relied on hand-written code, and 2.0 on training models with data; today, the core work of AI-native applications has shifted to "context engineering" — dynamically orchestrating prompts, memory, state, and tool invocations to construct an information environment that enables large models to efficiently complete tasks.
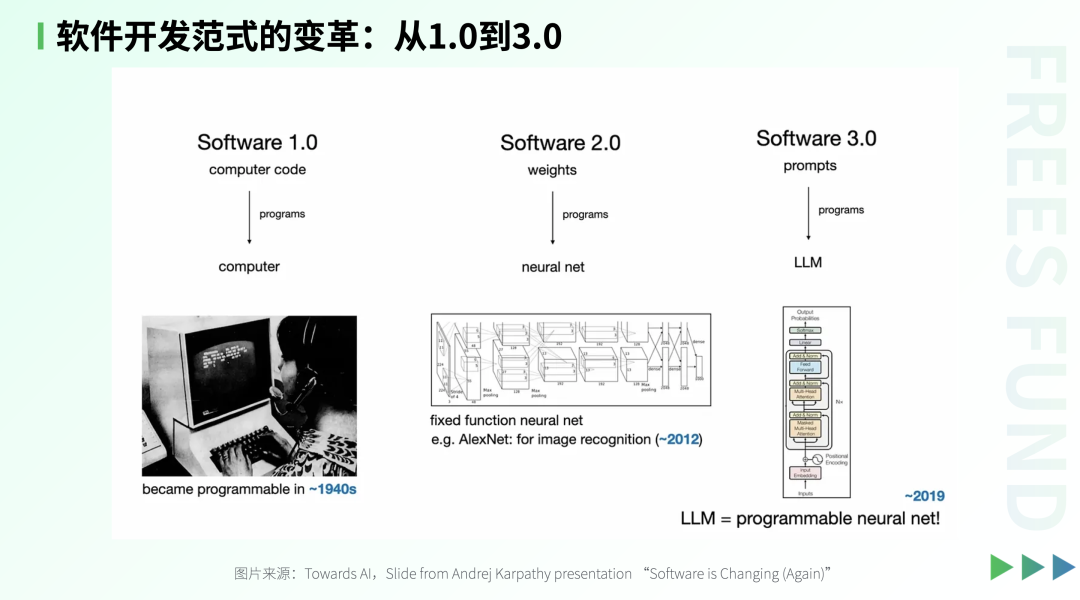
As researcher Andrew McCloskey points out, the essence of writing AI applications is no longer programming in the traditional sense, but designing a dynamic information system: providing the model with accurate context, long/short-term memory, retrieved information, and available tools — at the right time, in the right format.
With AI's assistance, developers will still write code, but primarily through "multi-turn dialogue with the model," continuously adjusting prompt strategies and content. In other words, future software engineers will be not only logic architects but also "AI collaboration directors" — their core capability lying in how to effectively guide model intelligence, rather than merely implementing functional logic.
To summarize in one sentence: "Context engineering" is the "invisible core code" of hardware and software applications in the large-model era!
3. Landing Dilemma: 95% of Enterprises See No Returns, the "Generative AI Gap" Is Real
Despite rapid technological evolution, the commercial landing of AI applications faces severe challenges.
A study by MIT's Nanda project team reveals: although global enterprises have invested $30–40 billion in generative AI, as many as 95% of organizations have failed to achieve measurable business returns, with only 5% of pilot projects creating actual value. This phenomenon is termed the "generative AI gap."
Why such a massive disconnect?
First, application scenario mismatch. Current mainstream AI tools (such as Copilot, customer service assistants) primarily enhance individual productivity, have high fault tolerance, and show quick results — hence their trial adoption by some enterprises. But such tools are difficult to directly convert into enterprise-level profits, because they are not embedded in core business processes and lack the capacity to support overall workflows. Once multi-system integration, data unification, or decision closed-loops are involved, the tools' "fragility" becomes apparent.
Second, difficulty capturing tacit knowledge. In actual enterprise operations, heavy reliance on undocumented experience, rules, and "context" means current models cannot effectively learn this "tacit knowledge," causing AI outputs to diverge from actual needs.
4. Revenue Pressure on AI Applications
Currently, domestic AI application entrepreneurship faces significant challenges, with one core reason being the lack of new hardware endpoints. Without a new entry point comparable to smartphones, AI applications must compete for users' time within existing mobile or computer ecosystems. The result: AI applications may end up competing with virtually all apps for user attention.
Meanwhile, AI penetration in the Chinese market is relatively high, and competition is exceptionally fierce, further intensifying survival pressure.
