Where Does AIGC Go After ChatGPT's Explosion? | FreeS Report 28

Why AIGC Won't Be a Short-Lived Fad
"ChatGPT" may well be one of the biggest tech buzzwords to break into mainstream consciousness since late 2022. GPT stands for Generative Pre-trained Transformer, a type of generative pre-trained transformer model. This language model developed by OpenAI has ignited a fresh wave of enthusiasm for AI technology. People chat with ChatGPT about everything under the sun, ask it to translate text, write code, and draft articles. (P.S. — guess whether this article was written by ChatGPT?)
Behind the viral sensation, we've tried to develop a deeper understanding of ChatGPT. If AIGC (AI-generated content), represented by ChatGPT, is fundamentally a technological revolution, then discussing the topic without grasping the underlying technology will inevitably lead to skewed conclusions.
In this report, we'll first trace the historical evolution of ChatGPT: where it came from, and what technologies are driving it forward. Our analysis will also engage with the public discourse surrounding it: How long will its popularity last? Does it have a shot at becoming a "human brain" or artificial general intelligence (AGI)? Equally important, we'll ground our discussion in the venture capital industry, exploring startup and investment opportunities related to AIGC.
We hope this read offers fresh perspectives. If you're interested in AIGC topics or building in this space, we welcome you to reach out to the author, Chen Shi, partner at FreeS Fund (chenshi@freesvc.com).
Livestream Preview
This Saturday, March 11, at 9:30 AM, the second online session of "Trends 2023 — FreeS US-China Venture Capital Summit" will go live.
Among FreeS Fund's portfolio companies, several are innovating within vertical industry scenarios. For instance, Attic, an online psychological counseling platform; Teakan, a short-video and livestream SaaS provider; and BodyPark, an online personal fitness training platform — all are actively leveraging generative AI to empower their businesses. We'll invite the founders of these three companies to share their explorations and findings. All are welcome to join.
Scan to reserve the livestream on FreeS Fund's video channel
If you're interested in joining an industry community
Or would like to submit questions for our guests
Please scan the QR code to register
AI's vision of humans communicating with robots (Image source: Wenxin Yige)
01 What Exactly Is This ChatGPT That's Gone Viral?
The Essence of ChatGPT — Language Models
ChatGPT is, at its core, a language model. According to OpenAI's official description, ChatGPT has developed the ability to understand and generate human language text, enabling easy conversation with people.
Image source: OpenAI official website
Human language is extraordinarily complex, and even more complex than language itself is the thinking that creates it. People have long attempted to model language, but without significant success. ChatGPT has opened a new window for language modeling — one reason its birth made global waves.
Wikipedia defines a language model as "a probability distribution over sequences of words. Given any sequence of length m of words, a language model assigns a probability to the whole sequence." Stanford's open course puts it more directly: "A language model is basically just predicting the next word." (Stanford's definition captures the core principle of GPT, not BERT-style language models. Perhaps this indirectly reflects how GPT's technical approach has come to be seen as the mainstream language model path.)
The GPT family of language models has one primary objective: predicting the next word. For example, given the first half of a sentence — "the students opened their" — the language model calculates the probability that the next word will be "books," "laptops," "exams," or something else. Though the technical principle of language models is simple, it has given rise to an intelligent product with complex application scenarios like ChatGPT.
ChatGPT May Be the Most Successful Large Language Model to Date; We're Living Through an iPhone Moment
ChatGPT may be the most successful language model to date. People are calling the moment of its emergence the "iPhone moment."
GPT stands for Generative Pre-trained Transformer. The Transformer neural network algorithm is the latest model architecture, which we'll expand on below. The GPT series models are all language models, the product of multiple overlapping factors: novel neural network algorithms, new model training methods, and massive data and compute power.
GPT models have several major versions, evolving from GPT-1, GPT-2, and GPT-3 to the latest GPT-3.5.
The ChatGPT people are using today was built on version 3.5, with extensive fine-tuning specifically for human needs to guide the model toward outputs that better serve human requirements. This has gradually "socialized" the GPT model, making it more human-like. The fine-tuned ChatGPT has grown more emotionally intelligent — no longer just a chatterbox, and no longer so unfiltered.
The Birth of ChatGPT
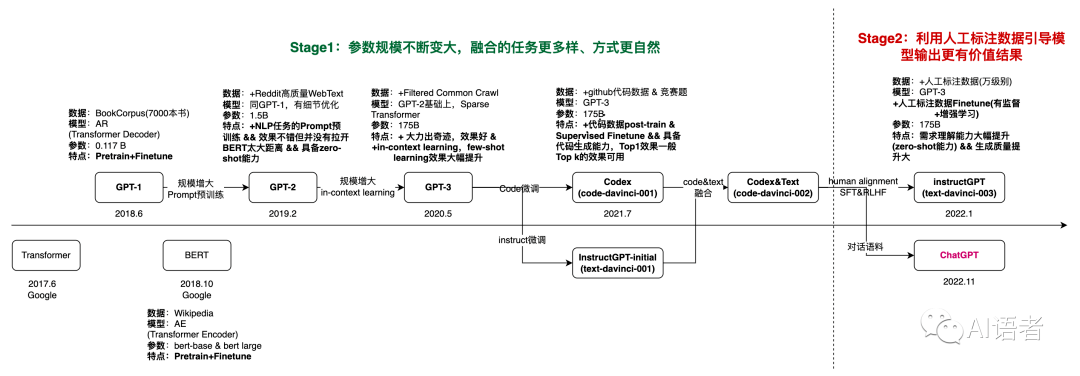
Image source: WeChat public account @AI Yuzhe
Before ChatGPT arrived, what developmental journey did GPT models undergo?
In June 2017, Google released Transformer, a neural network algorithm model that laid the foundation for large language model development.
A year later, OpenAI introduced GPT-1. GPT-1 adopted a two-stage training approach of language model pre-training plus fine-tuning, achieving decent performance on question-answering, commonsense reasoning, semantic similarity, and classification tasks.
In October 2018, Google launched another language model — BERT — which outperformed GPT-1.
