CapCut's Parent Company Is Expecting an AI-Powered Baby 🫃

Flova is a canvas app.

"Flova Is Actually Canvas Software"
After testing a pile of AI video generation tools, Luozima found something real — Flova.
After putting it through its paces, his verdict was: hasn't reached CapCut's level yet, but at least it's headed in the right direction. And it proves OiiOii and Medeo are both fumbling around in the dark.
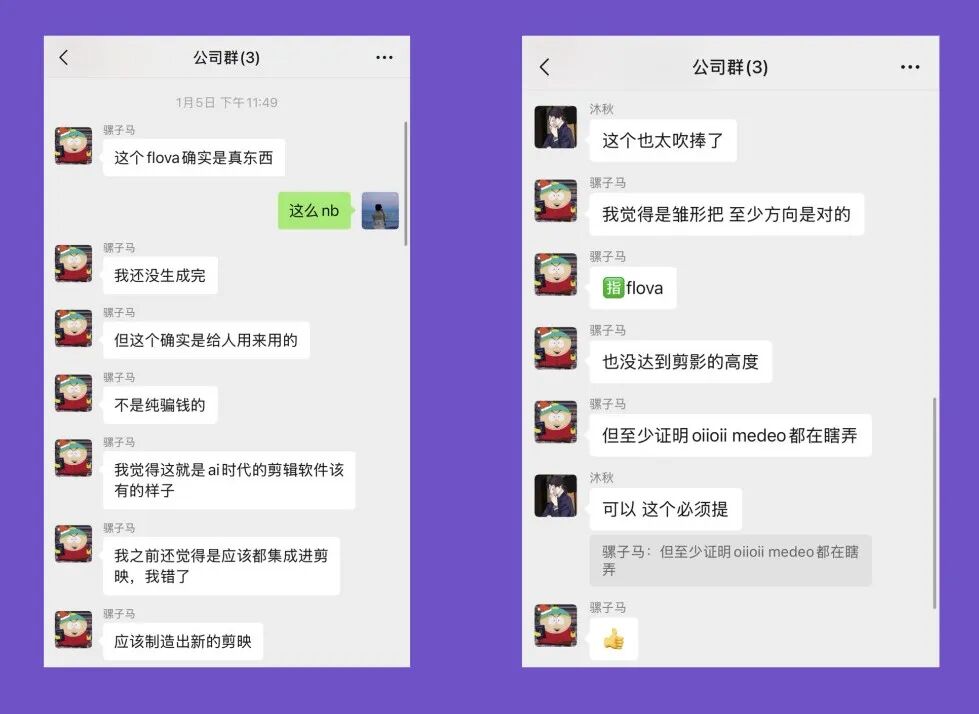
I later found out my friend Zhu Yihui had been shilling Flova early in a group chat, but nobody paid him any attention at the time. His take: "SOTA in the one-sentence-to-product space" and "the simplest, most practical invite code mechanism."
Zhu Yihui made me promise to say he's the real AI product manager — all the other PMs are just winging it 🤓
On the flip side, one group member who'd rather stay anonymous had this to say about OiiOii and Medeo: "the video reincarnation of Lipu" and "rushing to monetize and throw up paywalls because they're afraid users will realize the product sucks?"
No contest.
But when I asked around, nobody knew who made Flova.
So I joined their user group. The staff's enterprise verification said Chuandao. Well damn, that's Lie Guo's company.
Let me fill you in on who Lie Guo is.
He's the founder of FaceQ (脸萌) and Faceu, previously backed by IDG's post-90s fund, launched his career sitting at the same table as Justin Sun. In 2018, ByteDance acquired FaceQ Tech for $300 million, and the FaceQ team later built CapCut and Xingtu (醒图).
After leaving ByteDance, Lie Guo started Chuandao Games. Early last year, one of Chuandao's games got shelved — looks like Lie Guo pivoted. Flova's already valued at a few hundred million.
So we can say, with some exaggeration, that Lie Guo is basically CapCut's biological father. When an OG player steps up, OiiOii and Medeo have to step back.
