FreeS Report 23: Crossing the "Valley of Death": Systemic New Opportunities in Small-Molecule Drug R&D

Across every stage of preclinical drug R&D, new infrastructure, methods, and tools are emerging in China — making rapid, low-cost experimentation possible.

Since 2020, the "me too" reality in biopharma has triggered industry-wide reflection and debate. Not long ago, a feature titled The Story of Chinese Innovative Drugs traced the dramatic ups and downs of the past 18 years. On one side, Professor Fu Xinyuan's 2018 million-dollar challenge — offering a reward for any drug meeting five criteria for true innovation — still echoes in our ears. On the other, Dr. Liang Guibai's soul-searching essay Should We Even Do Me-Too?
The commercial translation of knowledge in any field must cross the "valley of death," and this is especially true for new drug R&D. When the dividends of copycat innovation dry up, China's biopharma industry will have to confront this valley collectively.
In this report, we analyze the historical opportunity in preclinical small-molecule drug discovery from multiple perspectives, and specifically within the Chinese context: why the present moment is ripe for innovative drug R&D, and what kinds of companies can seize this opportunity.
Before diving in, here are our key points:
- Crossing the "valley of death" is the central challenge of original new drug R&D.
- The core of crossing it lies in low-cost, rapid trial-and-error.
- New tools, algorithms, and technologies are empowering every DMTA (Design-Make-Test-Analyse) cycle across the R&D pipeline.
- China's new drug R&D sector is now facing a systemic new opportunity.
- Whether building products or services, good companies must have the capacity for continuous iteration in core technology.



Crossing the "Valley of Death": Systemic New Opportunities in Small-Molecule Drug Discovery
By Yikai Wang
Email / wang_yikai@keenthera.com
01
The Historical Origins of the "Valley of Death" Metaphor
"Even though I walk through the valley of the shadow of death, I will fear no evil, for you are with me; your rod and your staff, they comfort me."
This verse from Psalm 23 offers a metaphor for the human experience: though darkness and death are valleys we must traverse, we pass through them in safety because of divine love and protection. Rich in meaning, the phrase "valley of death" has appeared across countless works of literature and art.
In 1991, a report by Mohawk Research Corporation for Argonne National Laboratory, under the U.S. Department of Energy, first applied this concept to the innovation process, using it to describe the funding gap between product prototyping and commercialization. In 1998, a House Science Committee report titled Unlocking Our Future: Toward a New National Science Policy used the "valley of death" to illustrate the funding shortfall between basic research and product development, noting that this gap was widening due to limited government spending and industry's short-term profit-seeking.
Initially, the "valley of death" was seen as a corporate problem. But in biopharma, given the sector's massive capital requirements, long timelines, and high failure rates, there has long been debate about how public institutions can help fill this funding gap. In 2008, Nature senior correspondent Declan Butler published an article titled Bridging the Valley of Death, arguing that a chasm had opened between biomedical researchers and patients. He called on the U.S. National Institutes of Health (NIH) to adjust its philosophy, policy orientation, and funding support — even to transform itself — to support translational research that could move from lab to clinic and ultimately benefit patients.

Specifically, translational research — the "valley of death" in drug R&D — is typically defined as the stage from target validation to human proof-of-concept (Phase IIa clinical trials).
One major government-led attempt to cross this valley came in 2003, though the metaphor itself wasn't invoked at the time. Shortly after Dr. Elias A. Zerhouni became NIH director, he convened over 300 biomedical leaders from academic institutions, government agencies, and private organizations for more than a year of discussions on translational medical research. On October 1, 2003, he unveiled a "medium- to long-term development plan" for the future of life sciences — the NIH Roadmap. Over five years, with billions of dollars in planned investment, it aimed to accelerate the translation of basic medical research into clinical applications by focusing on new pathways for original innovation, research teams of the future, and rebuilding the clinical research system.
Even as public institutions increased support for translational research to cross the "valley of death," pharmaceutical companies were conducting their own extensive explorations. In 1998, GlaxoWellcome (predecessor to GSK) launched an acceleration program intended to compress the entire process from medicinal chemistry to drug launch into seven years. The lead optimization phase was targeted at just 12 months. Such optimism was possible because the field was then riding the wave of combinatorial chemistry and solid-phase chemistry — the belief was that applying these new technologies would usher in a new era of efficiency in preclinical drug R&D.
