Benchmark Update for AI Benchmarking: Seed 2.1 Pro Urgently Needs to Escape the Gravity of Mediocrity

Claude's kill threshold has arrived.

"The Claude Kill Zone Has Arrived"
Doubao the product is unstoppable, but the Seed model has always been lukewarm at best. People's impression of it boils down to two things:
Fat paychecks — every few weeks there's news about 10-million or even 100-million RMB annual packages, though nobody knows if they're real; and multimodal capabilities, but coding skills that don't quite measure up.
So much so that your girl Doubao got nicknamed "Sugarbao," and even became an adjective. When Gemini underperforms, you call it the North American Sugarbao. When Grok does even worse, you somehow label it the North American Sugarbao #2.
The audacity! Have you no sense of "when the ruler is worried, the minister toils; when the ruler is shamed, the minister dies"? Where are the Doubao defenders at?
So we have reason to believe the Seed model team has ample motivation to drop something big. Not asking for a Seedance-style moonshot, but at least bringing the text model up to domestic first-tier standards.
This Seed 2.1 Pro release specifically emphasized programming and long-horizon task execution capabilities. The marketing pitch: finally a model capable of Agent work, claiming to complete the coding puzzle.
Is that really the case?
To objectively assess Seed 2.1 Pro's programming level, I reran the Funeral AI Benchmark with it. Let me give you the model capability rankings in the most straightforward, no-nonsense way possible — no suspense, right here ⬇️
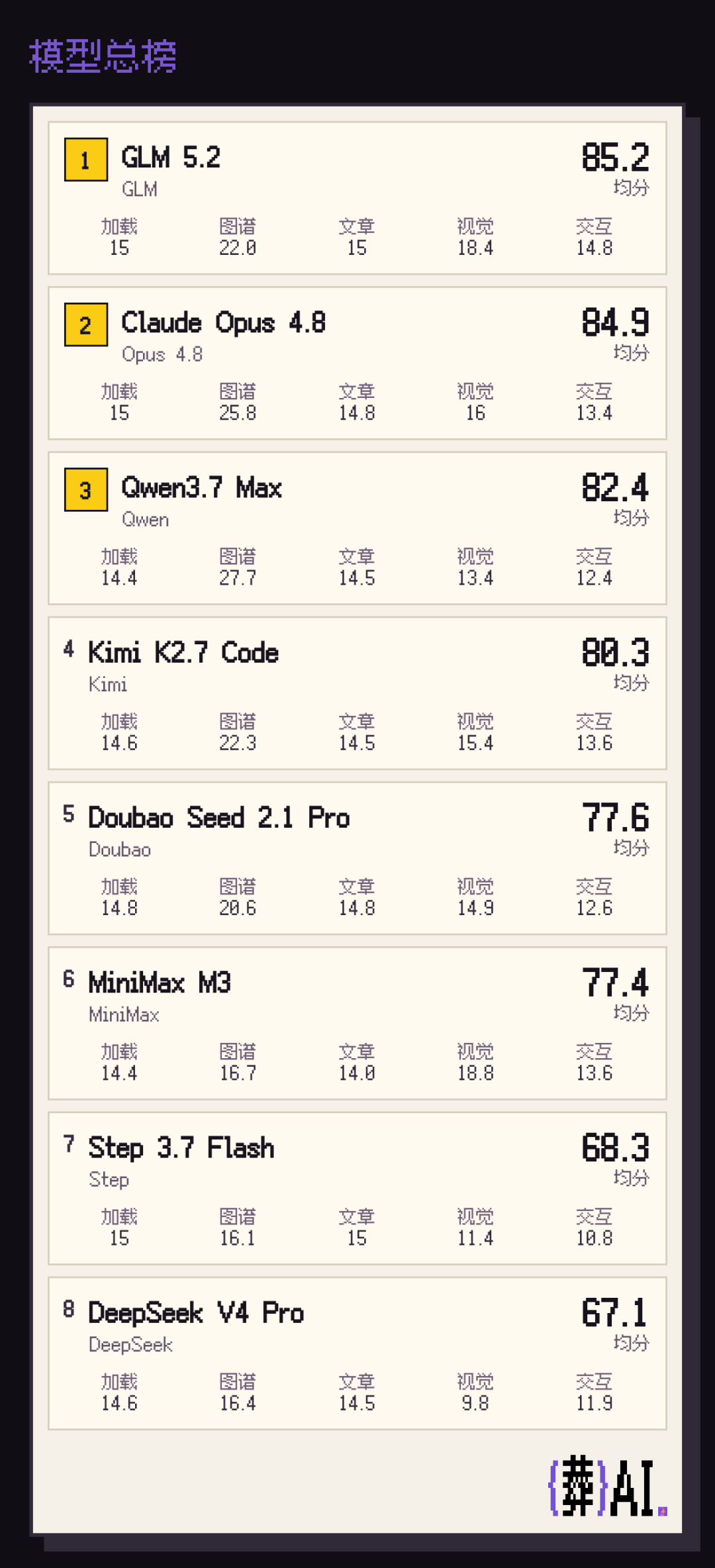
The results are shocking. Seed 2.1 Pro scored about the same as MiniMax M3, slightly below Kimi K2.7 Code, and showed a clear gap compared to the domestic #1 GLM 5.2.
