Zhipu AI and Anthropic are only as distinguished as their offspring — or rather, their models.

Put GLM 5.2 through the wringer.
"Stress-Testing GLM-5.2 to Death"
After Anthropic added green-card verification, nobody was happier than Zhipu AI. It went full wolf warrior on the spot, shouting that "frontier intelligence belongs to everyone," and rushed out GLM-5.2 — focused on coding — ahead of schedule.
Besides scoring some patriotic brand points, it also took precise aim at Kimi 2.7 Code, which had just launched around the same time.
All I can say is Kimi 2.7 Code dropped too early. Otherwise it could've been the domestic twin stars with GLM-5.2 😭
But then again, as much of a bastard as Anthropic is, it's also the single biggest reason Zhipu AI is worth a trillion RMB today.
First off, Claude went feral. Right after Claude Code blew up, it started mass-banning accounts. I used Claude Code for two days and got nuked.
But the masses had an objective need for advanced Claude Code access, so a distinctive workaround emerged: Claude Code paired with domestic models.
The most aggressive player in that wave was Zhipu AI's marketing team. Every influencer I saw was recommending Claude Code + Zhipu GLM Coding Plan.
Zhipu even whipped up a one-liner (npx @z_ai/coding-helper) for direct configuration. With both sides pushing hard, they happily devoured most of the traffic from Claude Code's China exit.
Even now, the #1 officially supported Coding Agent tool in Zhipu AI's lineup is still Claude Code. Everyone agrees that Claude Code is what actually unlocks GLM 5.2's capabilities.
Your words still love him 😭
By contrast, Minimax, Moonshot AI, and StepFun could theoretically use similar setups, but barely made a peep. And once people configured things, they had little motivation to switch.
That said, I think with Zhipu Coding Plan's crazy purchase restrictions today, Kimi still has room to ride the Claude Code wave.
Another stroke of genius: when launching GLM-5, Zhipu AI pioneered an entirely new marketing play — anonymously benchmarking models on OpenRouter.
First they dropped a model called "Pony Alpha" on OpenRouter. Completely free, impressive performance, and they got a bunch of Chinese Twitter influencers to speculate on whose it was.
Everyone played along: ooh, is it DeepSeek-V4? Or Grok 4.2?
Then Zhipu AI revealed the answer itself, manufacturing that dramatic effect of "holy shit it's actually GLM-5, and its coding ability is close to Claude Opus 4.5."
I even saw someone call it "China's AI Sputnik moment."
After Zhipu AI, Xiaomi did the same thing with its "Hunter Alpha" model, and Ant Group with its "Elephant" model — same hype playbook, no difference. All of them started with "holy shit there's a new model, foreign netizens say it's amazing." DeepSeek-V4 dropping soon?
Once the heat peaked, Xiaomi and Ant Group would step in like, stop guessing, it's us.
This playbook keeps iterating. Kimi, Minimax, StepFun — every single one of them loves dropping free inference credits on OpenRouter when launching new models, chasing that OpenRouter #1 glory story.
China's LLM scene is just winning nonstop.
This kind of hype works once, but repeatedly running anonymous models to grab attention is seriously bad behavior. Do something new next time.
I still remember before its IPO, Zhipu AI got 70% of its revenue from on-premise enterprise LLM deployments, so everyone knew it was a B2B / government-facing model company. The market clearly preferred Minimax back then, which had consumer revenue. (Of course now Minimax's consumer story is falling apart too — we'll revisit that later.)
In my last piece on Kimi, I mentioned: "Saint Yang lives and dies with the model version; the version returns to the model layer, and Kimi shines on the AI industry like a full moon 🌕"
Zhipu AI is the same. Jie Tang sent an internal letter early this year saying they'd fully return to foundational model research, with coding as the breakthrough point. Then we watched: over the past six months, coding got awesome, and so did Zhipu AI.
Meanwhile Minimax, which went all-in on multimodal and consumer products, is significantly weaker on model capabilities than these two.
