Flova and TapNow embrace back to back.

Making AI Videos Like You're Doing Hate-Sex

"Making AI Videos Like You're Making Hate"
The Seedance 2.0 integration competition just kicked off, and every video agent with any clout has become a ByteDance middleman and taken off overnight.
OiiOii stopped begging for the Sora2 API. Libtv went on a spending spree to celebrate its Seedance 2.0 integration. Even low-key Flova couldn't resist jumping into the hype, implying that CapCut's tech lead Xuezhi Wang and product lead Xiaoran Zhang had already joined them.
Why leave ByteDance in the first place if it was going to come to this? My suggestion: Dreamina should just allocate quotas to Naonao, Chen Mian, and Lie Guo based on whatever rank they held at ByteDance.
I went back to try Flova again, which I'd previously praised. I'd said it was pregnant with a baby CapCut prototype, so now I had to check if it had burst out of the womb.
Turns out they're hilarious. They insist they've integrated some video model that can do comprehensive reference, motion imitation, and doubled duration — looks exactly like Seedance 2.0 — but whether due to NDAs or something, they stubbornly named it StarDawn 2.0. I was stunned, thinking they'd mastered core distillation technology or something.
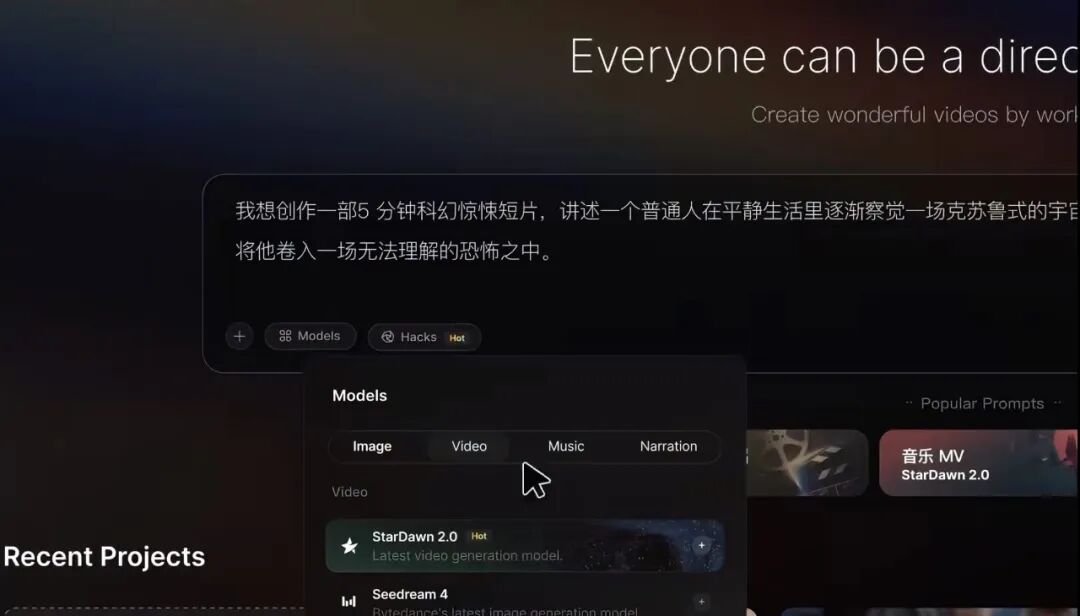
Only in the last couple days did they use find-and-replace to change the name to Seedance 2.0
So I started by trying to make a Magpie Murders-style opening for a North Korean propaganda film, planning to dedicate it to the General during our North Korea trip later this month.
Flova with Seedance 2.0's reference feature really does push the core selling point of "no prompt writing needed." I just send it a video I came across plus a one-sentence idea, and it automatically starts analyzing the style.