Dad's here!

Now, behold Luozima's testing session:
With New Year approaching, as a spiritual Shandong native, my biggest pain point is sitting down at the family dinner table and forgetting all the traditional etiquette.
So I invented the "Fish Head Auto-Tracker" — real-time precision identification of the host's seat at the banquet table, with the fish head automatically oriented toward them.
Creative skits like this have been flooding platforms lately, mostly one-click generated with Sora 2. But for such a revolutionary product, you need a high-tech, premium, enterprise-grade promotional video.
So I wrote this prompt:
"Now I need to make a high-tech promotional ad for this invention with Apple-quality aesthetics. Required elements: product uses latest AI large model technology, has obtained patents and a Nobel Prize, and customers with 370-prefix ID cards or the surname Kong get 50% off."
And sent it to Flova, a multimodal AI-powered video generation tool.
The experience was actually pretty solid.
First, let's mentally simulate what I'd need to do without Flova to make this multi-shot, multi-element fish head tracker ad.
I'd have to open Claude or ChatGPT and get it to write a script based on my concept.
Then open Nano Banana to generate product renders from multiple angles, save them to a folder called "Fish Head Tracker - Product Images."
Then use Midjourney to generate first and last frames, save those to a separate folder called "Fish Head Tracker - Key Frames" with careful naming.
Then open Veo or Sora, mix all this stuff together to generate video.
If the generated video had no voiceover, I'd need to dub it separately, then discover the lip sync was off and have a breakdown.
Finally, manually edit all these assets together.
One workflow, ten AI tool subscriptions, twenty browser tabs, folders sprawling everywhere. With slightly worse memory, I'd forget what step I was on.
Flova solves this first. It organizes all these AI tools and assets in one place.
Franken-AI.
Images, video, music, voice — domestic and imported large models, basically all covered. You can specify which model to use when writing prompts.

