A Debate: Two Investors With Different Perspectives on GPT | FreeS Research Institute

AlphaFold 2 vs. ChatGPT: Which Will Drive Greater Change?
This is the third installment in FreeS Fund's AIGC series. We've previously covered the evolution of AIGC and held in-depth conversations with entrepreneurs in vertical sectors. But recently, AIGC has undergone yet another seismic shift.
OpenAI released its large-scale language model GPT-4, adding multimodal capabilities that support both text and image output. On the flip side of this technological frenzy, OpenAI has faced scrutiny over personal data privacy, content accuracy, and minor protection. At the end of March, Italy announced a ban on ChatGPT. Germany, France, Ireland, and others also considered temporary ChatGPT bans. On April 11, China's Cyberspace Administration released the Administrative Measures for Generative Artificial Intelligence Services (Draft for Comment).
The impact of AI has also spread to biology laboratories, where scientists have begun using AI to build protein models — analyzing and predicting data based on text, proteins, sequencing, and more — to accelerate their research. Generative AI has brought new perspectives to biomedical research, giving rise to the concept of "generative biology."
We invited two investors from different fields to share their perspectives on AIGC. One is Rui Ma, partner at FreeS Fund, who focuses on materials and biotech, with investments concentrated in computationally driven approaches, synthetic biology, frontier technologies, and novel therapeutics. The other is Chen Shi, investment partner at FreeS Fund, who specializes in technology, software, internet, and consumer sectors.


Swipe left or right to see more
The conversation featured plenty of clashing viewpoints: What sparks will fly from the collision of GPT and biotech? Which will drive bigger changes in biology — AlphaFold 2 or ChatGPT? Amid these massive shifts, which areas — AI for science, generative biology, AI drug discovery — hold more opportunity?
We've edited their discussion into this article. You're also welcome to check out the full audio version on the Xiaoyuzhou app or Apple Podcasts by searching for and subscribing to "Gao Neng Liang" (High Energy).

Topics they covered include, but are not limited to:
- What entrepreneurial and investment opportunities has ChatGPT created? What capabilities do founders need?
- What are ChatGPT's limitations, and where are its boundaries? Will tech giants become even more dominant?
- How has generative AI brought new thinking to biotech research, and what specific products and applications exist?
- For the biopharma field, is ChatGPT an accelerator or a paradigm shift? What impact will it have on existing business models and industry structures?
- How will imprecise ChatGPT be used in biopharmaceuticals?

Interactive Giveaway: Have you used AIGC-related tools in your daily life? How have these tools changed things for you? What opportunities do you see? We look forward to hearing your thoughts in the comments. The five most thoughtful commenters will each receive a copy of AI 2041: Ten Visions for Our Future, recommended by Elon Musk. We hope this book will help everyone better understand AI's past and future.



/ 01 / In the ChatGPT Era, Where Are the Entrepreneurial and Investment Opportunities?
Rui Ma: People across industries have been paying attention to ChatGPT lately. What entrepreneurial and investment opportunities do you think it has created?
Chen Shi: That's an excellent question — I've been getting it a lot recently. We first need to understand what ChatGPT fundamentally is. Right now, ChatGPT is a successful language model that has mastered communication. But researchers' expectations for it have already moved beyond being merely a language model; they want it to become a thinking machine.
People are currently using techniques like chain-of-thought to gradually unlock logical reasoning capabilities in language models. (If you'd like to learn more about ChatGPT's history and entrepreneurial opportunities, check out Where Does AIGC Go After ChatGPT's Explosion? | FreeS Report 28)
I currently see five major categories of entrepreneurial and investment opportunities: infrastructure, content production, language models, thinking machines, and empowering all industries.
On the infrastructure side, generative AI may need its own IT stack — hardware at the chip level, for instance. We'll likely need more GPU and TPU (Tensor Processing Unit) capabilities, or supporting services.
TPU: Tensor Processing Unit, an application-specific integrated circuit (ASIC) developed by Google to accelerate machine learning.

Additionally, front-end sensors could become more intelligent if connected to AI models. Apple has already announced support for running diffusion models on devices like the iPad.