The reality for AI application companies is that although per-token inference costs are falling rapidly, because most scenarios require chain-of-thought reasoning, token invocation volume has surged dramatically — potentially causing overall company expenditures to rise rather than fall. This "cost paradox" has created genuine pressure on downstream application companies. For example, AI coding tools like Cursor have faced operational cost challenges from high inference loads. This has also prompted industry-wide rethinking: how to strike a balance between performance and cost?
The advertising model that traditional apps rely on has also hit bottlenecks.
In the past, internet product development relied heavily on the logic of "wool comes from the pig's back": attracting users with free services, then monetizing through advertising. For instance, Alibaba earned revenue by providing advertising display slots to merchants; Tencent, though supported by gaming and value-added services, also derived substantial income from advertising.
But today, this model poses heavy challenges for AI application products. On one hand, apps need continuous user acquisition and activation, yet customer acquisition costs keep rising. On the other hand, advertising unit prices are generally low. In China, apart from top apps like Douyin, Taobao/Tmall, and WeChat, most software earns only 10–20 RMB per thousand ad impressions (eCPM) or even less. If users frequently use AI features, service costs (i.e., tokens consumed) may far exceed advertising revenue — the math simply may not work.
Therefore, at the current stage, AI entrepreneurs may need to prioritize business revenue models beyond advertising. Additionally, for Chinese AI entrepreneurs, other paths need active exploration, such as pivoting to overseas markets or combining with hardware to create closed-loop experiences.
5. Software-Hardware Integration: A New Path for AI Entrepreneurship
Currently, Chinese AI software entrepreneurship faces certain challenges, such as weak user willingness to pay and difficulty monetizing pure software models; pivoting to overseas markets means confronting high customer acquisition costs and intense competition. Meanwhile, although domestic hardware supply chains are mature, originality is insufficient and "involution-style competition" is prevalent.
Against this backdrop, "software-hardware integration" may become a path worth exploring.
Take BodyPark, an early Frees investment, as an example. It initially focused on the software side, launching AI-based motion capture technology during the COVID-19 pandemic to assist fitness coaches in remotely guiding multiple students training at home. Through this process, the team gradually clarified and built its business model and operational methods, accumulated relevant core technology, and developed its team. But as mentioned above, pure software AI applications face commercialization pressure in China.
Later, BodyPark merged with a hardware company, adding hardware DNA atop its existing software foundation, and launched the integrated software-hardware product "ATOM" — which has recently performed impressively in overseas crowdfunding. Founder Ali said: "The core capabilities BodyPark has built over the years — AI motion capture algorithms, curriculum systems, agent architecture, coach SaaS teaching tools, live coach supply systems, and so on — are precisely what gives ATOM the confidence to land quickly and smoothly."
From BodyPark's development, we derive three observations about AI application entrepreneurship:
- Enter through software, solidifying technology and business model foundations, avoiding premature entanglement in hardware's high costs and low-barrier competition;
- After capabilities accumulate to a critical point, introduce hardware carriers to achieve synergistic effects of "software-defined hardware";
- Use hardware to enhance user experience and product perception, expand service boundaries, and build higher competitive moats.
Worth noting: software-hardware integration is not simple addition, but rather using software capability as the kernel and hardware as the amplifier — this may be a new path for Chinese AI entrepreneurship.
Another typical hot track for software-hardware integration is intelligent hardware. China has a mature and highly efficient consumer electronics manufacturing chain, plus a well-developed chip and sensor industry and supply chain infrastructure — this gives intelligent hardware startups a natural advantage. Add to that the recent advances in AI algorithms, the improvement in on-device computing power, and falling costs, and AI-empowered "software-hardware integrated" smart products have become viable.
FreeS Fund has made numerous bets in the AI hardware direction. Portfolio companies have successively launched AI-powered hardware products including Zero Zero Robotics' flying camera, AeroBand's smart musical instruments, Tsingz Meta-Optics' high-speed camera, MoeGo's AI emotional companion pet robot, and SoundAI's AI earphones. (We recommend reading Feng Shu's conversation with three intelligent hardware founders: "There's Always a New Opportunity in AI Hardware".)
Outlook: 2026, What's Next for AI
I. Technical Direction: Online Continuous Learning
One current limitation of large models is that once training is complete, parameters become "frozen" — they cannot autonomously update knowledge after deployment. Although through long context windows, external tool calling, and prompt engineering (i.e., "context engineering"), models can achieve "temporary learning" within a single interaction. But this mechanism is fundamentally static: all information must be reinjected with every conversation, making it both inefficient and constrained.