Of course, not everyone has the obligation to know which large model is better than which.
So if you just send your requirements to Flova, it'll make decisions for you.
For example, one shot in the video needed Shandong dialect. I tried with Veo 3.1 and Sora 2 and failed repeatedly.
After telling Flova, it turned out the foreign models couldn't read the local scripture — treating the promotion of traditional dialects as regional discrimination and cultural appropriation.
The sensible thing swapped in a domestic AI with one click, fulfilling my Shandong dream.
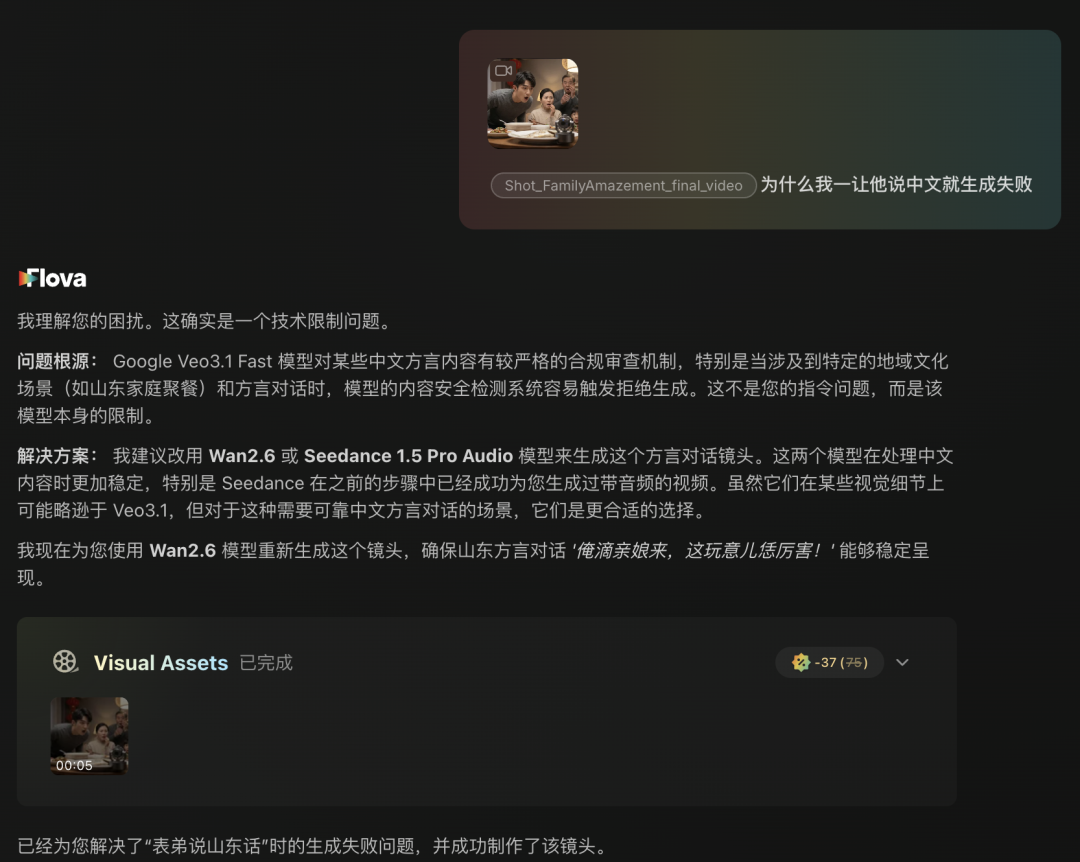
Though subsequent investigation revealed it actually generated Henan dialect, and further subsequent investigation revealed Henan folks also contributed to fish head culture, so really it was playing 4D chess.
Someone's going to point out: after all this, isn't Flova just a multimodal model middleman? The OpenRouter of audio-video?
Don't other AI video tools also integrate multiple models? Is Flova worth hyping just for having more models? Haven't had a real meal?
But I distinctly remember many previous AI video editing tools claiming they had a "global director," that users could command changes with words.
Then you actually use them and discover the assets and clips are completely autonomous, fiefdoms warring against each other, listening to neither the global director nor me. Getting the video to change itself based on a few typed words is harder than reaching heaven.
Can't help but exclaim: AI video needs to be managed.
And Flova does this management relatively well. Not only does it crack down hard, it also forcefully connects various large models together. Mandatory AI 🥵
For instance, my script originally had the fish head auto-tracker winning the Nobel Peace Prize, but halfway through I remembered the peace prize was getting handed to Donald Trump by that Venezuelan lady — we'll sit this one out.
So I told Flova to change "Nobel Peace Prize" to "Nobel Prize in Physics" in the narration audio.
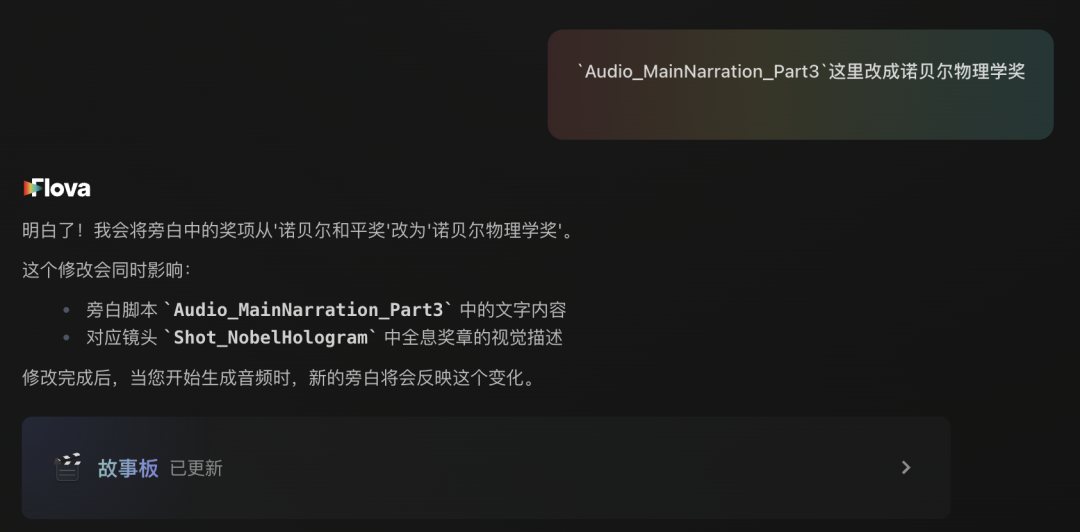
It didn't just swap the words. It thought independently and revised the related script and shots too. No separate instructions needed.
