A Deep Dive into 7 Core Questions About DeepSeek | FreeS Fund Report

In an era of rapid AI advancement, the DeepSeek story is only just beginning.
On February 10–11, Paris hosted the Artificial Intelligence (AI) Action Summit. The New York Times reported that, like all AI events over the past month, the Paris summit was filled with discussions about Chinese AI company DeepSeek — a firm that shocked the world with its powerful reasoning models. According to Caijing magazine, more than 100 Chinese companies have announced they are "integrating DeepSeek," covering every layer of the ecosystem from chips and compute providers to AI users and end users.
At the first all-hands meeting after the Lunar New Year holiday, colleagues on FreeS Fund's technology team held an in-depth discussion about DeepSeek. This article examines the reasons behind DeepSeek's explosive popularity and its multi-dimensional impact through seven key questions:
- Why did DeepSeek become so popular?
- What is DeepSeek's real technical innovation?
- Why DeepSeek?
- Does the scaling law still hold?
- What impact does DeepSeek have on other model vendors?
- What impact does DeepSeek have on the hardware ecosystem?
- How does DeepSeek affect the application ecosystem?
Additionally, we've summarized some related investment opportunities at the end of the article.
In this era of rapid AI advancement, DeepSeek's story may only be the beginning.
Engagement Perk: What do you think about the new opportunities DeepSeek has created? Share your thoughts in the comments — by 17:00 on February 25, the five most thoughtful commenters will receive a FreeS Fund research handbook.


/ 01 / Why Did DeepSeek Become So Popular?
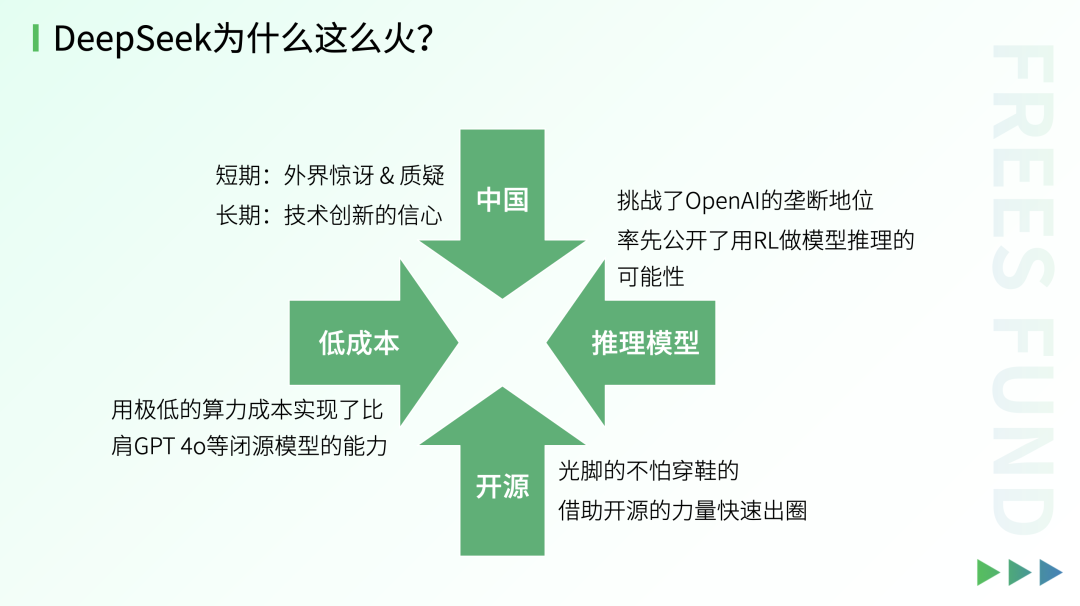
First question: why exactly did DeepSeek blow up?
From our observation, DeepSeek's viral moment this time around was 20% due to technical innovation and 80% due to the influence it gained from the open-source ecosystem — plus the China factor behind it.
Technically speaking, DeepSeek achieved capabilities on par with top-tier global pre-trained large models at extremely low compute costs. And for the first time, DeepSeek truly open-sourced a viable path to building reasoning models using Reinforcement Learning (RL). RL is a machine learning method where an agent learns optimal strategies through interaction with its environment.