Two new models were added this round: Seed 2.1 Pro and Step 3.7 Flash.
The testing methodology remains the same: each model runs 10 rounds, each an independent Opencode session with the same execution plan, to rebuild the beautiful Funeral AI website (funeralai.cc). Codex handles scheduling and scoring, with weighted averages for ranking.
All 80 outputs (8×10) are live on the Funeral AI website — judge the gaps for yourself.
Seed 2.1 Pro's main problem: it struggles to generate good results in one shot, with inconsistent engineering capabilities.
This led to a high number of model calls for Seed — 449 calls to complete the test task, far above GLM 5.2 (321), Qwen 3.7 Max (218), roughly on par with Step 3.7 Flash (443), and second only to the highest caller MiniMax M3 (653).
In terms of outputs, Seed 2.1 Pro's deliverables were highly unstable.
Seed's highs were high — it produced 3 top scores — but its lows were lower, with significant variance dragging down the total. Below is one of the high-scoring outputs, with a clear, interactive knowledge graph.
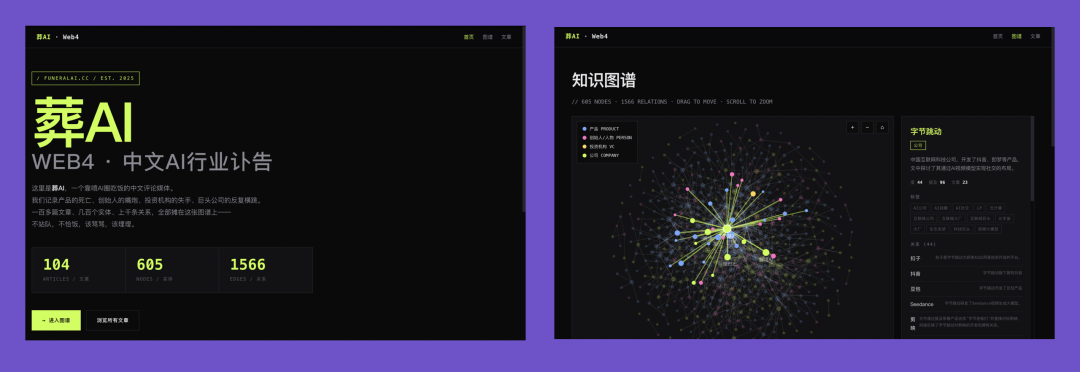 https://funeralai.cc/test/r4/doubao-seed-2-1-pro-260628
https://funeralai.cc/test/r4/doubao-seed-2-1-pro-260628
The main deduction came from Seed failing to generate functional knowledge graphs — it failed this relatively complex frontend task 6 out of 10 times. Below is a typical low-scoring output with an empty knowledge graph.
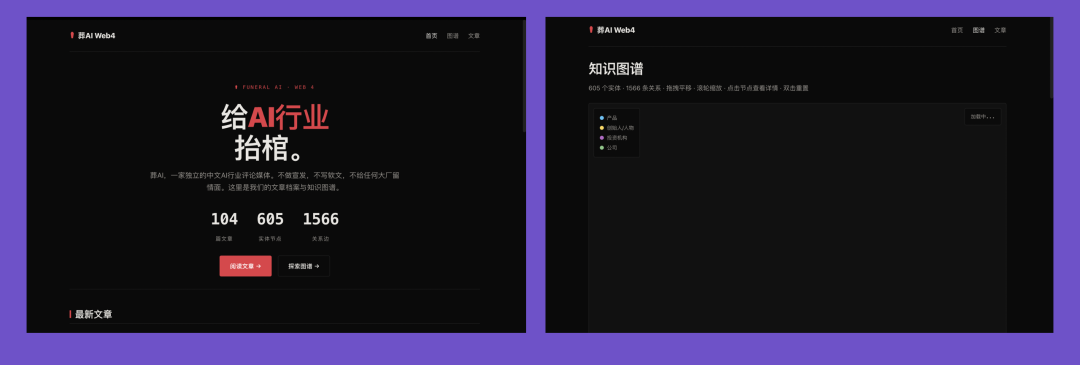 https://funeralai.cc/test/r10/doubao-seed-2-1-pro-260628
https://funeralai.cc/test/r10/doubao-seed-2-1-pro-260628
Another major issue: Seed 2.1 Pro's generation speed is too slow.