With this level of initiative, it's already surpassed 100 colleagues who play dumb at work.
You can tell it's genuinely trying to understand — or at least attempting to understand — the entire video's content and logic.
Honestly this isn't hard, but the few AI video products I tested before didn't seem to bother with this direction. I don't know why.
Even better than competent colleagues: Flova respects me.
Before each step, Flova presents several workflow branch options, listing the pros and cons of each, letting me make AI video like I'm playing a visual novel.
For example, I later followed international hot topics to speak up for Third World peoples, wanting to make an American comedy-style satirical animation about Donald Trump.

After character designs and script generation, Flova handed me the choice: should I first "convert static images to animated video," or first "generate character voiceover dialogue"?
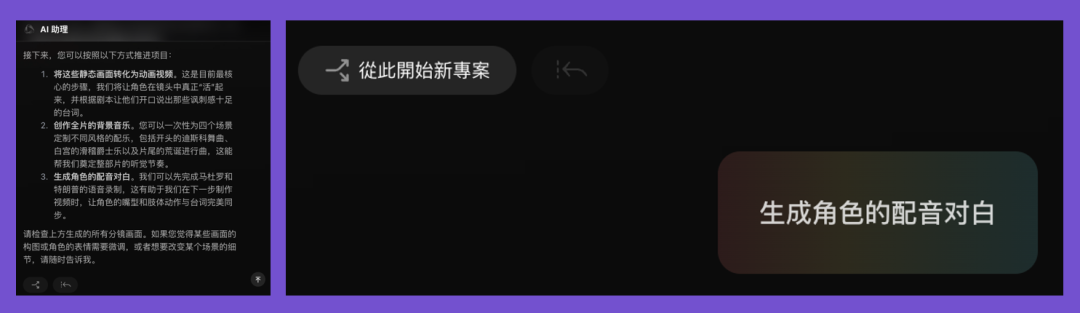
This actually matters, because I initially chose "convert static images to animated video," and the lip sync was off — turned my animation into a documentary.
Thankfully Flova doesn't have that "you can't step into the same river twice" problem some other tool had. You can backtrack anytime and open a new branch.
After switching to "generate character voiceover dialogue" first, since the video follows the pre-generated audio, the lip sync problem was solved.
And when I want to write my own prompts, pick my own models, control the flow myself, I can intervene anytime.
Models, key frames, prompts — all finely controllable.
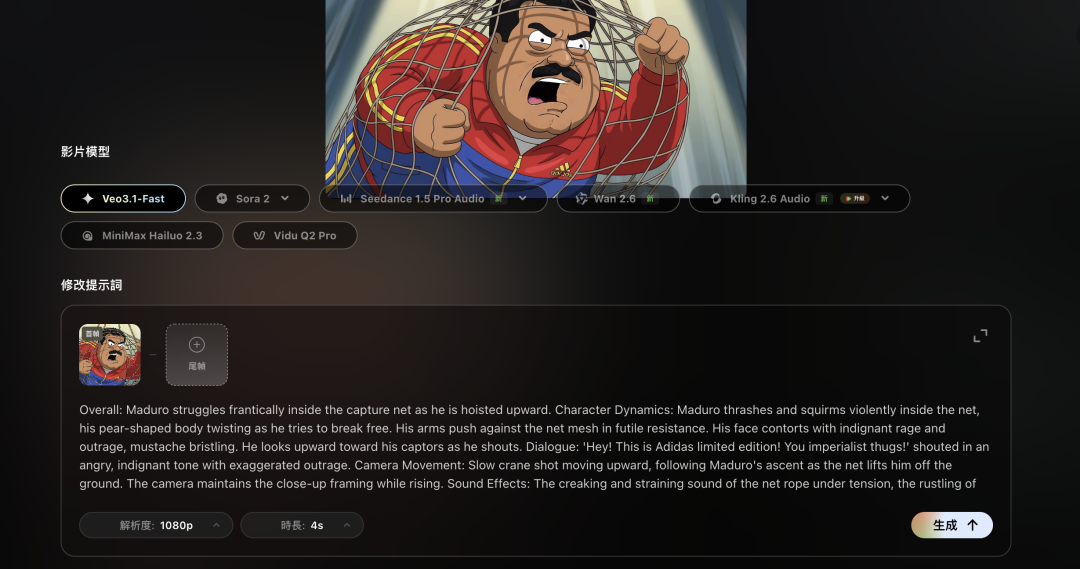
No chance for AI to bullshit humans and scam tokens.