To be honest, these achievements alone might not have been enough to trigger such a strong global reaction.
Most of the influence actually stems from the China factor behind these innovations. To some extent, due to information asymmetry between China and the rest of the world, this large language model from a Chinese team surprised people — the gap between China's AI development and the state of the art represented by OpenAI may not be as large as imagined. At the same time, DeepSeek also sparked considerable skepticism and debate. Of course, these are short-term effects.
In the long run, DeepSeek's success has given China more confidence in technological innovation. Both investors and entrepreneurs likely see more possibilities in it.
Also, open source deserves significant credit. As a latecomer, unlike major overseas tech companies, DeepSeek had nothing to lose — the "barefoot aren't afraid of those wearing shoes." DeepSeek open-sourced nearly all of its research findings, breaking OpenAI's monopoly on its o1 series of models and sending shockwaves through the entire community.
Key Takeaway

So, looking rationally at DeepSeek's breakout, market sentiment accounts for the bulk of it. Of course, we can't deny that the DeepSeek team has indeed made significant technical innovations.
/ 02 / What Is DeepSeek's Real Technical Innovation?
Since its founding, DeepSeek has published nine papers. In fact, within the large model technical community, people have long recognized DeepSeek's technical capabilities.
The answer to DeepSeek's technical innovation lies in two technical reports published at the end of 2024 and beginning of 2025 — "DeepSeek-V3 Technical Report" and "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning" — along with the open-source models they released.
From current observations, DeepSeek's technical contributions mainly manifest as engineering innovations. It didn't invent new paradigms, but made extensive optimizations on top of existing technologies.
Let's focus on the core work that made DeepSeek famous:
I. DeepSeek V2
In May 2024, DeepSeek released the V2 model, slashing API (Application Programming Interface) prices dramatically — pricing at 1 RMB per million input tokens and 2 RMB per million output tokens, directly undercutting GPT-4 by a factor of 35.
DeepSeek ignited a pricing revolution in the large model market. According to 21st Century Business Herald, in May 2024, Baidu made two flagship models of its Wenxin large model completely free. Alibaba Cloud followed suit, cutting the API input price for its Qwen GPT-4-class flagship model from 0.02 RMB per thousand tokens to 0.0005 RMB per thousand tokens — a 97% reduction.
DeepSeek V2's performance was already close to GPT-4, making it an extremely cost-effective choice. While domestic competitors were still struggling to catch up to GPT-4's performance, DeepSeek had already distinguished itself through low prices and high performance.
II. DeepSeek V3

DeepSeek V3 built on V2, further strengthening its cost-cutting and efficiency gains. V3 is essentially a pre-trained large model benchmarked against OpenAI's GPT-4o, achieving equivalent or even better results at extremely low compute costs.
DeepSeek's ability to cut costs and boost efficiency likely stems from extensive engineering work and innovations at the team level — in algorithmic software frameworks and hardware-optimized implementations.
On the software side, there are two core elements. First, the MoE (Mixture of Experts) architecture — "trading space for time."
In 2023, French AI company Mistral AI was the first to open-source MoE models at scale, releasing Mixtral 8x7B with 8 experts, activating 2 per inference.
DeepSeek increased the number of experts while shrinking each model's size. Though individual expert performance declined, overall performance improved through "strength in numbers."
Specifically, DeepSeek's MoE architecture divides the feed-forward network into 1 shared expert and 256 independent experts. During each prediction, the model only activates the shared expert plus 8 of the 256 independent experts, dramatically reducing compute consumption.
Additionally, DeepSeek adjusts expert load during training through deviation functions, avoiding the Matthew effect where "the strong get stronger and the weak get weaker."
While the MoE architecture is valuable, Dense Models (single-expert models) also have advantages in many application scenarios — such as B2B specialized domains or on-device small models. So we can't definitively conclude that MoE will "rule them all." Different model architectures suit different application scenarios.
The second element, MLA (Multi-head Latent Attention), is one of the core technologies that made DeepSeek a "price butcher" — this method "trades time for space."