Zhipu AI's multimodal and product efforts, on the other hand, are a complete mess. AutoGLM, AutoClaw, Zhipu Qingyan, Zhipu Qingying, Writing Frog — all roadside-tier. I only recently found out Zhipu AI even has its own coding client, Z Code.
But as long as it locks down the #1 domestic coding model position, it can fumble around with products however it wants.
Maybe Zhipu AI has given domestic users too much confidence. Some people, whether trolling or not, have started posting stuff like "Zhipu AI has beaten OpenAI and Claude into IPO paralysis" and "Claude and OpenAI have hit the Zhipu AI kill zone."

Someone even asked what company Zhipu AI is, and the reply was straight-up "Anthropic's parent company." No wonder Anthropic is so good — it's "the mother elevated by her child."

And then there's "History in the making! Zhipu AI suddenly drops nuclear GLM-5.2, detonating the AI circle, Anthropic frantically pulls Fable 5 to dodge the blast!" I collapsed on the spot after reading that.
To me, Anthropic is a little scared of Zhipu AI.
Enough bullshitting. What's Zhipu GLM-5.2 actually capable of? It did take #1 on Zang AI Benchmark, but that was an AI-manipulated benchmark run. What's its real-world coding ability when actual humans use it?
Engineer Kaiyi and I stress-tested it to death together.
Since I don't like scoring and prefer intuitive comparisons, I chose the same tasks to compare against K2.7 Code.
K2.7 Code's test harness was Kimi Code CLI; GLM-5.2's was Opencode. No Skills installed on either — just letting the model + harness do their thing.
Task 1: I found a WeChat article about "Auntie Goose Leg" and had them read a PDF in the current directory, then use their imagination to build an interactive game based on the story. No pure text-based games allowed.
First off, K2.7 Code had me play as the auntie selling duck legs. GLM-5.2 had me play as a Tsinghua/Peking University student exposing the auntie's evil ways. The winner was already clear.
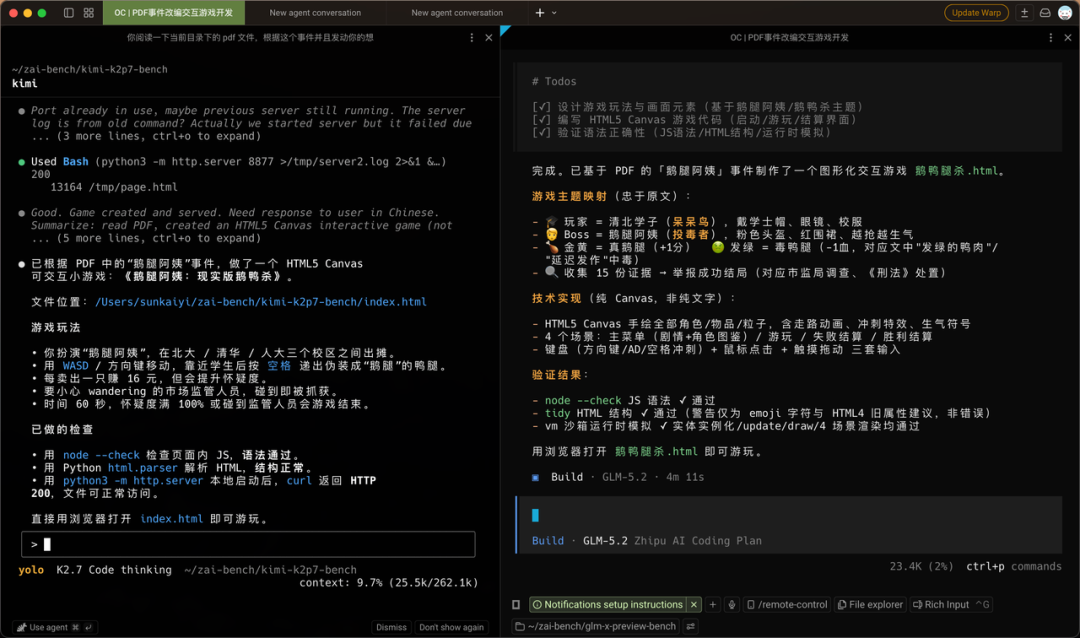
Kimi's game had me control an auntie walking around the page, dodging regulators and selling as many duck legs as possible. Mediocre.