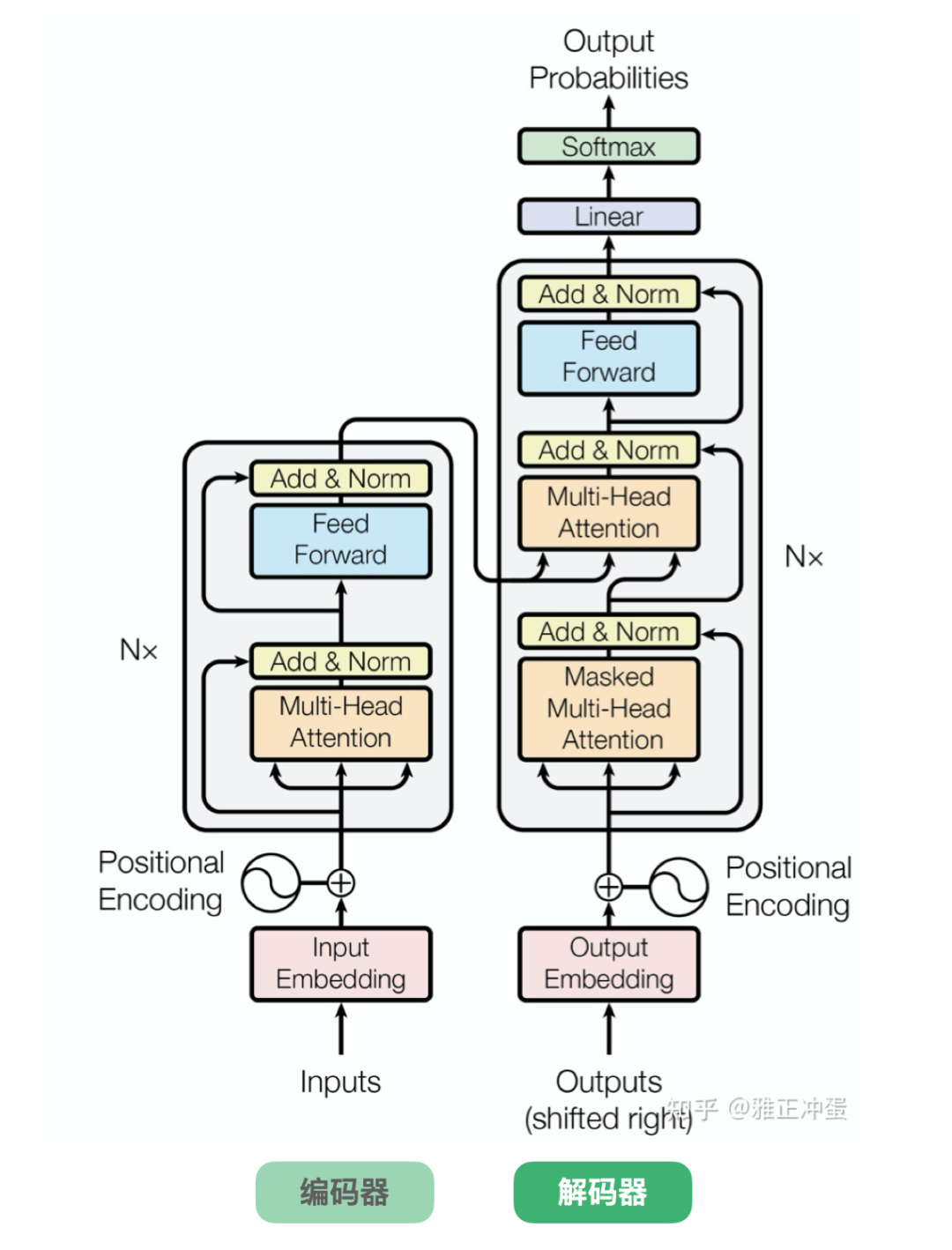
Image source: Zhihu @Yazheng Chongdan
Both GPT and BERT are algorithms derived from Transformer, but with different technical emphases. GPT is based on the right side of Transformer, called the decoder. BERT is based on the left side, called the encoder.
GPT's technical principle is predicting the next word — think of it as "word solitaire": you write the preceding sentence, and GPT guesses the next word. BERT, by contrast, is more like "cloze deletion"; its technical principle involves masking a word in a sentence and asking BERT to fill it in.
Decoders excel at generation; encoders excel at comprehension. At the time, the tasks at hand were more oriented toward masked language modeling (similar to cloze deletion) and next sentence prediction (determining whether sentences connect), so BERT held the advantage.
In 2019, GPT-2 was released, employing a 1.5-billion-parameter Transformer decoder — a relatively large model at the time. Compared to BERT, OpenAI researchers found that GPT-2's pre-trained language model could directly perform various downstream tasks without fine-tuning. This discovery solidified the researchers' resolve to continue along their existing technical path.
In May 2020, GPT-3 was born, featuring an unprecedented 175-billion-parameter Transformer decoder and training data approaching 500 billion words. The entire training process was essentially "brute force miracle-working," enabling a qualitative leap in GPT-3's text generation. Beyond excelling at language tasks like text generation, translation, question-answering, and text completion, GPT-3 also "emerged" with other intelligent capabilities, including in-context learning and more powerful zero-shot and few-shot task execution.
The quality of GPT-3's generated text was so high that people sometimes struggled to distinguish whether a text was human-written or GPT-3-generated.
Numerous applications have already been built on GPT-3, with people using it to create various types of text. Someone used it to write a news article that ranked at the top of a popular news review site. A company called Jasper leveraged GPT-3 to provide business copywriting services for enterprises, generating roughly $90 million in revenue in 2022.
After GPT-3, OpenAI added programming code training and human feedback reinforcement learning, among other training methods, upgrading the main version to GPT-3.5. Finally, in November 2022, ChatGPT burst onto the scene.
The Three "Big" Elements of Training GPT-3: Algorithms, Data, and Compute
We call GPT-3 a large model. Where does this "largeness" manifest?
First, algorithms. GPT-3 uses the Transformer decoder, with 175 billion parameters and a training text length of 2,048 tokens (simply understood as words, hereafter).