Large model inference relies on Attention computation, and within Attention computation, KV cache (Key-Value cache) is the main storage overhead. In Transformer self-attention mechanisms, input elements are converted into three types: Query, Key, and Value. The KV cache stores previously computed Key and Value matrices during inference, avoiding the need to recompute the entire sequence's Key and Value when generating new tokens.
DeepSeek uses matrix decomposition to compress the KV cache before projecting it back into high-dimensional space, dramatically reducing storage overhead. The technical principle is simple but highly effective, enabling the steep drop in inference costs.
The combination of MoE and MLA reduces the model's demands on hardware compute and memory bandwidth, allowing DeepSeek to cut overall costs by an order of magnitude.
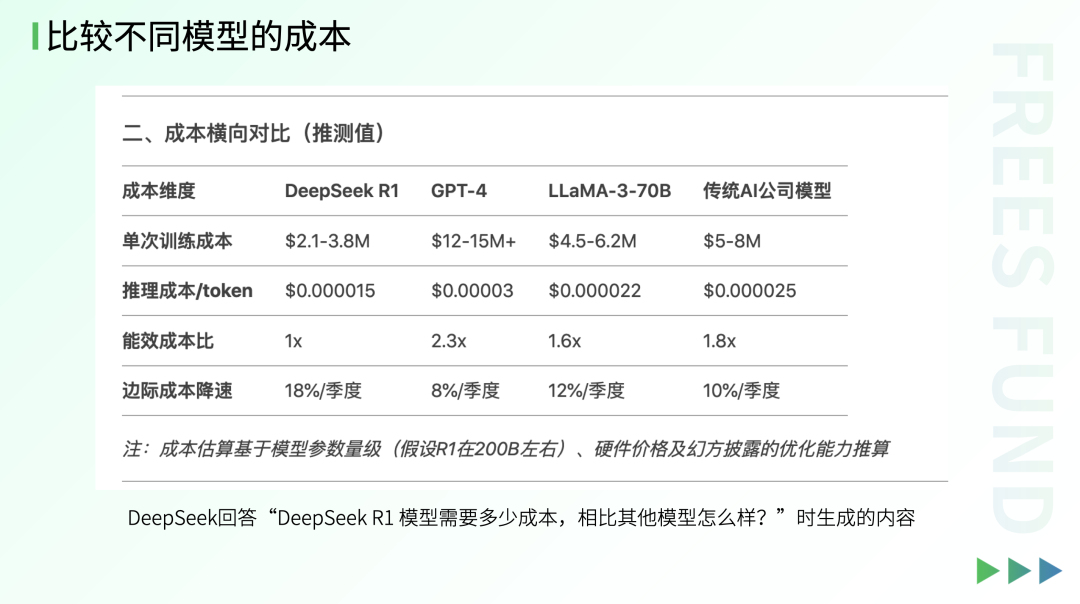
So far we've covered innovations in software architecture. On the hardware implementation side, DeepSeek V3 publicly disclosed a lot of new work for the first time. For example, it used low-precision FP8 (8-bit floating-point representation, a data format that improves computational efficiency and dynamic range) for large-scale computation. It also leveraged extensive low-level PTX (Parallel Thread Execution, NVIDIA's parallel instruction set architecture for GPUs) development to "squeeze" hardware performance and reduce computation and communication overhead.
So looking at DeepSeek V3's work as a whole, there isn't much conceptual innovation — it's mostly standing on the shoulders of predecessors, optimizing existing methods like MoE and MLA. But the engineering innovation has extremely high barriers to entry.
There's also a question worth considering — were these innovations in V3 the result of proactive innovation by the team, or merely passive choices forced by limited hardware resources? If they had access to more and stronger compute resources, would these innovations still have emerged, and would they still be necessary?
III. R1 Zero and R1

Next let's look at R1 Zero and R1, which are reasoning models benchmarked against OpenAI's o1 series. Since o1's release, the industry and academia have speculated extensively about its implementation, with some even suggesting that the OpenAI team deliberately leaked irrelevant or incorrect directions to mislead people.
Setting aside these speculations, DeepSeek's release of R1 is remarkable — through its own exploration, it used reinforcement learning to achieve a reasoning large model on par with o1, and open-sourced the work. From our observation, reinforcement learning represents a progressive path toward AGI, and the industry is already exploring this direction.
