ZangAI Benchmark Released: GLM 5.2 Takes First Place, Surpassing Opus 4.8

Not an ad, didn't actually get paid for this.

"Tang the God, Liang the Saint"
This is the most labor-intensive article Zang AI has published since launching.
To seriously evaluate the capabilities of domestic models, I developed my own benchmark. I thoroughly tested the latest Chinese models — Zhipu AI, Qwen, Moonshot AI, MiniMax, DeepSeek — and brought in the foreign competitor Claude as a control group.
What's wrong with LLM evaluations today?
Every model vendor is gaming the same benchmarks, and they're all gaming SWE-bench. This means you can't tell them apart from the leaderboards — every new model claims to be third globally, first domestically.
All vendors chasing the same benchmarks creates another major problem: model homogenization. Every model optimizes for the same high scores. Every model competes on coding and long-horizon agentic tasks.
So models end up with no personality, no style. The only difference between them is success rate on programming tasks.
Even worse, competing on coding damages writing ability. Coding has correct answers, so all models trend toward over-fixating on details, structuring their reasoning, and generating verbose responses.
The concise, human-feeling Claude Sonnet 3.5 is gone forever. After the coding arms race, Claude's writing keeps getting worse, directly hurting the conversation experience. When I chat with the Claude app now, I often feel like I'm using ChatGPT — answers that safely catch everything you throw at them.
I wanted to know how different models perform on real engineering tasks — not leaderboard gaming, but independently completing a full website rebuild: reading local data, writing code, generating pages, and producing a directly browsable website.
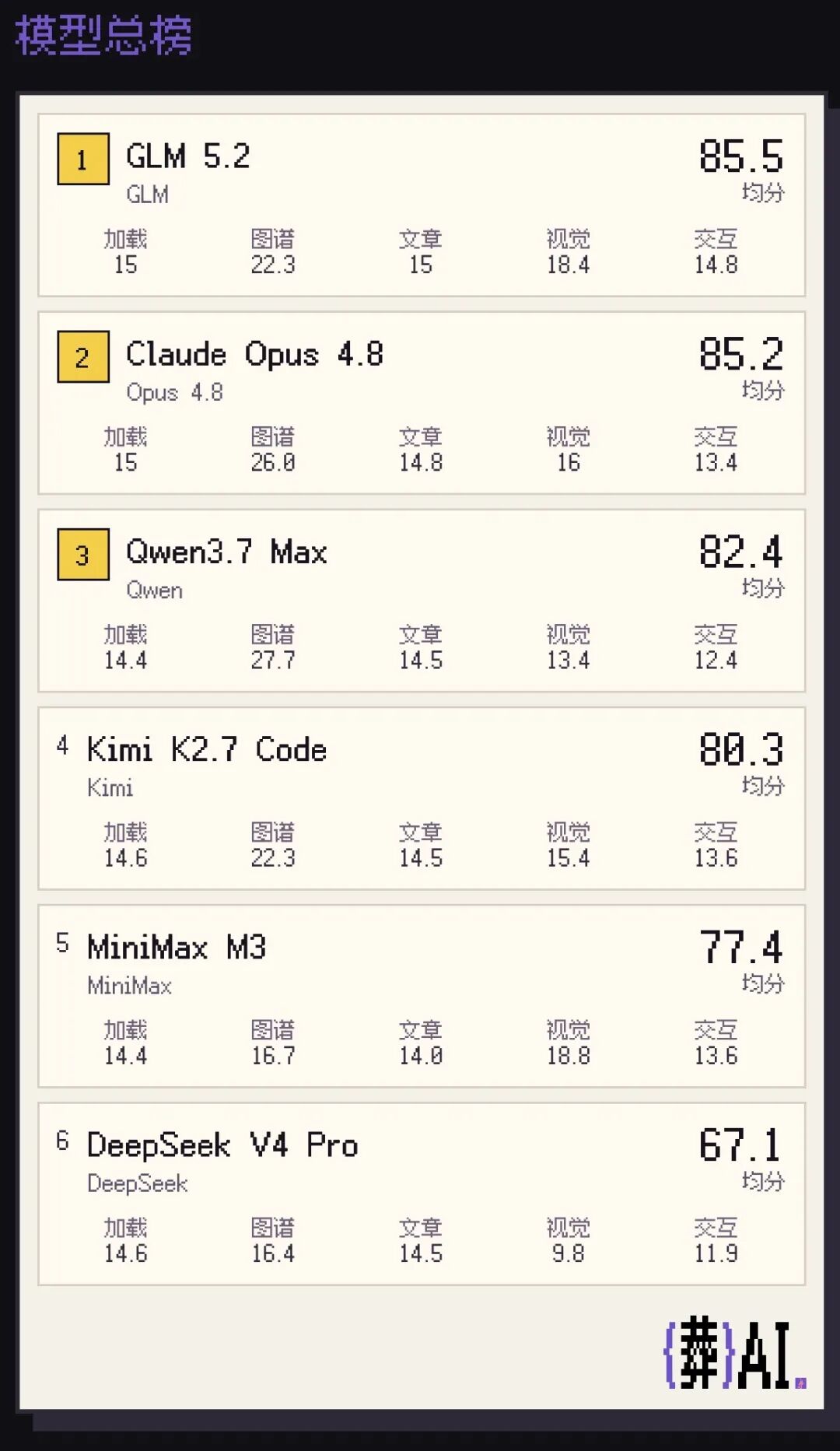
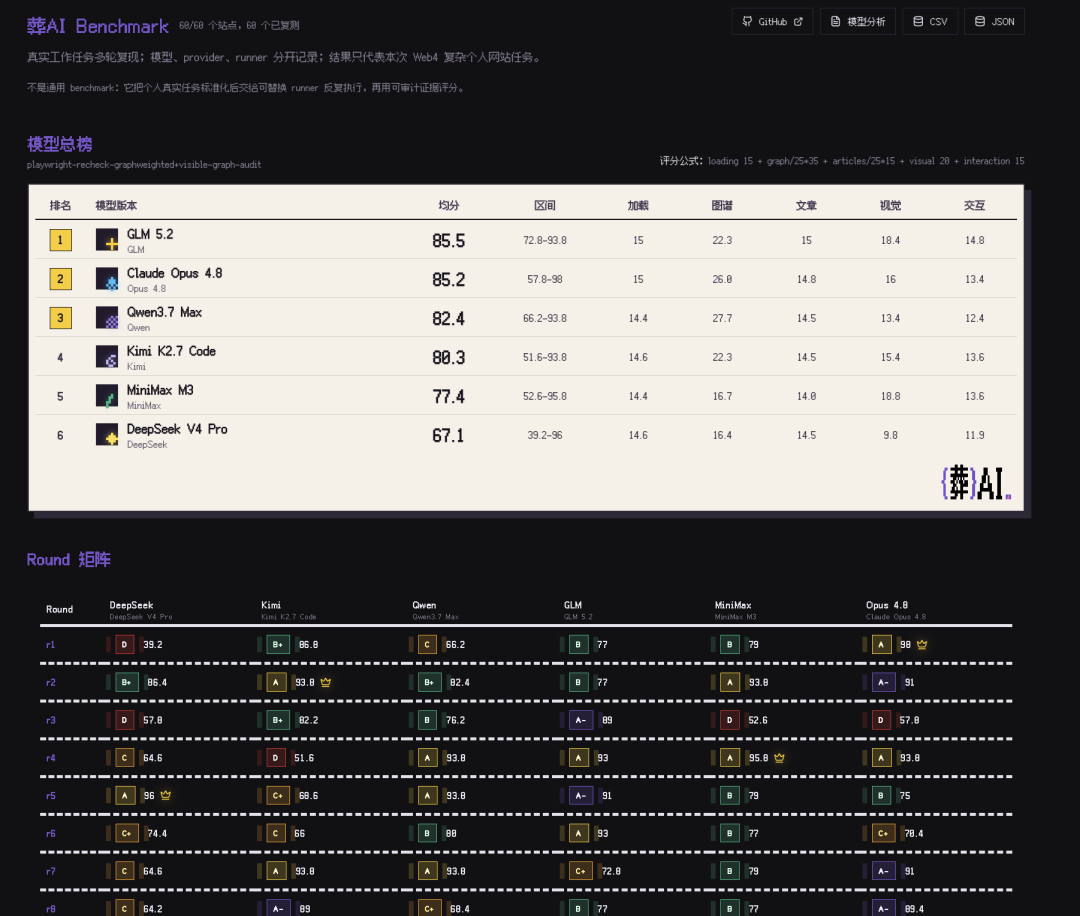
First, the results: GLM 5.2 scored first, even slightly edging out Claude Opus 4.8.