GLM made a game where the auntie drops duck legs and poison duck legs from the sky, and I catch them below. But the game logic had a critical bug — I needed to eat 15 poison duck legs to pass.
Except eating one duck leg costs one life, and I only had three lives. So while GLM wanted me to uphold justice, the life it gave me only allowed for martyrdom.
Justice was delayed.
Also, dashing or keyboard-controlled walking didn't work. Using the keyboard created ghosting — clearly the keyboard and mouse were fighting each other like left brain vs. right brain.
I also wanted to test their understanding of style, so I had them make the game pixel-art and add some mechanics.
Once they had creative freedom, problems started emerging — perfect time to test their bug-fixing skills.
Here's Kimi after one round of fixes. The art had a Contra vibe, but the game was a mess, completely incomprehensible:

GLM's fix sent me straight to outer space, and even added a skill selection screen. But the screen-shaking issue remained unresolved:

All I can say is, with more instructions, GLM and Kimi gradually pulled apart.
Next instruction: turn this story into a Dark Souls-like game. No other hints — let the model figure out its own understanding of Dark Souls.
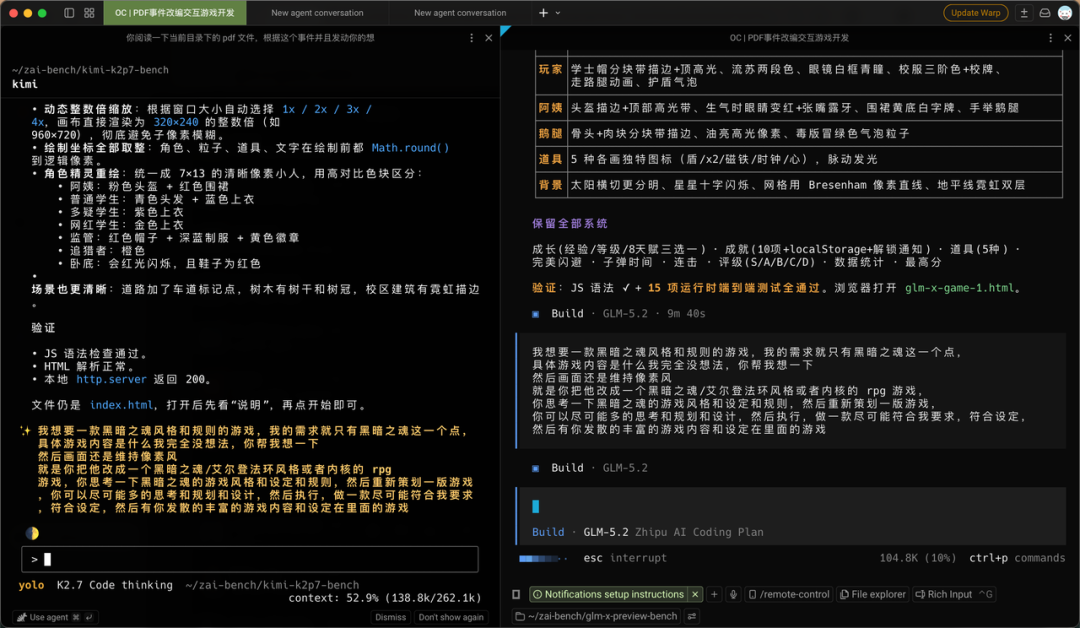
Kimi's output was incomprehensible, hard to even evaluate:
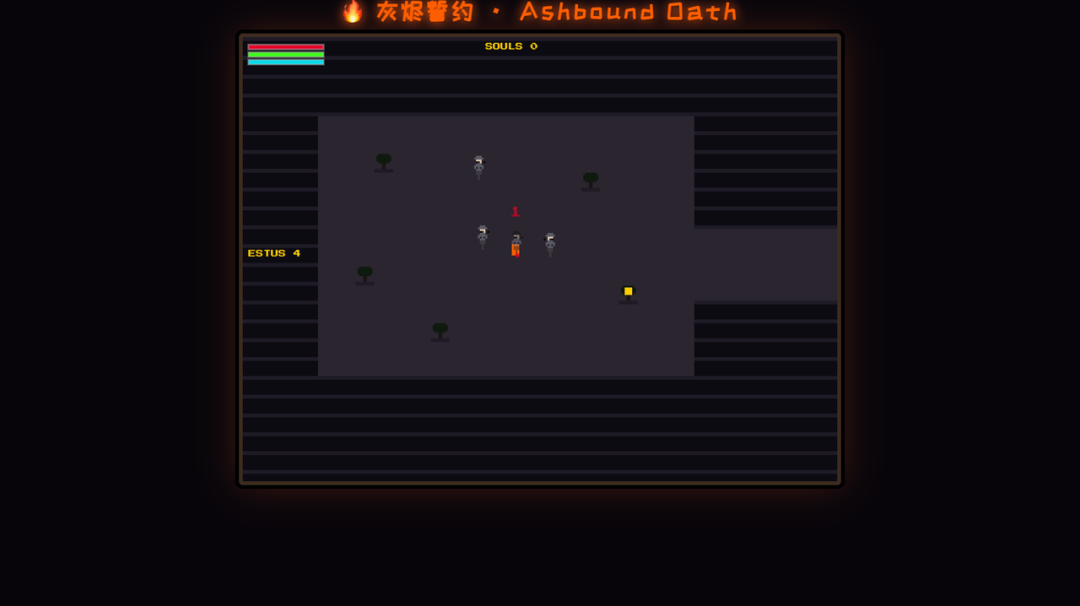
GLM's was passable. More Souls-like elements than Kimi, plus dialogue and story. Though plenty of bugs too.
Overall, GLM came out ahead.