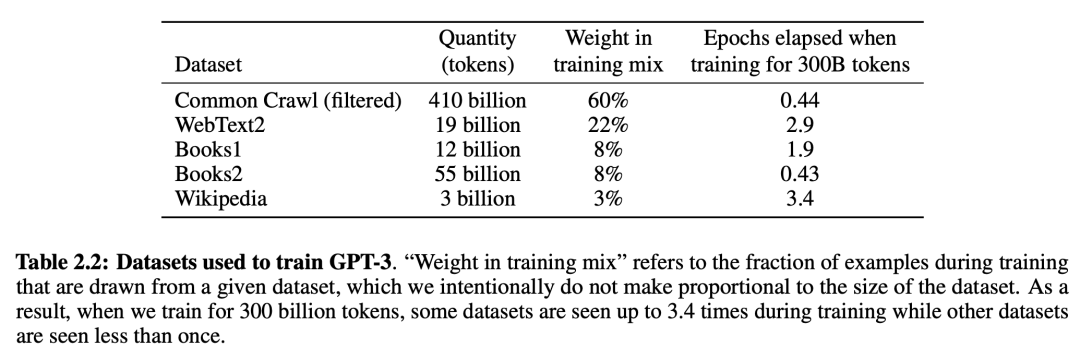
Image source: OpenAI team paper Language Models are Few-Shot Learners
Second, data. The image above shows GPT-3's training data: approximately 500 billion tokens of text in total, mainly including Common Crawl, WebText2, Books1, Books2, Wikipedia, and others. The largest share of training data is Common Crawl, an open-source dataset that crawls and archives data from a vast number of web pages globally.
Third, compute. According to information released by Microsoft, OpenAI used a top-5 globally ranked supercomputing system to train GPT-3. The system boasts over 285,000 CPU cores, 10,000 GPUs, and 400 Gbps networking. Training costs are estimated at approximately $12 million.
02 How Are People Viewing ChatGPT?
Since ChatGPT's debut, it has sparked considerable debate. So, how are people actually viewing this new thing, and what do they expect from it? Though opinions vary, three topics come up again and again.
▍People acknowledge ChatGPT as a competent language model
First, ChatGPT is the most successful human language model to date, already possessing formal linguistic competence — knowledge of the rule-governed patterns of language, among other things.
ChatGPT can understand and generate human language text, enabling effortless conversation with people. Its data-driven, large-scale neural network computation has, to some degree, decoded the internal regularities of human language. These regularities aren't formulas but rather a mysterious matrix of weight parameters that humans don't yet fully comprehend.
Previously, people believed that algorithmic models would struggle to acquire knowledge about language if they relied solely on text input. But now, ChatGPT can directly learn hierarchical structures and abstract categories of language from text — an unsupervised learning capability.
Moreover, ChatGPT isn't just a chatterbox. It can write essays, compose poetry, draft business documents, translate, do reading comprehension, and understand and generate code. As a language model, it's already fairly competent.
▍People hope ChatGPT will develop thinking capabilities
Expectations for ChatGPT go beyond language modeling. People even hope it will become a thinking machine, developing functional linguistic competence — the ability to use language to think and act.
ChatGPT has "emerged" with certain intelligent behaviors, including in-context learning (the ability to understand and learn from human conversational input), abstraction of world knowledge (such as factual and commonsense knowledge), execution of generalized tasks (including novel ones it hasn't encountered before), and complex reasoning. However, these capabilities are still not particularly robust at present; errors and even crashes occur with some frequency.
Currently, there's extensive exploration in the direction of thinking machines. One approach, for instance, uses Chain of Thought to guide or optimize language models into displaying complex reasoning abilities. Progress in these research directions continues.

The image above shows a researcher eliciting step-by-step thinking and calculation from ChatGPT through a conversation, using few-shot prompting with worked examples (the guidance process itself isn't shown). Analysis suggests this capability comes from the GPT-3.5 model itself; the Chain of Thought training method merely makes it aware that it should think and answer in this manner. The whole process is somewhat akin to a teacher tutoring a student through a problem.
Though this problem would be easy for a ten-year-old, it's difficult for a language model, mainly because math and language are mixed together. Such problems are just the beginning — current cutting-edge Chain of Thought research has already moved on to harder challenges, such as high school, university, and even International Mathematical Olympiad problems.
A recent paper from UCLA found that ChatGPT appears to demonstrate analogical reasoning ability.
What is analogical reasoning? There are three types of reasoning: deductive, inductive, and analogical. "Analogical reasoning is often regarded as a hallmark of human abilities for abstraction and generalization. Across a broad range of problem types, ChatGPT matches or exceeds human-level performance... demonstrating this zero-shot analogical reasoning ability."
However, ChatGPT's reasoning ability is constrained by its lack of physical understanding of the world, because it relies solely on text input and lacks multimodal data inputs such as vision (images and video), sound, and smell. Text's physical description of the world is limited. For example, it's hard to describe through text exactly where different objects are positioned in a room — whereas a single image of that room makes the spatial information immediately clear.
GPT-4 is reportedly scheduled for release in 2023, and it will incorporate multimodal inputs including vision. This is expected to further boost its intelligence.
▍There is intense controversy over whether ChatGPT can become a "human brain" or artificial general intelligence
At present, debate remains fierce over whether ChatGPT can evolve into a "human brain" or artificial general intelligence (AGI). Yann LeCun, one of the three giants of deep learning and chief AI scientist at Meta (formerly Facebook), believes machines differ from humans in that humans construct a virtual world in their minds for reasoning and simulation — something machines currently cannot do.
The renowned linguist Noam Chomsky noted in a 2019 interview that deep learning leans more toward engineering, somewhat like a bulldozer: it can be used, but it has no capacity to tell you anything about human language. (Note: Language models like ChatGPT can output impressive text, but we don't have conclusive evidence that they truly grasp the rules of language. It's also possible that they do grasp them, but in ways humans cannot understand.)