Then came Qwen 3.7 Max, Kimi K2.7-code, MiniMax M3, and DeepSeek V4 Pro.
Here's how the test worked.
Zang AI has a beautiful website, funeralai.cc, which syncs all our articles and runs them through a knowledge graph.
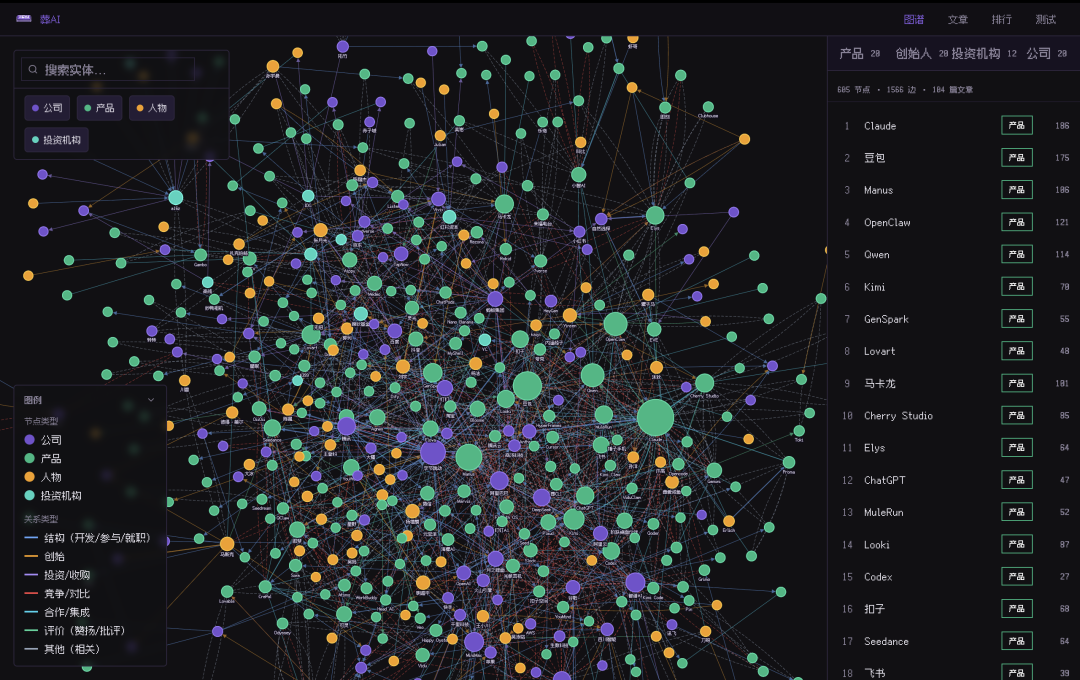
I fed each model the complete local dataset — 103 article bodies, a knowledge graph with 600 nodes and 1,546 edges — along with an identical execution plan. The task: rebuild a complete static site with a homepage, knowledge graph page, article index, and 103 detail pages.
To ensure fairness, each model ran 10 rounds, each an independent fresh Opencode session with no conversation memory. Sixty websites were generated total.
For scoring, an agent opened each one in a browser to inspect. Using the same scoring framework across five dimensions — basic completeness (15%), graph quality (35%), article completeness (15%), visuals (20%), and interaction stability (15%) — it scored each independently, then weighted and averaged.
I've open-sourced the full methodology on the Zang AI website, and deployed all 60 model-generated pages live.
funeralai.cc/test
This site contains all test artifacts, detailed analysis reports, and GitHub links. You can click through all 60 test pages one by one.
The results aren't particularly surprising — they match my hands-on experience with these models.
Let's break them down.
The GLM series is widely recognized as China's top model for programming. The only surprise was GLM 5.2 (85.5) slightly surpassing Claude Opus 4.8 (85.2).
Both produced high-quality websites with all necessary features, knowledge graphs rendering in one shot, and well-replicated interactions.
