Moonshot AI watches the sky and begs for food

The Chosen One of the Patch *(gaming slang: a character, build, or strategy that is disproportionately powerful in a particular game update/version, often used metaphorically to describe someone or something that is perfectly positioned to succeed under current conditions)*

"The Chosen One of This Meta"
"Comrades and friends, the meta's swung back!
Here's the situation: the AI application folks are out of moves. The scales of victory have once again tipped toward the foundation model companies. In light of this, we're bringing back our tribute series from a year ago, when we eulogized AI — writing up every model company one by one.
First up is our dear Kimi, the chosen one whose radiance shines upon China's AI industry like moonlight. Stay tuned for the rest 😘"
Basking in the glow of its funding, Kimi has been shipping products with the force of a flash flood. Kimi Code has achieved daily releases — a programming CLI that pushes updates every single day. Though seemingly few people actually use it; the "third-party programming CLI" slot is occupied by Opencode and the recently buzzy Pi coding agent. Kimi's agent cluster is solid too — in absolute quality, it can't match your old-school vibe coding where you feed a bunch of inputs into Codex and hand-craft everything, but it wins on convenience and brute force. Just one or two interactions, plus one-click deployment. Probably the most capable agent service available to ordinary Chinese users with zero technical barrier. They even suddenly dropped a plugin, Kimi WebBridge, that lets your local agent call Google Chrome, with no product restrictions — any agent can use it.
At first I thought Kimi had grown a conscience, sworn to build a bunch of useful little tools to give back to society.
Until a couple days ago, when I saw Kimi Work — Kimi's own Codex client, a local agent product that can also switch to cloud tasks. All those tools I mentioned are bundled inside it.
Some VCs are drooling with envy, going so far as to claim they were "the first institution to issue a TS for the A1 round." By that logic, as long as your qualifiers are long enough and your rounds subdivided finely enough, everyone's first.

Kimi's marketing and branding is also very much on point. They were first to partner with Manner, opening minds and inspiring a wave of programming tools like Trae to follow suit and "drink coffee"; for the recent World Cup they went all-in on advertising, not only launching a betting feature (token-based) but even boldly predicting Germany would win against the wind.

Regardless of Germany's final standing, Kimi has captured mindshare during the World Cup. The cost-effectiveness absolutely crushes Xiaohongshu shelling out real money for broadcast rights to treat HUPU bros to watch matches. Gone are the days of the absurd stunt where they rounded up a bunch of students to shoot B站 short dramas for ad spend, force-feeding "digital pickled vegetables" to the fam. It feels like the marketing department hired a hype sage who's seen the world, perfectly suited to Kimi's current script as a dragon-king son-in-law. Let me quote a celebrity to express my feelings:
"Please, Saint Yang, we're winning too much, we can't take it. Before you came, we doing foundation models had gotten used to losing. But now we're winning too much. We really can't handle it anymore 👋😭👋"
You have to understand, earlier this year, on the eve of Zhipu AI and MiniMax's IPOs, market sentiment was against Kimi. So at the time, Saint Yang still needed to emphasize that the new round raised $500 million, "more than the vast majority of IPO fundraises," so there was no rush to go public in the short term.
Market sentiment really does shift fast, leaving everyone who didn't get on the foundation model train behind the meta.
When Zhipu AI and MiniMax went public, I was still suggesting the "Six Little Tigers" merge to achieve an ecological monopoly at the model layer, and my suggested valuation was only 500 billion yuan — less than Zhipu AI alone is worth now.
Looking back, that's when I diverged from market sentiment.
The main theme of H1 2026 is foundation models are great. Model capabilities haven't dramatically changed; it's mainly the products model companies have built — Claude Code and Codex gradually penetrating the consumer market, driving the rebrand from "vibe coding" to "vibe working."
A clear trend is that programming agents can now handle all general tasks, and AI programming tools are becoming the engine of the networked world.
This passage is actually from my early-year piece AI Programming Creates the World, but I truly failed to walk the talk, not going all-in on Zhipu AI stock despite its programming focus, revealing my disloyalty and dishonesty to AGI 😭
I digress. Back to Kimi. Its inflection point roughly started with those two IPOs too.