At the end of 2001, GlaxoWellcome's researchers publicly shared the challenges they had encountered, hoping to generate industry-wide attention, empathy, and discussion. As a bold experiment, the thinking behind it was highly representative regardless of whether a replicable new model emerged. Even two decades later, crossing the "valley of death" remains a central problem we must face and solve.
02
What Is the Core of Crossing the "Valley of Death"?
Drug discovery is an experimental science. Finding one molecule that can treat a human disease from among millions is like searching for a needle in a haystack. Beyond increased government investment in translational research, what new opportunities exist to change this situation? What is truly at the core of crossing the "valley of death"? Does China have any advantages in developing new drugs?
Let's revisit the problems GlaxoWellcome identified in its 2001 acceleration experiment. They can be summarized in four areas: first, cycle time (including shorter timelines, parallel testing, and earlier consideration of drug-like properties); second, organic synthesis (including synthesizability, resource allocation, and compound management); third, data (processing and interpretation of large datasets); and fourth, human factors (including stress management, incentive mechanisms, and personnel management). Apart from human factors, the first three areas all involve what we call the Design-Make-Test-Analyse cycle.
Beginning in 2007, pharmaceutical companies led by AstraZeneca and BMS began applying Lean Six Sigma concepts to preclinical drug R&D. In 2008, professors Ullman and Boutellier at ETH Zurich proposed using feedback loops of design, synthesis, testing, and interpretation of results to optimize structure-activity relationships — an early form of what would become DMTA. In 2009, AstraZeneca became the first to break lead optimization into a cycle of four steps: design (D), make (M), test (T), and analyse (A).
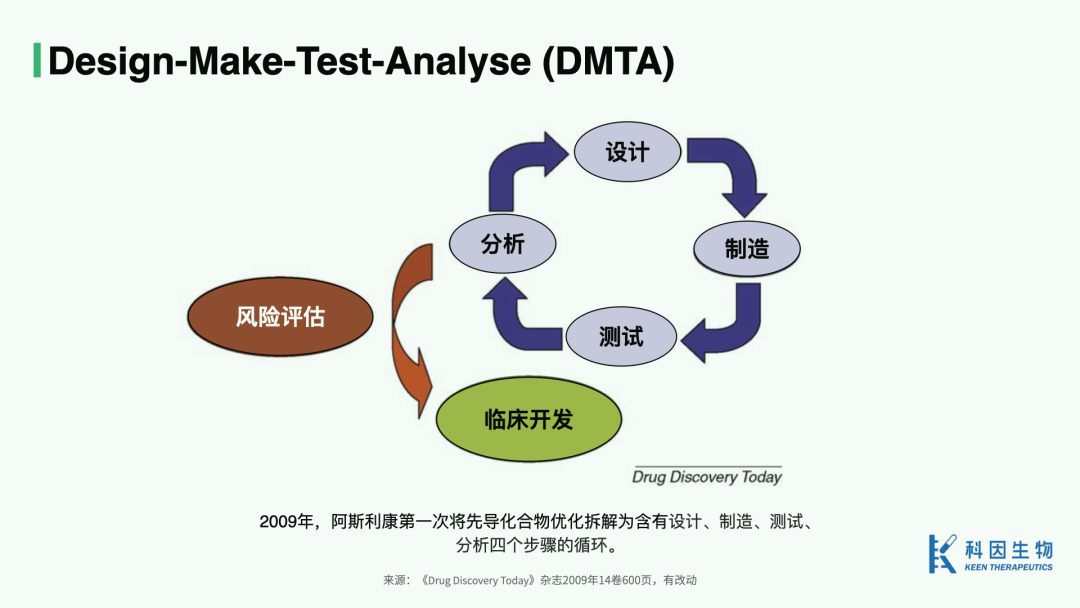
AstraZeneca started by optimizing the "make" step (involving compound synthesis, purification, and analytical characterization) — better synthetic planning, progress tracking, dramatically shortened purification times, and so on. These improvements cut average delivery time (from target molecule identification to delivery for bioactivity testing) from 23 days to 13 days.