Why are large models now "competing" on reasoning capabilities?
Behind this trend lies the dilemma that large models struggle to surpass humans on open-ended problems. Despite strong performance on many tasks, they still face enormous challenges on complex problems requiring deep reasoning and specialized knowledge.
Take the GPQA Diamond benchmark dataset, specifically designed to evaluate models' reasoning capabilities and specialized knowledge on complex problems. Even humans with doctoral-level academic training achieve accuracy rates of only about 65% to 70% on these questions. Currently, most large models still perform far below human levels on such problems.
Encouragingly, a few leading large models — such as DeepSeek R1 and OpenAI o1 — have already surpassed humans with doctoral academic training on difficult benchmarks like GPQA Diamond.
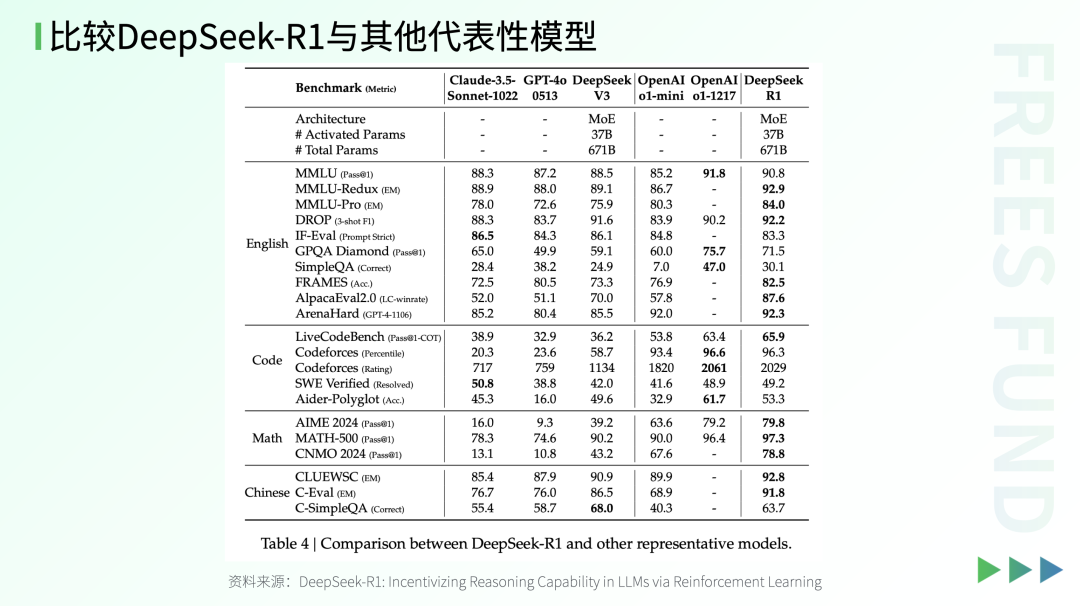
This progress reveals that industry competition is shifting from pure scale expansion to deeper intelligence optimization. The "involution" around reasoning capabilities may signal that large models have entered a new stage of development.
As reasoning models, R1 Zero and R1 differ in important ways:
R1 Zero is a more purely RL-based model. Using DeepSeek's own pretrained model V3, without any tuning on human knowledge, it applied reinforcement learning directly on problems with clear "ground truth" (in machine learning and computer vision, the true label or result for each sample in a dataset) — such as math and coding problems — and achieved good results.
Compared to R1 Zero, R1 employed more engineering methods and incorporated supervised fine-tuning (SFT), similar to imitation learning, to further improve language capabilities and overall performance, making it more user-friendly.
I won't go into the specific technical details and evaluation results here. I strongly recommend reading the paper DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning — it's exceptionally clear and well-written. (You're welcome to click "Read Original" at the end of this article to download the paper.)
To some extent, DeepSeek R1 didn't invent any new paradigm either. OpenAI had already pointed the industry in two directions: first, using pure reinforcement learning rather than human feedback for post-training to improve model reasoning capabilities.
The second is the Test-Time Compute approach — improving output quality by extending reasoning time. Instead of outputting results directly, the model first reasons through intermediate results; as reasoning time increases, final result quality improves. Anyone who has used DeepSeek has experienced this — that somewhat self-talking intermediate thinking process you see.