It took 128.9 minutes to complete the test task, second only to MiniMax M3 (153.9 minutes), and far behind the fastest DeepSeek V4 Pro (46.7 minutes), as well as the relatively quick Qwen 3.7 Max (53.3 minutes), Step 3.7 Flash (57.4 minutes), and GLM 5.2 (69.7 minutes).
The slow generation speed likely stems from weak long-horizon task execution capabilities.
This actually aligns with ByteDance's own published benchmarks.
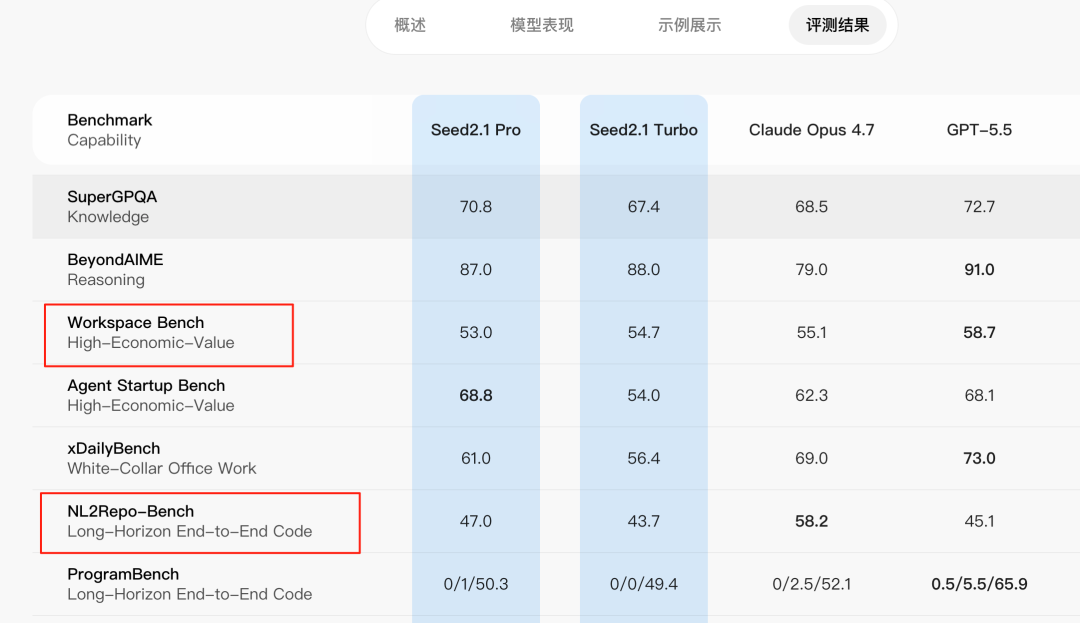
Thanks to Kaiyi's reminder, I realized ByteDance's own tests reflect this too. These two benchmarks are fairly representative for evaluating long-horizon task planning — and Doubao didn't hide it, they're genuinely not SOTA here.
Honest and clear, true to ByteDance values 👍
Kaiyi's explanation for Seed 2.1 Pro's scores: "Seed's general capabilities are actually a bit better, it's not coding-specialized. If you tested deep research, data scraping, clicking around in browsers, Seed might beat GLM. GLM is coding-specialized."
That said, every model lab is going all-in on coding right now, and Seed's update also focused on task execution and programming. So let's stick to this programming test.
Across 10 test rounds, Seed 2.1 Pro produced 8 invalid processes — a 55.6% valid output hit rate. Still far above GLM 5.2's 3 invalids, Kimi's 2 invalids, and Step's 1 invalid, with other models having zero failed processes.
High call counts and frequent task failures pushed Seed 2.1 Pro's costs up too — 41.3 RMB total, second only to Opus 4.8 (202.5 RMB) and Kimi K2.7 Code (164.6 RMB), far above DS, Qwen, and MiniMax all around 20 RMB, and tied with GLM 5.2.
So with no discounts, calling directly from the Volcano Engine official site, Seed 2.1 Pro delivers notably poor cost-performance for programming tasks.