A few days ago, our dear Elsewhere was still looking back at that $4.3 billion valuation round from late 2025. In a couple days the news became Kimi's latest valuation is being called at $30 billion.
What happened in these six months?
On the substance side, Claude broke through on programming capability, driving foundation models to generalize from coding to general competence. This expanded real-world applications from writing code to all white-collar work.
So we see ByteDance going hard on Trae, Alibaba betting big on Qoder, and everyone launching their own Codex client aka "agent pure-enjoyment" products.
On the market side, 2026 is the craziest IPO year in history. SpaceX, Anthropic, and OpenAI — three trillion-dollar companies going public, and all three call themselves AI companies.
By the classic AI project 1/10 valuation method, Anthropic and OpenAI should benchmark at $100 billion, and unless a financial crisis suddenly erupts, there's no reason these two should drop post-IPO.
So Kimi, Zhipu AI, and others still have massive room to rise. 2026 truly is the year foundation models became great.
The models themselves never changed; only market sentiment did. I quite like this passage from the evil Anthropic boss Dario:
"Every few months, public sentiment either becomes convinced that AI has hit a wall, or gets excited about some new breakthrough that will fundamentally change the game. But the reality is that behind the volatility and public speculation, AI's cognitive abilities have been improving steadily and relentlessly."
A basic fact: over the past six months, leading model capabilities haven't improved dramatically, but domestic models have patched their weaknesses quickly.
Specifically, Claude going from 4.6 to 4.8 barely counts as improvement — Fable 5, I found two problems within minutes of using it, and then my quota ran out. Meanwhile DeepSeek, Qwen, Kimi, and Zhipu AI all optimized tool use and long-horizon task capabilities, reaching a level fully adequate for daily work.
That's been my experience. I even downgraded my Claude membership to the entry tier. For daily tasks I use Opencode with DS, Qwen, and Kimi on rotation, and haven't run into bugs.
Given I'm not doing complex engineering tasks, I don't feel any substantive difference between these domestic models — they're all sufficient.
If I had to name a K2.6 characteristic, it's that the chain-of-thought is excessively detailed, constantly vomiting reasoning process, with the final output also being a wall of text — not concise enough.
When I use K2.6 for calculations, what I say most often is asking it to trim the response, otherwise I can't make sense of it. Using the same Opencode integration, DS and Qwen don't have this problem.
Another issue: I interact with agents entirely by voice. K2.6 is the only one that fails to recognize the three names of the Funeral AI team. I'll admit I don't distinguish front and back nasals, but other models all correct themselves based on project docs — only K2.6 insists on calling me "Xixiangyu," which is a bit much.
But whatever, the results K2.6 generates are correct, so this is all style preference. Maybe some people actually prefer AI generating more.
For instance, I saw someone suggest that if you want to quickly bullshit your boss, recommend Kimi Code, because this thing can rapidly spit out a massive pile — quantity over quality.
Below is Qwen's benchmark. What's easy to see: except for models lacking vision capabilities, these domestic models are all at roughly the same programming level, not far behind Claude, with small gaps between each other.