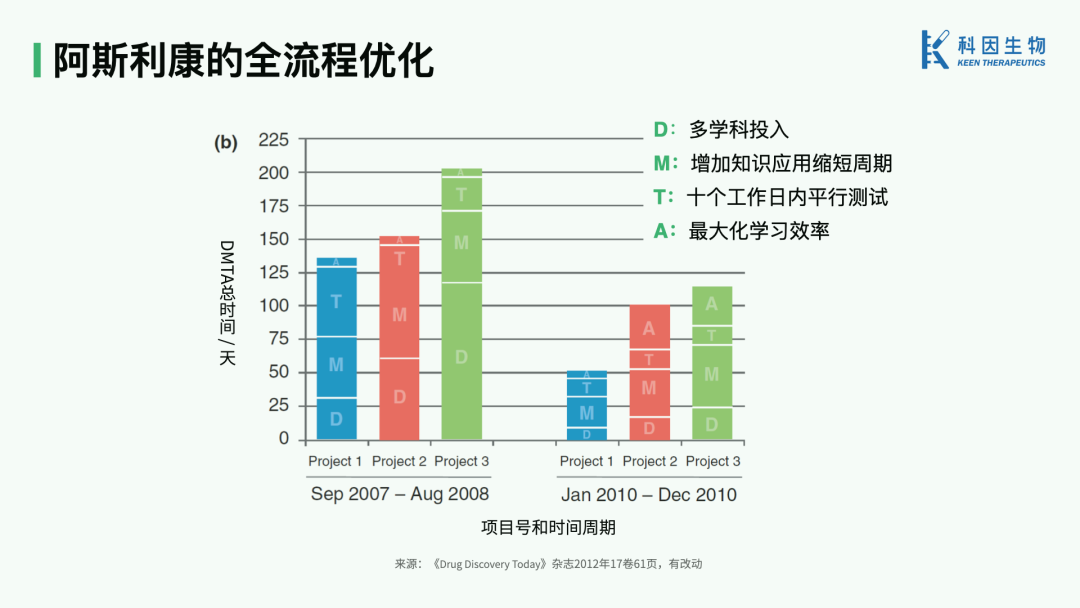
In 2012, building on the "make" improvements, AstraZeneca shared optimizations for the other three steps and the results of full-process optimization. In summary, the key improvements were: increased multidisciplinary investment in "design," greater application of knowledge in "make" to shorten cycle times, parallel delivery of relevant data within ten working days in "test," and maximized learning efficiency in "analyse." After several years of practice and iteration, average DMTA cycle time was reduced by 46%, and average cost per candidate compound entering safety assessment was cut by more than half.
If we subdivide the "valley of death" in drug R&D, it comprises two stages: preclinical development and early clinical research. Preclinical research includes three main components: target identification and validation, hit compound design and discovery, and optimization of drug-like properties — the latter two of which depend on organic synthesis. As shown in the figure below, besides the lead optimization (drug-like property optimization) at AstraZeneca mentioned earlier, which is a DMTA process, the other two components and organic synthesis itself all fit the DMTA cycle framework. Of course, the latter two components require organic synthesis as their foundation.
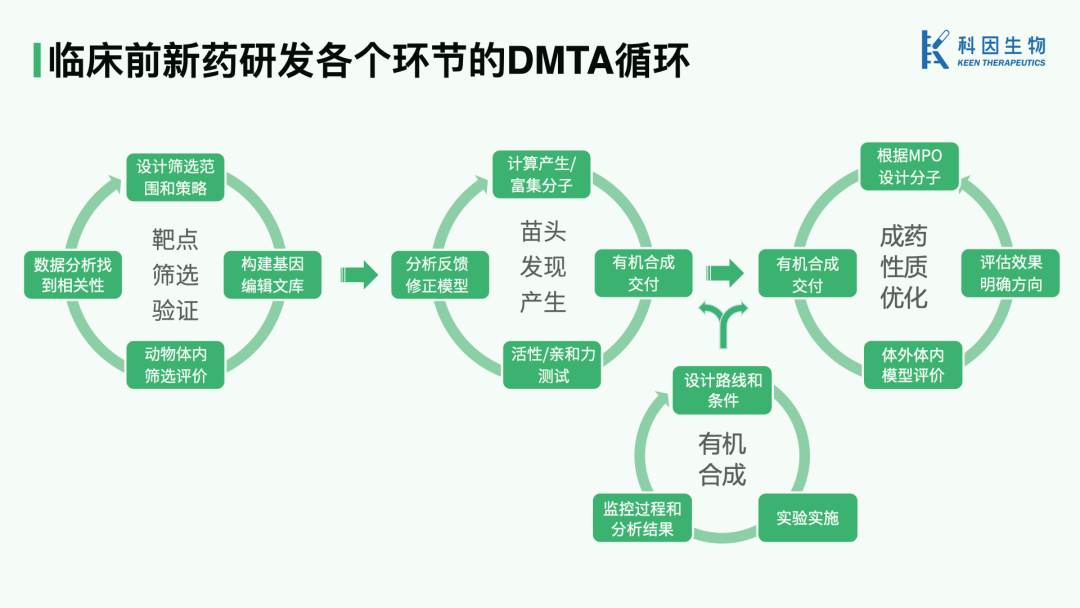
In fact, it's not just preclinical work — early clinical studies are essentially testing in humans, and this trial-and-error process isn't fundamentally different from preclinical stages. The only difference is that by this point, with only one or two backup molecules in hand, the possibility of starting another full cycle from scratch is pretty much gone.