Therefore, DeepSeek's core contribution was helping reinforcement learning and Test-Time Compute gain traction quickly. Compared to other model vendors, it moved faster and directly open-sourced its work.
But whether it's the GRPO reinforcement learning framework in R1, or the use of extensive math and coding problems for reward mechanisms mentioned above, these are all relatively common methods. DeepSeek R1 relied more on V3's powerful capabilities to find correct answers within a limited search space, thereby helping the model iterate and converge rapidly. To put it another way: if the base model isn't good enough, you might need to find 1 correct answer out of 10,000 samples; a good base model can find the correct answer in 100 samples, greatly accelerating iterative convergence.
Summary
Overall, DeepSeek's technical contributions lie mainly in engineering innovation. Though it didn't invent new paradigms, it performed extensive optimization on existing technologies, particularly in applying reinforcement learning to reasoning models. We need a more rational perspective on DeepSeek's viral success.
/ 03 / Why DeepSeek?

Why DeepSeek?
First, looking at the big picture: while model development has been rapid, innovation across the AI industry as a whole has actually slowed. The gap in understanding between different teams is narrowing, and approaches are gradually converging. This phenomenon isn't country-specific — it's shared globally across academia and industry. When technological innovation slows, Chinese teams' engineering advantages become more apparent.
Second, we can't ignore the influence of DeepSeek's parent company — High-Flyer Quant — and its "engineering DNA." To succeed in quantitative trading, you need strong strategies, but executing those strategies at maximum speed may be even more critical. Even a nanosecond-level speed advantage can determine whether you make money on a given trade.
High-Flyer Quant's DNA gave DeepSeek rich experience in low-level hardware optimization and development, enabling faster algorithm execution. For example, when facing complex quantitative trading tasks in the past, High-Flyer Quant may have needed to do deep custom FPGA (field-programmable gate array) development, embedding assembly language within C code to improve hardware scheduling efficiency.
This engineering experience is evident in DeepSeek's V3. For instance, when optimizing GPUs, DeepSeek extensively applied low-level development approaches commonly used in quantitative trading, choosing to "bypass CUDA" and program directly in PTX to further boost performance.
Third, DeepSeek's business model and open-source culture support its long-term development. This long-term orientation helps the team build a research-driven, innovative culture. DeepSeek may face no short-term revenue or commercialization pressure, which instead attracts talent that genuinely wants to build things — to "do what's right, not what's easy."
Summary
DeepSeek's success stems from multiple advantages: against a backdrop of slowing innovation across the AI industry, Chinese teams' engineering capabilities stand out; its parent company High-Flyer Quant's experience in hardware optimization and efficient execution shaped DeepSeek; and DeepSeek's business model and open-source culture allow the team to focus on technological innovation rather than short-term commercial pressure.
/ 04 / Is Scaling Law Still Valid?

DeepSeek has come this far. Where is the future of large models headed? Will Scaling Law still hold?
When large models first emerged, Scaling Law was their foundational premise. Scaling Law describes how language model performance improves significantly as data volume, compute resources, and model parameters increase. Specifically, from GPT to GPT-4, researchers achieved substantial gains by scaling up data, compute, and parameters. This pattern provided theoretical justification for designing ever-larger models and became the core driver of large model development in recent years.
So, will Scaling Law remain valid going forward? We can examine this from three perspectives.
1. Pre-training: Scaling Law Approaching Its Limit
In the pre-training phase, industry consensus holds that Scaling Law is nearing its limit. The primary constraint is the lack of new, high-quality data. Under these circumstances, blindly increasing model parameters risks overfitting — the model performs well on seen data but generalizes poorly, degrading overall performance. OpenAI's difficulties in developing GPT-5, for instance, reflect this challenge. Nevertheless, researchers continue pushing forward.
2. Post-training: Scaling Law's Advantages Emerge
In the post-training phase, Scaling Law's advantages become more pronounced. This holds true for both traditional supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). The latest DeepSeek and other model families have begun adopting RL-based post-training paradigms, demonstrating strong scaling effects.