Here's Claude Opus 4.8's highest-scoring output — functionally complete with interactive knowledge graphs. Points were deducted only for imperfect visual replication.
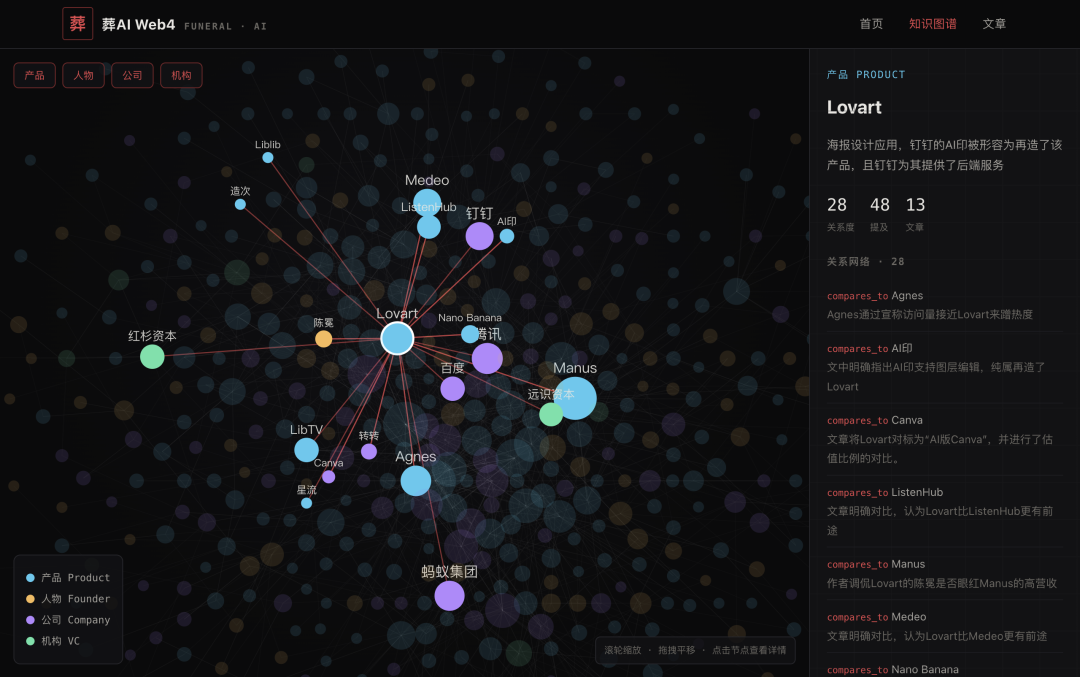 funeralai.cc/test/r1/claude-opus-4-8
funeralai.cc/test/r1/claude-opus-4-8
And here's a stronger output from GLM 5.2 — noticeably more faithful visuals, though interaction issues with overlapping nodes cost some points.
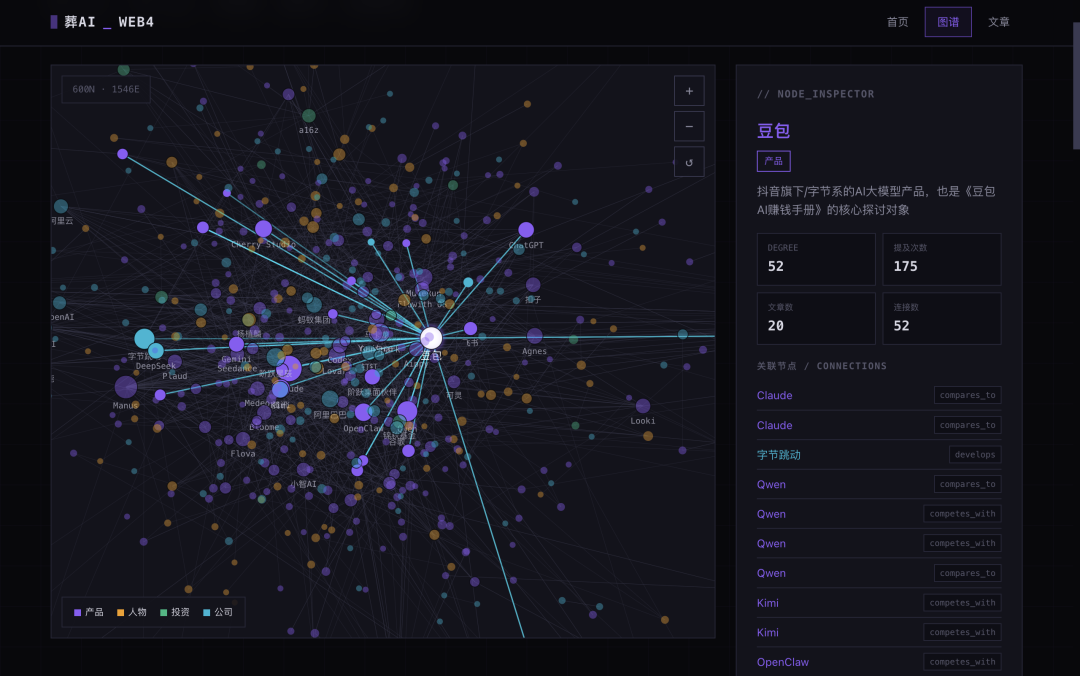 funeralai.cc/test/r5/glm-x-preview
funeralai.cc/test/r5/glm-x-preview
After 10 rounds each, GLM 5.2 and Opus 4.8 were largely comparable. The former won on output consistency with no extreme outliers. The latter was dragged down mainly by one round where the graph failed to render.
My friends share this intuition. For one-shot frontend and business logic generation, GLM 5.2 is fully on par with Opus 4.8.
My friend Kaiyi, after using several models to replicate LibTV, declared GLM unstoppable — even the canvas page was replicated convincingly, clearly surpassing Codex and Kimi, which failed to generate a canvas at all. He immediately canceled his Kimi subscription auto-renewal.
But some report GLM 5.2 still hasn't reached Opus 4.6 levels. As is well known, Opus 4.8 lags 4.6 in many areas — a classic Anthropic-style downgrade.
Beyond GLM 5.2's excellence, my other major finding: Qwen 3.7 Max (82.4) is genuinely capable.
It mainly wins on engineering stability — almost no major errors, graphs rendering consistently. Point deductions came from visual and interaction variance: several rounds had weak CSS variables and design systems, causing noticeable visual score drops.
Qwen 3.7 Max was the most engineering-stable model in the entire test, and felt close enough to the top two for daily work.
This is actually remarkable, because the Qwen series has traditionally been known for lacking a flagship model — people think of Qwen for open-source, smaller-parameter models. But the Qwen 3.7 series has reached fully usable levels.