On this point, reinforcement learning pioneer and Turing Award winner Richard Sutton once proposed a perspective: "Welcome to the Era of Experience." He argued that true intelligence comes from continuous interaction with the environment.
This model somewhat resembles the "lifelong learning" demonstrated by humans or certain animals — large models or agents learning continuously online, perceiving feedback, self-adjusting, even dynamically rewriting their own strategies. However, this autonomous learning model currently lacks mature algorithmic framework support. We look forward to new algorithmic developments in 2026 that could further elevate model intelligence.
II. Economic Impact: Can AI Break the "Productivity Paradox"?
Looking back at history, the first two industrial revolutions brought sustained leaps in total factor productivity. By contrast, despite computers and the internet being ubiquitous for decades, they seem not to have significantly boosted macro-level productivity data — a phenomenon known as the "Solow productivity paradox."
Why is this? One explanation: information technology mainly optimized information transmission efficiency, rather than directly replacing human core intellectual labor. It connected the world, but didn't truly "liberate" productivity.
AI's emergence may be changing this. As large models take on more and more intellectual work (programming, legal analysis) and robots gradually assume physical tasks (transportation, hazardous site exploration), humanity may achieve dual liberation of both intellect and physical labor. If this transformation penetrates key sectors like manufacturing, energy, and scientific research, it could potentially drive total factor productivity upward.
Of course, this process may also bring challenges. When efficiency improves and total GDP grows, but large numbers of workers are displaced, employment structure and income distribution will face drastic adjustment. We need to keep watching whether AI will exacerbate unemployment or inequality.
III. Investment Logic: From "Technology Narrative" Back to "Business Fundamentals"
Over 2023 and 2024, AI sector capital was mainly absorbed by three directions — large models, computing/chips and embodied intelligence, and related infrastructure projects. At this stage, investment logic was driven more by technology narrative: "Can the technology break through?" and "Who can seize first-mover advantage in models, chips, or intelligent robots?"
However, as the market gradually moves toward rationality, capital payback periods extend, and the AI industry enters the application deployment phase, investor focus is shifting. Compared to pure "technology narrative," investors are increasingly caring about a project's "business model fundamentals": Does it possess genuine competitive moats? Does it have a clear and sustainable economic model? Are user switching costs high? Does it demonstrate scale effects or network effects? Can it build a "data flywheel" through data accumulation, user feedback, and closed-loop mechanisms?
For entrepreneurs, this means it's no longer enough to say "we have the most advanced model" or "we're technologically ahead." You must present a business structure that can survive model iteration cycles and stand firm in actual combat — including replicable productization pathways, foreseeable revenue models, and steadily growing user systems, among other things. In short: shift from "what we can do" to "how we make money and keep growing."
Final Thoughts
Surveying the AI industry in 2025, what we see is a multi-layered stack of accelerating technology, industrial restructuring, and business models still taking shape.
Entering 2026, the key variable for the industry will no longer be "can model capabilities push one level higher" — the era of competing on model scale may have ended. Going forward, critical issues shaping AI's trajectory include:
- Can AI achieve online continuous learning, breaking through the structural constraints of "frozen parameters"?
- Can AI truly enter the physical world, becoming new infrastructure for embodied intelligence, robotics, autonomous driving, and other domains?
- Can AI applications build their own moats in specific domains while leveraging model capabilities and keeping appropriate distance from models, rather than being trapped by short-term cost pressures and high customer acquisition costs?
Overall, AI is a long slope with thick snow — a赛道 with enduring potential. As that time-tested aphorism goes: "People always overestimate technology's short-term impact and underestimate its long-term potential."
Currently, China's AI industry is carving out a unique path: breaking through technology blockades with open-source models, and opening market space through application globalization. This path isn't easy — it requires both patience and resolve. If we can use self-developed large models as the source of intelligence, then AI empowering all industries (including AI software, intelligent hardware, autonomous driving, embodied intelligence) will no longer be a distant vision, but a reality now unfolding.
Engagement Perk: What do you think the AI industry will look like in 2026? Share your thoughts in the comments. By 17:00 on December 4, 2025, the two most thoughtful commenters will receive a FreeS-curated book blind box.

How to Bridge the "Last Centimeter" of Robot-Real World Interaction?
Outlook 2025: What Innovation Opportunities Await in AI? | FreeS Report
"There's Always a New Opportunity in AI Hardware"
Seven Core Questions About DeepSeek, Explained | FreeS Report
Star the FreeS Fund WeChat Official Account — timely business insights delivered to you.