Scholars like Kyle Mahowald argue that being "good at language" doesn't necessarily mean being "good at thinking." Although human language and thought are inseparable, the brain regions specialized for language processing are separate from those responsible for memory, reasoning, and social skills. Therefore, we shouldn't expect too much from language models.

Mahowald cited a failure case where GPT-3 couldn't figure out how to get a sofa onto your roof.
As we mentioned earlier, knowledge about the physical world — roofs, sofas, cranes — comes more naturally to humans, who can easily think of various ways to get a sofa onto a roof. But it's difficult to get ChatGPT to understand this line of thinking. This example also illustrates the importance of physical world knowledge input, particularly multimodal data like vision.
The underlying technology and discoveries are impressive, but there's still plenty of room for development
Now that we've covered what ChatGPT is, let's talk about the technology behind it.
As we mentioned earlier, ChatGPT essentially uses a "next-token prediction" mechanism — a deceptively simple technical principle for training and using language models to achieve high-quality intelligent text conversations with humans. This principle theoretically offers opportunities for upgrades and improvements that could yield even better results.
Regarding neural network parameter scale, some in the industry believe there's optimization potential — for instance, whether comparable results could be achieved with smaller models. The 2,048-token text input window design and its computation mechanism may also have room for optimization. For example, some are currently trying to get ChatGPT to write mystery novels, but推理线索 in such novels are often subtle and distant (a small clue from several chapters earlier, for instance) — far beyond the 2,048-token window. How to incorporate knowledge and information from outside the current window remains an open optimization question.
Overall, the Transformer architecture underlying these models only emerged in June 2017. It's still in an early stage of development, undergoing rapid iteration and refinement, and should have considerable room for growth.
Additionally, the multimodal data input mentioned earlier — what emergent capabilities and performance improvements it might bring to GPT-4 — is something both industry insiders and the general public are eagerly awaiting.
▍What can humans learn about language from ChatGPT?
In exploring human language, ChatGPT has gone further and deeper than any previous product. What can we humans learn from it?
Scientist Stephen Wolfram believes that human language may not be as complex as we think — it's just that humans lack the capacity to understand and grasp its underlying rules. ChatGPT, using neural network-based algorithms, has successfully decoded the essence of human language.
According to OpenAI's published GPT-2 paper, GPT-2's training data was purely English text (with non-English text filtered out). Even so, it displayed some multilingual capabilities and showed remarkable French-English translation ability, despite receiving only about 10MB of residual French text in its training data.
This phenomenon has prompted reflection: humans currently invest enormous time and effort in language learning — is there room to improve this efficiency? Can we learn from language models to study human language more effectively?

When generating text, ChatGPT selects one word at a time from a probability distribution provided by the language model. Researchers have found something curious: always choosing the highest-probability word is theoretically optimal, yet the result tends to be a very ordinary piece of writing. But if you don't always choose the optimal option — say, randomly selecting from slightly lower-ranked alternatives — there's a greater chance of generating something excellent. This remains an intriguing unsolved puzzle.
Previously, we might have assumed that composing an essay or a poem involved careful human deliberation and creation. But for AI, creation means probability and selection. What we consider brilliant literary creation turns out to be, for AI, a rather dry process of choosing. Viewed through ChatGPT, humans may still know very little about the true mysteries of language.
▍Word distribution in the language feature space

**GPT vectorizes text, establishing a high-dimensional feature space of language, also known as latent space.
In GPT-2, each word is a 768-dimensional vector; in GPT-3, each word is a 12,288-dimensional vector. Each dimension represents an attribute — meaning GPT-3 uses over 10,000 attributes to describe the characteristics of words in human language.
Stephen Wolfram attempted to open up this feature space of human language to observe its patterns. He chose the smaller-scale GPT-2 feature space and mapped it to a two-dimensional space more easily comprehensible to humans, discovering many interesting phenomena. For instance, "crocodile" and "alligator" cluster closely together, as do "apple" and "pear" — fairly intuitive. More interestingly, relationships between words can also be reflected through vector arithmetic: the vector for "king" minus the vector for "man" plus the vector for "woman" yields the vector for "queen."
Additionally, he attempted to trace the wandering patterns within GPT-2's linguistic feature space — how it navigates through 768 dimensions to sequentially choose each next word. We can see this process in the image above, but unfortunately, he has yet to discover any underlying规律. Though much information is lost when mapping from high to low dimensions, combining vectors across multidimensional spaces may reveal deeper patterns about language in the future.
▍The Transformer Neural Network Architecture and Attention Mechanism
In June 2017, Google published the landmark Transformer paper, titled Attention Is All You Need — meaning that attention mechanisms alone are sufficient.
Image source: Zhihu user @雅正冲蛋
The Transformer architecture diagram above shows, as previously mentioned, the encoder on the left and the decoder on the right. Google's BERT uses the encoder, while OpenAI's GPT series uses the decoder.
In AI, there are four major types of neural network algorithms: MLP, CNN, RNN, and Transformer. MLP stands for multilayer perceptron, CNN for convolutional neural network, and RNN for recurrent neural network.
Transformer is the most recent algorithmic model. It is gradually replacing CNNs and RNNs in certain scenarios. Transformer excels at feature extraction, long-sequence processing, parallel computing, and multimodal handling. Its attention mechanism resembles human selective focus — with limited resources, it attends only to what matters most.
Transformer has been widely adopted in natural language processing, computer vision, and biotechnology. AlphaFold, used in the biotech industry to predict protein 3D structures, is built on the Transformer architecture.
▍Which Module Stores GPT-3's Intelligence?
When GPT-3 was released, the OpenAI team published the paper Language Models are Few-Shot Learners.