In content production, as AI-generated content becomes widely adopted, the media industry may undergo massive transformation. The market has already seen AI content creation tools for various formats including text, images, video, and 3D.
At the language model level, AIGC technology can be used for human-computer interfaces. The paradigm for human language learning could change, and cross-lingual communication may become barrier-free.
In the thinking machine dimension, if AI truly becomes a thinking machine, it could enable many new applications: smarter software, automated programming, knowledge engineering, super brains, and AI for science — helping humans conduct scientific research.
Ultimately, this wave of AI technology may transform all industries. Some eagerly anticipate this; others worry about being replaced. But AI-driven transformation across industries is already underway.
Rui Ma: I partially agree. AI infrastructure companies — NVIDIA, for example — will likely be the first to capture the upside.
One point of disagreement: I think generative biology holds more promise than AIGC or AI for science. Integrating GPT into biological R&D tools will create more opportunity than content generation or conversational human-computer interaction scenarios. Content tools may have broader applications, but drug development tools deliver greater value — for instance, generating a novel antibody with drug-like properties.
Chen Shi: I think that's true from a research perspective. Scientists are relatively capable of judging right from wrong, so they treat language models as idea generators. But if ChatGPT confidently outputs incorrect information, the rest of us may struggle to tell. So we need to be cautious in how we use ChatGPT.
Content generation sits closest to foundation models — what we call "low-hanging fruit" — but that's precisely why it's a weaker business model. It sits too close to the large models themselves.
There's a case study: Jasper. When GPT-3 came out, Jasper started using it to generate business copy, building annual revenue to roughly $90 million. But after ChatGPT opened to the public in 2022, Jasper came under significant pressure.
When choosing and designing a business model, founders need to maintain a safe distance from the foundation model and its trajectory, while building real depth into their product. You want to do something that would be difficult or unappealing for the foundation model provider to tackle.
Ma Rui: Understood. Right now, everyone is surely assembling teams, trying to build China's ChatGPT, or looking for opportunities in large models and AI more broadly. From your perspective, if you want to pursue these directions, is there still opportunity for startups today? Looking ahead, what capabilities do founders need?
Chen Shi: Looking at today's startup landscape from an industry structure perspective, the bottom layer is hardware and cloud services — the infrastructure providing the underlying technology. Above that sits the model layer, and above that, the application layer. It's a three-tier structure. That bottom layer will likely be dominated by the major tech companies. The model layer, as foundation models, doesn't offer that many startup opportunities, though there may be some for vertical-specific models.
So the main startup opportunities lie in the application layer. I think the key for application-layer startups is: technology first, scenarios matter most. Teams need to understand AI technology, accurately grasp where the technology is heading, and apply it appropriately to real scenarios.
But that's just the starting point. In the long run, you can't build a moat on AI alone. AI is the capability of large models and massive datasets — at best, you have access to localized, fine-tuned data. This is where deep industry understanding and translating that into closed-loop scenarios becomes your real opportunity to build defensible barriers.
/ 02 / The Similarity Between Programming Languages and Biological Foundations: What Applications Does AI Have in Biotech?
Chen Shi: When did you first start engaging with AI? What technical progress and applications is AI driving in biomedicine right now?
Ma Rui: I invest in biotech within the biomedical space, and my own background is in biochemistry. But why pay attention to AI? Because FreeS Fund's approach to biotech investing is quite distinctive — we believe IT (information technology) and BT (biotechnology) can deeply integrate, and we focus primarily on the digitization of biological systems and processes.
This is also why biotech is iterating so rapidly now — because the entire field is built on digital infrastructure. It's highly data-driven.
Starting about three or four years ago, we invested in multiple AI drug discovery projects. Back then, it was mainly small-molecule drugs — from target discovery to small-molecule screening, to synthesis pathway planning, to computational screening of crystal forms and formulations.

But what we found was that the biggest bottleneck for AI drug discovery in small molecules was still data. When everyone was losing hope, AlphaFold emerged in 2021. AlphaFold 2 solved the protein structure prediction problem.