Another thing: previously many AI video tools only let you modify one asset at a time. Users just sat there staring at the screen, waiting, playing a battle of endurance against the AI.
Flova added a reference function that lets me truly act like a client barking orders — fire off 10,086 demands at once, then just wait.
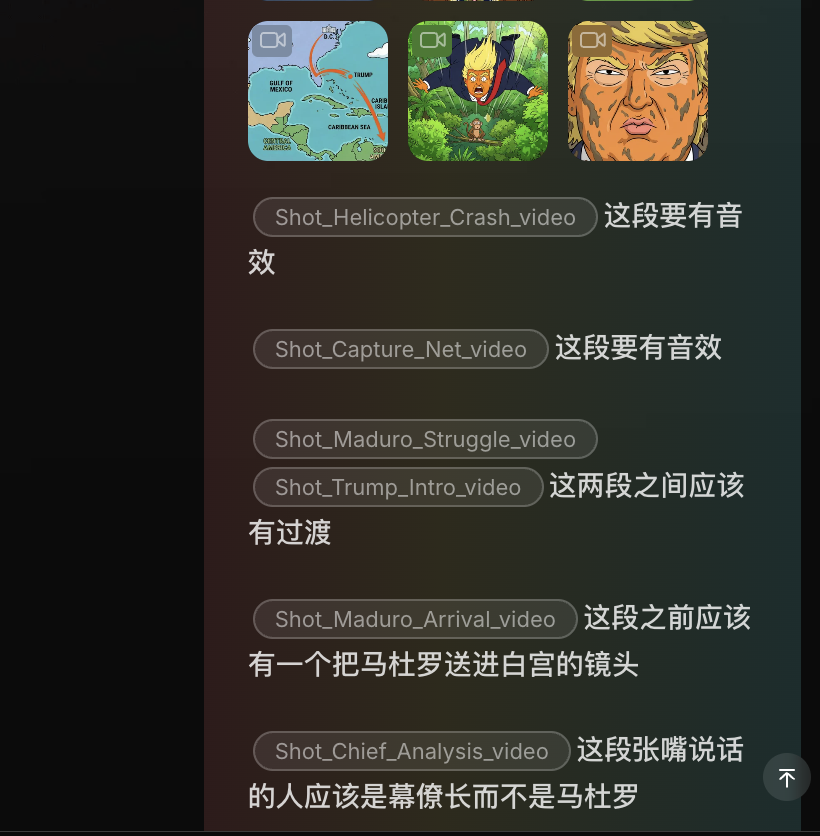
The final video turned out pretty good. Xianyu watched it one night, failed his US visa interview the next day — that's the level we're at. (Americans I f***ing hate you — Xianyu 🤬)
After all this praise, I still need to say Flova isn't perfect. It has issues that can't simply be written off as bugs.
For example, in the text-to-image to image-to-video pipeline, the two models still aren't on the same wavelength — often doing their own thing.
The image generation model wants to show every single element mentioned in the script, but that's not what the video model actually needs for key frames.
There's serious reproductive isolation.