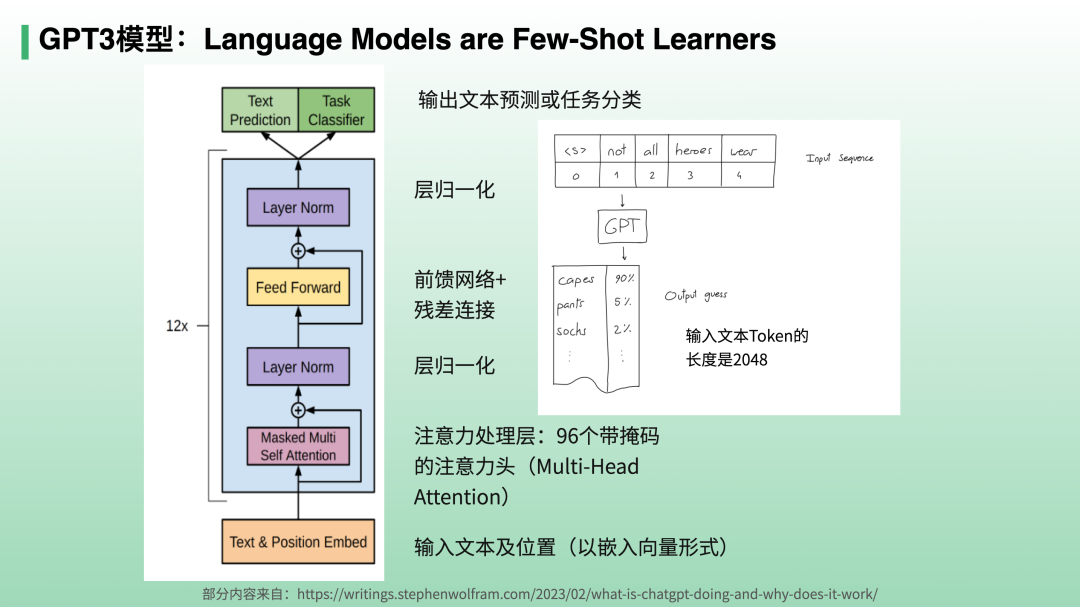
The diagram above shows the GPT-3 model architecture, which largely mirrors the decoder portion of the Transformer. Whether in pre-training or inference (task execution), input text is fed from the bottom (GPT-3's maximum context length is 2,048 tokens), processed through 12 layers, and output as next-token probability predictions from Text Prediction. (Task Classifier is a fine-tuning branch, not discussed in detail here.)
An intriguing question: GPT-3 uses 175 billion parameters to learn from roughly 500 billion words — clearly it isn't simply storing three words per parameter. Rather, it has largely grasped certain linguistic patterns and abstracted knowledge and capabilities. So where exactly are these patterns, knowledge, and capabilities stored?
Some researchers believe the 175 billion parameters are concentrated in the attention processing layers and feedforward network layers shown in the diagram. The former are dynamically computed (recalculated for every 2,048-token input) — data-dependent dynamic weights that shift based on the input. Feedforward network weights, by contrast, change slowly over the course of training. Thus, some scholars hypothesize that the feedforward layers store the linguistic patterns, knowledge, and capabilities GPT discovers. Since the computation proceeds through 12 layers, information stored in later layers tends to be more abstract.
Stephen Wolfram extracted a 768×768 weight parameter matrix from one of GPT-2's feedforward layers, compressed it to 64×64, and produced the mysterious image below — representing a fragment of GPT-2's distilled encoding of human linguistic patterns, along with other knowledge and capabilities. One wonders when scientists might gradually decrypt portions of it; doing so would surely benefit human self-improvement.
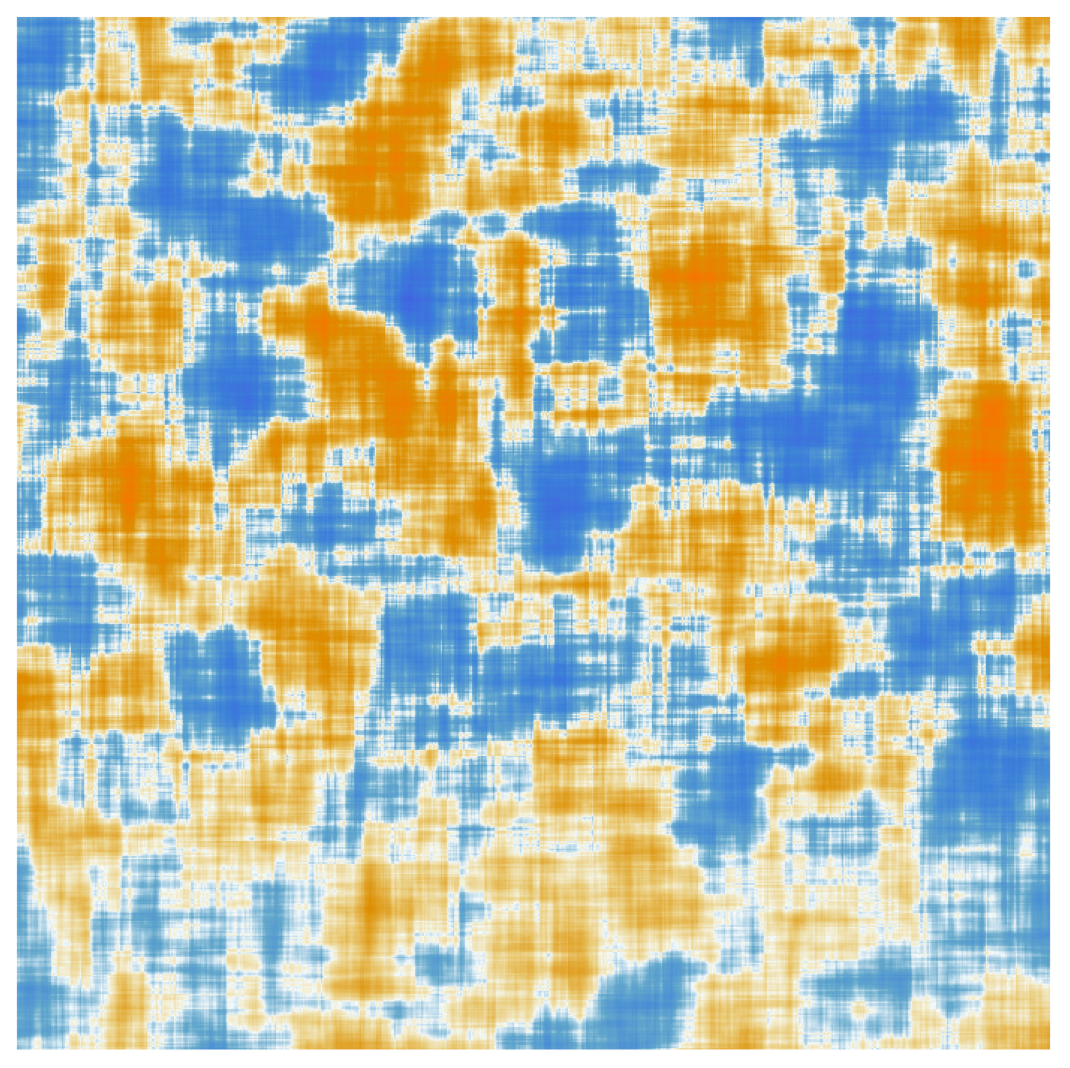
Image source: writings.stephenwolfram.com
/ 04 /
In the Future, Can ChatGPT Evolve Self-Awareness?