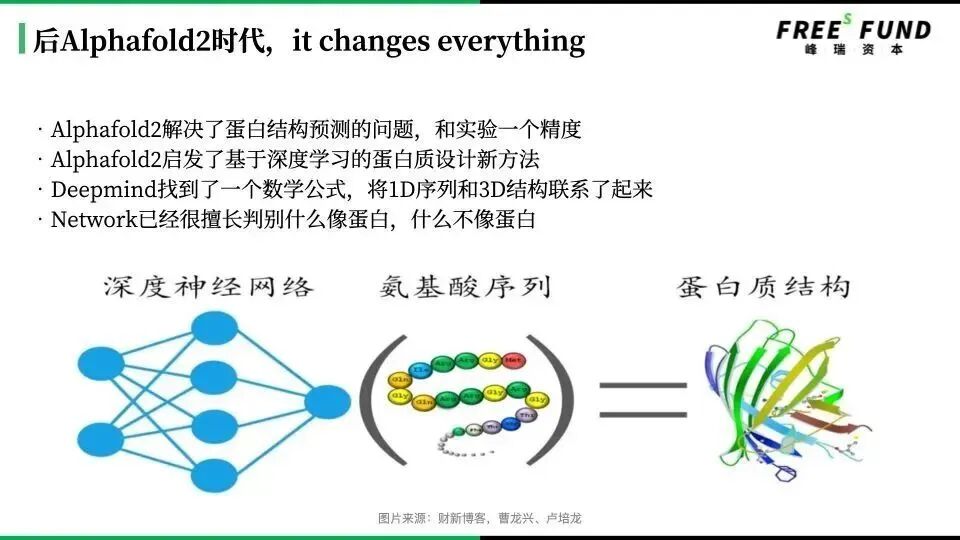
AlphaFold 2: A protein structure prediction program developed by DeepMind, owned by Google. Previously, deciphering the three-dimensional structure of a protein could take biologists years.
From that point on, over the past two to three years, I've been following new AI developments — for example, how Transformer architectures have been applied in structure prediction. Later, I realized that the inverse problem of structure prediction, namely protein design, would also be transformed by AI advances, with research paradigms constantly shifting.
From physics-based energy calculations to leveraging the latest AI tools like Transformers and diffusion models, AI technology and biotechnology are converging faster and faster, becoming increasingly tightly integrated. That's why I've been paying more and more attention to developments in GPT and AI broadly.
Chen Shi: Before AI technology, how did traditional biotechnology obtain data?
Ma Rui: Take DNA, RNA, and proteins — we care about their sequence, structure, and function. Whether at the DNA or RNA level, sequencing machines — like Illumina or China's MGI Tech — sequence the genes to determine how they connect in ATCG or TACG order. That gives you sequence data.
But once you have the sequence, you don't know what structure it takes. Structure is critically important — it determines biological molecular function. So sequencing only solves the ID number problem: you know who it is, but structure is the question of whether it's tall, short, fat, or thin — what shape it is.
Function is even more complex. "Function" is a very broad term. A biological macromolecule binding to a small molecule and producing some effect; a protein catalyzing a chemical reaction — these are all functions. Functional data is extremely scarce.
Why has biotechnology always progressed relatively slowly? Because biological systems are too complex — they're highly stochastic, high-dimensional, and nonlinear processes. There are no good models or equations that can explain biological systems, and even if there were, they would be extremely high-dimensional equations.
The way we solve these problems now is still largely trial-and-error — doing experiments one by one manually, rather than design based on rules. That's why we often say, "We can design bridges, yet we can only discover drugs."
Through computational research, people realized that AI is exceptionally good at solving these kinds of high-dimensional mathematical equations. AI can reduce dimensionality in implicit space (in implicit space, feature differences between similar samples are removed as redundant information, with only core features preserved). If we can use computation to solve prediction or design problems, it would be enormously helpful for biomedicine. And because biological systems are the best digitized, and this process is still accelerating, biology is likely the most promising field for AI for science.