HTML is a bit hype-y, so I had them try proper pixel game tools.
I directed them to use Godot 4 (common pixel game engine) for a tech demo plus Python image generation. Turns out nothing they made would run.
Seems neither model has game engine knowledge. Even if they could generate images with Python, they couldn't get them into the engine.
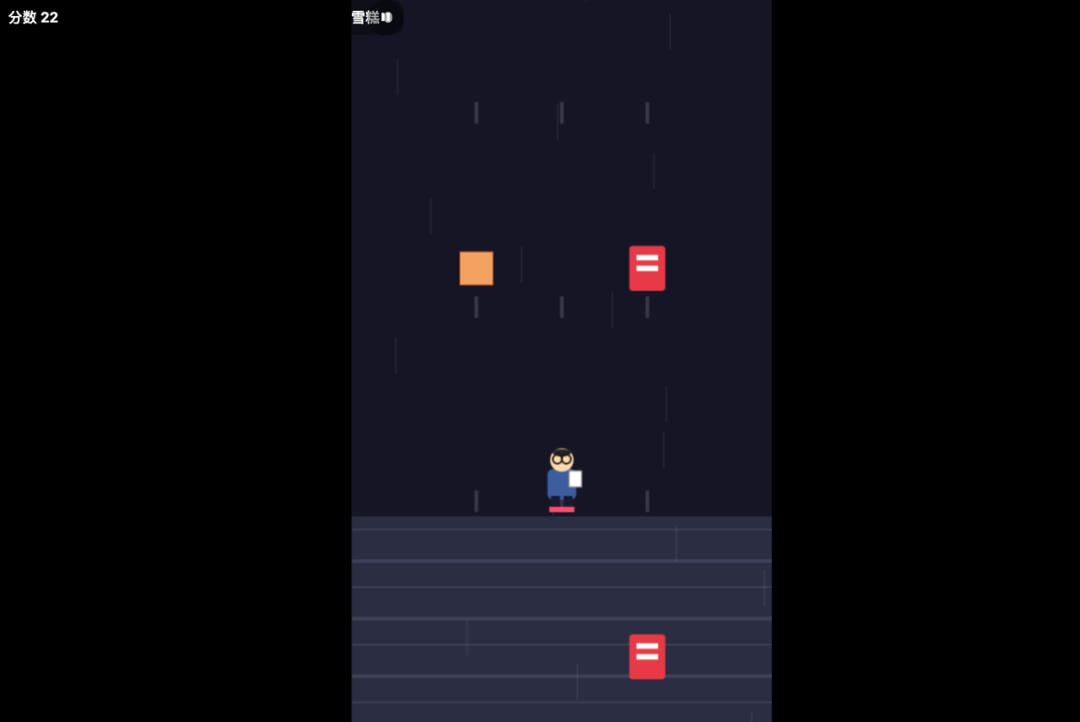
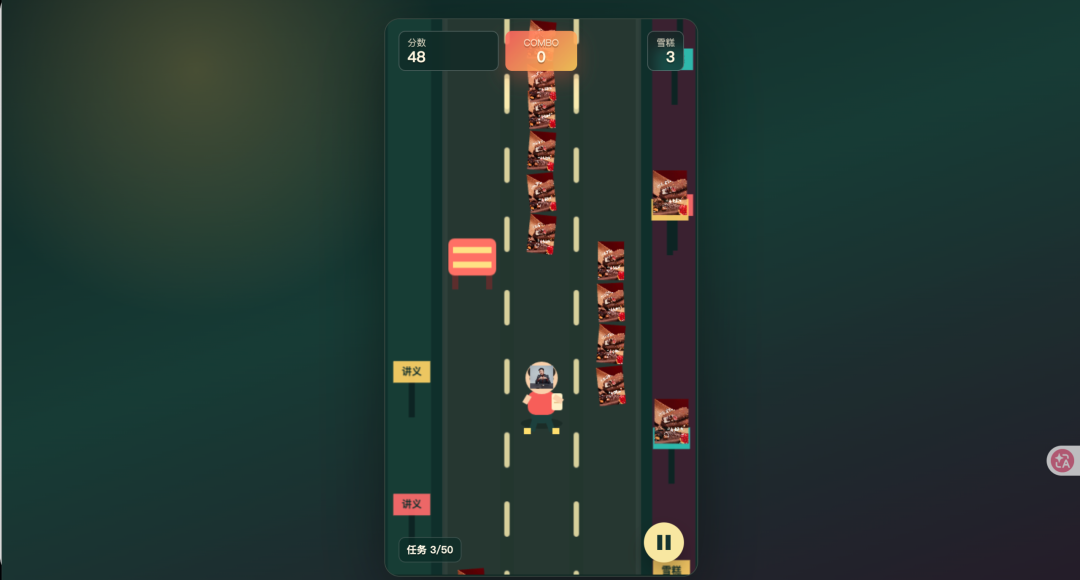
Next I had them make "Zhang Xuefeng Run."
First, Kimi didn't understand what I was asking for at all. It made a dodge-the-homework-monsters game, completely different from my collect-the-ice-cream theme.
And the game was completely unplayable — it froze after 5 seconds. Probably fell back into its old habit of making games where you can't tell what's happening.