So here we focus mainly on how to discover preclinical candidate compounds in greater quantity, faster, better, and more cheaply — on one hand, pushing optimization to the limit to improve the probability of molecular success; on the other, exhaustively exploring to provide more molecules worth trying.
Precisely because the probability of finding an ideal drug molecule is low, the semiconductor industry's "fail fast" philosophy applies at every stage of drug R&D. With adequate funding, the core of crossing the "Valley of Death" is low-cost, rapid trial and error — a challenge the entire industry needs to tackle together over the long term.
03
Interdependent Cycles in Preclinical Drug R&D and Opportunities for Efficiency Gains
In recent years, new tools and platforms, maturation of underlying technologies from invention to practical application, big data accumulation, and algorithmic breakthroughs have all impacted the efficiency gains and cost reductions of each cycle to varying degrees. Let's analyze and discuss them one by one.
Target Identification and Validation
In AstraZeneca's 5R framework (Right target, Right tissue, Right safety, Right patient, and Right commercial potential), the first R is the right target — above all, strong relevance between the target and the disease. Traditionally, discovering and validating this relevance required bioinformatic analysis, in vitro screening and evaluation, and then in vivo animal experiments. This process was not only long and inefficient; because cell culture conditions and microenvironments differ drastically from the body, in vitro results often failed to reproduce in vivo.
As gene editing technology has continuously upgraded and scaled, in vivo target screening to discover and validate disease associations has become feasible. It's not only low-cost, high-throughput, and fast — in vivo screening also more closely approximates real conditions, yielding more credible relevance. Beyond single-target validation, gene editing technology can also accelerate and empower applications in synthetic lethality, drug repurposing, resistance prediction, biomarker discovery, and other related scenarios.
On another front, as microfluidics, sensing, imaging, and other cross-disciplinary technologies have been applied to measurement instruments, rapid progress in single-cell sequencing, high-resolution imaging, and proteomics has enabled higher precision, greater dimensionality, and larger throughput of information acquisition — providing massive data for mining and studying target-disease associations.
Hit Compound Design and Discovery
After selecting a target, the next step is hit molecule discovery. There are two main approaches. One is direct experimental screening, from HTS (high-throughput screening) to the recently very hot DEL (DNA-encoded compound library). The other is computational generation or enrichment first, followed by experimental validation.
In the first path, DEL's rapid development owes mainly to intelligent upgrades in its design, synthesis, quality control, and screening — making high-quality correlation analysis from massive data possible. For the second path, AI-driven drug discovery has become an industry focal point.
Computation-based hit compound discovery has attracted unprecedented attention for three main reasons:
First, cryo-EM and rapid single-crystal diffraction, as new infrastructure, have improved the efficiency of obtaining protein structural information. The emergence of algorithms like AlphaFold2 and RoseTTAFold has enhanced protein structure prediction and simulation capabilities. This is the computational starting point for hit compound generation and design. Just recently on July 22, AlphaFold released predictions for 98.5% of human protein structures and will make all predictions freely available to society through a public database (https://alphafold.ebi.ac.uk/). This will undoubtedly greatly accelerate basic research on various proteins and drug development. We look forward to new breakthroughs in AI prediction of protein complexes and co-crystal structures.