Then there's our beloved Kimi (80.3), the most product-savvy of the bunch.
Kimi K2.7-code's main problem is inconsistent output quality. Good rounds scored high, but three rounds failed to render the graph at all, dragging down the average. Here's one round that produced just an empty shell:
 https://funeralai.cc/test/r4/kimi-k2-7-code
https://funeralai.cc/test/r4/kimi-k2-7-code
I must add: Kimi was the second most expensive model in this test, after only Claude.
One Claude test round cost me 202.5 RMB. Kimi somehow cost 164.6 RMB for the full test — far above Qwen at 23.5 and MiniMax at 23.2, and utterly demolished by DeepSeek at just 17.1.
I was shocked when I saw the bill and dug into the logs. Turns out the vast majority of Kimi's API cost went to cache hits — 104.7M cache hit tokens, costing 136.2 RMB.
DeepSeek had the same pattern, with 191M cache hit tokens. But DeepSeek's cache hits are absurdly cheap — 1/52 of Kimi's price. That's why DeepSeek's actual cost was so low.
Both models had extreme cache hit volumes because of excessive API calls. Kimi K2.7-code made 1,046 requests; DeepSeek v4-pro made 1,129. When the model can't get it right in one shot, the agent keeps requesting, fixing repeatedly.
This contrasts sharply with Qwen: the entire test generated only 288 requests for Qwen 3.7 Max, meaning fewer cache hits and lower costs. Truly the most engineering-stable model 👍
That said, while DeepSeek V4 Pro (67.1) had the most unstable generation quality — with high-scoring rounds but catastrophically low ones pulling down the average —
your boy Liang is really cheap. How does that saying go? DS only charges you for electricity on tokens; don't worry about the R&D costs — Liang the Saint has his ways to sort that out between 9:30 and 15:00 on weekdays.