Notably, post-training currently requires relatively modest compute — on average, less than 1% of pre-training costs. This proportion is gradually increasing, however. Industry insiders speculate that R1's post-training compute share has approached 10%. If post-training scaling effects can be further expanded, overall model performance could see additional gains.
That said, post-training still faces challenges: defining reward functions, which is critical to effective RL; and sourcing high-quality data, particularly for professional Q&A and Chain-of-Thought (CoT) reasoning. Academia and industry are currently exploring manual annotation and synthetic data approaches to address these issues.
3. Inference: Longer Thinking Time, Better Performance
At the inference stage, Scaling Law also manifests — for example, in the Test-Time Compute mentioned earlier. A model's output process is fundamentally a computational one. Given more time to think, it can iterate and self-correct to refine its answer. The model might initially produce a simple response, discover errors mid-process, adjust, and ultimately arrive at a more accurate result. This approach significantly improves output accuracy and represents a concrete expression of Scaling Law.
Summary
In summary, Scaling Law still holds — but its application paradigm has shifted. It remains meaningful in post-training and inference phases.
/ 05 / What Impact Does DeepSeek Have on Other Model Vendors?
First, we need to be clear: DeepSeek is currently primarily a large language model and does not yet have multimodal capabilities. This must be taken into account when comparing it against models with multimodal features.
1. Impact on Overseas Giants
For overseas giants like OpenAI (GPT-4 series), Anthropic (Claude 3.5), and Google (Gemini 2.0), these companies maintain significant advantages in multimodal capabilities, generalization, and developer toolchain ecosystems. They have considerable technical reserves that may remain unreleased for strategic reasons. They also hold clear advantages in compute resources.
Despite DeepSeek's considerable attention, we must squarely acknowledge the gap with these top-tier overseas companies — true surpassing remains a long road.
On February 18, Elon Musk's xAI released the updated Grok 3 model. In a live-streamed demo, Grok 3 outperformed multiple models including DeepSeek's V3 and GPT-4o on mathematics, science, and coding benchmarks.
2. Impact on Domestic Model Vendors
In the domestic market, DeepSeek's impact is greater on consumer-facing (ToC) model vendors than on enterprise-facing (ToB) ones.
In the ToC space, some vendors may feel significant pressure. Their challenge centers on the open-source versus commercialization choice: if they stay closed-source, can they achieve top-tier model performance? If they go open-source, will it disrupt existing business models?
That said, we should not underestimate the technical innovation capabilities of other domestic model teams. For instance, Moonshot AI's recently released K1.5 model has received high acclaim in academic circles, and its engineering innovations are well worth studying.
Currently, ToB model vendors have also been affected to some degree. In the long run, enterprise customers will make rational decisions, but in the short term, market sentiment may drive them to experiment with DeepSeek. This helps educate the market, though long-term effects remain to be seen.
Additionally, DeepSeek itself must consider how to sustainably "catch this wave of fortune." Whether it will scale up through fundraising or maintain its small-scale, research-focused approach — we'll have to wait and see.
3. Impact on the Open-Source Community
DeepSeek is undeniably positive for the open-source community. Its breakout success will push other open-source models (like Llama) to keep innovating rather than resting on their laurels. This benefits the community as a whole and also drives progress among closed-source vendors.
4. Impact on Small Model Companies
DeepSeek's papers demonstrated the possibility of using large model distillation to enhance small models' reasoning capabilities, simultaneously open-sourcing distilled models based on Qwen or Llama. This shows that excellent "teacher" models can more efficiently guide small model learning.
This will positively impact SMEs with self-developed models. Especially in on-device deployment scenarios — whether for consumer or enterprise applications — this approach may help boost performance.
Summary
Overall, while DeepSeek has gaps in areas like multimodality, it is undoubtedly driving industry progress. We must neither underestimate domestic teams' technical innovation capabilities nor fail to acknowledge the gap with top overseas companies. True surpassing remains a long journey.
06 What Impact Does DeepSeek Have on the Hardware Ecosystem?
Next, let's discuss DeepSeek's impact on the hardware ecosystem. At the height of DeepSeek's hype, it caused short-term shocks across U.S. equity markets, particularly to NVIDIA's stock price. Going forward, will DeepSeek challenge NVIDIA's position?