Second, the普及 of cloud computing has made computational evaluation of ultra-large compound libraries possible. Whether for small-molecule crystal forms and conformations or protein-ligand interactions, the so-called "first-principles" approach based on theoretical physics relies mainly on computing power — the core challenge being how to calculate faster and more accurately. If molecular generation and evaluation can be transformed into an exhaustive deep-search problem, approaching global optima through as many local optima as possible, the efficiency and quality of virtual hit discovery can be improved. Such exploration is receiving increasing attention in academia and industry.
Third, innovation in deep learning algorithms has spilled over into molecular design, showing the potential for data-driven efficiency gains. The most attempted direction is borrowing deep learning algorithms from image processing, natural language, and graph neural networks to describe molecules themselves or molecular-protein interactions, thereby generating new molecules or predicting molecular properties.
The biggest challenge for data-driven approaches is overcoming limitations in data volume, quality, structuralization, and balance. Whether the currently known number of small molecules and small-molecule-protein interaction (co-crystal) information can meet deep learning model training requirements remains an open question.
Whether in hit discovery or subsequent optimization, verifying molecular-protein interactions in wet experiments completes a DMTA cycle. The feedback cycle and efficiency of this process are crucial for computation and deep learning. We've noticed that many CRO (contract research organization) companies are building and expanding molecular interaction experimental platforms precisely to serve rapidly growing R&D demand.
Organic Synthesis
Obtaining target molecules through organic synthesis is the most time-consuming, labor-intensive, and expensive step. It was 20 years ago, and it still is today. In 2020, AstraZeneca scientists published an article comparing the automation progress of biological testing versus organic synthesis, noting that organic synthesis remains a highly manual process to this day.

In fact, that same year, Andrew I. Cooper's group at the University of Liverpool used an automated synthesis robot to perform 688 consecutive reactions over 8 days, optimizing a photocatalytic hydrogen evolution system. Though merely a laboratory experiment, it signaled that organic synthesis was on the verge of entering the automation era.

In a previous report, we systematically mapped out directions and opportunities for upgrading the pharmaceutical and chemical industry (click the blue link to review the report Investment Opportunities in Pharmaceutical and Chemical Industry Upgrading | FreeS Research). In this piece, we further analyze how automation, digitization, and intelligence are improving organic synthesis efficiency.
Organic chemists' skill levels depend heavily on experience. What is experience? It's data from reactions they've done (or seen) and their ability to search and evaluate literature data. Generally, synthesis team leaders who have managed groups are more experienced and better at problem-solving — fundamentally because data and information generated by every team member flows to the leader. Over time, they naturally see more and know more, allowing them to give the team more effective advice and guidance, and team efficiency keeps improving. This is a self-reinforcing DMTA cycle: more data improves D efficiency, the cycle speeds up, generating even more data, and so on.
In 2018, Professor Waller's group published a paper in Nature explaining how deep learning algorithms could analyze (A) chemical reaction historical data to solve new compound synthesis route design (D) problems — a direction that began attracting widespread attention and thorough exploration. In specific application scenarios such as exhaustive enumeration and ranking of synthesis routes, process route and condition search recommendations, and synthesizability analysis of large compound sets, machine learning algorithms have achieved varying degrees of progress and breakthrough. In the efficiency improvement process, algorithms and computing power matter, but data quantity and quality are the core. Currently used literature and patent data, while substantial in volume, have quality that is difficult to guarantee — the biggest bottleneck for deep learning algorithms. In this sense, domestic organic synthesis CROs, with large volumes of reliable internal experimental data, are best positioned to gain first-mover advantage in improving design capabilities through algorithms.
Another industry hotspot is organic synthesis automation — using robotic arms, microfluidics, robots, and other forms to perform organic reactions. Machines replace humans in data collection, ensuring precision and rigor without errors, and machines don't need rest — guaranteeing both data reliability and production efficiency. Additionally, declining willingness among young people to engage in organic synthesis provides both rationale and impetus for automation replacing humans.
In organic reaction data generation, high-throughput chemical catalysis and enzymatic catalysis are playing increasingly important roles. Of course, these two catalytic methods are currently more adopted in CDMO (contract development and manufacturing organization) production processes as new cost-reduction enabling tools; their value in new molecule synthesis and construction hasn't been universally recognized. Chemical catalysis enables low-cost rapid exploration of reaction conditions, greatly helping route development and key step implementation, while also addressing data accumulation for data-scarce reactions. Enzymatic catalysis, through bond-forming methods and synthetic strategies different from chemical reactions, can very efficiently solve control and modification problems that organic synthesis struggles with. Integrating both approaches for synergistic effects, supplemented by automation equipment and synthetic biology's efficiency gains in enzyme engineering, organic synthesis efficiency will welcome another major leap.