Using GPT-style generative biology, we can solve these biomedical problems very effectively. If we let our imagination run, in the future, if you want to develop a COVID vaccine, you could tell AI: I want to generate an antibody that binds to this specific antigen epitope — and AI would help you find the solution.
AlphaFold 2 VS GPT: What's the Difference? Which Is More Efficient?
Chen Shi: DeepMind, acquired by Google, developed AlphaFold 2. Microsoft-backed OpenAI launched the GPT series, and many approaches and models have emerged around GPT and generative AI. From your perspective, what's the difference between AlphaFold 2 and GPT? Which is more efficient, which delivers better results?
Ma Rui: I'd say the difference is this: AlphaFold 2 is still more domain-specific. Its progress is remarkable — it can solve a specific problem, and solve it thoroughly, achieving through computation the same precision as experimental methods.
But GPT applied to biology is more like an approach. It provides us with many excellent models and algorithms, giving us a new lens through which to view biological data.
I certainly think AlphaFold 2 is impressive, but I also believe GPT may unlock greater imagination. The main difference is that AlphaFold 2 is a finished model for a specialized domain, while GPT gives us new ways of looking at data, catalyzing a new concept of "generative biology."
Looking back, AlphaFold 2 actually did two things. One, it adopted the Transformer extractor. In structure prediction, some researchers essentially borrowed new techniques from AI.
Second, the most abundant data in biotechnology has historically been in sequence sequencing. AlphaFold 2 used multiple sequence alignment (MSA) to integrate protein structure and biological information into deep learning algorithms.
Multiple sequence alignment: A method of aligning two or more character sequences, comparing their characters column by column to make each column as consistent as possible, in order to discover their common structural features.
In biology, multiple sequence alignment is a prerequisite for evolutionary biology research. By studying how homologous sequences change over time in sequence alignments, we can infer how sequence structure and function evolve. Compared to AlphaFold 2, why might GPT bring revolutionary impact to the biological field? In one sentence: GPT uses AI to learn from biological data generated through evolution. Once AI extracts the underlying rules, it can generate entirely new molecules that conform to fundamental biological logic but have never existed in evolutionary history.
For instance, if we previously couldn't find a particular molecule, combining GPT with biology might enable us to discover it — and much more efficiently. What used to take a year might now take seconds. You could understand the convergence of GPT and biology as a paradigm shift; the entire biotech industry may eventually move toward a generative biology model.
Right now everyone is excited about where GPT can be applied. First, using NLP to mine existing knowledge, then protein structure prediction and protein design, RNA sequence mining, and enzyme design. Then whether it can be used for drug development — solving protein-protein binding, protein-RNA binding, protein-peptide binding, and finally protein-small molecule binding problems.
Further down the line, people will consider whether we can predict clinical trial success rates and modify trial designs to improve them.
These are all future directions. They may unfold sequentially or simultaneously, because every biology research group is now closely following GPT's progress and figuring out how to apply it. As you said, you "need to understand both the technology and the strong scenarios" to actually deploy it in practice.
Chen Shi: Beyond sequence analysis, AlphaFold 2 also incorporates labeled datasets. From this perspective, it's somewhat like "supervised learning." The advantage is that it's very accurate. Theoretically it can make errors, but its mistakes aren't open-ended — you can tell whether the fitting is good or not.
But ChatGPT is open-ended. Its advantage is that even when not precise, it produces many creative, groundbreaking ideas. You also mentioned that human scientists can gain insights from it that spark their own creativity. That's its value. It's a trade-off between precision and creativity.
Ma Rui: Based on what you just said, we can actually draw a conclusion: AlphaFold 2 will definitely occupy an important place in generative biology — Google hasn't completely lost. AlphaFold 2 now provides generative AI with a very accurate discriminative or computational tool that you can call upon to do generative things.
In generative biology, you learn from lots of data, master its underlying rules, and based on these rules generate many biological molecules. Some of these molecules are what you want, some aren't. But the tolerance for error in biology is much higher than in chat scenarios — if I design 5,000 proteins and just one is what I want, I'm still satisfied.