Compared to AI, self-awareness and free will might count as humanity's last fortress.
Yet one view holds that humans don't actually possess free will. We have two selves: an experiencing self and a narrating self. The experiencing self relatively "mechanically" interprets information and makes decisions; the narrating self then explains and articulates those decisions, sometimes even fabricating stories to "deceive" ourselves. So-called free will is merely a story the narrating self tells itself.
Some scientists and scholars believe that, in theory, we could construct a self-simulating self-referential machine — equipped with dual systems, one executing algorithms and another dedicated to simulating the self (description, or what might be called simulating the self within an embedded virtual world). Such a machine would behave "as if" it possessed self-awareness, to the point that we might use such systems to define "self-awareness" itself.
In ancient Europe, there was a legendary ouroboros — a serpent eating its own tail, achieving continuous self-renewal. Later, the concept of the Gödel Machine was proposed: if a program can simulate and modify itself, it might be deemed self-aware. Additionally, Quine program structures and Kleene's second recursion theorem have advanced similar hypotheses.

Image source: Wikipedia
It is difficult to predict whether machines might evolve self-awareness in the future.
/ 05 /
Other Developments in Generative AI
It should be noted that generative AI, as currently discussed, differs considerably from earlier analytical AI. Analytical AI primarily analyzes — data analysis, trend forecasting, product recommendations, image recognition, and so on. Generative AI primarily creates — writing poetry, painting, designing products, writing code.
Beyond language models, current generative AI progress includes image generation models, among others. Future advances in multimodal (text, image, video) alignment, fusion, understanding, and generation will also be profoundly significant.
Regarding image generation models, diffusion models deserve special mention. They primarily address the challenge of generating images and other media formats from text. Notable diffusion models in the industry include DALL·E 2 and Stable Diffusion.
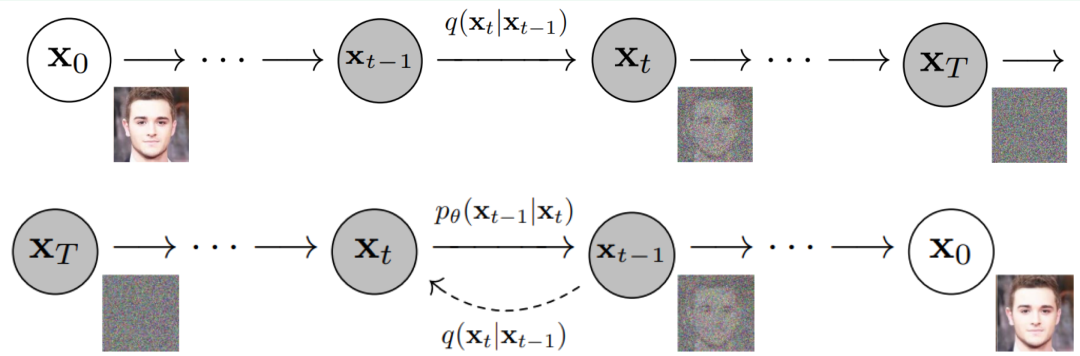
Image source: Denoising Diffusion Probabilistic Models
/ 06 /
Six Thoughts and Recommendations on Generative AI Entrepreneurship
In 2022, large language models exploded. According to statistics, a new large language model emerged on average every four days that year.
Generative AI technology has also been driving substantial traffic growth to well-known model-layer platforms and applications, with investment running hot. Between 2019 and 2021, capital flowing to generative AI businesses increased by roughly 130%, with text and writing up 630%, images up 400%, data up 370%, and audio/video up 350%.