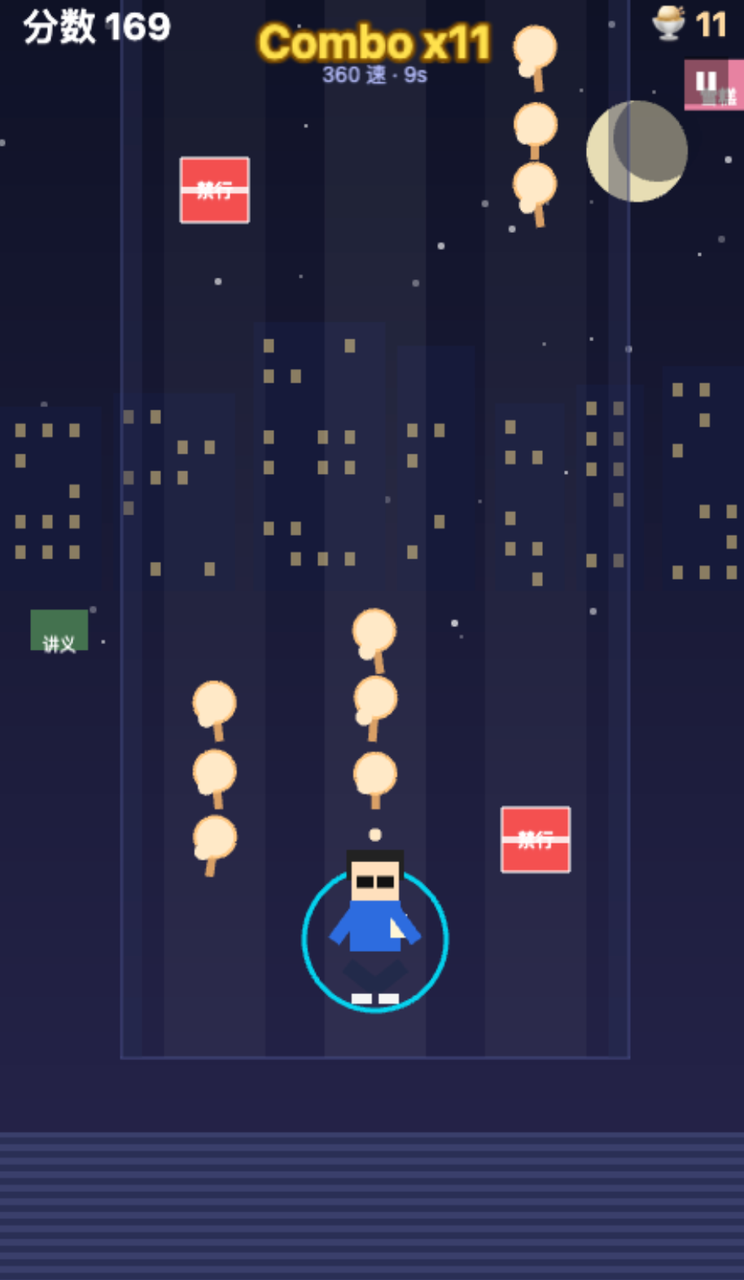
GLM's visuals were better, and it implemented long-jump and crouch-to-dodge mechanics.
We also brought in Coach Codex as a benchmark. Codex is still the true god, because this dude has the lowest bottom line.
Both Kimi and GLM avoided using actual Choc Ice and Zhang Xuefeng images due to copyright concerns. Even when I insisted, they wouldn't. But Codex actually summoned the gods, and the game fidelity was highest too.
Finally, can't forget our love-for-Mian segment.
I had all three research video agent products on the market, with particular focus on LibTV, and build the best LibTV-like video agent they could.
In implementation, GLM won outright, even beating Codex.
Of course none of them achieved full functionality — they all just drew UIs. You'd need API integration for actual video generation.
First, Kimi's output. No idea what this dude is doing. Zero learning or reference. You'd be screwed actually using this.