As generation becomes more abundant and data learning continues, generative biology may also see an explosion in data volume. Models will get larger, while also needing to call upon highly accurate tools to provide constraints. I think both of these developments have influenced my values and made me more optimistic about AI itself. This iteration will have enormous positive impact on downstream applications.
How Can GPT Leverage Its Strengths? And How Can We Improve GPT's Accuracy?
Chen Shi: What ChatGPT or subsequent models "learn" are parameter matrices. What they present to people is complex, but no one knows what's inside. Sometimes ChatGPT — at least version 3.5 — produces what we might call "confident nonsense." But biotechnology demands very precise results. How do you view this unexplainable yet error-prone GPT?
Ma Rui: I think ChatGPT may have generated many profound ideas, but during training, people may have labeled these imaginative thoughts as unsuitable for human consumption, so they weren't selected. So it's possible it has already produced some unexplainable or more intelligent thoughts that we simply haven't seen yet.
In biotechnology, the way we use ChatGPT or GPT definitely shouldn't rely on a single response. We should focus more on the new clues and fresh perspectives it provides us.
That said, how can we improve GPT's accuracy?
First, you need "domain knowledge" — specialized knowledge of the discipline. Second, you need good data within that discipline. Like AlphaFold 2 — it didn't use a generative model, but because it used good data, it achieved very high accuracy.

In recent decades, AlphaFold 2 was the first to make computation achieve the same precision as experiments. In structure prediction, AlphaFold 2 has essentially solved single-domain protein structure prediction through computation. There are scenarios in biotechnology where, once you give it the right data and know how to organize that data, and you apply the latest AI methods, it can give you very accurate information.
Chen Shi: There's also a view in the industry that humans need to develop the ability to judge the probability of correctness or reliability of answers ChatGPT gives you. Like content on many online forums — not necessarily accurate, but inspiring. If you only pursue absolute accuracy, you might miss out on inspiration or alternative perspectives that others stimulate in you. I think we should accept the current state and accept that some things may be inaccurate.
I've also been thinking recently: can our human languages or programming languages be optimized for GPT? We know that sometimes ChatGPT struggles to generate large blocks of code. I think this is also facing a transformation.
For example, as part of IT infrastructure, can our programming languages and program structures be optimized for ChatGPT, enabling it to more accurately output qualified programs? After all, most currently popular programming languages are products of the 1990s or earlier. Now we may need programming languages more compatible with GPT models.
Ma Rui: I think you make an excellent point. Incorrect inputs aren't necessarily unhelpful for knowledge formation — humans are essentially larger GPT models. We possess intelligence; give me data points and knowledge, and I can learn new knowledge and rules from them.
This is also the difference between generative and discriminative AI. Discriminative AI doesn't need to know all the points, but it needs accurate data to help you draw that line. For generative AI, it needs to know as many points as possible to help you discover the distribution patterns of these points.
Of course, if a new technology is to be used in serious medical scenarios, it definitely needs to go through the entire R&D and regulatory process, completing all required procedures before it can truly face consumers or patients. So beyond content uncertainty, for us the most important thing is to think about what impact a major breakthrough like ChatGPT might have on biology.
05 The Possibilities of Generative Biology: How Can Large Models Combine with Traditional Computational Tools?
Chen Shi: Multimodal alignment of text and images has been partially achieved in GPT. Are there similar cases in biotechnology?
Ma Rui: Yes. For example, in protein design, combining structural tools with diffusion models — such as AlphaFold 2 or RoseTTAFold — allows multimodal or multi-track information to be incorporated.
RoseTTAFold: A three-track neural network that can simultaneously consider patterns in protein sequences, how amino acids interact, and the possible three-dimensional structure of proteins.
For example, for sequences important to a protein's structure or function, graphs of pairwise residue contact distances, and three-dimensional structural coordinates — the model can input multimodal data simultaneously and iterate during diffusion.
This enables discovery of hidden connections between sequence and structure, learning the parameters between them in higher dimensions than humans can. So AI models converge very quickly, making protein design vastly more efficient than models without diffusion.