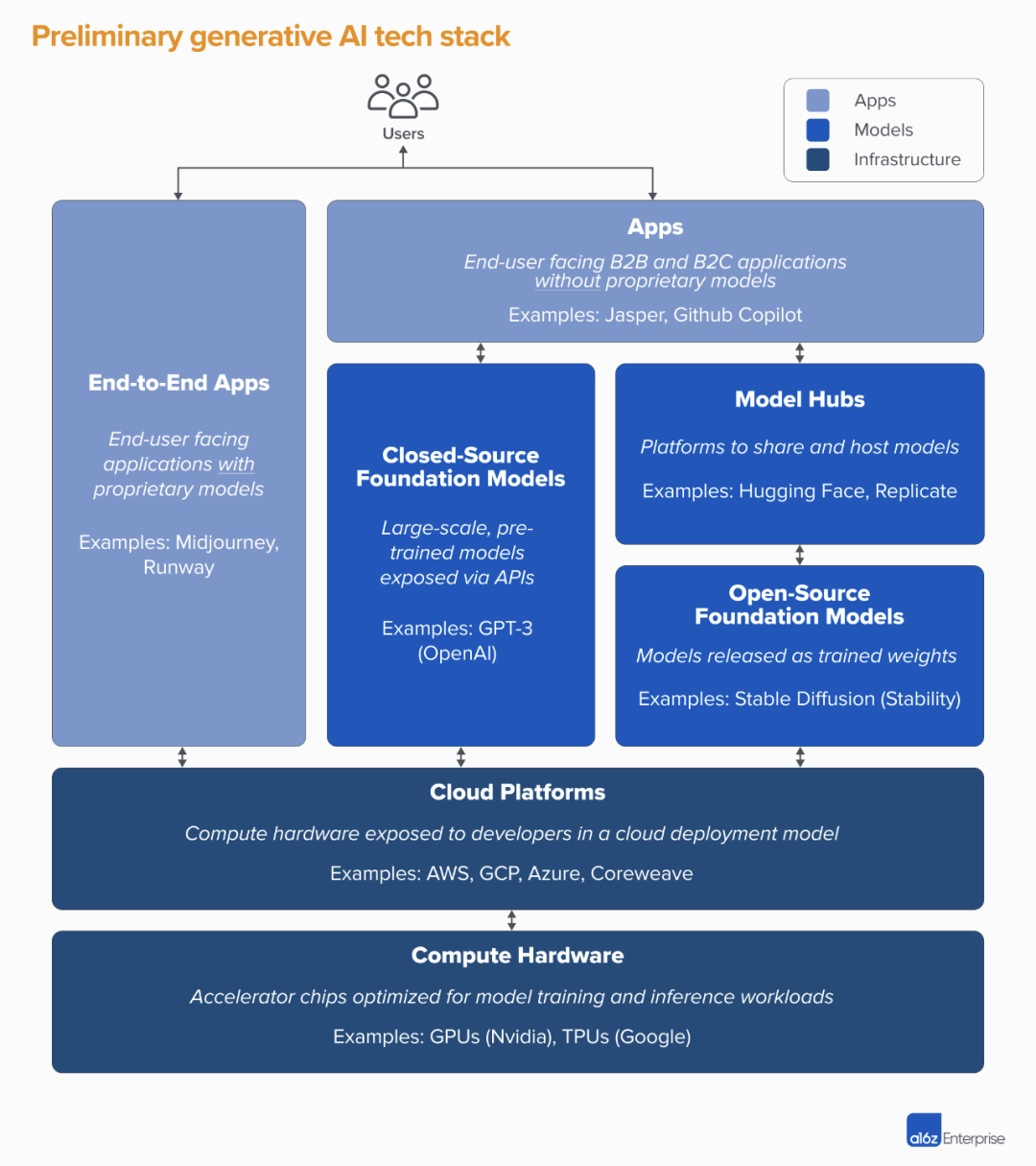
Image source: A16Z
The diagram above, from investment firm a16z, summarizes the generative AI industry stack. The dark blue base layer comprises foundational hardware and cloud platforms; the middle blue layer is the model layer; and the light blue upper layer is the application layer.
In the application layer, some startups build only applications, sourcing model capabilities externally; another approach is end-to-end application, where companies develop their own models — though generally not large foundation models, or instead fine-tuning atop existing large models.
In the model layer, there are open-source and closed-source models. The dark blue "Model Hubs" are third-party platforms for model storage and training.
Application-layer growth has been relatively rapid, driven primarily by novel AI-enabled use cases concentrated in image generation, copywriting, and code generation — each category now generating over $100 million in annual revenue.
Regarding generative AI entrepreneurship, I have six thoughts and recommendations:
First, AI-related research, engineering, product development, and commercialization are all iterating rapidly and simultaneously, with considerable uncertainty. Different technical branches and business paths will emerge; choosing the wrong one and then pivoting is painful. This requires founding teams to understand both technology and business, and to make sound choices early on.
Second, for startups, entering through the application layer or end-to-end application layer may be a relatively lower-risk approach. The model layer offers limited opportunities and may not suit most entrepreneurs.
Third, when designing business models at the application layer, be wary of the model layer's boundaries.
Take Jasper as an example. In 2020, building on the GPT-3 model, Jasper developed a paid business text writing model. By late 2022, when ChatGPT became freely available to users, Jasper faced significant pressure. Although OpenAI may not have made commercial text generation its primary business model, it leveled the playing field for other competitors entering the market. To maintain its footing, Jasper needed to demonstrate competitive technical depth and business vertical integration.
Fourth, applying AI technology to industrial scenarios can be divided into two approaches: new models and legacy model transformation. New models refer to creating entirely new application scenarios that didn't exist before. Legacy model transformation refers to using AI technology to retrofit parts of existing industrial scenarios, or teams bringing deep industry expertise combined with new AI technology to innovate within mature industrial contexts. Both new models and legacy transformation present enormous opportunities.
Among FreeS Fund's portfolio companies, several are innovating within vertical industry scenarios. For example, online psychological counseling platform Golo, short video and live-streaming SaaS provider TeKan Technology, and online personal fitness coaching platform BodyPark are all actively using generative AI to empower their businesses. This Saturday (March 11), we will invite the founders of these three companies to share their explorations and findings — all are welcome to join.

Fifth, AI also faces the challenge of rapid knowledge spillover from research, so finding your own moat is critical. Startups must clearly think through where their future moat lies — whether it's data moat, engineering moat (such as model fine-tuning), scenario moat, or scale moat, among others. For application-layer entrepreneurship, relying solely on capabilities provided by external model layers cannot form a sustainable moat.
Sixth, application-layer entrepreneurship should be "technology-first, scenario-heavy."
"Technology-first" means that while general-purpose AI technology may not be your core moat, the team must understand technology to be able to think through how to apply it earlier and better to suitable scenarios, creating genuinely usable products.
"Scenario-heavy" means that the final product and business need to find appropriate landing scenarios, establish their own business models, and develop core competitiveness within those scenarios.
/ 07 /
Outlook and Speculation on the Future Landscape of Generative AI

Finally, let's discuss future outlook and speculation on the AI industry landscape. For this section, I draw on a conceptual framework previously articulated by Dr. Qi Lu of MiraclePlus.
▍The New IT: Centered on AI and Large Models
New silicon-based hardware industry: Silicon-based industrial architectures and assemblies may welcome new development opportunities (for example: new computing chips and surrounding technologies and industries).
New software and cloud service systems: Cloud services for computing power, models, and data; foundational software; ML & DevOps; human-AI collaborative programming tools, and more.