One can make this bold conjecture: if the cost of generating new molecules through organic synthesis could be reduced to infinitely close to raw material costs, if a molecule requiring 20 steps could be delivered in 3 weeks, then the chemical space we could explore would greatly expand — enabling thorough investigation of newer, more challenging targets, increasing the probability of finding better molecules, at lower cost, with faster trial and error.
Optimization of Drug-Like Properties
Finally, let's look at optimization of drug-like properties. Traditional evaluation methods — whether in vitro experiments or animal studies — are designed to more fully characterize the various properties of compounds, reducing the risk of failure in clinical trials. Large pharmaceutical companies sit on extensive historical data that is constantly being analyzed and reused. With deep learning algorithms now ubiquitous, rebuilding models for data mining and prediction is no longer technically demanding. If major companies could share data to train models and open-source them for industry-wide use, it would dramatically improve the efficiency of drug-like property optimization while cutting trial-and-error costs.
Upgrading and replacing traditional drug-like property evaluation methods has long been a focus of industry R&D. For instance, physics-based calculations for predicting compound crystal forms and solubility have already achieved accuracy very close to experimental results. Although physics-based computations and data-driven algorithmic models can preliminarily predict certain drug-like properties of molecules, making the D more precise, limitations in computing power, data availability, and the complexity of living organisms mean that synthesizing molecules and validating them experimentally remains indispensable. Building more relevant animal models using gene-editing technology can better approximate human physiology than previous models; the recently hot organ-on-a-chip technology can replace some animal experiments for low-cost screening and evaluation. These advances will make the DMTA cycle for drug-like property optimization faster and more effective.
Across every stage of preclinical drug R&D, new infrastructure and novel methods and tools are emerging. The efficiency gains from computing power, algorithms, and data accumulation are particularly pronounced in hit identification and organic synthesis — areas with potentially disruptive impact. These will directly reshape the cost structure of trial and error, shorten validation cycles, and to some extent transform traditional preclinical R&D models, providing "staff and rod" for crossing the "Valley of Death."
Why China, Why Now?
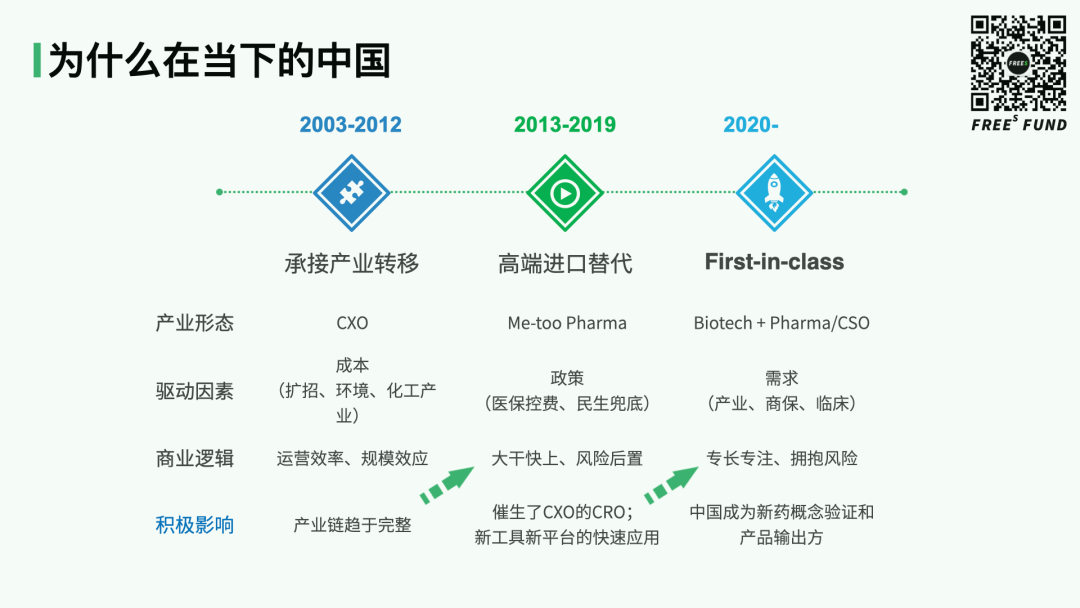
The development of China's biopharma industry over the past two decades can be roughly divided into three phases. The first phase, from 2003 to 2012, was primarily about undertaking industrial transfer. The second phase, from 2013 to 2019, focused on high-end import substitution. Starting from 2020, the industry entered the most challenging stage: original innovation in novel drug R&D.