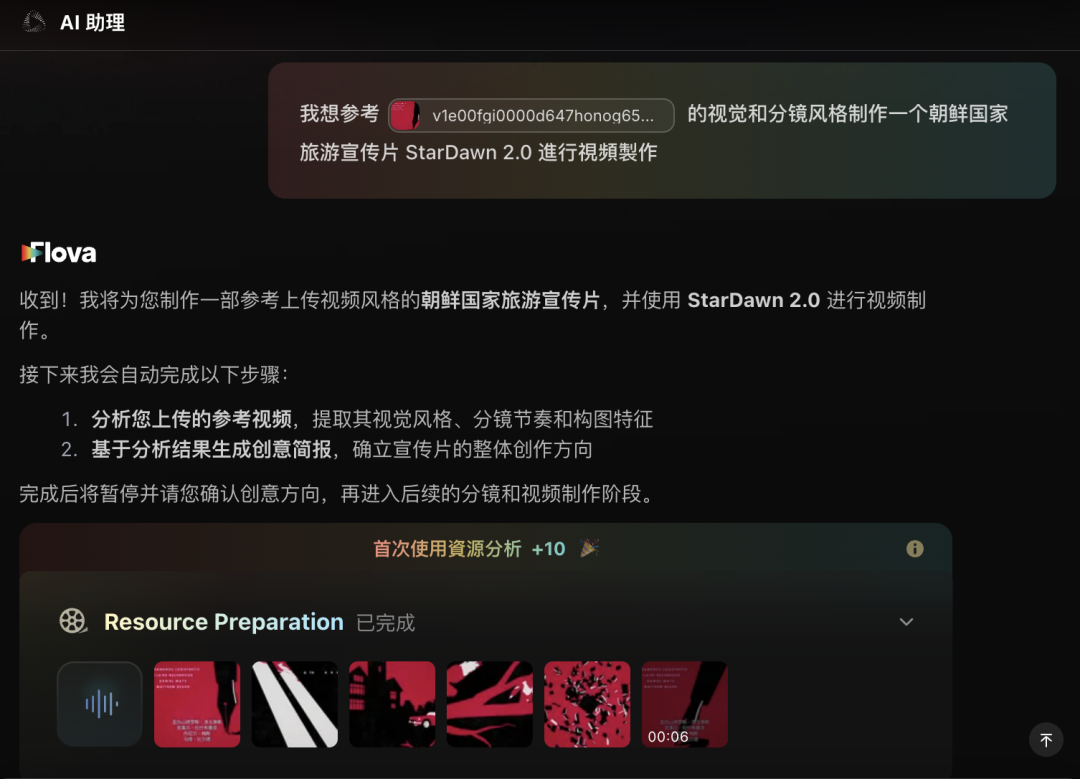
And for actual film planning, where I used to have to type, now it just gives me a few rounds of binary choices — making AI videos as easy as playing a visual novel.

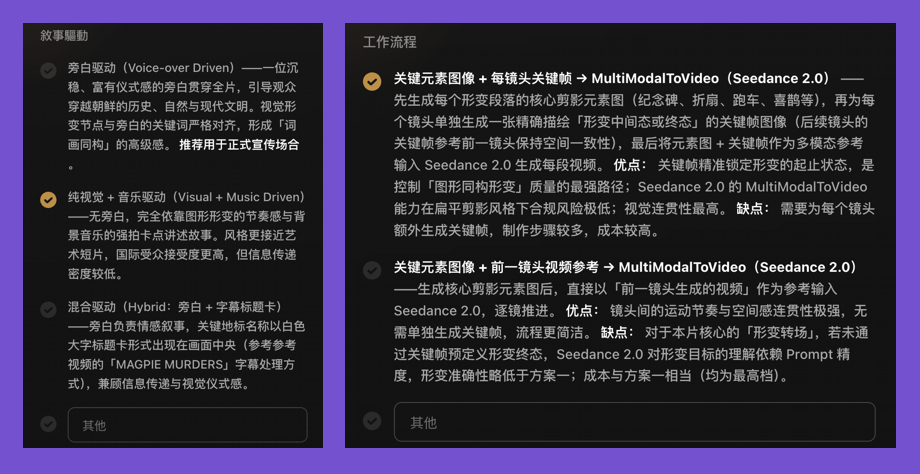
Which landmarks appear, how to smoothly transition between two shots — it basically figures all that out independently. I just do some minor work.
Here's the final video. No idea what the Korean at the end means, but it feels right.
Done with animation, time to try live-action. Riding the recent wave of "compressing your coworkers into skills," I made a sub-ten-second horror short.