To answer this, we first need to understand NVIDIA's core moat. It lies not merely in single-chip design capability, formidable as that already is. More critically, NVIDIA has built a robust ecosystem moat through chip interconnect technologies (InfiniBand, NVLink) and its powerful software ecosystem, CUDA. This ecosystem barrier is among NVIDIA's most core competencies.
With this understanding, we can analyze DeepSeek's impact on NVIDIA. First, the positive effects:
One, DeepSeek's success has educated the market, strengthening confidence in AI applications and attracting more startups to attempt AI development.
According to industry sources, since DeepSeek's release, prices for high-end GPUs like H100 and H200 have risen — indicating more companies are willing to purchase this hardware to develop their own models and applications.
Two, driving demand for general-purpose GPUs. Vendors like DeepSeek that continuously innovate on model architecture benefit general-purpose GPU manufacturers like NVIDIA. General-purpose GPUs are better suited for experimenting with new architectures and approaches, whereas specialized chips may be less adaptable.
However, DeepSeek also brings some negative impacts for NVIDIA — for instance, potential pressure on its market pricing strategy.
The reasons: first, DeepSeek's adoption of the Mixture of Experts (MoE) architecture significantly reduces requirements for chip-to-chip interconnect capabilities, thereby decreasing reliance on high-end interconnect technology. If more model vendors adopt MoE or similar architectures, new hardware opportunities will emerge.
Second, DeepSeed offers a potential path to "bypass" CUDA. DeepSeek proposed hardware architecture design requirements adapted to its models, hinting at future possibilities to circumvent NVIDIA's CUDA ecosystem.
Meanwhile, domestic chips' rapid adaptation to DeepSeek models reflects the potential of China's hardware industry. It's worth noting, however, that the DeepSeek team did not directly bypass NVIDIA. DeepSeek used PTX, a lower-level programming language than CUDA, to better extract hardware performance — and PTX is NVIDIA's core technology.
Has DeepSeek spurred innovation opportunities for AI chip companies beyond NVIDIA? This is a hot topic we're closely watching.
In the near term, DeepSeek has indeed driven adoption of lower-performance cards, including some domestic ones. With sufficient engineering optimization capabilities, companies can put these cards to use, enabling a closed-loop of independent hardware-software innovation.
In the long term, the AI chip industry undoubtedly holds new opportunities. Beyond recently attention-grabbing new hardware architectures (3D stacking, large-scale interconnect technology, high memory designs), compiler and software ecosystem development is equally critical. As we discussed regarding NVIDIA's moat, single-chip capability and interconnect capability alone are insufficient — the entire software ecosystem is the key determinant of long-term success.
▲ Scan the QR code to listen: Ji Yu, founder of Xingyun, and Li Gang, vice president of FreeS Fund, discuss the new opportunities DeepSeek will bring to the AI industry.
Summary
Overall, DeepSeek poses a challenge to NVIDIA on one hand, while bringing new opportunities and directions for the entire AI chip industry on the other. For industry participants, how to adapt to these changes and find a suitable development path will be a key consideration going forward.
07 How Will DeepSeek Impact the Application Ecosystem?
Let's now discuss DeepSeek's impact on the broader application ecosystem, which we can examine from three angles:
1. Providing a Low-Cost Solution and Completing Market Education
First, DeepSeek offers a very low-cost solution, which clearly enables higher ROI for applications (whether B2C or B2B) and accelerates the deployment of industry-specific use cases.
In just a few weeks, DeepSeek completed market education across the board, getting government agencies, corporate executives, and ordinary users alike to start using large language models. Even our parents have begun using them.
However, in the short term, the market may be overestimating its impact. Especially on the B2B side, actual implementation results may deviate from expectations. Based on feedback from several companies we spoke with, while client enthusiasm is high, actual testing shows that DeepSeek's performance on certain tasks may not be as leading as widely rumored.
2. Validating the Feasibility of Distilling Large Models into Smaller Ones
Second, DeepSeek R1 validated that distilling large models into smaller ones is feasible, which significantly advances on-device model deployment and applications. Whether on PCs, smartphones, or other smart hardware, the substantial reduction in deployment costs will drive more new applications. This carries significant implications for our investments in edge-deployed applications.