▍New foundational intelligent terminal devices: smart sensors, new forms of phones, etc.
Future intelligent terminals will become increasingly smart. Recently, Apple announced support for running the Stable Diffusion image generation model on iPads and other terminals; engineers have also managed to run trimmed-down versions of Stable Diffusion on iPhones. One can imagine how extraordinarily sophisticated our phone beautification and photo generation capabilities will become.
Moreover, current translation software technology still operates at a relatively shallow level of semantic understanding, with translation quality that is merely acceptable. If we could embed language model capabilities comparable to ChatGPT into intelligent terminals, enabling real-time text and voice translation, cross-lingual communication would become remarkably convenient — significantly enhancing human communication efficiency.
▍Industries centered on content creation
AI-powered content creation tools across text, image, video, 3D, and various other media formats represent one of the most opportunity-rich new industries currently visible.
Text generation technology represented by language models like ChatGPT, and image-video multimodal generation technology represented by diffusion models, may profoundly impact the content industry. From PGC to UGC, and now to AIGC, the content domain will see even more new changes and new possibilities.
Looking at media industry development, current leading content media platforms such as Douyin, Kuaishou, and Bilibili are so-called Web 2.0 platforms that predominantly rely on UGC for content production. However, with the emergence of AI-generated content (AIGC), AI can produce large volumes of high-quality content at low cost with excellent results — and even genuine creativity. Under these circumstances, content media platforms and the broader industry may undergo significant transformation.
▍Industries centered on language models
In this domain, new opportunities may include: transformed paradigms for language learning, reshaped cross-lingual communication methods, and more human-friendly human-computer interfaces.
Particularly worth noting is the transformation of language learning paradigms. As mentioned earlier, if we can open up language models and discover the patterns underlying language learning, we might be able to help people learn languages more efficiently. In fact, OpenAI invested in a Korean English-learning app called Speak. From limited public information, this company's future product appears to be a language learning assistant, or virtual language teacher — leveraging language model capabilities and discovered linguistic patterns to help people learn foreign languages better, and at extremely low cost.
Cross-lingual communication technology remains immature. As noted above, if we can load language models onto intelligent terminals, it could dramatically improve cross-lingual communication capabilities.
Because language models are sufficiently powerful, future human-computer interfaces will adopt more natural language-based interaction, whether conversing with apps or with intelligent hardware.
Industries centered on thinking models
Let's imagine: smarter software (or robots), scientific research services, "knowledge engineering," "world brain," and more.
The current software industry, even with AI assistance, still falls short in terms of generality and intelligence — in most cases it can only handle specific tasks, serving merely as human efficiency assistants. As more general-purpose AI capabilities emerge, software could think and act like humans, enabling it to take on more complete tasks on our behalf.
If AI can develop thinking capabilities approaching human level, it might become a research assistant to human scientists, given its tirelessness and scalability. Currently, it's difficult to imagine AI reaching the level of top human scientists. For example, asking it to prove Goldbach's conjecture would still be quite unrealistic. Of course, other possibilities exist: as mentioned earlier, if AI programs can achieve self-optimization with the ability to iterate their own algorithms and techniques, their intelligence could catch up rapidly.
If we let our imagination run further, even more possibilities emerge. Take "knowledge engineering": if human knowledge could be modeled and made accessible or learnable in some fashion, we could bypass the "painful" learning process. "World brain" refers to extremely large-scale thinking models that could help us execute various important computations and reasoning. However, if things truly develop to this point, we may not be far from the Matrix depicted in The Matrix.
Empowering humanity, deeply transforming all industries (especially knowledge workers)
Language is humanity's primary mode of communication and the main carrier of knowledge and thought; deep thinking is humanity's higher-order capability and the most important ability distinguishing us from other species. If AI masters both of these capabilities, it essentially gains the potential to empower or partially replace certain knowledge workers.
Much as automated manufacturing equipment empowered traditional industry, various AI models and applications will have opportunities to better empower all industries. But unlike manufacturing, software deployed at scale has extremely low marginal usage costs — and it's smart, learns quickly, thinks, and communicates. There should be vast application scenarios waiting to be developed. This contains enormous entrepreneurial opportunities and will bring new momentum to all industries.
Final thoughts: Why AIGC won't be a short-term fad
First, ChatGPT represents a major advance in language models. Given the profound significance of language to human communication and thought, the inherent generality of language models, and the potential for humans to study language models to discover patterns of language and knowledge acquisition for efficiency gains — these factors will continue to generate long-term innovation opportunities.
Second, AI still has much further to go in the direction of thinking machines. For example, if AI can achieve robust multimodal information input and enhanced understanding of the physical world, it may "emerge" with greater intelligence. Any progress in this direction would be profoundly significant.
Third, the underlying technical principles and algorithms related to AIGC are still in early stages of development, with substantial room for future iteration and optimization.
Everything is just beginning.
Livestream Announcement
Saturday, March 11 at 9:30 AM, the second online session of "Trends 2023 — FreeS Fund China-US Venture Capital Summit" will go live.
Among FreeS Fund's portfolio companies, several are innovating within vertical industry scenarios. For example, online psychological counseling platform Golo, short video and live-streaming SaaS provider TeKan Technology, and online personal fitness coaching platform BodyPark are all actively using generative AI to empower their businesses. We will invite the founders of these three companies to share their explorations and findings — all are welcome to join.

Follow FreeS Fund's video channel to reserve your spot for the livestream

If you're interested in joining an industry community
Or would like to ask questions of our guests
Please scan the QR code to register


▲ Trends 2023 | FreeS Fund China-US Venture Capital Summit Registration Now Open ▲ Join FreeS Fund and Discover New Changes and Opportunities ▲ What Will Humans Eat in the Future? | FreeS Report 27 ▲ How Will Humans Work in the Future? | FreeS Report 26 ▲ China's Dietary Structure and Food Investment | FreeS Report 25 ▲ FreeS Report 24 | Embracing the "Smartest" Opportunity: Investing Boldly in Brain and Neuroscience