In the early days of the 2020 pandemic, we analyzed trends in domestic innovative drug development (click the blue link to revisit our report Hammer and Dance: Investment Opportunities in Healthcare's Next Wave Amid the Pandemic | FreeS Research). We proposed a shift from copycat innovation to original and systematic innovation. In retrospect, this transition arrived even faster than anticipated.
Several factors enabled this. First, Phase One — built on university enrollment expansion to ensure talent supply and structured around CRO/CMO as the industrial form — left the industry with a more complete industrial chain, increasingly experienced R&D personnel, and improved efficiency.
Then came Phase Two, driven by policy imperatives to address new drug supply and healthcare cost control, with biopharma as the industrial form. A surge of innovative drug projects launched simultaneously in a short period, dramatically increasing demand for R&D and manufacturing outsourcing. This not only spawned more efficient CRO companies serving other CROs/CDMOs, but also facilitated widespread adoption across the industry of all the new technologies, cross-disciplinary tools, and algorithms mentioned earlier.
With investment running hot, demand massively unleashed, and industrial upgrade pressure all coexisting, these new efficiency tools received such abundant capital investment and rapid iterative development — something unprecedented even in the relatively mature US and European markets.
Starting in 2020, China's innovative drug market ended its period of rapid growth from zero and entered a stock market. Business models relying on aggressive scale-up and marketing prowess have begun to "involute" — product quality and whether a drug truly addresses unmet clinical needs are becoming core competitive advantages.
On the foundation of an ever-improving industrial chain and continuous commercialization of new tools and technologies, the systemic new opportunity for small-molecule novel drug R&D lies in whether companies can achieve better or newer products through low-cost, rapid trial and error.
What Kinds of Companies Can Seize This Opportunity?
In recent years, with investment and markets running so hot, many CRO companies and novel technology companies have hoped to expand their scope to develop new drugs themselves — the end product. Such attempts are understandable, but may not represent the best business logic. Product development carries product risks; services follow service logic. Whatever the path, companies need the ability to continuously iterate on core technology — that is, the capability to complete DMTA cycles efficiently and at low cost. Companies that can accumulate data and refine technology through these cycles, thereby raising barriers, will become the standouts.
Of course, new drug R&D involves long processes, extensive chains, and high risks. The emergence of great companies especially depends on a more open, collaborative industrial ecosystem where players focus on their specialties. In the coming years, we believe the pharmaceutical industry will see not only product-centric "Huaweis" and "BYDs," but also new infrastructure players like "CATL" and more efficient service outsourcing companies like "Luxshare Precision Industry Co., Ltd."
Discussion In this piece, the author shares research on new molecular entities and innovative drugs. We'd also welcome your observations and thoughts: How do you view China's novel drug R&D industry, and what opportunities do you see? Contact Us Entrepreneurs and industry experts are welcome to continue the conversation with the author, Yikai Wang (wang_yikai@keenthera.com). Thank you for reading. If you have questions for the author or are interested in our future brand events, please take 1–2 minutes to fill out this form. We look forward to engaging with you.

FreeS Family Funding News · July | PatPat, Yanming Biotech, Qbit, and Xisu Technology Secure Funding Hammer and Dance: Investment Opportunities in Healthcare's Next Wave Amid the Pandemic | FreeS Research Investment Opportunities in the Pharmaceutical and Chemical Industry Upgrade | FreeS Research Why Is AI Drug Discovery So Hot, and Why Now? | Transcript from FreeS Biomedical and Pharmaceutical Investment Summit Feng Li: One Chart to Understand Biotech Innovation Opportunities | Complete Guide to FreeS 2020 Biomedical Summit Early-Stage Medical Aesthetics Investment Turns to Underlying Technology | FreeS Research