And DeepSeek's main issue is stability. For my own use, with multi-turn interaction, DeepSeek is perfectly workable. For over a month now, I've been using Opencode with DeepSeek for daily tasks without issues.
So there really is a DeepSeek kill line: models that cost more without clearly better quality get eliminated.
MiniMax M3 (77.4) is approaching that kill line.
MiniMax's visual design is a clear strength — CSS variables and page texture often look great. But on the graph page that most tests engineering capability, it succeeded only 3 of 10 rounds, dragging down the average.
Below is a typical empty-shell graph page.
 https://funeralai.cc/test/r3/minimax-m3
https://funeralai.cc/test/r3/minimax-m3
For the same cost, I could use the more engineering-stable Qwen 3.7 Max. So where exactly does MiniMax fit?
MiniMax and Kimi share similar problems: good frontend completion but unstable engineering. Kimi's situation is much better — not at risk of being killed by DeepSeek.
But with GLM 5.2 for strongest coding and Qwen 3.7 Max for relatively cheap, stable engineering, why use expensive Kimi 2.7 code?
I won't belabor the point — all 60 test pages are live on the Zang AI site. Click through to see each model's outputs, strengths and weaknesses at a glance.
Let me wrap up.
This benchmark originated because I needed to write about Qwen. I didn't want to spout empty organizational strategy — that would be pure Alibaba flavor.
To seriously evaluate Qwen 3.7 Max's capabilities, I thought to use my own relatively complex engineering task — the Zang AI website — as a benchmark to evaluate these models.
The core reason: vendors are all gaming the same leaderboards, so the most famous benchmarks have lost their discriminating power. And if you've looked at SWE-bench problems, you'll see the approach is to find GitHub issues — real human programming problems — and see if AI can solve them.
This is the same philosophy as the Zang AI benchmark. I also gave AI a complete repository, asked it to rebuild a relatively complex website with knowledge graphs, then scored it against the original.
Moreover, this approach generalizes. I know many product and engineering friends who maintain private evaluation sets — a few real engineering problems they encounter at work, run against each new model release.
This is a good thing. Everyone should have their own benchmark for evaluating these models.
Because one leaderboard can't represent all needs. The point isn't finding the world's strongest model, but finding the model most useful for your actual work.
For example, while GLM scores higher, its writing is less flexible than DeepSeek's. And by my feel, all current models' writing may lag behind Claude Sonnet 4.0 released over a year ago.
I've open-sourced the Zang AI benchmark approach. The core is abstracting work you actually do daily into a repeatable task, then having different models complete it across multiple rounds and scoring.
github.com/FrichXi/personal-work-benchmark
Send this link to your agent and have it reference this approach to build a benchmark you personally trust.
Of course, my scores here may just be for fun.
Though I tried to control variables, other factors crept in. For instance, I couldn't buy a GLM membership, so GLM 5.2 was called through an internal testing interface provided by Zhipu AI folks — whether it got special sauce or not I can't say, but it definitely wasn't a dumbed-down version.
If I buy GLM 5.2 membership in a few days and get different scores, I will apologize to the family and denounce Zhipu AI as fraudsters (hopefully not).
As for Claude Opus 4.8, I used a relay API. Though it's a major relay station featured in Anthropic's reports, with original pricing, whether it's fully authentic is hard to say.
Minor score differences from this evaluation are meaningless — look at the broad conclusions.
The conclusion: GLM 5.2 is legit, truly reaching Opus 4.8 level. Qwen 3.7 Max is next, most engineering-stable.
Kimi especially needs to strengthen infrastructure — learn from Liang the Saint on cost reduction and efficiency. Your cache pricing I genuinely can't afford. Most needing to hustle is MiniMax — run faster, kid, don't accidentally fall below the kill line 💪
Final disclaimer: This article accepted no sponsorship. It's purely a combination of objective evaluation results and subjective experience.
It may look like a Zhipu AI ad, but I genuinely took no money from Zhipu AI or anyone. Love you ❤️
Stay tuned as we write up Qwen, Zhipu AI, and other model vendors one by one.
(Cover image generated by ChatGPT, purely human-written)
⬇️
Subscribe to our Substack funeralai.substack.com