Where AI previously took ten hours to calculate a protein, it now takes milliseconds. In protein design, we've already seen progress from multimodal integration. We look forward to seeing AI improve R&D speed or accuracy in other biomedical subfields as well.
Chen Shi: You raised an interesting topic: the industry is now exploring how to combine traditional computation with language models. Sometimes when people ask ChatGPT to add three-digit numbers, it makes mistakes. So there's a view: could we leverage traditional computational tools, like calling Python code, to directly calculate three-digit addition or multiplication in one line?
This way ChatGPT can play to its strengths, solving tasks it's not good at through external calls (note: On March 24, OpenAI announced ChatGPT supports third-party plugins). Do you see possibilities for combining these two approaches in biotechnology?
Ma Rui: My understanding is this: large models solve the core intelligence problem and perform well in chat scenarios, but you actually need to call many peripheral tools. The future trend is definitely engineering-oriented — modules that can accurately calculate or execute tasks will be connected to the core intelligence framework.
For biotechnology, it's like a vertical domain of a large model. Biology has sufficient data volume, so some have directly used language models to accomplish many things in biology. For example, Meta (formerly Facebook) trained a contextual language model on 86 billion amino acids from 280 million protein sequences.
My feeling is that several directions will coexist in future biotechnology. People will explore whether existing sequence, structure, and function data can be made into individual language models, and whether multimodal data can be fused into one large model. A second direction is along the original professional track, incorporating the latest methods from generative AI or diffusion models, blending in new ideas and models like GPT.
I don't think there will be an exceptionally large Foundation Model specifically for biology, but the field will likely develop its own large models and specialized models by leveraging new AI algorithms.
Chen Shi: My understanding is that biology may eventually end up with a large Foundation Model that takes multimodal inputs. This specialized model would likely start by aligning on text, and as multimodal recognition improves, it would align across other modalities too, becoming a relatively complete foundational model for the biology domain.
Ma Rui: I agree. At the intersection of GPT and biotech, I see three major directions. The first and most obvious spillover is NLP large models. We're already seeing biology-focused large language models like BioGPT — this is the most intuitive direction, the first thing everyone thinks of.
BioGPT: A large language model based on biomedical research literature, capable of text generation and mining for life science literature. Released by Microsoft Research.
The second direction follows the central dogma — designing and computing biological molecular building blocks.
The central dogma of biology is DNA transcribed into RNA, then translated into protein. The most useful data in biotech follows this DNA-RNA-protein axis, looking at sequence, structure, and function.
"Sequence" isn't just a biology term; it's common in computer science too. The underlying logic of biological and computer code is remarkably similar. At the DNA level, the combinatorial arrangements of the four nucleotides A, T, G, and C resemble writing program code. At the protein level, each position in a sequence is a choice among 20 amino acids — also very much like code. So the first step in biotech research is definitely understanding sequences thoroughly.
In biotech, the gap between different modalities is still quite large. You might collect someone's blood pressure data, EEG data, heart rate data, and other biochemical data, but you don't know how to align these different-dimensional datasets together into one model. We've been talking about big data for a while, but we lack a truly engineering-driven approach, or a framework for alignment.
From DNA to RNA to protein, predicting and designing their sequences, structures, and functions. Some of these problems have already been solved, and protein design is iterating extremely quickly — basically new methods emerge on a monthly cadence.
When you finally get to function, you still need to solve the computation of biomolecular interactions — how one protein binds to another, and how strong that binding is.
Protein design needs to consider the flexibility of both backbone and side chains simultaneously. Now, empowered by diffusion models, there could be major breakthroughs within the next two years. Once that happens, future protein or macromolecule drug design, and even the entire AI-driven macromolecule pharma space, could be completely disrupted. So I think there are many directions in biotech worth paying attention to and thinking through with GPT.
06 Will GPT Empowerment in Biotech Favor the Strong, or Give Startups More Opportunities?
Chen Shi: What kind of impact will GPT have on current business models and industry structure in biotech? With GPT, how will the competitive landscape between large companies and startups shift — will giants get stronger and startups lose out? Or will GPT enable small companies to access piles of data and potentially beat the giants?