To visualize these models' completion speed, cost, and call counts, I also made a Funeral AI Benchmark Cost-Performance Ranking.
So beyond recognizing the strongest models, we can also show some love to the high-value ones ❤️
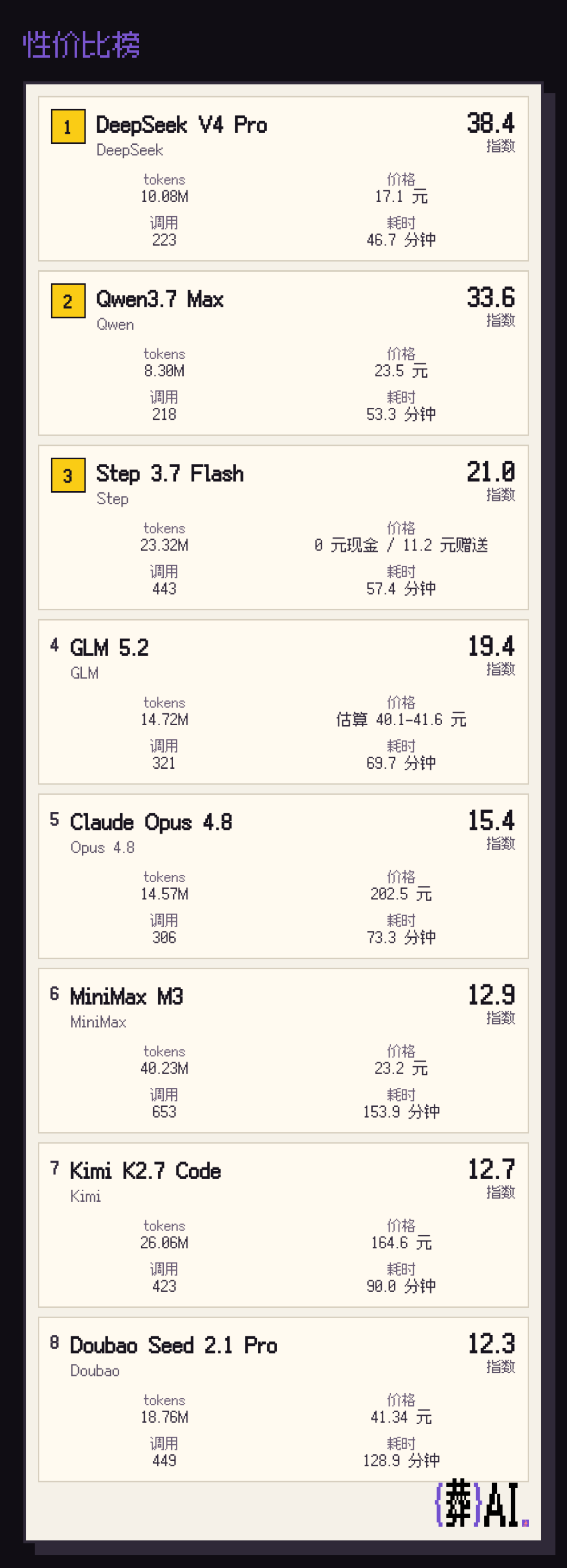
What's clear here: StepFun's Step 3.7 Flash model was a particularly pleasant surprise. It scored higher than DeepSeek V4 Pro, yet cost less than DS — completing the test for just 11.2 RMB, not even burning through the 15 RMB signup credit.
So after weighting call counts, time, and other dimensions, Step 3.7 Flash ranks #3 in cost-performance across all models.
The cost-performance ranking also vividly reveals a danger line: not only does the DeepSeek kill zone exist, there's a Claude kill zone too.
Being less cost-effective than Liang's saint is normal. But being less cost-effective than Claude is genuinely dangerous. And MiniMax M3, Kimi K2.7 Code, and Seed 2.1 Pro all scored below Opus 4.8 on the value index.
Step it up, folks at Kimi, MiniMax, and Seed — you gotta fight to escape the gravity of mediocrity 💪
I do believe in Seed, because I've never heard of Seed distilling. The hope of domestic AI rests on you.

Final disclaimer: the Funeral AI Benchmark still accepts no sponsorship.
This is a relatively objective programming capability evaluation. Both rankings and all test outputs are available in full detail at:
funeralai.cc/test
On Seed models specifically: tomorrow there's a subjective review by Luozi Ma, examining Seed 2.1 Pro's multimodal and general capabilities. Striving for combined subjective and objective coverage to help you really understand each model 🫰
(Cover image generated by ChatGPT, text 100% human-written)
⬇️
Subscribe to our Substack: funeralai.substack.com