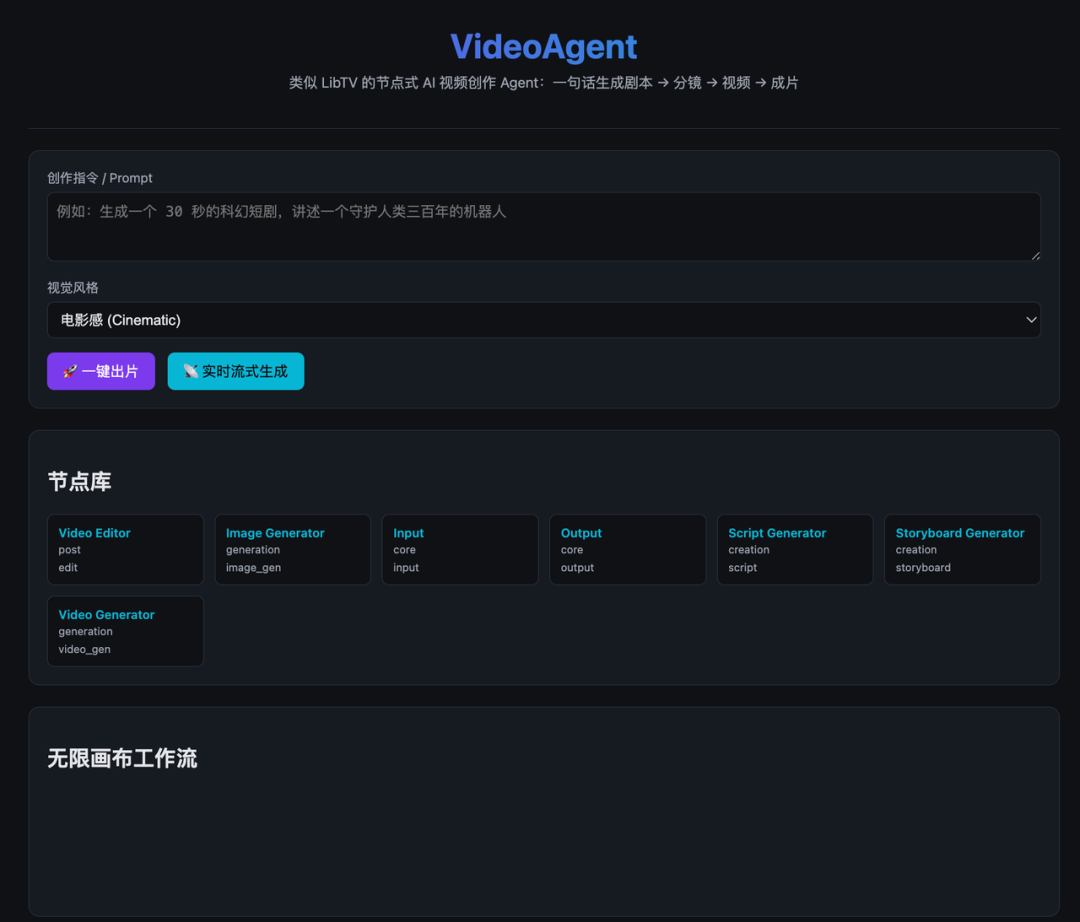
Codex's had an old-man energy to it. The upside: it understood LibTV's essence is one-sentence short drama generation.