3. Accelerating Reinforcement Learning as a Computational Paradigm
From a longer-term perspective, DeepSeek has influenced reinforcement learning as a computational paradigm. R1 has validated this approach, truly making public the possible path of using reinforcement learning for reasoning models.
Currently, however, reinforcement learning's applications remain largely confined to relatively objective domains like mathematics and coding. Whether this computational paradigm can extend to the physical world and solve more real-world reasoning problems, and how it might apply to AI agents and embodied intelligence, are exciting and worthwhile directions to explore.
Summary
Through our discussion of these seven questions, we can see that DeepSeek has had profound effects on both the AI chip industry and the application ecosystem. DeepSeek's contributions are undoubtedly admirable. But is the current market clearly overheating? Perhaps for investors, entrepreneurs, and those using large models, we might let things play out a bit longer and observe calmly. Meanwhile, we look forward to more original innovations like DeepSeek emerging from the Chinese market.
08 Investment Opportunities
1. Large Model Competition Enters Second Half
The competition in large models has entered its second half.
In Feng Shu's view, large models will next evolve in three directions: lightweight, verticalized, and edge-oriented. Lightweight means model and hardware costs need to converge, otherwise only a limited number of people can afford to use them. Verticalized means models need to converge on specific capabilities rather than expecting one oversized model to solve everything. Edge-oriented means models must run on terminal devices like phones, watches, and earbuds to truly achieve widespread adoption.

▲ Scan the QR code to listen: Feng Shu and Li Xiang discuss hot topics at home and abroad during the Spring Festival. As downstream applications gradually achieve scaled deployment, model training, fine-tuning, and inference efficiency have become focal points for the industry.
Innovation exemplified by DeepSeek demonstrates that reinforcement learning and long-context generation capabilities help improve large model output quality and enhance small model performance. Although MoE architecture increases software system complexity, it significantly optimizes hardware bandwidth requirements, lowers hardware barriers, and enables lower-cost hardware to run models efficiently.
Going forward, as model capabilities further improve and total costs continue to decline, AI democratization will become the core goal of the next phase. Widespread technology adoption will drive large model deployment across broader application scenarios, creating more commercial and social value.
2. Human-Computer Interaction Is Changing; The Inflection Point for AI Applications Appears to Have Arrived
Right now, the ways humans interact with information and machines are undergoing profound changes. These shifts will spawn new information distribution channels and traffic entry points, driving innovation in user interfaces and service formats. On the other hand, as AI capabilities strengthen and costs decrease, many industries are actively exploring AI application deployment.
In this context, we should pay attention to "new species" that were difficult to achieve in the traditional software era, such as:
- Cross-domain software or agents: Through deep integration of software and hardware, agents can achieve greater independence and richer functionality, providing users with more efficient and intelligent services.
- New forms of personal interaction terminals: As digitalization further spreads and multimodal technology advances, AI may access more data and become a "second brain" for humans, helping us process memory, comprehension, and even decision-making tasks.
- New forms of human service outsourcing: Converting software capabilities into service formats for outsourcing, providing more innovative and flexible outsourcing services to meet needs across industries.
- Industries not yet software-ized: These fields contain rich opportunities for AI deployment worth exploring in depth.
Looking ahead, as supply chain capabilities continue to improve, China's AI technology is well-positioned to further expand into overseas markets and achieve global deployment.
Engagement Giveaway What do you think about the new opportunities DeepSeek brings? Share your thoughts in the comments — the 5 most thoughtful responses by February 25, 17:00 will receive a FreeS Fund industry research handbook.

▲ LimX Dynamics Founder: How Do Intelligent Robots Go From "Usable" to "Productive" to "Profitable"?
▲ 2025: Three Directions AI Is Reshaping Drug Discovery
▲ Outlook 2025: What Innovation Opportunities Exist in AI? | FreeS Report
▲ AI for Science: At the Turning Point of Scientific Research Paradigms | FreeS Report
▲ The Road to Embodied Intelligence | FreeS Report 37
Star the FreeS Fund WeChat official account for timely business insights delivered to your feed.