Ma Rui: Biotech has seen many waves of technological revolution, so we can probably anticipate GPT's impact. New technologies are typically pioneered by small biotech companies, then diffuse across the entire industry. Once protein design's interaction problems are solved, the most immediate consequence is the ability to fully design protein drugs.
At first, only frontier biotech companies may be able to do GPT-bio integration — there aren't many companies or scientists worldwide who can do this kind of work right now. Going forward, the technology may become more mainstream infrastructure, radiating across the industry.
Small companies lead first, changing the entire industry's landscape, then big pharma follows. Big pharma's strength lies in clinical development and later-stage commercialization; small companies excel at technology and zero-to-one discovery. Eventually the two integrate into a single value chain. The technological disruption will be greater than the commercial disruption.
Chen Shi: For the biopharma industry, I don't think they'll build large language models, but they might build somewhat smaller sequence-based Foundation Models. Do you think biotech companies or big pharma would be better positioned, more efficient at doing this?
Ma Rui: It seems like both. Right now for protein large language models, there's work from Facebook, from Salesforce, and from biotech companies.
Because these are large models, you basically need hundreds of millions of sequences — all from public databases. Everyone shows their own capabilities, leveraging their understanding of AI technology to build these models. I don't think there will be a huge difference between large and small companies going forward. It mainly comes down to who can access the data and who understands AI models better.
Chen Shi: Maybe the data just isn't large enough yet. If it reached the scale of language models, many people couldn't afford to play. But in biotech, neither model parameters nor data volume are large enough yet, so startups can still compete.
Ma Rui: Right. We can compare data volumes across three categories: text, biology, and AI for science (outside biology, like materials). Text has the largest data volume. Biological data sits right between text and materials. So I'm not that optimistic about AI for science outside of biology — I think biology is the most likely to be ignited by data.
In text, there aren't many startup opportunities. Without funding capacity and compute to build large models, it's hard to start a company. But biotech could be a future focal point for entrepreneurship. The datasets aren't as massive, but they're larger than those in materials, physics, or chemistry, so there may be some opportunities.
Many people want to do AI for science, like materials design or computation. But the problem with materials is that you really have to measure data through experiments. Biology builds upward from underlying sequencing data step by step — once sequencing is unlocked, that brings substantial change.
Chen Shi: This is quite interesting. Biotech entrepreneurs can build vertical language models or foundational-model-like things. Right now it looks like foundation models and language models are out there in general, but entering a specialized domain may require vertical foundation models.
Ma Rui: I think biology is a field where vertical language models are possible, but many scientific domains don't have biology's favorable conditions.
What's more interesting in biology is how complex biological processes can be encoded purely through DNA sequences, because it also progresses by hierarchical complexity. DNA becomes RNA, and RNA is a highly dynamic process that performs many functions, then RNA becomes protein.
Protein is the unit closest to us that we can actually see. It's both a target and an executor, and also an information transmitter or sensor. If you combine DNA-level models with protein-level data, can you transfer-learn into the RNA domain?
Right now the market for small-molecule drugs targeting RNA is also quite large. In biology, RNA is an extremely important molecule, but we can't measure it well. Many people wonder: can we feed DNA sequencing data, protein structure and functional sequence data into a large model, and transfer-learn RNA-related knowledge and other information? So in biology, Foundation Models may indeed bring quite a few entrepreneurial opportunities.
Engagement Giveaway: Have you used AIGC-related tools in your daily life? How have these tools changed your life? What opportunities do you see? Looking forward to hearing your thoughts in the comments. The 5 most thoughtful commenters will each receive a copy of Life 3.0: Being Human in the Age of Artificial Intelligence, recommended by Elon Musk. We hope this book helps everyone better understand AI's past and future.

Every Brain Is a Unique Little Universe | FreeS Special Initiative for World Autism Awareness Day
How to Invest in Biotech in 2023? | FreeS Research Institute
AIGC: How Can Vertical Sectors Find Opportunities in This AI Wave? | FreeS Fund Dialogue
Star the FreeS Fund WeChat official account for timely business insights