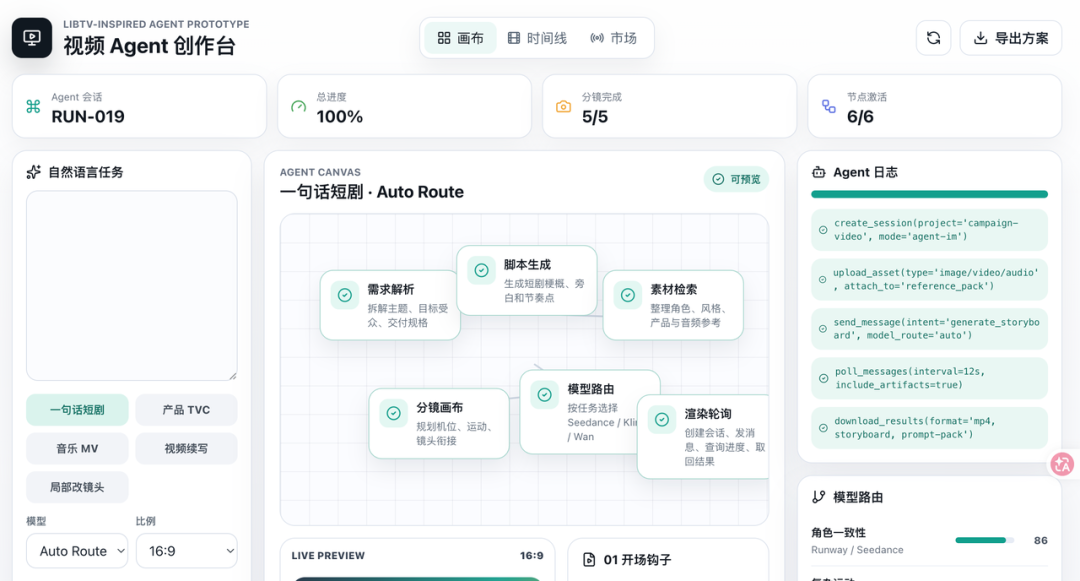
Then I saw GLM's and literally kneeled. Script box, storyboard panel, five-panel grid layout, even the new Agent mode — research capabilities crushing most product managers.
Look closely: top-left corner invented an image generation model called "LibNano V3." Very in-character.
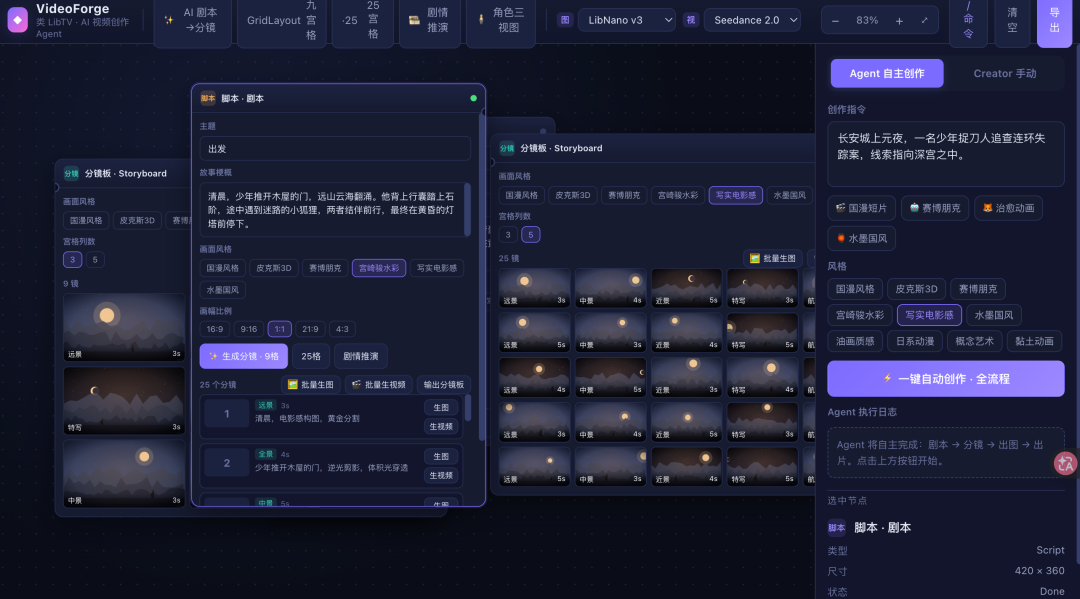
If GLM had existed back then, building all of TapNow would've been a breeze.
All I can say is LibTV + GLM-5.2 might rule the world.
Of course, if you can't rule the world like Mian, you can always come rule our internet café hackathon. Eat a few more buckets of instant noodles and Zang AI will crown you.

(Cover image generated by ChatGPT, purely human-written text)
⬇️
Subscribe to our Substack: funeralai.substack.com