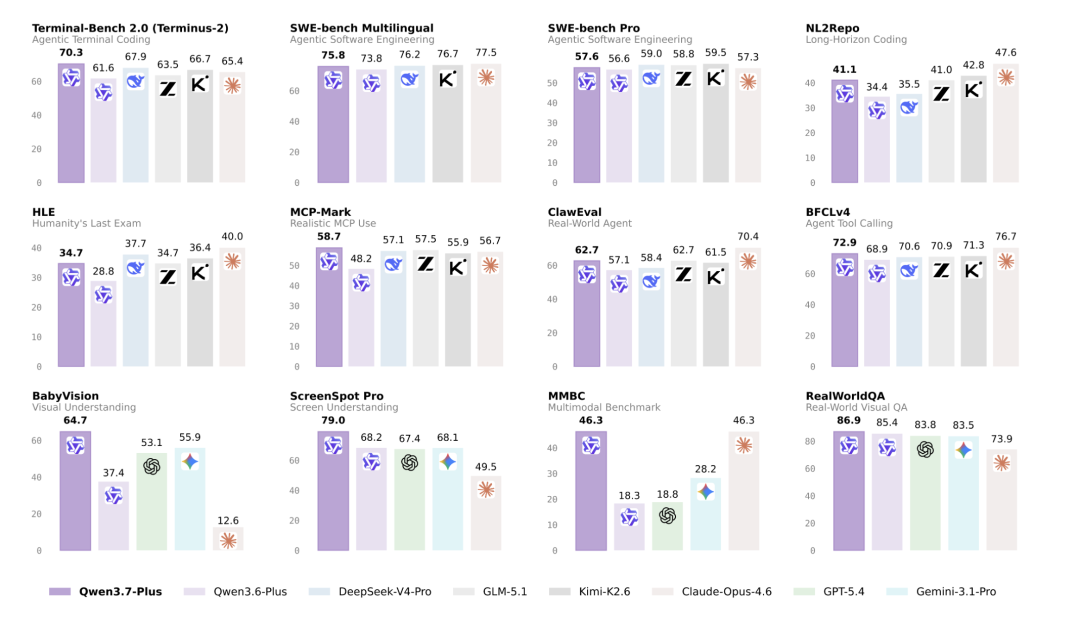
This actually means using domestic models for productivity products is completely viable.
So during this period, we've seen a flood of new product releases from model factories: Trae, Qoder, DeepSeek GUI, and Kimi Work, each achieving daily iteration.
Everyone's foundation is model capability. So as long as Kimi's new models can keep following the meta upward, the fam can casually build products and flex their taste however they want. Everything is additive value on top of the model — just buffs, really.
I don't know if this is the reason. In any case, Kimi Work has quite the variety packed into its narrow left sidebar: World Cup predictions, PPT, documents, deep research, websites, spreadsheets, agent cluster, Kimi Code, Kimi WebBridge, even Kimi Claw, among many other tabs.
The left sidebar even splits into Work and Chat views. I find this a bit absurd, because these are fundamentally the same thing — you can't just copy Claude's client because Claude does it 😭
The Claude client is complete garbage. A small suggestion here: when building agent clients, could everyone learn from Codex, which is actually better? Don't copy the bad stuff.
But this also completely doesn't matter. As long as Kimi's new models can keep following the meta, then all the product bros building stuff below counts as taste.
Right. As long as Claude and OpenAI across the ocean are crushing it, our Chinese prodigies will never lose.
Another fact: building a programming agent today is relatively easy.
The open-source community keeps popping out new programming agents — DeepSeek TUI was hot not long ago, now it's Pi coding agent. I tried the latter; the interface is very minimalist, the experience nothing special, but apparently the cache optimization is solid, very token-efficient.
Another example: my friend Erlich built an agent client early this year called Proma. Dude spent two days on the prototype, then iterated continuously. The user group seems quite active. Just goes to show that in product ideas, indie developers lead startups lead big-company teams.
In short, this truly is a great era. Analogous to the steam engine: we're still in the phase of competing to build wheels, inventing steam engines, and creating a new steam engine prototype only takes a day or two.
Our dear Kimi belongs to the chosen one of this meta.
In 2023, when foundation models first became great, Kimi entered the track with 200K-token ultra-long context, and Saint Yang and Moonshot AI's reputation shone upon AI circles like the full moon.
In the dark night when foundation model momentum weakened — those unbearable years of 2024-25 when old geezers howled that foundation models were a terrible business and glorious Claude Code had yet to spread — Kimi, aside from being brutally arbitrated by investors, fell into slumber like a sleeping prince, taking over a year to go from $3 billion to $4 billion valuation.
In 2026, when that arbitration case resurfaced, public opinion had flipped to: are the investors who missed out on foundation models the ones panicking?
The meta has swung back. Saint Yang and Yutong have made Moonshot AI great again.
(This article's cover image was generated by ChatGPT; purely human-written)
⬇️
Subscribe to our Substack
funeralai.substack.com