Eh, not particularly scary, but you can basically follow the core plot and the intended horror beats. It works as a finished piece.
But when I asked Flova to make a 30-second mid-length video, things went sideways.
The plot I had in mind was simple: entirely first-person perspective, the protagonist filming a farewell vlog for a coworker, following them out the company gates only to discover they've been thrown into a distillation factory where evil capitalists recycle them into skills for secondary use. Kind of like The Promised Neverland.
But using Flova, I ran into three serious problems.
First, spatial relationships only serve individual shots, with no overall planning.
For example, the protagonist sticks their head through the floor to look, and the next shot shows a ceiling — it's an upside-down world.
Understandable, I guess. In Flova's workflow, it just generates a few isolated flat images for scenes the story needs. It's not building a virtual studio with 3D modeling.
Second, when generating video, it fails to incorporate the story's basic setup as part of the visual prompts.
I said the protagonist sneaks into the factory and secretly films with their phone. But many shots were either third-person CCTV documentary angles, or close-ups of humanoid robot faces. It felt like the protagonist was personally inspecting the factory.
Third, multiple shot sequences are often joined together awkwardly, giving the final video a stock-footage feel.
I told Flova the video needed three things: coworker gets captured, coworker gets compressed into a SKILL, coworker.skill gets installed on company computers.
And it did generate clear shots for Event A, Event B, and Event C.
But the transition from seeing Event A to seeing Event B — turning a head, walking, or saying to the screen "let's go check that out" — none of that exists. You have to add it manually.
Fortunately these three problems aren't very noticeable in short, punchy production workflows, so I didn't suffer much making the North Korean propaganda film and the horror short.
Flova probably realizes this too, since their recent events basically encourage people to make more one-sentence-generated short videos.

The opposite of Flova is TapNow.
First, while Flova invites users to make 3-shot videos for social media, TapNow hosted an animation hackathon requiring 36 straight hours of rerolling, launched an AI video generation competition where even the teaser had to be 1–3 minutes, and their homepage and external promotions all feature cinematic mid-length video creations.

Second, Flova's interaction is basically all conversational. TapNow's interface is a canvas, like opening 100 folders.
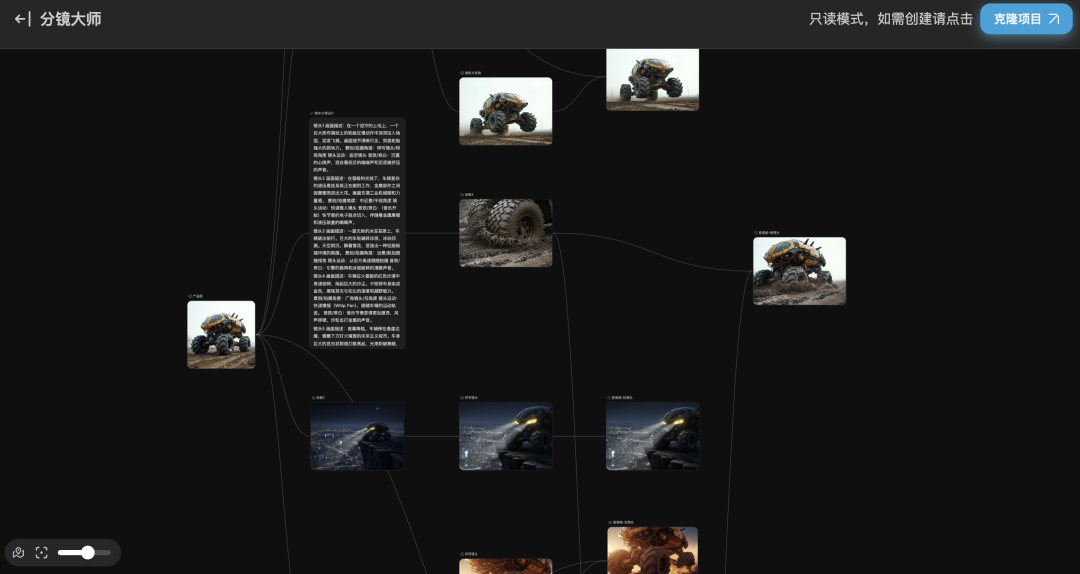
This is just a template, honestly. The canvas looks more complicated than the After Effects interface. Anyone who can figure out this interface doesn't need AI to make videos.