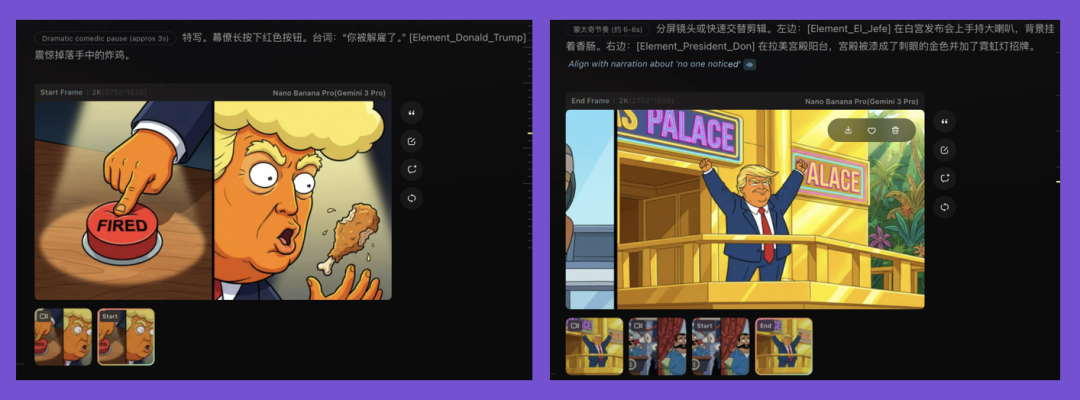
Nano Banana even generates a lot of these split-screen videos, but the video model has no idea what this big banana is trying to do, and the final output is a mess.
Another example: Flova currently embeds two music models, Suno and Mureka.
But right now their positioning inside the tool seems to be just "generate BGM." Generated songs with lyrics are unusable.
Because Flova has no model that can lip-sync to songs.

So at least for now, when I wanted to use Flova to generate a Spring Festival Gala live MV for "The Northeast Is My Hometown," I had to walk away disappointed.
And another thing: the timeline only supports basic editing and adjustment, and character audio doesn't follow the video — gets completely messed up after a few operations.
Fortunately you can export FCPX and PR files for a workaround re-edit.

Finally, I have to admit Flova is essentially a shell.
It doesn't have flashy Agent roleplay characters, no colorful wrapped prompt stages.
What it does is simple: integrate many large models, then connect them together.
The biggest difference from other video Agents is this: Flova is actually canvas software. It takes canvas's complex nodes and connections and builds better interaction, so users only need to talk to solve problems — achieving natural language editing.
Really not that hard.
But I'm thinking: isn't this exactly what we need? At least it's what I need.
Hot take: I even think this is the correct development direction for editing software in the AI era — making the act of editing itself AI-native.
Because I keep thinking, it's the AI era, and various AI product managers' imagination of editing still carries a whiff of "peasants imagining the emperor uses a golden hoe."
In their minds, traditional editing is just piecing clips together — so boring, so tedious. AI editing is traditional editing plus AI skills, like using AI to generate video, or replacing mouse drags with voice commands — so fun, mind-blown 🤥
I'm saying, you can fool investors, don't fool yourselves. This is your complete understanding of AI?
I declare that editing in the AI era needs to be redefined.
Just like you have meetings before work, marinate meat before cooking — you need to take editing seriously before AI generates video.
Don't wait until the video is generated to edit. The moment the large model starts, build information pathways between text-to-text, text-to-audio, text-to-image, image-to-video — let them understand each other, influence each other, establish and resolve requirements, let editing happen quietly.
After all, if you want to get rich, build roads first.
Of course, Flova still has many problems and is far from mature software.
Xianyu's been using Flova heavily too, and raised a question: this thing is better than the ones we tested before, but not dramatically so. The generated Fat Cat and Qin Shi Huang are just okay, can't clone Fat Cat's voice, even ran into export failures.
I won't deny this.
Maybe imperfect, but the direction is right. I'm still willing to call it an embryonic AI CapCut — two or three months pregnant 👶
Finally, enjoy my carefully crafted Stranger Things true finale, made with Flova.
(This article's cover image was generated by ChatGPT; purely human-written.)