Based on these two points, TapNow does generate precise, high-quality videos with real texture. Flova generates chaotic, almost-there videos.
In the current AI video generation space, you could say TapNow is a professional precision instrument, while Flova is more like a toy.
I was chatting with Muqiu about video agents, and he said the canvas is the meta right now. That's probably industry consensus.
But even so, I absolutely hate the canvas and avoid TapNow as much as possible.
Because the essence of any video agent is the canvas. AI video generation is always text-to-image to image-to-video, a few steps like that. They definitely have some massive canvas running silently in the backend. The only product difference is how much of that canvas you hide from users, how much you draw for them.
With TapNow? The canvas IS the essence. That's not some great invention.
In other words, with enough patience, time, and energy, if you create 100 nested folders on your computer, then open Gemini and Dreamina, you've basically hand-crafted a canvas.
That's all TapNow really did — the UI for this canvas. Personally, I don't feel like they put much thought into the design.
Look at how complex this canvas is, my computer would crash just opening it. I'm exhausted just looking at it, completely unmotivated to continue.

So I have to be some contemporary film master to become an AI video master?
What can I say? I'm not some contemporary film master. I'm a dumbass who can't even understand the canvas.
You don't actually think that before AI technology existed, the only thing stopping me from making a movie was budget, right? Obviously there's also my impoverished aesthetic knowledge and video production skills.
You can't just swap the camera and full lighting kit for a computer that can log onto TapNow's website, reshape the storyboard into a canvas, and translate batteries and film reels into tokens, then claim there are no more barriers to visualizing creativity.
Broadly speaking, this is even a kind of arrogance. Assuming consumers should work to adapt to the product rather than the reverse — even a great product will get eliminated this way.
In the 1980s and 90s, Japanese point-and-shoot cameras swept the globe because they were simple and easy to use. Leica, which had always gone high-end and pretentious, nearly went bankrupt and had to partner with Minolta to release rebadged products.
Note that at this point they didn't send out some PR executive to educate users that sure, point-and-shoots are nice, but our manual mechanical cameras are the BEST for precise exposure, the most film-efficient, no rerolling needed.
Right? Doesn't matter what they said. This was Leica. Do canvas-type products have Leica's product strength and user loyalty? Can you handle the foolproof products that'll show up later, even if they're less precise but more accessible?
For us dumbass users, if a product has a learning curve, it's trash on the sidewalk.
No obligation to learn.jpg
That's also why CapCut is greater than Premiere. Premiere can do advanced effects, can import 16K 240fps footage, whatever — I drag one effect over, and the old lady at the village entrance has already posted ten Douyins.
Oh, speaking of rerolling, many people mention one big advantage of canvas products like TapNow: saving tokens.
The truth is, using TapNow burns double tokens. Before the AI burns them, your human brain burns them too. The time spent studying that canvas is enough for you to earn two months of membership doing manual labor.
Don't undervalue your own energy. Human tokens are tokens too.
Of course, roasting TapNow across a whole screen doesn't mean Flova wins.
From my purely personal perspective, video agents basically have two development directions right now.
One is copying TapNow, committed to building bigger, fuller, more infinite super-canvases, then racing other canvases to see who integrates Seedance 8.0 faster.
The other is Flova's path, taking the ignorance-is-strength route, letting users ignore how prompts are written, not think about scripts or models, using user feel as the moat. (Muqiu also sincerely suggested that after Lovart finishes TapNow, they could casually make a Flova too.)
Yet right now, the former's user experience makes me want to die, and the latter's finished videos make me not want to live.
So I've decided to wait. Like how I couldn't figure out driving and now we have autonomous vehicles. Like how I missed the coding bootcamp wave and now we're vibecoding.
I'm going to stand right here and roast both of your companies every day, until TapNow makes its interaction and operation friendly to dumbass users like me, until Flova can understand my dream-logic instructions — then I'll start using you for AI video.
Until then, using you to make AI is like making hate — painfully uncomfortable.
(This article's cover image was generated by ChatGPT; purely human-written)
⬇️
Subscribe to our Substack
funeralai.substack.com